1.本发明涉及受电弓磨耗检测领域,具体涉及一种受电弓滑板磨耗预测方法。
背景技术:
2.随着铁路的快速发展,对铁路运输安全管理提出了更高的要求。其中,受电弓滑板的磨损情况一直是铁路安全运输的重要参数,当受电弓滑板磨损严重时,会引起受电弓卡网、拉网等故障,为此,需要对受电弓滑板的磨耗值进行监测。现有的受电弓磨耗监测系统,采用激光测量、超声测量、图像测量等技术手段,对受电弓滑板的厚度值进行的测量,当检测到滑板磨耗值高于阈值时,监测系统发出超限警报、提示运维人员存在安全风险,该技术方案存在以下问题:
3.为了列车的行驶安全,系统的报警限界往往会低于检测规程中的滑板磨损限界值,也就是说,磨耗值的阈值设置过低。所以在监测系统发出超限警报后,受电弓滑板的磨耗值程度还不是很高,没有达到需要更换的程度,什么时候需要更换受电弓,只能依据列车运维人员的人工经验预判,若在人工经验不足的情况下,将会过早更换受电弓,不利于受电弓的养护和替换,造成物料的浪费,还会增加维修人员的工作量。
4.针对以上不足,技术人员提出了受电弓滑板磨耗值预测方法,用于辅助列车运维人员判断受电弓的维修、更换时间,其中,论文:滑板磨耗对受电弓系统服役性能的影响研究,宋冬利等人提出了以下方案:实测滑板磨耗形面数据,研究了以形面数据的滑板磨耗数字化表征及磨耗规律,提出以二次函数描述滑板磨耗形面,给出形面形状参数和磨耗深度参数两个特征量,并获得了特征量随运行时间的变化规律。该方法是通过观察实验数据后,假设滑板磨耗曲线呈二次分布规律,所以预测结果限制较大,建立的磨耗预测模型可复用性较差,无法拓展至车次不同、型号不同的受电弓磨耗预测中。论文:基于多核lssvr受电弓磨耗趋势预测的研究,作者徐文文在受电弓滑板厚度测量的基础上,采用多核最小二乘支持向量机对受电弓的磨耗趋势进行预测。虽然预测精度较为可靠,但是,由于支持向量是线性模型,因此预测输入变量较少,未将平均车速、受电弓类型等关键信息作为输入变量,建立的预测模型较为简单,考虑情况少,而实际列车检修中的关联因素多,因此该模型预测较为理想化,准确程度欠佳,难以在实际列车检修中推广应用,并且影响受电弓滑板磨耗的变量众多,lssvr模型超参数确定困难,预测模型泛化能力有所缺乏。类似的,专利文件cn112613234a-一种受电弓滑板磨耗趋势估算及寿命预测方法及装置,也利用了支持向量机作为预测模型,同样存在输入参数少,预测准确率受限的问题。
技术实现要素:
5.为了解决上述技术问题,本发明提供一种受电弓滑板磨耗预测方法,旨在解决列车实际运行中受电弓磨耗程度难以智能化评估的问题,本方法基于超限学习机模型(elm)利用多参数对受电弓滑板磨耗进行有效预测,超限学习机模型(elm)作为一种非线性模型,可输入多个影响磨耗的关联参数,使得预测结果更加合理、准确率高,进而提高列车运维的
安全性和经济性。
6.技术方案如下:
7.一种受电弓滑板磨耗预测方法,利用以下步骤训练受电弓滑板磨耗的预测模型:
8.s1、获取受电弓滑板磨耗的历史数据,将其划分为训练集和测试集;
9.所述历史数据包括多个磨耗样本;单个磨耗样本包含受电弓的使用参数以及在该使用参数下的磨耗值;所述受电弓的使用参数为:影响受电弓滑板磨耗程度的关联参数;
10.s2、利用训练集对超限学习机预测模型进行训练;
11.再根据测试集验证训练后超限学习机预测模型的准确率;
12.s3、判断准确率是否超过阈值,若是,预测模型训练完成;
13.若否,增加训练集的数量或者修改超限学习机预测模型的初始参数,对超限学习机预测模型进行再次训练,直到准确率超过阈值,完成预测模型训练;
14.保存预测模型;
15.将待测的受电弓使用参数输入到预先存储的预测模型中,预测模型输出该受电弓滑板的磨耗值,完成对磨耗值的预测。
16.进一步,受电弓的使用参数包括至少两个影响受电弓滑板磨耗程度的关联参数。
17.优选,受电弓的使用参数包括受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、列车运行平均速度、列车车型、受电弓滑板的初始厚度、弓网接触力、受电弓标准长度和受电弓倾角中的至少两个参数。
18.优选,受电弓的使用参数为以下形式中的任意一种:
19.形式一:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、受电弓滑板的初始厚度、弓网接触力、受电弓标准长度、受电弓倾角、列车运行平均速度和列车车型;
20.形式二:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、受电弓滑板的初始厚度、弓网接触力、受电弓标准长度和受电弓倾角;
