1.本发明属于城市监控视频检索技术领域,尤其涉及一种基于部件表征学习和个性化属性结构的车辆重识别方法。
背景技术:
2.随着社会治安网络视频监控系统的快速发展,视频监控数据也呈现了大批量的增长。研究高效的视频图像分析技术来满足从大规模视频监控数据中提取有效的信息,以此来节省治安防控的成本,已成为安防领域关注的焦点。例如警方在追踪肇事逃逸等违法犯罪活动的车辆时,面对的往往是海量的交通监控视频,通过手工方法的层层筛选,最终确定唯一的嫌疑车辆。然而这种手工方法无法对车辆信息进行有效的过滤并分类,效率不高,而且伴随着人为主观因素的影响,导致无法达到满意的效果,严重费时费力。因此,研究车辆重识别方法在车辆检索、安防等社会治安工作中具有重大的意义和实用价值。
3.车辆重识别是指在特定范围内的交通监控环境中,通过匹配算法计算非重叠范围内监控获取的车辆图像的身份是否相同的任务。该任务目前主要的问题在于类似车型类似颜色的近似样本问题和不同摄像头视角下的视角变换问题。传统的方法通常依赖于车辆行进路线上的各种传感器或感应器,车辆经过传感器时,通过捕捉车辆的时间信号、磁场信号等信息来区分不同车辆。然而这种传感器的方法重识别精度较低且难以实现。如今利用深度学习网络
[1-3]
通过输入的车辆图像进行特征提取,从而实现车辆重识别是专家学者的研究热点内容。
技术实现要素:
[0004]
针对现有技术存在的不足,本发明提供了一种基于部件表征学习和个性化属性结构的车辆重识别方法,该方法着眼于车辆重识别任务中的关键信息:部件外观信息和个性化属性结构信息。对于车辆的部件信息采用超分辨率的方法和多视角的对比学习的方法来进行表征学习,以增强车辆部件级的特征的鲁棒性和有效性。同时,提取车辆的属性特征并且挖掘部件和属性之间的双粒度结构关系。在部件分支中,首先通过车辆部件语义分割器获得车辆部件特征,然后引入自编码器来实现对部件特征的超分辨率处理,最后对于成对部件特征进行多视角下的对比学习。在属性分支中,首先通过属性检测器获得车辆的属性特征,然后对于属性特征进行属性结构建模进行加强,最后抽取部件特征与属性特征构建双粒度结构关系模型来使得属性特征具有跨粒度的车辆结构表达能力。对于车辆部件特征、属性特征以及由resnet50提取的全局特征进行加权融合后得到车辆重识别的最终结果。
[0005]
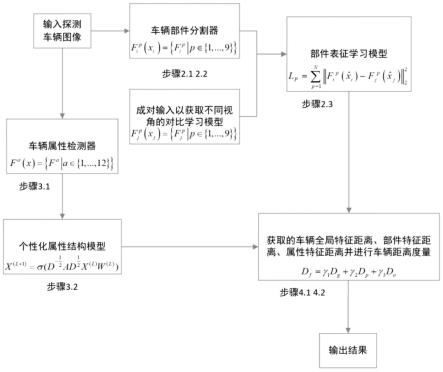
本发明所采用的技术方案是:一种摄像头网络下一种基于部件表征学习和个性化属性结构的车辆重识别方法,其特征在于对多个粒度的车辆特征以不同的方式进行加强,同时挖掘结构信息来帮助车辆重识别。系统框架图见附图2,其具体实现包括以下步骤:
[0006]
一种基于部件表征学习和个性化属性结构的车辆重识别,其特征在于,
[0007]
通过车辆部件分割器获得车辆部件特征,并对部件特征进行超分辨率处理,对于成对部件特征进行多视角下的对比学习,构建多视角下的车辆部件表征学习模型;
[0008]
在属性分支中,通过车辆属性检测器获得车辆的属性位置信息,将其与车辆特征相乘后获得车辆属性特征,并基于车辆属性特征构建属性结构模型;
[0009]
抽取车辆部件特征与属性特征构建双粒度结构关系模型,对全局特征、部件特征和属性特征加权融合后得到车辆重识别的最终结果。
[0010]
在上述的一种基于部件表征学习和个性化属性结构的车辆重识别,定义
[0011]
多摄像头下的车辆重识别:识别出在m 1个视场区域不重叠的摄像头组成的摄像机网络c中,某个摄像头cn下的某个特定车辆i用o
in
表示,c={c0,c1,c2,
…
,cm})。
[0012]
车辆部件:将车辆图片按照车辆的固有部件进行划分获得部件集p(表示为p={p0,p1,p2,
