1.本发明涉及计算机视觉领域中的人脸复杂表情识别问题,具体涉及一种结合上下文信息的多粒度学业情绪识别方法。
背景技术:
2.人脸表情识别技术是计算机视觉领域的一个长期研究热点,它在人机交互、在线购物、驾驶安全等诸多领域有着广泛的应用。现如今,基于计算机视觉的人脸表情识别研究主要基于七种基本表情,通过让网络模型提取人脸表情特征信息或者组合多个面部动作单元等方法进行表情识别。而实际场景中,人类表情通常是复杂的,基本表情无法诠释实际场景中人类的表情,使得已有方法在实际应用中效果不佳。学业情绪是人类在学习过程中展现的情绪状态,了解学生的学业情绪有助于掌握和分析学生的学习情况,从而为每个学生指定独特的学习计划。因此,在实际应用场景中,尤其在本发明提出的学习场景下产生的学业情绪,如何有效提高人脸复杂表情的识别效果仍然是一项难题。此外,由于复杂表情的研究数据集稀缺,使得表情识别算法受到限制。因此,如何有效扩充样本数据,同时保持表情种类之间数量平衡,提高网络模型的鲁棒性和泛化性也是需要攻克的难题。
技术实现要素:
3.基于上述技术问题,本发明的目的在于提供一种结合上下文信息的多粒度学业情绪识别方法,有效提高面向学业情绪的人脸表情识别准确率,进一步推进复杂表情在实际场景中的识别应用。
4.为了实现上述目的,本发明采用了以下技术方案:
5.一种结合上下文信息的多粒度学业情绪识别方法,采集动态学生视频,从动态学生视频中提取静态人脸图像,进行以下处理,
6.步骤s1:对人脸图像数据进行预处理;
7.步骤s2:构建自监督解耦人脸图像重建网络;
8.步骤s3:实现学业情绪数据集增广;
9.步骤s4:对人脸图像数据进行再处理;
10.步骤s5:构建结合上下文信息的多粒度学业情绪识别网络;
11.步骤s6:对面向学业情绪的人脸表情图像进行分类;
12.步骤s1、步骤s2、步骤s3通过对输入的人脸图像进行特征信息解耦,保留与学业情绪相关的表情、头部姿态信息,替换个体身份、光照背景信息,保证表情一致性、扩充稀有表情类别的数量,缩小数据集种类之间的差距,此外,生成的数据样本掩盖个体身份信息,实现对学业情绪数据集的扩充;步骤s4、步骤s5、步骤s6对输入的人脸图像进行再处理,将输入的人脸图像分割为:人脸图像和上下文信息图像,然后构建结合上下文信息的多粒度学业情绪识别网络,得到具有多种特征信息的特征融合向量,最后进行学业情绪类别预测。
13.进一步的,所述的步骤s1包括以下步骤:
14.步骤s11:采集的学业情绪视频数据,共包含6种学业情绪类别,分别为专注、喜悦、困惑、沮丧、分神、疲倦,从动态视频序列中抽帧提取静态学业情绪数据,做成学业情绪数据集;使用retinaface人脸检测算法,对输入图像进行人脸区域关键点检测、裁剪、对齐,得到人脸面部区域边框以及关键点坐标信息,并生成对应的皮肤掩码;
15.步骤s12:将数据分成训练集和测试集,其中每张图像都对应一个68个人脸关键点文件和一个皮肤掩码文件。
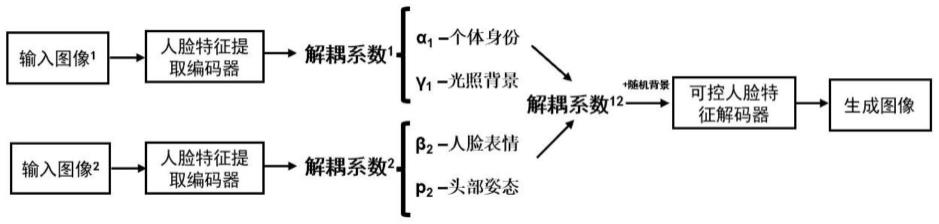
16.进一步的,所述的步骤s2包括两个模块:人脸特征提取编码器e和可控人脸特征解码器g,其中,
17.步骤s21:人脸特征提取编码器e使用resnet50网络模型作为主干网络用于提取人脸特征信息,包括四组不同的resnet残差块,每个残差块包含大小不同的卷积层,最后一层连接全连接层,实现将人脸特征属性解耦,最后得到257维的人脸特征属性系数,分别为:个体身份、人脸表情、光照和头部姿态系数,其中,其中,
18.步骤s22:可控人脸特征解码器g使用生成对抗网络gan作为主干网络,实现对人脸特征系数重构出人脸图像;
19.步骤s23:为使得可控人脸特征解码器g重构出的人脸图像更加拟合于输入图像,从而保证人脸特征提取编码器e能根据输入的图像得到期望的精确、分离的人脸属性解耦表示,通过在生成图像和输入图像之间构建损失函数对整个网络进行训练,定义了像素感知损失、表情与姿态损失、光照损失、深度感知损失,像素感知损失定义如下:
