1.本发明涉及车辆目标跟踪领域,具体涉及一种无人机视角下多目标车辆旋转框跟踪方法。
背景技术:
2.与载人飞机相比,无人机具有体积小,灵活性强、造价低、操作简单、作战环境要求低以及战场生存能力强等优势,使得无人机在军事领域对于未来空战有着重要的意义。除了军事领域,无人机在民用领域的应用也是极其广泛。目前在航拍、农业、植保、快递运输、电力巡检以及抢险救灾等领域都发挥着巨大价值。随着国民经济的飞速发展,居民可支配收入增多以及在交通强国、交通数字化转型等行业政策的引导之下,国内城市中汽车数量不断增多,2022年3月已突破4亿辆。智能交通检测系统成为了保证城市交通安全和提高交通设施运行效率的必要措施。对于车辆的检测与跟踪更是智能交通检测系统的主要任务。将无人机技术应用到车辆跟踪任务中,可以发挥无人机独特的优势的同时,无人机视角下的车辆跟踪也是亟待解决的重要问题。
3.跟踪主要应用于对视频或连续有语义关联的图像中任意目标,通过其外观特征和运动信息进行建模,通过对运动状态的预测,来实现对其空间位置和形状大小的获知。根据跟踪目标的不同,可以分为单目标跟踪和多目标跟踪;根据跟踪方法的不同可以分为生成类跟踪方法和判别类跟踪方法。生成类跟踪方法将更多的注意力放在目标本身,比较经典的方法有卡尔曼滤波、粒子滤波、均值漂移等;判别类滤波可以分别基于相关滤波和基于深度学习的方法,可以一定程度上解决样本不足的问题。
4.不同于常见的摄像机视角下地面车辆目标跟踪,在无人机视角下,车辆目标跟踪面临着以下几个挑战。
5.1)无人机拍摄时处于高空位置,视野广阔,背景复杂。感兴趣的车辆目标与其他物体、感兴趣目标与环境背景之间相互干扰,构造精准的目标检测器比较困难;
6.2)当无人机飞行到一定高度时,视野变大,图像分辨率变低,车辆目标的轮廓和纹理特征变得稀少,给目标检测与跟踪带来了新的挑战;
7.3)无人机在拍摄过程中,受光线、风力以及操作员的飞行控制影响,可能会出现相机抖动、运动模糊、车辆行驶方向快速变化等情况。
8.4)由于无人机自身结构特点,无法提供足够的计算资源,在保证精度的前提下,降低算法复杂度以及压缩模型大小,成为重中之重。
技术实现要素:
9.无人机视角下的车辆目标存在背景复杂、目标较小、方向任意以及排列紧密等特点,给车辆检测与跟踪带来了一定的挑战。同时,由于无人机自身可携带计算资源有限,对于算法优化以及模型轻量化也提出了更高的要求。
10.为了解决上述问题,更好地实现对于无人机视角下的车辆目标跟踪,本发明拟解
决的技术问题是提供一种无人机视角下多目标车辆旋转框跟踪方法,具体如下:
11.一种无人机视角下多目标车辆旋转框跟踪方法,包含如下步骤:
12.步骤1),车辆旋转框检测:制作无人机视角下的车辆数据集,搭建检测网络模型并进行训练,实现对车辆目标的旋转框检测;
13.步骤2),fpgm剪枝:基于几何中值卷积神经网络滤波器来修剪冗余的滤波器来实现对检测网络模型的压缩;
14.步骤3),重识别网络训练:构造车辆重识别数据集,训练重识别网络模型,得到目标的外观特征和运动特征,实现车辆目标的重识别;
15.步骤4),多目标车辆跟踪:将待检测视频输入检测网络模型,得到目标车辆检测框,通过重识别网络提取检测框的外观特征和运动特征,从而计算检测结果与卡尔曼滤波预测结果的相似度,最后通过匈牙利算法进行数据关联,从而实现多目标的跟踪。
16.作为本发明一种无人机视角下多目标车辆旋转框跟踪方法进一步的优化方案,所述步骤1)的具体步骤为:
17.步骤1.1),通过无人机在若干个交通要道以不同的飞行状态来对车辆目标进行拍摄,获得原始数据;再通过标注软件,人工地对每个车辆目标进行旋转框的标注;标注格式为(x1,y1,x2,y2,x3,y3,x4,y4,class),其中,(xi,yi)为第i个顶点坐标,1≤i≤4,class为车辆的类别,包含汽车(car)、公交车(bus)、卡车(truck)三类;
18.步骤1.2),对于n张原始图片,重复步骤1.1)得到n个对应的标签数据,再将(x1,y1,x2,y2,x3,y3,x4,y4,class)标注格式转化为(x
center
,y
center
,x
bottom
,y
bottom
,w,h,class)训练格式,其中,(x
center
,y
center
)表示旋转框中心点坐标,(x
bottom
,y
bottom
)表示旋转框底点坐标,w、h、class分别表示旋转框的宽、高、类别,最后将其分割为训练集和测试集;
19.步骤1.3),在原yolov5检测模型中增加ca注意力模块和transformer预测头,修改模型的参数,搭建模型的运行环境;
