1.本发明涉及容器化应用管理的技术领域,具体涉及一种基于容器化应用管理系统的故障隔离方法。
背景技术:
2.随着容器化应用上云的趋势,越来越多的企业选择容器化应用管理系统(kubernetes)进行集群环境容器化部署业务应用。
3.基于kubernetes的集群容器环境特性,应用容器组(pod)调度到某个节点后,由于主机本身原因或其他原因导致应用pod没法运行成功,kubelet会不停的重启容器,但不会重启应用pod,导致应用pod没法重新调度到合适的节点上,业务pod只会在不合适的节点上不停重启。
4.当应用发生故障时,kubelet会重启容器,删除故障容器,导致应用发生故障时的“现场”(故障发生时的应用容器)没有保留,不方便回溯排查应用报错原因。
5.当kubernetes集群内主机发生故障时,会影响故障主机上运行的业务pod。只能通过人工介入驱逐,故障主机导致的应用故障恢复较慢,无法实时隔离故障主机,实时驱逐业务,以减小对业务的影响。
6.因此为了更好地利用kubernetes集群,需要突破故障隔离的机制。
技术实现要素:
7.针对现有技术中存在的上述技术问题,本发明提供一种基于容器化应用管理系统的故障隔离方法和系统,对故障容器或容器组进行隔离或终止,方便排查故障原因。
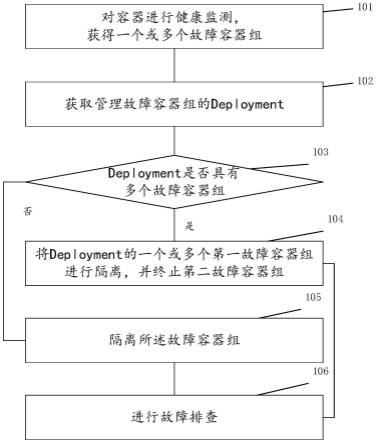
8.本发明公开了一种基于容器化应用管理系统的故障隔离方法,所述故障隔离方法包括容器隔离的方法:对容器进行健康监测,获得一个或多个故障容器组;获取管理故障容器组的deployment;判断所述deployment是否具有多个故障容器组;若是,将deployment的一个或多个第一故障容器组进行隔离,并终止第二故障容器组。
9.优选的,利用隔离的第一故障容器组进行故障排查:
10.利用排查脚本对第一故障容器组进行故障排查,并保存排查结果。
11.优选的,监测容器健康的方法包括:
12.通过探针检测故障容器;
13.或者监测出以下任一情况或它们的组合时存在故障容器:容器的cpu或者内存的使用率持续超过第一域值;容器的线程池满;容器出现错误关键字。
14.优选的,通过第一标签进行隔离的方法:
15.为故障容器组设置第一标签;
16.将具有第一标签的容器组移出deployment、移除该容器组在endpoint列表中的ip和端口、并注销所述容器组。
17.优选的,容器组的调度方法:
18.判断第三容器组是否满足第一条件:为故障容器组、且启动时间超过第二域值;
19.若满足,删除所述第三容器组,并记录所在的节点信息;
20.获得新建第四容器组的调度列表;
21.判断所述调度列表是否包括所述节点;
22.若包括所述节点,从所述调度列表中删除所述节点;
23.若不包括,按照所述调度列表进行调度;
24.判断所述调度列表是否为空;
25.若为空,清除所记录的节点信息。
26.优选的,所述故障隔离方法还包括节点隔离的方法:
27.检查所述节点的健康状态,
28.其中,所述检查的包括以下任一项目或它们的组合:kubelet健康检查、磁盘压力、内存压力、pid压力、网络、docker组件、containerd组件和calico组件;
29.若节点的健康存在故障,隔离所述节点。
30.优选的,若节点的健康存在故障,查看所述节点的全局锁是否有效;
31.若无效,隔离所述节点、注销相应的容器组,并为所述节点打上第二标签。
32.优选的,部署在节点中的节点监测模块定期将自身的心跳上报到全局锁的节点对象中;
33.节点控制器监听节点对象、并判断所述节点对象的心跳数据是否存在异常;
34.若存在异常,通过节点控制器为所述节点打上第二标签,并隔离所述节点。
35.优选的,docker组件的检测指标包括:dockerd进程存在、且不为僵尸进程,每一秒检测一次,连续失败三次,则认为节点故障;
36.calico组件的检测指标包括:kubelet进程存在、且不为僵尸进程,每一秒检测一次,连续失败三次,则认为节点故障;
37.containerd组件的检测指标包括:docker-containerd进程存在、且不为僵尸进程,confd/felix/bird进程存在、且不为僵尸进程,每一秒检测一次,连续失败三次,则认为节点故障。
38.本发明还提供一种用于实现上述故障隔离方法的系统,包括容器监测模块和容器隔离模块,所述容器监测模块用于对容器进行健康监测,获得一个或多个故障容器组;所述容器隔离模块用于获取管理故障容器组的deployment,若所述deployment是否具有多个故障容器组,将deployment的一个或多个第一故障容器组进行隔离,并终止第二故障容器组。
39.与现有技术相比,本发明的有益效果为:容器隔离的过程中,保留故障应用pod,方便排查故障原因;同一deployment下的多个故障容器组,仅隔离其中的部分故障容器组,而终止或杀死其余的故障容器组,减少隔离造成的资源消耗。
附图说明
40.图1是本发明的基于容器化应用管理系统的故障隔离方法的流程图;
41.图2是容器隔离的方法流程图;
42.图3是容器隔离的架构图;
43.图4是新建容器组的调度方法流程图;
44.图5是节点隔离的架构图;
45.图6是本发明的系统逻辑框图。
具体实施方式