[0020][0021]
其中,i表示像素索引,表示人脸区域,||
·
||2表示l2范数,a表示图像的基于肤色的注意掩码值,ai的定义如下:
[0022][0023]
pi表示每个像素的肤色概率;
[0024]
表情与姿态损失用人脸对齐的方法检测图像人脸68个关键点,从而控制图像之间表情和姿态特征参数的差异,定义如下:
[0025][0026]
其中,{pn}表示输入图像检测的68关键点坐标位置,{p
′n}表示生成图像检测的68关键点坐标位置,ωn表示关键点权重,将嘴巴和鼻子周围的关键点权重值设置为1;
[0027]
对于光照条件的设定,只需要最小化sh系数差异,控制图像之间光照特征参数的差异,光照损失定义如下:
[0028][0029]
其中,γ(x)在3d重建网络中生成图像x给出的光照系数,是输入图像得到的光照系数;
[0030]
通过目视检查发现重构出来的图像人脸形状还是不够准确,为了解决这个问题引入感知级别的损失进一步调整训练,其定义如下:
[0031][0032]
其中,f(
·
)表示深度特征编码,《
·
,
·
》表示向量内积,
[0033]
通过上述网络结构训练,实现将人脸属性特征信息进行分解,可以对解耦的特征向量进行合理化的编辑,可用于数据增强工作。
[0034]
进一步的,所述的步骤s3包括以下步骤:
[0035]
步骤s31:选择两张具有不同人脸属性的输入图像1、输入图像2;
[0036]
步骤s32:将两张图像分别送入解耦重建网络,通过人脸特征提取编码器e回归出系数向量coeff1、coeff2;
[0037]
步骤s33:选取不同属性的人脸特征系数,选择输入图像1的个体身份、头部姿态和光照背景系数、选择输入图像2的表情系数进行编辑操作,合成解耦系数coeff
12
,同时具有两张图像的特征信息;
[0038]
步骤s34:将解耦系数coeff
12
送入网络的可控人脸特征解码器g重建出图像,该图像具有输入图像2的表情、头部姿态特征,输入图像1的其余人脸属性特征,实现可视化基于隐私安全的学业情绪数据集增广。
[0039]
进一步的,所述的步骤s4包括以下步骤:
[0040]
步骤s41:将步骤s3中扩充后的学业情绪数据集随机分为70%训练集,20%测试集, 10%验证集;
[0041]
步骤s42:使用retinaface人脸检测算法对输入图像进行人脸检测得到人脸区域边界框bi={x1,y1,x2,y2};根据边界框bi的坐标位置对原始输入图像进行裁剪、缩放操作,得到大小为96
×
96的人脸表情图像if;根据边界框bi的坐标位置对原始输入图像将人脸区域进行遮挡、缩放,得到112
×
112的遮挡人脸区域的上下文信息图像ic。
[0042]
进一步的,所述的步骤s5包括两个模块:双分支编码器模块和自适应特征融合模块,其中,双分支编码器模块是由表情特征编码模块和上下文信息编码模块构成;
[0043]
步骤s51:表情特征编码模块选择resnet18残差网络作为主干网络,通过多个残差块对输入的人脸图像if进行表情特征提取,得到面部表情的特征向量xf;
[0044]
步骤s52:上下文信息编码模块同样选择resnet18残差网络作为主干网络,对输入的上下文信息图像ic进行特征提取,得到上下文特征向量xc;为使得上下文信息编码模块仍能重视有效的上下文信息从而辅助表情特征信息,该模块加入注意力机制推理模块,将该特征向量xc送入注意力机制推理模块,得到注意力增强后的上下文特征向量表示如下:
[0045][0046]
其中,表示相乘运算符,是所有像素点的注意力权重值矩阵。注意力推理模块包含两个卷积层,以无监督的方式学习,xc经softmax函数归一化处理,保证所有像素点的注意力权重值之和为1。每个像素值的注意力权重表示如下:
[0047]
[0048]
其中,j∈{1,...,h
×
w},h
×
