1.本公开涉及自然语言处理技术领域,具体而言,涉及一种文本标签确定方法、文本标签确定装置、计算机可读存储介质及电子设备。
背景技术:
2.随着互联网技术的不断发展应用,如何对海量数据进行分析进而获取有价值的数据是至关重要的。而对于文本数据来讲,通过打标的方式能快速获取文本数据的关键信息。
3.相关技术中,采用人工打标,或者采用神经网络模型预测文本数据的标签,进而实现对文本数据的打标。但是人工打标存在效率低和准确性差的问题;而神经网络模型打标往往只能实现单一标签的预测,对于多标签的文本数据存在标签预测准确性低的问题。
4.需要说明的是,在上述背景技术部分公开的信息仅用于加强对本公开的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现要素:
5.本公开实施例的目的在于提供一种文本标签确定方法、文本标签确定装置、计算机可读存储介质及电子设备,进而在一定程度上解决了相关技术中对文本数据的多标签预测过程中,存在的效率低和预测准确性低的问题。
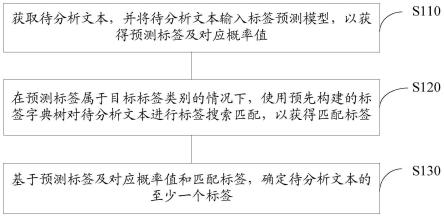
6.根据本公开的第一方面,提供了一种文本标签确定方法,包括:获取待分析文本,并将所述待分析文本输入标签预测模型,以获得预测标签及对应概率值;在所述预测标签属于目标标签类别的情况下,使用预先构建的标签字典树对所述待分析文本进行标签搜索匹配,以获得匹配标签;基于所述预测标签及对应概率值和所述匹配标签,确定所述待分析文本的至少一个标签。
7.在本公开的一种示例性实施例中,基于前述方案,所述标签预测模型的训练过程包括:获取具有标签的文本数据作为训练数据,得到训练样本数据和样本标签向量;将所述训练样本数据输入所述标签预测模型,获得对应的样本分类概率向量;采用目标损失函数,计算所述样本分类概率向量和所述样本标签向量之间的损失函数值;其中,所述样本分类概率向量包括正样本分类概率值和负样本分类概率值,所述目标损失函数为基于所述正样本分类概率值和所述负样本分类概率值进行展开的二元交叉熵损失函数,所述目标损失函数不包含所述正样本分类概率值的高阶项和所述负样本分类概率值的高阶项;基于所述损失函数值,更新所述标签预测模型的参数。
8.在本公开的一种示例性实施例中,基于前述方案,所述标签预测模型包括预训练编码模块和分类模块,所述将所述训练文本数据输入所述标签预测模型,获得对应的样本分类概率向量,包括:基于所述训练文本数据,获得训练初始向量;将所述训练初始向量输入所述预训练编码模块进行语义编码,获得编码结果;将所述编码结果输入所述分类模块进行线性变换,获得样本分类概率向量。
9.在本公开的一种示例性实施例中,基于前述方案,所述将所述训练文本数据输入
所述标签预测模型,获得对应的样本分类概率向量,还包括:通过旋转矩阵对所述训练初始向量中元素的绝对位置信息进行编码,获得元素的相对位置向量;所述语义编码的过程,包括:将所述相对位置向量和所述训练初始向量输入所述预训练编码模块,获得编码结果。
10.在本公开的一种示例性实施例中,基于前述方案,所述方法还包括:在所述待分析文本的长度大于第一阈值的情况下,对所述待分析文本进行截断处理。
11.在本公开的一种示例性实施例中,基于前述方案,所述对所述待分析文本进行标签搜索匹配,包括:将所述待分析文本作为主字符串,将所述标签字典树作为模式字符串;采用前缀树匹配方式,在所述模式字符串中对所述主字符串进行搜索匹配,获得匹配标签。
12.在本公开的一种示例性实施例中,基于前述方案,所述方法还包括:在所述预测标签不属于目标标签类别的情况下,响应于所述预测标签的对应概率值与第二阈值的比较结果,确定所述待分析文本的至少一个标签。
13.根据本公开的第二方面,提供一种文本标签确定装置,预测模块,用于获取待分析文本,并将所述待分析文本输入标签预测模型,以获得预测标签及对应概率值;匹配模块,用于在所述预测标签属于目标标签类别的情况下,使用预先构建的标签字典树对所述待分析文本进行标签搜索匹配,以获得匹配标签;第一确定模块,用于基于所述预测标签及对应概率值和所述匹配标签,确定所述待分析文本的至少一个标签。
