1.本发明涉及计算机科学人工智能领域,尤其涉及一种针对基于强化学习的深度学习gpu显存管理的内存调度决策的模型训练方法与系统。
背景技术:
2.深度学习技术的革新大大推动了计算机视觉,自然语言处理,医学等领域的发展。为了进一步提高准确率,深度学习模型规模不断增大,结构更加复杂,这对于训练设备的存储空间提出了更高的需求。然而,以gpu为代表的深度学习加速器的存储空间有限,限制了研究人员开发探索规模更大的网络,制约了深度学习技术的迭代。目前常用的内存优化方案在训练过程中选择将gpu显存内暂时不需要的部分层数据转移至系统内存,以减轻gpu显存压力,并在后期需要访问该数据前将所需数据转移回gpu显存。该技术的难点是选择哪些数据在什么阶段进行交换。然而,gpu-cpu之间的转移带宽有限,粗粒度的交换大量数据使得转移时间较长,引入无法忽略的通信延迟。现有方案通过使用传统启发式方法或专家经验进行转移策略设计。但是,难以在大规模的神经网络上决策出较优的数据转移方案,从而带来严重的模型训练性能损耗。
技术实现要素:
3.本发明的目的是针对现有技术的不足,提出一种基于强化学习内存调度决策的模型训练方法及系统。
4.本发明采用的技术方案具体如下:
5.一种基于强化学习内存调度决策的模型训练方法,包括以下步骤:
6.步骤一:在第一轮迭代训练过程中,初始化调度方案;
7.步骤二:采集上一轮次神经网络模型迭代训练完后的gpu的内存空间、转移带宽,以及神经网络模型的网络层信息,记录数据的大小、各层的依赖关系;并根据采集的信息计算数据交换时间和训练时间;
8.步骤三:基于步骤二获取的信息动态决策每轮次的调度方案,包括以下子步骤:
9.(3.1)对步骤二获得的训练时间、内存空间消耗进行归一化处理后,进行加权评估作为上一轮次的奖励收益。
10.(3.2)根据步骤(3.1)获得的上一轮次的奖励收益和上一轮次获得的反馈值q采用ε-greedy算法,选择当前轮次等待交换的张量和当前轮次的调度方案,神经网络模型依据调度方案进行当前轮次训练;
11.(3.3)根据上一轮次的反馈值q、奖励收益以及当前轮次的调度方案,对反馈值q进行更新并存储至q表;
12.步骤四:重复步骤二、三进行迭代训练;随着迭代次数增加,调度方案将收敛到调度最优解;当达到预期训练效果时,结束训练。
13.进一步地,所述步骤(3.1)中,当前轮次的奖励收益r
plan
具体如下:
14.r
plan
=r
time
w(r
mem-r
time
)
15.其中,r
time
表示上一轮次的训练时间,r
mem
表示上一轮次的训练消耗的gpu内存空间,w表示在奖励收益r
plan
中,上一轮次的训练消耗的gpu内存空间r
mem
所占据的比例。
16.进一步地,所述步骤(3.3)中,对反馈值q进行更新具体为:
17.qk(s,t)=q
k-1
(s,t) α[r
plan
γq
k-1
(s',t')-q
k-1
(s,t)]
[0018]
其中,k表示当前轮次,k-1表示上一轮次,t是上一轮次被交换的数据张量,s是上一轮次采用的调度方案,t'、s'分别是当前轮次被交换的数据张量和采用的调度方案,r
plan
是上一轮次的奖励收益,α是学习率,γ是折扣因子;q
k-1
(s,t)表示第k-1轮次,被交换的数据张量为t和采用的调度方案为s时的反馈值,q
k-1
(s',t')表示第k-1轮次,被交换的数据张量为t'和采用的调度方案为s'时的反馈值,q
k-1
(s,t)、q
k-1
(s',t')依据q表查找获得。
[0019]
进一步地,所述步骤(3.2)中,采用ε-greedy算法,选择当前轮次等待交换的张量和当前轮次的调度方案时,每轮次只选择同一种网络层类型对应的张量作为等待交换的张量。
[0020]
进一步地,所述模型训练方法包括预训练和正式训练,其中,预训练采用部分训练数据进行训练并动态决策每轮次的调度方案,正式训练采用全部训练数据在预训练的基础上继续进行训练并动态决策每轮次的调度方案。
[0021]
一种基于强化学习内存调度决策的模型训练系统,用于实现上述基于强化学习内存调度决策的模型训练方法,包括:
[0022]
采集模块,用于采集上一轮次神经网络模型迭代训练完后的gpu的内存空间、转移带宽,以及神经网络模型的网络层信息,记录数据的大小、各层的依赖关系;并根据采集的信息计算数据交换的对应时间和训练时间;
[0023]
决策模块,用于基于采集模块获取的信息动态决策每轮次的调度方案;
[0024]