21.形式三:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、滑板数量、受电弓滑板的初始厚度、弓网接触力、列车运行平均速度和列车车型;
22.形式四:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、受电弓滑板的初始厚度、弓网接触力和列车运行平均速度;
23.形式五:受电弓滑板测量位置、受电弓累计使用时间、受电弓滑板的初始厚度、弓网接触力和列车运行平均速度。
24.进一步,步骤s2中,利用训练集对超限学习机预测模型进行训练的方式为:
25.1)将训练集等分成k个集合;任选1~0.3k个集合记为集合a;
26.2)随机为预测模型中的隐含层数量l、每层神经元数量r赋初值;
27.利用除集合a以外的其他集合,对预测模型进行训练,将训练后的模型记为初始模型;
28.将初始模型中的l和r恢复为未知变量,得到待优化预测模型;
29.将集合a中的各个磨耗样本分别输入到待优化预测模型中,建立优化模型,求解目标函数,得出l和r的优化值,将优化值代入到待优化预测模型中,得到优化后的预测模型;
30.3)从其他集合中另选1~0.3k个集合记为新的集合a,将旧的集合a标记成其他集合,再次进行步骤2);重复标记新的集合a,直到遍历k个集合中的各个集合;
31.将最后一次得出的预测模型记为最优预测模型,训练完成。
32.进一步,步骤2)将集合a中各个磨耗样本分别输入到待优化预测模型中,建立优化模型,求解目标函数e,方式如下:
[0033][0034]
其中,x
p
为集合a中第p个磨耗样本,y
p
为集合a中第p个磨耗样本中的磨耗值,p=1,2
……
n,n表示集合a中磨耗样本的总数;wear(x
p
)为所述待优化预测模型。
[0035]
进一步,采用随机分层采样的方式,将训练集等分成k个集合,100≥k≥10;
[0036]
在步骤s3中,判断准确率是否超过阈值,若是,预测模型训练完成;
[0037]
若否,增加k的数量或者增加训练集的数量或者修改超限学习机预测模型的初始参数,对超限学习机预测模型进行再次训练,直到准确率超过阈值,完成预测模型训练;
[0038]
保存预测模型。
[0039]
优选,目标函数的求解方法为梯度下降法或牛顿法。
[0040]
优选,步骤s1中,所述历史数据包括至少10000个磨耗样本;采用随机分层采样的方式,将历史数据划分为测试集与训练集;1:9≤测试集与训练集之间的比例≤1:3。
[0041]
优选,先对历史数据进行数据清洗,包括:剔除缺失磨耗样本、剔除重复保存的磨耗样本;修改或剔除存在格式错误的磨耗样本;采用聚类分析,将异常磨耗样本剔除。
[0042]
本发明依据受电弓滑板磨耗数据样本数量大、数据类别多、变量之间存在耦合关系的特点,提出了一种用于列车智能运维的受电弓滑板磨耗趋势预测方法。
[0043]
与现有的技术相比,本发明具有以下特点:
[0044]
(1)当列车运维人员认为需要评估滑板磨耗程度(当受电弓检测系统发出磨耗值超限警报或者受电弓使用时间较长、使用过程发生异常等情况发生)时运维人员只需要输入相应的受电弓使用参数(如受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓型号、列车运行平均速度、列车车号、受电弓滑板的初始厚度、弓网接触力、受电弓标准长度、受电弓倾角等参数),预测模型就能够基于训练时的历史数据,合理预测出滑板磨耗值,不仅为列车智能运维提供可靠的参考依据,保证列车安全,还能够有效节省人力物力成本。
[0045]
(2)基于超限学习机模型elm,模型输入不仅可以是受电弓型号、受电弓滑板测量位置等自身属性输入,还可以是列车平均运行速度、受电弓平均检修时间间隔等外部属性输入,运维人员将这些影响受电弓滑板磨耗程度的关联参数作为受电弓的使用参数输入到预测模型elm中进行训练;得到学习速度快、泛化能力强的预测模型,实现了对磨耗程度的多参数关联预测,预测结果准确率高。
[0046]
(3)本方法还对预测模型的训练过程进一步改进,将训练集分组处理,形成多个集合,并采用多层次训练和最优化的方法,对模型输出层权重超参数wβb及网络尺寸超参数lr进行了优化训练,生成最优预测模型,有效提高模型的准确率。当历史数据更新时(如关联参数增加),再次训练得出预测模型的网络参数,更新预测模型,保持预测模型的准确性。
附图说明
[0047]
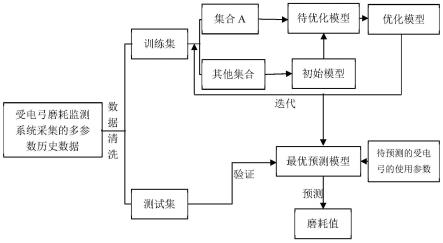
图1为具体实施方式中磨耗预测结构框图;
[0048]
