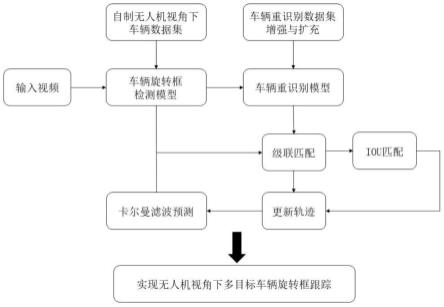
用于从二维图像构建三维模型的系统和方法
1.相关申请的交叉引用
2.本技术要求于2019年11月26日提交的美国专利申请第16/696,468号的优先权,该申请的内容在此通过引用以其整体并入。
3.背景
4.本公开总体上涉及构建用于制造牙科器具的三维模型。更具体地,本公开涉及从用户牙弓的二维图像构建用户牙弓的三维模型以制造牙齿矫正器(dental aligner)。
5.可基于用户牙齿的3d模型为用户制造用于重新定位用户牙齿的牙齿矫正器。3d模型可以从用户牙齿的牙印模(dental impression)或口腔内扫描生成。用于生成这样的3d模型的牙印模可以由用户或正畸专业人员使用牙印模套件获得。可以使用3d扫描设备对用户的口腔进行口腔内扫描。然而,用于获得生成用户牙齿的3d模型所必需的信息的这些方法可能是耗时的,用户或正畸专业人员容易出错,并且需要专门的设备。
6.概述
7.一个实施例涉及一种系统。该系统包括模型训练系统和模型生成系统。模型训练系统被配置成接收训练集的多个数据分组。多个数据分组中的每个数据分组包括与相应牙弓的一个或更多个训练图像和相应牙弓的三维(3d)训练模型相对应的数据。模型训练系统被配置成针对训练集的多个数据分组中的每个数据分组,识别在相应牙弓的一个或更多个训练图像和3d训练模型之间的多个相关点(correlation point)。模型训练系统被配置成使用一个或更多个训练图像、3d训练模型以及在训练集的多个数据分组的每个相关点的一个或更多个训练图像和3d训练模型之间的多个相关点来生成机器学习模型。模型生成系统被配置成接收用户牙弓的一个或更多个图像。模型生成系统被配置成通过将用户牙弓的一个或更多个图像应用于机器学习模型来生成牙弓的3d模型。
8.另一实施例涉及一种方法。该方法包括由模型训练系统接收训练集的多个数据分组。多个数据分组中的每个数据分组包括与相应牙弓的一个或更多个训练图像和相应牙弓的三维(3d)训练模型相对应的数据。该方法包括由模型训练系统针对训练集的多个数据分组中的每个数据分组,识别在相应牙弓的一个或更多个训练图像和3d训练模型之间的多个相关点。该方法包括由模型训练系统使用一个或更多个训练图像、3d训练模型以及在训练集的多个数据分组中的每一个的一个或更多个训练图像和3d训练模型之间的多个相关点来生成机器学习模型。该方法包括由模型生成系统接收用户牙弓的一个或更多个图像。该方法包括由模型生成系统通过将用户牙弓的一个或更多个图像应用于机器学习模型来生成牙弓的3d模型。
9.另一实施例涉及一种存储指令的非暂时性计算机可读介质,该指令在由一个或更多个处理器执行时,使得该一个或更多个处理器接收训练集的多个数据分组。多个数据分组中的每个数据分组包括与相应牙弓的一个或更多个训练图像和相应牙弓的三维(3d)训练模型相对应的数据。指令还使得一个或更多个处理器针对训练集的多个数据分组中的每个数据分组识别在相应牙弓的一个或更多个训练图像和3d训练模型之间的多个相关点。指令还使得一个或更多个处理器使用一个或更多个训练图像、3d训练模型以及在训练集的多
个数据分组中的每一个的一个或更多个训练图像和3d训练模型之间的多个相关点来生成机器学习模型。指令还使得一个或更多个处理器接收用户牙弓的一个或更多个图像。指令还使得一个或更多个处理器通过将用户牙弓的一个或更多个图像应用于机器学习模型来生成牙弓的3d模型。
10.本概述仅是说明性的,并不打算以任何方式加以限制。在本文所阐述的详细描述中,结合附图,本文所述的设备或过程的其他方面、发明性特征和优点将变得明显,在附图中相似的附图标记指代相似的元件。
11.附图简述
12.图1是根据说明性实施例的用于从一个或更多个二维(2d)图像生成三维(3d)模型的系统的框图。
13.图2a是根据说明性实施例的患者口腔的第一示例图像的图示。
14.图2b是根据说明性实施例的患者口腔的第二示例图像的图示。
15.图2c是根据说明性实施例的患者口腔的第三示例图像的图示。
16.图3是根据说明性实施例的由图1的系统生成的图像特征图(image feature map)的框图。
17.图4是根据说明性实施例的可以在图1的一个或更多个部件内实现的神经网络的框图。
18.图5a是根据说明性实施例的覆盖在上牙弓的数字模型上的示例点云的图示。
19.图5b是根据说明性实施例的覆盖在下牙弓的数字模型上的示例点云的图示。
20.图5c根据说明性实施例的包括图5a和图5b中示出的点云的点云的图示。
21.图6是根据说明性实施例的从一个或更多个2d图像生成3d模型的方法的示意图。
22.图7是根据说明性实施例的从一个或更多个2d图像生成点云的方法的示意图。
23.图8是根据另一说明性实施例的用于从一个或更多个2d图像生成3d模型的系统的示意图。
24.图9根据说明性实施例的训练机器学习模型的方法的示意图。
25.图10a是根据说明性实施例的第一示例训练图像的图示。
26.图10b是根据说明性实施例的第二示例训练图像的图示。
27.图10c是根据说明性实施例的第三示例训练图像的图示。
28.图10d是根据说明性实施例的第四示例训练图像的图示。
29.图11是根据说明性实施例的训练图像和对应的3d训练模型的图示。
30.图12是根据说明性实施例的一系列训练图像和用于训练图像的3d训练模型的对应姿势的图示。
31.图13是根据说明性实施例的在训练集中使用的3d模型的处理进展的图示。
32.图14是根据说明性实施例的从一个或更多个2d用户图像生成3d模型的方法的图示。
33.图15是根据说明性实施例的图8系统的用例示意图的图示。
34.图16是根据说明性实施例的对应于图8系统的机器学习模型的训练的一系列图形的图示。
35.图17是根据说明性实施例的与由图8系统的机器学习模型生成的模型相对应的一
系列模型评估界面的图示。
36.图18是根据说明性实施例的一系列用户图像和使用图8系统的机器学习模型生成的对应的一系列3d模型的图示。
37.详细描述
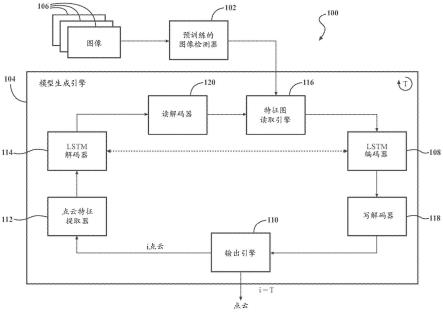
38.在转到详细说明某些示例性实施例的附图之前,应当理解,本公开不限于在说明书中阐述或在附图中示出的细节或方法。还应当理解,本文使用的术语仅用于描述的目的,且不应被视为限制性的。
39.总体参考附图,本文描述了用于从二维(2d)图像生成用户牙弓的三维(3d)模型的系统和方法。模型生成系统接收用户牙弓的图像,使用用户牙弓的图像生成点云,并基于该点云制造牙齿矫正器。本文描述的系统和方法与其它实现相比具有许多优点。例如,本文描述的系统和方法通过更有效地生成用户牙列的3d模型来加快牙齿矫正器的制造和向用户的交付,而不需要用户施用牙印模套件、进行用户牙列的扫描或参加与牙医或正畸医师的约见。由于不需要约见牙医或正畸医师,这样的系统和方法可以使用户在接受正畸治疗时更加舒适和自信,并且避免由于需要重新进行牙印模或扫描用户的牙齿而导致延误接受正畸治疗。如果需要用户牙列的附加2d图像,则可以通过拍摄用户牙列的附加照片来轻易地获取此类图像,而正在接受更传统的正畸治疗的用户则需要获得印模套件或访问牙医或正畸医师以对其牙列进行附加扫描。与要求用户施用牙印模或访问口腔内扫描部位以接收用户牙列的口腔内扫描相反,本文描述的系统和方法利用由用户捕获的图像来制造牙齿矫正器。作为另一个示例,本文描述的系统和方法可用于通过补充关于用户牙列的数据来制造牙齿矫正器,例如,通过口腔内扫描或由用户施用的牙印模获得的数据。
40.现在参考图1,示出了根据说明性实施例的用于生成三维(3d)模型的系统100。系统100(本文中也被称为模型生成系统100)被示出为包括预训练的图像检测器102和模型生成引擎104。如下面更详细地描述的,预训练的图像检测器102被配置成从用户口腔的一个或更多个图像106生成图像特征图。模型生成引擎104被配置成使用该一个或更多个图像106生成3d模型。模型生成引擎104包括长短期记忆(lstm)编码器108,该lstm编码器108被配置成使用一个或更多个权重计算图像特征图的每个特征的概率。模型生成引擎104包括输出引擎110,该输出引擎110被配置成使用来自lstm编码器108的数据生成点云。模型生成引擎104包括点云特征提取器112,该点云特征提取器112被配置成从由输出引擎110生成的点云确定特征。模型生成引擎104包括lstm解码器114,该lstm解码器114被配置成确定来自点云的特征与图像特征图的特征的对应概率之间的差。lstm编码器108训练一个或更多个权重,用于基于由lstm解码器114确定的差计算概率。模型生成引擎104在lstm编码器108、输出引擎110、点云特征提取器112和lstm解码器114之间迭代循环,以生成并细化对应于图像106的点云。在最终迭代处,输出引擎110被配置成使用点云的最终迭代来生成3d模型。
41.模型生成系统100被示出为包括预训练的图像检测器102。预训练的图像检测器102可以是被设计或实现成从一个或更多个图像106生成图像特征图的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。预训练的图像检测器102可以体现在服务器或计算设备上、体现在通信地耦合到服务器的移动设备上,等等。在一些实现中,预训练的图像检测器102可以体现在服务器上,该服务器被设计或实现成使用二维(2d)图像生成3d模型。服务器可以(例如,经由各种网络连接)通信地耦合到移动设备。
42.现在参考图1和图2a-图2c,预训练的图像检测器102可以被配置成接收用户口腔的一个或更多个图像106,例如一个或更多个2d图像。具体地,图2a-图2c是用户口腔的示例图像106的图示。用户可以通过以平视(straight on)方式垂直于牙齿唇面瞄准相机来捕获用户口腔的平视、闭合视图的第一图像106(图2a中示出),通过从上角向下朝向下牙瞄准相机来捕获用户口腔的下部打开视图的第二图像106(图2b中示出),以及通过从下角向上朝向上牙瞄准相机来捕获用户口腔的上部打开视图的第三图像106(图2c中示出)。用户可以使用至少部分地定位在用户口腔内的牙科器具200来捕获图像106。牙科器具200被配置成保持打开用户的嘴唇以暴露用户的牙齿和牙龈。用户可以捕获用户口腔的各种图像106(例如,其中牙科器具200定位在口腔内)。在一些实施例中,用户从基本上相同的视点(例如,两者都从平视视点),或者从基本上相同的视点但稍微偏移地,拍摄他们牙齿的两个图像。在捕获图像106之后,用户可以将图像106上传到预训练的图像检测器102(例如,通过向电子邮件地址或手机号码或与预训练的图像检测器102相关联的其他帐户邮件传送或发送图像106的消息,将图像106上传到与预训练的图像检测器102或模型生成系统100相关联的网站或基于互联网的门户,等等)。
43.预训练的图像检测器102被配置成从用户的移动设备接收图像106。预训练的图像检测器102可以直接从移动设备接收图像106(例如,由移动设备经由网络连接向托管预训练的图像检测器102的服务器传输图像106)。预训练的图像检测器102可以(例如,在移动设备将图像106存储在诸如数据库或云存储系统的存储设备上的情况下)从存储设备检索图像106。在一些实施例中,预训练的图像检测器102被配置成对图像106进行评分。预训练的图像检测器102可以生成标识图像的总体质量的度量。预训练的图像检测器102可以包括盲/无参考图像空间质量评估器(brisque)。brisque被配置成生成范围内的图像分数(例如,在0-100之间,例如,其中针对质量较高的图像生成较低的分数)。brisque可以被配置成基于例如所测量的像素噪声、图像失真等来生成图像分数,以客观地评估图像质量。在图像分数不满足阈值的情况下,预训练的图像检测器102可以被配置成为用户生成提示,该提示指示用户重新拍摄图像106中的一个或更多个。
