1.本发明属于档案自动识别技术方向,具体涉及一种档案自动识别的方法。
背景技术:
2.目前,各个档案管理机构已经存有大量的纸质档案,后续还不断有新的纸质档案产生。纸质档案从诞生到现在的很长时间内都是以人工管理为主,人工管理纸质档案费时费力,检索极其不方便、效率低,利用时经常造成档案丢失和损坏、非常不利于档案的保管,档案信息无法共享、利用率低、经济效益不显著。
3.在档案数字化的过程中,档案整理扫描后势必要采集档案目录信息,档案目录信息作为后续档案信息化管理的依据,必须保证其百分百的正确率。目前比较多采取的方法大都是利用ocr识别技术进行著录,不可避免地会因为档案文件的类型不同导致识别发生错误,反而增加了人工审核和修改的成本,而且ocr识别技术并不能每次都准确地正确识别并填充到目录信息中。更甚的是档案卷宗中通常存在一些比如身份证、发票或者一些地形图之类的复印件文件,有些甚至可能是复印件的复印件,图像模糊难辨,单凭ocr技术无法识别,必须要人工审核后著录,增加了极大的人工返工成。
技术实现要素:
4.本发明的目的在于针对现有的装置一种档案自动识别的方法,以解决上述背景技术中提出的问题。
5.为了解决上述技术问题,本发明提供如下技术方案:一种档案自动识别的方法,包括如下步骤:
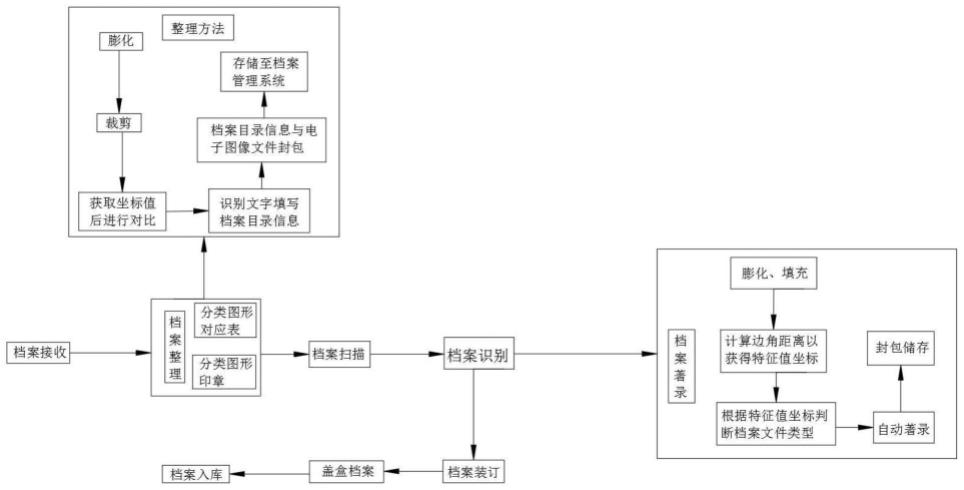
6.步骤s01,档案接收,接收纸质档案,由档案整理工作负责人统计本次工作所整理的档案的所有类型,选择其所对应的图形后制成分类图形对应表,制作相关分类图形印章;
7.步骤s02,档案整理,档案整理人员拿取需要进行识别的纸质档案并且对照分类图形对应表,选择该种档案对应的印章及相应颜色的印泥,在纸质档案的左上角、右上角或者规定部位盖章;
8.步骤s03,档案扫描,档案整理完毕后,档案整理人员将纸质档案扫描成电子图像文件存储进入档案整理系统中;档案管理软件内置分类图形对应算法,通过对档案文件上的分类图形的形状以及颜色进行识别后判断该文件的类别;
9.步骤s04,档案识别,档案整理系统内置的分类图形识别算法识别图像文件上的图形所对应的档案类型,从而确定该档案的类型后调用相应的档案模板进行自动著录;
10.步骤s05,档案装订,著录完毕后的档案文件与其对应的目录信息一同封包保存如档案管理系统中,纸质档案装订装盒后归还上架保存。
11.步骤s02中的整理方法包括如下步骤
12.步骤s21,档案整理人员将纸质档案扫描成电子图像文件后上传至档案管理系统,档案管理系统对电子图像文件进行膨化和填充;
13.步骤s22,膨化,对标准版式档案进行膨化填充操作;
14.步骤s23,裁剪,根据图像文件四条边的极值坐标进行裁剪,根据裁剪后的图像获取相关坐标(图像裁剪可排除因扫描的操作导致坐标不一致的问题,保证存储的是标准版式的坐标);
15.步骤s24,获取坐标值后进行对比,将处理后获得的坐标与原本系统信息库中的标准版式坐标相比对,坐标相同的就是同一类型的档案;
16.步骤s25,识别文字填写档案目录信息,确定档案类型后调用标准版式档案模板,根据模板所需信息的坐标点匹配电子图像文件坐标点所对应的信息填写进标准版式档案模板,完成自动编目;
17.步骤s26,封包存储至档案管理系统内,档案目录信息制作完毕后,将该电子图像文件和目录信息进行封包存储后进档案管理系统。
18.步骤s04中著录的方法包括如下步骤
19.步骤s41,膨化、填充,利用了opencv中的膨胀和填充操作,将纸质档案的电子图像文件中的文字部分转化为黑色色块;
20.步骤s42,计算边角距离以获得特征值坐标,得到黑色色块后,计算各个黑色色块与电子图像文件四条边和四个顶点的距离,并将所有数据进行比对;
21.步骤s43,根据特征值坐标判断档案文件类型,将所有数据进行比对后去掉相同的坐标值,留下不同的坐标值,该坐标就是各个种类的档案文件的特征值,根据该特征值即可判断这个文件的类别并且达成自动编目的目的;
22.步骤s44,自动著录,在获得档案文件的特征值坐标后确定其类型,根据其类型选择相应的档案格式模板,根据模板内容进行识别操作后自动填写进模板中,完成自动著录。
