1.本发明属于计算机数据查询与存储技术领域,具体涉及一种面向分布式存储系统的查询负载均衡方法。
背景技术:
2.面对海量数据存储需求,分布式存储系统能够将大量廉价pc服务器通过网络互联,作为一个整体对外提供存储服务,突破单机存储下的扩展性和性能瓶颈,因此得到了广泛的研究。由于存储服务器节点宕机、网络分区等异常情况的存在,分布式存储系统设计时往往会将数据冗余存储多个副本,当某个节点出现故障时,可从其他副本上读取数据,达到容错的目的。副本是分布式存储系统容错的唯一手段,但由于多副本的存在,如何保证副本之间的一致性是设计分布式系统的关键。
3.数据一致性算法raft简单且易于理解,能够有效满足数据一致性需求,但是基于单raft算法实现的分布式存储系统仍然存在系统负载均衡问题,其存储资源易于集中在部分节点,且客户端数据处理流量均由单个领导者(leader)节点完成,其他节点的计算资源始终处于空闲状态,集群的性能上限取决于单个raft集群中leader节点数据处理的速率。在查询过程中,查询操作仅与领导者节点进行交互,跟随者节点虽然存储数据,但无法提供查询服务。因此在维持数据一致性前提下,利用跟随者节点进行数据查询操作,将极大提高系统的查询负载能力,有效利用跟随者节点的计算资源。
4.因此,根据存储设备的资源情况,实现负载的感知迁移,在存储设备扩缩容及数据读写过程中使各设备资源使用率达到均衡的状态,对分布式存储系统的性能提升及其重要。
技术实现要素:
5.本发明正是针对现有技术中存在的问题,提供一种面向分布式存储系统的查询负载均衡方法,基于跟随者数据查询机制,设计基于代价评估的数据查询路由策略,通过分析查询过程消耗的资源情况,动态进行查询节点选择,完成数据查询;其中,跟随者数据查询机制为:对集中于领导者的查询请求向跟随者节点进行负载转移,执行数据查询;基于代价评估的数据查询路由策略为:收集当前存储的各存储节点的通信开销进行动态的代价评估,选择最合适的跟随者节点执行跟随者数据查询,均衡利用节点的计算资源。
6.为了实现上述目的,本发明采取的技术方案是:面向分布式存储系统的查询负载均衡方法,基于跟随者数据查询机制,设计基于代价评估的数据查询路由策略,通过分析查询过程消耗的资源情况,动态进行查询节点选择,完成数据查询;
7.所述跟随者数据查询机制为:对集中于领导者的查询请求向跟随者节点进行负载转移,执行数据查询;
8.所述基于代价评估的数据查询路由策略为:收集当前存储的各存储节点的通信开销进行动态的代价评估,选择最合适的跟随者节点执行跟随者数据查询。
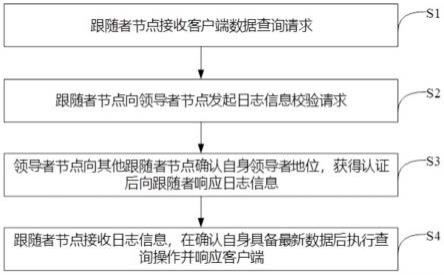
9.作为本发明的一种改进,所述跟随者数据查询机制具体包括如下步骤:
10.s1:跟随者节点接受客户端数据查询请求;
11.s2:跟随者节点向领导者节点发起日志信息校验请求,所述请求是应对集群中各节点状态在不断切换时,跟随者节点依旧保持与领导者数据的一致性;
12.s3:领导者节点向其他跟随者节点确认自身领导者地位,获得认证后向跟随者响应日志信息,所述领导者通过主动向跟随者节点广播心跳信息,来确认自身领导者角色,向请求日志信息校验的跟随者节点反馈当前集群的commitindex;
13.s4:跟随者节点接收反馈信息,在确认自身具备最新数据后执行查询操作并响应客户端,所述反馈信息仅包含日志信息commitindex。
14.作为本发明的另一种改进,所述基于代价评估的数据查询路由策略具体包括如下步骤:
15.s1'、统计数据查询代价信息:通过计算数据存储范围分区中的每个键值对的数据大小,来进行数据查询代价信息统计;
16.s2'、确定参数:根据步骤s1'统计获得的数据查询代价信息,确定影响代价评估的常量因子,计算路由选择算法参数;所述影响代价评估的常量因子为计算机硬件信息;
17.s3'、计算查询操作代价:依据基于代价评估的数据查询路由策略,计算各个节点的查询操作代价,所述查询操作代价为节点与存储层之间数据处理过程的耗时;
18.s4'、确定目的节点:根据步骤s3'的操作代价值,确定查询路由,根据对各节点的代价评估结果,选择合适的目的节点进行数据查询,即选择合适的跟随者节点。
19.与现有技术相比,本发明的技术优势为:
20.(1)提供的负载均衡方法针对分布式存储系统的查询过程,提出了跟随者数据查询机制,跟随者主动向领导者请求日志信息校验,领导者通过主动广播,确认自身地位,确认自身地位,为后续数据查询提供了数据的有效性保障。
21.(2)在跟随者节点执行数据查询的过程中,通过与领导者节点的日志信息校验,以极小的通信开销确认了自身数据处于最新状态,在提升系统查询负载的同时具备了数据强一致性。
22.(3)在跟随者查询机制的基础上,依据计算机硬件与网络通信的相关特点和参数,设计了动态适配系统资源使用情况的负载均衡策略,充分利用了分布式系统各节点的计算资源和存储资源,有效提升了系统性能。
附图说明
23.图1是本发明方法中跟随者数据查询机制的步骤流程图;
24.图2是本发明方法中基于代价评估的数据查询路由策略的步骤流程图;
25.图3是本发明方法中跟随者数据查询机制的结构框架流程图;
26.图4是本发明实施例2中提供的范围分区直方图信息统计示意图;
27.图5是单条数据1kb大小下,单领导者查询机制、跟随者数据查询机制和基于代价评估的数据查询路由策略三种数据查询方法性能的对比图;
28.图6是单条数据5kb大小下,单领导者查询机制、跟随者数据查询机制和基于代价评估的数据查询路由策略三种数据查询方法性能的对比图。
具体实施方式
29.下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
30.实施例1
31.面向分布式存储系统的查询负载均衡方法,基于跟随者数据查询机制,设计基于代价评估的数据查询路由策略,通过分析查询过程消耗的资源情况,动态进行查询节点选择,完成数据查询。
32.其中,跟随者数据查询机制为:对集中于领导者的查询请求向跟随者节点进行负载转移,执行数据查询。该方法可以应用于众多的基于raft算法维持数据一致性的分布式存储系统的数据读取场景中,解决了raft协议数据查询集中于leader节点的问题。
33.跟随者(follower)数据查询方法,如图3所示,通过向follower节点发送查询请求,分摊leader查询负载;follower在接收到客户端查询请求时,向leader发起提交日志核对请求;leader向follower返回当前已提交日志编号;follower在核对本地已提交日志编号大于等于leader后,执行查询请求并向客户端返回查询结果。如图1所示,所述跟随者数据查询机制具体包括如下步骤:
34.步骤s1:跟随者节点接受客户端数据查询请求,对于数据查询请求的接收方式不作任何限定;
35.步骤s2:跟随者节点向领导者节点发起日志信息校验请求;
36.跟随者向当前集群的领导者节点获取集群已提交数据的日志信息commitindex。该请求是应对集群中各节点状态在不断切换时,跟随者节点依旧保持与领导者数据的一致性,保证向客户端返回的数据正确性;
37.步骤s3:领导者节点向其他跟随者节点确认自身领导者地位,获得认证后向跟随者响应日志信息;
38.集群状态的切换可能会引起选举的重新进行,领导者节点的角色可能发生转换,因此在收到跟随者的日志信息commitindex的校验请求后,领导者通过主动向跟随者节点广播心跳信息,来确认自身领导者角色,保证数据一致性。领导者节点在获得多数节点的响应信息后,确认自身领导者角色后向请求日志信息校验的跟随者节点反馈当前集群的commitindex;
39.步骤s4:跟随者节点接收反馈信息,在确认自身具备最新数据后执行查询操作并响应客户端;
40.反馈信息仅包含日志信息commitindex,因此领导者与跟随者通信开销极小。跟随者在获取日志信息后,与自身存储数据的日志信息进行比较,若本地commitindex大于等于领导者节点的commitindex,即可确认自身节点已具备最新数据,可以执行查询操作,向磁盘中读取目标数据并相应客户端。
41.面向分布式存储系统的查询负载均衡方法,其中,基于代价评估的数据查询路由策略为建立数据查询操作代价评估模型,根据查询的时间代价,选择合适的目标节点,进行查询操作的负载均衡,如图2所示,其步骤具体包括:
42.步骤s1'、统计数据查询代价信息:
43.通过数据存储中的分区信息管理设计,进行数据查询代价信息统计,计算范围分