44.现在参考图1和图3,预训练的图像检测器102被配置成处理图像106以生成图像特征图300。具体地,图3是对应于由预训练的图像检测器102接收的图像106之一的图像特征图300的框图。预训练的图像检测器102可以被配置成处理从用户的移动设备接收的图像106,以生成图像特征图300。在一些实现中,预训练的图像检测器102被配置成分解、解析图像106或以其他方式将图像106分割成多个部分。在一些实现中,预训练的图像检测器102被配置成将图像106分割成多个图块(tile)302。每个图块302对应于相应图像106的特定部分、区段(section)或区域。在一些实例中,图块302可以具有预定大小或分辨率。例如,图块302可以具有512像素
×
512像素的分辨率(尽管图块302可以具有不同的大小或分辨率)。图块302可以每个都是相同的大小,或者一些图块302可以具有不同于其他图块302的大小。在一些实施例中,图块302可以包括主要部分306(例如,位于图块302的中间或朝向中间)和重叠部分308(例如,沿着图块302的周边定位)。每个图块302的主要部分306可以是每个相应图块302所独有的。重叠部分308可以是与一个或更多个相邻图块302共享的公共部分。重叠部分308可以由预训练的图像检测器102在从图块302的主要部分提取特征(例如,牙齿大小、牙齿形状、牙齿位置、牙齿取向、牙冠大小、牙冠形状、牙龈位置、牙龈形状或轮廓、牙齿
到牙龈界面位置、邻面区域位置(interproximal region location)等)时用作背景(context)。
45.预训练的图像检测器102被配置成确定、识别或以其他方式从图块302提取一个或更多个特征。在一些实现中,预训练的图像检测器102包括图像分类器神经网络304(本文中也称为图像分类器304)。图像分类器304可以使用类似于图4中示出并随后描述的神经网络400的神经网络来实现。例如,图像分类器304可以包括(例如,被配置成接收图块302的)输入层、包括各种预训练的权重(例如,其对应于图块302的特定分类的概率)的一个或更多个隐藏层以及输出层。下面描述了这些层中的每一个。预训练的图像检测器102的图像分类器神经网络304被配置成对每个图块302进行分类。预训练的图像检测器102可以使用各种架构、库或者诸如mobilenet架构的软件和硬件的其他组合来实现,尽管也可以(例如,基于内存需求、处理速度和性能之间的平衡)使用其他架构。预训练的图像检测器102被配置成(例如,逐块地)处理图块302中的每一个并将图块302拼接在一起以生成图像特征图300。相应图块302的每种分类可以对应于图块302内的相关特征。分类的各种示例包括,例如,包括在图块302中的牙齿的分类(例如,门齿或门牙(centrals)、犬齿、前臼齿或双尖牙、臼齿等),包括在图块302中的牙齿的一部分(例如,牙冠、牙根),牙龈是否包括在图块302中,等等。这些分类可以各自包括可能存在于图块中的对应特征。例如,如果图块302包括牙齿的一部分和牙龈的一部分,则图块302可能包括牙齿到牙龈界面。作为另一示例,如果图块302包括示出牙冠的臼齿,则图块302可能包括牙冠形状、牙冠大小等。
46.在一些实现中,预训练的图像检测器102被配置成对每个图块302进行分类。例如,来自图像分类器304的输出可以是(例如,作为输入被提供给图像分类器304的)对应图块302的分类(或分类的概率)。在这样的实现中,图像特征图300可以包括具有其对应分类的每一个图块302。预训练的图像检测器102被配置成通过将每个图块302拼接在一起来构造图像特征图300,其中每个图块302包括其相应的分类。就此而言,预训练的图像检测器102被配置成通过将图块302拼接在一起以形成图像特征图300来重构图像106,其中图像特征图300包括图块302和对应的分类。预训练的图像检测器102被配置成提供图像特征图300作为模型生成引擎104的输入。在一些实现中,由预训练的图像检测器102生成的图像特征图300可以是压缩文件(例如,压缩的(zipped)或其他格式)。预训练的图像检测器102可以被配置成将图像特征图300格式化为用于传输到模型生成引擎104的压缩文件。模型生成引擎104可以被配置成解析图像特征图300,以生成对应于图像106的点云,如下面更详细描述的。
47.模型生成系统100被示出为包括模型生成引擎104。模型生成引擎104可以是被设计或实现成从用户牙列的一个或更多个图像106生成用户牙弓的三维(3d)模型的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。模型生成引擎104被配置成使用由预训练的图像检测器102(例如,从用户的移动设备)接收的多个图像106来生成3d模型。模型生成引擎104可以包括处理电路,该处理电路包括一个或更多个处理器和存储器。存储器可以存储各种指令、例程或其他程序,当由处理器执行时,这些指令、例程或其他程序使处理器执行与生成3d模型有关的各种任务。在一些实现中,处理器、存储器、指令、例程、库等的各种子集可以形成引擎。每个引擎可以专用于执行与3d模型的生成相关联的特定任务。一些引擎可以与其他引擎组合。另外,一些引擎可以被分割成多个引擎。
48.模型生成引擎104被示出为包括特征图读取引擎116。特征图读取引擎116可以是被设计或实现成从图像特征图300读取特征的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。特征图读取引擎116可以被设计或实现成格式化、重新格式化或修改从预训练的图像检测器102接收的图像特征图300,以供模型生成引擎104的其他部件使用。例如,在来自预训练的图像检测器102的输出是图像特征图300的压缩文件的情况下,特征图读取引擎116被配置成解压缩该文件,使得图像特征图300可以被模型生成引擎104的其他部件或元件使用。就此而言,特征图读取引擎116被配置成解析从预训练的图像检测器102接收的输出。特征图读取引擎116可以解析输出以识别图块302、图块302的分类、对应于图块302的分类的特征等。特征图读取引擎116被配置成提供图像特征图300作为lstm编码器108的输入,如下面更详细描述的。
49.现在参考图1和图4,模型生成引擎104被示出为包括lstm编码器108和lstm解码器114。具体地,图4是神经网络400的实现的框图,神经网络400可以实现lstm编码器108和/或lstm解码器114内的各种部件、特征或方面。lstm编码器108可以是被设计或实现成使用一个或更多个权重计算图像特征图300的每个特征的概率的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。lstm解码器114可以是被设计或实现成确定来自点云的特征与图像特征图300的特征的(例如,由lstm编码器108计算的)对应概率之间的差的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。lstm编码器108和lstm解码器114可以通信地耦合到彼此,使得一个的输出可以用作另一个的输入。lstm编码器108和lstm解码器114可以协同地工作以细化对应于图像106的点云,如下面更详细描述的。
50.如图4所示,神经网络400包括:包括多个输入节点402a-402c的输入层402、包括多个感知节点404a-404h的多个隐藏层404、以及包括输出节点408的输出层406。输入层402被配置成经由输入节点402a-402c接收一个或更多个输入(例如,图像特征图300、来自lstm解码器114的数据等)。隐藏层404连接到输入层402的输入节点402a-402c中的每一个。隐藏层404中的每一层被配置成基于从其他节点接收的数据执行一个或更多个计算。例如,第一感知节点404a被配置成从输入节点402a-402c中的每一个接收数据作为输入,并通过与输入相乘或以其他方式提供权重来计算输出。如下面更详细描述的,可以在不同时间调整权重以调节输出(例如,某些特征被包括在图块302中的概率)。然后将计算出的输出提供给下一个隐藏层404(例如,提供给感知节点404e-404h),该下一个隐藏层404然后基于来自感知节点404a的输出以及来自感知节点404b-404d的输出来计算新的输出。例如,在在lstm编码器108中实现的神经网络中,隐藏层404可被配置成基于图像特征图300和来自lstm解码器114的数据来计算用户牙列的图像106中某些特征的概率,如下面更详细描述的。例如,隐藏层404可被配置成计算特征的概率,例如牙齿大小、牙齿形状、牙齿位置、牙齿取向、牙冠大小、牙冠形状、牙龈位置、牙龈形状或轮廓、牙齿到牙龈界面位置、邻面区域位置等的概率。这些特征一起描述、表征或以其他方式定义用户的牙列。
51.lstm编码器108被配置成计算每个潜在特征存在于图像106中的概率。lstm编码器108被配置成接收图像特征图300(例如,直接从预训练的图像检测器102接收,或者从特征图读取引擎116间接接收)。lstm编码器108可以是或者可以包括神经网络(例如,类似于图4中描绘的神经网络400),该神经网络被设计或实现成使用图像特征图300计算图像106中潜
在特征的概率。lstm编码器108可以被配置成使用来自lstm解码器114的数据和图像特征图300来计算图像106内的特征的概率。与(例如,用户牙列的)图像或图像106的图块302相关联的每个特征可以具有对应的概率。概率可以是图像106或图块302内存在特定特征的概率或可能性(例如,图像106或图块302内特定牙齿大小、牙齿取向、牙齿到牙龈界面位置等的概率)。例如,神经网络的神经元可以被训练来检测和计算图像106内上述各种潜在特征的概率。可以使用图像和/或图块以及对应于特定特征的标签的训练集、使用来自用户的(例如,验证来自神经网络的输出的)反馈等来训练神经元。
52.作为一个示例,侧切牙可以有几个可能的取向。可以训练lstm编码器108的神经元来计算侧切牙相对于牙龈线的取向的概率。神经元可以(例如,基于来自图像特征图300的特征)检测具有沿着牙弓的唇侧从牙龈线扩展(extend)45
°
的取向的侧切牙。lstm编码器108被配置成计算侧切牙具有从牙龈线扩展45
°
的取向的概率。如下面更详细描述的,在随后的迭代期间,神经元可以具有权重,这些权重被进一步训练以检测具有沿着牙弓的唇侧从牙龈线扩展60
°
的取向的侧切牙,并计算侧切牙具有从牙龈线扩展60
°
的取向的概率。通过多次迭代,基于确定的取向和来自lstm解码器114的反馈,调整、修改或以其他方式训练侧切牙的取向的概率。就此而言,lstm编码器108的神经元具有权重,这些权重随时间被调节、调整、修改或以其他方式训练,以具有长期记忆(例如,通过上面示例中45
°
取向的训练)和短期记忆(例如,通过上面示例中60
°
取向的训练)。
53.因此,神经元被训练来检测牙齿可能有多个可能的特征(例如,牙齿可能有45
°
或60
°
的取向,或者通过其他迭代检测到的其他取向)。这样的实现和实施例通过提供lstm系统来提供更准确的整体3d模型,该整体3d模型更紧密地匹配用户的牙列,该lstm系统被优化以记住来自先前迭代的信息并将该信息作为用于训练神经网络的隐藏层404的权重的反馈而并入,该隐藏层404又(例如,经由输出层406)生成输出,该输出由输出引擎110用于生成输出(例如,3d模型)。在一些实现中,可以用训练集(例如,样本图像)对lstm编码器108和lstm解码器114进行训练。在其他实现中,可以用从用户接收的图像(例如,类似于图像106)对lstm编码器108和lstm解码器114进行训练。在任一实现中,lstm编码器108和lstm解码器114可被训练以检测用户牙弓的图像内的一大组潜在特征(例如,用户牙列内牙齿的各种取向、大小等)。这样的实现可以提供鲁棒的lstm系统,通过该lstm系统,lstm编码器108可以计算给定图像包含某些特征的概率。
54.返回参考图1,lstm编码器108被配置成基于输入(例如,图像特征图300和来自lstm解码器114的输入,下面进行了更详细地描述)和来自lstm编码器108的神经网络的权重来生成每个特征的多个概率的输出。对应于lstm编码器108的神经网络的输出层406被配置成输出由隐藏层404计算的概率中的至少一些。输出层406可以被配置成输出每个概率、概率的子集(例如,最高的一些概率)等。输出层406被配置成向写解码器(write decoder)118传输、发送或以其他方式提供概率。
