技术特征:
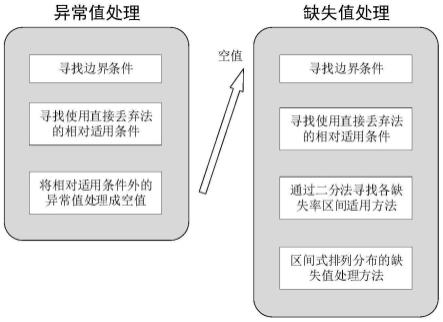
1.基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,包括以下步骤:s1、进行异常值处理,具体过程包括以下步骤:s11、确定异常值处理的初始边界条件为x%,即对多余物定位数据集的完备数据集做x%比例的异常化处理;利用分类学习器在未经处理的数据集上进行预测并取得一个预测精度,再利用分类学习器分别在使用直接丢弃法和数值替换法处理后的数据集上进行预测并分别取得多个预测精度;分析分类学习器在未经处理的数据集上取得的预测精度是否高于在使用直接丢弃法和数值替换法处理后的数据集上取得的预测精度;根据分析结果,选择以1%的幅度上浮或下调边界条件,重新对该结构的完备数据集做新的比例的异常化处理;通过循环上述过程,当数据集的异常度为某个数值时,分类学习器在未经处理的数据集上取得的预测精度要高于在使用直接丢弃法和数值替换法处理后的数据集上取得的预测精度;以此时异常度对应的数值作为异常值边界条件;s12、在异常值边界条件的适用范围内,通过二分法寻找直接丢弃法的相对适用条件;s2、进行缺失值处理,具体过程包括以下步骤:s21、确定缺失值处理的初始边界条件为y%,即对多余物定位数据集的完备数据集做y%比例的缺失化处理;分别使用直接丢弃法和数值填充法进行处理,比较分类学习器在使用数值填充法处理后的数据集上取得的预测精度是否低于在使用直接丢弃法处理后的数据集上取得的;根据比较结果,选择以1%的幅度上浮或下调边界条件,重新对完备数据集做新的比例的缺失化处理;通过循环上述过程,确定当数据集的缺失率为某个数值时,分类学习器在使用数值填充法处理后的数据集上取得的预测精度要低于或等于在使用直接丢弃法处理后的数据集上取得的预测精度,即当数据集的缺失率小于该某个数值时,认定该缺失率的具体数值为缺失值处理方法对应的边界条件;s22、在缺失值处理方法边界条件的适用范围内,通过二分法寻找直接丢弃法的相对适用条件;s3、针对于多余物定位数据集,基于s1、s2即确定了不完备数据处理模型。2.根据权利要求1所述的基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,在异常值边界条件的适用范围内,通过二分法寻找直接丢弃法的相对适用条件的过程包括以下步骤:将零异常度到新边界条件对应异常值的具体数值视为一个区间,并且区间的上限为新边界条件对应异常值的具体数值,下限为零异常度;新边界条件初始值为异常值边界条件;利用式(1)寻找当前上限与下限之间的中点,即当前异常度区间的中值,称之为第一中值;式中,high表示异常度区间的上限,也即边界条件对应异常值的具体数值;low表示异常度区间的下限,也即零异常度;对完备数据集做比例为第一中值的异常化处理,并分别使用直接丢弃法和数值替换法
进行处理,分析分类学习器在使用直接丢弃法处理后的数据集上取得的预测精度是否高于在使用数值替换法处理后的数据集上取得的;若判断结果为假,调整得到新的异常度区间,区间的上限调整为第一中值对应的具体数值,区间的下限保持零异常度不变;继续利用式(1)寻找当前上限和下限之间的中点,称之为第二中值;继续对该结构的完备数据集做比例为第二中值的异常化处理,并同样分别使用直接丢弃法和数值替换法进行处理,分析分类学习器在使用直接丢弃法处理后的数据集上取得的预测精度是否高于在使用数值替换法处理后的数据集上取得的;若判断结果仍然为假,根据上述过程,继续调整得到新的异常度区间,并且将第二中值视为新的上限,保持下限不变;如此往复判断与调整,直至判断结果为真;在判断结果为真的的情况下,分类学习器在使用直接丢弃法处理后的数据集上取得的预测精度要高于在使用数值填充法处理后的数据集上取得的;认定当前第n中值对应的具体数值为直接丢弃法的相对适用条件。3.根据权利要求2所述的基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,在异常值处理的过程中,当确定了直接丢弃法的相对适用条件之后,再通过使用二分法来寻求相对适用条件到边界条件之间的区间范围内,多个小的异常度区间适用的具体的数值填充法。