1.本发明涉及数据处理技术领域,具体而言,涉及一种数据生态链应用系统和应用方法。
背景技术:
2.目前,大数据分析技术广泛应用于各行各业中,其能够对行业相关的大数据进行分析挖掘,从而基于行业的需求,得到可行性的解决方案。其中,进行大数据分析的基础是,针对不同的行业形成不同的数据生态链,但是,在现有技术中,构建的数据生态链一般是直接基于产业的上下游关系进行构建,使得形成的数据生态链存在可靠度不佳的问题。
技术实现要素:
3.有鉴于此,本发明的目的在于提供一种数据生态链应用系统和应用方法,以改善现有技术中形成的数据生态链的可靠度不佳的问题。
4.为实现上述目的,本发明实施例采用如下技术方案:
5.一种数据生态链应用方法,包括:
6.从目标数据库中获取到多条待处理数据生态链,所述多条待处理数据生态链中的每一条待处理数据生态链包括具有先后关系的多个生态链节点,每一个所述生态链节点包括具有时间先后关系的多条节点数据;
7.对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度,所述生态链节点关联度用于表征对应的所述待处理数据生态链中各生态链节点包括的节点数据之间的数据关联度;
8.对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链,所述目标数据生态链包括的生态链节点的数量小于或等于对应的待处理数据生态链包括的生态链节点的数量。
9.在一些优选的实施例中,在上述数据生态链应用方法中,所述从目标数据库中获取到多条待处理数据生态链的步骤,包括:
10.从目标数据库中获取到多条节点数据,并获取到所述多条节点数据中的每一条节点数据对应的数据标识信息;
11.根据每一条所述节点数据对应的数据标识信息对获取到的所述多条节点数据进行生态链构建处理,以输出对应的多条待处理数据生态链。
12.在一些优选的实施例中,在上述数据生态链应用方法中,所述根据每一条所述节点数据对应的数据标识信息对获取到的所述多条节点数据进行生态链构建处理,以输出对应的多条待处理数据生态链的步骤,包括:
13.根据预先配置的产业链分类规则和每一条所述节点数据对应的数据标识信息,对
获取到的所述多条节点数据进行数据分类处理,以输出多个数据分类集合,每一个所述数据分类集合包括的多条节点数据属于相同的产业链,不同所述数据分类集合包括的节点数据属于不同的产业链;
14.对于所述多个数据分类集合中的每一个数据分类集合,根据预先配置的节点分类规则和每一条所述节点数据对应的数据标识信息,对该数据分类集合包括的多条节点数据进行分类处理,以输出多个生态链节点,每一个所述生态链节点包括的多个节点数据属于同一产业,不同所述生态链节点包括的节点数据属于不同产业;
15.对于所述多个数据分类集合中的每一个数据分类集合,根据预先配置的产业排序关系和每一条所述节点数据对应的数据标识信息,对该数据分类集合包括的多个生态链节点进行排序处理,以输出该数据分类集合对应的待处理数据生态链,每一条所述待处理数据生态链中的任意相邻两个生态链节点分别属于对应的上游产业和下游产业。
16.在一些优选的实施例中,在上述数据生态链应用方法中,所述对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度的步骤,包括:
17.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每一个生态链节点进行数据特征提取处理,以输出每一个生态链节点对应的节点数据特征信息,每一条所述节点数据特征信息用于表征对应的生态链节点的数据变化特征;
18.对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点对应的节点数据特征信息进行数据分析,以输出该待处理数据生态链对应的生态链节点关联度。
19.在一些优选的实施例中,在上述数据生态链应用方法中,所述对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点对应的节点数据特征信息进行数据分析,以输出该待处理数据生态链对应的生态链节点关联度的步骤,包括:
20.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每相邻两个生态链节点对应的节点数据特征信息进行相似度计算,以输出每相邻两个生态链节点对应的特征相似度;
