一种基于cnn-transformer的油井产油量预测方法
技术领域
1.本发明属于石油地质中的油井产油量预测技术领域,具体涉及一种基于cnn-transformer的油井产油量预测方法。
背景技术:
2.石油在工业发展中扮演着重要角色,随着工业的发展,石油需求量随之增加。石油的开采受到诸多方面的影响,开采过程中,在记录油井产量的同时还会记录与之有关的生产信息。这些信息在油井产油量预测中发挥重要作用。
3.现有的油井产油量预测方法可分为三种:统计学习方法、机器学习方法和深度学习方法。统计学习方法更多的是利用数学模型来预测油井产量,这个方法旨在通过一定的条件把相关生产信息理想化,从而对油井产油量进行预测。在油井生产环境较为复杂、影响因素较多时,无法准确预测油井产量,并且该方法不能满足在不同生产井上的通用性。近年来,机器学习方法在石油地质领域被广泛应用。有研究人员利用支持向量机方法来预油井产油量,但是在数据量较大、生产信息较多时,支持向量机方法效率较低,精确度相对较差,重要的是支持向量机方法无法利用数据间存在的关联。随着深度学习的发展,研究人员利用长短期记忆网络来对油井产油量进行预测,长短期记忆网络可以充分利用生产信息中的时间序列特征。长短期记忆网络在循环神经网络的基础上引入了输入门、遗忘门和输出门,有效避免了在长时间学习时间序列特征时存在的梯度消失和梯度爆炸问题。但是当输入信息较长时长短期记忆网络会出现重要数据信息丢失的现象。
4.近几年来,transformer模型被广泛应用在时间序列问题中,transformer模型中的编码器可以提取输入数据中的时间序列特征,自注意力机制可以提取输入信息中对预测结果影响较大的信息。
技术实现要素:
5.本发明的目的是解决油井产油量预测精度不足的问题。
6.为此,本发明提供了一种基于cnn-transformer的油井产油量预测方法,
7.包括如下步骤:
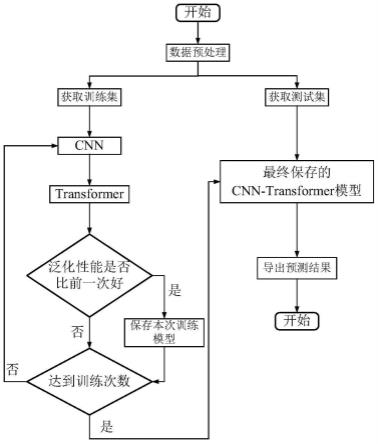
8.步骤1:输入数据的预处理,得到训练集、测试集;
9.步骤2:建立cnn-transformer模型;
10.步骤3:输入训练集进行模型训练;
11.步骤4:输入测试集进行油井产油量预测。
12.进一步的,所述步骤1:输入数据的预处理,得到训练集、测试集,包括如下步骤:
13.步骤201:查找输入数据中是否存在缺失值或者零值,并对缺失值或零值进行平均值填充;
14.步骤202:利用皮尔逊相关系数查看各属性与油井产量的相关性大小,删除相关性较小的属性;
15.步骤203:使用最大最小归一化对数据进行归一化处理,公式如(1)所示:
[0016][0017]
式中x
′
表示输入值的运算结果,x表示输入值,x
min
表示数据所在列的最小值,x
max
表示数据所在列的最大值;
[0018]
步骤204:对归一化后的数据进行数据集划分,划分成训练集和测试集。
[0019]
进一步的,所述步骤3:输入训练集进行模型训练,包括如下步骤:
[0020]
步骤301:输入训练集数据;
[0021]
步骤302:利用cnn对输入数据进行特征提取,提取数据中重要的局部特征,得到的数据;
[0022]
步骤303:将得到的数据输入至池化层,提取卷积后的显著特征;
[0023]
步骤304:将提取后的数据输入transformer模型,提取数据中的时间序列信息,并获取到对预测结果影响较大的信息;
[0024]
步骤305:数据输入回归预测层,进行油井产油量预测。
[0025]
进一步的,所述步骤4:输入测试集进行油井产油量预测的具体过程是:
[0026]
步骤401:输入测试集数据;
[0027]
步骤402:将测试集数据输入到模型中,使用均方根误差、平均绝对误差和平均绝对百分比误差作为评价指标,当测试集在模型中的拟合误差达到要求后,将需要预测油井产油量的数据输入到模型中,得到油井产油量。
[0028]
进一步的,所述步骤2:建立cnn-transformer模型主要包括:cnn卷积层、cnn池化层、transformer层、回归预测层。
[0029]
本发明提供这种基于cnn-transformer模型的油井产油量预测方法,可以将其应用到油井产油量预测任务中,该方法充分地利用了石油开采过程中记录的相关数据信息,并且对原有的油井产油量预测方法进行改进,得到了较好的预测结果。
[0030]
下面结合附图和实施例对本发明做详细说明。
附图说明
[0031]
图1为基于cnn-transformer的油井产油量预测方法流程图。
具体实施方式
[0032]
为进一步阐述本发明达成预定目的所采取的技术手段及功效,以下结合附图及实施例对本发明的具体实施方式、结构特征及其功效,详细说明如下。