图2为具体实施方式中对预测模型进行优化处理的示意图。
具体实施方式
[0049]
以下结合附图和具体实施方式对本发明的技术方案进行详细描述。本发明使用的超限学习机,其数学模型为现有技术中提供的数学模型。为了便于理解,以下提供现有技术中关于超限学习机的阐述,极限学习机(extreme learning machine,elm)或“超限学习机”是一类基于前馈神经网络(feedforward neuron network,fnn)构建的机器学习系统或方法,适用于监督学习和非监督学习问题。elm在研究中被视为一类特殊的fnn,或对fnn及其反向传播算法的改进,其特点是隐含层节点的权重为随机或人为给定的,且不需要更新,学习过程仅计算输出权重。超限学习机使用单层前馈神经网络的结构。具体地,包括输入层、隐含层和输出层,其中隐含层的输出函数具有如下定义:
[0050][0051]
这里x为神经网络的输入、β为输出权重,h(x)被称为特征映射或激励函数(activation function),其作用是将输入层的数据由其原本的空间映射到elm的特征空间:
[0052]
h(x)=g(ai,bi,x)
[0053]
式中,ai和bi是特征映射的参数,在elm研究中也被称为节点参数(node parameter),其中,ai为输入权重(input weights)。由于elm中输入层至隐含层的特征映射是随机的或人为给定的且不进行调整,因此elm的特征映射是随机的。
[0054]
以下对本发明方法进行具体阐述:
[0055]
一种受电弓滑板磨耗预测方法,利用以下步骤训练受电弓滑板磨耗的预测模型:
[0056]
s1、获取受电弓滑板磨耗的历史数据,将其划分为训练集和测试集;
[0057]
历史数据包括多个磨耗样本;单个磨耗样本包含受电弓的使用参数以及在该使用参数下的磨耗值;受电弓的使用参数为:影响受电弓滑板磨耗程度的关联参数;
[0058]
示例展示:单个磨耗样本{受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、受电弓滑板的初始厚度、弓网接触力、受电弓标准长度、受电弓倾角、列车运行平均速度、列车车型、磨耗值};
[0059]
为了保证样本的有效性、规范性,具体实施时,可以先对历史数据进行数据清洗,包括:剔除缺失磨耗样本、剔除重复保存的磨耗样本;修改或剔除存在格式错误的磨耗样本;采用聚类分析,将异常磨耗样本剔除。历史数据包括至少10000个磨耗样本;采用随机分层采样的方式,将历史数据划分为测试集与训练集;其中,1:9≤测试集与训练集之间的比例≤1:3,本实施例中,为2:8。
[0060]
s2、利用训练集对超限学习机预测模型进行训练;
[0061]
再根据测试集验证训练后超限学习机预测模型的准确率;
[0062]
s3、判断准确率是否超过阈值,若是,预测模型训练完成;
[0063]
若否,增加训练集的数量或者修改超限学习机预测模型的初始参数,对超限学习
机预测模型进行再次训练,直到准确率超过阈值,完成预测模型训练;
[0064]
保存预测模型;
[0065]
将待测的受电弓使用参数输入到预先存储的预测模型中,预测模型输出该受电弓滑板的磨耗值,完成对磨耗值的预测。
[0066]
其中,受电弓的使用参数包括至少两个影响受电弓滑板磨耗程度的关联参数。
[0067]
更具体的,受电弓的使用参数包括受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、列车运行平均速度、列车车型、受电弓滑板的初始厚度、弓网接触力、受电弓标准长度和受电弓倾角中的至少两个参数。
[0068]
其中,受电弓滑板测量位置为:在整个滑板表面上均匀划分n个测量位置,每次只选择其中一个测量位置作为受电弓滑板测量位置输入到使用参数中,50≤n≤300。
[0069]
以下进行示例性描述,受电弓的使用参数为以下形式中的任意一种:
[0070]
形式一:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、受电弓滑板的初始厚度、弓网接触力、受电弓标准长度、受电弓倾角、列车运行平均速度和列车车型;
[0071]
形式二:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、受电弓滑板的初始厚度、弓网接触力、受电弓标准长度和受电弓倾角;
[0072]
形式三:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、滑板数量、受电弓滑板的初始厚度、弓网接触力、列车运行平均速度和列车车型;
