基于体素特征和稀疏sinkhorn transformer的3d姿态估计方法
技术领域
1.本发明属于计算机视觉与深度学习技术领域,具体涉及基于体素特征和稀疏sinkhorn transformer的3d姿态估计方法,在基于体素特征的利用多视角2d图像来预测空间中3d姿态的任务中,使用transformer与cnn的残差网络结合来提升预测表现,并利用sinkhorn稀疏注意力来降低计算复杂度。
背景技术:
2.三维人体姿态估计通常被视为从人体图像或图像序列中预测人体关键点(如肩膀、肘部、手腕等)的三维位置的任务。由于其广泛的潜在应用,人体姿势估计仍然是计算机视觉中一个日益活跃的研究领域,具有广阔的应用前景。在强大的深度学习技术和最近收集的大规模数据集的推动下,三维人体姿势估计继续取得巨大进展。
3.chunyu wang等人在2020年提出的voxelpose网络在此任务上达到了较为优秀的准确度。voxelpose使用了一种自上而下的双阶段方法,包含cpn和prn两个子网络。首先会把全部公共空间进行体素化,使用cpn网络对空间中的每个人物中心进行预测。接着会对每一个预测的人体中心周围的空间进行更细致的体素化,分别使用prn网络来预测出一个人物的所有关节节点。这两个网络的过程整体上都是相似的,首先会通过多视角下的产生的2d关节预测热图来构建出体素特征,并把体素特征通过由多层3d卷积网络组成的v2v-posenet处理,会得到每个关键点的每体素可能性,最后分别进行不同的处理。
4.然而,在voxelpose所使用到的3d卷积网络存在着卷积网络中共性的问题,即卷积网络(cnn)善于提取局部特征,但cnn在捕捉长距离的依赖关系时有局限性,会受到感受野的限制。与此同时,transformer网络在许多视觉任务中表现出很好的性能,可以有效获取长距离的依赖关系。因此,本发明提出了基于体素表示和稀疏sinkhorn transformer框架的3d姿态估计方案,优化了体素空间的预测效果,在三个公开数据集cmu-panoptic,shelf和campus下均取得了更佳的效果。
技术实现要素:
5.基于现有技术中存在的上述不足,本发明的目的是提供一种基于体素特征和稀疏sinkhorn transformer的3d姿态估计方法。
6.为了实现上述发明目的,本发明采用如下技术方案:
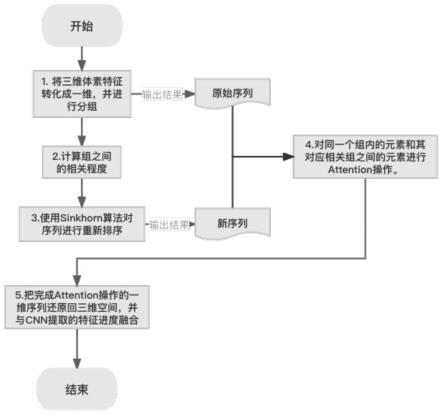
7.基于体素特征和稀疏sinkhorn transformer的3d姿态估计方法,包括以下步骤:
8.s1、将三维的体素特征分解成transformer可处理的一维体素序列,然后把序列按同样的大小分为多个组;
9.s2、在自注意力机制中,计算出每个体素元素的键值向量key、值向量value和查询向量query,然后计算每组的平均key、平均value和平均query,并计算组与组之间的相关度;
10.s3、按照相关度计算出转换矩阵,以组为单位对原序列进行重新排序,使得相关的两个组被分配在原序列和新序列中同样的位置;
11.s4、对同一个组内的元素和其对应相关组之间的元素进行自注意力操作;
12.s5、把完成自注意力操作的一维体素序列还原回三维空间,并与cnn提取的特征进度融合,得出最终的体素特征,最后把每个关节在体素中的概率与体素在三维空间中的坐标进行加权平均得到关节的预测位置。
13.作为优选方案,所述步骤s1具体包括以下步骤:
14.s11、获取由某一个时刻下由各个相机所构建的体素空间特征,设一个拥有h
×w×
l个n维度向量的3d网格为v={v
0,0,0
,
…
,v
h,w,l
}∈rn×h×w×
l
,其中,v
x,y,z
代表了一个坐标为(x,y,z)的网格向量,此时的维度n等于数据集中定义的人体关节节点个数;
15.s12、把v送入一个dim
in
=n,dim
out
=e的3d卷积网络中会得到一个提取了更多特征的体素网格,记为接着每个ve会加上长度同样为e的位置特征嵌入,完成对初始输入的特征嵌入过程;
16.s13、把有四个维度h,w,l,e的网格向量转化为二维的序列s={s0,
…ꢀsl
}∈re×
l
,映射关系为对于长度为l的输入序列s,会以每b个元素为一个块的方式,划分为nb个组;记分割函数为θ(
·
),bins=θ(s),bins代表了分割出来的所有组,故一个块内包含了在三维空间内相邻的体素特征。
17.作为优选方案,所述步骤s2具体包括:
18.每个bi块中每个元素分别乘以三个不同的线形变换矩阵wq,wk,wv,得到三个新的矩阵分别代表每个块中各个元素的query,key,value的集合;
19.计算每个块的query,key平均值
[0020][0021][0022]
上述点乘用于估计两个组之间的相关程度,计算所有组的复杂度,从输入序列长度l的二次方降低为得到注意力矩阵为:
[0023][0024]
其中,a
x,y
表示组x与组y的之间的相关度。
[0025]
作为优选方案,所述步骤s3具体包括:
[0026]
对于矩阵r进行sinkhorn规范化过程,nk代表用户自定义的迭代次数,此过程用公式表达如下:
[0027]
s0=exp(r)
[0028]
sk=fc(fr(s
k-1
(r)))
[0029][0030]
每次迭代的操作由以下两步组成:
[0031][0032][0033]
其中,fr,fc表示行和列的正则化函数,exp是以自然常数e为底的指数函数;
[0034]
经过sinkhorn操作之后得到的矩阵将会被用来重新对块序列进行排序,即对初始块序列计算出的序列进行重排序,从而得到新的序列。
[0035]
作为优选方案,所述步骤s4具体包括:
[0036]
对两个序列的query,key,value分别进行以组为单位的拼接,得到bin容量为2b个元素的query,key,value;
[0037]
设当前有n个关注头,则自注意力机制将对其query,key,value参数拆分成n份,分别送入n个关注头,进行缩放点乘注意力操作,最后将结果拼接在一起;
[0038]
自注意力机制的计算公式为:
[0039][0040]
作为优选方案,所述步骤s5具体包括:
[0041]
经过了sinkhorn稀疏注意力transformer网络之后,将会得到与输入s={s0,
…ꢀsl
}∈re×
l
,相同维度的输出,每个元素都是一个e维度的向量;
[0042]
把序列再还原成回三维空间,加上来自3d卷积网络的输出,设3d卷积网络的输出维度dim
out
=c,此时每个体素元素的维度会变为e c维度;
[0043]
之后经过最后一层3d卷积网络,dim
in
=e c,dim
out
=n,n是人体关节点个数,将高维的向量转化为每个关节在当前体素空间存在的概率;
[0044]
最后把每个关节在体素中的概率与体素在三维空间中的坐标进行加权平均得到关节的预测位置。
[0045]
与现有技术相比,本发明具有如下技术效果:
[0046]
(1)本发明对多视角图像的二维关键点输入特征进行体素表示,并对其进行有效的序列化,以适用于transformer网络框架;
[0047]
(2)本发明提出了一个基于transformer网络的3d姿态估计方法,并结合cnn网络和残差结构进行特征提取,带来了更高的预测精度。
[0048]
(3)为了克服繁重的体素计算,本发明利用了稀疏的sinkhorn注意力机制,使用局部窗口来近似全局注意力的效果。
附图说明
[0049]
图1是本发明实施例的基于体素特征和稀疏sinkhorn transformer的3d姿态估计
方法的流程图;
[0050]
图2是本发明的估计方法与voxelpose的对比效果图;
[0051]
图3是本发明实施例的体素特征的划分原理示意图;
[0052]
图4是本发明实施例的新序列的生成原理示意图;
[0053]
图5是本发明实施例的原始序列与新序列的组合原理示意图。
具体实施方式
[0054]
为了更清楚地说明本发明实施例,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
[0055]
如图1所示,本发明实施例的基于体素特征和稀疏sinkhorn transformer的3d姿态估计方法,主要包括以下5个步骤:
[0056]
步骤1:把三维的体素特征(体素特征代表空间中某一范围内,各个视角的2d热图在对应位置的预测概率拼接成的向量)分解成transformer可处理的一维体素序列,然后把序列按同样的大小分为多个组。
[0057]
步骤1:首先获取由某一个时刻下由各个相机所构建的体素空间特征,设一个拥有h
×w×
l个n维度向量的3d网格为v={v
0,0,0
,
…
,w
h,w,l
}∈rn×h×w×
l
,其中v
x,y,z
代表了一个坐标为(x,y,z)的网格向量,此时的维度n等于数据集中定义的人体关节节点个数。接着把v送入一个dim
in
=n,dim
out
=e的3d卷积网络中会得到一个提取了更多特征的体素网格,记为接着每个ve会加上长度同样为e的位置特征嵌入(position embedding),至此便完成了对初始输入的特征嵌入过程。接着要把有四个维度h,w,l,e的网格向量转化为二维的序列s={s0,
…ꢀsl
}∈re×
l
,映射关系为对于长度为l的输入序列s,会以每b个元素为一个块的方式,划分为nb个块。记分割函数为θ(
·
),bins=θ(s),这里bins代表了分割出来的所有块,),bins=θ(s),这里bins代表了分割出来的所有块,所以一个块内包含了在三维空间内相邻的体素特征,过程如图3所示。
[0058]
步骤2:在自注意力机制中,计算出每个体素元素的键值向量(key),值向量(value),查询向量(query),然后计算每组的平均key,value,query向量,并计算组与组之间的相关度。
[0059]
具体地,:每个bi块中每个元素分别乘以三个不同的线形变换矩阵wq,wk,wv,可以得到三个新的矩阵分别代表每个块中各个元素的query,key,value的集合。接下来计算每个块的query,key平均值