20.步骤1.4),在操作系统为ubuntu 16.04,显卡为nvidia rtx 2080ti的工作站上,设置训练batch size大小为4,初始学习率为0.001,训练120个epochs。
21.作为本发明一种无人机视角下多目标车辆旋转框跟踪方法进一步的优化方案,所述步骤2)的具体步骤为:
22.步骤2.1),加载模型参数到检测网络模型中,对于每一个卷积层,计算每个卷积核与所有的卷积核的欧式距离之和;
23.步骤2.2),对得到的所有欧式距离之和,按照从小到大排序,剪裁掉低于预定阈值μ所对应的卷积核;
24.步骤2.3),将剪裁掉的卷积核的梯度强制为零,对剪枝后的检测网络模型重新训练,重复裁剪和训练过程,直至检测网络模型收敛;
25.步骤2.4),去掉全零卷积核以及卷积核中的冗余通道,同时去掉bn层参数冗余数值,得到剪枝且去零的压缩的检测网络模型。
26.作为本发明一种无人机视角下多目标车辆旋转框跟踪方法进一步的优化方案,所述步骤3)的具体步骤为:
27.步骤3.1),构建车辆重识别数据集,完成对原始veri数据集的数据增强和容量扩展;
28.步骤3.2),基于余弦度量学习对重识别网络模型进行训练,使得重识别网络模型有良好的分类能力,准确实现对短暂消失又重新出现的车辆目标进行重识别。
29.作为本发明一种无人机视角下多目标车辆旋转框跟踪方法进一步的优化方案,所述步骤4)的具体步骤为:
30.步骤4.1),单帧图片车辆目标检测:从视频中获取单帧图片,送入检测网络模型中得到该图片中所有车辆的位置信息(x,y,w,h,theta)和置信度其中,x、y分别为车辆旋转框中心点的横坐标、纵坐标;w、h分别为车辆旋转框的宽度、高度;theta为车辆旋转框的长边与水平线所成的角度;
31.步骤4.2),对于步骤4.1)中得到的检测框,通过训练好的重识别网络模型,得到其外观特征和运动特征;
32.步骤4.3),卡尔曼滤波预测:采用(x,y,w,h,theta,dx,dy,dw,dh,dtheta)作为状态估计模型的状态向量,采用匀速运动模型的卡尔曼滤波器预测轨迹,预测下一帧目标轨迹,其中,dx,dy,dw,dh,dtheta分别为x,y,w,h,theta的变化量;
33.步骤4.4),对卡尔曼滤波预测的确认态轨迹与目标检测器得到的检测框进行级联匹配;
34.步骤4.5),将卡尔曼滤波预测的不确认态轨迹与级联匹配产生的检测框失配和轨迹失配结果进行iou匹配,通过匈牙利算法,得到最终的匹配结果;
35.步骤4.6),进行卡尔曼滤波参数更新;
36.步骤4.7),循环执行步骤4.1)至步骤4.6),直至视频结束,得到最终的跟踪结果。
37.本发明采用以上技术方案,可以实现对无人机视角下车辆目标的旋转框跟踪。针对无人机视角下,车辆目标较小、排列紧密、方向任意以及背景环境复杂等挑战,采用改进型yolov5目标检测器,提出基于底点坐标的旋转框表示方法,以旋转框代替水平框,实现更加准确的车辆目标检测,提升视觉辨识效果;通过deepsort目标跟踪器可以实现对车辆目标的实时跟踪;同时,对网络模型进行fpgm剪枝,在保证跟踪精度和速度的同时,进一步压缩模型,旨在解决在无人机计算资源有限的问题。
附图说明
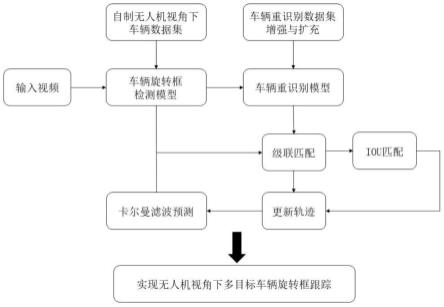
38.图1为本发明的方法流程图;
39.图2为基于底点坐标的旋转框表示方法示意图;
40.图3为改进型yolov5网络结构图;
41.图4为deepsort目标跟踪流程图。
具体实施方式
42.下面给出本发明的具体实施例。具体实例仅用于进一步详细说明本发明,不限制本技术权利要求的保护范围。
43.结合附图对本发明作更进一步的说明。见参考图1,本发明提供了一种无人机视角下多目标车辆旋转框跟踪方法,具体实施步骤如下:
44.步骤1),车辆旋转框检测:制作无人机视角下的车辆数据集,搭建检测网络模型进行训练,实现对车辆目标的旋转框检测;
45.步骤1.1),通过无人机在若干个交通要道以不同的飞行状态来对车辆目标进行拍摄,获得原始数据;再通过标注软件,人工地为每个车辆目标进行旋转框的标注,标注格式为(x1,y1,x2,y2,x3,y3,x4,y4,class),其中,(xi,yi)(1≤i≤4)为第i个顶点坐标class为车辆的类别,包含汽车(car)、公交车(bus)、卡车(truck)三类;再将标注格式转化为(x
center
,y
center
,x
bottom
,y
bottom
,w,h,class)训练格式,其中,(x
center
,y
center
)表示旋转框中心点坐标,(x
bottom
,y
bottom
