1.本发明涉及个性化服务快讯推荐技术领域,具体涉及一种基于结构化多兴趣协同的企业服务快讯推荐方法。
背景技术:
2.随着中小微企业综合质量服务平台的快速发展,平台每天发布数以万计的企业服务快讯,由于激增的快讯数量与人们有限的阅读时间之间的矛盾导致用户几乎不可能阅读所有的快讯信息。个性化企业服务快讯推荐可以帮助用户在海量服务快讯当中找到他们感兴趣的服务快讯,其作为缓解信息过载的有效手段在中小微综合质量服务平台上扮演着越来越重要的角色。
3.企业服务快讯具有比较强的时效性,基于协同过滤(cf)的推荐算法在解决企业服务快讯推荐问题时面临着严重的冷启动。如何从快讯和用户自身拥有的特征出发构建企业快讯推荐方案是急需解决的问题。虽然推荐技术取得了较大进步,但企业服务快讯推荐仍面临着以下的问题。首先,为企业服务快讯学习一个良好的嵌入表示是做好企业服务快讯推荐的前提,但是手工从企业服务快讯中提取特征的方法可能无法精准的建模快讯的语义信息。其次,先前工作通常将用户点击历史视为一个连续的序列,无法以一种显式的方式结构化提取用户兴趣,这可能无法精准的建模用户多样化兴趣。
技术实现要素:
4.本发明为了克服以上技术的不足,提供了一种提高快讯推荐效果的基于结构化多兴趣协同的企业服务快讯推荐方法。
5.本发明克服其技术问题所采用的技术方案是:
6.一种基于结构化多兴趣协同的企业服务快讯推荐方法,包括如下步骤:
7.a)获取用户的历史点击快讯序列数据v=[v1,v2,...,vi,...,vn]和候选快讯序列数据v
′
=[v
′1,v
′2,...,v
′i,...,v
′m],其中vi为第i个历史点击的快讯,i∈{1,...n},n为历史点击的快讯数量,v
′i为第i个候选快讯,i∈{1,...m},m为候选快讯的数量,获取快讯的服务类型数量s;
[0008]
b)使用分词工具将历史点击快讯序列中每条快讯标题转换为分词序列[x1,x2,...,xi,...,xf],将候选快讯序列中的每条快讯标题转换为分词序列[x
′1,x
′2,...,x
′i,...,x
′f],其中xi及x
′i均为第i个分词,i∈{1,...f},f为快讯标题单词截取的最大长度,将分词序列[x1,x2,...,xi,...,xf]映射为词嵌入序列[e1,e2,...,ei,...,ef],将分词序列[x
′1,x
′2,...,x
′i,...,x
′f]映射为词嵌入序列[e
′1,e
′2,...,e
′i,...,e
′f],其中ei及e
′i均为第i个词嵌入;
[0009]
c)将词嵌入序列[e1,e2,...,ei,...,ef]及[e
′1,e
′2,...,e
′i,...,e
′f]分别输入到两个并行的双向gru中进行语义理解,建模快讯标题的双向顺序性特征,分别得到融合双向语义的词嵌入序列[h1,h2,...,hi,...,hf]和[h
′1,h
′2,...,h
′i,...,h
′f],其中hi及h
′i均为
第i个融合双向语义的单词;
[0010]
d)使用附加选择器分别应用于融合双向语义的词嵌入序列[h1,h2,...,hi,...,hf]和[h
′1,h
′2,...,h
′i,...,h
′f],分别得到特征增强后的词嵌入序列和其中及均为第i个的增强后的词嵌入;
[0011]
e)使用词注意力网络为历史点击快讯序列中每条快讯标题分词分配一个权重,第i个单词的权重为αi,为候选快讯序列中的每条快讯标题转换为分词分配一个权重,第i个单词的权重为α
′i;
[0012]
f)通过公式计算得到第x个历史点击快讯的标题词嵌入的加权和c
x
,通过公式计算得到第x个候选快讯的标题词嵌入的加权和c
′
x
,x∈{1,...n},建立得到历史点击表示序列c=[c1,c2,...,c
x
,...,cn]和候选快讯表示序列c
′
=[c
′1,c
′2,...,c
′
x
,...,c
′n];
[0013]
g)创建与快讯的服务类型数量s相同个数的兴趣代理节点v
p
=[v
p,1
,v
p,2
,...,v
p,i
