技术特征:
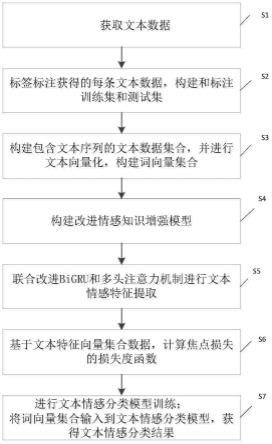
1.一种文本情感分类方法,其特征在于,包括:获取文本数据;标签标注获得的每条文本数据,构建和标注训练集和测试集;构建包含文本序列的文本数据集合,并进行文本向量化,构建词向量集合;构建改进情感知识增强模型;联合改进bigru和多头注意力机制进行文本情感特征提取;基于文本特征向量集合数据,计算焦点损失的损失度函数;进行文本情感分类模型训练;将词向量集合输入到文本情感分类模型,获得文本情感分类结果。2.根据权利要求1所述的一种文本情感分类方法,其特征在于,所述获取文本数据,包括:通过数据服务中心系统获取文本数据,以线上方式获取包括语音和文本的格式的在线情感数据,其中,将语音格式的数据转为文本数据。3.根据权利要求1所述的一种文本情感分类方法,其特征在于,所述构建包含文本序列的文本数据集合,并进行文本向量化,构建词向量集合,包括:标注数据集完成之后,令s={s1,s2,...,s
l
,...,s
n
},其中,s表示所有文本数据集合,s
l
表示第l条文本序列,表示第l条文本序列中的第i个字符,n表示文本数据集合有n条序列,m表示第l条文本序列中有m个字符;从文本序列s
l
中分别获取每个字符的向量和每个字符所对应的位置向量其中位置向量计算方式如下:其中,pos表示文本在文本序列中的具体位置,i表示向量维度,d
model
表示情感知识增强模型所接受的512维向量;将512维的向量和进行加和运算,获得文本输入向量t
l
,作为后续模型的输入,计算方式如下:其中,表示通过文本词嵌入和位置向量嵌入综合得到的后续情感知识增强模型所需要的输入向量,进而构成向量集合t={t1,t2,...,t
l
,...,t
n
}。4.根据权利要求1所述的一种文本情感分类方法,其特征在于,所述构建改进情感知识增强模型,包括:引入以自注意力机制为核心的transformer编码器与解码器架构;首先对情感词、情感词极性和属性词-情感词搭配二元组进行掩盖,并计算情感词的损失函数:
其中,表示第i个词经过transformer层后输入到softmax中所计算得到的概率分布,w
sw
表示情感词输出层的权重值,b
sw
表示情感词输出层的偏差值,m
i
表示情感词的标识符,若第i个词为情感词时m
i
=1,否则m
i
=0,y
isw
表示原始第i个词通过one-hot方式生成的向量表示;计算情感词极性的损失函数f
wp
::其中,表示第i个情感词的极性经过transformer层后输入到softmax中所计算得到的概率分布,w
wp
表示情感词极性输出层的权重值,b
wp
表示情感词极性输出层的偏差值,y
iwp
表示原始第i个情感词的极性通过one-hot方式生成的向量表示;计算属性词-情感词对的损失函数f
asp
::其中,表示第a个属性词-情感词对经过transformer层后输入到softmax中所计算得到的概率分布,w
asp
表示属性词-情感词对的输出层权重值,b
asp
表示属性词-情感词对的输出层偏差值,y
aasp
表示原始第a个属性词-情感词对通过one-hot方式生成的向量表示;针对上述三个损失函数,构建三目标优化模型(9),来权衡三个优化函数之间的关系,从而找到得到最优的多种情感任务的情感预训练目标优化函数,具体公式如下:max(f
sw
),max(f
wp
),max(f
asp
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(9)采用pareto优化策略求解三目标优化模型(9),获得优化情感词、情感词极性和属性词-情感词的模型权重,并改进情感知识增强模型,得到情感知识增强模型的输出集合x={x1,x2,...,x
l
,...,x
n
}。5.根据权利要求1所述的一种文本情感分类方法,其特征在于,所述联合改进bigru和多头注意力机制进行文本情感特征提取;包括:引入多头注意力机制来学习不同的子空间下情感文本的情感特征,提取联合改进bigru和多头注意力机制的情感文本情感特征,获取文本中的内部结构信息;通过公式(10)计算文本集合x中所有文本情感向量的隐藏特征值h
l
:其中,p1表示第l条信息文本前向gru所对应的权重,p2表示第l条信息文本反向gru所对应的权重,b
z
表示第l条信息文本的偏置,h
l
表示经过加权求和后的隐藏特征值,表示前向gru输出的隐藏状态值,表示反向gru输出的隐藏状态值。遍历计算每条文本对应的隐藏特征值,最后获得情感隐藏特征集合h={h1,h2,...,h
l
,...,h
n
};