4.根据权利要求3所述的基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,异常值处理的初始边界条件为20%。5.根据权利要求4所述的基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,利用式(1)寻找异常度区间的中值过程中,当异常度区间长度的具体数值为奇数时,先增加1%调整为偶数后,再获取新的偶数式异常度区间的中值。6.根据权利要求5所述的基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,在缺失值处理方法边界条件的适用范围内,通过二分法寻找直接丢弃法的相对适用条件的过程包括以下步骤:将零缺失率到新的边界条件对应的缺失值的具体数值视为一个区间,并且区间的上限为新的边界条件对应缺失值的具体数值,下限为零缺失率;利用式(2)寻找当前上限与下限之间的中点,即当前缺失率区间的中值,称之为第一中值;式中,high表示缺失率区间的上限,也即边界条件对应缺失值的具体数值;low表示缺失率区间的下限;对该完备数据集做比例为第一中值的缺失化处理,并分别使用直接丢弃法和数值填充法进行处理,分析分类学习器在使用直接丢弃法处理后的数据集上取得的预测精度是否高于在使用数值填充法处理后的数据集上取得的;若判断结果为假,则调整得到新的缺失率区间,区间的上限调整为第一中值对应的具体数值,区间的下限保持零缺失率不变;继续利用式(2)寻找当前上限和下限之间的中点,称之为第二中值;继续对该结构的完备数据集做比例为第二中值的缺失化处理,并同样分别使用直接丢弃法和数值填充法进行处理,分析分类学习器在使用直接丢弃法处理后的数据集上取得的预测精度是否高于在使用数值填充法处理后的数据集上取得的;若判断结果仍然为假,根据上述步骤,继续调整得到新的缺失率区间,并且将第二中值视为新的上限,保持下界不变;如此往复判断与调整,直至判断
结果为真;在判断结果为真的情况下,认定当前第n中值对应的具体数值为直接丢弃法的相对适用条件。7.根据权利要求6所述的基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,在缺失值处理的过程中,当在确定了直接丢弃法的相对适用条件之后,再通过使用二分法来寻求直接丢弃法的相对适用条件到边界条件之间的区间范围内,多个小的缺失率区间适用的具体的数值填充法。8.根据权利要求7所述的基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,通过使用二分法来寻求直接丢弃法的相对适用条件到边界条件之间的区间范围内,多个小的缺失率区间适用的具体的数值填充法的过程包括以下步骤:将直接丢弃法的相对适用条件到边界条件视为一个区间,称之为总区间,则区间的上限为边界条件对应缺失值的具体数值,下限为相对适用条件对应缺失值的具体数值;利用式(2)寻找当前上限与下限之间的中点,即当前缺失率区间的中值;对完备数据集做比例为当前中值的缺失化处理;分别使用多种具体的数值填充法进行处理,比较分类学习器在分别使用多种具体的数值填充法处理后的数据集上取得的预测精度,得出最高预测精度对应的数值填充法;调整得到新的缺失率区间,区间的上限调整为当前的中值对应的具体数值,区间的下限保持相对适用条件不变;继续利用式(2)寻找当前上限和下限之间的中点,并同样对完备数据集做比例为当前中值的缺失化处理;再次分别使用多种具体的数值填充法进行处理,比较分类学习器在分别使用多种具体的数值填充法处理后的数据集上取得的预测精度,得出最高预测精度对应的数值填充法;将本次的比较结果与上一次的比较结果进行对比,判断最高预测精度对应的数值填充法相同;调整得到新的缺失率区间,区间的上限调整为当前的中值对应的具体数值,区间的下限保持相对适用条件不变,重复一次上述步骤;同样得出本次分类学习器取得最高预测精度的数据集对应的具体数值填充法;将本次的比较结果与前两次的比较结果进行对比,判断三次分析结果是否一致;若三次分析结果一致,则将第一次分析时对应的中值视为上限,直接丢弃法的相对适用条件视为下限,得到一个缺失率区间;认定当前的具体数值填充法为得到的新的缺失率区间上的最佳缺失值处理方法;若前三次分析结果不一致,则继续采用同样的步骤得到第4、5、
