1.本发明属于医学图像分析及人工智能技术领域,本发明涉及一种基于异构交叉伪监督网络的半监督医学图像分割方法。
背景技术:
2.随着医学成像技术的进步与全球推广,医学图像数据的增长速度远远快于现有的人类专家所能处理的速度。在过去数年中,基于深度学习医学图像分割技术已成为医学领域的研究热点,该技术极大地提升了医学图像分割工作的效率。医学图像的标注工作都需要医学专家手动标记,图像分割效果的好坏跟专家的经验和水平紧密相关,高质量的标注数据往往规模较小,这种困境使得对标注数据依赖程度较低的半监督分割技术的研究迫在眉睫。半监督图像分割追求高效率利用小量标记数据和大量无标记数据以达到更好的分割效果,使用半监督分割方法能有效削减人力成本,同时又能够提高医学图像分割的准确性。
3.近年来,在医学图像分割领域中,transformer备受关注,但transformer及其变种都依赖大规模的训练数据集,因此在小样本分割上往往表现不佳。已有的半监督方法的研究大多基于cnn网络,例如unet及其变种,并且在医学图像分割领域取得了不错的效果。然而cnn网络通过卷积、池化等操作捕捉局部特征,但不关注全局特征的学习,在标记数据有限的情况下对图像分割全部特征捕捉。
技术实现要素:
4.本发明针对上述的不足之处提供一种能够在标记数据有限的情况下达到较好的分割效果的半监督医学图像分割方法。
5.本发明目的是这样实现的:一种基于异构交叉伪监督网络的半监督医学图像分割方法,其特征在于:所述该方法包括以下步骤:
6.步骤1:收集样本,标注标签,按照5:1的比例将数据集随机划分为训练集和测试集,通过随机裁剪、水平翻转、旋转的方式进行数据增强;
7.步骤2:搭建hcps网络模型;
8.步骤3:在训练集上对hcps网络进行训练,执行分割任务并生成分割模型;
9.步骤4:通过训练集上测试模型,根据测试结果,选择最优的模型为最终模型,并保存用于图像的分割。
10.优选的,所述步骤1中的数据增强的方法如下:
11.采用随机裁剪,直接裁剪处出固定大小的影像输入网络;
12.在-25度和25度之间随机旋转;
13.取概率p为0.5随机抽取训练数据进行随机翻转。
14.优选的,所述步骤2中搭建hcps网络模型,hcps网络模型选用交叉伪监督策略来作为基本网络框架;所述hcps网络模型包括unet和swin-unet,使用unet和swin-unet进行特征提取和还原,最终输出目标的预测图。
15.优选的,所述swin-unet的下采样采用移位图块标记化模块。
16.优选的,所述hcps网络模型中cps中添加置信度评价模块,抑制质量不稳定的伪标签对网络训练效果的影响。
17.优选的,所述移位图块标记化模块的结构为:
18.在图像输入时和下采样阶段将输入图像向左上、左下、右上、右下4个方向移位半个图像块尺寸(patch-size),然后将移位后的图像与输入图像级联;
19.将图块分割,然后依次执行图块展平、层归一化和线性投影三个操作,最终将图像转化为视觉符号供网络训练。
20.优选的,所述置信度评价模块结构为:
21.置信度评价模块的核心思想是:两种网络产出的伪标签越是相似,该伪标签往往质量越高;基于这种假设,选取kl散度作为衡量伪标签之间相似度的标准,计算公式如下:
[0022][0023]
在公式(1)中,p(x)和q(x)分别是两个网络产生的伪标签,x是伪标签像素的集合,l
kl
是两者的kl散度。
[0024]
优选的,所述hcps网络模型采用有监督方式和无监督方式,有监督方式采用交叉熵损失函数,无监督方式采用dice损失函数。
[0025]
与现有技术相比,本发明的有益效果:1、通过采用hcps网络模型,将hcps网络模型中unet与swin-unet组合进行交叉伪监督学习,提升网络的训练效率和分割效果,同时根据unet与swin-unet组合进行交叉伪监督学习,提高全局特征的捕捉能力和局部捕捉能力,充分利用有的标注数据以达到令人满意的分割效果。
[0026]
2、采用置信度评价模块来调控网络的伪监督损,提高网络中伪监督损失的置信度,置信度评价模块赋予了网络自适应调控伪监督损失权重的能力,大幅降低了伪标签质量不稳定对网络训练造成的影响。
附图说明
[0027]
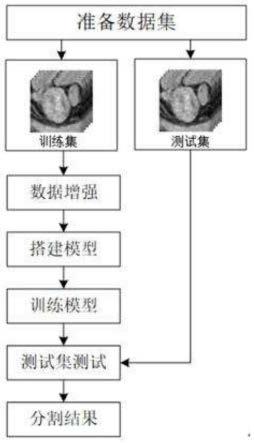
图1为本发明的方法流程图。
[0028]
图2为hcps的网络图。
[0029]
图3为位图块标记化模块的结构。
[0030]
图4为fcrb-u-net的实例分割效果图。