训练模块,依据采集模块和决策模块的数据进行迭代训练;随着迭代次数增加,调度方案将收敛到调度最优解;当达到预期训练效果时,结束训练。
[0025]
本发明的有益效果是:本发明基于强化学习算法,对于训练过程中产生的训练信息进行分析,并根据反馈更新决策方案,决定对哪些数据进行转移。从而进一步优化内存空间,并提高深度学习模型训练的整体性能。
附图说明
[0026]
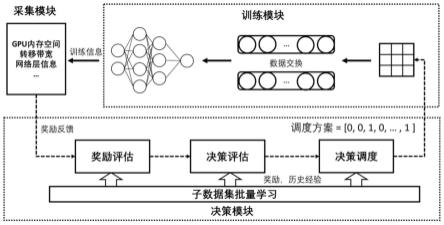
图1是系统架构图
[0027]
图2是决策过程流程图
[0028]
图3是cifar10上训练支持的最大批量增长比例统计图
[0029]
图4是子数据集批量学习优化效果结果图
具体实施方式
[0030]
下面结合附图和具体实施例对本发明作进一步说明。
[0031]
本发明提供一种基于强化学习内存调度决策的模型训练方法,如图2所示,包括以下步骤:
[0032]
步骤一:用户通过接口完成模型代码的实现后,在第一轮迭代训练过程中,深度学
习框架会初始化调度方案s并进行训练。调度方案描述了每轮次迭代中,训练数据中每个张量是否在迭代中被交换,包括选择的被交换的张量和不交换的张量;一般地,调度方案可以采用二维数组表示,即将数据的状态使用二维数组进行表示,以便于策略拓展。在调度方案中,每个二维数组的维度为2,其中,调度策略为0表示保留在gpu内存中,为1表示进行数据交换。一系列数组构成了一个状态,决策的变化过程体现为状态间的转移。系统的最终目标,是求解得到一组数组,从而达到理想的训练效果。初始化调度方案s可以自行设定。
[0033]
步骤二:自第二轮次训练开始,每轮次训练时先采集上一轮次神经网络模型迭代训练完后的gpu的内存空间、转移带宽,以及神经网络模型的网络层信息,记录数据的大小、各层的依赖关系;并根据上一轮次的调度方案结合带宽计算数据交换时间和训练时间;其中,各层的依赖关系用于在训练过程中数据交换时保证数据交换的正确。比如保证当前层开始反向计算时,依赖层的数据要在gpu内存。
[0034]
步骤三:基于步骤一获取的信息进行动态决策,该步骤是本发明的核心,可以分为以下子步骤:
[0035]
(3.1)对步骤二获得的训练时间、内存空间消耗进行归一化处理后,进行加权评估作为上一轮次的奖励收益,上一轮次的奖励收益是上一轮决策的调度方案的动作收益。示例性地,可以采用如下方法进行计算:
[0036]rplan
=r
time
w(r
mem-r
time
)
[0037]
其中,r
time
表示上一轮次的训练时间(单位ms),r
mem
表示上一轮次的训练消耗的gpu内存空间,w表示在奖励收益r
plan
中,上一轮次的训练消耗的gpu内存空间r
mem
所占据的比例(权重),取值在0-1之间。动态决策的学习目标是这一奖励目标值最小化。
[0038]
(3.2)根据步骤(3.1)获得的上一轮次的奖励收益和上一轮次获得的反馈值q采用ε-greedy算法,选择当前轮次等待交换的张量和当前轮次的调度方案并记录,神经网络模型依据调度方案进行当前轮次训练;
[0039]
(3.3)根据上一轮次的反馈值q、奖励收益以及当前轮次的调度方案,对上一轮次的策略选择进行评估,对反馈值q进行更新并存储至q表,为调度决策提供依据;
[0040]
对反馈值q进行更新具体为:
[0041]
qk(s,t)=q
k-1
(s,t) α[r
plan
γq
k-1
(s',t')-q
k-1
(s,t)]
[0042]
其中,k表示当前轮次,k-1表示上一轮次,t是上一轮次被交换的数据张量,s是上一轮次采用的调度方案,t'、s'分别是当前轮次被交换的数据张量和采用的调度方案,r
plan
是上一轮次的奖励收益,α,γ均为强化学习中常见的通用参数,α是学习率,表示策略学习的步长,γ是折扣因子,表示当前奖励对后面时刻的影响衰减系数。两个参数取值都在0-1之间,常见配置为α=0.5,γ=0.9;q
k-1
(s,t)表示第k-1轮次,被交换的数据张量为t和采用的调度方案为s时的反馈值,q
k-1
(s',t')表示第k-1轮次,被交换的数据张量为t'和采用的调度方案为s'时的反馈值,q
k-1
(s,t)、q
k-1
(s',t')依据q表查找获得。q表记录所有被交换的数据张量和采用的调度方案下的反馈值并随着迭代训练更新,在迭代训练开始q表中所有的值都会被初始化;
[0043]
步骤四:重复步骤二、三。每一轮迭代的训练时间和空间消耗都会发生变化,随着迭代次数增加,调度方案将收敛到调度最优解。当达到迭代次数,或者训练效果达到预期标准时,即得到了预期的调度决策。当达到预期训练效果时,系统结束训练,保存当前决策模
