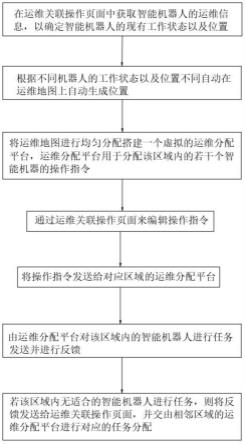
1.本发明属于集群智能控制领域,特指一种基于感知控制与感知容限的集群控制方法。
背景技术:
2.在机械制造与自动化领域,机器人和无人机有着重要的研究与应用意义,随着人工智能与数字通信技术的兴起,智能机器人或飞行器技术逐渐成为多学科、多领域混合的研究课题。人多力量大的道理同样适用于智能机械,一般来说机器人集群具有更高的执行效率,这意味着在相同时间内可以完成更多的任务需求,或者说执行相同任务时消耗时间更少;驱动群体需要依靠集群控制技术,相比于单独个体的驱动,其更需要考虑集群个体间的通信传输以及排列结构问题。
3.由于现实环境中存在的噪声以及各种工程误差,被控制个体往往无法精准的达到人为设置的目标状态,此时需要额外的控制方法以应对环境中的干扰因素,其中最为常见同时应用最为广泛的当属pid控制方法,其根据历史数据和差别的出现率来调整输入值,使系统更加准确稳定。pid能有效应对环境噪声造成的控制误差,但在面对个体数量增加而导致的集群拥挤问题时表现不够理想。如何通过构建方法模型同时解决复杂环境干扰与个体数增加导致集群性能指标下降的问题成为集群智能控制研究的重点。
技术实现要素:
4.为克服现有技术的不足及存在的问题,本发明提供一种基于感知控制与感知容限的集群控制方法。
5.为实现上述目的,本发明采用如下技术方案:
6.一种基于感知控制与感知容限的集群控制方法,包括如下步骤:
7.步骤1:处理器配置群体的集群信息,其中,集群信息包括个体数量、终止迭代次数、终点状态最大误差和个体感知属性,个体感知属性包括极限加速度、感知范围、感知容限和路径规划方法的迭代步长;
8.步骤2:处理器初始化迭代次数,配置个体的状态信息,其中,状态信息包括初始状态和终点状态;
9.步骤3:处理器将状态信息代入路径规划方法计算得到路径轨迹数据,其中,路径轨迹数据包括每个迭代步长内个体的速度信息和位置信息,路径轨迹方法可以是基于dubins曲线的路径规划方法;
10.步骤4:处理器根据路径轨迹数据驱动个体进行运动,根据路径轨迹数据索引得到个体的当前状态目标值和终点状态目标值;
11.步骤5:传感器感知传感器所在个体的自身状态和传感器感知范围内的其他个体状态,根据自身状态和其他个体状态计算得到个体当前的感知信息量;
12.步骤6:传感器将自身状态和感知信息量输入至当前状态控制单元,将感知信息
量、终点状态目标值和感知容限输入至感知属性控制单元;
13.步骤7:感知属性控制单元根据感知信息量、终点状态目标值和感知容限更新个体感知属性;
14.步骤8:当前状态控制单元预测状态误差和误差校正量;
15.步骤9:感知属性控制单元将更新后的个体感知属性输入至传感器和终点状态控制单元,当前状态控制单元将状态误差和误差校正量输入至终点状态控制单元,终点状态控制单元根据状态误差、误差校正量和更新后的终点状态更新得到终点状态;
16.步骤10:处理器将更新后的个体感知属性和终点状态代入路径规划方法更新得到路径轨迹数据,迭代次数加一;
17.步骤11:处理器判断迭代次数是否等于终止迭代次数,若是则终止迭代,若否则迭代步骤4至步骤11。
18.作为优选,所述步骤5中,具体包括:
19.步骤51:传感器感知传感器所在个体的自身状态和传感器感知范围内的其他个体状态;
20.步骤52:传感器根据自身状态和其他个体状态计算得到个体和其他个体之间的欧氏距离;
21.步骤53:传感器根据如下公式计算得到其他个体所占的感知角度:
[0022][0023]
式中,φ为其他个体所占的感知角度,bl为个体自身直径,dissefoth为欧氏距离;
[0024]
将所有其他个体的感知角度累加在一起得到总体的感知角度,将总体的感知角度除以2π得到感知信息量。
[0025]
作为优选,所述步骤7中,具体包括:
[0026]
步骤71:感知属性控制单元比较感知信息量和感知容限的大小得到两者的差值,判断两者的差值是否大于0,若是则保留两者的差值,若否则判断两者的差值的绝对值是否小于η倍的感知容限,η为控制个体逆向调整个体感知属性的区间参数,η∈(0,1),若是则保留两者的差值,若否则将两者的差值设置为0;