…
,p9}),具体指背景、车顶、左车窗、左车身、右车窗、右车身、正车窗、前车身、后车窗、后车身。其中排除背景p0后即为车辆的全部部件。
[0013]
车辆属性:对于车辆上极具个性化表达能力的小目标进行定义,获得车辆的属性集a(表示为a={a1,a2,a3,
…
,a
12
}),具体指后视镜,车牌标志,年检标志,车身贴纸,车灯、纸巾盒、装饰摆件、通行许可证、悬挂物、行李架、车顶天窗、杂志。
[0014]
同一车辆的确定:对车辆的全局特征、部件特征、属性特征进行余弦距离度量,对结果进行加权融合后得出相似度排序结果,实现车辆重识别。
[0015]
在上述的一种基于部件表征学习和个性化属性结构的车辆重识别,车辆的部件表征学习模型构建包括:
[0016]
网络接受一对不同视角下的车辆图像xi与xj,利用分割网络获取部件特征分别为f
ip
(xi)={f
ip
|p∈{1,...,9}}和
[0017]
车辆部件表征学习分支:双分支部件超分辨率网络来生成不同视角的和基于的id保留的车辆部件增强表征,为了在图像重建中恢复更多的视觉线索,使用了感知重建损失约束超分辨率网络,可表示为
[0018]
对于不同视角下的部件,利用成对输入的部件关系构建对比学习模型,将超分后的部件特征连接,在一定程度上避免了图像中全局信息的干扰,有效增强车辆部件表征,特征连接可表示为xi,分别表示第i个地面真值和经过超分辨率网络后的重建图像,表示vgg-19网络,利用该网络能够有效获取高维度特征,c
jhj
wj是网络中第j层特征图的形状。
[0019]
在上述的一种基于部件表征学习和个性化属性结构的车辆重识别,个性化属性结构模型构建包括
[0020]
车辆图片首先输入属性检测器来获得对应属性的位置信息,并且通过将掩码与全局特征相乘的方式获得车辆的属性特征,表示为fa(x)={fa|a∈{1,...,12}}。
[0021]
对于车辆的属性特征进行结构建模,不同的属性特征的集合作为结点v,属性之间的关联性则作为边e,从而构建了一个图模型。与此同时,属性结构图中还引入了一个两层
的图卷积神经网络gcn来进行结点之间的权重学习,每一层的计算方式为fa(x)
(l)
表示gcn中的第l层的输入矩阵,σ(
·
)表示激活函数,a表示属性结构图中的邻接矩阵,d表示a的度矩阵,w
(l)
表示第l层的可学习参数。
[0022]
将获得的车辆部件特征进行抽取,与属性特征聚合后进行双粒度结构关系建模。对于每个信道特征作为一个结点v,将每个结点代表的车辆属性或车辆部件之间的是否具有联系作为是否有边e的依据,以此构建一个双粒度结构关系图模型。此外,通过设计了一个异构的gcn网络来学习结点之间的权重学习。
[0023]
在上述的一种基于部件表征学习和个性化属性结构的车辆重识别,双粒度结构关系模型是对车辆的全局特征距离、部件特征距离、属性特征距离进行余弦距离度量,其中,
[0024]
对于通过resnet50对于车辆图片进行特征提取获得的车辆全局特征,获得的车辆部件特征以及获的车辆属性特征,分别进行余弦距离的计算,获得全局特征距离部件特征距离和属性特征距离
[0025]
对于车辆的全局特征距离、部件特征距离、属性特征距离以一定的权重进行融合得到最终的车辆特征距离根据的大小判断车辆的相似度完成车辆重识别任务。
[0026]
在上述的一种基于部件表征学习和个性化属性结构的车辆重识别,
[0027]
最终距离可表示为其中γ1、γ2、γ3为平衡不同粒度特征权重的超参数。
[0028]
在上述的一种基于部件表征学习和个性化属性结构的车辆重识别,
[0029]
对于属性结构图中的邻接矩阵a,用于表示两个不同属性结点之间是否有关联。对于a(i,j)来说,如果属性结点i与属性结点j有关联,则认为在图中这两个结点有边,即a(i,j)=1,反之则a(i,j)=0。