14.根据本公开的第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一实施例所述的方法。
15.根据本公开的第四方面,提供一种电子设备,包括:一个或多个处理器;以及存储装置,用于一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器执行上述任一实施例所述的方法。
16.本公开示例性实施例可以具有以下部分或全部有益效果:
17.在本公开示例实施方式所提供的文本标签确定方法中,可以通过标签预测模型获得预测标签及对应概率值;同时使用标签字典树对待分析文本进行标签搜索匹配,获得匹配标签;再基于预测标签及对应概率值和匹配标签,确定待分析文本的至少一个标签。一方面通过引入标签字典树,对预测标签进行二次处理,保证处理效率的同时,提高了最终确定标签的准确性,从而提高用户体验。另一方面,本公开可以对目标标签类型的文本数据进行多标签预测,保证目标场景的多标签预测的准确性。
18.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
19.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
20.图1示意性示出了根据本公开的一个实施例的文本标签确定方法的流程图。
21.图2示意性示出了根据本公开的一个实施例中标签预测模型的训练过程流程图。
22.图3示意性示出了根据本公开的一个实施例中标签预测模型的训练过程流程图之
一。
23.图4示意性示出了根据本公开的一个实施例中标签预测模型的训练过程流程图之二。
24.图5示意性示出了根据本公开的一个实施例中标签字典树的示意图。
25.图6示意性示出了根据本公开的一个实施例的文本标签确定方法的实施过程流程图。
26.图7示意性示出了根据本公开的一个实施例中文本标签确定装置的结构框图。
27.图8示出了适于用来实现本公开实施例的电子设备框图。
具体实施方式
28.现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本公开将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。在下面的描述中,提供许多具体细节从而给出对本公开的实施方式的充分理解。然而,本领域技术人员将意识到,可以实践本公开的技术方案而省略特定细节中的一个或更多,或者可以采用其它的方法、组元、装置、步骤等。在其它情况下,不详细示出或描述公知技术方案以避免喧宾夺主而使得本公开的各方面变得模糊。
29.此外,附图仅为本公开的示意性图解,并非一定是按比例绘制。图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。附图中所示的一些方框图是功能实体,不一定必须与物理或逻辑上独立的实体相对应。可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。
30.如图1所示,提供了一种文本标签确定方法,本实施例以该方法应用于终端设备进行举例说明,可以理解的是,该方法也可以应用于服务器,还可以应用于包括终端设备和服务器的系统,并通过终端设备和服务器的交互实现。其中,服务器可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn、以及大数据和人工智能平台等基础云计算服务的云服务器,也可以是区块链中的节点,终端可以是智能手机、平板电脑、笔记本电脑、台式计算机、智能音箱、智能手表、车载设备等,但并不局限于此。当本实施例提供的文本标签确定方法通过终端和服务器的交互实现时,终端以及服务器可以通过有线或无线通信方式进行直接或间接地连接,本公开在此不做限制。
31.本公开实施例所提供的文本标签确定方法可以在服务器执行,相应地,文本标签确定装置一般设置于工作服务器中。本公开实施例所提供的文本标签确定方法可以在终端设备执行,相应地,文本标签确定装置一般设置于终端设备中。
32.参考图1所示,本公开提供的一种示例实施方式的文本标签确定方法,可以包括以下步骤:
33.步骤s110,获取待分析文本,并将待分析文本输入标签预测模型,以获得预测标签
及对应概率值。
34.在本示例实施方式中,待分析文本可以是不同场景下的文章,例如,可以是旅游相关文章、健康咨询相关文章/养生科普相关文章、特定年龄阶段相关文章等,本示例对此不做限定。待分析文本的长度可以是长文本(如上千字符)或短文本(几十或几百字符),本示例对此不做限定。待分析文本的获取方式可以是接收终端上传或通过界面交互的方式输入的,也可以是读取存储器存储的,本示例对此不做限定。
35.在本示例实施方式中,标签预测模型可以包括卷积神经网络(convolutional neural networks,cnn)、循环神经网络(recurrent neural network,rnn)或基于注意力机制(attention)的transformer网络及分类层;cnn、rnn、transformer用于对文本进行语义编码,分类层用于对编码向量进行标签维度的映射。示例性地,标签预测模型可以是bert预训练模型。
36.步骤s120,在预测标签属于目标标签类别的情况下,使用预先构建的标签字典树对待分析文本进行标签搜索匹配,以获得匹配标签。
37.在本示例实施方式中,目标标签类别是指需要优先保证预测准确性的标签类型。示例性地,当待分析文本为健康资讯类标签时,可以将目标标签类别设置为疾病类标签,例如疾病类标签:“急性肠胃炎”等。
38.在本示例实施方式中,标签字典树的构建可以使用标签体系中的目标标签类别(如疾病类标签)进行词语扩充,以避免在标签字典树中搜索不到结果的问题。用查找的标签词的集合进行前缀树建模,形成对应的标签字典树。
39.步骤s130,基于预测标签及对应概率值和匹配标签,确定待分析文本的至少一个标签。
40.在本示例实施方式中,可以基于预测标签概率值设定第一判断条件,基于预测标签和匹配标签设定第二判断条件。例如,可以设置第一判断条件为预测标签概率值大于某一阈值,第二判断条件设置为预测标签和匹配标签相同。也可以基于预测标签对应概率值、预测标签和匹配标签设置标签丢弃方案,将未丢弃的标签作为最终结果。
41.在本示例实施方式所提供的文本标签确定方法中,所提供的文本标签确定方法中,可以通过标签预测模型获得预测标签及对应概率值;同时使用标签字典树对待分析文本进行标签搜索匹配,获得匹配标签;再基于预测标签及对应概率值和匹配标签,确定待分析文本的至少一个标签。一方面通过引入标签字典树,对预测标签进行二次处理,保证处理效率的同时,提高了最终确定标签的准确性,从而提高用户体验。另一方面,本公开可以对目标标签类型的文本数据进行多标签预测,保证目标场景的多标签预测的准确性。
42.以下对本公开的各个步骤进行更加详细的描述。
43.在一些实施例中,参考图2,标签预测模型的训练过程包括以下步骤s210-s240。
44.步骤s210,获取具有标签的文本数据作为训练数据,得到训练样本数据和样本标签向量。
45.在本示例实施方式中,为了适应不同使用场景的多标签分类需求,可根据不同的应用场景和数据特点,选用不同的训练数据。示例性地,对于平台的健康咨询类文章,可以选用同平台或不同平台的健康资讯类/养生科普类文章作为训练数据,训练数据的多样化能够保证训练效果。可以将一篇或一段健康资讯类文章作为一个训练样本。
46.在本示例实施方式中,采用人工标注的方式对训练样本打标签,可以对不同的标签设置不同的标号或数字表示,以形成样本标签向量。也可以以标签向量的位置代表一个标签,以该位置的数值(0或1)确定是否含有该标签。例如,文章的人工打标签结果为:肝病、腹泻、便秘、肝炎。可以将这些标签词转换为one-hot形式,也就是可以采用长度一定长度(如151)的向量表示这些标签,向量的每个位置代表一类标签,样本打上了该标签,则该位置为1,否则为0。
