一种基于mysqlbinlog的元数据同步方法
技术领域:
:1.本发明涉及关系型数据库同步
技术领域:
:,具体地说是一种基于mysqlbinlog的元数据同步方法。
背景技术:
::2.随着信息时代的飞速发展,大数据、人工智能的兴起,数据作为一种资源,越来越被一些企业、单位重视,数据产出的经济和社会价值也越来越明显。当今社会,企业数据越来越庞大、复杂,呈现数据量巨大、数据种类繁多包括结构化数据和非结构化数据、数据存放单一等特点,这势必给数据带来安全和不可靠的隐患,因此数据的同步和备份显得越来越重要。3.在数据库同步需要同步数据库的全量和增量数据。全量可以认为是当前数据库中数据的一个快照,比如有多少库多少表等。增量是以采集全量的点为基准点之后的变更。增量数据包括dml(表数据的增删改)以及dml(增删库、增删表或表中增删列、重命名等表属性的修改)。为保证源端和目的端库的元数据一致,需要及时进行ddl数据的同步。4.mysql作为一种开源关系型数据库,由于其良好的功能和性能成为最流行的数据库,广泛应用于各种业务系统。mysql生成的二进制日志binlog中包含了ddl及dml数据,可以解析日志还原出数据操作用于数据同步。5.在现有技术中,公开号为cn112306743a,名称为《数据处理方法、装置、电子设备及计算机存储介质》的专利申请描述了mysql分库分表的分布式系统的备份恢复,但是该专利申请中未对ddl进一步描述处理。还有公开号为cn110879813a,名称为《一种基于二进制日志解析的mysql数据库增量同步实现方法》的专利申请描述了基于binlog的dml增量采集,但是该申请未对ddl数据进行采集及进一步处理。技术实现要素:6.本发明的目的是针对以上不足,提供一种基于mysqlbinlog的元数据同步方法,7.本发明所采用技术方案是:8.一种基于mysqlbinlog的元数据同步方法,包括如下步骤:9.s1、配置源端mysql数据库,开启binlog;10.s2、采集全量表元数据,获取当前数据库中的库、表、字段等信息;11.s3、查询并记录当前日志文件,并将日志文件内偏移量作为增量基准;12.s4、根据增量基准,获取并解析binlog日志文件;13.s5、将从binlog日志文件中解析出来的sql语句进行解析,并将解析后的sql语句填充到数据结构中;14.s6、将所获取的增量日志传递到目的端,并在目的端执行同步数据;15.s7、记录所获取的日志文件及最后的偏移量作为新的增量基准;16.s8、间隔一定的时间后,重复步骤s4-s7。17.作为进一步的优化,本发明步骤s1中,配置源端mysql数据库配置过程中,在开启binlog后,还包括配置binlog日志文件名以及binlog日志文件路径,并配置serverid。18.作为进一步的优化,本发明步骤s2中,通过访问information_schema中的表,获取表schemata为库信息,tables为表信息,columns为列信息,views为视图信息;19.采集全量表元数据时,在内存中记录该表结构数据。20.作为进一步的优化,本发明步骤s3中,在采集全量表元数据之前需要记录下当前的binlog文件以及当前binlog文件的位置,若开启了gtid,并记录gtid号。21.作为进一步的优化,本发明步骤s4中,与源端数据库建立数据库连接,向master注册slave,然后发送从某个增量点获取数据的请求(com_binlog_dump),接收二进制日志数据并逐个解析,直到数据解析完成。22.作为进一步的优化,本发明步骤s4中,解析binlog过程中需要记录日志文件及位置position,以用于下次增量查询或异常恢复。23.作为进一步的优化,本发明步骤s5中,在binlog中解析出来的sql语句中包括ddl变更和dwl变更,在解析ddl变更以后,需要将解析后的ddl变更对内存中记录的表元数据进行更新,在解析dwl数据时,需要依照此前记录的表元数据。24.作为进一步的优化,本发明步骤s6中,源端采集解析的ddl变更数据序列化后传递到目的端,目的端根据requestparam以及自身的数据类型,生成相应操作的sql语句,并执行所生成的语句。25.