1.本发明涉及机器学习技术领域,具体涉及一种高效的矩阵乘运算加速装置及方法。
背景技术:
2.人工神经网络(artificial neutral networks)通过模拟动物神经网络行为,以神经元与网络互连为基础构建数学算法模型,进行分布式信息处理,实现机器学习功能,广泛应用于语音处理、图像识别、计算机视觉、自然语言处理和交叉学科等人工智能领域。人工神经网络包括多层感知机(multi-layer perceptron,mlp)、卷积神经网络(convolutional neural network)和循环神经网络(recurrent neural network,rnn)等多种经典模型,这些模型由多层神经网络组成,每层网络包含大量的卷积与矩阵乘运算,无论是训练还是推理,均需要计算机提供超高的计算能力与硬件加速架构以支持人工智能加速。
3.采用脉动阵列(systolic array)加速矩阵乘或卷积运算是一种可行的方式,脉动阵列为二维运算结构,以数据流驱动方式实现运算加速。脉动阵列各个处理单元(processing element,pe)可以在相邻pe间传输数据,通过数据重用,减少对输入/输出数据的存取次数,进而降低访存带宽需求。脉动阵列可以在较小的访存带宽下实现较高的运算吞吐率,解决多数处理器面临的访存瓶颈问题,特别是在神经网络这种高密集型计算和访存的处理中应用优势明显。
4.现有技术比较经典的是tpu(tensor processing unit)处理器,面向卷积运算加速,应用于人工智能推理。tpu的核心是矩阵计算单元,采用256*256,二维cell数量,超大脉动阵列,每个cell支持8*8 16的定点运算。预先对数据格式进行转换,卷积核经过旋转,转换成矩阵对应脉动阵列的行输入数据,激活activation数据经过重组,转换成矩阵向量对应脉动阵列的列输入。权重weight数据,卷积核kernel,沿列自上而下流动,激活activation数据,图片或语音数据,沿行从左至右流动,在cell单元中进行乘法,并与上方cell传输下来的加法结果求和后,乘加结果沿列从上往下流动。其中,权重数据通过权重定序器确定在cell中的流动方式以及在最下方对应每列cell有一个累加单元,用于执行最后一行cell输出的乘加结果累加,并保存中间结果,以实现矩阵乘法或卷积运算。
5.tpu利用脉动阵列对卷积运算进行加速,存在以下缺点:1、面向推理,运算精度低,运算模式单一;2、权重与激活数据同时流动,可重用性低。tpu主要面向推理,支持推理全流程加速,而推理相比训练对运算精度要求不高,采用8位定点运算实现单个cell乘加即可满足要求,而训练对数据处理精度要求相对较高,一般需要采用16位定点或者半精度浮点运算进行加速。因此,tpu运算模式单一,灵活性和可适用性性差;运算精度较低,不适用于训练加速。基于二维脉动阵列实现的tpu,卷积运算加速过程中,权重与激活数据分别沿列自上而下、沿行从左至右同时传输,数据可重用性低,特别是在神经网络训练过程中,卷积运算存在权重数据可以大量重用特性,即同一个卷积核可以重复使用多次,对多个激活数据
矩阵进行滑动卷积。
6.因此,有必要继续研究提高矩阵乘运算效率的技术。
技术实现要素:
7.本发明所要解决的技术问题:目前矩阵乘法运算效率低的技术问题。提出了一种高效的矩阵乘运算加速装置及方法,能够进一步提高矩阵乘法运算的效率,提高机器学习的效率。
8.解决上述技术问题,本发明采用如下技术方案:一种高效的矩阵乘运算加速装置,包括矩阵乘法加速单元、北向数据加载器、西向数据整形与加载器、累加缓冲器、累加结果写回控制器和本地局部存储器,
9.矩阵乘法加速单元包括呈二维脉动阵列排列的矩阵乘法加速核心,所述矩阵乘法加速核心包括运算单元和数据调度单元,相邻矩阵乘法加速核心之间由数据调度单元建立数据交换通道,矩阵乘法加速单元通过北向数据加载器从所述本地局部存储器获取北向数据,所述北向数据为卷积核,所述北向数据在矩阵乘法加速单元中由数据调度单元调度从北向南依次流动,所述西向数据整形与加载器从本地局部存储器获取西向数据并整形,所述西向数据为图片矩阵,所述西向数据在矩阵乘法加速单元中由数据调度单元调度从西向东依次流动,所述北向数据及西向数据在流动过程中,所述矩阵乘法加速核心的运算单元进行乘加运算,乘加结果由北向南传输并最终输入至累加缓冲器,所述累加缓冲器进行累加并暂存中间结果,全部运算结束后,所述累加结果写回控制器将所述累加缓冲器内的累加结果写入本地局部存储器进行存储。