47.举例而言,训练样本可以包括标题和正文,标题为“大便不好也可能是肝病”;正文为“有读者问,大便总是不正常,不是便秘就是大便失禁,做过肠镜检验没发现问题,但是吃了很多药也不见好,而且也不知道是该通便还是该止泻。如果这种情况长期存在,又排除了肠道的问题,必要时要查查肝脏和胆囊,因为有的腹泻是“肝源性腹泻”,和肝脏的功能有关系,很多慢性肝病的人腹泻是常见症状,但之前并不知道自己是肝病,只不过是肝炎病毒的携带者,因为没有症状,什么时候转变成了慢性肝炎,自己也说不清,后来是因为检查腹泻的原因发现有肝病问题的,甚至有的已经是晚期,肝功能都快失去代偿了。几乎每个科的医生,都会把自己熟悉的疾病称为“无声的杀手”,包括高血压、肝炎、青光眼,这些病在慢慢转变甚至加重的过程中,是没有什么明显感觉的:高血压的时候,人可能已经适应了,不吃药也没觉得异常,但就在这种无感中,心脑肾等靶器官时时刻刻都在受到损伤。青光眼也一样,可以引起失明,但发生在单侧时,通过另一只眼睛的代偿,病人看东西没什么障碍,最后发现失明的时候,都说不清什么时候发生的,但往往已经过了治疗良机。肝炎也同样,最典型的肝脏症状是疲劳,但很多人把这归结为上了年岁,或工作太累,因为疲劳这个症状实在没有特异性,可以是病状也可以是劳累之后的正常生理感受,以至于贻误治疗。因此,只要一种病症长期存在,而且用常规的原因解释不了,比如大便异常,但肠道却没问题,就要从其他方面想一想,包括胆囊,很多胆囊炎、胆结石的病人都有便秘与腹泻交替的症状,和胆汁对脂肪的消化能力下降有关,所以不是单纯的通便止泻的问题,而是要关注肝胆的状况。”可以将上述标题和正文进行拼接组成一个训练文本,样本长度为651。该示例中的人工标注标签为“肝病、腹泻、便秘、肝炎”。
48.步骤s220,将训练样本数据输入标签预测模型,获得对应的样本分类概率向量。
49.在本示例实施方式中,标签预测模型可以先对文章中的字进行数字化、向量化,再对向量化后的字向量进行语义编码,抽取更多的上下文信息,获得向量序列;再经过分类层映射到样本标签向量维度,获得样本分类概率向量。其中,用于语义编码的网络具体可以是循环神经网络、卷积神经网络等,本实施例对此不做具体限定。
50.步骤s230,采用目标损失函数,计算样本分类概率向量和样本标签向量之间的损失函数值。
51.在本示例实施方式中,样本分类概率向量包括正样本分类概率值和负样本分类概率值,目标损失函数为基于正样本分类概率值和负样本分类概率值进行展开的二元交叉熵损失函数,目标损失函数不包含正样本分类概率值的高阶项和负样本分类概率值的高阶项。本示例中,高阶项是指正样本分类概率值和/或负样本分类概率值的二次及以上的计算项。
52.目标损失函数的表达式推导过程如下:
53.二元交叉熵(binary cross entropy,bce)损失函数表达式为:
[0054][0055]
式中,x表示模型输出的预测标签,y表示样本真实标签。n表示样本总数,a表示样本编号。
[0056]
将样本的标签类别分为正样本和负样本两组,将上式(1)变形并进行展开为:
[0057][0058]
式中,l表示损失函数,ω
pos
表示正样本分类概率值的编号集合,ω
neg
表示负样本分类概率值的编号集合,sj表示第j个正样本分类概率值,si表示第i个负样本分类概率值,j、o、p、q分别表示正样本分类概率值的编号,i、l、m、n分别表示负样本分类概率值的编号。
[0059]
从式(2)可以看出,式中将累乘形式转换成求和形式后,式中会包含二阶项和三阶项还有其他更高阶次项。而通过对某平台文章的统计结果可知,当样本标签向量维度为151时,也就是总共151个标签时,平均每个样本的标签数量约为4~5个,每个标签的正负样本比例小于0.006,出现了正负样本极度不平衡的现象。因此,若使用bce损失函数,根据上式(2)可知,前半部分的对数的真数中的累乘项数量很多,而后半部分对数的真数中的累乘项数量很少,且同一个样本中多达一百多个标签的后半部分累乘项不存在。这样就会导致模型在训练过程中,标签的负样本对梯度的影响较大,使得模型无法有效学习到正样本的信息,影响模型训练效果。
[0060]
为了缓解标签正负样本比例不平衡的问题,本公开丢弃bce损失函数中的高价展开项(如丢弃二阶以上展开项),这样模型在训练过程中学习到的正样本和负样本信息量差距减小,可以提升模型的学习效果。本示例得到的目标损失函数的表达式为:距减小,可以提升模型的学习效果。本示例得到的目标损失函数的表达式为:
[0061]
通过该目标损失函数,可以提高模型学习效果,进而提高模型的预测准确率;同时,可以大量减小模型训练过程中的数据处理量,减小硬件运力负担。
[0062]
步骤s240,基于损失函数值,更新标签预测模型的参数。
[0063]
在本示例实施方式中,可以采用初始化进程对标签预测模型的参数进行初始化,例如,将模型参数初始化为0或者1。每轮训练结束后,基于步骤s230计算的损失函数值,进行梯度的反向传播,更新标签预测模型的参数。直到模型收敛或达到预设的训练次数,停止训练即可。训练好的标签预测模型可以用于步骤s110中的待分析文本的标签预测过程。
[0064]
在一些实施例中,参考图3,标签预测模型300包括预训练编码模块310和分类模块320,标签预测模型300的数据处理过程,包括:
[0065]
先对训练文本数据进行向量化,获得训练初始向量。
[0066]
在本示例实施方式中,可以通过某种映射方式将字转换成数字,再对数字进行向量化即可获得训练初始向量。例如:可以采用词的embedding来实现向量化过程。
[0067]
将训练初始向量输入预训练编码模块进行语义编码,获得编码结果。
[0068]
在本示例实施方式中,预训练编码模块采用transformer架构中的编码(encoder)模块,对训练初始向量进行特征提取,获得编码后的向量序列,例如,语义编码输出向量维度为768
×
2048,2048为输入向量长度。
[0069]
将编码结果输入分类模块进行线性变换,获得样本分类概率向量。
[0070]
在本示例实施方式中,分类模块可以是线性变换层,将编码结果变换到标签维度。还可以在分类模块前加入一层dropout,以一定概率(如0.1)随机丢弃一些神经元,然后再进行线性变换,得到标签维度的样本分类概率向量。
[0071]
在一些实施例中,参考图4,标签预测模型400包括预训练编码模块410和分类模块420,预训练编码模块包括旋转位置编码模块411和语义编码模块412,标签预测模块400的数据处理过程包括:先进行训练样本数据的向量化,获得训练初始向量及位置向量。位置向量为基于训练初始向量中元素的绝对位置信息得到的。经旋转位置编码模块411通过旋转矩阵对训练初始向量中元素的绝对位置信息进行编码,获得元素的相对位置向量。将相对位置向量和训练初始向量进行语义编码,获得编码结果。对编码结果进行线性变换,得到输出结果。
[0072]
本示例中,通过旋转位置编码模块引入字符的位置相关信息,增加了对文本的语义提取,提高预测标签的准确性。此外,通过加入旋转位置编码模块,使得标签预测模型对输入篇章序列长度的没有限制,保证了长文本的前部文本语义信息提取,避免多端切割处理带来的段与段之间信息丢失的问题。
[0073]
一些实施例中,方法还包括:
[0074]
在待分析文本的长度大于第一阈值的情况下,对待分析文本进行截断处理。
[0075]
在本示例实施方式中,考虑到数据处理效率以及一般文章的长度,可以设置第一阈值,使得在保证正常的数据处理效率的前提下,一般文章都不需要进行截断处理。而对于个别较长的文章进行截断处理,避免一个处理数据长度过长而影响处理效率。例如,可以将第一阈值设置为2048。
[0076]
一些实施例中,对待分析文本进行标签搜索匹配,包括:
[0077]
将待分析文本作为主字符串,将标签字典树作为模式字符串;
[0078]
采用前缀树匹配方式,在模式字符串中对主字符串进行搜索匹配,获得匹配标签。
[0079]
在本示例实施方式中,前缀树匹配方式中,根节点到目标节点之间每个字符按顺序排列形成一个标签字符串。如果主字符串中存在匹配到模式字符串的根字符,则继续匹配直到匹配出整个疾病标签字符串。如图5所示,匹配到的疾病字符串可以是“胃癌”、“胃溃疡”或“肾炎”、“肾衰竭”。
[0080]
一些实施例中,方法还包括:
[0081]
在预测标签不属于目标标签类别的情况下,响应于预测标签的对应概率值与第二
阈值的比较结果,确定待分析文本的至少一个标签。
[0082]