55.写解码器118可以是被设计或实现成维护由lstm编码器108计算的概率中的每一个的列表的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。写解码器118被配置成从lstm编码器108(例如,从对应于lstm编码器108的神经网络的输出层406)接收输出。在一些实现中,写解码器118维护分类账(ledger)、数据库或者(例如,在系统100内部或外部的)其他数据结构中的概率。当lstm编码器108在随后的迭代期间使用更新的权重
重新计算概率时,写解码器118可以更新数据结构以针对过程的每次迭代维护图像106内每个特征的计算概率的列表或分类账。
56.输出引擎110可以是被设计或实现成生成点云500的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。图5a-图5c分别是覆盖在上牙弓504a和下牙弓504b上的示例点云500的图示,以及彼此对齐的上牙弓和下牙弓的点云500的透视图。图5a-图5c中所示的点云500由输出引擎110生成。输出引擎110可以被配置成使用由预训练的图像检测器102接收的图像106来生成点云500。如下面更详细描述的,输出引擎110可以被配置成使用图像106中的一个或更多个图像内的特征的概率来生成用户牙弓的点云500。在一些实例中,输出引擎110可被配置成使用图像106之一内的特征的概率来生成牙弓的点云500。例如,输出引擎110可以被配置成使用用户的上牙弓的上部打开视图的图像(例如,诸如图2c中所示的图像)来生成上牙弓504a的点云500。在一些实例中,输出引擎110可以被配置成使用两个或更多个图像(例如,在图2b和图2c中示出的图像、在图2a-图2c中示出的图像或其他图像)来生成上牙弓504a的点云500。在一些实例中,输出引擎110可以被配置成使用一个图像(例如,图2a中所示的图像)、多个图像(例如,图2a-图2b中所示的图像、图2a-图2c中所示的图像)等来生成下牙弓504b的点云500。输出引擎110可以被配置成组合针对上牙弓504a和下牙弓504b生成的点云500以生成点云500(如图5c中所示,其对应于用户的口腔)。输出引擎110可以使用图像106中的每一个来对齐上牙弓504a和下牙弓504b的点云。
57.输出引擎110被配置成基于经由写解码器118的来自lstm编码器108的数据生成点云500。输出引擎110被配置成解析由lstm编码器108生成的概率,以生成点云500的对应于图像106内的特征的点502。使用前面的示例,lstm编码器108可以确定侧切牙的取向的最高概率是沿唇侧偏离牙龈线45
°
。输出引擎110可以生成点云500的对应于侧切牙的点502,该侧切牙具有沿唇侧偏离牙龈线45
°
的取向。输出引擎110被配置成生成3d空间中的点502,这些点502对应于具有如lstm编码器108所确定的最高概率的特征,其中点502沿着用户牙列的外表面定位。在一些实例中,输出引擎110可以在3d空间内与图像106的最高概率特征对齐的各个位置处生成点502。每个点502可以在映射到图像中的特征位置的位置处位于3d空间内。因此,输出引擎110可以被配置成生成点云500的点502,这些点匹配图像106中特征的概率(例如,使得点云500的点502基本上匹配如基于概率确定的用户牙列的轮廓)。输出引擎110被配置成将点云500提供给点云特征提取器112。
58.点云特征提取器112可以是被设计或实现成确定点云500内的一个或更多个特征的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。点云特征提取器112可以被配置成从点云500计算、提取或以其他方式确定一个或更多个特征,以生成图像特征图(例如,类似于由lstm编码器108接收的图像特征图)。点云特征提取器112可以利用一个或更多个外部架构、库或用于从点云500生成图像特征图的其他软件。在一些实现中,点云特征提取器112可以利用pointnet架构从点云500提取特征向量。就此而言,图像106(例如,被预训练的图像检测器102)用于生成图像特征图300,该图像特征图300(例如,被lstm编码器108和输出引擎110)用于生成点云500,点云500又(例如,被点云特征提取器112)用于提取特征。点云特征提取器112被配置成向lstm解码器114传输、发送或以其他方式提供从点云500提取的特征。
59.lstm解码器114被配置成(例如,作为输入)接收来自点云特征提取器112的所提取
的特征和由lstm编码器108计算的特征的概率。lstm解码器114被配置为基于所提取的特征和概率来计算lstm编码器108的输出与点云500之间的差。在一些实现中,lstm解码器114被配置成使用从点云500提取的特征和来自图像特征图300的每个特征的对应概率来计算损失函数。lstm解码器114可以被配置成确定从点云500提取的哪些特征对应于图像特征图300内的特征。lstm解码器114可以通过比较(例如,从点云500中提取的和在图像特征图300中识别出的)每个特征来确定哪些特征彼此最紧密匹配,从而确定哪些特征彼此对应。lstm解码器114可以基于点云500的点的坐标和图像特征图300中图块302的相关位置(例如,位于图块302之一内的坐标、其中点对应于特定图块302的3d空间的特定区域等)来确定哪些特征彼此对应。
60.一旦两个特征(例如,被lstm解码器114)确定为彼此对应,lstm解码器114比较对应的特征以确定差。例如,在特征被确定为特定牙齿的取向的情况下,lstm解码器114被配置成比较来自图像106的特征的取向和来自点云500的取向。lstm解码器114被配置成比较这些取向以确定在点云500中表示的特征是否与在图像106中识别出的特征匹配(例如,相同的取向)。在一些实现中,lstm解码器114被配置成通过计算损失函数(例如,使用来自点云500的点502和来自图像特征图300的对应特征)来确定差。损失函数可以是两点(例如,点云500的点502和来自图像特征图300的对应特征)之间距离的计算。随着损失函数值增大,点云500相应地不那么准确(例如,因为点云500的点502与图像特征图300的特征不匹配)。相应地,随着损失函数值减小,点云500更加准确(例如,因为点云500的点502更加紧密地匹配图像特征图300的特征)。lstm解码器114可以(例如,直接地或通过读解码器(read decoder)120)向lstm编码器108提供计算出的损失函数、特征之间的差等,以便lstm编码器108基于来自lstm解码器114的反馈来调整、调节或以其他方式修改用于计算概率的权重。在lstm解码器114被配置成通过读解码器120向lstm编码器108提供数据的实现中,读解码器120(例如,类似于写解码器118)被配置成处理来自lstm解码器114的数据,以记录用于调整lstm编码器108的权重的差。
61.在后续迭代期间,lstm编码器108被配置成基于来自lstm解码器114的反馈来修改、细化、调节或以其他方式调整神经网络400的权重。lstm编码器108然后可以计算图像106中特征的新概率,然后输出引擎110使用该新概率生成点云500的点。因此,lstm解码器114和lstm编码器108协作地调整用于形成点云500的权重,以使点云500与在图像106中识别出的特征更紧密地匹配。在一些实现中,lstm编码器108和lstm解码器114可以执行多次迭代。迭代数量可以是预定的迭代数量(例如,2次迭代、5次迭代、10次迭代、50次迭代、100次迭代、200次迭代、500次迭代、1000次迭代、2000次迭代、5000次迭代、8000次迭代、1万次迭代、10万次迭代等)。在一些实现中,迭代数量可以在由模型生成系统100生成的模型之间(例如,基于用户选择、基于反馈、基于最小化或损失函数或其他算法等)变化。例如,在lstm解码器114基于来自点云500的特征与由lstm编码器108计算的概率之间的差计算损失函数的情况下,迭代数量可以是取决于损失函数满足阈值的次数的可变数量。因此,lstm编码器108可以基于来自lstm解码器114的反馈迭代地调整权重,直到计算出的损失函数值满足阈值(例如,为0.05mm、0.1mm、0.15mm、0.2mm、0.25mm等的平均值)。在最终迭代之后,输出引擎110被配置成提供点云500的最终迭代。
62.在一些实现中,输出引擎110被配置成将点云500与用户牙列的另一个点云或数字
模型合并。例如,输出引擎110可被配置成从第一数字模型(例如,点云500)和第二数字模型(例如,用户牙列的扫描、用户牙列的牙印模的扫描等)生成合并的模型。在一些实现中,输出引擎110被配置成使用如2019年8月22日提交第16/548,712号美国专利申请中描述的至少一些方面将点云500与另一3d模型合并,该专利申请的内容通过引用以其整体并入本文。
63.点云500可用于制造特定于用户的牙齿矫正器,并且被配置成重新定位用户的一颗或更多颗牙齿。输出引擎110可以被配置成将点云500提供给一个或更多个外部系统以用于生成牙齿矫正器。例如,输出引擎110可以将点云500传输到3d打印机以使用点云打印阳模(positive mold)。可以将材料热成形到阳模上以形成牙齿矫正器的形状,并且牙齿矫正器可以从阳模切割。作为另一示例,输出引擎110可将点云500传输到3d打印机以直接打印牙齿矫正器。
64.现在参考图6,示出了根据说明性实施例的从一个或更多个二维图像生成三维模型的方法600的示意图。方法600可以通过上面参考图1-图5描述的一个或更多个部件来实现。作为概述,在步骤602,模型生成系统100接收用户口腔的一个或更多个图像106。在步骤604,模型生成系统100从一个或更多个图像106生成点云500。在步骤606,模型生成系统从点云500生成三维(3d)模型。在步骤608,基于3d模型制造牙齿矫正器。
65.在步骤602,模型生成系统100接收用户口腔的一个或更多个图像106。图像106可以由用户捕获。用户可以使用至少部分定位在用户口腔中的牙科器具200来捕获用户口腔的图像106。在一些实现中,指示用户如何捕获图像106。可以指示用户拍摄至少三个图像106。图像106可以类似于图2a-图2c中所示的图像。用户可以在他们的移动设备或具有相机的任何其他设备上捕获图像106。用户可以将图像106上传、传输、发送或以其他方式提供给模型生成系统100(例如,经由基于互联网的门户、经由网站等上传、传输、发送或以其他方式提供给与模型生成系统100相关联的电子邮件或帐户)。模型生成系统100(例如,从用户的移动设备)接收图像106。模型生成系统100使用图像106来生成用户口腔的3d模型,如下面更详细描述的。
66.在步骤604,模型生成系统100从一个或更多个图像生成点云500。在一些实施例中,模型生成系统100基于来自用户牙弓的(例如,在步骤602接收的)一个或更多个图像106的数据生成点云500。模型生成系统100可以解析图像106以生成图像特征图300。模型生成系统100可以计算图像特征图300的特征的概率。模型生成系统100可以使用图像特征图300的特征的概率来生成点云500。模型生成系统100可以确定点云500的特征。模型生成系统100可以确定点云的特征与图像特征图的特征的对应概率之间的差。模型生成系统100可以训练用于计算概率的权重。模型生成系统100可以迭代地细化点云500,直到满足预定条件。下面参考图7更详细地描述其中模型生成系统100生成点云500的各个方面。