[0027]
步骤72:将两者的差值放大倍后代入如下公式更新个体感知属性:
[0028]
pecpatrbnew=pecpatrbcurr α
·
pecpdiff,
[0029]
式中,pecpatrbnew为更新得到的个体感知属性,pecpatrbcurr为当前的个体感知属性,α为比例系数;
[0030]
步骤73:根据路径轨迹数据和其他个体状态预判当前个体和其他个体是否会发生碰撞,若是则将碰撞信号设置为1,若否则将碰撞信号设置为0。
[0031]
作为优选,所述步骤8中,具体包括:
[0032]
步骤81:将自身状态和当前状态目标值相减得到状态误差;
[0033]
步骤82:判断状态误差容器中的状态误差数量是否等于误差预测序列长度,若等于则根据误差预测模型得到误差校正量,将误差校正量输入至终点状态控制单元,初始化
状态误差容器,若不等于则将状态误差输入至状态误差容器,并设置误差校正量为0输入至终点状态控制单元。
[0034]
作为优选,所述步骤9中,具体包括:
[0035]
步骤91:将碰撞信号输入至终点状态控制单元,判断碰撞信号是否等于1,若是则改变终点状态,若否则不改变终点状态;
[0036]
步骤92:比较自身状态的模长和终点状态目标值的模长得到两者之间的差距,判断两者之间的差距是否小于等于终点状态最大误差,若是则改变终点状态,若否则不改变终点状态;
[0037]
步骤93:将误差校正量输入至终点状态控制单元,采用如下公式更新终点状态:
[0038]
stateendnew=stateend β
·
errcorrval,
[0039]
式中,stateendnew为更新得到的终点状态,stateend为当前的终点状态,β为误差放大系数;
[0040]
步骤94:将更新的极限加速度和迭代步长输入至终点状态控制单元,终点状态单元将更新得到的极限加速度、更新得到的迭代步长和更新得到的终点状态代入路径轨迹方法。
[0041]
本发明相比现有技术突出且有益的技术效果是:
[0042]
在本发明中,从感知控制与感知容限实现了群体的运动的联动控制,使得群体行为、信息交互和任务意图达到有机的结合,能够显著地提升群体中的每个个体协同完成任务的效率和性能,而且面对复杂环境和突发事件也能够灵活地解决,以及面对个体数量增加也不会带来集群拥挤的问题,因此本发明具有工作效率高、鲁棒性强、可靠性高和集群表现优异等优点。
[0043]
在本发明中,本基于感知控制与感知容限的集群控制方法帮助集群有效应对复杂环境干扰以提高控制的稳定性与精准性并解决封闭空间内集群存活率随着个体数增加而迅速降低的问题。
附图说明
[0044]
图1是本发明的步骤流程示意图;
[0045]
图2是本发明的方法框架示意图;
具体实施方式
[0046]
为了便于本领域技术人员的理解,下面结合附图和具体实施例对本发明作进一步描述。
[0047]
需要说明的是,本基于感知控制与感知容限的集群控制方法应用在群体机器人系统上,用于解决通过控制个体运动实现期望的集群运动。群体机器人系统包括群体,群体由多个个体组成,个体指的是单个的机器人。机器人指的是能够半自主或全自主工作的智能机器。
[0048]
如图1所示,一种基于感知控制与感应容限的集群控制方法,包括如下步骤:
[0049]
步骤1:处理器配置群体的集群信息,其中,集群信息包括个体数量(n)、终止迭代次数(termstepcnt)、终点状态最大误差(termstepcnt)和个体感知属性(pecpatrbcurr),
个体感知属性包括极限加速度(maxacc)、感知范围(detrange)、感知容限(pecplmttagt)和迭代步长(iterstepsize);
[0050]
上述步骤中,感知范围为传感器的检测区域,若个体位于感知范围内时,则传感器可检测个体的状态,若个体位于感知范围外时,则传感器不检测个体的状态。
[0051]
步骤2:处理器初始化迭代次数(agentitercnt),配置个体的状态信息,其中,状态信息包括初始状态(stateinit)和终点状态(stateend);