结合获得的情感隐藏特征集合h,通过多头注意力机制来获取情感隐藏特征集合在不同的子空间下不同的特征表示能力,进行不同子空间下的权重计算与分配,将情感隐藏特征集合h中的每个隐藏特征值h
l
赋值给查询向量q、键向量k和值向量v,并计算如下公式:其中,attention()表示注意力函数,softmax()表示归一化指数函数,d
k
表示键向量k的维度;通过归一化指数函数来最大化每个查询向量q与键向量k乘积的概率分布,获得文本中每个字在上下文中的权重关系,从而提取情感上下文中最关键的词语特征信息;令第t次投影注意力函数计算后的值head
t
为head
t
=attention(qw
tq
,kw
tk
,vw
tv
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)其中,head
t
表示在第t次通过线性层投影下通过注意力机制计算后得到的值,w
tq
、w
tk
、w
tv
表示经过第t次投影学习到的权重值;通过多个head进行拼接得到多头注意力机制函数,计算方式如下:multihead(q,k,v)=concat(head1,head2,...,head
t
,...,head
h
)w
c
ꢀꢀꢀꢀꢀ
(13)其中,w
c
表示在拼接过程中学习到的权重参数,concat()表示将h个head进行拼接的函数,从而得到新的一个情感特征向量表示;最后,对于特征集合h的所有隐藏特征值进行多头注意力机制计算,从而得到新的情感特征向量表示集合m={m1,m2,...,m
l
,...,m
n
}。6.根据权利要求5所述的一种文本情感分类方法,其特征在于,所述基于文本特征向量集合数据,计算焦点损失的损失度函数,包括:结合权利要求5学习到新的特征向量集合数据,通过公式(14)计算焦点损失的损失度函数,通过调节难、易分类样本的权重系数来输出文本的情感标签,作为最后的标签输出结果;l=-α(1-p
r
)
γ
log(p
r
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)其中,p
r
为文本情感分类模型预测情感特征向量m
l
的概率,α和γ为文本情感权重调节系数。7.根据权利要求1所述的一种文本情感分类方法,其特征在于,所述进行文本情感分类模型训练,包括:在训练过程中,迭代计算所有文本情感特征向量预测的概率对应的损失值当损失函数值大于预设阈值ε,则更新模型参数继续训练,否则,通过迭代计算得到模型的最小化损失函数值,即为模型训练的最终目标。8.一种文本情感分类系统,其特征在于,包括:文本数据预处理模块:用于获取文本数据;标签标注获得的每条文本数据,构建和标注训练集和测试集;构建包含文本序列的文本数据集合,并进行文本向量化,构建词向量集合;文本情感分类模型构建模块:用于构建改进情感知识增强模型;联合改进bigru和多头注意力机制进行文本情感特征提取;基于文本特征向量集合数据,计算焦点损失的损失度函数;进行文本情感分类模型训练;
文本情感分类模块:用于将词向量集合输入到文本情感分类模型,获得文本情感分类结果。9.一种文本情感分类装置,其特征在于,包括:输入设备、输出设备、存储器、处理器;所述输入设备、所述输出设备、所述存储器和所述处理器相互连接,其中,所述存储器用于存储计算机程序,所述计算机程序包括程序指令,所护处理器被配置调用所述程序指令,执行如权利要求1-7中任一所述的一种文本情感分类方法。10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器所执行时执行如权利要求1-7中任一所述的一种文本情感分类方法。
技术总结
本发明提供一种文本情感分类方法、系统、装置及计算机介质,包括:获取文本数据;标签标注获得的每条文本数据,构建和标注训练集和测试集;构建包含文本序列的文本数据集合,并进行文本向量化,构建词向量集合;构建改进情感知识增强模型;联合改进BiGRU和多头注意力机制进行文本情感特征提取;基于文本特征向量集合数据,计算焦点损失的损失度函数;进行文本情感分类模型训练;将词向量集合输入到文本情感分类模型,获得文本情感分类结果,解决了现有技术中文本情感分类准确率低的问题。有技术中文本情感分类准确率低的问题。有技术中文本情感分类准确率低的问题。
技术研发人员:陈友荣 王本安 张旭东 吕晓雯 缪克雷 刘半藤
受保护的技术使用者:浙江树人学院
技术研发日:2022.07.22
技术公布日:2022/11/25
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。