67.在步骤606,模型生成系统100生成三维(3d)模型。模型生成系统100生成用户口腔的3d模型(例如,用户的上牙弓和下牙弓的3d模型)。在一些实施例中,模型生成系统100生成用户的上牙弓的第一3d模型和用户的下牙弓的第二3d模型。模型生成系统100可以使用(例如,在步骤604)生成的点云500来生成3d模型。在一些实施例中,模型生成系统100通过将上牙弓的点云500和下牙弓的点云500转换成立体光刻(stl)文件来生成3d模型,其中stl文件是3d模型。在一些实施例中,模型生成系统100使用3d模型来生成合并模型。模型生成系统100可以将基于点云500生成的3d模型(例如,在步骤606)与另一3d模型(例如,与通过
扫描用户牙列生成的3d模型、与通过扫描用户牙列的印模生成的3d模型、与通过扫描基于用户牙列的印模制作的用户牙列的物理模型生成的3d模型等)合并,以生成合并的(或复合)模型。
68.在步骤608,基于3d模型制造牙齿矫正器。在一些实施例中,制造系统至少部分地基于用户口腔的3d模型制造牙齿矫正器。制造系统通过接收与由模型生成系统100生成的3d模型相对应的数据来制造牙齿矫正器。制造系统可以使用由模型生成系统100生成的3d模型来(例如,在步骤608)制造牙齿矫正器。制造系统可以通过3d打印基于3d模型的物理模型、将材料热成形到物理模型、以及从物理模型切割材料以形成牙齿矫正器来制造牙齿矫正器。制造系统可以通过使用3d模型3d打印牙齿矫正器来制造牙齿矫正器。在任何实施例中,牙齿矫正器是特定于用户的(例如,与用户的牙列接合),并且被配置成重新定位用户的一颗或更多颗牙齿。
69.现在参考图7,示出了根据说明性实施例的从一个或更多个二维图像106生成点云500的方法700的示意图。方法700可以通过上面参考图1-图5c描述的一个或更多个部件来实现。作为概述,在步骤702,模型生成系统100使用一个或更多个图像生成图像特征图300。在步骤704,模型生成系统100计算图像特征图300中每个特征的概率。在步骤706,模型生成系统100生成点云500。在步骤708,模型生成系统100确定点云500的特征。在步骤710,模型生成系统100确定点云的特征与图像特征图300的特征之间的差。在步骤712,模型生成系统100训练用于计算概率的权重。在步骤714,模型生成系统100确定是否满足预定条件。在不满足预定条件的情况下,方法700循环回到步骤704。在满足预定条件的情况下,在步骤716,模型生成系统100输出点云的最终迭代。
70.在步骤702,模型生成系统100从一个或更多个图像106生成图像特征图300。在一些实施例中,模型生成系统100的预训练的图像检测器102从(例如,在图6的步骤602接收的)图像106生成图像特征图300。图像特征图300可以包括图像106的多个部分的分类。每个分类可以对应于将要在点云中表示的图像106的相应部分内的特征。
71.在一些实施例中,预训练的图像检测器102可以接收用户口腔的图像106。预训练的图像检测器102对从用户的移动设备接收的图像106进行划分。预训练的图像检测器102可以将图像106划分成预定大小的部分。例如,预训练的图像检测器102可以将图像106划分成图块302。图块302可以是图像106的相同大小的部分。对应于图像106的多个图块302可以一起形成图像106。预训练的图像检测器102可以确定图像106的每个部分(例如,对应于图像106的每个图块302)的分类。预训练的图像检测器102可以通过解析图像106的每个部分来确定分类。预训练的图像检测器102可以通过利用一个或更多个架构(例如mobilenet架构)来解析图像106的部分。在一些实现中,预训练的图像检测器102可包括图像分类器304,该图像分类器304可以被实施为神经网络。图像分类器304可以包括输入层(例如,其被配置成接收图块302)、包括各种预训练的权重的一个或更多个隐藏层以及输出层。图像分类器304可以基于预训练的权重对每个图块302进行分类。各个图块302的每种分类可对应于相关特征。预训练的图像检测器102可以使用包括其相应分类的图像106的部分的分来生成图像特征图300。例如,在由图像分类器304对图块302进行分类之后,预训练的图像检测器102可以将图像106重构为图像特征图300(例如,通过将图块302拼接在一起以形成图像特征图300)。
72.在步骤704,模型生成系统100计算图像特征图300中的特征的概率。在一些实施例中,模型生成系统100的lstm编码器108计算概率。lstm编码器108可以使用一个或更多个权重计算图像特征图300的每个特征的概率。lstm编码器108接收(例如,在步骤604生成的)图像特征图300。lstm编码器108解析图像特征图300以计算图像特征图300中存在的特征的概率。lstm编码器108可以被实施为包括具有权重的一个或更多个节点的神经网络,这些权重被调节以检测图像特征图300中的某些特征。神经网络的输出可以是图像特征图中对应特征的概率。lstm编码器108可以被调节以使用图像特征图300来检测和计算图像106中潜在特征的概率。
73.在步骤706,模型生成系统100生成点云500。在一些实施例中,模型生成系统100的输出引擎110可以使用(例如,在步骤702计算的)概率生成点云500。输出引擎110基于来自lstm编码器108的数据生成点云500。输出引擎110可以使用最高的概率生成点云500。例如,输出引擎110可以通过解析与图像106的每个特征的概率相对应的数据来生成点云500。每个特征可以包括对应的概率。输出引擎110可以(例如,基于哪个概率最高)识别出图像106的最可能的特征。输出引擎110可以使用图像106的最可能的特征生成点云500。点云500包括共同定义3d模型的表面轮廓的多个点。表面轮廓可以跟随用户牙弓的表面,使得点云500匹配、镜像或以其他方式表示用户的牙弓。
74.在步骤708,模型生成系统100确定点云500的特征。在一些实施例中,模型生成系统100的点云特征提取器112从由输出引擎110(例如,在步骤706)生成的点云500中确定一个或更多个特征。点云特征提取器112可以处理点云500,以从点云500的点识别出特征。点云特征提取器112可以独立于由lstm编码器108计算的概率和/或图像特征图300来处理点云500。就此而言,点云特征提取器112在没有来自lstm编码器108的反馈的情况下从点云500确定特征。点云特征提取器112可以利用来自一个或更多个架构或库(例如pointnet架构)的数据来从点云确定特征。
75.在步骤710,模型生成系统100确定(例如,在步骤708确定的)点云500的特征与(例如,在步骤702生成的)图像特征图300的特征之间的差。在一些实施例中,模型生成系统100的lstm解码器114确定由点云特征提取器112确定的特征与来自图像特征图300的对应特征之间的差。lstm解码器114可以对由点云特征提取器112(例如,基于点云500)确定的特征和来自图像特征图300的对应特征(例如,由lstm编码器108计算的特征的概率)进行比较。lstm解码器114可以比较特征以确定由输出引擎110计算的点云500与图像特征图300相比有多准确。
76.在一些实施例中,lstm解码器114可以使用(例如,由点云特征提取器112)从点云500提取的特征和图像特征图300的每个特征的对应概率来计算损失函数。lstm解码器114可以基于损失函数来确定差。lstm编码器108可以训练权重(在下面更详细地描述)以使由lstm解码器114计算的损失函数最小化。
77.在步骤712,模型生成系统100训练权重用于计算概率(例如,在步骤704使用的权重)。在一些实施例中,模型生成系统100的lstm编码器108训练一个或更多个权重,用于基于所确定的差(例如,在步骤710被确定)计算概率。lstm编码器108可以调节、调整、修改或以其他方式训练用于计算图像特征图300的特征概率的神经网络的权重。lstm编码器108可以使用来自lstm解码器114的反馈来训练权重。例如,在lstm解码器114计算图像特征图300
的对应特征和从点云500提取的特征的损失函数的情况下,lstm解码器114可以将损失函数值提供给lstm编码器108。lstm编码器108可基于反馈(例如,针对该特定特征)相应地训练神经网络节点的权重。lstm编码器108可以训练神经网络的节点的权重以最小化损失函数或以其他方式限制点云500的特征与图像特征图300的特征之间的差。
78.在步骤714,模型生成系统100确定是否符合或满足预定条件。在一些实施例中,预定条件可以是步骤704-712将被重复的预定或预先设置的迭代数量。迭代数量可以由用户、操作员或牙齿矫正器的制造商设置,可以基于优化函数进行训练,等等。在一些实施例中,预定条件可以是损失函数满足阈值。例如,模型生成系统100可以重复步骤704-712,直到由lstm解码器114计算的损失函数值满足阈值(例如,损失函数值小于0.1mm)。在模型生成系统100确定不满足预定条件的情况下,方法700可循环回到步骤704。在模型生成系统100确定满足预定条件的情况下,方法700可以进行到步骤716。
79.在步骤716,模型生成系统100输出点云500的最终迭代。在一些实施例中,模型生成系统100的输出引擎110可以输出点云500。输出引擎110可以输出用于用户的上牙弓的点云500和用于用户的下牙弓的点云500。这样的点云500可用于生成3d模型,该3d模型又可用于制造用于用户的上牙弓和下牙弓的牙齿矫正器,如上面在图6中所描述的。
80.现在参考图8,示出了根据说明性实施例的用于从一个或更多个2d图像生成3d模型的系统800的另一实施例的框图。系统800被示出为包括模型训练系统802和模型生成系统824。如下面关于图8-图13更详细地描述的,模型训练系统802可以被配置成基于训练集来训练机器学习模型822,该训练集包括一个或更多个训练图像804、3d训练模型806、以及图像804和3d训练模型806之间的多个相关点816。模型生成系统824可以被配置成将机器学习模型822应用于(例如,从用户设备826接收的)一个或更多个用户图像828以生成3d模型830。系统800可以包括类似于上面参考图1描述的那些元件的元件。例如,模型生成系统824可以包括预训练的图像检测器102,该预训练的图像检测器102被配置成处理从用户接收的图像。类似地,模型生成系统824可以包括输出引擎110,该输出引擎110被配置成将从用户接收的图像应用于机器学习模型822以生成3d模型830(其可以是或者包括如上文参考图1-图7所描述的点云,可以是用于立体光刻、网格(mesh)或其他形式的3d模型的标准三角语言(stl)文件)。
81.系统800被示出为包括模型训练系统802。模型训练系统802可以是被设计或实现为生成、配置、训练或以其他方式提供用于从一个或更多个用户图像生成3d模型的机器学习模型822的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。模型训练系统802可以被配置成接收一个或更多个训练图像804和对应的3d训练模型806。在一些实施例中,模型训练系统802可以被配置成从存储多个图像和相关3d模型的数据源接收训练图像804和3d训练模型806。训练图像804可以是由患者或顾客捕获的图像(如上面参考图1-图2c所描述的)。训练图像804可以是由患者或顾客的牙科专业人员在(例如,经由牙印模或患者牙列的3d扫描)捕获患者牙列的3d表示时捕获的图像。3d训练模型806可以是患者牙列的3d表示。可以通过(例如,经由3d扫描设备)扫描患者的牙列来捕获3d训练模型806。可以通过扫描患者牙列的表示(例如,通过扫描患者牙列的牙印模、通过扫描从患者牙列的牙印模铸造的物理模型等)来捕获3d训练模型806。每个图像804可以对应于相应的训练模型806。例如,对于用户牙弓的给定的3d训练模型806,模型训练系统802可以被配置成接收用
户牙弓的一个或更多个2d训练图像804。因此,对于给定的3d训练模型806,一个或更多个2d训练图像804和3d训练模型806都可以表示公共牙弓。