23.步骤s45,封包存储,在自动著录完成后,将扫描得到的电子图像文件和所获得的目录信息共同封包成一个文件存储进入档案管理系统中。
24.分类图形对应表包括档案类型,以及每种档案唯一对应的图形,分类图形对应表包括分类图形印章,分类图形印章包含分类图形对应表中的所有图形。
25.与现有技术相比,本发明所达到的有益效果是:本发明,
26.通过opencv的膨胀技术实现档案类型的自动识别,识别成功后再根据膨化坐标的相对距离自动定位并读取所需部分的信息并填写至档案目录信息内。利用自动识别、编目技术降低人工输档的出错风险,提高档案数字化的效率,而且opencv具有较高的可使用性和准确性。
附图说明
27.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
28.图1是本发明的档案识别流程示意图。
具体实施方式
29.以下结合较佳实施例及其附图对本发明技术方案作进一步非限制性的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的
实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
30.请参阅图1,本发明提供技术方案:一种档案自动识别的方法,包括如下步骤:步骤s01,档案接收,接收纸质档案,由档案整理工作负责人统计本次工作所整理的档案的所有类型,选择其所对应的图形后制成分类图形对应表,制作相关分类图形印章;
31.步骤s02,档案整理,档案整理人员拿取需要进行识别的纸质档案并且对照分类图形对应表,选择该种档案对应的印章及相应颜色的印泥,在纸质档案的左上角、右上角或者规定部位盖章;
32.步骤s03,档案扫描,档案整理完毕后,档案整理人员将纸质档案扫描成电子图像文件存储进入档案整理系统中;档案管理软件内置分类图形对应算法,通过对档案文件上的分类图形的形状以及颜色进行识别后判断该文件的类别;
33.步骤s04,档案识别,档案整理系统内置的分类图形识别算法识别图像文件上的图形所对应的档案类型,从而确定该档案的类型后调用相应的档案模板进行自动著录;
34.步骤s05,档案装订,著录完毕后的档案文件与其对应的目录信息一同封包保存如档案管理系统中,纸质档案装订装盒后归还上架保存。
35.步骤s02中的整理方法包括如下步骤
36.步骤s21,档案整理人员将纸质档案扫描成电子图像文件后上传至档案管理系统,档案管理系统对电子图像文件进行膨化和填充;
37.步骤s22,膨化,对标准版式档案进行膨化填充操作;
38.步骤s23,裁剪,根据图像文件四条边的极值坐标进行裁剪,根据裁剪后的图像获取相关坐标(图像裁剪可排除因扫描的操作导致坐标不一致的问题,保证存储的是标准版式的坐标);
39.步骤s24,获取坐标值后进行对比,将处理后获得的坐标与原本系统信息库中的标准版式坐标相比对,坐标相同的就是同一类型的档案;
40.步骤s25,识别文字填写档案目录信息,确定档案类型后调用标准版式档案模板,根据模板所需信息的坐标点匹配电子图像文件坐标点所对应的信息填写进标准版式档案模板,完成自动编目;
41.步骤s16,封包存储至档案管理系统内,档案目录信息制作完毕后,将该电子图像文件和目录信息进行封包存储后进档案管理系统。
42.步骤s04中著录的方法包括如下步骤
43.步骤s41,膨化、填充,利用了opencv中的膨胀和填充操作,将纸质档案的电子图像文件中的文字部分转化为黑色色块;
44.步骤s42,计算边角距离以获得特征值坐标,得到黑色色块后,计算各个黑色色块与电子图像文件四条边和四个顶点的距离,并将所有数据进行比对;
45.步骤s43,根据特征值坐标判断档案文件类型,将所有数据进行比对后去掉相同的坐标值,留下不同的坐标值,该坐标就是各个种类的档案文件的特征值,根据该特征值即可判断这个文件的类别并且达成自动编目的目的;
46.步骤s44,自动著录,在获得档案文件的特征值坐标后确定其类型,根据其类型选择相应的档案格式模板,根据模板内容进行识别操作后自动填写进模板中,完成自动著录。