10.作为优选,所述累加缓冲器包括若干个缓存器,每个缓存器对应所述矩阵乘法加速单元的一列。
11.作为优选,所述矩阵乘法加速核心的数据调度单元包括北向数据影子寄存器、北向数据寄存器、累加数据寄存器、北向更新使能寄存器、西向数据寄存器和运算模式配置信号线,所述北向数据影子寄存器与北向数据加载器或者北侧数据调度单元的北向数据影子寄存器连接,所述北向数据寄存器与北向数据影子寄存器连接,所述北向更新使能寄存器与北向数据寄存器连接,同一行北向更新使能寄存器相互连接,所述西向数据寄存器与同一行所述运算模式配置信号线与运算单元连接,同一行西向数据寄存器相互连接,所述运算单元与西向数据寄存器、北向数据寄存器及累加数据寄存器连接,所述运算单元的计算结果输入南侧矩阵乘法加速核心的累加数据寄存器。
12.作为优选,所述矩阵乘法加速核心的运算单元包括乘法器和加法器,所述乘法器将北向数据寄存器和西向数据寄存器内的数据相乘获得乘积,所述加法器将所述乘积与累加数据寄存器的数据相加获得和,所述加法器将所述和输入南侧矩阵乘法加速核心的累加数据寄存器。
13.一种高效的矩阵乘运算加速方法,使用如前述的一种高效的矩阵乘运算加速装置,包括以下步骤:
14.步骤1)配置运算模式,设置运算单元的运算精度配置;
15.步骤2)北向数据加载器预加载北向数据,将北向数据加载到相应的矩阵乘法加速核心的北向数据影子寄存器中;
16.步骤3)西向数据整形与加载器加载携带北向数据更新使能的西向数据,使西向数据流动至对应的矩阵乘法加速核心时,能够将对应矩阵乘法加速核心的北向数据影子寄存器中的北向数据加载至北向数据寄存器;
17.步骤4)运算单元实现乘法运算,将乘法运算结果与累加数据寄存器求和后,将和传输至南侧累加数据寄存器;
18.步骤5)西向数据整形与加载器加载再次加载西向数据,同时北向数据加载器再次预加载北向数据至北向数据影子寄存器;
19.步骤6)不断重复步骤4)至步骤5),直到全部西向数据被加载并流动完成;
20.步骤7)累加结果写回控制器读取累加缓冲器内的数据,即为矩阵乘法结果,并矩阵乘法结果回写至本地局部存储器存储。
21.作为优选,在步骤3)中,西向数据整形与加载器对西向数据进行整形,整形方法为将西向数据的每行数据向左移动n-1列,n为行序号。
22.作为优选,所述运算单元的运算精度配置包括:半精度浮点混合乘加模式、半字定点混合乘加模式和双字节定点混合乘加模式。
23.作为优选,当矩阵乘法加速单元用于训练时,将运算单元的运算精度配置为半精度浮点混合乘加模式,当矩阵乘法加速单元用于预测时,将运算单元的运算精度配置为双字节定点混合乘加模式。
24.本发明的有益技术性效果包括:1)北向数据可以预加载,掩盖延迟,北向数据可以在西向数据流动时预先加载,通过影子寄存器传输,掩盖北向数据加载延迟,而不必等到北向数据加载完毕再流动西向数据,在西向数据流驱动运算的同时预加载北向数据,充分发挥加速性能;2)固定北向数据,增加数据重用性,由于北向数据可以预先加载,锁存至对应北向数据影子寄存器中,西向数据携带北向数据更新使能从西向东流动,北向更新使能到达运算单元后将影子寄存器中的数据更新至北向数据寄存器后锁存不动,通过加载多轮西向数据实现卷积运算和矩阵乘法运算加速,充分利用卷积核的可重用性,减少了北向数据的重复读取和无效缓存,降低缓存带宽需求;3)减少数据流动,降低功耗,由于北向数据固定缓存在北向数据影子寄存器中,利用数据可重用性减少流动,包括北向数据的重复读取和无效缓存,减少了本地局部存储器存取操作和寄存器锁存,降低了功耗,矩阵乘法加速单元的阵列规模越大,效果越明显。
25.本发明的其他特点和优点将会在下面的具体实施方式、附图中详细的揭露。
附图说明
26.下面结合附图对本发明做进一步的说明:
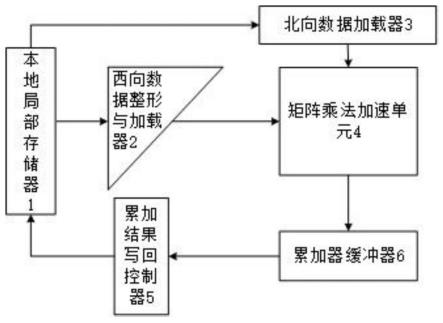
27.图1为本发明实施例的矩阵乘运算加速装置结构示意图。
28.图2为本发明实施例的矩阵乘法加速单元结构示意图。
29.图3为本发明实施例的矩阵乘法加速核心结构示意图。
30.图4为本发明实施例进行矩阵乘运算示意图。
31.图5为本发明实施例进行矩阵乘运算过程示意图。