区中每个键值对的数据大小所使用的公式如下所示:
[0044][0045]
averagesize用于表示每个键值对的数据平均大小;
[0046]
range
total
用于表示当前分区所负责的数据总大小;
[0047]
range
keys
用于表示当前分区存储的键值对数目;
[0048]
下表1所示为计算机体系结构中常用硬件的参数性能参数,从表中可知,cpu、内存处理数据的速度相比网络、磁盘io快几十倍甚至上千倍,因此数据在cpu与内存中的处理时间可以忽略不计,针对数据查询时的磁盘、网络耗时进行代价评估,并给出具体选择查询的节点选择算法。
[0049]
表1常用硬件性能参数
[0050][0051]
步骤s2'、确定参数:根据步骤s1'统计获得的数据查询代价信息,确定影响代价评估的常量因子,计算路由选择算法参数;
[0052]
本实施例中,选择了一些计算机硬件信息作为最终进行代价评估算法的常量因子,并计算不同节点之间传输的网络消耗等信息作为路由选择的算法参数。
[0053]
步骤s3'、计算查询操作代价:依据基于代价评估的数据查询路由策略,计算各个节点的查询操作代价,所述查询操作代价为节点与存储层之间数据处理过程的耗时;
[0054]
本实例中,数据查询处理流程均由计算节点代理完成,并将查询结果响应至客户端,因此可仅计算节点与存储层之间数据处理过程的耗时。计算节点通过raft集群的leader节点和follower节点查询数据的耗时评估公式分别如以下公式所示。
[0055][0056][0057]
query
leader
用于表示通过领导者节点进行查询的总时间消耗;
[0058]
query
follower
用于表示通过跟随者节点进行查询的总时间消耗;
[0059]
cost
c-l
用于表示计算节点与leader传输的网络消耗;
[0060]
cost
l-c
用于表示leader与计算节点传输的网络消耗;
[0061]
cost
c-f
用于表示计算节点与follower传输的网络消耗;
[0062]
cost
f-c
用于表示follower与计算节点传输的网络消耗;
[0063]
result
size
用于表示查询结果集预估大小;
[0064]
用于表示查询结果集在领导者与计算节点的传输过程中的时延消耗,;
[0065]
用于表示查询结果集在跟随者与计算节点的传输过程中的时延消耗。
[0066]
cost
f-l
用于表示leader节点与follower节点网络消耗;
[0067]
λ用于表示磁盘读取数据的消耗;
[0068]
在代价评估时需获取各参数的参数值,具体获取方法如下:
[0069]
cost
c-l
/cost
l-c
、cost
c-f
/cost
f-c
,采取定时轮询的方式获取估计值。redis支持测试节点连通性指令ping指令,计算层发出该指令至指定存储层节点时,存储节点不会将其转移至raft算法流程处理,而是直接响应计算层节点,以此检测计算节点与存储节点的连通性。计算节点通过计算ping指令发出与收到响应之间的时间差,大致估计与存储层各节点的网络传输消耗,并通过map数据结构进行保存。为了动态评估该值大小,用户可设置定时轮询的间隔,时间间隔越小,评估值越能准确的描述节点间的传输耗时。
[0070]
result
size
,存储层节点中的每个range leader会定时向调度层发送心跳,同步当前range的状态信息,其中包括各range的存储数据量及键值对个数,若调度层检测到range的统计信息发生变化,会同步至计算节点。计算节点利用b树维护集群中所有range,数据查询时可通过搜索b树快速定位主键对应的range,并根据range统计信息估计其查询操作的结果集数据大小。
[0071]
cost
f-l
,本发明采用估计方式获取follower节点与leader节点之间的传输时延。存储层节点在启动时,需配置节点的标签信息,包括位置、机房、机架。若两个节点位于不同的机房,其cost
f-l
取值范围在15-50ms,若两个节点位于相同机房,可取值为0.1-0.25ms。
[0072]