46.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
47.下面结合附图对本发明做进一步的详细描述:
48.本发明的提供一种基于容器化应用管理系统的故障隔离方法,如图1所示,包括:
49.步骤s1:容器隔离。
50.通过对容器进行健康检测,及时对故障容器组进行隔离或终止,便于故障排查、防止不停重启。
51.步骤s2:容器组的调度。
52.终止容器组后,对新建容器组进行调度。
53.步骤s3:节点隔离。对节点/主机进行健康检测,及时隔离故障节点。
54.如图2所示,容器隔离的方法:
55.步骤101:对容器进行健康监测,获得一个或多个故障容器组(pod)。
56.其中,健康监测或隔离触发机制包括:探针机制和监控机制。
57.探针机制:kubelet拨测就绪探针(readiness probe)失败时,存在故障容器组。就绪探针可以感知到容器发生crash、oom、业务拨测等。但不限于就绪探针,也可以使用在线探针,但开销将加大。
58.监控机制:即基于现有的容器监控平台(prometheus)监控告警、运维监控、决策系统发现故障容器组,可以调用相关的api触发隔离。例如监测出以下任一情况或它们的组合时,存在故障容器组:容器的cpu或者内存的使用率持续很高,例如超过第一域值;容器的线程池满;容器出现错误关键字。
59.步骤102:获取管理所述故障容器组的deployment。
60.步骤103:判断所述deployment是否具有多个故障容器组。
61.若是,执行步骤104:将deployment的一个或多个第一故障容器组进行隔离,并终止第二故障容器组。
62.其中,第二故障容器组和第一故障容器组为同一deployment管理的故障容器组。deployment是用于部署和管理多个pod实例的控制器,可以实现无缝迁移、自动扩容缩容、自动灾难恢复、一键回滚等功能。
63.若否,执行步骤105:隔离所述故障容器组。
64.步骤106:利用隔离的故障容器组或第一故障容器组进行故障排查:利用排查脚本对第一故障容器组进行故障排查,并保存排查结果。
65.容器隔离的过程中,保留故障应用pod,方便排查故障原因;同一deployment下的多个故障容器组,仅隔离其中的部分故障容器组,而终止或杀死其余的故障容器组,减少隔离造成的资源消耗。
66.实施例1
67.如图3所示,通过第一标签进行隔离。
68.步骤111:分别通过容器监控平台(prometheus)和就绪控针进行容器组的健康进行监控。其中,容器组包括一个或多个容器,可以在容器中部署进程管理工具,用于管理应用子进程,防止应用程序主进程意外退出导致容器销毁,无法保留故障现场。可以在通过容器的基础镜像进行部署。
69.步骤112:就绪控针失败时,判断为故障容器组,为故障容器组添加第一标签,例如pod状态为:noready;或者容器监控平台在运维监控和决策系统中发现故障,则调用api为故障容器添加第一标签。
70.步骤113:通过故障隔离控制器(controller)执行隔离,将具有第一标签的容器组移出所在的deployment、移除该容器组在endpoint列表中的ip和端口、并在注册中心注销所述容器组。
71.具体实施例中,controller以list/watch的形式监听集群内所有(有隔离需求的)pod状态变化,一旦发现pod状态由ready转变为not ready,则执行隔离pod的动作:修改该pod的label(例如,删除标签labels:app:nginx),并在该pod的label中增加一条用来识别故障pod的特殊label(例如,status:problem)修改label后的故障pod,会被移出deploy,原来endpoint列表中会移除该pod ip,该故障pod的流量会被切断。
72.在controller进行隔离故障pod的同时,针对不使用kubenetes集群内服务发现机制的pod,如微服务,使用其他注册中心来实现服务注册与发现,但是这个pod应用进程销毁,未从注册中心注销,则该pod的流量仍在,controller会获取该pod在对应注册中心的信息,将pod信息(pod ip等)从注册中心中移除。如zookeeper注册中心的provider叶子节点path并将pod ip对应的provider叶子节点path从zookeeper注册中心删除。
73.controller执行pod隔离时,对多个属于同一deployment的故障pod,只隔离且保留其中一个或多个第一故障pod(保留个数可以通过配置传入controller),其余的第二故障pod直接终止重启。
74.步骤114:同时kubelet将重新为deployment拉起一个新的pod来维护现有的流量,重新拉起新pod的耗时与常规pod容器重启时间相近,既保留的故障现场,也不影响现有的流量。
75.步骤115:controller执行故障pod隔离时,可以使用jvm排查脚本,生成jmap文件、jstack文件等,保留在容器内,方便后续排查pod故障原因。进入隔离的故障应用pod排查原因结束之后,可以手动删除。
76.实施例2
77.如图4,步骤s2中,容器组的调度方法包括:
78.步骤201:判断第三容器组是否满足第一条件:为故障容器组、且启动时间超过第二域值。如3分钟,但不限于此。
79.在一个具体实施例中,为故障容器组建立第一标签:pod状态为:noready;启动时间可以根据容器组的创建时间(时间字段,metadata.creationtimestamp)和当前时间来计算。
80.若满足,执行步骤202:删除所述第三容器组,并记录所在的节点信息。可以通过调
用apiserver接口去删除该故障pod。可以将删除的pod的所在节点信息,写入pod对应的deployment的annotation(注解)中进行记录。
81.若不满足,持续监测第三容器组。
82.步骤203:获取新建的第四容器组的调度列表。通过kubelet为deployment新建第四容器组。重新拉起新pod的耗时与常规pod容器重启时间相近。
83.步骤204:判断所述调度列表是否包括所述节点。
84.若包括所述节点,步骤205:从所述调度列表中删除所述节点,执行步骤206或208。
85.若不包括,执行步骤206:按照所述调度列表进行调度。
86.步骤207:判断所述调度列表是否为空。
87.若为空,执行步骤208:清除所记录的节点信息,并按原始调度列表进行调度。
88.若不为空,执行步骤206。
89.可以通过部署pod-problem-controller组件来步骤201-202。通过自定义拓展调度器执行步骤203-207。
90.通过本实施例的容器组调度方法,可以有效避免由于节点/主机本身原因或其他原因导致应用pod没法在当前节点上运行成功的问题,可以及时发现长时间未运行成功的pod。
91.实施例3
92.步骤s3中,节点隔离的方法包括:
93.步骤301:检查所述节点的健康状态,其中,所述检查的包括以下任一项目或它们的组合:kubelet健康检查、磁盘压力、内存压力、pid压力、网络、docker组件、containerd组件和calico组件。
94.可以通过node-agent node-controller组件对主机进行检测,检测指标如表1所示:
[0095][0096]
步骤302:若节点的健康存在故障,隔离所述节点。
[0097]
当kubernetes集群内主机发生故障时,会影响故障主机上的运行的pod,通隔离故
障主机,实时驱逐业务,以减小对业务的影响。
[0098]
在具体实施例中,采用如图5所示的架构,在节点中部署有检测模块(node-agent)。
[0099]
如图5虚线所示,一个具体的隔离机制中,步骤302包括:
[0100]
步骤312:若节点的健康存在故障,查看所述节点的全局锁(etcd)是否有效。
[0101]
若无效,执行步骤312:隔离所述节点、注销所述节点中部署的容器组,并为所述节点打上第二标签。例如,可以通过调用kube-apiserver接口将故障节点打上noexecute污点。
[0102]
若有效,持续监测所述节点,而不执行隔离。全局锁用于节点保护,例如30-60分钟内不进行节点隔离。
[0103]
图5实线示出了另一个具体的隔离机制,步骤302包括:
[0104]
步骤321:部署在节点中的节点监测模块(node-agent)定期将自身的心跳上报到全局锁(etcd)的节点对象中。所述节点对象可以是定义的轻量级crd对象,包含node-agent所在节点的节点健康状态。
[0105]
步骤323:节点控制器(node-controller)监听所述节点对象、并判断所述节点对象的心跳数据是否存在异常,例如连接3次获取不到节点对象的变化。
[0106]
若存在异常,执行步骤324:通过节点控制器执行隔离:隔离所述节点、注销相应的容器组,并为所述节点打上第二标签。
[0107]
通过节点控制器监听心跳数据,防止在node-agent故障或节点的情况下,不能及时发现节点异常。例如节点硬件故障导致宕机、节点网卡故障、节点系统crash、节点系统hang住(网络不佳)等。
[0108]
实施例4
[0109]
如图6所示,本实施例提供一种用于实现上述故障隔离方法的系统,包括容器监测模块1和容器隔离模块2,
[0110]
容器监测模块1用于对容器进行健康监测,获得一个或多个故障容器组;
[0111]
容器隔离模块2用于获取管理故障容器组的deployment,若所述deployment是否具有多个故障容器组,将deployment的一个或多个第一故障容器组进行隔离,并终止第二故障容器组。
[0112]
本发明的系统还包括容器调度模块3、节点监测模块4和节点控制器5。
[0113]
容器调度模块3用于容器组的调度;节点监测模块4用于检测节点的健康状态和节点隔离,还可以用于上传自身的心跳;节点控制器5用于根据节点对象中的心跳数据,执行节点隔离。
[0114]
本发明通过容器隔离,完整保留故障应用pod容器现场,方便后续排查应用报错原因;通过容器组的调试,调度应用pod,避免主机因素对应用pod的影响,同时及时发现长时间未运行成功的业务pod;在节点隔离中,新增多种主机故障隔离的检测和触发机制,同时优化健康检测的时效。
[0115]
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。