82.模型训练系统802被示出为包括数据摄取引擎(data ingestion engine)808。数据摄取引擎808可以是被设计或实现成摄取训练图像804和3d训练模型806的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。在一些实施例中,数据摄取引擎808可以被配置成选择训练图像804的子集,以用于训练机器学习模型822。数据摄取引擎808可以被配置成基于所确定的图像质量来选择训练图像804的子集。例如,数据摄取引擎808可以包括上面参考图1所描述的预训练的图像检测器102的一个或更多个方面或特征。在一些实施例中,数据摄取引擎808可以被配置成摄取一系列训练图像804,例如包括多个帧的视频,其中每个帧是一系列训练图像804中的一个。数据摄取引擎808可以被配置成(例如,基于如上关于图1所描述的所确定的帧质量)选择一系列训练图像804的子集以用于训练机器学习模型822。数据摄取引擎808可以被配置成(例如,自动地)选择一系列训练图像804以包括具有预定视角(例如图2a-图2c中所示的视角)的多个训练图像804。数据摄取引擎808可以被配置成选择具有预定视角的一系列训练图像804。数据摄取引擎808可以被配置成(例如,使用机器学习模型)自动地选择被训练用来检测训练图像中的预定视角的一系列训练图像804。例如,机器学习模型可以是2d分割模型,其被配置或训练成自动识别图像中的各颗牙齿,并(例如,基于图像中表示的各颗牙齿)确定该图像是否适合包括在训练集中。在一些实施例中,数据摄取引擎808可以被配置成从计算设备(例如下面更详细描述的计算设备810)接收对训练图像804的选择。在一些实施例中,数据摄取引擎808可以被配置成从照片捕获应用接收训练图像804,照片捕获应用被配置成捕获适合于训练集的图像。
83.在一些实施例中,数据摄取引擎808可以被配置成处理3d训练模型806(例如,以生成修改的3d训练模型)。例如,3d训练模型806可以是初始训练模型,其包括与患者的上牙弓和下牙弓的3d表示相对应的数据。如下面参考图9和图13更详细描述的,数据摄取引擎808可被配置成接收初始训练模型,并通过将上牙弓的3d表示与下牙弓的3d表示分离,并移除相应牙弓中牙龈的3d表示来生成最终3d训练模型,从而使得最终3d训练模型包括多颗上(或下)牙的3d表示。
84.在一些实施例中,数据摄取引擎808可以被配置成生成对应于训练图像804和相关联的3d训练模型806的元数据文件。元数据文件可以是或者可以包括将用户的一组训练图像804与该组训练图像804中表示的用户牙列的3d训练模型806关联或链接起来的数据。数据摄取引擎808可以被配置成在处理训练图像804和相关联的3d训练模型806以生成训练集812的对应数据分组814(或数据点、数据包或其他结构化数据)时维护元数据文件,如下面更详细描述的。在一些实施例中,元数据文件可以包括对应于训练图像804和/或用于捕获图像的设备的数据。例如,元数据文件可以包括与以下项相对应的数据:训练图像804的图像对比度、训练图像804的焦点、训练图像804的像素大小、训练图像804的归一化因子、训练图像804的缩放、手机或相机类型、手机或相机型号、照片取向等。这些数据可以用于跨训练集812对训练图像804进行标准化。
85.模型训练系统802被示出为包括计算设备810。计算设备810可以被配置成确定、生成或以其他方式识别训练图像804和3d训练模型806之间的相关点816。相关点816可以是在训练图像804和3d训练模型806中共同表示的点。例如,相关点816可以是位于牙齿牙冠上的
点,该点在训练图像803和3d训练模型806两者中被描绘、示出或以其他方式表示。在一些实施例中,计算设备810可以是或者可以包括模型训练系统802的一个或更多个处理器和存储器,其被配置成自动生成相关点816。在一些实施例中,计算设备810可以是被配置成接收对相关点816的选择的计算机(例如,台式机、膝上型计算机或其他计算机)。计算设备810可以被配置成使用相关点816来建立用于训练机器学习模型822的训练集812的数据分组814,如下面更详细描述的。在一些实施例中,计算设备810可以被配置成用相关点816更新元数据文件。
86.计算设备810(或模型训练系统802的一个或更多个其他设备、部件或引擎)可以被配置成生成、建立、填充或以其他方式提供训练集812。训练集812可以包括多个数据分组814。数据分组814中的每一个可以包括训练图像804和相关联的3d训练模型806,以及训练图像804和相关联的3d训练模型806之间的相关点816。因此,多个数据分组814中的每个数据分组814可以表示用于训练机器学习模型822的相应牙弓。训练集812可以包括针对多个不同用户和针对多个不同牙弓的数据分组814。因此,每个数据分组814可以包括表示唯一牙弓的数据。
87.计算设备810可以被配置成生成、建立或以其他方式提供用于生成机器学习模型822的一个或更多个配置参数818。在一些实施例中,配置参数818可以通过用户(例如技术人员)操作计算设备810以调节机器学习模型822的训练来自动设置。用户可以基于来自机器学习模型822的输出来调节机器学习模型822的训练。在一些实施例中,计算设备810可以被配置成自动生成配置参数818。计算设备810可基于模型评估界面(例如图17中所示的那些界面)自动生成配置参数818。用于自动或手动生成配置参数818的各种示例包括由机器学习模型822生成的3d模型(与实际3d模型相比)的准确性、机器学习模型822生成3d模型的处理时间等。
88.计算设备810可以被配置成将配置参数818提供给机器学习训练引擎820,用于生成机器学习模型822。在一些实施例中,配置参数818可以包括迭代数量,机器学习训练引擎820在这些迭代中被执行以使用训练集812训练机器学习模型822。在一些实施例中,配置参数818可以包括由机器学习训练引擎820使用的一组超参数的损失权重。计算设备810可以被配置成向机器学习训练引擎820发送、传输或以其他方式提供配置参数(例如,与训练集812一起),以用于训练机器学习模型822。
89.模型训练系统802被示出为包括机器学习训练引擎820。机器学习训练引擎820可以是被设计或实现为生成、配置、训练或以其他方式提供用于从一个或更多个用户图像生成3d模型的机器学习模型822的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。机器学习训练引擎820可以被配置成(例如,从计算设备810和/或从模型训练系统802的另一设备或部件)接收训练集812和配置参数818以生成机器学习模型822。在一些实施例中,机器学习训练引擎820在一些方面可以类似于上面关于图1描述的模型生成引擎104。在一些实施例中,机器学习训练引擎820可以类似于或结合来自网格r-cnn训练系统的特征,该网格r-cnn训练系统例如是georgia gkioxari、jitendra malik和justin johnson在“mesh r-cnn”(mesh r-cnn,facebook ai research(fair),2020年1月25日)(其内容通过引用以其整体并入)中描述的系统。机器学习训练引擎820可以被配置成生成机器学习模型822,以用于根据用户(例如将要接受或正在接受牙科治疗的患者)的牙弓的图像生成3d
模型,如下面更详细描述的。下面关于图9到图13更详细地描述对应于模型训练系统802的另外的细节。
90.系统800被示出为包括模型生成系统824。模型生成系统824可以是或者可以包括被设计或实现成从接收自用户设备826的一组2d图像828生成3d模型830的任何设备、部件、应用、元件、脚本、电路或软件和/或硬件的其他组合。模型生成系统824可以包括或者利用由机器学习训练引擎820生成的机器学习模型822,以用于生成3d模型830。
91.模型生成系统824可以被配置成从用户设备826接收一个或更多个用户图像828。用户设备826可以是移动设备(例如,智能手机、平板电脑等)。在一些实施例中,用户设备826可以与用户(例如,在用户图像828中描绘的用户)相关联。在一些实施例中,用户设备826可以是通用设备(例如,用于例如在口腔内扫描位置、牙科诊室或医务室等处捕获多个用户的图像828的设备)。用户设备826可以是计算设备(例如,类似于上面描述的计算设备810)。用户设备826可以被配置成生成、捕获或以其他方式向模型生成系统824提供用户图像828。在一些实施例中,用户设备826可以被配置成通过将图像828上传到由模型生成系统824维护或以其他方式与模型生成系统824相关联的门户,来将用户图像828提供给模型生成系统824。在一些实施例中,用户设备826可以被配置成通过将图像828传输到与模型生成系统824相关联的地址(例如,与托管模型生成系统824的服务器相关联的ip地址、与链接到模型生成系统824的帐户相关联的电子邮件地址等)来向模型生成系统824提供用户图像828。一个或更多个用户图像828可以表示公共牙弓。在一些实施例中,该一个或更多个图像在某个方面可以类似于上述图2a-图2c中所示的图像。在一些实例中,用户图像828可以由用户牙弓的用户捕获。在一些实例中,用户图像828可由另一用户牙弓的用户捕获。在任一实例中,用户图像828可以表示公共牙弓,并且可以用于生成图像中表示的牙弓的3d模型830。
92.模型生成系统824被示出为包括(例如,由机器学习训练引擎820生成或以其他方式训练的)机器学习模型822。模型生成系统824可以被配置成将接收到的用户图像828传输、发送或以其他方式提供给机器学习模型822,以生成在用户图像828中表示的牙弓的3d模型830。模型生成系统824可以被配置成通过提供用户图像828作为对机器学习模型822的输入来执行机器学习模型822的实例。机器学习模型822可以被配置成基于用户图像828生成牙弓的3d模型830作为输出。在一些实施例中,机器学习模型822可以被配置成生成包括在相应图像828中的牙弓的每个视角的多个3d模型。机器学习模型822可以被配置成将牙弓的每个视角的多个3d模型拼接在一起,以建立、生成或以其他方式形成3d模型830作为输出。
93.3d模型830可用于生成、构造或以其他方式制造一个或更多个牙齿矫正器,如上面参考图1-图6所描述的。例如,在一些实施例中,制造系统至少部分地基于用户牙弓的3d模型830来制造牙齿矫正器。制造系统可以通过接收与由模型生成系统824生成的3d模型830相对应的数据来制造牙齿矫正器。制造系统可以通过3d打印基于3d模型830的物理模型、将材料热成形到物理模型、以及从物理模型切割材料以形成牙齿矫正器来制造牙齿矫正器。制造系统可以通过使用3d模型830来3d打印牙齿矫正器从而制造牙齿矫正器。在这些或其他实施例中,牙齿矫正器是特定于用户的,并且被配置成重新定位用户的一颗或更多颗牙齿。
94.在一些实施例中,3d模型830可用于跟踪患者的牙齿矫正器治疗的进展。例如,可以使用牙齿矫正器治疗患者,以在不同阶段将患者的牙齿从(例如,治疗之前的)初始位置移动到(例如,治疗之后的)最终位置。在治疗期间,患者的牙齿可以从(例如,在治疗计划的第一阶段的)初始位置移动到(例如,在治疗计划的一个或更多个中间阶段的)一个或更多个中间位置,并移动到(例如,在治疗计划的最终阶段的)最终位置。每个治疗阶段可以在患者文件中被表示为目标3d模型(例如,表示第一治疗阶段的第一3d模型、表示中间治疗阶段的一个或更多个中间3d模型以及表示最终治疗阶段的最终3d模型)。在每个阶段,患者可以施用被配置成将患者牙齿从当前治疗阶段移动到后续治疗阶段的一系列牙齿矫正器中的一个。