,...,v
p,s
],其中v
p,i
为用户对第i种服务类型快讯的兴趣,i∈{1,...,s},构建用户兴趣结构无向图g=(v
st
,e
st
),式中v
st
为兴趣代理节点v
p
和历史点击快讯序列数据v中每条快讯为节点在内的节点集合,e
st
为图的边集合,e
st
∈《vi,v
i 1
》∪《vi,v
p,j
》,《vi,v
i 1
》为用户点击历史中第i个快讯vi和第i 1个快讯v
i 1
的无向边,《vi,v
p,j
》为用户点击历史中第i个快讯vi和其所属服务类型的兴趣代理节点v
p,j
的无向边;
[0014]
h)使用图注意力网络gat将用户兴趣结构无向图g中相同服务类型的快讯聚合到对应的兴趣代理节点v
p
中,得到结构化后的兴趣代理节点表示其中为第i个结构化后的兴趣代理节点,i∈{1,...s};
[0015]
i)将结构化后的兴趣代理节点表示输入到多头自注意力网络的兴趣协同层中,得到增强后的兴趣节点表示式中为第i个增强后的兴趣节点,i∈{1,...s};
[0016]
j)通过公式计算得到第i个兴趣代理节点的归一化注意力权重α
p,i
,式中a
p.i
为第i个兴趣代理节点的权重,q
p
为兴趣查询向量,t为转置,d
p
为兴趣查询向量长度,d
p
=200,w
p
及b
p
均为用户兴趣注意力网络中可学习参数;
[0017]
k)通过公式计算得到所有兴趣协同增强后的代理节点的加权和u;
[0018]
l)通过公式y=u
tc′
x
计算得到用户和每一个候选快讯的点击概率y,选取概率最大
的5个候选快讯推荐给用户。
[0019]
优选的,步骤a)中n取值为128,m取值为32。
[0020]
优选的,步骤b)中分词工具为jieba分词工具,使用预训练的300维glove中文词嵌入将历史点击快讯标题的分词序列[x1,x2,...,xi,...,xf]映射为词嵌入序列[e1,e2,...,ei,...,ef],将候选快讯标题的分词序列[x
′1,x
′2,...,x
′i,...,x
′f]映射为词嵌入序列[e
′1,e
′2,...,e
′i,...,e
′f],f取值为32。
[0021]
进一步的,步骤c)包括如下步骤:
[0022]
c-1)中通过公式计算得到hi,式中,式中,式中为拼接操作,gru(
·
)为gru网络,为正向门控循环单元中的上一时刻的隐藏状态,为反向门控循环单元中的上一时刻的隐藏状态;
[0023]
c-2)中通过公式计算得到h
′i,式中,式中,式中为拼接操作,gru(
·
)为gru网络,为正向门控循环单元中的上一时刻的隐藏状态,为反向门控循环单元中的上一时刻的隐藏状态。
[0024]
进一步的,步骤d)附加选择器应用于融合双向语义的词嵌入序列[h1,h2,...,hi,...,hf]和[h
′1,h
′2,...,h
′i,...,h
′f]的方法为:
[0025]
d-1)通过公式计算得到第i个的增强后的词嵌入式中
⊙
为逐点元素相乘,slti=σ
slt
(w
slthi
b
slt
),w
slt
及b
slt
为可学习参数,σ
slt
(
·
)为relu非线性激活函数;
[0026]
d-2)通过公式计算得到第i个的增强后的词嵌入式中
⊙
为逐点元素相乘,slt
′i=σ
slt
(w
′
slth′i b
′
slt
),w
′
slt
及b
′
slt
为可学习参数,σ
slt
(
·
)为relu非线性激活函数。
[0027]
进一步的,步骤e)使用词注意力网络为每条快讯标题分配一个权重的方法为:
[0028]
e-1)通过公式计算得到i个单词的归一化注意力权重为αi,式中w
t
及b
t
均为注意力网络中可学习的参数,q
t
为词查询向量,t为转置,αj为第j个单词的权重,j∈{1,...f},d
t
为词查询向量长度,d
t
=200;
[0029]
e-2)通过公式计算得到i个单词的归一化注意力权重为α
′i,式中w
t
′
及b
′
t
均为注意力网络中可学习的参数,q
′
t
为词查询向量,α