本发明具有以下优点:26.1、本发明的元数据同步方法,先其中一个时间点作为基准点,记录binlog日志文件名和偏移量作为增量基准,从该增量基准作为起始点获取binlog日志文件数据并解析其中的事件,对于binlog日志文件中解析出来的ddl变更需要解析成中间格式的数据结构,并转换成二进制数据通过mq发送到目的端,目的端对中间格式的数据结构反序列化,生成sql语句并执行;27.2、本发明通过同时同步ddl变更和dml变更使得源端和目的端的结构和数据保持一致性;28.3、本发明通过将ddl变更变换为中间数据结构,既可以用作异构数据的元数据同步,还可以在目的端精准控制允许执行的操作。附图说明29.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。30.下面结合附图对本发明进一步说明:31.图1为源端数据库的采集流程示意图;32.图2为从源端获取binlog日志并解析的流程示意图。具体实施方式33.下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互结合。34.需要理解的是,在本发明实施例的描述中,“第一”、“第二”等词汇,仅用于区分描述的目的,而不能理解为指示或暗示相对重要性,也不能理解为指示或暗示顺序。在本发明实施例中的“多个”,是指两个或两个以上。35.本发明实施例中的属于“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,单独存在b,同时存在a和b这三种情况。另外,本文中字符“/”一般表示前后关联对象是一种“或”关系。36.本实施例提供一种基于mysqlbinlog的元数据同步方法,主要过程为在源端数据库采集binlog日志文件,并进行解析后应用到目标端,具体的,包括如下步骤:37.s1、配置源端mysql数据库,开启binlog;38.步骤s1中,配置源端mysql数据库配置过程中,在开启binlog后,还包括配置binlog日志文件名以及binlog日志文件路径,并配置serverid;具体的,需要如下方式重启mysql配置文件::39.log_bin=on40.log_bin_basename=binlog日志文件路径41.log_bin_index=binlog日志文件名42.server-id=唯一标识一个客户端的整形数43.并在配置完成后,重启mysql服务;44.s2、采集全量表元数据,获取当前数据库中的库、表、字段等信息;45.通过访问information_schema中的表,获取表schemata为库信息,tables为表信息,columns为列信息,views为视图信息;可以通过执行sql简单查看,获取所有库(》showdatabases;),获取库的表(》showtables;),获取表的字段(》showcreatetabletable1;显示建表语句);46.在内存中记录此表结构数据,后续通过解析增量数据来更新;47.s3、查询并记录当前日志文件,并将日志文件内偏移量作为增量基准;48.binlog是一组文件,其中包含了有关对mysql服务器实例进行的数据修改的信息。日志由一组二进制日志文件和一个索引文件组成。索引文件记录了当前的日志文件。日志文件中包含了数据修改的事件。日志文件格式到目前有三个版本,需要根据mysql版本确定日志文件格式;49.在采集全量表元数据之前需要记录下当前的binlog文件以及当前binlog文件的位置,若开启了gtid,并记录gtid号;通过sql获取增量点的方式示例如下:[0050][0051]s4、根据增量点,获取并解析binlog日志文件;[0052]通过建立数据库连接,并向mysql发送命令再接收数据进行处理。向master注册slave(com_register_slave),然后发送从某个增量点获取数据的请求(com_binlog_dump),接收二进制日志数据并逐个解析,直到数据解析完成。解析过程中需要记录日志文件及位置position,以用于下次增量查询或异常恢复。在发送获取增量数据前获取增量基准及当前表结构并记录备用。