w为上下文特征向量xc的空间分辨率。
[0049]
步骤s53:将步骤s51得到的表情特征向量xf和步骤s52注意力机制增强后的上下文特征向量通过自适应特征融合模块进行融合,产生融合特征向量xa,自适应融合模块进行无监督学习,分别为两种特征向量分配最优的融合权重值,以产生最佳的融合特征向量,λf表示特征向量xf的权重值,λc表示特征向量的权重值,表示如下:
[0050][0051][0052]
其中,we、w
t
均表示网络参数,同样要对注意力权重值进行softmax函数归一化处理,得到λf λc=1,
[0053]
将两种特征向量进行融合得到融合特征向量xa,表示如下:
[0054][0055]
其中,表示连接运算符;
[0056]
所述的步骤s6包括以下步骤:
[0057]
步骤s61:将步骤s53获取的融合特征向量xa进行粗粒度分支的二分类学业情绪特征提取得到特征向量x1;
[0058]
步骤s62:将粗粒度分支提取的特征向量x1结合细粒度分支提取的六分类学业情绪特征向量x2进行特征融合;
[0059]
步骤s63:使用两个全连接层,联合softmax损失函数对面部表情进行学业情绪分类,得到复杂表情识别结果;
[0060]
进一步的,对步骤6的分类结果的准确率进行测算,将网络模型正确分类的样本数量占总测试样本数量的比例,如下:
[0061][0062]
其中,n
correct
表示网络模型正确分类的样本数量,n
total
表示总测试样本数量。
[0063]
本发明首为解决当前学业情绪数据难以大规模收集的技术问题,提出如下实现步骤:获取学业情绪数据集的人脸表情图像;设计一个自监督解耦人脸图像重建网络;对自监督解耦人脸图像重建网络进行迭代训练;基于训练好的人脸图像重建网络模型,通过编辑替换人脸特征的某些属性,获取新的人脸图像;又提出了一种面向学业情绪的人脸表情识别方法,用于解决当前现实环境中面向学业情绪的复杂表情识别准确率低的技术问题,实现步骤为:对获取的学业情绪数据集进行数据预处理得到人脸表情图像和上下文信息图像;将预处理后的全部图像分为训练样本集和测试样本集两部分;设计构建一个结合上下文信息的双分支人脸表情识别模型;利用双分支特征提取模块分别提取上下文特征信息和表情特征信息,然后使用自适应融合模块进行自监督融合两种特征向量;最后,通过结合多粒度分类思想,通过类似二分类查找法的思想将学业情绪进行细粒度划分,对人脸表情识别模型进行迭代训练;获取人脸表情识别结果,从而让网络通过多特征信息对学业情绪进行识别,降低了仅考虑人脸表情产生的歧义性,有效提高了面向学业情绪的人脸表情识别准确率;另外,面向学业情绪的数据增广方法,提高了网络模型对学业情绪的识别能力,有效实现数据扩充。
[0064]
本发明的有益效果为:1.隐私安全的学业情绪数据集增广方法,相较于常用数据增强方法而言实现对原数据的身份掩盖并保证数据的有效扩充;2.面向学业情绪的人脸情识别方法有效提高表情识别准确率,且相较于基本表情识别而言扩展了复杂表情在实际场景中的识别应用。
附图说明
[0065]
图1为本发明学业情绪数据集增广网络结构。
[0066]
图2为本发明学业情绪数据集增广效果图。
[0067]
图3为本发明原理结构示意图。
[0068]
图4为本发明注意力推理模块原理结构示意图。
[0069]
图5为本发明自适应特征融合模块原理结构示意图。
具体实施方式
[0070]
下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0071]
如图1-图5所示,本发明提供一种技术方案:
[0072]
图2中,第一行为affectnet数据集输入的原始图像,第一列为采集的原始学业情绪输入图像,选择第一行图像的身份、光照系数,选择第一列图像的表情、头部姿态系数,然后加入随机背景噪声,生成新的图像。
[0073]
一种结合上下文信息的多粒度学业情绪识别方法,采集动态学生视频,从动态学生视频中提取静态人脸图像,进行以下处理,