[0033]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0034]
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
[0035]
本说明书(包括任何附加权利要求、摘要和附图)中公开的任一特征,除非特别叙
述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
[0036]
实施例1
[0037]
本实施例是基于cnn-transformer的油井产油量预测方法,包括如下步骤:
[0038]
步骤1:输入数据的预处理,得到训练集、测试集;
[0039]
步骤2:建立cnn-transformer模型;
[0040]
步骤3:输入训练集进行模型训练;
[0041]
步骤4:输入测试集进行油井产油量预测。
[0042]
进一步的,所述步骤1:输入数据的预处理,得到训练集、测试集,包括如下步骤:
[0043]
步骤201:查找输入数据中是否存在缺失值或者零值,并对缺失值或零值进行平均值填充;
[0044]
步骤202:利用皮尔逊相关系数查看各属性与油井产量的相关性大小,删除相关性较小的属性;
[0045]
步骤203:使用最大最小归一化对数据进行归一化处理,公式如(1)所示:
[0046][0047]
式中x
′
表示输入值的运算结果,x表示输入值,x
min
表示数据所在列的最小值,x
max
表示数据所在列的最大值;
[0048]
步骤204:对归一化后的数据进行数据集划分,划分成训练集和测试集。
[0049]
进一步的,所述步骤3:输入训练集进行模型训练,包括如下步骤:
[0050]
步骤301:输入训练集数据;
[0051]
步骤302:利用cnn对输入数据进行特征提取,提取数据中重要的局部特征,得到的数据;
[0052]
步骤303:将得到的数据输入至池化层,提取卷积后的显著特征;
[0053]
步骤304:将提取后的数据输入transformer模型,提取数据中的时间序列信息,并获取到对预测结果影响较大的信息;
[0054]
步骤305:数据输入回归预测层,进行油井产油量预测。
[0055]
进一步的,所述步骤4:输入测试集进行油井产油量预测的具体过程是:
[0056]
步骤401:输入测试集数据;
[0057]
步骤402:将测试集数据输入到模型中,使用均方根误差、平均绝对误差和平均绝对百分比误差作为评价指标,当测试集在模型中的拟合误差达到要求后,将需要预测油井产油量的数据输入到模型中,得到油井产油量。
[0058]
计算公式为:
[0059][0060]
公式中:yi为预测值,为实际值,n为样本数目。
[0061]
[0062]
公式中:yi为预测值,为实际值,n为样本数目。
[0063]
进一步的,所述步骤2:建立cnn-transformer模型主要包括:cnn卷积层、cnn池化层、transformer层、回归预测层。
[0064]
实施例2
[0065]
本实施例的实验数据来自我国东部某油田采油生产数据,具体包括油层厚度、泵深、日产水量、月产水量、累积产水量、动液面、含水、月产油量、冲程、冲次和日产油量。将日产油量作为预测值,然后利用厚度、泵深、日产水量、月产水量、累积产水量、动液面、含水、月产油量、冲程、冲次和相邻井的相同生产数据作为训练数据,最终一共有6995组训练数据,每组数据的时间序列步长为30,训练过程中的批次大小(batch_size)为50,即训练时每次取出50组数据进行训练。训练集的数据格式为[50,30,8]。实验的模型包含1个卷积层、1个池化层、1个transformer层和1个回归预测层。卷积层的隐状态为128维,transformer层中transformer块为5,模型采用dropout来避免过拟合,dropout设置为0.1,表示丢弃10%的网络节点,迭代次数为50次,每迭代一次使用adam优化器优化网络模型。
[0066]
以预测z2井日产油量为例,训练数据由待预测井的油层厚度、泵深、日产水量、月产水量、累积产水量、动液面、含水、月产油量、冲程、冲次以及相邻井的相同生产数据组成,并且选取多种模型进行实验对比,分别为xgboost模型、lstm模型、transformer模型和cnn_lstm模型,这些模型均有相同的超参数设置。本实施例采用rmse和mae作为预测结果的评价指标,rmse表示预测值与真实值偏差的平方与观测次数比值的平方根,衡量的是预测值与真实值之间的偏差,并且对数据中的异常值较为敏感;mae是真实值与预测值的绝对误差的平均值,能表示预测值与真实值之间误差的真实情况。
[0067]