[0030]
在上述的一种基于部件表征学习和个性化属性结构的车辆重识别,
[0031]
部件特征和属性特征按照聚合时的信道进行保留,分别对应9和12个信道。
[0032]
对于双粒度图模型的输出只截取了属性特征对应的一部分信道。
[0033]
与现有车辆重识别方法与系统相比,本发明具有以下优点和有益效果:1、提出了一种全新的车辆部件表征学习方式;2、提出了一个全新的车辆属性特征提取模块和双粒度结构关系模块;3、提取了鲁棒的多粒度车辆外观特征,挖掘了车辆的跨粒度的结构关系信息,简洁高效地利用这些信息进行车辆重识别,在视角变换和车辆外观接近的情况下也能保持良好的表现。
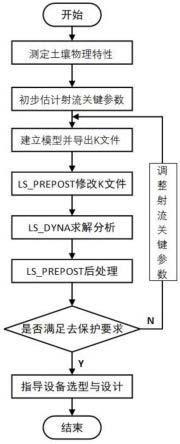
附图说明
[0034]
图1为本发明的系统流程图。
[0035]
图2为本发明的系统框架图。
[0036]
图3为本发明的验证实验结果图。
具体实施方式
[0037]
为了便于本领域普通技术人员理解和实施本发明,下面结合附图对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定
本发明。
[0038]
本发明提供了一种基于部件表征学习和个性化属性结构的车辆重识别方法,该方法着眼于车辆重识别任务中的关键信息:部件外观信息和个性化属性结构信息。对于车辆的部件信息采用超分辨率的方法和多视角的对比学习的方法来进行表征学习,以增强车辆部件级的特征的鲁棒性和有效性。同时,提取车辆的属性特征并且挖掘部件和属性之间的双粒度结构关系。在部件分支中,首先通过车辆部件语义分割器获得车辆部件特征,然后引入自编码器来实现对部件特征的超分辨率处理,最后对于成对部件特征进行多视角下的对比学习。在属性分支中,首先通过属性检测器获得车辆的属性特征,然后对于属性特征进行属性结构建模进行加强,最后抽取部件特征与属性特征构建双粒度结构关系模型来使得属性特征具有跨粒度的车辆结构表达能力。对于车辆部件特征、属性特征以及由resnet50提取的全局特征进行加权融合后得到车辆重识别的最终结果。
[0039]
框架图请见图2,本实施例在公共的数据集veri和vehicleid上进行测试。veri数据集包含20个摄像头下776个车辆的近50000张车辆图片,vehicleid包含在来自26267辆车的221763张图像。以下针对上述实例对本发明做进一步的阐述,本发明的流程包括:
[0040]
步骤一:
[0041]
几个定义
[0042]
①
多摄像头下的车辆重识别:识别出在m 1个视场区域不重叠的摄像头(表示为c={c0,c1,c2,
…
,cm})组成的摄像机网络c中,某个摄像头cn下的某个特定车辆i(用o
in
表示)。
[0043]
②
车辆部件:将车辆图片按照车辆的固有部件进行划分获得部件集p(表示为p={p0,p1,p2,
…
,p9}),具体指背景、车顶、左车窗、左车身、右车窗、右车身、正车窗、前车身、后车窗、后车身。其中排除背景p0后即为车辆的全部部件,这些部件在不同视角下的可视区域往往有极大的变化。
[0044]
③
车辆属性:对于车辆上极具个性化表达能力的小目标进行定义,获得车辆的属性集a(表示为a={a1,a2,a3,
…
,a
12
}),具体指后视镜,车牌标志,年检标志,车身贴纸,车灯、纸巾盒、装饰摆件、通行许可证、悬挂物、行李架、车顶天窗、杂志。这些车辆上的属性虽然区域较小,但是具有很强的辨识度,即使是相同车型的车辆也可以在这些属性上体现出车辆身份的异同。
[0045]
④
同一车辆的确定:
[0046]