[0074]
步骤s1,对人脸图像数据进行预处理;包括以下步骤:步骤s11:采集的学业情绪视频数据,共包含6种学业情绪类别,分别为专注、喜悦、困惑、沮丧、分神、疲倦,从动态视频序列中抽帧提取静态学业情绪数据,做成学业情绪数据集;使用retinaface人脸检测算法,对输入图像进行人脸区域关键点检测、裁剪、对齐,得到人脸面部区域边框以及关键点坐标信息,并生成对应的皮肤掩码;步骤s12:将数据分成训练集和测试集,其中每张图像都对应一个68个人脸关键点文件和一个皮肤掩码文件;
[0075]
步骤s2:构建自监督解耦人脸图像重建网络;步骤s2包括两个模块:人脸特征提取编码器e和可控人脸特征解码器g,其中,
[0076]
步骤s21:人脸特征提取编码器e使用resnet50网络模型作为主干网络用于提取人脸特征信息,包括四组不同的resnet残差块,每个残差块包含大小不同的卷积层,最后一层连接全连接层,实现将人脸特征属性解耦,最后得到257维的人脸特征属性系数,分别为:个体身份、人脸表情、光照和头部姿态系数,其中,其中,
[0077]
步骤s22:可控人脸特征解码器g使用生成对抗网络gan作为主干网络,实现对人脸特征系数重构出人脸图像;
[0078]
步骤s23:为使得可控人脸特征解码器g重构出的人脸图像更加拟合于输入图像,
从而保证人脸特征提取编码器e能根据输入的图像得到期望的精确、分离的人脸属性解耦表示,通过在生成图像和输入图像之间构建损失函数对整个网络进行训练,定义了像素感知损失、表情与姿态损失、光照损失、深度感知损失,像素感知损失定义如下:
[0079][0080]
其中,i表示像素索引,表示人脸区域,||
·
||2表示l2范数,a表示图像的基于肤色的注意掩码值,ai的定义如下:
[0081][0082]
pi表示每个像素的肤色概率;
[0083]
表情与姿态损失用人脸对齐的方法检测图像人脸68个关键点,从而控制图像之间表情和姿态特征参数的差异,定义如下:
[0084][0085]
其中,{pn}表示输入图像检测的68关键点坐标位置,{p
′n}表示生成图像检测的68关键点坐标位置,ωn表示关键点权重,将嘴巴和鼻子周围的关键点权重值设置为1;
[0086]
对于光照条件的设定,只需要最小化sh系数差异,控制图像之间光照特征参数的差异,光照损失定义如下:
[0087][0088]
其中,γ(x)在3d重建网络中生成图像x给出的光照系数,是输入图像得到的光照系数;
[0089]
通过目视检查发现重构出来的图像人脸形状还是不够准确,为了解决这个问题引入感知级别的损失进一步调整训练,其定义如下:
[0090][0091]
其中,f(
·
)表示深度特征编码,《
·
,
·
》表示向量内积,
[0092]
通过上述网络结构训练,实现将人脸属性特征信息进行分解,可以对解耦的特征向量进行合理化的编辑,可用于数据增强工作;
[0093]
步骤s3:实现学业情绪数据集增广,如图1、2;包括以下步骤:步骤s31:选择两张具有不同人脸属性的输入图像1(image1)、输入图像2(image2);步骤s32:将两张图像分别送入解耦重建网络,通过人脸特征提取编码器e回归出系数向量coeff1、coeff2;步骤s33:选取不同属性的人脸特征系数,选择输入图像1(image1)的个体身份、头部姿态和光照背景系数、选择输入图像2(image2)的表情系数进行编辑操作,合成解耦系数coeff
12
,同时具有两张图像的特征信息;步骤s34:将解耦系数coeff
12
送入网络的可控人脸特征解码器g重建出图像,该图像具有输入图像2(image2)的表情、头部姿态特征,输入图像1 (image1)的其余人脸属性特征,实现可视化基于隐私安全的学业情绪数据集增广;
[0094]
步骤s4:对人脸图像数据进行再处理;包括以下步骤:步骤s41:将步骤s3中扩充后的学业情绪数据集随机分为70%训练集,20%测试集,10%验证集;步骤s42:使用
