1.本发明是在基于机器学习中推荐系统的理论,根据数据来源的特点进行算法上的创新与应用。本发明属于推荐系统领域,具体地说,涉及多模态偏好上下文、轨迹表征、图结构增强表达和自注意力机制方法。
背景技术:
2.在当前人工智能迅猛发展的今天,机器学习相关算法在诸如:机器视觉、自然语言处理、推荐系统等多个方面极大的推动了生产力的发展。其中位置预测的相关算法更在搜索和电子商务等领域发挥着重要的作用。
3.推荐算法初始目的是为了解决信息过载的问题。所谓信息过载就是在信息社会信息爆炸的当下,如何从海量的信息中提取有价值或者研究对象关心的信息,从而降低研究对象对信息处理所需要的强度,提高对信息利用的效率。
4.推荐算法的数学理论基础是基于大数定理和pac理论。具体到位置推荐算法是利用研究对象(“研究对象”具体而言是能提供连续位置信息的物体,具体应用中可以包括但不仅限于:移动手机、车载发射器、gps终端、北斗终端等)的历史位置数据来发掘应用场景中的规律和周期性特征,然后利用规律和周期性对未来时间点需求进行预测。
5.因为移动的研究对象的活动是基于位置的三维空间的,因此基于位置的位置预测是电子商务中常用场景。某个特定的位置出现在研究对象的活动轨迹中会相对清晰地提供用户的偏好。在旅游、商品推荐等商业活动中具有广泛的应用价值。
6.现有技术的不足之处在于:基于稀疏数据集而建立的算法,在算法使用过程中都会在不同程度的对数据的稀疏性进行处理。现有的大多数算法的基础都是在稀疏位置上进行的建模和计算。类似的算法存在天然缺陷就是无法更好的拟合位置信息终端的位置偏好。有数据表明在自然情况下公开发表的位置只占位置信息终端总访问位置数量的0.03%。无论是从理论上还是从直觉上来说,从如此小的比例数据中获取的位置信息终端偏好是无法很好得拟合研究对象真实偏好。又由于位置数据的稀疏性,因此很难将其它多模态的数据和位置信息进行统一的嵌入(embedding)。原因是显然的,位置信息终端提交的位置数据很难和其它相关多模态数据正好处于同一时间节点上。另外,当位置信息终端出现兴趣漂移时,由于数据的稀疏性,两个check-in位置的时间间隔不确定,因此无法区分是位置信息终端实际目的地还是兴趣漂移之后的目的地。
7.领域内常识性介绍:
8.poi数据是一种对地理数据进行结构化表示的形式。通过这种结构化的表示形式,可以将地理特征融入到预测模型时所需的特征向量中。基于poi所表示的地理特征,可以将地理信息在基于位置的位置预测系统应用在旅游、餐饮、购物等多种场景中。
9.图(graph)是一种用于表示实体之间关系的数据方法。实体通过顶点(node)表示,实体之间的关系通过(edge)进行表示,同时一个全局变量用于表示图的整体属性。图不仅可以表示简单的数据信息,而且可以比较方便的定义实体之间的关系。因此在表示地理位
置之间的关系和时序关系时,图结构是一种非常好的表达方式。
10.transformer模型是一种使用self-attention机制的编码-解码模型。自从其出现以来在nlp(自然语言处理)取得了非常好的效果。在后续的研究中将其应用在了诸如计算机视觉、语音编码等方面都取得了非常好的效果。从而transformer展示出了一种模型统一多模态数据的潜质。
技术实现要素:
11.本发明的目的在于公开了基于偏好上下文和轨迹图增强表达的位置预测方法,该方法将图增强结构、多模态偏好上下文、self-attention机制和研究对象周期性分析综合用于基于位置预测中,从而达到两个目的:第一,下一个时刻研究对象可能出现的位置;第二,预测对于指定位置被研究对象访问的可能性。其中,“研究对象”具体而言是能提供连续位置信息的物体,包括但不仅限于包括:手机、车载发射器、gps终端、北斗终端。
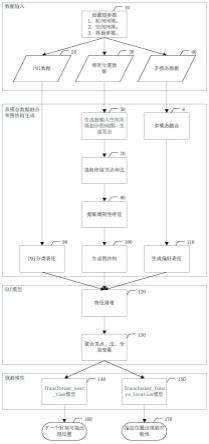
12.本发明使用的数据包含3种:第一,poi数据;第二,稠密的轨迹数据;第三,多模态偏好上下文。算法过程为,本发明首先设置超参数来确定输入条件;第二,将所有数据进行融合,形成包含多种特征的初始图结构;第三,用gat模型对初始图中的顶点、边和全局信息进行动态聚合;第四,将下一个位置的预测转化关联预测的排序问题,对研究对象可能出现的位置进行预测。将指定位置研究对象出现的可能性转化为一个分类问题,对给定的位置研究对象是否会被访问。