在本示例实施方式中,当预测标签为普通标签时,示例性地,预测标签为非疾病类标签,如“青少年”、“产后”、“办公室”等,可以将预测标签的概率值大于第二阈值(如0.85)的预测标签作为最终标签,该标签可以为一个或多个,以保证处理效率。
[0083]
举例而言,本公开的文本标签确定方法的实现过程如图6所示,可以包括以下步骤:
[0084]
步骤s601,获取待分析文本。
[0085]
在本示例中,可以从各类资讯平台或公众号获取待分析文本。例如,可以是一篇关于健康咨询的文章。
[0086]
步骤s602,将待分析文本向量化,获得对应目标向量。
[0087]
在本示例中,可以采用embedding对待分析文本进行向量化,获得目标向量。
[0088]
步骤s603,采用预训练编码模块对目标向量进行语义编码,获得编码结果。
[0089]
在本示例中,预训练编码模块可以包括旋转位置编码模块和语义编码模块。旋转位置编码模块通过旋转矩阵对目标向量中元素的绝对位置信息进行编码,获得元素的相对位置向量。将相对位置向量和目标向量进行语义编码,获得编码结果。
[0090]
步骤s604,采用分类模块对编码结果进行线性变换,获得预测标签概率向量。
[0091]
在本示例中,线性变换之前可以进行dropout丢弃部分神经元,再对编码结果进行线性变换,获得标签维度的预测标签概率向量。例如,输出结果为“胃炎:0.95,胃溃疡:0.4”。
[0092]
以上步骤s603和s604的预训练编码模块和分类模块的模型参数都是经过模型训练后确定的。
[0093]
步骤s605,基于预测标签概率向量,判断当前预测标签是否属于目标标签类型的预测标签。若是,则转入步骤s608,否则,转入步骤s609。
[0094]
在本示例中,目标标签类型可以是疾病类标签。
[0095]
步骤s606,构建针对目标标签类型的标签字典树。
[0096]
在本示例中,使用标签体系中的疾病类标签进行词语扩充,然后用这些词的集合进行前缀树建模,获得所需的字典树,如附图5所示,图5中,root表示根字符,根字符为空。
[0097]
步骤s607,使用标签字典树对待分析文本进行标签搜索匹配,获得匹配标签。
[0098]
在本示例中,采用前缀树匹配方式进行搜索匹配,如附图5所示,匹配标签可以为“胃癌、胃溃疡”等多个标签。
[0099]
以上示例中,步骤s606和s607可以与步骤s601同时进行,也可以在步骤s601之前实施。
[0100]
步骤s608,判断当前预测标签的概率值是否小于第三阈值(如0.5),且该预测标签在匹配标签中不存在,若是,转入步骤s611,否则,转入步骤s609。
[0101]
步骤s609,判断当前预测标签的概率值是否大于第二阈值(如0.85),若是,则转入步骤s610。否则,转入步骤s611。
[0102]
步骤s610,确定当前预测标签为待分析文本的一个标签。
[0103]
步骤s611,丢弃该预测标签。
[0104]
根据上述具体实施过程,提供了一个具体实施例,本实施例包含151个标签的健康
咨询类文本数据,文本长度为1680。分别采用本公开方法和bert-base方法在相同实验条件下,对该文本数据进行标签预测,结果如表1所示。
[0105]
表1不同预测方法的预测结果
[0106]
预测模型f1值bert-base0.8897本公开方法0.9249
[0107]
其中,f1=2
×
p
×
r/(p r),p表示精确率,r表示召回率。
[0108]
从表1结果可以看出,本公开方法相较于相关技术中较成熟的bert-base模型,预测结果的f1值显著提高,说明本公开方法对于文章长度较长的文章具有较好的标签预测准确性,相较于bert-base模型显著提高了标签预测的准确性,保证预测效果。
[0109]
本公开针对需要优先保证准确率的目标标签类型进行设计,以提高该类标签的预测准确性。示例性的,对于健康资讯类文章,将目标标签类别设为疾病类标签。通过本公开方法提高标签预测准确性,特别是疾病类标签预测的准确性,从而使平台能够更准确的为用户推荐健康咨询类文章。此外,可以将非疾病类标签作为另一类普通标签,本公开方法同样也适用于对普通标签的预测及推荐,提升文章推荐的效果,从而一方面可以提升用户的使用体验,另一方面可以提升平台的内容点击率。