[0052]
上述步骤中,初始状态包括个体初始时的位置和速度,终点状态包括个体终止时的位置和速度,初始状态的参数类型和终点状态的参数类型是相同的。初始时的迭代次数为0。
[0053]
步骤3:处理器将状态信息代入路径规划方法计算得到路径轨迹数据(pathtrajset),其中,路径轨迹数据包括每个迭代步长内个体的速度信息和位置信息;
[0054]
上述步骤中,初始状态的参数类型、终点状态的参数类型和输入路径规划方法的参数类型是相同的。路径轨迹方法可预先设置在处理器中。路径规划方法无限制但需要满足如下条件:
[0055]
(1)路径规划方法符合运动学规律,根据初始状态和终点状态代入路径规划方法计算得到路径轨迹数据,采用该路径轨迹数据驱动个体运动时,个体的运动状态呈现连续的变化;
[0056]
(2)路径轨迹数据包括个体的极限加速度和迭代步长,迭代步长为一秒内的步骤4至步骤11的迭代次数;
[0057]
(3)路径轨迹数据需要保证输入(即初始状态和终点状态)和输出(即路径轨迹数据)之间的映射关系是唯一的,即相同的输入只能计算得到相同的输出。
[0058]
步骤4:处理器根据路径轨迹数据驱动个体进行运动,根据路径轨迹数据索引得到个体的当前状态目标值(statecurrtagt)和终点状态目标值(stateendtagt);
[0059]
上述步骤中,个体可包括电机和舵机中的至少一种,处理器根据路径轨迹数据驱动个体进行运动,即处理器根据路径轨迹数据控制电机运转和舵机转向。由于路径轨迹数据为理想状态下的离散的轨迹序列,个体的当前状态目标值和终点状态目标值包含在路径轨迹数据中,通过索引得到当前状态目标值和终点状态目标值以便于后续进行迭代。初始状态为索引位置为0时的路径轨迹数据中索引得到的数据,个体当前状态目标值为索引位置为1时路径轨迹数据中索引得到的数据,终点状态目标值为索引位置为最后一位时路径轨迹数据中索引得到的数据。
[0060]
步骤5:传感器感知传感器所在个体的自身状态(statecurrsef)和传感器感知范围内的其他个体状态(statecurroth),根据自身状态和其他个体状态计算得到个体当前的感知信息量(pecpinfoamt);
[0061]
上述步骤中,传感器内嵌在个体中,传感器检测对应个体的数据作为个体的自身状态,其他个体为感知范围内除传感器所在个体外的个体。传感器的数量和个体的数量一致,传感器一一对应于个体,传感器内嵌在对应的个体中。
[0062]
步骤6:传感器将自身状态和感知信息量输入至当前状态控制单元(statecurrecu),将感知信息量、终点状态目标值和感知容限输入至感知属性控制单元(pecpatrbecu);
[0063]
上述步骤中,当前状态控制单元和感知属性控制单元为处理器的一部分。
[0064]
步骤7:感知属性控制单元根据感知信息量、终点状态目标值和感知容限更新个体感知属性;
[0065]
上述步骤中,感知属性控制单元实现了个体感知属性根据感知信息量、终点状态目标值和感知容限进行迭代调整,进而实现了个体在运动过程中感知属性控制单元可迭代获取到更加真实的个体感知属性。
[0066]
步骤8:当前状态控制单元预测状态误差(stateerr)和误差校正量(errcorrval);
[0067]
上述步骤中,当前状态控制单元实现了状态误差和误差校正量的迭代检测,进而实现了个体在运动过程中当前状态控制单元可迭代检测到更加真实的状态误差和误差校正量。
[0068]
步骤9:感知属性控制单元将更新后的个体感知属性输入至传感器和终点状态控制单元(stateendtagtecu),当前状态控制单元将状态误差和误差校正量输入至终点状态控制单元,终点状态控制单元根据状态误差、误差校正量和更新后的终点状态更新得到终点状态;
[0069]
上述步骤中,终点状态控制单元为处理器的一部分。更新后的个体感知属性包括更新后的极限加速度、感知范围和迭代步长,感知属性控制单元将更新后的感知范围输入至传感器,感知属性控制单元将更新后的感知范围和迭代步长输入至终点状态控制单元。状态误差、误差校正量、更新后的感知范围和迭代步长用于更新终点状态,从而迭代实现个体的终点状态进行环境误差的补偿,提高了个体运动状态的准确性。