13.本发明技术方案:
14.一种基于偏好上下文和轨迹图增强表达的位置预测方法,其特征在于,首先,基于特征表示和图理论,将地理空间以图结构的形式进行表示,再将poi数据向量化表示之后添加到顶点的属性中;其次,将多模态偏好上下文融合到图结构之上;第三,通过位置数据提取研究对象的轨迹图;第四,对图中的顶点、边和全局向量进行更新;第五,根据轨迹图增强表达对可能出现的位置进行预测。进一步的,所述的基于特征表示和图理论,将地理空间以图结构的形式进行表示:通过对地理空间二维平面的分割,得到表示空间位置的图结构中的顶点。进一步的,所述的再将poi数据向量化表示之后添加到顶点的属性中:通过poi的分类特征进行向量化表示之后,得到每个顶点属性中的地理部分的属性。
15.一种基于偏好上下文和轨迹图增强表达的位置预测方法,其特征在于,具体方法过程为:
16.步骤10:设置以时间间隔和空间间隔为主的多个超参数。
17.步骤20:将指定地域的poi数据引入方法,进入步骤90。
18.步骤30:将指定地域的稠密轨迹数据输入,进入步骤50。
19.步骤40:将指定地域的、需要研究的研究对象的多模态数据输入,进入步骤60;
20.步骤50:按照步骤10中设置的空间间隔生成连续的划分的地图,然后按照分片生成顶点,进入步骤70;
21.步骤60:将多模态上下文中对地域的偏好信息提取出来之后进行嵌入;具体而言,对于多模态的上下文采用基于特征融合(feature fusion)的决策融合(decision fusion)方法来对来对多模态数据提取研究对象偏好特征向量,进入步骤110。
22.步骤70:提取指定研究对象生成该对象的停留点和连接停留点的边,进入步骤80。
23.步骤80:提取图结构中的周期性信息,进入步骤100。
24.步骤90:将poi的分类生成顶点的位置特征,记为f
poi
。将f
poi
赋值给顶点特征向量中的v
location
=f
poi
部分,提供步骤120;
25.步骤100:生成图增强结构,以生成的图结构信息生成尺寸为n
×
n的邻接矩阵(adjacency matrix),记为a=(a
ij
),a
ij
=μ(vi,vj),其中μ(vi,vj)表示为图连接vi和vj的边的数目;提供步骤120。生成的图,记为g(v,e)。以研究对象本身的属性将其向量化,记为u。生成的地理位置分片,每个分片均生成为一个顶点。所有顶点的集合记为v={v1,v2,
…
,vn},其中n为顶点的个数。顶点特征向量,对于一个顶点其特征记为vi,其中i为顶点id。
26.步骤110:在步骤60的基础上,生成研究对象多模态偏好上下文,记为f
preference
。将f
preference
,提供步骤120。
27.步骤120:将轨迹特征、周期性特征、偏好上下文附着生成的图增强结构中对应的全局、顶点、边上。最终形成包含研究对象轨迹特征的矩阵。其中第i个顶点的属性记为vi,第k条边记为ek。其中,v
location
=f
poi
、v
preference
=f
preference
,v
location
和v
preference
如表4中所示,分别表示顶点特征中的地域特征和偏好特征。进入步骤130。
28.步骤130:聚合更新图增强结构中的顶点、边、全局变量特征,进入步骤140、步骤150;在图增强结构中将执行2次汇聚以便于顶点、边和全局变量之间进行消息传递。
29.顶点聚合使用v
ineighbor
=∑
jaj
vj ∑
kbkek
cu得到顶点vi的辅助信息,其中vj为vi距离为1的邻居,ek为vi相连边的特征,u为全局特征;aj、bk、c通过self-attention机制训练得到的权重。为汇聚之后一次vi的特征,通过transformer模型来得到训练参数。
30.边聚合使用得到边ei的辅助信息,其中vj为ei两端的顶点,u
feature
为全局特征;aj、b通过self-attention机制训练得到的权重。为汇聚之后ei的特征,通过transformer模型来得到训练参数。
31.全局变量聚合使用u
agg
=∑
jaj
vj ∑
kbkek
得到u
agg
的辅助信息,其中vj为所有停留顶点的特征,ek为所有边的特征;aj、bk通过self-attention机制训练得到的权重。u=attention(u,u