95.在一些实现中,患者可以在完成一个阶段的治疗之后上传用户图像828。例如,可以提示患者以各种间隔(例如,每天、每周、每两周、在一个治疗阶段完成之后、在经由牙齿矫正器进行治疗之后的每六个月或每年、每当患者请求检查他们的进展时,等等)上传图像828。可以提示患者上传图像828,以确保患者的牙齿根据治疗计划进展,或者确保患者的牙齿没有回复到经由牙齿矫正器进行治疗之前的位置。模型生成系统824可以被配置成基于用户图像828生成3d模型830。然后,可以将3d模型830与包括在患者文件中的3d模型进行比较,以确定患者的牙齿是否根据患者的治疗计划移动。患者文件可以包括针对每个治疗阶段的3d模型(例如,对应于初始治疗阶段的初始3d模型、对应于中间治疗阶段的一个或更多个中间3d模型、以及对应于最终治疗阶段的最终3d模型)。可以将由模型生成系统824生成的3d模型830与来自患者文件的3d模型进行比较。例如,在从用户图像828生成的3d模型830与患者文件中包括的对应于治疗计划的特定阶段的3d模型相匹配(或基本上匹配)的情况下,可以确定患者正在根据治疗计划进展,因为患者的牙齿正在根据治疗计划中定义的进展从治疗前的初始位置移动到治疗之后的一个或更多个中间位置并且移动到最终位置。然而,在从用户图像828生成的3d模型830与患者文件中包括的对应于治疗计划的特定阶段的3d模型不匹配(或基本上不匹配)的情况下,可以确定患者没有根据治疗计划进展。这样的实施例可以提供对治疗计划的中途校正(mid-course correction)需求的早期开始识别。例如,当确定患者没有根据治疗计划进展时,可以标记患者文件以从患者的当前牙齿位置生成新的治疗计划(以及相对应地,根据新的治疗计划生成新的牙齿矫正器)。作为另一个示例,当确定患者没有根据治疗计划进展时,可以提示患者跳过一个或更多个矫正器(例如,在患者进展快于治疗计划下的预期或预测的情况下,提前到治疗的另一个阶段),不按顺序地使用特定矫正器,使得患者的牙齿根据治疗计划移动回正确的方向。
96.在一些实施例中,3d模型830可以在用户界面上被渲染并向用户回放显示。例如,模型生成系统824可以被配置成向用户设备826传输、发送或以其他方式提供3d模型830,以供向用户渲染。在一些实施例中,模型生成系统824可以被配置成生成用于在用户设备826处显示的用户界面。用户界面可以包括例如基于用户图像828生成的3d模型830。在一些实施例中,用户界面可以包括另一3d模型。例如,用户界面可以包括基于用户图像828生成的3d模型830和预期的3d模型(例如,来自患者文件的对应于当前治疗阶段的3d模型)。这样的实施例可以允许用户与对应于治疗的目标3d模型相比较地来跟踪他们的进展。作为另一示例,用户界面可包括3d模型830和前一个(和/或下一个)3d模型。前一个3d模型可以是来自患者文件的对应于治疗计划的前一个阶段的3d模型。前一个3d模型可以是从先前用户图像
828生成的3d模型。下一个3d模型可以是来自患者文件的对应于治疗计划的下一个阶段的3d模型。用户可以查看前一个3d模型、当前3d模型830和/或下一个3d模型以示出患者治疗的进展。
97.现在参考图9,示出了流程图,该流程图示出了训练机器学习模型822的示例方法900。方法900可以由上面参考图8描述的部件中的一个或更多个(例如模型训练系统802)来执行。作为简要概述,在步骤902,模型训练系统802捕获数据(例如训练图像804和3d训练模型806)。在步骤904,模型训练系统802处理捕获的数据。在步骤906,模型训练系统802为经处理的数据生成元数据。在步骤908,模型训练系统802执行掩模推断(mask inference),并且在步骤910,模型训练系统802处理掩模推断。在步骤912,模型训练系统802标记2d到3d相关点816。在步骤914,模型训练系统802计算估计的姿势。在步骤916,模型训练系统802执行数据格式化。在步骤918,模型训练系统802处理3d模型806。在步骤920,模型训练系统802训练机器学习模型822。下面将结合图10-图13参考图8和图9来更详细地描述这些步骤。
98.在步骤902,模型训练系统802接收数据(例如训练图像804和3d训练模型806)。在一些实施例中,模型训练系统802可以从存储多个图像和对应的3d模型的数据结构或源接收或检索数据。如上所述,3d训练模型806中的每一个可以表示唯一的牙弓。模型训练系统802可以捕获、检索或以其他方式接收多个3d训练模型806和一组训练图像804,该组训练图像804包括与相应3d训练模型806相关联的牙弓的表示的至少一部分。换句话说,模型训练系统802可以针对要在训练集812中使用的特定牙弓接收牙弓的3d训练模型806和包括牙弓的至少一部分的表示的一个或更多个训练图像804。
99.在步骤904,模型训练系统802处理所接收的数据。在一些实施例中,模型训练系统802的数据摄取引擎808可以处理接收到的数据(例如,在步骤902接收到的数据)。数据摄取引擎808可以通过选择将用于训练机器学习模型822的训练图像804的子集来处理所捕获的数据。例如,在步骤902处接收的训练图像804可以包括包括一系列帧的视频,每个帧示出患者口腔的透视视图。数据摄取引擎808可以从视频的一系列帧中选择帧子集。在一些实施例中,数据摄取引擎808可以基于帧子集的质量来选择帧子集。在一些实施例中,数据摄取引擎808可以基于在相应帧中描绘的用户牙弓的特定透视视图来选择帧子集。在一些实施例中,数据摄取引擎808可以处理3d模型,如下面参考步骤918更详细描述的。换句话说,可以当在步骤902处摄取或以其他方式捕获3d训练模型806时执行步骤918,或者可以在下面更详细描述的以下步骤中的一个或更多个之后执行步骤918。
100.在步骤906,模型训练系统802为经处理的数据生成元数据。在一些实施例中,数据摄取引擎808可以为经处理的数据生成元数据。在一些实施例中,数据摄取引擎808可以生成包括用于训练图像804和相关联的3d训练模型806的元数据的元数据文件。元数据文件可以是或者可以包括将用户的一组训练图像804与该组训练图像804中表示的用户牙列的3d训练模型806关联或链接起来的数据。在一些实施例中,元数据文件可以包括对应于训练图像804的数据。例如,元数据文件可以包括与以下项相对应的数据:训练图像804的图像对比度、训练图像804的焦点、训练图像804的像素大小、用于捕获训练图像804的相机的焦距、训练图像804的归一化因子、训练图像804的缩放等。这些数据可以用于跨训练集812对训练图像804进行标准化。
101.现在参考图9和图10a-图10d,在步骤908,模型训练系统802执行掩模推断。具体
地,图10a-图10d示出了相应的训练图像1000a-1000d。如图10a-图10d所示,图像1000a-1000d中的每一个可以包括围绕相应图像1000a-1000d中描绘的人的牙弓的边界框1002a-1002d,以及施加到牙弓的掩模1004a-1004d。模型训练系统802可以通过执行图像1000a-1000d内的牙齿的对象识别,以及在图像1000a-1000d内的牙齿上生成覆盖层(overlay)来施加掩模1004a-1004d。因此,掩模1004a-1004d可以是或者可以包括施加于图像1000a-1000d内的特定对象或特征(例如,如图10a-图10d所示的牙齿)的覆盖层。模型训练系统802可以施加边界框1002a-1002d来包围在图像1000a-1000d中识别的每颗牙齿(例如,包围图像1000a-1000d内的掩模1004a-1004d)。在一些实施例中,模型训练系统802可以包括或访问一个或更多个掩模系统,该掩模系统被配置成自动生成用于图像1000a-1000d的掩模1004a-1004d和边界框1002a-1002d。在一些实施例中,模型训练系统802可以包括掩蔽软件(masking software)或经由用于掩蔽软件的应用程序接口(api)以其他方式访问托管在远离系统800的服务器上的掩蔽软件。例如,模型训练系统802可以访问fair开发的用于掩蔽训练集的图像1000的detectron2。掩模1004可以限定牙弓中示出或表示的牙齿的周界或边缘。在一些实施例中,可以将掩模1004a-1004d施加到单颗牙齿(例如,逐颗牙齿地施加)。在一些实施例中,掩模1004a-1004d可以被施加到牙齿的子集(例如,基于牙齿类型,例如门齿、臼齿、前臼齿等)。在一些实施例中,掩模1004a-1004d可以被施加到位于公共牙弓中的每颗牙齿(例如,上颌牙和下颌牙)。
102.在步骤910,模型训练系统802处理掩模推断。在一些实施例中,模型训练系统802处理掩模推断(例如,被施加到训练图像1000a-1000d的掩模1004a-1004d),以确定掩模1004a-1004d被正确施加到训练图像1000a-1000d中表示的牙弓。模型训练系统802可以显示、渲染或以其他方式向计算设备810提供包括掩模1004a-1004d的图像1000a-1000d,以执行掩模1004a-1004d的质量控制。在一些实现中,模型训练系统802可以(例如,从计算设备810)接收掩模1004a-1004d的一个或更多个调整。可以通过拖动掩模1004a-1004d边缘的一部分以与图像1000a-1000d中牙弓的对应部分对齐、调整边界框1002a-1002d等来进行调整。
103.现在参考图9和图11,在步骤912,模型训练系统802标记2d到3d相关点816。具体地,图11示出了训练图像1100和对应的3d训练模型1102。训练图像1100和对应的3d训练模型1102可以是在步骤902接收的训练集812的数据分组814之一。如图11所示,训练图像1100和3d训练模型1102可以包括相关点1104a-1104b。具体地,训练图像1100包括相关点1104a,3d训练模型1102包括相关点1104b。相关点1104a-1104b中的每一个可以表示或以其他方式标识在训练图像1100和3d训练模型1102中都进行表示的公共点。如图11所示,给定相关点1104可以映射到在训练图像1100和3d训练模型1102两者中示出的相应牙齿。在一些实施例中,计算设备810可以自动生成训练图像1100和3d训练模型1102中的相关点1104a-1104b。例如,计算设备810可以分析图像1100和3d训练模型1102,以识别位于图像1100和3d训练模型1102中的各颗牙齿中的每一颗。计算设备810可以被配置成将一个或更多个标签施加到图像1100和3d训练模型1102两者中的各颗牙齿中的每一颗。计算设备810可以被配置成在训练图像1100和3d训练模型1102两者中表示出的每颗牙齿的中点处自动生成相关点1104a-1104b。在一些实施例中,计算设备810可以(例如,从计算设备810的用户)接收对训练图像1100和3d训练模型1102中的相关点1104的选择。
104.现在参考图9和图12,在步骤914,模型训练系统802计算估计的姿势。具体地,图12示出了一系列训练图像1200和用于训练图像1200的3d训练模型1202的对应姿势。在一些实施例中,模型训练系统802通过执行图像的相机常数(camera constant)、旋转和平移(krt)分析(或其他姿势对准分析)来计算训练图像1200中的用户的估计姿势。在一些实施例中,模型训练系统802使用与用于捕获图像1200的相机相对应的元数据(例如,捕获图像1200的相机的一个或更多个固有属性,例如焦距、主轴等)、图像中反映的牙弓的旋转以及图像中反映的牙弓的平移,来计算训练图像1200中的用户的估计姿势。模型训练系统802可以计算相应训练图像1200的估计姿势,以将3d训练模型的姿势与训练图像1200中的用户的估计姿势进行匹配。例如,模型训练系统802可以平移、旋转或以其他方式修改3d训练模型的姿势以匹配训练图像1200的计算出的姿势。
105.在一些实施例中,步骤908到914可以并行执行。例如,步骤908到910可以在图像上执行,而步骤912到914可以在3d模型上执行。在一些实施例中,步骤908到914可以串行执行(例如,模型训练系统802可以在处理掩模推断之后对2d到3d相关点816进行标记)。
106.在步骤916,模型训练系统802执行数据格式化。在一些实施例中,模型训练系统802可以将训练图像804、3d训练模型806和相关点816(通常称为训练集812)格式化为可接受的用于训练机器学习模型的格式。例如,模型训练系统802可以将训练集812格式化为上下文中的公共对象(coco)数据格式。模型训练系统802可以在将训练集812提供给机器学习训练引擎820以训练机器学习模型822之前格式化训练集812。