[0073]
形式四:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、受电弓类别、滑板数量、受电弓滑板的初始厚度、弓网接触力和列车运行平均速度;
[0074]
形式五:受电弓滑板测量位置、受电弓累计使用时间、受电弓滑板的初始厚度、弓网接触力和列车运行平均速度。
[0075]
具体实施时,可以依据影响受电弓滑板磨耗程度的重要性,将部门关联参数或者将全部关联参数作为受电弓的使用参数,参与模型训练;
[0076]
优选实施为,受电弓的使用参数包含:受电弓滑板测量位置、受电弓累计使用时间、受电弓平均检修时间间隔、列车运行平均速度在内的至少4个关联参数;
[0077]
为了更加快速准确的获取预测模型,如图1所示,本实施例中,还对步骤s2的训练过程进行了以下优化处理:
[0078]
步骤s2中,利用训练集对超限学习机预测模型进行训练的方式为:
[0079]
1)将训练集等分成k个集合(采用随机分层采样的方式等分成s1~sk);任选1~0.3k个集合记为集合a;
[0080]
100≥k≥10,本实施例中,训练集有8000个样本,k=20,每个集合包含400个样本,如图2所示,集合a中包含一个集合sk(内含400个样本),实施时,集合a也可以包含1~6(0.3
×
20)个集合,如3个集合(内含1200个样本)、4个集合(内含1600个样本)。
[0081]
2)随机为预测模型中的隐含层数量l、每层神经元数量r赋初值,如l=10,r=50;
[0082]
利用除集合a以外的其他集合,对预测模型进行训练,将训练后的模型记为初始模型;
[0083]
初始模型wear(x)表达式为:
[0084][0085]
其中,x为其他集合中的磨耗样本,g为激活函数(sigmoid函数或relu函数);w
i,j
为初始模型中已经训练好的第i层隐藏层的第j个神经元的权重,b
i,j
为初始模型中已经训练好的第i层隐藏层的第j个神经元的偏置,βj为初始模型中已经训练好的输出层第j个神经元的权重。
[0086]
将初始模型中的l和r恢复为未知变量,得到待优化预测模型;
[0087]
将集合a中的各个磨耗样本分别输入到待优化预测模型中,建立优化模型,求解目标函数e:
[0088][0089]
其中,x
p
为集合a中第p个磨耗样本,y
p
为集合a中第p个磨耗样本中的磨耗值,p=1,2
……
n,n表示集合a中磨耗样本的总数,本实施例n=400;wear(x
p
)为待优化预测模型。
[0090]
利用梯度下降法或牛顿法求解目标函数e,得出l和r的优化值,将优化值代入到待优化预测模型中,得到优化后的预测模型;
[0091]
3)从其他集合中另选1~0.3k个集合记为新的集合a,将旧的集合a标记成其他集合,再次进行步骤2);重复标记新的集合a,直到遍历k个集合中的各个集合(本实施例中,采用倒叙的方式,第一次将sk记为集合a、第二次将s
k-1
记为新的集合a、第三次将将s
k-1
记为新的集合a、
……
最后一次将s1记为新的集合a);
[0092]
将最后一次得出的预测模型记为最优预测模型,训练完成。
[0093]
再根据测试集验证训练后超限学习机预测模型的准确率;
[0094]
在步骤s3中,判断准确率是否超过阈值,若是,预测模型训练完成;
[0095]
若否,增加k的数量(另k=30,40
…
)或者增加训练集的数量或者修改超限学习机预测模型的初始参数,对超限学习机预测模型进行再次训练,直到准确率超过阈值,完成预测模型训练。
[0096]
本实施例对模型输出层权重超参数wβb及网络尺寸超参数lr进行了优化训练,生成最优预测模型,有效提高模型的准确率。
[0097]
在使用模型时,仅需将待测的受电弓使用参数(与训练时的使用参数类型、数量保持一致)输入到预先存储的预测模型中,预测模型输出该受电弓滑板的磨耗值,完成对磨耗值的预测。
[0098]
本方法将实现了对磨耗程度的多参数关联预测,预测结果准确率高。
[0099]
前面对本发明具体示例性实施方案所呈现的描述是出于说明和描述的目的。前面的描述并不想要成为毫无遗漏的,也不是想要把本发明限制为所公开的精确形式,显然,根据上述教导很多改变和变化都是可能的。选择示例性实施方案并进行描述是为了解释本发明的特定原理及其实际应用,从而使得本领域的其它技术人员能够实现并利用本发明的各种示例性实施方案及其不同选择形式和修改形式。本发明的范围旨在由所附权利要求书及其等价形式所限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。