retinaface人脸检测算法对输入图像(input
image
)进行人脸检测得到人脸区域边界框 bi={x1,y1,x2,y2};根据边界框bi的坐标位置对原始输入图像(input
image
)进行裁剪、缩放操作,得到大小为96
×
96的人脸表情图像if;根据边界框bi的坐标位置对原始输入图像 (input
image
)将人脸区域进行遮挡、缩放,得到112
×
112的遮挡人脸区域的上下文信息图像ic;
[0095]
步骤s5:构建结合上下文信息的多粒度学业情绪识别网络,如图3、4、5;包括两个模块:双分支编码器模块和自适应特征融合模块,其中,双分支编码器模块是由表情特征编码模块和上下文信息编码模块构成;
[0096]
步骤s51:表情特征编码模块选择resnet18残差网络作为主干网络,通过多个残差块对输入的人脸图像if进行表情特征提取,得到面部表情的特征向量xf;
[0097]
步骤s52:上下文信息编码模块同样选择resnet18残差网络作为主干网络,对输入的上下文信息图像ic进行特征提取,得到上下文特征向量xc;为使得上下文信息编码模块仍能重视有效的上下文信息从而辅助表情特征信息,该模块加入注意力机制推理模块,将该特征向量xc送入注意力机制推理模块,得到注意力增强后的上下文特征向量表示如下:
[0098][0099]
其中,表示相乘运算符,是所有像素点的注意力权重值矩阵,注意力推理模块包含两个卷积层,以无监督的方式学习,xc经softmax函数归一化处理,保证所有像素点的注意力权重值之和为1,每个像素值的注意力权重表示如下:
[0100][0101]
其中,j∈{1,...,h
×
w},h
×
w为上下文特征向量xc的空间分辨率;
[0102]
步骤s53:将步骤s51得到的表情特征向量xf和步骤s52注意力机制增强后的上下文特征向量通过自适应特征融合模块进行融合,产生融合特征向量xa,自适应融合模块进行无监督学习,分别为两种特征向量分配最优的融合权重值,以产生最佳的融合特征向量,λf表示特征向量xf的权重值,λc表示特征向量的权重值,表示如下:
[0103][0104][0105]
其中,we、w
t
均表示网络参数,同样要对注意力权重值进行softmax函数归一化处理,得到λf λc=1,
[0106]
将两种特征向量进行融合得到融合特征向量xa,表示如下:
[0107][0108]
其中,表示连接运算符;
[0109]
步骤s6:对面向学业情绪的人脸表情图像进行分类;包括以下步骤:步骤s61:将步骤s53获取的融合特征向量xa进行粗粒度分支的二分类学业情绪特征提取得到特征向量 x1;步骤s62:将粗粒度分支提取的特征向量x1结合细粒度分支提取的六分类学业情绪特征向量x2进行特征融合;步骤s63:使用两个全连接层,联合softmax损失函数对面部表情进行学业情绪分类,得到复杂表情识别结果。
[0110]
步骤s1、步骤s2、步骤s3通过对输入的人脸图像进行特征信息解耦,保留与学业情绪相关的表情、头部姿态信息,替换个体身份、光照背景信息,保证表情一致性、扩充稀有表情类别的数量,缩小数据集种类之间的差距,此外,生成的数据样本掩盖个体身份信息,实现对学业情绪数据集的扩充;步骤s4、步骤s5、步骤s6对输入的人脸图像进行再处理,将输入的人脸图像分割为:人脸图像和上下文信息图像,然后构建结合上下文信息的多粒度学业情绪识别网络,得到具有多种特征信息的特征融合向量,最后进行学业情绪类别预测。
[0111]
对步骤6的分类结果的准确率进行测算,将网络模型正确分类的样本数量占总测试样本数量的比例,如下:
[0112][0113]
其中,n
correct
表示网络模型正确分类的样本数量,n
total
表示总测试样本数量。
[0114]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