21.对于所述多条待处理数据生态链中的每一条待处理数据生态链,对该待处理数据生态链包括的每相邻两个生态链节点对应的特征相似度进行均值计算,以输出该待处理数据生态链对应的生态链节点关联度。
22.在一些优选的实施例中,在上述数据生态链应用方法中,所述对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链的步骤,包括:
23.对于所述多条待处理数据生态链中的每一条待处理数据生态链,对该待处理数据生态链对应的生态链节点关联度与预先配置的节点关联度阈值进行大小比较处理,以输出该待处理数据生态链对应的大小比较结果;
24.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数
据生态链对应的大小比较结果表征对应的生态链节点关联度小于或等于所述节点关联度阈值,则筛除该待处理数据生态链中的每一个生态链节点,以输出该待处理数据生态链对应的目标数据生态链,该目标数据生态链包括的生态链节点的数量为0;
25.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度大于所述节点关联度阈值,则根据该待处理数据生态链包括的每两个生态链节点之间的特征相似度对该待处理数据生态链包括的生态链节点进行优化,以输出该待处理数据生态链对应的目标数据生态链,所述特征相似度用于表征对应的两个生态链节点关于节点数据的变化特征之间的相似度。
26.在一些优选的实施例中,在上述数据生态链应用方法中,所述对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度大于所述节点关联度阈值,则根据该待处理数据生态链包括的每两个生态链节点之间的特征相似度对该待处理数据生态链包括的生态链节点进行优化,以输出该待处理数据生态链对应的目标数据生态链的步骤,包括:
27.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度大于所述节点关联度阈值,则分别对该待处理数据生态链包括的每一个生态链节点进行数据特征提取处理,以输出每一个生态链节点对应的节点数据特征信息,每一条所述节点数据特征信息属于对应的一条数据序列,用于表征对应的生态链节点的数据变化特征,每一条所述数据序列包括对应的生态链节点中每相邻两条节点数据之间的数据差值;
28.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每两个生态链节点对应的节点数据特征信息进行相似度计算,以输出每两个生态链节点对应的特征相似度;
29.对于所述多条待处理数据生态链中的每一条待处理数据生态链,依次对该待处理数据生态链包括的每一个生态链节点进行遍历,并将当前遍历到的生态链节点确定为根节点,以及,将与当前遍历到的生态链节点之间的特征相似度大于或等于预先配置的相似度阈值、且排序位于当前遍历到的生态链节点之后的每一个生态链节点设置为当前遍历到的生态链节点的叶子节点,对于每一个叶子节点,将与该叶子节点之间的特征相似度大于或等于所述相似度阈值、且排序位于该叶子节点之后的每一个生态链节点设置为当该叶子节点的下一级叶子节点,如此循环,直到不能确定出新的下一级叶子节点,以输出当前遍历到的生态链节点对应的节点树;
30.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每一个生态链节点对应的节点树进行遍历,以输出每一个生态链节点对应的节点树中的最长遍历路径,从而输出该待处理数据生态链对应的多条最长遍历路径;
31.对于所述多条待处理数据生态链中的每一条待处理数据生态链对应的每一条最长遍历路径,分别计算该最长遍历路径中每相邻两个生态链节点之间在该待处理数据生态链中的间隔节点数量,并对每相邻两个生态链节点之间的间隔节点数量进行离散值计算,以输出该最长遍历路径对应的节点数量离散值,以及,对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据具有最小值的节点数量离散值对应的最长遍历路径,对该待处理数据生态链包括的生态链节点进行优化,以输出该待处理数据生态链对应的目标
数据生态链。
32.本发明实施例还提供一种数据生态链应用系统,包括:
33.数据生态链获取模块,用于从目标数据库中获取到多条待处理数据生态链,所述多条待处理数据生态链中的每一条待处理数据生态链包括具有先后关系的多个生态链节点,每一个所述生态链节点包括具有时间先后关系的多条节点数据;