[0053]binlog-event表示了所有的事件及每个事件的格式,以此二进制格式解析;[0054]其中的事件:write_rows_event,update_rows_event,delete_rows_event记录了数据的增删改操作的dml事件。query_event记录了ddl操作成功的sql语句。[0055]s5、将从binlog日志文件中解析出来的sql语句进行解析,并将解析后的sql语句填充到数据结构中;[0056]从binlog中解析出的sql语句如果是同一种数据库且配置完全一样,可以直接使用。否则需要进一步解析使用。sql解析需要使用语法分析及词法分析工具,如flex/bison,可以参考mysql源码中的sql_yacc.yy及sql_lex.h和sql_lex.cc。解析sql语句,并填充到数据结构中。[0057]数据结构用proto3语法描述如下:[0058][0059][0060][0061]proto3定义的数据结构可以生成c /java等语言的代码。数据结构提供了序列化和反序列化的功能[0062]s6、将所获取的增量日志传递到目的端,并在目的端执行同步数据;[0063]在解析ddl变更之后,需要将解析后的ddl操作对内存中记录的表元数据做更新。比如ddl为在某位置增加列,则需要在表示表列的数组中增加一列,并正确修改列的序号;如果ddl为重命名列,则需要修改表列中的命名;如果删除列,则需要修改该列后续列的列序列号。[0064]解析dml数据时需要依照记录此处记录的表元数据。[0065]当解析binlog日志到与增量日志采集前获取的日志位置一致时,此时内存中的表元数据应该与数据库中的表元数据一致。如果有误差可以依据策略(忽略误差或报错),使用数据库中的元数据替换内存中的元数据,以使得后续binlog日志中的dml数据能正确解析。[0066]s7、间隔一定的时间后,重复步骤s4-s6。[0067]以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本
技术领域:
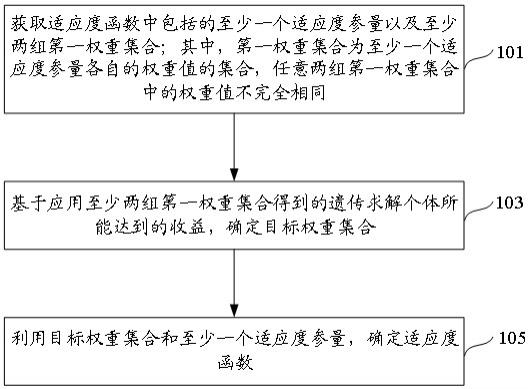
:的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。当前第1页12当前第1页12
技术领域:
:1.本发明涉及关系型数据库同步
技术领域:
:,具体地说是一种基于mysqlbinlog的元数据同步方法。
背景技术:
::2.随着信息时代的飞速发展,大数据、人工智能的兴起,数据作为一种资源,越来越被一些企业、单位重视,数据产出的经济和社会价值也越来越明显。当今社会,企业数据越来越庞大、复杂,呈现数据量巨大、数据种类繁多包括结构化数据和非结构化数据、数据存放单一等特点,这势必给数据带来安全和不可靠的隐患,因此数据的同步和备份显得越来越重要。3.在数据库同步需要同步数据库的全量和增量数据。全量可以认为是当前数据库中数据的一个快照,比如有多少库多少表等。增量是以采集全量的点为基准点之后的变更。增量数据包括dml(表数据的增删改)以及dml(增删库、增删表或表中增删列、重命名等表属性的修改)。为保证源端和目的端库的元数据一致,需要及时进行ddl数据的同步。4.mysql作为一种开源关系型数据库,由于其良好的功能和性能成为最流行的数据库,广泛应用于各种业务系统。mysql生成的二进制日志binlog中包含了ddl及dml数据,可以解析日志还原出数据操作用于数据同步。5.在现有技术中,公开号为cn112306743a,名称为《数据处理方法、装置、电子设备及计算机存储介质》的专利申请描述了mysql分库分表的分布式系统的备份恢复,但是该专利申请中未对ddl进一步描述处理。还有公开号为cn110879813a,名称为《一种基于二进制日志解析的mysql数据库增量同步实现方法》的专利申请描述了基于binlog的dml增量采集,但是该申请未对ddl数据进行采集及进一步处理。技术实现要素:6.本发明的目的是针对以上不足,提供一种基于mysqlbinlog的元数据同步方法,7.本发明所采用技术方案是:8.