[0070]
步骤10:处理器将更新后的个体感知属性和终点状态代入路径规划方法更新得到路径轨迹数据,迭代次数加一;
[0071]
上述步骤中,迭代次数加一即为:
[0072]
agentitercntnew=agentitercnt 1,
[0073]
式中,agentitercntnew为输出的迭代次数,agentitercnt为输入的迭代次数。
[0074]
步骤11:处理器判断迭代次数是否等于终止迭代次数,若是则终止迭代,若否则迭代步骤4至步骤11;
[0075]
上述步骤中,步骤4至步骤11为感知控制流程,通过迭代的方式实现了负反馈控制,以便于更加准确地进行集群控制。
[0076]
所述步骤5中,具体包括:
[0077]
步骤51:传感器感知传感器所在个体的自身状态和感知范围内的其他个体状态。
[0078]
步骤52:传感器根据自身状态和其他个体状态计算得到个体和其他个体之间的欧氏距离(dissefoth);
[0079]
上述步骤中,自身状态包括当前个体的位置(locsef),其他个体状态包括其他个体的位置(agentoth),欧式距离为个体的位置和其他个体的位置之间的距离,欧式距离的计算公式为:
[0080][0081]
上式中,locsef.x为个体的位置的x轴坐标,locsef.y为个体的位置的y轴坐标,agentoth.x为其他个体的x轴坐标,agentoth.y为其他个体的y轴坐标。
[0082]
步骤53:传感器根据如下公式计算得到其他个体所占的感知角度(φ):
[0083][0084]
式中,φ为其他个体所占的感知角度,bl为个体自身直径,dissefoth为欧氏距离。
[0085]
步骤54:传感器将所有其他个体的感知角度累加在一起得到总体的感知角度(pecpangle),将总体的感知角度除以2π得到感知信息量;
[0086]
上述步骤中,感知信息量的计算公式为:
[0087][0088]
所述步骤7中,具体包括:
[0089]
步骤71:感知属性控制单元比较感知信息量和感知容限的大小得到两者的差值(pecpdiff),判断两者的差值是否大于0,若是则保留两者的差值,若否则判断两者的差值的绝对值是否小于η倍的感知容限,η为控制个体逆向调整个体感知属性的区间参数,η∈(0,1),若是则保留两者的差值,若否则将两者的差值设置为0;
[0090]
上述步骤中,两者的差值的计算公式为:
[0091]
pecpdiff=pecpinfoamt-pecplmttagt,
[0092]
η可预先设置在处理器的感知属性控制单元中。
[0093]
步骤72:感知属性控制单元将两者的差值放大k倍后代入如下公式更新个体感知属性:
[0094]
pecpatrbnew=pecpatrbcurr α
·
pecpdiff,
[0095]
式中,pecpatrbnew为更新得到的个体感知属性,pecpatrbcurr为当前的个体感知属性,α为比例系数;
[0096]
上述步骤中,感知属性控制单元包括极限加速度控制单元(maxaccecu)、感知范围控制单元(dectrangeecu)、迭代步长控制单元(iterstepsizeecu)。由于个体感知属性包括极限加速度、感知范围和迭代步长,极限加速度控制单元根据上式更新极限加速度,感知范围控制单元根据上式更新感知范围,迭代步长控制单元根据上式更新迭代步长,极限加速度控制单元、感知范围控制单元和迭代步长控制单元可分别采用不同的比例系数α,从而更新得到个体感知属性。比例系数α可分别预先设置在极限加速度控制单元、感知范围控制单元和迭代步长控制单元中。感知属性控制单元将更新后的感知范围输入至传感器,从而调节传感器的感知范围。感知属性控制单元将更新后的极限加速度和迭代步长输入至终点状态控制单元,用于后续调整终点状态。
[0097]
步骤73:处理器根据路径轨迹数据和其他个体状态预判当前个体和其他个体是否会发生碰撞,若是则将碰撞信号设置为1,若否则将碰撞信号设置为0;
[0098]