34.节点关联度确定模块,用于对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度,所述生态链节点关联度用于表征对应的所述待处理数据生态链中各生态链节点包括的节点数据之间的数据关联度;
35.数据生态链优化模块,用于对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链,所述目标数据生态链包括的生态链节点的数量小于或等于对应的待处理数据生态链包括的生态链节点的数量。
36.在一些优选的实施例中,在上述数据生态链应用系统中,所述节点关联度确定模块具体用于:
37.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每一个生态链节点进行数据特征提取处理,以输出每一个生态链节点对应的节点数据特征信息,每一条所述节点数据特征信息用于表征对应的生态链节点的数据变化特征;
38.对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点对应的节点数据特征信息进行数据分析,以输出该待处理数据生态链对应的生态链节点关联度。
39.在一些优选的实施例中,在上述数据生态链应用系统中,所述数据生态链优化模块具体用于:
40.对于所述多条待处理数据生态链中的每一条待处理数据生态链,对该待处理数据生态链对应的生态链节点关联度与预先配置的节点关联度阈值进行大小比较处理,以输出该待处理数据生态链对应的大小比较结果;
41.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度小于或等于所述节点关联度阈值,则筛除该待处理数据生态链中的每一个生态链节点,以输出该待处理数据生态链对应的目标数据生态链,该目标数据生态链包括的生态链节点的数量为0;
42.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度大于所述节点关联度阈值,则根据该待处理数据生态链包括的每两个生态链节点之间的特征相似度对该待处理数据生态链包括的生态链节点进行优化,以输出该待处理数据生态链对应的目标数据生态链,所述特征相似度用于表征对应的两个生态链节点关于节点数据的变化特征之间的相似度。
43.本发明实施例提供的一种数据生态链应用系统和应用方法,即先获取到多条待处理数据生态链,然后,对于多条待处理数据生态链中的每一条待处理数据生态链,根据该待
处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度,最后,对于多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链。如此,在获取到数据生态链的基础上,进一步进行优化处理,使得得到的目标数据生态链更佳可靠,从而改善现有技术中形成的数据生态链的可靠度不佳的问题。
44.为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
45.图1为本发明实施例提供的数据处理服务器的结构框图。
46.图2为本发明实施例提供的数据生态链应用方法包括的各步骤的流程示意图。
47.图3为本发明实施例提供的数据生态链应用系统包括的各模块的示意图。
具体实施方式
48.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例只是本发明的一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
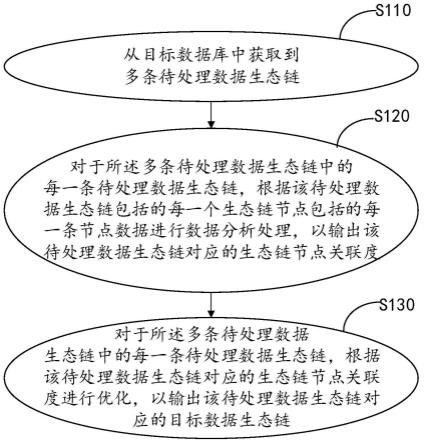
49.因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
50.如图1所示,本发明实施例提供了一种数据处理服务器。其中,所述数据处理服务器可以包括存储器和处理器。
51.详细地,所述存储器和处理器之间直接或间接地电性连接,以实现数据的传输或交互。例如,相互之间可通过一条或多条通讯总线或信号线实现电性连接。所述存储器中可以存储有至少一个可以以软件或固件(firmware)的形式,存在的软件功能模块(计算机程序)。所述处理器可以用于执行所述存储器中存储的可执行的计算机程序,从而实现本发明实施例提供的数据生态链应用方法。