32.图6为本发明实施例矩阵乘运算加速方法流程示意图。
33.其中:1、本地局部存储器,2、西向数据整形与加载器,3、北向数据加载器,4、矩阵
乘法加速单元,5、累加结果写回控制器,6、累加缓冲器,41、北向数据影子寄存器,42、北向数据寄存器,43、累加数据寄存器,44、北向更新使能寄存器,45、运算模式配置信号线,46、西向数据寄存器,47、乘法器,48、加法器。
具体实施方式
34.下面结合本发明实施例的附图对本发明实施例的技术方案进行解释和说明,但下述实施例仅为本发明的优选实施例,并非全部。基于实施方式中的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得其他实施例,都属于本发明的保护范围。
35.在下文描述中,出现诸如术语“内”、“外”、“上”、“下”、“左”、“右”等指示方位或者位置关系仅是为了方便描述实施例和简化描述,而不是指示或暗示所指的装置或者元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
36.名称解释:矩阵乘法加速单元(matrix multiply accelerating unit,简称mmau)、北向数据加载器、西向数据整形与加载器、累加器缓冲器(accumulation buffer,简称acmb)、累加结果写回控制器和本地局部存储器(local data memory,简称ldm)、运算单元(computing unit,简称cu)。
37.本实施例所称北向和西向,以矩阵的上北下南及左西右东进行明确。
38.一种高效的矩阵乘运算加速装置,请参阅附图1,包括矩阵乘法加速单元4、北向数据加载器3、西向数据整形与加载器2、累加缓冲器6、累加结果写回控制器5和本地局部存储器1,请参阅附图2,矩阵乘法加速单元4包括呈二维脉动阵列排列的矩阵乘法加速核心,矩阵乘法加速核心包括运算单元和数据调度单元,相邻矩阵乘法加速核心之间由数据调度单元建立数据交换通道,矩阵乘法加速单元4通过北向数据加载器3从本地局部存储器1获取北向数据,北向数据为卷积核,北向数据在矩阵乘法加速单元4中由数据调度单元调度从北向南依次流动,西向数据整形与加载器2从本地局部存储器1获取西向数据并整形,西向数据为图片矩阵,西向数据在矩阵乘法加速单元4中由数据调度单元调度从西向东依次流动,北向数据及西向数据在流动过程中,矩阵乘法加速核心的运算单元进行乘加运算,乘加结果由北向南传输并最终输入至累加缓冲器6,累加缓冲器6进行累加并暂存中间结果,全部运算结束后,累加结果写回控制器5将累加缓冲器6内的累加结果写入本地局部存储器1进行存储。累加缓冲器6包括若干个缓存器,每个缓存器对应矩阵乘法加速单元4的一列。
39.请参阅附图3,矩阵乘法加速核心的数据调度单元包括北向数据影子寄存器41、北向数据寄存器42、累加数据寄存器43、北向更新使能寄存器44、西向数据寄存器46和运算模式配置信号线45,北向数据影子寄存器41与北向数据加载器3或者北侧数据调度单元的北向数据影子寄存器41连接,北向数据寄存器42与北向数据影子寄存器41连接,北向更新使能寄存器44与北向数据寄存器42连接,同一行北向更新使能寄存器44相互连接,西向数据寄存器46与同一行运算模式配置信号线45与运算单元连接,同一行西向数据寄存器46相互连接,运算单元与西向数据寄存器46、北向数据寄存器42及累加数据寄存器43连接,运算单元的计算结果输入南侧矩阵乘法加速核心的累加数据寄存器43。
40.矩阵乘法加速核心的运算单元包括乘法器47和加法器48,乘法器47将北向数据寄存器42和西向数据寄存器46内的数据相乘获得乘积,加法器48将乘积与累加数据寄存器43的数据相加获得和,加法器48将和输入南侧矩阵乘法加速核心的累加数据寄存器43。
41.请参阅附图4和附图5,为一个4*4脉动阵列的实例,西向数据为4*4图片矩阵x,北向数据为4个2*2的卷积核a、b、c、d。
42.西向数据为:
43.北向数据为:
44.t0~t4为各时钟周期下数据流图,右侧的为脉动阵列运算单元缓存数据,左侧为整形缓冲中缓存的整形后的西向数据:
45.在t0时钟周期完成北向数据加载,即将各个卷积核按列预先加载到mmau各cu的北向数据影子寄存器41中,随后固定保持不变;