一种基于mysqlbinlog的元数据同步方法,包括如下步骤:9.s1、配置源端mysql数据库,开启binlog;10.s2、采集全量表元数据,获取当前数据库中的库、表、字段等信息;11.s3、查询并记录当前日志文件,并将日志文件内偏移量作为增量基准;12.s4、根据增量基准,获取并解析binlog日志文件;13.s5、将从binlog日志文件中解析出来的sql语句进行解析,并将解析后的sql语句填充到数据结构中;14.s6、将所获取的增量日志传递到目的端,并在目的端执行同步数据;15.s7、记录所获取的日志文件及最后的偏移量作为新的增量基准;16.s8、间隔一定的时间后,重复步骤s4-s7。17.作为进一步的优化,本发明步骤s1中,配置源端mysql数据库配置过程中,在开启binlog后,还包括配置binlog日志文件名以及binlog日志文件路径,并配置serverid。18.作为进一步的优化,本发明步骤s2中,通过访问information_schema中的表,获取表schemata为库信息,tables为表信息,columns为列信息,views为视图信息;19.采集全量表元数据时,在内存中记录该表结构数据。20.作为进一步的优化,本发明步骤s3中,在采集全量表元数据之前需要记录下当前的binlog文件以及当前binlog文件的位置,若开启了gtid,并记录gtid号。21.作为进一步的优化,本发明步骤s4中,与源端数据库建立数据库连接,向master注册slave,然后发送从某个增量点获取数据的请求(com_binlog_dump),接收二进制日志数据并逐个解析,直到数据解析完成。22.作为进一步的优化,本发明步骤s4中,解析binlog过程中需要记录日志文件及位置position,以用于下次增量查询或异常恢复。23.作为进一步的优化,本发明步骤s5中,在binlog中解析出来的sql语句中包括ddl变更和dwl变更,在解析ddl变更以后,需要将解析后的ddl变更对内存中记录的表元数据进行更新,在解析dwl数据时,需要依照此前记录的表元数据。24.作为进一步的优化,本发明步骤s6中,源端采集解析的ddl变更数据序列化后传递到目的端,目的端根据requestparam以及自身的数据类型,生成相应操作的sql语句,并执行所生成的语句。25.本发明具有以下优点:26.1、本发明的元数据同步方法,先其中一个时间点作为基准点,记录binlog日志文件名和偏移量作为增量基准,从该增量基准作为起始点获取binlog日志文件数据并解析其中的事件,对于binlog日志文件中解析出来的ddl变更需要解析成中间格式的数据结构,并转换成二进制数据通过mq发送到目的端,目的端对中间格式的数据结构反序列化,生成sql语句并执行;27.2、本发明通过同时同步ddl变更和dml变更使得源端和目的端的结构和数据保持一致性;28.3、本发明通过将ddl变更变换为中间数据结构,既可以用作异构数据的元数据同步,还可以在目的端精准控制允许执行的操作。附图说明29.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。30.下面结合附图对本发明进一步说明:31.图1为源端数据库的采集流程示意图;32.图2为从源端获取binlog日志并解析的流程示意图。具体实施方式33.下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互结合。34.需要理解的是,在本发明实施例的描述中,“第一”、“第二”等词汇,仅用于区分描述的目的,而不能理解为指示或暗示相对重要性,也不能理解为指示或暗示顺序。在本发明实施例中的“多个”,是指两个或两个以上。35.本发明实施例中的属于“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,单独存在b,同时存在a和b这三种情况。另外,本文中字符“/”一般表示前后关联对象是一种“或”关系。36.本实施例提供一种基于mysqlbinlog的元数据同步方法,主要过程为在源端数据库采集binlog日志文件,并进行解析后应用到目标端,具体的,包括如下步骤:37.s1、配置源端mysql数据库,开启binlog;38.