′j为第j个单词的权重,j∈{1,...f},d
′
t
为词查询向量长度,d
′
t
=200。
[0030]
进一步的,步骤h)中通过公式计算得到第i个兴趣代理节点在第k个图注意力头中的表示k为图注意力头的总数,式中为可学习的线性投影参数,为第i个兴趣代理节点v
p,i
的一阶邻居集合,为第k个图注意力头中第j个一阶邻居对兴趣代理节点v
p,i
的重要性参数,式中σ
gat
为负斜率为0.2的leakyrelu非线性激活函数,f(
·
)为单层前馈神经网络,v
p,i
′
为第i个兴趣代理节点v
p,i
的原始向量表示,通过公式计算得到第i个兴趣代理点所有图注意力头产生表示的拼接第i个兴趣代理点所有图注意力头产生表示的拼接为拼接操作。
[0031]
优选的,k取值为20。
[0032]
进一步的,步骤i)中通过公式计算得到第i个兴趣代理节点在第l个自注意力头中的表示式中为在第l个自注意力头中第i个兴趣代理节点和第j个兴趣代理节点之间的协同作用参数,和第j个兴趣代理节点之间的协同作用参数,及均为l个自注意力头中可学习的线性投影参数,t为转置,为第j个结构化后的兴趣代理节点,j∈{1,...s},通过公式计算得到第i个增强后的兴趣节点趣节点为拼接操作,l为自注意力中注意力头的总数。优选的,l取值为20。
[0033]
本发明的有益效果是:充分考虑了快讯的双向语义信息,无需大量特征工程,并设计了一种附加选择器以增强快讯的特征,有效增强了最终的企业服务快讯表示;本发明提出的用户兴趣表示学习方法通过构建用户兴趣结构无向图,利用图注意力网络可以一种显示的方式结构化编码用户的多种潜在兴趣,这可以提取更加精确的用户兴趣表示;本发明提出的用户兴趣表示学习方法充分考虑了用户多种潜在兴趣之间的相互作用,利用自注意力网络模拟兴趣之间的作用关系有效增强了用户兴趣表示;本发明得益于良好的企业服务快讯表示学习方法和用户兴趣表示学习方法,有效提高了企业服务快讯推荐的准确性。
附图说明
[0034]
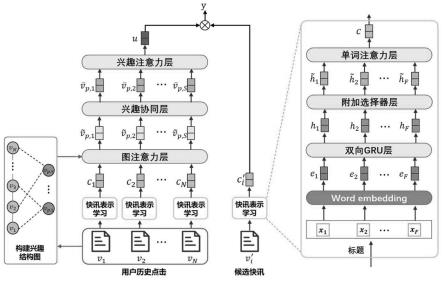
图1为本发明的模型结构图。
具体实施方式
[0035]
下面结合附图1对本发明做进一步说明。
[0036]
一种基于结构化多兴趣协同的企业服务快讯推荐方法,该方法提出利用并行的gru网络建模企业服务快讯(以下简称为“快讯”)标题双向语义信息,进一步结合提出的附加选择器有效增强快讯的表示效果。该方法提出将用户点击历史和兴趣代理节点相结合构建用户兴趣结构图,通过图注意力网络显式提取用户结构化的多兴趣,并利用自注意力网络建模兴趣之间的相互作用关系以有效增强用户兴趣表示的效果。最终在良好表示基础上有效提高快讯推荐效果。具体的包括如下步骤:
[0037]
a)获取用户的历史点击快讯序列数据v=[v1,v2,...,vi,...,vn]和候选快讯序列数据v
′
=[v
′1,v
′2,...,v
′i,...,v
′m],其中vi为第i个历史点击的快讯,i∈{1,...n},n为历史点击的快讯数量,v
′i为第i个候选快讯,i∈{1,...m},m为候选快讯的数量,获取快讯的服务类型数量s。
[0038]
b)使用分词工具将历史点击快讯序列中每条快讯标题转换为分词序列[x1,x2,...,xi,...,xf],将候选快讯序列中的每条快讯标题转换为分词序列[x
′1,x
′2,...,x
′i,...,x
′f],其中xi及x
′i均为第i个分词,i∈{1,...f},f为快讯标题单词截取的最大长度,将分词序列[x1,x2,...,xi,...,xf]映射为词嵌入序列[e1,e2,...,ei,...,ef],将分词序列[x
′1,x
′2,...,x
′i,...,x
′f]映射为词嵌入序列[e
′1,e
′2,...,e
′i,...,e
′f],其中ei及e
′i均为第i个词嵌入。
[0039]
c)将词嵌入序列[e1,e2,...,ei,...,ef]及[e
′1,e
′2,...,e
′i,...,e