agg
)为汇聚之后u的特征,通过transformer模型来得到训练参数。
32.步骤140:使用transformer模型对下一个时刻研究对象可能出现的位置进行预测,进入步骤160。将研究对象当前所在第i个顶点的特征vi与图中其他顶点的特征vj组合在一起,使用self-attention机制对其关联性给出回归预测值,pn
ij
=attention
nexttime
(vi,vj)。然后将pn
ijmax
=argmax(pn
ij
),i≠j,i,j∈{1,2,
…
,n}。则j对应的顶点即为下一时刻最可能出现的位置。可以按照pn
ij
降序排序,取前3个位置作为最可能出现的位置列表推荐给用户。
33.步骤150:使用transformer模型对下一个时刻研究对象可能出现的位置进行预测,进入步骤170。将指定位置所在顶点vi的特征使用self-attention机制对其给出回归预测值,pli值即为研究对象对指定位置访问的可能性。
34.步骤160:得出可能出现位置的推荐列表;top-n准确度公式计算如下:
其中tp(true positive)做出positive的判定,且判定是正确的。fp(false positive)做出positive的判定,但判定是错误的。tn(true negative)做出negative的判定,且判定是正确的。fn(false negative)做出negative的判定,但判定是错误的。
35.步骤170:得出指定位置研究对象访问的可能性数值。
36.上述技术方案中,所述步骤60的实现过程,即对多模态数据采用feature level融合策略进行融合,最终提取偏好特征。具体而言包含以下步骤:
37.步骤601:输入评论数据。
38.步骤602:输入图片数据。
39.步骤603:输入评分数据。
40.步骤604:使用self-attention机制,对评论语句编码输出为长度为128的偏好特征向量;定义为f
comment
,f
comment
=attention(comments)。
41.步骤605:首先将图片的大小进行统一,输出偏好特征向量。首先将图片的大小进行统一为512*512像素。统一的方法采用按比例缩放。将512*512除以输入图像尺寸(width,height),取其中较小的一个比例,将长宽同时按此比例进行缩放。生成大小为512*512,rgb值为(255,255,255)的底色图片。然后将缩放之后的图片和底色图片进行中心对齐合成一张图片。其次将图片按照为16*16进行分片。第三将这些分片的线性embedding序列作为transformer模型的输入。最终输出为长度为128的偏好特征向量。将图片偏好特征向量定义为f
image
,f
image
=attention(image
embedding
)。
42.步骤606:将3级、5级、10级评分通过三个输入向量长度分别为3、5、10,输出mlp模型,偏好向量,将评分偏好特征定义为f
rank
。
43.步骤607:在步骤604、步骤605、步骤606统一长度偏好特征的基础上,将3种类型的偏好特征组成偏好矩阵。定义中间特征变量为f
temp
,f
temp
=concat(f
comment
,f
image
,f
rank
)。使用self-attention机制对其进行处理,输出偏好特征向量。最终输出的多模态上下文偏好特征定义为f
preference
,f
preference
=attention(f
temp
)。
44.上述技术方案中,所述步骤70用于实现图增强结构中生成研究对象停留点及边的算法:使用滑动窗口的方式来提取指定时间断的停留点,默认情况下是提取研究对象所有历史数据在时间间隔模型值情况下的停留点,具体而言包含以下步骤:
45.步骤701:判断是否设置阈值速度;如果设置阈值速度则转至步骤704,如果没有设置阈值速度则转至步骤702。
46.步骤702:对研究对象的当前时刻的前整数倍时间间隔内的行动路程求和。
47.步骤703:计算研究对象滑动窗口中的平均速度。
48.步骤704:在步骤701和步骤703的基础上,判断当前时间间隔内的速度是否小于输入速度(阈值速度或者平均速度);如果小于输入速度,转至步骤706,;如果大于或等于输入速度,转至步骤705。