[0110]
本公开一方面通过标签预测模型完成对普通标签的快速预测,另一方面结合标签字典树对目标标签类别的标签进行二次确认,提升了目标标签类别的预测准确性,且能够在模型层面平衡预测结果的准确率和召回率。此外,扩展了本公开的应用场景。
[0111]
本公开通过对语义编码过程引入旋转编码位置信息,进一步增加了对文本的语义信息提取,保证了预测结果的准确性。本公开通过对实际情况的分析,对二元交叉熵损失函数进行了改进,缓解了标签正负样本不平衡对模型带来的负面影响,提升了模型的训练效果,减轻模型训练过程中的运算负担,提升硬件运行效率。
[0112]
进一步的,本示例实施方式中,还提供了一种文本标签确定装置700。该文本标签确定装置700可以应用于服务器。参考图7所示,该文本标签确定装置700可以包括:预测模块710,用于获取待分析文本,并将待分析文本输入标签预测模型,以获得预测标签及对应概率值;匹配模块720,用于在预测标签属于目标标签类别的情况下,使用预先构建的标签字典树对待分析文本进行标签搜索匹配,以获得匹配标签;第一确定模块730,用于基于预测标签及对应概率值和匹配标签,确定待分析文本的至少一个标签。
[0113]
在本公开的一种示例性实施例中,装置700还包括训练模块740,训练模块740包括:获取子模块,可以用于获取具有标签的文本数据作为训练数据,得到训练样本数据和样本标签向量;预测子模块,可以用于将训练样本数据输入标签预测模型,获得对应的样本分类概率向量;计算子模型,可以用于采用目标损失函数,计算样本分类概率向量和样本标签向量之间的损失函数值;其中,样本分类概率向量包括正样本分类概率值和负样本分类概率值,目标损失函数为基于正样本分类概率值和负样本分类概率值进行展开的二元交叉熵损失函数,目标损失函数不包含正样本分类概率值的高阶项和负样本分类概率值的高阶项。更新子模块,可以用于基于损失函数值,更新标签预测模型的参数。
[0114]
在本公开的一种示例性实施例中,标签预测模型包括预训练编码模块和分类模块;预测子模块还可以用于:基于训练文本数据,获得训练初始向量;将训练初始向量输入
预训练编码模块进行语义编码,获得编码结果;将编码结果输入分类模块进行线性变换,获得样本分类概率向量。
[0115]
在本公开的一种示例性实施例中,预测子模块还可以用于:
[0116]
通过旋转矩阵对训练初始向量中元素的绝对位置信息进行编码,获得元素的相对位置向量;语义编码的过程,包括:将相对位置向量和训练初始向量输入预训练编码模块,获得编码结果。
[0117]
在本公开的一种示例性实施例中,装置700还包括截断模块,截断模块可以用于:在待分析文本的长度大于第一阈值的情况下,对待分析文本进行截断处理。
[0118]
在本公开的一种示例性实施例中,匹配模块720还可以用于:将待分析文本作为主字符串,将标签字典树作为模式字符串;采用前缀树匹配方式,在模式字符串中对主字符串进行搜索匹配,获得匹配标签。
[0119]
在本公开的一种示例性实施例中,装置700还包括第二确定模块,第二确定模块可以用于:在预测标签不属于目标标签类别的情况下,响应于预测标签的对应概率值与第二阈值的比较结果,确定待分析文本的至少一个标签。
[0120]
上述文本标签确定装置中各模块或单元的具体细节已经在对应的文本标签确定方法中进行了详细的描述,因此此处不再赘述。
[0121]
作为另一方面,本技术还提供了一种计算机可读介质,该计算机可读介质可以是上述实施例中描述的电子设备中所包含的;也可以是单独存在,而未装配入该电子设备中。上述计算机可读介质承载有一个或者多个程序,当上述一个或者多个程序被一个该电子设备执行时,使得该电子设备实现如下述实施例中的方法。例如,电子设备可以实现如图1~图6所示的各个步骤等。
[0122]
需要说明的是,本公开所示的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本公开中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
[0123]