……
n次的分析结果,并分别以当前的分析结果与相近的前两次的分析结果进行对比,直至连续三次的分析结果一致;这样,调整得到新的缺失率区间,区间的上限为连续三次分析中第一次分析对应中值的具体数值,区间的下限为直接丢弃法的相对适用条件。9.根据权利要求8所述的基于缺失率与异常度度量的不完备数据集建模方法,其特征在于,在确定多个小的缺失率区间适用的具体的数值填充法的过程中,在满足“连续三次分析结果一致”的基础上,将进行第三次分析的中值视为下界,将进行第二次分析的中值视为上界,将它们组成的区间称为辅助判断区间;需要满足辅助判断区间的长度低于总区间长度的1/10。10.基于缺失率与异常度度量的不完备数据集处理方法,其特征在于,包括以下步骤:步骤一:将待处理的多余物定位数据集记为当前数据集a;同时获取数据集a的同种结构的不完备数据集,获取当前数据集a中异常值的个数,进而计算数据集的异常度;所述的同种结构的不完备数据集的确定过程:将数据集a的同种结构的完备数据集,带入不完备数据处理模型进行处理,得到获取数据集a的同种结构的不完备数据集;所述的不
完备数据处理模型为基于权利要求9所述的基于缺失率与异常度度量的不完备数据集建模方法确定的不完备数据处理模型;步骤二:判断当前数据集a的异常度是否在不完备数据处理模型的异常值处理部分的边界条件内;如果判断结果为真,表明当前数据集在能够进行异常值处理的范围内,继续步骤三的处理;步骤三:判断当前数据集a的异常度是否在不完备数据处理模型的异常值处理部分适用直接丢弃法的相对适用条件内;如果判断结果为假,表明数据集的异常度在边界条件和相对适用条件范围内,将异常值处理成空值进行统一处理,并继续步骤四的处理;如果判断结果为真,表明数据集的异常度较小,则对当前数据集中的异常值使用直接丢弃法进行处理,跳过步骤四,直接进入步骤五进行处理;步骤四:将当前数据集a中的异常值处理成空值,即缺失值;步骤五:集中获取当前数据集a中的缺失值个数,进而计算数据集的缺失率;步骤六:判断当前数据集a的缺失率是否在不完备数据处理模型的缺失值处理部分的边界条件内;如果判断结果为真,表明当前数据集在能够进行缺失值处理的范围内,继续步骤七的处理;如果判断结果为假,表明当前数据集的质量已经比较低下,不对该数据集进行处理;步骤七:判断当前数据集a的缺失率是否在不完备数据处理模型的缺失值处理部分适用直接丢弃法的相对适用条件内;如果判断结果为假,表明数据集的缺失率在边界条件和相对适用条件范围内,表明当前数据集在值得处理的范围内,继续步骤八的处理;如果判断结果为真,表明数据集的缺失率较小,则对当前数据集中的缺失值使用直接丢弃法进行处理;步骤八:根据当前数据集的缺失率的数值大小,确定其归属于不完备数据处理模型的具体缺失率区间,并应用该缺失率区间对应的数值填充法对当前数据集进行缺失值处理。
技术总结
基于缺失率与异常度度量的不完备数据集建模及处理方法,属于多余物检测技术领域。本发明为了解决现有的多余物检测方法忽略了对异常值的探索的问题和针对缺失值的填补方法很少将应用对象扩展到数据集层面的问题。本发明对数据集中容易忽视的异常值问题进行了充分考虑,并引入数据结构领域的二分法来缩小区间长度和找寻数据分布规律,构建静态或固定结构数据集的不完备数据处理模型,在模型建立阶段先对不完备数据处理模型异常值处理部分的规则进行了探索,后对不完备数据处理模型缺失值处理部分的规则进行了探索,最终针对多余物定位数据集,参照不完备数据处理模型的处理过程建立不完备数据处理模型,并基于模型对多余物定位数据进行处理。物定位数据进行处理。物定位数据进行处理。
技术研发人员:王国涛 孙志刚 张敏 于松屹 耿仁轩 王佳琦
受保护的技术使用者:黑龙江大学
技术研发日:2022.08.11
技术公布日:2022/11/15
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。