49.步骤705:在步骤704的基础上,判断将要生成的停留点和上一个停留点是否是同一个地域;如果是同一个地域,转至步骤706;如果不是同一个地域,转至步骤707。
50.步骤706:在步骤704和步骤705的基础上,判断边是否存在,如果边存在则修改边
的属性,转至步骤708;如果边不存在则生成一条新边,转至步骤709。
51.步骤707:在步骤705的基础上,生成一个停留点和对应边的信息,并保存该停留点和边的相关信息;停留点和边上包含的信息如表4和表5所示。对于没有偏好特征的停留点,采用基于最大似然估计原理的方法将偏好的分布进行估计,然后将偏好特征分布的期望对其赋值。
52.步骤708:在步骤706的基础上,修改已有边的属性。
53.步骤709:在步骤709的基础上,生成一条新的边。
54.步骤7010:判断滑动窗口是否已经达到当前时刻,如果已经达到当前时刻,那么存储所有停留点信息,如果没有到达当前时刻,那么转至步骤701。
55.上述技术方案中,所述步骤80用于实现提取研究对象周期性特征的算法:按照稠密轨迹数据和已经建立的停留顶点、边统计数据中的周期性特征,具体而言包含以下步骤:
56.步骤801:按照稠密轨迹数据对应的停留顶点,统计该停留顶点的周期性信息;其中包括:v
duration_maximum
为停留点在时间t内停留的最大时长,v
duration_average
为停留点时间t内的平均时长,v
total_visit_count
为在时间t内访问停留点的总次数,v
cycle_visit_count
为在δt内访问停留点的次数。
57.步骤802:按照稠密轨迹数据经过的边,统计该边的周期性信息;e
duration
为边上消耗的平均时长,e
total_visit_count
为在时间t内经过边的总次数,e
cycle_visit_count
为在δt内经过边的次数;
58.步骤803:将步骤801中的特征向量化;
59.步骤804:将步骤802中的特征向量化;
60.步骤805:将步骤803、步骤804得到特征向量分别赋值给对应停留顶点和边中对应的属性。
61.本发明在多模态偏好上下文融合、图增强结构和预测时使用self-attention机制,将self-attention机制定义如下:
62.q=relu(input wq)
63.k=relu(input wk)
64.v=relu(input wv)
65.其中,input=[v1,v2,
…
,vn]
t
表示由多个向量组合而成的输入矩阵。
[0066]
为模型权重。其中d
model
、dk、dv分别为模型维度、q和k的维度、v的维度。multihead(q,k,v)=concat(head1,
…
,headh)wo,其中headi=attention
head
(qw
iq
,kw
ik
,vw
iv
),为多头注意力权重。模型中使用self-attention机制输入和输出的关系为:
[0067]
附图说明
[0068]
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0069]
图1为发明总体数据流程图
[0070]
图2为多模态偏好上下文融合图
[0071]
图3为图增加结构中停留顶点及边生成流程图
[0072]
图4为图增加结构中周期性特征提取流程图
[0073]
图5为表1时间间隔和空间间隔调整对应关系表
[0074]
图6为表2数据包含特征说明表
[0075]
图7为表3地理位置分类表
[0076]
图8为表4停留点包含的特征
[0077]
图9为表5边包含的特征
具体实施方式
[0078]
以下将配合附图及实施例来详细说明本发明的实施方式,藉此对本发明如何应用技术手段来解决技术问题并达成技术功效的实现过程能充分理解并据以实施。
[0079]
基于偏好上下文和轨迹图增强表达的位置预测方法,包括以下具体步骤:如图1所示。
[0080]
步骤10:设置以时间间隔和空间间隔为主的多个超参数。本发明需要设置的超参数包含至少5个需要提前设置的超参数,具体而言:第一,指定研究地域,一般而言可以将一个城市作为一个研究地域。对于无法整除的可以适当将研究地域的长宽进行放大,以便于分片。同时将地理位置分片中的所有poi的分类使用统计方法生成特征向量。并且将poi分类特征向量赋值给顶点特征向量中的v
