1.本发明属于图像处理技术领域,更进一步涉及一种多目标检测跟踪一体化方法,可用于视频序列中多个目标的单帧检测与跨帧关联,实现自然视频场景下对多个感兴趣目标的准确检测与跟踪。
背景技术:
2.多目标检测跟踪一体化方法就是从视频序列的每一帧图像中提取图像帧的特征,利用该特征对当前图像帧中可能存在的感兴趣目标进行检测与跟踪。根据图像帧的特征,为目标检测与目标跟踪建模,利用目标检测模型识别目标所在位置与长宽,利用跟踪模型将检测模型输出的当前图像帧中的目标与上一图像帧中存在的目标进行关联匹配,以在整个视频序列中按序同时实现图像帧中多个目标的检测与跟踪。现有的多目标检测跟踪一体化方法通常分为运动模型建模方法和身份特征关联匹配方法两种。其中:
3.运动模型建模方法,着重于提取目标在相邻图像帧之间的运动特征,通过构建目标运动特征模型,预测目标在下一图像帧中的位置,并通过预测结果与检测模型结果的匹配实现目标的检测与关联。常用的方法包括:光流法,帧间差分法,深度学习建模等方法。这些方法在目标数量少且分布稀疏的情况下已经被证实能够取得良好的跟踪结果,然而因运动建模方法特征依赖单一,运动信息提取误差较大,在目标数量多、分布密集场景下难以取得良好的跟踪结果。
4.身份特征关联匹配方法,着重于提取目标的表观信息作为身份特征,通过相邻帧中目标身份特征的相似程度进行目标跟踪,常用深度学习建模方法进行特征建模。虽然身份特征关联匹配方法在目标间表观特征可区分性强的情况下取得了较良好的跟踪结果,然而因为其非常依赖目标表观特征的强可分性,在目标表观特征匮乏,相似目标多的情况下难以取得良好的跟踪结果。
5.北京邮电大学在其申请号为202110631768.9的专利申请文献中公开了一种“基于mask r-cnn和表观特征融合的多目标跟踪方法”。其首先调整图像大小,利用mask r-cnn网络搜索待识别的图像,获取图像中目标所在的候选区域及特征图;再通过在候选区域上切割特征图,提取目标特征;再利用孪生网络对比多个候选目标之间的相似度,判断目标是否属于同一目标并进行关联。该方法存在两方面的不足:一是由于该方法使用了独立的检测网络与跟踪网络进行检测与跟踪,检测使用基于锚点的mask r-cnn网络,无法在全局执行端到端优化训练,不能达到理论最优的检测与跟踪结果;二是由于将全局的目标分别输入到孪生网络进行目标之间两两对比,极大地增加了运算代价,且跟踪的实时性较差。
6.中国科学院大学在其申请号为202010015437.8的专利文献中公开了“一种基于目标场景一致性的无人机视频多目标跟踪方法”。其基于检测网络输出的结果,分别构建孪生神经网络计算目标与场景的一致置信度和目标与目标的相似度,将两个孪生神经网络的输出同时输入到构建的分支网络中,预测目标的所在位置。该方法由于存在多个孪生神经网络分支,因而导致网络的复杂性很高,网络的优化难度大且跟踪实时性低。
技术实现要素:
7.本发明的目的是针对上述现有技术存在的不足,提出了一种基于无锚孪生神经网络的多目标检测跟踪一体化方法,以降低网络的复杂性,提高孪生神经网络多目标跟踪的实时性;通过对检测与跟踪网络的联合优化,提升检测跟踪精度。
8.为实现上述目的,本发明的技术方案包括如下:
9.(1)构建训练数据集与测试数据集:
10.将至少5个光学视频序列组成训练数据集,将至少1个光学视频序列组成测试数据集,其中:
11.每个光学视频序列中至少包含50帧连续图像,每帧图像包含至少一个完整的运动目标,且每帧图像中运动目标位置相比前一帧中该目标所在位置移动幅度大于等于2个像素点,每帧图像的长宽不得小于500
×
500;
12.每种数据集的标签均包括当前帧图像每个目标所在的中心点,目标的长宽,目标类别以及目标的序号;
13.(2)构建基于无锚孪生神经网络的一体化检测与跟踪网络:
14.(2a)搭建一个包括三个下采样层和三个上采样的并行多尺度特征融合模块;
15.(2b)搭建一个包括三个卷积层和三个激活函数层的检测分支子网络;
16.(2c)选用现有的resnet50网络和siamban网络,并将siamban网络作为跟踪分支子网络;
17.(2d)将并行多尺度特征融合模块的输入端分别与现有resnet50网络的第三、第四、第五卷积层连接,将并行多尺度特征融合模块的输出端分别与跟踪分支子网络和检测分支子网络连接,构成基于无锚孪生神经网络的一体化检测与跟踪网络;
18.(2e)设置基于无锚孪生神经网络的一体化检测与跟踪网络的损失函数:loss=l e2,其中:
19.e2为已知siamban网络中所使用的损失函数;
20.l=l
heat
l
size
l
offset
为检测分支子网络的损失函数,l
heat
、l
size
、l
offset