52.所述存储器可以是,但不限于,随机存取存储器(random access memory,ram),只读存储器(read only memory,rom),可编程只读存储器(programmable read-only memory,prom),可擦除只读存储器(erasable programmable read-only memory,eprom),电可擦除只读存储器(electric erasable programmable read-only memory,eeprom)等。
53.所述处理器可以是一种通用处理器,包括中央处理器(central processing unit,cpu)、网络处理器(network processor,np)、片上系统(system on chip,soc)等;还可以是数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
54.结合图2,本发明实施例还提供一种数据生态链应用方法,可应用于上述数据处理
服务器。其中,所述数据生态链应用方法有关的流程所定义的方法步骤,可以由所述数据处理服务器实现。
55.下面将对图2所示的具体流程,进行详细阐述。
56.步骤s110,从目标数据库中获取到多条待处理数据生态链。
57.在本发明实施例中,所述数据处理服务器可以从目标数据库中获取到多条待处理数据生态链。所述多条待处理数据生态链中的每一条待处理数据生态链包括具有先后关系的多个生态链节点,每一个所述生态链节点包括具有时间先后关系的多条节点数据。
58.步骤s120,对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度。
59.在本发明实施例中,所述数据处理服务器可以对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度。
60.所述生态链节点关联度用于表征对应的所述待处理数据生态链中各生态链节点包括的节点数据之间的数据关联度。
61.步骤s130,对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链。
62.在本发明实施例中,所述数据处理服务器可以对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链。所述目标数据生态链包括的生态链节点的数量小于或等于对应的待处理数据生态链包括的生态链节点的数量。
63.基于上述的数据生态链应用方法,即先获取到多条待处理数据生态链,然后,对于多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度,最后,对于多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链。如此,在获取到数据生态链的基础上,进一步进行优化处理,使得得到的目标数据生态链更佳可靠,从而改善现有技术中形成的数据生态链的可靠度不佳的问题。
64.具体而言,上述的步骤s110可以进一步包括以下内容:
65.从目标数据库中获取到多条节点数据,并获取到所述多条节点数据中的每一条节点数据对应的数据标识信息;
66.根据每一条所述节点数据对应的数据标识信息对获取到的所述多条节点数据进行生态链构建处理,以输出对应的多条待处理数据生态链。
67.具体而言,上述的所述根据每一条所述节点数据对应的数据标识信息对获取到的所述多条节点数据进行生态链构建处理,以输出对应的多条待处理数据生态链的步骤,可以进一步包括以下内容:
68.根据预先配置的产业链分类规则和每一条所述节点数据对应的数据标识信息,对
获取到的所述多条节点数据进行数据分类处理,以输出多个数据分类集合,每一个所述数据分类集合包括的多条节点数据属于相同的产业链,不同所述数据分类集合包括的节点数据属于不同的产业链;
69.对于所述多个数据分类集合中的每一个数据分类集合,根据预先配置的节点分类规则和每一条所述节点数据对应的数据标识信息,对该数据分类集合包括的多条节点数据进行分类处理,以输出多个生态链节点,每一个所述生态链节点包括的多个节点数据属于同一产业,不同所述生态链节点包括的节点数据属于不同产业;
70.对于所述多个数据分类集合中的每一个数据分类集合,根据预先配置的产业排序关系和每一条所述节点数据对应的数据标识信息,对该数据分类集合包括的多个生态链节点进行排序处理,以输出该数据分类集合对应的待处理数据生态链,每一条所述待处理数据生态链中的任意相邻两个生态链节点分别属于对应的上游产业和下游产业。
71.具体而言,上述的步骤s120可以进一步包括以下内容:
72.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每一个生态链节点进行数据特征提取处理,以输出每一个生态链节点对应的节点数据特征信息,每一条所述节点数据特征信息用于表征对应的生态链节点的数据变化特征;
73.对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点对应的节点数据特征信息进行数据分析,以输出该待处理数据生态链对应的生态链节点关联度。
74.具体而言,上述的所述对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点对应的节点数据特征信息进行数据分析,以输出该待处理数据生态链对应的生态链节点关联度的步骤,可以进一步包括以下内容:
75.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每相邻两个生态链节点对应的节点数据特征信息进行相似度计算,以输出每相邻两个生态链节点对应的特征相似度;
76.对于所述多条待处理数据生态链中的每一条待处理数据生态链,对该待处理数据生态链包括的每相邻两个生态链节点对应的特征相似度进行均值计算,以输出该待处理数据生态链对应的生态链节点关联度。
77.具体而言,上述的所述对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每相邻两个生态链节点对应的节点数据特征信息进行相似度计算,以输出每相邻两个生态链节点对应的特征相似度的步骤,可以进一步包括以下内容:
78.分别将相邻的两个生态链节点对应的节点数据特征信息设置为第一数据序列和第二数据序列,所述节点数据特征信息属于对应的一条数据序列,所述第一数据序列包括对应的生态链节点中每相邻两条节点数据之间的第一数据差值,所述第二数据序列包括对应的生态链节点中每相邻两条节点数据之间的第二数据差值;
79.分别对所述第一数据序列和所述第二数据序列中每一个序列位置对应的第一数据差值和第二数据差值进行求差处理,以输出每一个序列位置对应的求差值,并对每一个
序列位置对应的求差值进行均值计算,以输出对应的求差均值,再根据该求差均值进行负相关值确定处理,以输出所述第一数据序列和所述第二数据序列对应的相似系数;
80.从所述第一数据序列中,提取出至少一个第一数据差值,并将该至少一个第一数据差值设置为目标第一数据差值,以及,对于每一个所述第一数据差值,分别对该第一数据差值与每一个所述目标第一数据差值进行求差处理,以输出该第一数据差值对应的多个求差值,再将该第一数据差值分配至该多个求差值中具有最小值的求差值对应的目标第一数据差值对应的第一数据差值集合中;
81.对于每一个所述第一数据差值集合,对该第一数据差值集合中的每两个第一数据差值之间的求差值进行大小比较处理,且倘若该第一数据差值集合中的每两个第一数据差值之间的求差值小于预设值,则将该第一数据差值集合设置为候选第一数据差值集合,以及,倘若当前得到的每一个所述第一数据差值集合都被设置为所述候选第一数据差值集合,则将当前得到的每一个所述第一数据差值集合设置为目标第一数据差值集合,或者,倘若当前得到至少一个第一数据差值集合未被设置为所述候选第一数据差值集合,则再次执行所述从所述第一数据序列中,提取出至少一个第一数据差值,并将该至少一个第一数据差值设置为目标第一数据差值,以及,对于每一个所述第一数据差值,分别对该第一数据差值与每一个所述目标第一数据差值进行求差处理,以输出该第一数据差值对应的多个求差值,再将该第一数据差值分配至该多个求差值中具有最小值的求差值对应的目标第一数据差值对应的第一数据差值集合中的步骤,直到当前得到的每一个所述第一数据差值集合都被设置为所述候选第一数据差值集合;
82.从所述第二数据序列中,提取出至少一个第二数据差值,并将该至少一个第二数据差值设置为目标第二数据差值,以及,对于每一个所述第二数据差值,分别对该第二数据差值与每一个所述目标第二数据差值进行求差处理,以输出该第二数据差值对应的多个求差值,再将该第二数据差值分配至该多个求差值中具有最小值的求差值对应的目标第二数据差值对应的第二数据差值集合中;