location
部分;第二,指定一个预测研究对象,对于预测研究对象需要具备大于等于3个月的历史轨迹数据,具体在步骤30中进行说明;第三,设置时间间隔,设置以固定时间间隔为运算时时间的最小划分粒度,记为δt,以分钟为单位,默认值为60分钟。6种固定的时间间隔分别为:30分钟、小时(默认值)、天、周、月、3个月。需要强调的是:无论是特征提取、建模和预测结果都是基于同一时间间隔的。预测结果时默认情况下时和特征提取、建模、预测使用相同的时间粒度,也可以选择大于特征提取、建模的时间粒度,但是不能选择小于之前步骤的时间粒度。当时间粒度进行调整时,对应的空间间隔也会相应的进行调整。调整的对应关系如表1所示;第四,设置地理空间间隔划分,本发明是建立在二维平面地理位置数据之上,位置数据不包含高度信息,空间间隔记为δl,以米为单位,默认值为1000米。将指定的地域按照定义5种的空间间隔:500米、1000米(默认值)、10,000米、50,000米、自定义为50,000米的正整数倍进行区域分割;第五,设置地理poi数据更新时间间隔,该值的默认值为1年。
[0081]
步骤20:将指定地域的poi数据引入方法,进入步骤90。poi数据不限于包含以下特征:地点名称、详细分类、邮政地址、所在行政区(就中国而言至少需要具体到地级市一级)、经纬度。具体而言,所包含数据的具体描述信息如表2,表3所示。poi数据,即point of interest数据。具体到数据内容而言poi数据至少具备以下特征:地点名称、详细分类、邮政地址、所在行政区(就中国而言至少需要具体到地级市一级)、经纬度。
[0082]
poi数据主要用途体现为对地理位置的标签。这种标签表明了位置的分类。这种分类方便于本发明对poi进行向量化处理,也方便于和研究对象的偏好进行运算。表2说明了poi数据包含的特征,表3说明了“详细分类”的具体类别。
[0083]
综合poi特征为每个特定poi数据生成一个全局唯一标识,记为poi_id。poi数据的
分类的设施类型包含14个大类,81个中类,524个小类。14个大类包括餐饮服务、购物服务、科教文化服务、风景名胜、公共设施、公司企业、交通设施服务、金融保险服务、商务住宅、生活服务、体育休闲服务、医疗保健服务、政府机构及社会团体、住宿服务。基本覆盖了所有设施类型。另一种参考分类方式为gb50137-2011。通过one-hot的编码的方式,为每个poi_id生成一个分类标识。
[0084]
对于新产生的poi数据,通过poi名称、邮政地址等已具备的特征使用全连接的neural network模型,将已有数据作为监督学习的训练数据对其生成新的分类标签。如果有大量新产生的poi数据,需要人工抽检复核其生成的标签。
[0085]
按照详细分类,参考分类方式如表3所示。
[0086]
将地理位置分片中的所有poi的分类使用统计方法生成特征向量。poi分类特征记为f
poi
。
[0087]
步骤30:将指定地域的稠密轨迹数据输入,进入步骤50。稠密轨迹数据为按照固定时间间隔采集的符合wgs 1984标准的经纬度数据。稠密轨迹数据的特征如下:第一,获取轨迹中每个位置数据之间的时间间隔远远小于δt。第二,长时间的获取研究对象的轨迹数据。获取的历史数据总时长记为t,要求t≥2160δt≈3个月。第三,每个位置数据提供的数据格式可以是但不限于是经纬度、相对初始位置的距离和方向等形式。这种形式不是使用类似:“上海嘉定区同济大学”等描述含有地理属性特征的形式表述的。也就是说这种数据格式仅仅只表达了空间信息。第四,特定研究对象的最终稠密位置数据表示为一个按照时间顺序排列的位置点集合,记为l。
[0088]
步骤40:将指定地域的、需要研究的研究对象的多模态数据输入,进入步骤60;本发明多模态偏好数据包含3种类型:评分、文本、图片。多模态偏好上下文具备以下特征:第一,对位置的评分描述;第二,对位置的评论(文字)描述;第三,在位置上拍摄的图片。
[0089]
步骤50:按照步骤10中设置的空间间隔生成连续的划分的地图,然后按照分片生成顶点,进入步骤70。
[0090]