块的学习结果。
[0044]
进一步地,在决策过程中,依据计算出的历史q值,调用ε-greedy算法,得出下一步决策方案。而对于决策的调整,系统每次只进行一种神经网络层类型的张量的变更,作为系统的一次动作。整个过程,模型将根据先验经验和实时训练反馈,对于新的调度方案进行决策。当决策制定后,系统将具体的决策送至训练模块,从而进行下一轮迭代。
[0045]
进一步地,动态决策能够在有限状态(决策)学习得到更优的调度方案。然而,在选择策略后,需要经过长时间的训练迭代才能得到反馈,搜索求解的收敛速度较慢。因此,本发明结合神经网络的训练特征,还提供了一种优选方案。在多轮神经网络训练的迭代过程中,数据的访问模式是相同的。对于同一个神经网络,训练数据的访问模式也更为相似。因此,可以将训练分为两个过程:预训练和真实训练,在训练开始前先对原始训练数据进行切分,在预训练过程中通过训练原始数据的子批量数据进行训练决策,并在正式训练后继续动态调整,从而加速收敛。从实验结果看来,在保证了较好的内存优化前提下,该方案较大程度上提升了网络训练的性能。
[0046]
与一种基于强化学习内存调度决策的模型训练方法的实施例相对应,本发明还提供了一种基于强化学习内存调度决策的模型训练系统的实施例。
[0047]
本发明所设计的系统架构包括训练模块、采集模块以及决策模块,如图1所示。训练模块完成整个训练任务,包括数据输入,模型前向传播、反向传播、梯度更新等过程。此外,本发明在传统训练框架的基础上添加了数据交换技术,该技术使用转移函数(cudamemcpy()),按照转移策略,支持数据在特定阶段进行gpu与cpu之间的交换。采集模块则负责采集训练信息,包括gpu的内存空间、转移带宽等设备信息,模型各层的类型、参数等网络信息以及模型训练时间。并在每轮次迭代结束后及时反馈给决策模块。决策模块对于训练信息进行分析,并给出新一轮迭代的内存调度方案。
[0048]
对于系统实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0049]
本发明还提供了一具体实施例对本发明的效果作进一步说明:
[0050]
具体实验如下:
[0051]
实验配置:
[0052]
(1)操作系统:ubuntu 18.04.3lts;
[0053]
(2)cpu:2.10ghz intel(r)xeon(r)gold 521r,配有128gb dram;
[0054]
(3)gpu:rtx 2080ti 11gb显存;
[0055]
模型配置:
[0056]
(1)模型:alexnet,vgg16,resnet50,inceptionv3;
[0057]
(2)数据集:cifar10,包含60000张彩色图像,大小为32*32,分为10个类,每类6000张图,其中50000张图片用于训练,10000张图片用于测试;
[0058]
(3)奖励评估与策略评估中的公式根据经验将α取0.5,γ取0.9;
[0059]
对比对象介绍:
[0060]
1.pytorch:产业界默认的深度学习训练框架,不涉及显存优化技术;
[0061]
2.vdnn与capuchin:当前最好的深度学习显存优化框架;
[0062]
最终测试结果:
[0063]
空间测试:如图3所示,在上述实验环境下,通过pytorch框架训练alexnet,所能支持的最大批量大小超过3800,而本系统所能支持的最大批量大小超过5500。对于最大的神经网络inceptionv3,本系统所能支持的最大批次大小超过360,超过了pytorch所能支持大小的两倍。相比pytorch框架,本系统在cifar10数据集上支持训练的最大批量大小提高了1.4
×
到2.0
×
。相比vdnn方案,本系统可支持的最大批量提高了20%到70%。相比世界上最好的capuchin方案,本系统实现了3%到5%的空间优化提升,并且没有明显性能损失。
[0064]
图4展示了采用子数据集预训练的学习优化效果,实验所示选择80%的cifar数据集,可以提高30%的学习效率,并且能实现最优情况85.6%的训练性能。因此,选择适当大小的子数据集,对于提高训练效率有明显的提升。
[0065]
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化或变动。这里无需也无法把所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