83.对于每一个所述第二数据差值集合,对该第二数据差值集合中的每两个第二数据差值之间的求差值进行大小比较处理,且倘若该第二数据差值集合中的每两个第二数据差值之间的求差值小于预设值,则将该第二数据差值集合设置为候选第二数据差值集合,以及,倘若当前得到的每一个所述第二数据差值集合都被设置为所述候选第二数据差值集合,则将当前得到的每一个所述第二数据差值集合设置为目标第二数据差值集合,或者,倘若当前得到至少一个第二数据差值集合未被设置为所述候选第二数据差值集合,则再次执行所述从所述第二数据序列中,提取出至少一个第二数据差值,并将该至少一个第二数据差值设置为目标第二数据差值,以及,对于每一个所述第二数据差值,分别对该第二数据差值与每一个所述目标第二数据差值进行求差处理,以输出该第二数据差值对应的多个求差值,再将该第二数据差值分配至该多个求差值中具有最小值的求差值对应的目标第二数据差值对应的第二数据差值集合中的步骤,直到当前得到的每一个所述第二数据差值集合都被设置为所述候选第二数据差值集合;
84.分别统计每一个所述目标第一数据差值集合包括的第一数据差值的数量,并根据该数量对每一个所述目标第一数据差值集合进行排序,以输出对应的第一集合序列,分别统计每一个所述目标第二数据差值集合包括的第二数据差值的数量,并根据该数量对每一
个所述目标第二数据差值集合进行排序,以输出对应的第二集合序列;
85.对于所述第一集合序列和所述第二集合序列中相同的每一个序列位置,根据该序列位置在所述第一集合序列中的目标第一数据差值集合和在所述第二集合序列中的目标第二数据差值集合进行重合度计算,以输出该序列位置对应的集合重合度,并根据每一个序列位置对应的集合重合度进行均值计算,以输出所述第一数据序列和所述第二数据序列对应的重合度均值,以及,根据所述第一数据序列和所述第二数据序列对应的相似系数和所述第一数据序列和所述第二数据序列对应的重合度均值进行融合处理,以输出所述两个生态链节点对应的特征相似度(可以进行加权求和计算,所述相似系数对应的加权系数大于所述特征相似度对应的加权系数)。
86.具体而言,上述的步骤s130可以进一步包括以下内容:
87.对于所述多条待处理数据生态链中的每一条待处理数据生态链,对该待处理数据生态链对应的生态链节点关联度与预先配置的节点关联度阈值进行大小比较处理,以输出该待处理数据生态链对应的大小比较结果;
88.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度小于或等于所述节点关联度阈值,则筛除该待处理数据生态链中的每一个生态链节点,以输出该待处理数据生态链对应的目标数据生态链,该目标数据生态链包括的生态链节点的数量为0;
89.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度大于所述节点关联度阈值,则根据该待处理数据生态链包括的每两个生态链节点之间的特征相似度对该待处理数据生态链包括的生态链节点进行优化,以输出该待处理数据生态链对应的目标数据生态链,所述特征相似度用于表征对应的两个生态链节点关于节点数据的变化特征之间的相似度。
90.具体而言,上述的所述对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度大于所述节点关联度阈值,则根据该待处理数据生态链包括的每两个生态链节点之间的特征相似度对该待处理数据生态链包括的生态链节点进行优化,以输出该待处理数据生态链对应的目标数据生态链的步骤,可以进一步包括以下内容:
91.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度大于所述节点关联度阈值,则分别对该待处理数据生态链包括的每一个生态链节点进行数据特征提取处理,以输出每一个生态链节点对应的节点数据特征信息,每一条所述节点数据特征信息属于对应的一条数据序列,用于表征对应的生态链节点的数据变化特征,每一条所述数据序列包括对应的生态链节点中每相邻两条节点数据之间的数据差值;
92.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每两个生态链节点对应的节点数据特征信息进行相似度计算,以输出每两个生态链节点对应的特征相似度;
93.对于所述多条待处理数据生态链中的每一条待处理数据生态链,依次对该待处理数据生态链包括的每一个生态链节点进行遍历,并将当前遍历到的生态链节点确定为根节点,以及,将与当前遍历到的生态链节点之间的特征相似度大于或等于预先配置的相似度
阈值、且排序位于当前遍历到的生态链节点之后的每一个生态链节点设置为当前遍历到的生态链节点的叶子节点,对于每一个叶子节点,将与该叶子节点之间的特征相似度大于或等于所述相似度阈值、且排序位于该叶子节点之后的每一个生态链节点设置为当该叶子节点的下一级叶子节点,如此循环,直到不能确定出新的下一级叶子节点,以输出当前遍历到的生态链节点对应的节点树;