[0060]
[0061][0062]
这里用得到的进行点乘就可以用来估计两个块之间的相关程度,近似于原本transformer中元素与元素的关系,此时计算所有块的复杂度就可以从输入序列长度l的二次方降低为得到注意力矩阵为:
[0063][0064]
其中,a
x,y
表示块x与块y的之间的整体相关程度。
[0065]
步骤3:按照相关度计算出转换矩阵,以组为单位,对原序列进行重新排序,使得相关的两个组会被分配在原序列和新序列中同样的位置。
[0066]
如果矩阵r是双重随机矩阵(矩阵是非负的,且行和列的总和都为1),则它将成为排序矩阵(或置换矩阵)。更具体地说,置换矩阵是双随机矩阵的特例(其中行和列之和为1,所有条目为0或1)。由于每个置换矩阵是双随机矩阵的凸组合,所以我们认为学习双随机矩阵是松弛置换矩阵的一种形式。下述方法根据已经计算得到的块与块的相关性矩阵来计算一种排列方式,也就是一个置换矩阵,用它乘上当前块序列得到一个新顺序的块序列,并尽可能使得较为相关的两个块排列在新旧序列的同一位置。
[0067]
对于一个矩阵r分别对行,列重复的进行归一化,即sinkhorn规范化过程,nk代表用户自定义的迭代次数,此过程用公式表达如下:
[0068]
s0=exp(r)
[0069]
sk=fc(fr(s
k-1
(r)))
[0070][0071]
每次迭代的操作由以下两步组成,其中fr,fc表示行和列的正则化函数,exp是以自然常数e为底的指数函数:
[0072][0073][0074]
sinkhorn表明,重复以上的两步,最终可以收敛到一个行和为1,列和也为1的双随机矩阵。其中的每一步操作都是可导的,于是深度学习更新参数所需要的链式求导便不会计算置换矩阵而中断,从而实现端到端训练。
[0075]
经过sinkhorn操作之后得到的矩阵将会被用来重新对块序列进行排序,更具体的讲是对初始块序列计算出的序列进行重排序,从而得到新的序列,如图4所示。
[0076]
步骤4:对同一个组内的元素和其对应相关组之间的元素进行自注意力(self-attention)操作。
[0077]
此时对两个序列的query,key,value分别进行以块为单位的拼接,于是将会得到bin容量为2b个元素的query,key,value,如图5所示。这里的一个bin中既包含了局部相邻的元素也包含了来自远端的、和当前bin中元素较为相关的其他元素。计算注意力时会采用多头注意力机制,注意模块会进行并行计算。设当前有n个关注头,那么自注意力(attention)模块将会对其query,key,value参数拆分成n份,分别送入n个关注头,进行缩放点乘注意力(scaled dot-product attention)操作,最后将结果拼接在一起。提供了多个“表示子空间”,可以使模型在不同位置上关注来自不同“表示子空间”的信息。即通过多头注意力机制,模型可以捕捉到更加丰富的特征信息。
[0078]
其中,自注意力机制的计算公式为:
[0079][0080]
步骤5:把完成自注意力操作的一维体素序列还原回三维空间,并与cnn提取的特征进度融合,得出最终的体素特征,最后把每个关节在体素中的概率与体素在三维空间中的坐标进行加权平均得到关节的预测位置。网络分为训练阶段和预测阶段,训练阶段中通过已有的数据集学习网络的参数,在预测阶段使用学习到的参数对真实数据进行预测。
[0081]
具体地,经过了sinkhorn稀疏注意力transformer网络之后,将会得到与输入s={s0,
…ꢀsl
}∈re×
l
,相同维度的输出,每个元素都是一个e维度的向量。把序列再还原成回三维空间,加上来自3d卷积网络的输出,设3d卷积网络的输出维度dim
out
=c,此时每个体素元素的维度会变为e c维度。最后进过最后一层3d卷积网络,dim
in
=e c,dim
out
=n,n是人体关节点个数,将高维的向量转化为每个关节在当前体素空间存在的概率。最后把每个关节在体素中的概率与体素在三维空间中的坐标进行加权平均得到关节的预测位置。训练过程中的损失函数定义如下:
[0082][0083]
k代表总关节节点个数,j
*
代表数据集中的真实节点坐标,j代表网络输出的预测坐标,每次预测的loss为所有节点的真实位置与预测位置的l1 loss的总和。训练过程中网络会通过反向传播学习到合适的参数,在预测阶段使用这些参数对新的场景进行预测。
[0084]
如图2所示,本发明实施例的基于体素特征和稀疏sinkhorn transformer的3d姿态估计方法(简称本方法)相对于voxelpose而言,预测精度更高。
[0085]
以上所述仅是对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,而这些改变也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