107.现在参考图9和图13,在步骤918,模型训练系统802处理3d模型1300。具体地,图13示出了根据说明性实施例的在训练集812中使用的3d模型806的处理进展。如图13所示,模型训练系统802可以接收初始3d训练模型1300a,该初始3d训练模型1300a包括用户的上牙弓的3d表示1302和用户的下牙弓的3d表示1304。3d表示1302、1304中的每一个可以包括对应牙弓的牙龈的表示1306、1312和牙齿的表示1308、1310。模型训练系统802可以通过将3d模型1300分离成两个3d模型(例如,上牙弓的3d表示1302的第一3d模型和下牙弓的3d表示1304的第二3d模型)来处理3d模型1300a,这可以是来自初始3d模型1300a的第一迭代的经处理的3d模型1300b。模型训练系统802可以处理如图13所示的第一迭代的3d模型1300b中的每一个,以从牙齿的3d表示1308中移除牙龈的3d表示1306。因此,模型训练系统802可以处理第一迭代的3d模型1300b以形成第二迭代的3d模型1300c,该3d模型1300c包括牙齿的3d表示1308,而不包括牙龈的任何3d表示1306。模型训练系统802可以通过体素化3d模型1300c中牙齿的3d表示1308来生成经处理的3d模型1300的最终迭代1314。因此,经处理的3d模型1300的最终迭代1314包括牙齿的体素化3d表示1316,该体素化3d表示1316对应于初始3d模型1300中的牙齿的3d表示1308。模型训练系统802可以使用3d模型1300的最终迭代1314作为用于训练机器学习模型822的3d训练模型806。
108.在一些实施例中,模型训练系统802可以添加、生成或以其他方式将牙龈合并到3d模型1300的最终迭代1314中。例如,模型训练系统802可以被配置成基于模型的最终迭代1314中的牙齿的体素化3d表示1316的一个或更多个参数、特征(trait)、形状或其他特性来生成牙龈。在一些实施例中,模型训练系统802可以被配置成将3d模型1300的最终迭代1314提供给机器学习模型,该机器学习模型被训练成将体素化的牙龈添加或合并到模型1300中牙齿的体素化3d表示1316中。
109.在步骤920,模型训练系统802训练机器学习模型822。模型训练系统802可以向机器学习训练引擎820传输、发送或以其他方式提供训练集812,以训练机器学习模型822。在一些实施例中,模型训练系统可以向机器学习训练引擎820提供训练集和一个或更多个配置参数,以用于训练机器学习模型822。在一些实施例中,配置参数818可以包括迭代数量,在这些迭代中,机器学习训练引擎820使用训练集812来训练机器学习模型822。在一些实施例中,配置参数818可以包括由机器学习训练引擎820使用的一组超参数的损失权重。计算设备810可以被配置成向机器学习训练引擎820发送、传输或以其他方式提供配置参数(例如,与训练集812一起),以用于训练机器学习模型822。机器学习训练引擎820可以接收并使用(例如,来自计算设备810和/或来自模型训练系统802的另一设备或部件的)训练集812和配置参数818作为用于训练机器学习模型822的输入。机器学习训练引擎820可以基于来自训练图像804、3d训练模型806和相关点816的数据来训练神经网络(例如图4中示出并在上面描述的神经网络)的一个或更多个权重。
110.在一些实施例中,3d训练模型806和/或训练图像804可以包括颜色或以颜色表示。在这样的实施例中,机器学习训练引擎820可以被配置成训练机器学习模型822,以基于来自一个或更多个图像的数据来检测、确定或以其他方式预测3d模型的颜色。机器学习训练引擎820可以被配置成训练神经网络的一个或更多个权重,以基于提供给机器学习模型822(例如,作为输入)的一个或更多个图像来检测、确定或以其他方式预测3d模型的颜色。
111.现在参考图14,示出了根据说明性实施例的示出从一个或更多个2d用户图像生成3d模型的示例方法1400的流程图。方法1400可以由上面参考图8描述的一个或更多个部件来执行。作为简要概述,在步骤1402,模型训练系统802接收训练集812的多个数据分组814。在步骤1404,模型训练系统802识别相关点816。在步骤1406,模型训练系统802训练机器学习模型822。在步骤1408,模型生成系统824接收一个或更多个图像828。在步骤1410,模型生成系统824基于一个或更多个图像828生成3d模型830。
112.在步骤1402,模型训练系统802接收训练集812的多个数据分组814。在一些实施例中,每个数据分组814包括与第一用户的第一牙弓的一个或更多个训练图像804和第一用户的第一牙弓的三维(3d)训练模型806相对应的数据。因此,数据分组814可以对应于相应的牙弓,并且可以包括对应于牙弓的训练图像804和牙弓的3d训练模型806的数据。在一些实施例中,数据摄取引擎808可以从数据源接收训练图像804和3d训练模型806,如上面关于图9所描述的。数据摄取引擎808可以从训练图像804和3d训练模型806生成训练集812的数据分组814,以用于训练机器学习模型822,如下面更详细描述的。
113.在一些实施例中,模型训练系统802可以将掩模施加到训练图像804中表示的一颗或更多颗牙齿。在一些实例中,模型训练系统802可以在训练图像804中表示的牙弓周围施加边界框,并将掩模施加到牙弓的一颗或更多颗牙齿。在一些实现中,模型训练系统802可以将掩模施加到牙弓的各颗牙齿。在一些实现中,模型训练系统802可以将掩模施加到牙弓的牙齿集合(如在图11中示出并在上面更详细描述的)。因此,可以逐颗牙齿地施加掩模,或者可以将掩模施加到训练图像804中所示出的牙弓的每一颗牙齿。
114.在一些实施例中,模型训练系统802可以计算训练图像804中牙弓的估计姿势。模型训练系统802可以通过执行krt分析(例如,使用与训练图像804相对应的元数据)来计算估计的姿势,如上面关于图9和图12所描述的。模型训练系统802可以使用估计的姿势来修
改3d训练模型806的姿势。例如,模型训练系统802可以调整、修改或以其他方式改变3d训练模型806的姿势,以匹配(或基本上匹配)训练图像804中示出的牙弓的估计姿势。模型训练系统802可以修改3d训练模型806的姿势以匹配训练图像804中的估计姿势,以显示在计算设备上用于选择相关点816,如下面更详细描述的。
115.在一些实施例中,模型训练系统802可以从(如图13中示出并在上面进行描述的)初始3d训练模型生成3d训练模型806。例如,模型训练系统802可以接收初始3d训练模型,该初始3d训练模型包括用户的上牙弓的3d表示和用户的下牙弓的3d表示。每个3d表示可以包括牙齿和牙龈的表示(例如,上牙的3d表示和上牙龈的3d表示,以及下牙的3d表示和下牙龈的3d表示)。模型训练系统802可通过将上牙弓的3d表示与下牙弓的3d表示分离,并从分离的牙齿3d表示中移除牙龈的3d表示,而从初始3d训练模型生成3d训练模型。因此,3d训练模型可以包括牙弓的多颗牙齿的3d表示。在一些实现中,模型训练系统802可以体素化3d训练模型(例如,至少体素化3d训练模型中表示的牙齿)。
116.在步骤1404,模型训练系统802识别相关点816。在一些实施例中,模型训练系统802可以为训练集812的数据分组814识别相应牙弓的一个或更多个训练图像804和3d训练模型806之间的多个相关点816。在一些实施例中,模型训练系统802可以通过从计算设备810接收对相关点816的选择来识别相关点816。计算设备810可以显示训练图像804和3d训练模型806。计算设备810的用户可以选择训练图像804上的第一点。然后,用户可以选择3d训练模型806上对应于训练图像804上的第一点的第二点。因此,第一点和第二点可以一起形成相关点。在一些实施例中,模型训练系统802可以自动选择训练图像804和3d训练模型806之间的相关点。
117.在步骤1406,模型训练系统802训练机器学习模型822。在一些实施例中,模型训练系统802可以使用用于训练集812的多个数据分组814的多个相关点816训练机器学习模型822。在一些实施例中,模型训练系统802可以通过向训练机器学习模型822的机器学习训练引擎820传输、发送或以其他方式提供相关点816、训练图像804和3d训练模型806(它们共同形成训练集812)来训练机器学习模型822。机器学习训练引擎820可以使用训练集812作为输入以用于训练对应于机器学习模型822的神经网络的一个或更多个权重。在一些实施例中,机器学习训练引擎820可以训练机器学习模型822以检测、确定或以其他方式预测3d模型的颜色。在这些实施例中,训练集812可以包括颜色数据(例如,训练图像804和/或3d训练模型806可以包括颜色数据)。
118.在一些实施例中,模型训练系统802可以接收用于生成机器学习模型822的一个或更多个配置参数。模型训练系统802可以从计算设备(例如计算设备810)接收配置参数。配置参数可以包括例如训练迭代的数量,机器学习训练引擎820在这个数量的训练迭代中使用训练集812训练机器学习模型822。模型训练系统802可以将配置参数连同训练集812一起传输到机器学习训练引擎820,以使机器学习训练引擎820对训练集执行该数量的迭代来生成经训练的机器学习模型822。
119.在步骤1408,模型生成系统824接收一个或更多个图像828。在一些实施例中,模型生成系统824接收患者牙弓的一个或更多个图像828。模型生成系统824可以从用户设备826接收图像828。用户设备826可以向模型生成系统824传输、发送或以其他方式提供图像828(例如,通过将图像828上传到与模型生成系统824相关联的门户,通过将图像828传输到与
模型生成系统824相关联的地址,等等)。图像828可以表示患者牙弓的一部分。在一些实施例中,模型生成系统824可以接收牙弓的多个图像828。多个图像828可以各自从不同的视角描绘或以其他方式表示牙弓的一部分,使得多个图像828一起表示牙弓(例如,以其整体表示)。
120.在步骤1410,模型生成系统824基于一个或更多个图像828生成3d模型830。在一些实施例中,模型生成系统824可以通过将第二牙弓的一个或更多个图像应用于(例如,在步骤1406生成的)机器学习模型来生成患者牙弓的3d模型。模型生成系统824可以将在步骤1408接收的一个或更多个图像提供给机器学习模型作为输入。可以训练机器学习模型以基于作为输入接收的图像和用于机器学习模型的神经网络的对应权重来生成3d模型830。因此,机器学习模型可以基于输入图像828和机器学习模型的神经网络的对应权重生成3d模型830作为输出。在一些实施例中,例如其中机器学习模型被训练以预测3d模型830的颜色的实施例,机器学习模型可以基于输入图像828生成3d模型830以包括颜色数据。3d模型830可以被生成为用于立体光刻、网格或图像中表示的患者牙弓的其他3d表示的标准三角语言(stl)文件。stl文件可以仅描述3d模型830的三角化表面几何形状,而没有颜色、纹理或其他属性的任何表示。
121.在一些实施例中,方法1400还可以包括基于3d模型制造牙齿矫正器,其中牙齿矫正器是特定于用户的并且被配置成重新定位用户的一颗或更多颗牙齿。制造牙齿矫正器可以类似于上面描述的图6的步骤608。