具体实施方式
[0031]
以下结合附图对本发明做进一步概述。
[0032]
如图1所示,一种基于异构交叉伪监督网络的半监督医学图像分割方法,包括以下步骤:
[0033]
步骤1:收集样本,标注标签,按照5:1的比例将数据集随机划分为训练集和测试集,通过随机裁剪、水平翻转、旋转的方式进行数据增强;
[0034]
数据增强的方法如下:
[0035]
采用随机裁剪,直接裁剪处出固定大小的影像输入网络;
[0036]
在-25度和25度之间随机旋转;
[0037]
取概率p为0.5随机抽取训练数据进行随机翻转。
[0038]
步骤2:搭建hcps网络模型;
[0039]
hcps网络模型选用交叉伪监督策略来作为基本网络框架;所述hcps网络模型包括unet和swin-unet,使用unet和swin-unet进行特征提取和还原,最终输出目标的预测图。
[0040]
hcps网络模型采用有监督方式和无监督方式,有监督方式采用交叉熵损失函数,无监督方式采用采用dice损失函数;将unet和swin-unet以交叉伪监督策略组合进行交叉学习。
[0041]
交叉熵损失函数为:
[0042][0043]
式中,c表示所需计算的对象拥有的类别数,p(i)和q(i)即为计算对象。
[0044]
dice损失函数为:
[0045][0046]
式中,l
dice
即是dice损失,a和b是以集合形式表示的计算对象。
[0047]
通过计算每个样本的dice再求平均,根据平均dice的数值判断模型的优劣。
[0048]
在swin-unet中嵌入移位图块标记化模块以增加输入图像包含的空间信息,在交叉伪监督策略中加入置信度评价模块以提升网络性能。
[0049]
进一步,标记化模块的结构为:
[0050]
在图像输入时和下采样阶段将输入图像向左上、左下、右上、右下4个方向移位半个图像块尺寸(patch-size),然后将移位后的图像与输入图像级联;
[0051]
将图块分割,然后依次执行图块展平、层归一化和线性投影三个操作,最终将图像转化为视觉符号供网络训练。
[0052]
置信度评价模块结构为:
[0053]
置信度评价模块的核心思想是:两种网络产出的伪标签越是相似,该伪标签往往质量越高;基于这种假设,选取kl散度作为衡量伪标签之间相似度的标准,计算公式如下:
[0054][0055]
在公式(4)中,p(x)和q(x)分别是两个网络产生的伪标签,x是伪标签像素的集合,l
kl
是两者的kl散度。
[0056]
当kl散度较大时,对应的伪标签是低质量的,这时候网络中伪监督损失的置信度也降低,反之,网络中伪监督损失的置信度升高。置信度评价模块赋予了网络自适应调控伪监督损失权重的能力,大幅降低了伪标签质量不稳定对网络训练造成的影响。
[0057]
步骤3:在训练集上对hcps网络进行训练,执行分割任务并生成分割模型;
[0058]
步骤4:通过训练集上测试模型,根据测试结果,选择最优的模型为最终模型,并保存用于图像的分割。
[0059]
通过与其他方法的比较,可以验证本发明所提出的方法性能明显优于其他的卷积
神经网络的算法。其中,swin-unet采用全监督,其他方法采用半监督,有标记数据与无标记数据比例为8:72。
[0060]
表1语义分割模型实验结果比较
[0061]
modellabeled:unlabeleddicejaccardhd95asdswin-unet80:00.86300.73327.43.51mt8:720.83040.725515.213.85ua-mt8:720.84250.734813.843.36dtc8:720.86570.765514.473.74本发明方法8:720.89230.80677.512.21
[0062]
观察表1的数据不难发现,我们的方法在有标记数据量仅为总数据量的10%时,我们的方法表现出了强大的性能,具体体现在我们的方法在四项指标上超出其余半监督方法,且dice指标比第二名高出2.66%,比swin-unet全监督高出2.93%。显然我们的方法能在标记数据极为有限的情况下达到令人满意的分割效果。
[0063]
以上所述仅为本发明的实施方式而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理内所作的任何修改、等同替换、改进等,均应包括在本发明的权利要求范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。