47.步骤s45,封包存储,在自动著录完成后,将扫描得到的电子图像文件和所获得的目录信息共同封包成一个文件存储进入档案管理系统中。
48.膨化技术,是对扫描后所获得的电子图像文件的文字部分进行膨胀的形态学运算,即求局部最大值的过程。将档案中的某些数值看做是一个独立的图像文件,在该图像文件中的每一个像素点都看做是一个像素原点,同时确定该图像的膨胀范围,一般设定为一个n*n的矩阵,只要在该膨胀范围内存在像素点,则该膨胀范围则会全部变成黑色,是将膨化后文字形成的黑色不规则色块的空白处进行填充,使其成为一个规则的黑色长方形方块,填充技术,是将膨化后文字形成的黑色不规则色块的空白处进行填充,使其成为一个规则的黑色长方形方块,文字部分,由于现今需归档的档案均按照相关单位的制式要求进行制作,因此每种档案都有每种档案的固定格式,并且均为白底黑字打印。只要将档案电子图像文件的文字部分进行膨化填充得到一个个黑色的长方形方块,再将方块转化为多个坐标值,经过大量对比即可确定某种档案具有某些特有的、相同的坐标,即拥有这些特有的相同坐标的档案就是同类型的档案,并可得出该种档案的版式坐标,像素原点,由于档案均为白底黑字打印,因此将白底看做是背景色,黑色字迹看做是由无数个像素点聚合构成的一个图像,而该无数个像素点,就是像素原点,膨胀范围,为达到求取局部最大值,因此膨胀范围设定为一个n*n的矩阵,n的大小决定了膨胀的程度,该矩阵可称之为卷积核。在图像文件中,只要在该矩阵的范围内存在和黑色像素点,那么该矩阵将全部变为黑色。通过调整n的大小,可以调整变为黑色的部分大小,可以设定膨胀的次数,可称之为迭代次数。通过更改迭代次数可以更改膨胀范围,同时更改卷积核和迭代次数可以获得更加精确的结果,如在膨化、填充操作后不能成功识别该档案的类型,可通过修改n的大小或者迭代次数来使膨化识别的结果更加精确。
49.档案文件通过整理扫描后上传到档案管理系统中,系统内置的opencv算法对档案文件图像中的文字部分进行膨化,使每个文字都变成一个黑色的小方块,再对这些小方块进行填充操作,使小方块的顶点互相连接形成一个黑色长方形方块。分别计算所得到的黑色长方形方块的四个顶点四条边与该电子图像文件的四个顶点和四条边的距离,根据该距离确定该黑色长方形的相对坐标,并将所有的相对坐标之进行比对后去掉相同的坐标值,留下不同的坐标值,每个黑色长方形方块对应的不同坐标值就看做是其特征坐标值。
50.所述文字部分,如果该份档案文件是图片复印件,比如身份证、发票等,本身比较模糊难辨,同时由于复印时的放置位置不可能相同,因此计算与电子图像文件的四个顶点及四条边的距离没有参考价值。此时可以通过膨化、填充后,计算所得黑色长方形方块与图像本身四个顶点和四条边的距离已获得相对坐标值。所有图像文件所获得的相对坐标值比对去除相同部分后所得的坐标值即为其特征坐标值,档案整理人员扫描各种类型的标准版式档案,上传到识别系统中进行膨化填充处理,并记录保存下标准版式坐标,档案整理人员将纸质档案扫描成电子图像文件后上传至计算机相关文件夹,识别系统读取相关文件夹内电子图像文件,对图像文件的文字部分进行膨化填充处理,对膨化填充后的图像进行裁剪,将裁剪后获得的坐标与原本系统信息库中的坐标相比对,坐标相同的就是同一类型的档案,确定该档案类型后,调用标准版式档案模板,定为据模板所需信息的坐标点,匹配电子图像文件坐标点所对应的信息填写进标准版式档案模板,完成自动编目工作。
51.分类图形对应表包括档案类型,以及每种档案唯一对应的图形,分类图形对应表
包括分类图形印章,分类图形印章包含分类图形对应表中的所有图形。
52.在本发明的描述中,需要理解的是,术语“上”、“下”、“前”、“后”、“左”、“右”、等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
53.最后需要指出的是:以上实施例仅用以说明本发明的技术方案,而非对其限制。尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。