122.在一些实施例中,方法1400还可以包括跟踪经由一个或更多个牙齿矫正器将患者的一颗或更多颗牙齿从治疗前的初始位置重新定位到治疗后的最终位置的进展。如上所述,可以根据包括一系列移动阶段的治疗计划(以及在相应阶段中用于根据治疗计划实现牙齿移动的对应的牙齿矫正器)对患者进行治疗。模型生成系统824可以基于在一个或更多个治疗阶段之后(或在经由牙齿矫正器进行治疗之后)捕获的图像828生成3d模型830。用户可以响应于一个或更多个捕获图像提示来以各种治疗间隔捕获图像828。例如,可以提示患者以各种间隔(例如,每天、每周、每两周、在一个治疗阶段完成之后、在经由牙齿矫正器进行治疗之后的每六个月或每年、每当患者请求检查他们的进展时,等等)上传图像828。然后,可以将由模型生成系统824生成的3d模型830与患者文件中包括的对应于该治疗阶段的3d模型进行比较,以确定患者的牙齿是否根据患者的治疗计划(例如,如预期的那样)移动。患者文件可以包括针对每个治疗阶段的3d模型(例如,对应于初始治疗阶段的初始3d模型、对应于中间治疗阶段的一个或更多个中间3d模型、以及对应于最终治疗阶段的最终3d模型)。可以将由模型生成系统824生成的3d模型830与来自患者文件的3d模型进行比较。例如,在从用户图像828生成的3d模型830与患者文件中包括的对应于治疗计划的特定阶段的3d模型匹配(或基本上匹配)的情况下,可以确定患者正在根据治疗计划进展,因为患者的牙齿正在根据治疗计划中定义的进展从治疗前的初始位置移动到治疗之后的一个或更多个中间位置以及移动到最终位置。然而,在从用户图像828生成的3d模型830与患者文件中包括的对应于治疗计划的特定阶段的3d模型不匹配(或基本上不匹配)的情况下,可以确定患者没有根据治疗计划进展。当确定患者没有根据治疗计划进展时,可以标记患者文件以进行治疗的中途校正。例如,当确定患者没有根据治疗计划进展时,可以标记患者文件以从患者的当前牙齿位置生成新的治疗计划(以及相对应地,根据新的治疗计划生成新的牙齿
矫正器)。作为另一个示例,当确定患者没有根据治疗计划进展时,可以提示患者跳过一个或更多个矫正器(例如,在患者进展快于治疗计划下的预期或预测的情况下,提前到治疗的另一个阶段),不按顺序地使用特定矫正器,使得患者的牙齿根据治疗计划移动回正确的方向。
123.在一些实施例中,方法1400还可以包括在用户设备826处的用户界面上显示3d模型830。换句话说,3d模型830可以经由用户设备826在用户界面上向用户进行回放渲染。例如,模型生成系统824可以向用户设备826传输、发送或以其他方式提供3d模型830,以供向用户渲染。在一些实施例中,模型生成系统824可以生成用于在用户设备826处显示的用户界面。用户界面可以包括例如基于用户图像828生成的3d模型830。在一些实施例中,用户界面可以包括另一3d模型。例如,用户界面可以包括基于用户图像828生成的3d模型830和预期的3d模型(例如,来自患者文件的对应于当前治疗阶段的3d模型)。这样的实施例可以允许用户与对应于治疗计划的目标3d模型相比较地来跟踪他们的进展。作为另一示例,用户界面可包括3d模型830和前一个(和/或下一个)3d模型。前一个3d模型可以是来自患者文件的对应于治疗计划的前一个阶段的3d模型。前一个3d模型可以是从先前用户图像828生成的3d模型。下一个3d模型可以是来自患者文件的对应于治疗计划的下一个阶段的3d模型。用户可以查看前一个3d模型、当前3d模型830和/或下一个3d模型以示出患者治疗的进展。
124.现在参考图15,示出了根据说明性实施例的图8系统800的用例示意图。如图15所示,用户可以上传包括用户牙齿的表示的一个或更多个图像(例如图像1500)。在一些实施例中,用户可以从不同的视角捕获图像,例如在图2a-图2c中所示的那些视角。在一些实施例中,用户可以捕获他们自己牙齿的图像。在一些实施例中,不同的人可以(例如,从用户的设备或从不同的设备)捕获用户牙齿的图像。用户可以将图像1500提供给模型生成系统824。模型生成系统824可将图像1500应用于经训练的机器学习模型822(例如,作为输入)以基于图像1500生成3d模型1502。因此,机器学习模型822被训练以使用从用户接收的图像1500来生成3d模型1502。
125.在一些实施例中,经由机器学习模型822生成的一些结果(例如,3d模型)可用于细化机器学习模型822和/或用于生成后续模型的其他过程。例如,执行经由机器学习模型822生成的3d模型的质量审查或检查的用户可基于机器学习模型的输出进一步细化参数(例如配置参数)。
126.现在参考图16和图17,在图16中示出了对应于机器学习模型822的训练的一系列图表1600,并且在图17中示出了一系列模型评估界面1702,这些模型评估界面1702示出了由机器学习模型822基于来自用户的图像1700生成的模型。图16中所示的每个图表1600可以代表用于训练机器学习模型822的每个模型的度量。这样的度量可以包括或对应于用于训练机器学习模型822的配置参数818。相应地,执行机器学习模型822的质量控制的人可以查看图16中示出的图表1600和界面1702以修改各种配置参数818,从而更新或以其他方式细化机器学习模型822的训练。可以在图表1600中表示的配置参数818的各种示例包括损失边缘(loss edge)、损失区域建议网络(rpn)、分类(cls)、损失倒角(loss chamfer)、损失掩模、损失z回归(reg)、损失体素(loss voxel)、损失rpn局部(loss rpn local)、损失分类、准确度等。可以在图表1600中表示的配置参数181的附加示例包括数据时间、以秒为单位的估计到达时间(eta)、具有卷积神经网络的快速区域(r-cnn)、损失法向(loss normal)、掩
模r-cnn、感兴趣区域(roi)头部、rpn、时间、总损失和体素r-cnn。尽管描述了这些配置参数818,但注意机器学习模型822可以被训练或配置成利用这些(和其他)配置参数818的各种组合。可以在计算设备810上渲染图表1600和界面1702。查看图表1600和界面1702的技术人员可以调整、调节或以其他方式修正配置参数818中的一个或更多个以修改机器学习模型822。在一些实施例中,计算设备810可以自动调整、调节或以其他方式修正配置参数818,或者可以提出对配置参数818的改变的建议,以供技术人员接受。这样的实施例可以提供对用于训练机器学习模型822的配置参数818的更准确的调节。
127.现在参考图18,示出了用户的一系列图像1800和使用机器学习模型822生成的对应的一系列3d模型1802。如图18所示,在图像1800中表示出了用户的牙弓。图18中所示的模型1802是由机器学习模型822从多个图像1800生成的分离的3d模型。因此,机器学习模型822可以从用户牙弓的多个图像1800(例如,从不同的视角)生成多个3d模型1802。在一些实施例中,模型生成系统824可以从多个3d模型1802生成合并的3d模型。如上所述,模型生成系统824可以组合、融合或以其他方式合并多个3d模型1802,以形成牙弓的合并3d模型。可以如上所述合并3d模型以形成合并的模型1802。如图18所示,通过上述实现和实施例,机器学习模型822可从不同视图生成3d模型,这些模型可以被合并并且一起对可能难以建模的整个牙弓(包括咬合区域)进行建模。
128.如本文所使用的,术语“大概(approximately)”、“大约(about)”、“基本上(substantially)”和类似的术语旨在具有与本公开的主题所属领域的普通技术人员共同接受的用法相一致的广义含义。阅读本公开的本领域技术人员应当理解,这些术语旨在允许对所描述和要求保护的某些特征进行描述,而不将这些特征的范围限制于所提供的精确数值范围。因此,这些术语应被解释为表明:所描述和要求保护的主题的非实质性或无关紧要的修改或变更被认为在如所附权利要求中所述的本公开的范围内。
129.应该注意的是,如本文用来描述各个实施例的术语“示例性的”及其变型旨在表明:这些实施例是可能的实施例的可能的示例、表示或说明(并且这些术语并不旨在暗示这些实施例必然是特别的或最高级的示例)。
130.如本文使用的术语“耦合”及其变型是指两个构件直接或间接地彼此连接。这种连接可以是固定的(例如,永久的或固定的)或可移动的(例如,可移除的或可释放的)。这种连接可以利用两个直接彼此耦合的构件来实现,其中两个构件使用单独的插入构件和彼此耦合在一起的任何附加的中间构件彼此耦合,或者其中两个构件使用插入构件彼此耦合,该插入构件与两个构件中的一个构件一体成型为单个整体。如果“耦合”或其变型被附加术语修改(例如,直接耦合),则上面提供的“耦合”的一般定义被附加术语的普通语言含义修改(例如,“直接耦合”意味着两个构件的连接,而没有任何单独的插入构件),导致比上面提供的“耦合”的一般定义更窄的定义。这种耦合可以是机械的、电的或流体的。
131.如本文使用的术语“或”以其包含性的意义(而不是以其排他性的意义)使用,使得当用于连接元素列表时,术语“或”意味着列表中的一个元素、一些元素或所有元素。除非另有特别说明,否则连接语言(例如,短语“x、y和z中的至少一个”)被理解为表示元素可以是x、y或z;x和y;x和z;y和z;或者x、y和z(即,x、y和z的任意组合)。因此,除非另有说明,否则这样的连接语言一般不旨在暗示某些实施例需要x中的至少一个、y中的至少一个和z中的至少一个都存在。
132.本文对元件位置(例如,“顶部”、“底部”、“上面”、“下面”)的引用仅用于描述附图中各个元件的取向。应当注意,根据其他示例性实施例,各个元件的取向可以不同,并且这种变化旨在被本公开所涵盖。
133.用于实施结合本文公开的实施例描述的各个过程、操作、说明性逻辑、逻辑块、模块和电路的硬件和数据处理部件可以用以下一项来实施或执行:通用单芯片或多芯片处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或其他可编程逻辑器件、分立门或晶体管逻辑、分立硬件部件或被设计为执行本文描述的功能的其任意组合。通用处理器可以是微处理器,或者任何传统的处理器、控制器、微控制器或状态机。处理器还可以被实施为计算设备的组合,例如dsp和微处理器的组合、多个微处理器、一个或更多个微处理器与dsp内核的结合、或者任何其他这样的配置。在一些实施例中,可以由特定于给定功能的电路来执行特定的过程和方法。存储器(例如,存储器、存储器单元、储存设备)可以包括用于存储数据和/或计算机代码的一个或更多个设备(例如,ram、rom、闪存、硬盘储存器),以完成或促进本公开中描述的各个过程、层和电路。存储器可以是或包括易失性存储器或非易失性存储器,并且可以包括数据库部件、目标代码部件、脚本部件或用于支持本公开中描述的各个活动和信息结构的任何其他类型的信息结构。根据示例性实施例,存储器经由处理电路可通信地连接到处理器,并且包括用于(例如,由处理电路或处理器)执行本文描述的一个或更多个过程的计算机代码。
134.本公开设想用于完成各个操作的方法、系统和在任何机器可读介质上的程序产品。可以使用现有计算机处理器或通过为此目的或其他目的所引入的恰当系统的专用计算机处理器或通过硬接线的系统来实现本公开的实施例。本公开的范围内的实施例包括程序产品,其包括用于携带或具有存储于其上的机器可执行指令或数据结构的机器可读介质。这种机器可读介质可以是任意可用介质,其可由通用或专用计算机或具有处理器的其他机器访问。举例来讲,这种机器可读介质可以包括ram、rom、eprom、eeprom或其他光盘储存器、磁盘储存器或其他磁储存设备、或可用于携带或存储以机器可执行指令或数据结构形式的所需程序代码的且可以通过通用或专用计算机或具有处理器的其他机器访问的任何其他介质。上面的组合也被包括在机器可读介质的范围内。例如,机器可执行指令包括指令和数据,该指令和数据使得通用计算机、专用计算机或专用处理机器执行某一功能或一组功能。
135.尽管附图和描述可以说明方法步骤的特定顺序,但是这些步骤的顺序可以不同于所描绘和描述的内容,除非上面另有说明。此外,除非上面另有说明,否则两个或更多个步骤可以同时或部分同时执行。例如,这种变化可能取决于所选择的软件和硬件系统以及设计者的选择。所有这种变化都在本公开的范围内。同样地,所描述的方法的软件实现可以用具有基于规则的逻辑和其他逻辑的标准编程技术来完成,以完成各个连接步骤、处理步骤、比较步骤和决策步骤。
136.重要的是要注意,在各个示例性实施例中所示的系统和方法的构建和布置仅是说明性的。此外,在一个实施例中公开的任何元件可以与本文公开的任何其他实施例结合或一起使用。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。