′f]分别输入到两个并行的双向gru中进行语义理解,建模快讯标题的双向顺序性特征,分别得到融合双向语义的词嵌入序列[h1,h2,...,hi,...,hf]和[h
′1,h
′2,...,h
′i,...,h
′f],其中hi及h
′i均为第i个融合双向语义的单词。
[0040]
d)使用附加选择器分别应用于融合双向语义的词嵌入序列[h1,h2,...,hi,...,hf]和[h
′1,h
′2,...,h
′i,...,h
′f],分别得到特征增强后的词嵌入序列和其中及均为第i个的增强后的词嵌入。
[0041]
e)使用词注意力网络为历史点击快讯序列中每条快讯标题分词分配一个权重,第i个单词的权重为αi,为候选快讯序列中的每条快讯标题转换为分词分配一个权重,第i个单词的权重为α
′i。
[0042]
f)通过公式计算得到第x个历史点击快讯的标题词嵌入的加权和c
x
,通过公式计算得到第x个候选快讯的标题词嵌入的加权和c
′
x
,x∈{1,...n},建立得到历史点击表示序列c=[c1,c2,...,c
x
,...,cn]和候选快讯表示序列c
′
=[c
′1,c
′2,...,c
′
x
,...,c
′n]。
[0043]
g)创建与快讯的服务类型数量s相同个数的兴趣代理节点v
p
=[v
p,1
,v
p,2
,...,v
p,i
,...,v
p,s
],其中v
p,i
为用户对第i种服务类型快讯的兴趣,i∈{1,...,s},构建用户兴趣结构无向图g=(v
st
,e
st
),式中v
st
为兴趣代理节点v
p
和历史点击快讯序列数据v中每条快讯
为节点(重复快讯视为不同节点)在内的节点集合,e
st
为图的边集合,e
st
∈《vi,v
i 1
》∪《vi,v
p,j
》,《vi,v
i 1
》为用户点击历史中第i个快讯vi和第i 1个快讯v
i 1
的无向边,即用户在点击了快讯vi之后点击了快讯v
i 1
,《vi,v
p,j
》为用户点击历史中第i个快讯vi和其所属服务类型的兴趣代理节点v
p,j
的无向边,即用户点击的快讯vi的服务类型为j。
[0044]
h)使用图注意力网络(gat)将用户兴趣结构无向图g中相同服务类型的快讯聚合到对应的兴趣代理节点v
p
中,得到结构化后的兴趣代理节点表示每一个兴趣代理节点代表了用户对该类型快讯的兴趣,其中为第i个结构化后的兴趣代理节点,i∈{1,...s}。
[0045]
i)用户兴趣之间并不是孤立存在的,用户兴趣之间的协同作用对于学习用户兴趣表示十分重要,因此将结构化后的兴趣代理节点表示输入到多头自注意力网络的兴趣协同层中,得到增强后的兴趣节点表示式中为第i个增强后的兴趣节点,i∈{1,...s}。兴趣协同层是由多头自注意力网络建模兴趣代理节点之间的协同关系。
[0046]
j)通过公式计算得到第i个兴趣代理节点的归一化注意力权重α
p,i
,式中a
p.i
为第i个兴趣代理节点的权重,q
p
为兴趣查询向量,t为转置,d
p
为兴趣查询向量长度,d
p
=200,w
p
及b
p
均为用户兴趣注意力网络中可学习参数。
[0047]
k)通过公式计算得到所有兴趣协同增强后的代理节点的加权和u。
[0048]
l)通过公式y=u
tc′
x
计算得到用户和每一个候选快讯的点击概率y,点击概率y表示用户对第i个候选快讯点击概率大小,y越大则点击概率越大,选取概率最大的5个候选快讯推荐给用户。
[0049]
充分考虑了快讯的双向语义信息,无需大量特征工程,并设计了一种附加选择器以增强快讯的特征,有效增强了最终的企业服务快讯表示;本发明提出的用户兴趣表示学习方法通过构建用户兴趣结构无向图,利用图注意力网络可以一种显示的方式结构化编码用户的多种潜在兴趣,这可以提取更加精确的用户兴趣表示;本发明提出的用户兴趣表示学习方法充分考虑了用户多种潜在兴趣之间的相互作用,利用自注意力网络模拟兴趣之间的作用关系有效增强了用户兴趣表示;本发明得益于良好的企业服务快讯表示学习方法和用户兴趣表示学习方法,有效提高了企业服务快讯推荐的准确性。
[0050]
实施例1:
[0051]