上述步骤中,路径轨迹数据包括当前个体的路径,其他个体状态包括其他个体的速度方向,处理器判断当前个体的路径和其他个体的速度方向是否存在交叉,若是则判定当前个体和其他个体会发生碰撞,若否则判定当前个体和其他个体不会发生碰撞。
[0099]
所述步骤8中,具体包括:
[0100]
步骤81:将自身状态和当前状态目标值相减得到状态误差(stateerr);
[0101]
步骤82:判断状态误差容器中的状态误差数量是否等于误差预测序列长度(errpredlength),若等于则根据误差预测模型得到误差校正量,将误差校正量输入至终点状态控制单元,初始化状态误差容器,若不等于则将状态误差输入至状态误差容器,并设置误差校正量为0输入至终点状态控制单元;
[0102]
上述步骤中,误差预测序列长度和误差预测模型有关。状态误差容器是处理器的一部分,误差预测模型可以是卡尔曼滤波器模型。
[0103]
所述步骤9中,具体包括:
[0104]
步骤91:处理器将碰撞信号输入至终点状态控制单元,判断碰撞信号是否等于1,若是则改变终点状态,若否则不改变终点状态;
[0105]
上述步骤中,实现了当前个体和其他的避免发生碰撞的问题。
[0106]
步骤92:处理器比较自身状态的模长和终点状态目标值的模长得到两者之间的差距(currenddiff),判断两者之间的差距是否小于等于终点状态最大误差,若是则改变终点状态,若否则不改变终点状态;
[0107]
上述步骤中,比较自身状态的模长和终点状态目标值的模长得到两者之间的差距即:
[0108]
两者之间的差距=自身状态的模长-终点状态目标值的模长。
[0109]
步骤93:处理器将误差校正量输入至终点状态控制单元,采用如下公式更新终点状态:
[0110]
stateendnew=stateend β
·
errcorrval,
[0111]
式中,stateendnew为更新得到的终点状态,stateend为当前的终点状态,β为误差放大系数;
[0112]
上述步骤中,β预先设置在处理器中,可采用实际测试方式调整β的大小,使得个体实际轨迹与理想轨迹的偏差越小。
[0113]
步骤94:处理器将更新的极限加速度和迭代步长输入至终点状态控制单元,终点状态单元将更新得到的极限加速度、更新得到的迭代步长和更新得到的终点状态代入路径轨迹方法。
[0114]
如图2所示,为本发明提供的方法框架示意图,本发明是一种基于感知控制与感知容限的控制方法,包括如下5个部分:
[0115]
(1)感知区:个体通过传感器获取自身状态和感知范围内其他个体状态,借助其他个体状态与自身状态可以通过相关方法生成当前个体的感知容量,将自身状态与感知容量作为处理器的输入信号,其中,自身状态包括当前状态与终点状态,终点状态只有在单次迭代的最后才会被感知和传输;
[0116]
(2)目标状态区:作为ecu区的参考信号输入,其中的感知容限和初次终点目标状态需要提前设置,当前状态目标值与终点状态目标值可由路径规划方法生成;
[0117]
(3)ecu区:即为处理器,发明中的决策控制与误差校正部分,依托于基本控制单元与层级架构,其中感知属性控制单元作为最高层,输出的信号不仅用于控制极限加速度控制单元、感知范围控制单元与迭代步长控制单元输出值的变化幅度,还能实现个体预判碰撞时产生的决策转变;当前状态控制单元将个体的当前状态值与状态目标值作比对分析,用于评价环境中的误差以及其他噪声,输出信号至终点状态控制单元用于调整终点信息;
终点状态控制单元一方面接收当前状态控制单元输入的误差分析参考信号,从而调整终点信息来对抗环境因素,另一方面接收最高层感知属性控制单元输入的决策转换参考信号,用于实现封闭环境下个体间避障操作;
[0118]
(4)路径规划方法区:用于帮助个体规划未来路径并引导个体做出运动行为;
[0119]
(5)外部区:包括环境反馈函数、传感器和行动发生器硬件设施。
[0120]
上述实施例仅为本发明的较佳实施例,并非依此限制本发明的保护范围,故:凡依本发明的结构、形状、原理所做的等效变化,均应涵盖于本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。