94.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每一个生态链节点对应的节点树进行遍历,以输出每一个生态链节点对应的节点树中的最长遍历路径,从而输出该待处理数据生态链对应的多条最长遍历路径;
95.对于所述多条待处理数据生态链中的每一条待处理数据生态链对应的每一条最长遍历路径,分别计算该最长遍历路径中每相邻两个生态链节点之间在该待处理数据生态链中的间隔节点数量,并对每相邻两个生态链节点之间的间隔节点数量进行离散值计算,以输出该最长遍历路径对应的节点数量离散值,以及,对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据具有最小值的节点数量离散值对应的最长遍历路径,对该待处理数据生态链包括的生态链节点进行优化,以输出该待处理数据生态链对应的目标数据生态链(即该最长遍历路径)。
96.结合图3,本发明实施例还提供一种数据生态链应用系统,可应用于上述数据处理服务器。其中,所述数据生态链应用系统可以包括:
97.数据生态链获取模块,用于从目标数据库中获取到多条待处理数据生态链,所述多条待处理数据生态链中的每一条待处理数据生态链包括具有先后关系的多个生态链节点,每一个所述生态链节点包括具有时间先后关系的多条节点数据;
98.节点关联度确定模块,用于对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度,所述生态链节点关联度用于表征对应的所述待处理数据生态链中各生态链节点包括的节点数据之间的数据关联度;
99.数据生态链优化模块,用于对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链,所述目标数据生态链包括的生态链节点的数量小于或等于对应的待处理数据生态链包括的生态链节点的数量。
100.具体而言,所述节点关联度确定模块具体用于:
101.对于所述多条待处理数据生态链中的每一条待处理数据生态链,分别对该待处理数据生态链包括的每一个生态链节点进行数据特征提取处理,以输出每一个生态链节点对应的节点数据特征信息,每一条所述节点数据特征信息用于表征对应的生态链节点的数据变化特征;
102.对于所述多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点对应的节点数据特征信息进行数据分析,以输出该待处理数据生态链对应的生态链节点关联度。
103.具体而言,所述数据生态链优化模块具体用于:
104.对于所述多条待处理数据生态链中的每一条待处理数据生态链,对该待处理数据
生态链对应的生态链节点关联度与预先配置的节点关联度阈值进行大小比较处理,以输出该待处理数据生态链对应的大小比较结果;
105.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度小于或等于所述节点关联度阈值,则筛除该待处理数据生态链中的每一个生态链节点,以输出该待处理数据生态链对应的目标数据生态链,该目标数据生态链包括的生态链节点的数量为0;
106.对于所述多条待处理数据生态链中的每一条待处理数据生态链,倘若该待处理数据生态链对应的大小比较结果表征对应的生态链节点关联度大于所述节点关联度阈值,则根据该待处理数据生态链包括的每两个生态链节点之间的特征相似度对该待处理数据生态链包括的生态链节点进行优化,以输出该待处理数据生态链对应的目标数据生态链,所述特征相似度用于表征对应的两个生态链节点关于节点数据的变化特征之间的相似度。
107.综上所述,本发明提供的一种数据生态链应用系统和应用方法,即先获取到多条待处理数据生态链,然后,对于多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链包括的每一个生态链节点包括的每一条节点数据进行数据分析处理,以输出该待处理数据生态链对应的生态链节点关联度,最后,对于多条待处理数据生态链中的每一条待处理数据生态链,根据该待处理数据生态链对应的生态链节点关联度进行优化,以输出该待处理数据生态链对应的目标数据生态链。在获取到数据生态链的基础上,进一步进行优化处理,使得得到的目标数据生态链更佳可靠,从而改善现有技术中形成的数据生态链的可靠度不佳的问题。
108.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