步骤60:将多模态上下文中对地域的偏好信息提取出来之后进行嵌入;具体而言,对于多模态的上下文采用基于特征融合(feature fusion)的决策融合(decision fusion)方法来对来对多模态数据提取研究对象偏好特征向量,进入步骤110。
[0091]
步骤70:提取指定研究对象生成该对象的停留点和连接停留点的边,进入步骤80;
[0092]
步骤80:提取图结构中的周期性信息,进入步骤100。
[0093]
步骤90:将poi的分类生成顶点的位置特征,将f
poi
赋值给顶点特征向量中的v
location
=f
poi
部分,提供步骤120。
[0094]
步骤100:生成图增强结构,以生成的图结构信息生成尺寸为n
×
n的邻接矩阵(adjacency matrix),记为a=(a
ij
),a
ij
=μ(vi,vj),其中μ(vi,vj)表示为图连接vi和vj的边的数目。因为是简单无向图,所以该邻接矩阵是一个元素均为0、1而且主对角线元素均为0的对称阵。提供步骤120;生成的图结构是一个不包含环(cycle)和平行边(parallel edges)的简单无向图(simple undirected graph)。记为g(v,e)。以研究对象本身的属性将其向量化长度为256的向量。记为u。生成的地理位置分片,每个分片均生成为一个顶点。所有顶点的集合记为v={v1,v2,
…
,vn},其中n为顶点的个数。顶点特征向量长度为256,对于一个顶点其特征记为vi,其中i为顶点id。将稠密位置数据和生成的顶点使用滑动窗口的方
式来提取指定时间断的停留顶点,默认情况下是提取研究对象所有历史数据在时间间隔模型值情况下的停留顶点。停留顶点包含的特征如表4所示。停留顶点特征向量长度为256。
[0095]
在图增强结构生成阶段停留顶点和普通顶点的不同在于:
[0096]
1).停留顶点的特征向量含有信息的部分更多;具体而言,所有顶点包含的特征包括v
identity
、v
location
;其余特征为停留顶点才会对其赋值。
[0097]
2).停留顶点与其他的停留顶点之间有边连接,而普通顶点没有和其他顶点连接的边。在稠密轨迹数据的基础上,两个停留顶点之间生成一条边。边包含的特征如表5所示。第j条边特征向量长度为256,记为ej。
[0098]
通过对研究对象历史数据的处理,将与时间相关的特征v
duration_maximum
、v
duration_average
、v
total_visit_count
、v
cycle_visit_count
、e
duration
、e
total_visit_count
、e
cycle_visit_count
提取出来。具体详见周期性特征提取实施步骤80中所示。
[0099]
步骤110:在步骤60的基础上,生成研究对象多模态偏好上下文,得到f
preference
,提供步骤120。
[0100]
步骤120:将轨迹特征、周期性特征、偏好上下文附着生成的图增强结构中对应的全局、顶点、边上。最终形成包含研究对象轨迹特征的矩阵。其中第i个顶点的属性记为vi,第k条边记为ek。其中如表4和表5所示,v
location
=f
poi
、v
preference
=f
preference
,进入步骤130。
[0101]
步骤130:聚合更新图增强结构中的顶点、边、全局变量特征,进入步骤140、步骤150;在图增强结构中将执行2次汇聚以便于顶点、边和全局变量之间进行消息传递。顶点聚合使用得到顶点vi的辅助信息,其中vj为vi距离为1的邻居,ek为vi相连边的特征,u为全局特征;aj、bk、c通过self-attention机制训练得到的权重。为汇聚之后一次vi的特征,通过transformer模型来得到训练参数。
[0102]
边聚合使用得到边ei的辅助信息,其中vj为ei两端的顶点,u
feature
为全局特征;aj、b通过self-attention机制训练得到的权重。为汇聚之后ei的特征,通过transformer模型来得到训练参数。
[0103]
全局变量聚合使用u
agg
=∑
jaj
vj ∑
kbkek
得到u
agg
的辅助信息,其中vj为所有停留顶点的特征,ek为所有边的特征;aj、bk通过self-attention机制训练得到的权重。u=attention(u,u