46.在t1时钟周期,经过整形后的西向数据x00传输至mmau的西北角cu,同时与更新的北向数据a00完成乘法运算,得到乘法结果a00*x00并传输给南侧cu;
47.在t2时钟周期,西向数据x01和x10传输至mmau的最西侧一列的最北两个cu,其中x01与a01完成乘法运算,x10与a01完成乘法运算并实现与北侧cu传输进来t1时钟周期的计算结果a00*x00进行累加得到累加结果a00*x00 a01*x01;同时,西向数据x00传输到b00北向数据cu,并完成乘法运算,将结果x00*b00传输往南侧cu传输;
48.依次类推
…
49.直至t4时钟周期,x10/x03/x11/x11西侧数据传输至mmau最西侧一列cu,在西南角cu内完成乘加运算得到累加结果a11*x11 (a00*x00 a01*x01 a0*x11),其中括号内结果为北侧cu传入的中间累加结果,至此,完成了卷积核a与x左上角2*2分块矩阵的卷积操作第一个元素y00的计算:
50.一种高效的矩阵乘运算加速方法,使用如前述的一种高效的矩阵乘运算加速装置,请参阅附图6,包括以下步骤:
51.步骤1)配置运算模式,设置运算单元的运算精度配置;
52.步骤2)北向数据加载器3预加载北向数据,将北向数据加载到相应的矩阵乘法加速核心的北向数据影子寄存器41中;
53.步骤3)西向数据整形与加载器2加载携带北向数据更新使能的西向数据,使西向数据流动至对应的矩阵乘法加速核心时,能够将对应矩阵乘法加速核心的北向数据影子寄存器41中的北向数据加载至北向数据寄存器42;
54.步骤4)运算单元实现乘法运算,将乘法运算结果与累加数据寄存器43求和后,将和传输至南侧累加数据寄存器43;
55.步骤5)西向数据整形与加载器2加载再次加载西向数据,同时北向数据加载器3再次预加载北向数据至北向数据影子寄存器41;
56.步骤6)不断重复步骤4)至步骤5),直到全部西向数据被加载并流动完成;
57.步骤7)累加结果写回控制器5读取累加缓冲器6内的数据,即为矩阵乘法结果,并
矩阵乘法结果回写至本地局部存储器1存储。
58.在步骤3)中,西向数据整形与加载器2对西向数据进行整形,整形方法为将西向数据的每行数据向左移动n-1列,n为行序号。
59.运算单元的运算精度配置包括:半精度浮点混合乘加模式、半字定点混合乘加模式和双字节定点混合乘加模式。半精度浮点混合乘加模式为:16位半精度*16位半精度 32位单精度浮点,结果为32位单精度浮点。半字定点混合乘加模式为:16位半字定点*16位半字定点 32位字定点,结果为32位字定点。双字节定点混合乘加模式为:可同时执行两个:8位字节定点*8位字节定点 16位半字定点,结果为两个16位半字定点。
60.当矩阵乘法加速单元4用于训练时,将运算单元的运算精度配置为半精度浮点混合乘加模式,当矩阵乘法加速单元4用于预测时,将运算单元的运算精度配置为双字节定点混合乘加模式。
61.本实施例的有益技术性效果包括:1)北向数据可以预加载,掩盖延迟,北向数据可以在西向数据流动时预先加载,通过影子寄存器传输,掩盖北向数据加载延迟,而不必等到北向数据加载完毕再流动西向数据,在西向数据流驱动运算的同时预加载北向数据,充分发挥加速性能;2)固定北向数据,增加数据重用性,由于北向数据可以预先加载,锁存至对应北向数据影子寄存器41中,西向数据携带北向数据更新使能从西向东流动,北向更新使能到达运算单元后将影子寄存器中的数据更新至北向数据寄存器42后锁存不动,通过加载多轮西向数据实现卷积运算和矩阵乘法运算加速,充分利用卷积核的可重用性,减少了北向数据的重复读取和无效缓存,降低缓存带宽需求;3)减少数据流动,降低功耗,由于北向数据固定缓存在北向数据影子寄存器41中,利用数据可重用性减少流动,包括北向数据的重复读取和无效缓存,减少了本地局部存储器1存取操作和寄存器锁存,降低了功耗,矩阵乘法加速单元4的阵列规模越大,效果越明显。
62.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,熟悉该本领域的技术人员应该明白本发明包括但不限于附图和上面具体实施方式中描述的内容。任何不偏离本发明的功能和结构原理的修改都将包括在权利要求书的范围中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。