应用基于cnn-transformer的油井产油量预测方法对z2井日产油量预测具体操作过程如下:
[0068]
步骤101:输入数据的预处理,得到训练集、测试集;
[0069]
步骤102:建立cnn-transformer模型;
[0070]
步骤103:输入训练集进行模型训练;
[0071]
步骤104:输入测试集进行油井产油量预测。
[0072]
进一步的,所述步骤101:输入数据的预处理,得到训练集、测试集,首先,查找输入数据中是否存在缺失值或者零值,并对缺失值或零值进行平均值填充;然后,使用皮尔逊相关系数查看各属性与油井产量的相关性,删除相关性小的属性,如月产油量、冲程和冲次;然后,使用最大最小归一化对数据进行归一化处理;将处理完的数据拆分成训练集和测试集,训练集占80%共5356条数据,测试集占20%共1339条数据。
[0073]
进一步的,所述步骤102:建立cnn-transformer网络,该网络采用层级堆叠网络结构。第一层为cnn网络层,包含一个一维卷积层和一个最大值池化层,其中一维卷积层卷积核的个数为128个,卷积核大小为128,步长为1,激活函数为relu,padding方式选用causal,最大值池化层的池化窗口大小为2,padding方式选用valid,步长为1;第二层为transformer层;第三层为回归预测层,该层的节点个数为1,整个模型将dropout设置为0.1,来避免过拟合。
[0074]
进一步的,所述步骤103:输入训练集进行模型训练,
[0075]
步骤201、输入训练序列数据,训练数据来自我国东部某油田采油生产数据,具体
包括油层厚度、泵深、日产水量、月产水量、累积产水量、动液面、含水、月产油量、冲程、冲次和日产油量。将日产油量作为预测值,然后利用厚度、泵深、日产水量、月产水量、累积产水量、动液面、含水、月产油量、冲程、冲次和相邻井的相同生产数据作为训练数据,最终一共有6995组训练数据,每组数据的时间序列步长为30,训练过程中的批次大小(batch_size)为50,即训练时每次取出50组数据进行训练,训练集的数据格式为[50,30,8]。
[0076]
步骤202、利用cnn对输入数据进行特征提取,提取数据中重要的局部特征;
[0077]
步骤203:将得到的数据输入至池化层,提取不同卷积映射属性的显著特征;达到进一步过滤信息的作用;
[0078]
步骤204、将提取后的数据输入transformer层,提取数据中的时间序列信息,并获取到对预测结果影响较大的信息;
[0079]
步骤205:数据输入回归预测层,进行油井产油量预测。
[0080]
进一步的,以上的步骤201至步骤205为一次迭代的训练流程,本实验设置的迭代次数为50次。采用adam算法来优化网络模型。
[0081]
进一步的,所述步骤104:输入测试集进行油井产油量预测的具体过程:将测试集数据输入训练好的模型中,会得到与之相对应的油井产油量预测数据,本实验采用rmse和mae作为评价指标,利用模型得到预测数据与z2井中的真实数据可以计算出该模型的rmse和mae,当模型对测试集拟合的误差达到要求后将需要预测产油量的数据输入至达到误差要求的模型中,即可得到预测的产油量。
[0082]
进一步的,不同模型对z2井的油井产油量预测效果的评价如表1所示,对表1的rmse和mae仔细观察可发现:cnn-transformer模型的rmse以及mae均明显小于其他模型的rmse以及mae,这表明cnn-transformer模型的油井产油量预测结果明显优于其他模型的预测结果。因此本实施例提出的方法可以很好地应用于油井产油量预测的任务当中。
[0083]
表1 z2号油井产油量产生的rmse与mae列表
[0084][0085]
综上所述,该基于cnn-transformer模型的油井产油量预测方法,可以将其应用到油井产油量预测任务中,该方法充分地利用了石油开采过程中记录的相关数据信息,并且对原有的油井产油量预测方法进行改进,得到了较好的预测结果。
[0086]
最后需要说明的是本实施例提供的英文缩写的指代如下:
[0087]
cnn:convolutional neural networks,卷积神经网络;
[0088]
cnn-transformer:convolutional neural networks-transformer,卷积神经网络结合transformer;
[0089]
rmse:root mean square error,均方根误差;
[0090]
mae:mean absolute error,平均绝对误差。
[0091]
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。