本发明对车辆的全局特征、部件特征、属性特征进行余弦距离度量,对结果进行加权融合后得出相似度排序结果,实现车辆重识别。
[0047]
步骤二:
[0048]
车辆的部件表征学习模型
[0049]
1.网络接受一对不同视角下的车辆图像xi与xj,利用分割网络获取部件特征分别为f
ip
(xi)={f
ip
|p∈{1,}}.和
[0050]
2.车辆部件表征学习分支:双分支部件超分辨率网络来生成不同视角的和基于的id保留的车辆部件增强表征,为了在图像重建中恢复更多的视觉线索,使用了感知重建损
失约束超分辨率网络,可表示为
[0051]
3.对于不同视角下的部件,利用成对输入的部件关系构建对比学习模型,将超分后的部件特征连接,在一定程度上避免了图像中全局信息的干扰,有效增强车辆部件表征,特征连接可表示为
[0052]
步骤三:
[0053]
个性化属性结构模型
[0054]
1.车辆图片首先输入属性检测器来获得对应属性的位置信息,并且通过将掩码与全局特征相乘的方式获得车辆的属性特征,表示为fa(x)={fa|a∈{1,...,12}}。
[0055]
2.对于车辆的属性特征进行结构建模,不同的属性特征的集合作为结点v,属性之间的关联性则作为边e,从而构建了一个图模型。与此同时,属性结构图中还引入了一个两层的图卷积神经网络gcn来进行结点之间的权重学习,每一层的计算方式为
[0056]
3.将步骤二中获得的车辆部件特征进行抽取,与属性特征聚合后进行双粒度结构关系建模。对于每个信道特征作为一个结点v,将每个结点代表的车辆属性或车辆部件之间的是否具有联系作为是否有边e的依据,以此构建一个双粒度结构关系图模型。此外,通过设计了一个异构的gcn网络来学习结点之间的权重学习。
[0057]
步骤四:
[0058]
特征距离度量
[0059]
1.对于通过resnet50对于车辆图片进行特征提取获得的车辆全局特征,步骤二所述获得的车辆部件特征以及步骤三所述获的车辆属性特征,分别进行余弦距离的计算,获得全局特征距离部件特征距离和属性特征距离
[0060]
2.对于车辆的全局特征距离、部件特征距离、属性特征距离以一定的权重进行融合得到最终的车辆特征距离根据的大小判断车辆的相似度完成车辆重识别任务。
[0061]
本发明中所设计的内容均通过实验实例验证了有效性。
[0062]
对于步骤二中的车辆部件表征学习方式(lmrff lmrfe)的实验结果如下。
[0063]
表1与表2分别列出了在mlr-veri776数据集与vric数据集上基于特征融合和特征增强融合方法的map、rank-1和rank-5指标,同时为了更明显展示出网络各个模块对车辆重识别指标的影响,以mlr-veri776数据集为例,给出cmc曲线图如附图3所示。
[0064]
表1几种模型在mlr-veri776数据集上的准确率对比
[0065][0066]
表2几种模型在vric数据集上的准确率对比
[0067][0068]
表1中的fsrcnn-reid框架是将经典的超分辨率网络fsrcnn与车辆重识别框架融合,lmrff lmrfe融合框架与之相比,在mlr-veri776数据集与vric数据集上的map指标分别提高了17.4%与32.2%,rank-1指标分别提升了33.4%与41.6%。因而可知,将组件分割后的特征与全局融合,并通过特征增强,两个模块可以效地融合,快速提升多分辨率车辆重识别的精度。csr-gan、mv-gan均采用了生成对抗网络的方法,试图利用生成对抗网络生成高分辨率的车辆图像或者补充车辆的不可见视角,这些方法相较于简单得将超分辨率与重识别网络结合的框架而言,在vric数据集上csr-gan的rank-1指标提高了与3%,mv-gan虽然在map指标达到了67.3%,相较于其他方法有了一定的提升,属于近年较为领先的方法之一,但其指标仍然无法继续提升。由此可见,基于生成对抗网络的方法在多分辨率场景下仍然存在一定的瓶颈,导致生成的高分辨率图像包含伪影,在一定程度上影响重识别的精度。与特征融合方法相比较,本发明的融合方法lmrff lmrfe在一定程度上弥补了精度下降的问题,在map的指标有了大幅提升,达到了63.2%,体现本发明基于组件超分辨率特征增强的先进性,两个模块相辅相成,共同促进网络参数优化。