)表示旋转框底点坐标,w,h,class分别表示旋转框的宽高以及类别,通过旋转框的中心点坐标、底点坐标以及宽高,即可表示出一个完整旋转框,如图2所示;
46.步骤1.2),重复步骤1.1)得到1015组数据,并将其分割为训练集和测试集,训练集共828组数据,测试集187组数据;
47.步骤1.3),在原yolov5检测模型中增加ca注意力模块和transformer预测头,修改模型的参数,搭建模型的运行环境,如参考图3所示;
48.步骤1.4),在操作系统为ubuntu 16.04,显卡为nvidia rtx 2080ti的工作站上,设置训练batch size大小为4,初始学习率为0.001,训练120个epochs;
49.步骤2),fpgm剪枝:基于几何中值卷积神经网络滤波器来修剪冗余的滤波器来实现对检测网络模型的压缩;
50.步骤2.1),加载模型参数到检测网络模型中,对于每一个卷积层,计算每个卷积核与所有的卷积核的欧式距离之和;
51.步骤2.2),对得到的所有欧式距离之和,按照从小到大排序,剪裁掉低于预定阈值μ所对应的卷积核;
52.步骤2.3),将剪裁掉的卷积核的梯度强制为零,对剪枝后的检测网络模型重新训练,重复裁剪和训练过程,直至检测网络模型收敛;
53.步骤2.4),去掉全零卷积核以及卷积核中的冗余通道,同时去掉bn层参数冗余数值,得到剪枝且去零的压缩的检测网络模型;
54.步骤3),重识别网络训练:构造车辆重识别数据集,训练重识别网络模型,得到目标的外观特征和运动特征,实现车辆目标的重识别;
55.步骤3.1),构建车辆重识别网络训练数据集,通过编写脚本,加强车辆与背景区分度,并随机翻转和调节图像明暗度,完成对原始veri数据集的数据增强和容量扩展;
56.步骤3.2),基于余弦度量学习对重识别网络模型进行训练,设置batch size为32,学习率为0.001,在经过400000次迭代后,分类准确度可以达到94.5%,此时网络有良好的分类能力,可以准确实现对短暂消失又重新出现的车辆目标进行重识别;
57.步骤4),多目标车辆跟踪:将待检测视频输入检测网络模型,得到目标车辆检测框,通过重识别网络提取检测框的外观特征和运动特征,从而得到检测结果与卡尔曼滤波预测结果的相似度,最后通过匈牙利算法进行数据关联,从而实现多目标的跟踪,具体流程如图4所示;
58.步骤4.1),单帧图片车辆目标检测:从视频中获取单帧图片,送入检测网络模型中得到该图片中所有车辆的位置信息(x,y,w,h,theta)和置信度其中,x、y分别为车辆旋转框中心点的横坐标、纵坐标;w、h分别为车辆旋转框的宽度、高度;theta为车辆旋转框的长边与水平线所成的角度;
59.步骤4.2),对于步骤4.1)中得到的检测框,通过训练好的重识别网络模型,得到其
外观特征和运动特征;
60.步骤4.3),卡尔曼滤波预测:采用(x,y,w,h,theta,dx,dy,dw,dh,dtheta)作为状态估计模型的状态向量,采用匀速运动模型的卡尔曼滤波器预测轨迹,预测下一帧目标轨迹,其中,dx,dy,dw,dh,dtheta分别为x,y,w,h,theta的变化量;
61.步骤4.4),对卡尔曼滤波预测的确认态轨迹与目标检测器得到的检测框进行级联匹配;得到三种结果,分别为tracks失配(unmatched tracks)、detections失配(unmatched detections)以及tracks匹配(tracks matched);
62.步骤4.5),对于级联匹配结果是tracks匹配,直接进行轨迹更新和id维护;对于级联匹配结果是detections失配和tracks失配,以及卡尔曼滤波预测的不确认态轨迹,再次进行iou匹配,计算代价矩阵,通过匈牙利算法,得到tracks失配、detections失配以及tracks匹配三种匹配结果;
63.对于iou匹配结果是detections失配时,将添加一条新的轨迹信息和id,并进行更新;对于iou匹配结果是tracks失配的不确认态轨迹,直接删除轨迹,不再更新轨迹和维护id;对于iou匹配结果是tracks失配的确认态轨迹,当tracks失配次数大于既定的最大生命周期时,将直接删除轨迹,当次数不大于最大生命周期时,继续更新轨迹参数和维护id信息;
64.步骤4.6),进行卡尔曼滤波参数更新;
65.步骤4.7),循环执行步骤4.1)至步骤4.6),直至视频结束,得到最终的跟踪结果。
66.以上所述仅是本发明的优选实施方式,其目的在于让熟悉此项技术的人士了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