agg
)为汇聚之后u的特征,通过transformer模型来得到训练参数。
[0104]
步骤140:使用transformer模型对下一个时刻研究对象可能出现的位置进行预测,进入步骤160;所有的预测是在下一个时间间隔下做出的预测,因此需要做不同时间间隔的预测需要训练不同时间间隔下的模型。将研究对象当前所在第i个顶点的特征vi与图中其他顶点的特征vj组合在一起,使用self-attention机制对其关联性给出回归预测值,pn
ij
=attention
nexttime
(vi,vj)。然后将则j对应的顶点即为下一时刻最可能出现的位置。可以按照pn
ij
降序排序,取前3个位置作为最可能出现的位置列表推荐给用户。
[0105]
步骤150:使用transformer模型对下一个时刻研究对象可能出现的位置进行预测,进入步骤170;所有的预测是在下一个时间间隔下做出的预测,因此需要做不同时间间
隔的预测需要训练不同时间间隔下的模型。将指定位置所在顶点vi的特征使用self-attention机制对其给出回归预测值,pli值即为研究对象对指定位置访问的可能性。
[0106]
步骤160:得出可能出现位置的推荐列表;top-n准确度公式计算如下:其中tp(true positive)做出positive的判定,且判定是正确的。fp(false positive)做出positive的判定,但判定是错误的。tn(true negative)做出negative的判定,且判定是正确的。fn(false negative)做出negative的判定,但判定是错误的。步骤170:得出指定位置研究对象访问的可能性数值。
[0107]
上述技术方案中,所述步骤60的实现过程,即对多模态数据采用feature level融合策略进行融合,最终提取偏好特征。如图2所示,具体而言包含以下步骤:
[0108]
步骤601:输入评论数据。
[0109]
步骤602:输入图片数据。
[0110]
步骤603:输入评分数据。
[0111]
步骤604:使用self-attention机制,对评论语句编码输出为长度为128的偏好特征向量;定义为f
comment
,f
comment
=attention(comments)。
[0112]
步骤605:首先将图片的大小进行统一为512*512像素。统一的方法采用按比例缩放。将512*512除以输入图像尺寸(width,height),取其中较小的一个比例,将长宽同时按此比例进行缩放。生成大小为512*512,rgb值为(255,255,255)的底色图片。然后将缩放之后的图片和底色图片进行中心对齐合成一张图片。其次将图片按照为16*16进行分片。第三将这些分片的线性embedding序列作为transformer模型的输入。最终输出为长度为128的偏好特征向量。定义为f
image
,f
image
=attention(image
embedding
)。
[0113]
步骤606:将3级、5级、10级评分通过三个输入向量长度分别为3、5、10,输出长度为128的mlp模型,统一编码为长度为128的偏好向量。定义为f
rank
。
[0114]
步骤607:在步骤604、步骤605、步骤606统一长度偏好特征的基础上,将3种类型的偏好特征组成一个维度为3*128的偏好矩阵f
temp
=concat(f
comment
,f
image
,f
rank
)。使用self-attention机制对其进行处理,输出为长度为128的偏好特征向量。f
preference
=attention(f
temp
)。
[0115]
上述技术方案中,所述步骤70用于实现图增强结构中生成研究对象停留点及边的算法:使用滑动窗口的方式来提取指定时间断的停留点,默认情况下是提取研究对象所有历史数据在时间间隔模型值情况下的停留点,如图3所示,具体而言包含以下步骤:
[0116]
步骤701:判断是否设置阈值速度;如果设置阈值速度则转至步骤704,如果没有设置阈值速度则转至步骤702。
[0117]
步骤702:对研究对象的当前时刻的前整数倍时间间隔内的行动路程求和。
[0118]
步骤703:计算研究对象滑动窗口中的平均速度。
[0119]