[0069]
对于步骤三中设计的车辆属性特征提取模块和双粒度结构关系模块(gsan)的实验结果如下。
[0070]
在vehicleid数据集上,本发明对于最终设计的gsan模型进行了训练并分别在small(test=800)、medium(test=1600)、large(test=2400)三个测试集上进行了实验。实验结果与主流的车辆重识别方法的比较如表3、4、5所示,其中对每项指标中的最高值进行了加粗,对于次高值则用蓝色表示。
[0071]
表3在vehicleid small(test=800)上与主流方法的比较
[0072]
[0073][0074]
表4在vehicleid medium(test=1600)上与主流方法的比较
[0075][0076]
表5在vehicleid large(test=2400)上与主流方法的比较
[0077][0078]
根据对于上述实验结果及对比结果的分析可知,本发明提出的方法gsan在vehicleid small测试集上与主流的方法相比,比如multi-scale和pcrnet,我们的方法在rank-1上提升了2.4%,在rank-5上提升了0.4%,在map上提升了1.2%。在对于vehicleid medium的测试中,gsan的表现在map上比multi-scale提升了1.5%,在rank-1上比baseline提升了1.6%,在rank-5上提升了1.3%。在vehicleid large测试集中的表现则是在map上略低于最先进的方法mvan,在rank-1上提升了2.4%,在rank-5提升了1.6%。mvan是一种基于视角注意力的车辆重识别方法,它将车辆分为前、侧、后三个可视区域,用视角注意力机
制来调整三个区域特征的权重。mvan虽然在map上略高于我们的方法,但是在rank-1和rank-5上的指标远低于我们的方法,由此可见我们的方法的性能更全面,更能满足车辆重识别的任务需求。
[0079]
在veri-776数据集上,gsan模型经过训练,测试结果与主流方法的对比如表6所示。其中对每项指标中的最高值进行了加粗,对于次高值则用蓝色表示。
[0080]
从表中的数据分析可知,gsan在map上比mvan低0.3%,在rank-1上比vcam低1.2%,在rank-5上比mvan低0.7%。mvan方法和vcam方法都对于视角变化进行了专门的注意力机制的设计,而在veri-776数据集中,视角变化的问题尤其显著,mvan和vcam中设计的方法更适合解决这类问题。与此同时,veri-776数据集中车辆图片本身可获取的属性信息的辨识度和分布率都较低,对于我们的方法的奏效产生了一定的限制作用。然而,即使如此,综合来说gsan仍然可以在veri-776上获得不错的实验指标,这也进一步的验证了我们的方法的先进性。
[0081]
3.表6在veri-776上与主流方法的比较
[0082][0083]
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
[0084]
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。