优选的,步骤a)中n取值为128,m取值为32。
[0052]
实施例2:
[0053]
步骤b)中分词工具为jieba分词工具,使用预训练的300维glove中文词嵌入将历史点击快讯标题的分词序列[x1,x2,...,xi,...,xf]映射为词嵌入序列[e1,e2,...,ei,...,ef
],将候选快讯标题的分词序列[x
′1,x
′2,...,x
′i,...,x
′f]映射为词嵌入序列[e
′1,e
′2,...,e
′i,...,e
′f],f取值为32。
[0054]
实施例3:
[0055]
步骤c)包括如下步骤:
[0056]
c-1)中通过公式计算得到hi,式中,式中,式中为拼接操作,gru(
·
)为gru网络,为正向门控循环单元中的上一时刻的隐藏状态,为反向门控循环单元中的上一时刻的隐藏状态。
[0057]
c-2)中通过公式计算得到h
′i,式中,式中,式中为拼接操作,gru(
·
)为gru网络,为正向门控循环单元中的上一时刻的隐藏状态,为反向门控循环单元中的上一时刻的隐藏状态。
[0058]
实施例4:
[0059]
步骤d)附加选择器应用于融合双向语义的词嵌入序列[h1,h2,...,hi,...,hf]和[h
′1,h
′2,...,h
′i,...,h
′f]的方法为:
[0060]
d-1)通过公式计算得到第i个的增强后的词嵌入式中
⊙
为逐点元素相乘,slti=σ
slt
(w
slthi
b
slt
),w
slt
及b
slt
为可学习参数,σ
slt
(
·
)为relu非线性激活函数。
[0061]
d-2)通过公式计算得到第i个的增强后的词嵌入式中
⊙
为逐点元素相乘,slt
′i=σ
slt
(w
′
slth′i b
′
slt
),w
′
slt
及b
′
slt
为可学习参数,σ
slt
(
·
)为relu非线性激活函数。
[0062]
实施例5:
[0063]
步骤e)使用词注意力网络为每条快讯标题分配一个权重的方法为:
[0064]
e-1)通过公式计算得到i个单词的归一化注意力权重为αi,式中w
t
及b
t
均为注意力网络中可学习的参数,q
t
为词查询向量,t为转置,αj为第j个单词的权重,j∈{1,...f},d
t
为词查询向量长度,d
t
=200。
[0065]
e-2)通过公式计算得到i个单词的归一化注意力权重为α
′i,式中w
t
′
及b
′
t
均为注意力网络中可学习的参数,q
′
t
为词查询向量,α
′j为第j个单词的权重,j∈{1,...f},d
′
t
为词查询向量长度,d
′
t
=200。
[0066]
实施例6:
[0067]
步骤h)中通过公式计算得到第i个兴趣代理节点在第k个图注意力头中的表示k为图注意力头的总数,式中为可学习的线性投影参数,为第i个兴趣代理节点v
p,i
的一阶邻居集合,为第k个图注意力头中第j个一阶邻居对兴趣代理节点v
p,i
的重要性参数,式中σ
gat
为负斜率为0.2的leakyrelu非线性激活函数,f(
·
)为单层前馈神经网络,v
p,i
′
为第第i个兴趣代理节点v
p,i
的原始向量表示,通过公式计算得到第i个兴趣代理点所有图注意力头产生表示的拼接理点所有图注意力头产生表示的拼接为拼接操作。
[0068]
实施例7:
[0069]
k取值为20。
[0070]
实施例8:
[0071]
步骤i)中通过公式计算得到第i个兴趣代理节点在第l个自注意力头中的表示式中为在第l个自注意力头中第i个兴趣代理节点和第j个兴趣代理节点之间的协同作用参数,代理节点之间的协同作用参数,及均为l个自注意力头中可学习的线性投影参数,t为转置,为第j个结构化后的兴趣代理节点,j∈{1,...s},通过公式计算得到第i个增强后的兴趣节点计算得到第i个增强后的兴趣节点为拼接操作,l为自注意力中注意力头的总数。
[0072]
实施例9:
[0073]
l取值为20。
[0074]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。