步骤704:在步骤701和步骤703的基础上,判断当前时间间隔内的速度是否小于输入速度(阈值速度或者平均速度);如果小于输入速度,转至步骤706,;如果大于或等于输入速度,转至步骤705。
[0120]
步骤705:在步骤704的基础上,判断将要生成的停留点和上一个停留点是否是同
一个地域;如果是同一个地域,转至步骤706;如果不是同一个地域,转至步骤707。
[0121]
步骤706:在步骤704和步骤705的基础上,判断边是否存在,如果边存在则修改边的属性,转至步骤708;如果边不存在则生成一条新边,转至步骤709。
[0122]
步骤707:在步骤705的基础上,生成一个停留点和对应边的信息,并保存该停留点和边的相关信息;停留点和边上包含的信息如表4和表5所示。对于没有偏好特征的停留点,采用基于最大似然估计原理的方法将偏好的分布进行估计,然后将偏好特征分布的期望对其赋值。
[0123]
步骤708:在步骤706的基础上,修改已有边的属性。
[0124]
步骤709:在步骤709的基础上,生成一条新的边。
[0125]
步骤7010:判断滑动窗口是否已经达到当前时刻,如果已经达到当前时刻,那么存储所有停留点信息,如果没有到达当前时刻,那么转至步骤701。
[0126]
上述技术方案中,所述步骤80用于实现提取研究对象周期性特征的算法:按照稠密轨迹数据和已经建立的停留顶点、边统计数据中的周期性特征,如图4所示,具体而言包含以下步骤:
[0127]
步骤801:按照稠密轨迹数据对应的停留顶点,统计该停留顶点的周期性信息;其中包括:v
duration_maximum
为停留点在时间t内停留的最大时长,v
duration_average
为停留点时间t内的平均时长,v
total_visit_count
为在时间t内访问停留点的总次数,v
cycle_visit_count
为在δt内访问停留点的次数。
[0128]
步骤802:按照稠密轨迹数据经过的边,统计该边的周期性信息;e
duration
为边上消耗的平均时长,e
total_visit_count
为在时间t内经过边的总次数,e
cycle_visit_count
为在δt内经过边的次数;
[0129]
步骤803:将步骤801中的特征向量化;
[0130]
步骤804:将步骤802中的特征向量化;
[0131]
步骤805:将步骤803、步骤804得到特征向量分别赋值给对应停留顶点和边中对应的属性。
[0132]
本发明的创新点在于以下三点:
[0133]
本发明主要是克服当前基于poi位置预测中无法有效利用多种研究对象偏好上下文,只能使用隐性特征来表示研究对象信息和poi特征的缺点。而且在训练模型时,对超参数的设置,无法提供有说服力的可解释性来充分说明研究对象的为什么会对特定位置抱有偏好,并且是什么原因导致研究对象访问某个位置。同时在对研究对象特征建模时,无法有效获取研究对象的个体特征,因此无法对研究对象的进行充分的表示。
[0134]
创新点之一:有效组织偏好上下文和空间特征。
[0135]
传统的基于poi位置的位置预测模型中,由于位置数据的稀疏性无法有效的将用户的多模态上下文与轨迹进行对齐。本发明有效的将多模态偏好上下文和轨迹进行了对齐。从而将偏好特征和空间特征进行有有机融合。
[0136]
创新点之二:基于增强图表达融合用户时间特征和空间特征。
[0137]
在融合偏好上下文和空间特征的基础上,本发明使用图结构对用户的轨迹进行了可表示的嵌入,从而可解释性的将时间特征和空间特征进行了有机融合。所有的图中的参数均具备良好的可解释性。同时将研究对象的个体特征作为图增强结构中的全局变量,从
而充分利用图增强结构对非线性数据的表达能力。这种方法扩展了现有基于poi位置预测的模型构建方式,同时能够提升预测效果。
[0138]
创新点之三:基于self-attention机制进行特征提取本发明充分利用了self-attention机制。将其用于图增强结构的汇聚、特征融合和位置预测部分。从而有效的关注特征中权重更高的部分。这种方法有效利用了self-attention的多模态表征潜力,使得模型更加简单、易用,方便在工业化场景中进行应用。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。