步骤s1中,配置源端mysql数据库配置过程中,在开启binlog后,还包括配置binlog日志文件名以及binlog日志文件路径,并配置serverid;具体的,需要如下方式重启mysql配置文件::39.log_bin=on40.log_bin_basename=binlog日志文件路径41.log_bin_index=binlog日志文件名42.server-id=唯一标识一个客户端的整形数43.并在配置完成后,重启mysql服务;44.s2、采集全量表元数据,获取当前数据库中的库、表、字段等信息;45.通过访问information_schema中的表,获取表schemata为库信息,tables为表信息,columns为列信息,views为视图信息;可以通过执行sql简单查看,获取所有库(》showdatabases;),获取库的表(》showtables;),获取表的字段(》showcreatetabletable1;显示建表语句);46.在内存中记录此表结构数据,后续通过解析增量数据来更新;47.s3、查询并记录当前日志文件,并将日志文件内偏移量作为增量基准;48.binlog是一组文件,其中包含了有关对mysql服务器实例进行的数据修改的信息。日志由一组二进制日志文件和一个索引文件组成。索引文件记录了当前的日志文件。日志文件中包含了数据修改的事件。日志文件格式到目前有三个版本,需要根据mysql版本确定日志文件格式;49.在采集全量表元数据之前需要记录下当前的binlog文件以及当前binlog文件的位置,若开启了gtid,并记录gtid号;通过sql获取增量点的方式示例如下:[0050][0051]s4、根据增量点,获取并解析binlog日志文件;[0052]通过建立数据库连接,并向mysql发送命令再接收数据进行处理。向master注册slave(com_register_slave),然后发送从某个增量点获取数据的请求(com_binlog_dump),接收二进制日志数据并逐个解析,直到数据解析完成。解析过程中需要记录日志文件及位置position,以用于下次增量查询或异常恢复。在发送获取增量数据前获取增量基准及当前表结构并记录备用。[0053]binlog-event表示了所有的事件及每个事件的格式,以此二进制格式解析;[0054]其中的事件:write_rows_event,update_rows_event,delete_rows_event记录了数据的增删改操作的dml事件。query_event记录了ddl操作成功的sql语句。[0055]s5、将从binlog日志文件中解析出来的sql语句进行解析,并将解析后的sql语句填充到数据结构中;[0056]从binlog中解析出的sql语句如果是同一种数据库且配置完全一样,可以直接使用。否则需要进一步解析使用。sql解析需要使用语法分析及词法分析工具,如flex/bison,可以参考mysql源码中的sql_yacc.yy及sql_lex.h和sql_lex.cc。解析sql语句,并填充到数据结构中。[0057]数据结构用proto3语法描述如下:[0058][0059][0060][0061]proto3定义的数据结构可以生成c /java等语言的代码。数据结构提供了序列化和反序列化的功能[0062]s6、将所获取的增量日志传递到目的端,并在目的端执行同步数据;[0063]在解析ddl变更之后,需要将解析后的ddl操作对内存中记录的表元数据做更新。比如ddl为在某位置增加列,则需要在表示表列的数组中增加一列,并正确修改列的序号;如果ddl为重命名列,则需要修改表列中的命名;如果删除列,则需要修改该列后续列的列序列号。[0064]解析dml数据时需要依照记录此处记录的表元数据。[0065]当解析binlog日志到与增量日志采集前获取的日志位置一致时,此时内存中的表元数据应该与数据库中的表元数据一致。如果有误差可以依据策略(忽略误差或报错),使用数据库中的元数据替换内存中的元数据,以使得后续binlog日志中的dml数据能正确解析。[0066]s7、间隔一定的时间后,重复步骤s4-s6。[0067]以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本
技术领域:
:的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。