以领导者节点的查询代价计算公式中的为例,影响该参数的估计结果有多种因素,包括网络带宽、网络拥塞情况以及收发双方节点的距离。大小为result
size
(mb)的数据块在带宽为band
net
的网络中传输的耗时计算如以下公式所示:
[0073][0074]
但在实际网络传输中,上述计算方式并不准确,例如局域网千兆网络和跨城市千兆网络的传输时延其差距达数十倍以上,还需同时考虑网络拥塞以及传输距离等情况。因此本节引入矫正因子以使估算结果尽可能接近真实值。引入矫正因子后的计算方法如以下公式所示:
[0075][0076]
为了动态计算数据在网络中的传输消耗,采用cost
l-c
作为一个真实测试值,其值大小会随着网络使用情况实时变化。σ是引入的矫正因子,其取值范围在(0.1,1)之间,根据实际情况选择。
[0077]
λ,该值大小与存储节点磁盘类型及查询数据量大小相关。磁盘类型可分为固态硬盘ssd和机械硬盘hdd,同类产品不同型号的数据读取速度也存在差异。λ的评估公式如以下公式所示,其中ν
read
表示磁盘的读取速率,一般出厂时会标注磁盘读取速率,也可通过读写测试获取该值。
[0078]
λ=result
size
*ν
read
[0079]
s4'、确定目的节点:根据步骤s3'的操作代价值,确定查询路由,根据对各节点的代价评估结果,选择合适的目的节点进行数据查询,即选择合适的跟随者节点。
[0080]
确定合适的跟随者节点后,再根据跟随者数据查询机制,执行数据查询。本方法基于跟随者数据查询机制,制定了动态适配系统资源使用情况的负载均衡策略,充分利用了分布式系统各节点的计算资源和存储资源,有效提升了系统性能。
[0081]
实施例2
[0082]
本实施例与实施例1的不同之处在于:在基于代价评估的数据查询路由策略的步骤s1'中,也可采用直方图信息描述对每个键值对数据大小的统计方式,如图4所示,图中包含4个直方图块,每个直方图代表一个range,其横轴的长度表示range内包含的键值对个数,纵轴的长度表述当前range存储的数据量大小,为简化模型,假设当前每个range存储的数据量大小均为64mb,但存储的键值对个数不同,因此可计算得到每个range分区中键值对数据的平均值大小。根据上述分析可知,基于range的信息统计方式相比扫描整个磁盘数据进行均值估计具有更细粒度、更精确的数据统计信息。
[0083]
测试例
[0084]
本测试例中部署了3台存储节点。节点启动后,写入20w条数据,总数据量约200mb,分别验证get指令在单领导者查询机制(leader based)、跟随者查询机制(follower read)和基于代价评估路由选择方法costbased三种方法下的性能指标。
[0085]
实验结果如图5所示。当并发量较小时,领导者节点能够较好的应对吞吐需求,跟随者查询机制性能最差,由于当前测试环境部署于局域网当中,测试时的网络延时并非影响系统吞吐的主要因素,选择从跟随者读取的方式造成了额外的网络开销,虽然基于代价评估路由选择方法能够计算查询代价,但查询代价计算过程需要程序加锁,对性能造成了一定影响。当并发量增加时,领导者负载增加导致性能瓶颈,从跟随者节点上读取数据能够提升系统吞吐,因此ops更高。图6展示了单条数据量在5kb情形下的实验结果。与1kb相同,在并发数较小时,跟随者查询机制的性能最差,基于代价评估路由选择方法次之,单领导者查询机制方法最佳,但随着并发数增加,由于此时单条数据较大,对领导者节点的资源消耗更多,因此跟随者查询机制和基于代价评估路由选择方法能够有效提升系统性能。
[0086]
通过两个不同数据大小下的实验可以得出,基于代价评估的数据查询负载均衡方法,能够综合计算raft集群中各节点的数据查询代价,并选择合适的节点进行查询操作,该方法可在单领导者查询机制和跟随者查询机制两种方法下得到均衡,在不同并发数大小下,性能表现良好。
[0087]
需要说明的是,以上内容仅仅说明了本发明的技术思想,不能以此限定本发明的保护范围,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰均落入本发明权利要求书的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。