下面参照图8来描述根据本公开的这种实施例的电子设备800。图8显示的电子设备800仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。
[0124]
如图8所示,电子设备800以通用计算设备的形式表现。电子设备800的组件可以包
括但不限于:上述至少一个处理单元810、上述至少一个存储单元820、连接不同系统组件(包括存储单元820和处理单元810)的总线830、显示单元840。
[0125]
其中,存储单元存储有程序代码,程序代码可以被处理单元810执行,使得处理单元810执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施例的步骤。
[0126]
存储单元820可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(ram)8201和/或高速缓存存储单元8202,还可以进一步包括只读存储单元(rom)8203。
[0127]
存储单元820还可以包括具有一组(至少一个)程序模块8205的程序/实用工具8204,这样的程序模块8205包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
[0128]
总线830可以为表示几类总线结构中的一种或多种,包括存储单元总线或者存储单元控制器、外围总线、图形加速端口、处理单元或者使用多种总线结构中的任意总线结构的局域总线。
[0129]
电子设备800也可以与一个或多个外部设备870(例如键盘、指向设备、蓝牙设备等)通信,还可与一个或者多个使得用户能与该电子设备800交互的设备通信,和/或与使得该电子设备800能与一个或多个其它计算设备进行通信的任何设备(例如路由器、调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口850进行。并且,电子设备800还可以通过网络适配器860与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图所示,网络适配器860通过总线830与电子设备800的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备800使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、ra标识系统、磁带驱动器以及数据备份存储系统等。
[0130]
通过以上的实施例的描述,本领域的技术人员易于理解,这里描述的示例实施例可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本公开实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中或网络上,包括若干指令以使得一台计算设备(可以是个人计算机、服务器、终端装置、或者网络设备等)执行根据本公开实施例的方法。
[0131]
此外,上述附图仅是根据本公开示例性实施例的方法所包括的处理的示意性说明,而不是限制目的。易于理解,上述附图所示的处理并不表明或限制这些处理的时间顺序。另外,也易于理解,这些处理可以是例如在多个模块中同步或异步执行的。
[0132]
需要说明的是,尽管在附图中以特定顺序描述了本公开中方法的各个步骤,但是,这并非要求或者暗示必须按照该特定顺序来执行这些步骤,或是必须执行全部所示的步骤才能实现期望的结果。附加的或备选的,可以省略某些步骤,将多个步骤合并为一个步骤执行,以及/或者将一个步骤分解为多个步骤执行等,均应视为本公开的一部分。
[0133]
应可理解的是,本说明书公开和限定的本公开延伸到文中和/或附图中提到或明显的两个或两个以上单独特征的所有可替代组合。所有这些不同的组合构成本公开的多个可替代方面。本说明书的实施方式说明了已知用于实现本公开的最佳方式,并且将使本领域技术人员能够利用本公开。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。