分别为检测分支网络的目标中心热图损失函数、尺寸回归损失函数和目标中心偏移损失函数;
21.(3)利用训练数据集对基于无锚孪生神经网络的一体化检测与跟踪网络进行训练:
22.(3a)构建一个空的训练集目标轨迹模板集合,并根据训练集第一帧图像标签对其初始化;
23.(3b)将训练集目标轨迹模板集合与当前图像一起输入到基于无锚孪生神经网络的一体化检测与跟踪网络,得到检测与跟踪的结果;
24.(3c)根据总损失函数,计算网络损失值,并通过梯度下降法更新网络参数;
25.(3d)更新目标轨迹模板集合;
26.(3e)重复(3b)到(3d)直到网络损失函数收敛,得到训练好的基于无锚孪生神经网络的一体化检测与跟踪网络模型;
27.(4)对测试集的图像进行目标检测与跟踪:
28.(4a)将测试集第一帧图像输入到训练好的基于无锚孪生神经网络的一体化检测与跟踪网络,输出第一帧图像的目标检测结果;
29.(4b)构建一个空的测试集目标轨迹模板集合,根据测试集第一帧图像及(4a)的检测结果初始化测试集目标轨迹模板集合;
30.(4c)将测试集与已初始化后的测试集轨迹模板集合输入到训练好的基于无锚孪生神经网络的一体化检测与跟踪网络,输出测试集第二帧及第二帧之后的每一帧图像的检测与跟踪结果。
31.(4d)根据检测结果与跟踪结果的iou大小进行匹配,并将匹配目标的检测结果替换其跟踪结果,输出最终的检测与跟踪结果。
32.本发明与现有技术相比具有以下优点:
33.第一,由于本发明构建了无锚的一体化检测与跟踪网络,检测与跟踪分支共用resnet50提取的图像特征,能在局部进行多目标跟踪,减少了全局目标匹配的时间损耗,且使用无锚的神经网络结构,减少了特征的重复提取与计算,降低了网络的计算损耗,增强了网络的实时性。
34.第二,本发明的网络结构能进行端到端的训练,即在学习过程中不进行分模块或分阶段训练,直接优化任务的总体目标,可使网络各个分支联合优化,取得更好的检测与跟踪表现;
35.第三,由于本发明构建的基于无锚孪生神经网络的一体化检测与跟踪网络使用了并行多尺度特征融合模块提取并融合目标多个尺度的特征,这种特征能有效增强目标的特征强度,辅助网络取得更好的检测与跟踪表现。
附图说明
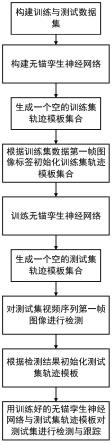
36.图1是本发明的实现流程图;
37.图2是本发明中使用的现有resnet50特征提取网络结构示意图;
38.图3是本发明中构建的并行多尺度特征融合模块结构示意图;
39.图4是本发明中构建的检测分支子网络结构示意图;
40.图5是本发明中使用的siamban跟踪子网络结构示意图;
41.图6是本发明中构建基于无锚孪生神经网络的一体化检测与跟踪网络总体结构示意图。
具体实施方式
42.结合附图对本发明的实施例和效果作进一步详细说明。
43.如图1所示,本实例的具体实现如下:
44.步骤1,构建训练数据集与测试数据集:
45.从公开网络下载现有的光学视频跟踪数据集,并将至少5个光学视频序列组成训练数据集,将至少1个光学视频序列组成测试数据集,其中:
46.每个光学视频序列中至少包含50帧连续图像,每帧图像包含至少一个完整的运动目标,且每帧图像中运动目标位置相比前一帧中该目标所在位置移动幅度大于等于2个像素点,每帧图像的长宽不得小于500
×
500;
47.每种数据集的标签均包括当前帧图像每个目标所在的中心点,目标的长宽,目标类别以及目标的序号。
48.步骤2,构建基于无锚孪生神经网络的一体化检测与跟踪网络。
49.2.1)选用现有一个resnet50网络作为基于无锚孪生神经网络的一体化检测与跟踪网络的特征提取网络:
50.如图2所示,现有的resnet50网络,包括三层卷积层、三层bn层、一层激活函数层,一层最大池化层,其结构依次为:第一卷积层,第一bn层,激活函数层,最大池化层,第二卷积层,第二bn层,第三卷积层,第三bn层,第四卷积层,第四bn层,第五卷积层,第五bn层;
51.各层参数设置及使用的计算函数如下:
52.第一至第五层卷积层的卷积核个数依次设置为64,64,128,256,512,卷积核尺寸依次设置为7,3,3,3,3;
53.第一、二、三层卷积层步长均设置为2,
54.第四、第五卷积层步长均为1,
55.第四、第五卷积层中卷积核空洞率为2,4;
56.最大池化层池化区域核的大小设置为3
×
3,步长均设置为2;
57.第一至第五bn层均采用批标准化函数,
58.激活函数层采用线性整流函数,
59.最大池化层采用区域最大值池化函数;
60.2.2)搭建一个并行多尺度特征融合模块:
61.如图3所示,该并行多尺度特征融合模块包括三个下采样层和三个上采样,其结构参数如下:
62.第一下采样层、第二下采样层、第三下采样层、第一上采样层、第二上采样层、第三上采样层的输出端与输入端按顺序依次相连,且第一下采样层的输入端与第三上采样层的输出端相连,第二下采样层的输入端与第二上采样层的输出端相连,第三下采样层的输入端与第三上采样层的输出端相连;
63.三个下采样层均由并行的三个卷积层组成,其第一、第三下采样层的卷积核尺寸均为3
×
3,卷积核数量为128,256,512;第二下采样层的卷积核尺寸为3,卷积核数量为64,128,256;
64.2.3)搭建检测分支子网络:
65.如图4所示,该检测分支子网络包括三个卷积层和三个激活函数层,其结构参数如下:
66.第一卷积层与第一激活函数层连接,第二卷积层与第二激活函数层连接,第三卷积层与第三激活函数层连接,形成并行的三条支路;
67.三层卷积层的卷积核尺寸均为3,卷积核数量分别为1,2,2;
68.三个激活函数层采样的激活函数均为线性整流函数;
69.2.4)选用现有的一个siamban网络作为基于无锚孪生神经网络的一体化检测与跟踪网络的跟踪子网络:
70.如图5所示,现有的siamban网络包括三层互相关分类层,三层互相关回归层与两层卷积层,其结构为;第一互相关分类层、第二互相关分类层、第三互相关分类层、第一卷积层依次连接;第一互相关回归层、第二互相关回归层、第三互相关回归层、第二卷积层依次连接,形成两条并行的支路;
71.该第一、第二卷积层卷积核尺寸均为1,卷积核数量为2,4;
72.2.5)将resnet50特征提取网络的第三、第四、第五卷积层的输出端分别与并行多尺度特征融合模块第一下采样层的第一、第二、第三卷积层连接,将并行多尺度的输出端分别与检测分支子网络和siamban跟踪分支网络两条支路的输入端连接,构成基于无锚孪生神经网络的一体化检测与跟踪网络,如图6所示。
73.步骤3,设置基于无锚孪生神经网络的一体化检测与跟踪网络的损失函数loss。
74.3.1)设置检测分支子网络的损失函数l:
75.l=l
heat
l
size
l
offset
76.其中,l
heat
,l
size
,l
offset
分别为检测分支网络的目标中心热图损失函数、目标尺寸回归损失函数、目标中心偏移损失函数,分别表示如下:
[0077][0078][0079][0080]
式中,n为每一批输入训练样本数量,p、size、offset分别为检测网络对目标中心置信度、目标尺寸、目标中心偏移的预测结果;p_gt、size_gt、offset_gt分别为目标中心、目标尺寸、目标中心偏移量的真实标签值;
[0081]
3.2)设置跟踪分支子网络的损失函数为已知siamban网络中所使用的损失函数e2,表示如下:
[0082][0083]
其中,n为单次训练输入样本数量,yi为样本正负例标签,pi为网络预测得分,iou为网络预测目标位置与目标真值的交并比;
[0084]
3.3)将检测分支子网络的损失函数l与跟踪分支子网络的损失函数e2相加,得到无锚孪生神经网络的一体化检测与跟踪网络的损失函数:
[0085]
loss=l e2。
[0086]
步骤4,生成空的训练集轨迹模板集合并进行初始化。
[0087]
4.1)建立一个空的训练集轨迹模板集合,用于存放每个轨迹对应的模板特征;
[0088]
4.2)选取训练集视频序列的第一帧图像作为网络的输入,提取并行多尺度特征融合模块的输出特征图;
[0089]
4.3)根据视频序列的第一帧图像中每个目标的标签,提取输出特征图中该目标所在区域的特征块;
[0090]
4.4)将所有目标特征块通过现有技术roi align转换为目标轨迹模板特征,并将每个目标轨迹模板特征存放至目标轨迹训练模板集合,完成目标轨迹训练模板集合初始化。
[0091]
步骤5,对基于无锚孪生神经网络的一体化检测与跟踪网络进行训练。
[0092]
5.1)将训练集目标轨迹模板集合与当前图像一起输入到基于无锚孪生神经网络的一体化检测与跟踪网络,得到检测与跟踪的结果;
[0093]
5.2)利用网络输出的测试与跟踪结果更新目标轨迹模板集合;
[0094]
5.3)根据总损失函数,计算网络的损失值,并通过梯度下降法更新网络参数;
[0095]
5.4)重复步骤5.1)到5.3),直到网络损失函数收敛,得到训练好的基于无锚孪生神经网络的一体化检测与跟踪网络模型。
[0096]
步骤6,生成空的测试集轨迹模板集合并进行初始化。
[0097]
6.1)建立一个空的测试集轨迹模板集合,用于存放每个轨迹对应的模板特征;
[0098]
6.2)选取测试集视频序列的第一帧图像作为训练好的基于无锚孪生神经网络的一体化检测与跟踪网络的输入,输出对第一帧图像目标检测的结果;
[0099]
6.3)根据测试集第一帧图像每个目标的检测结果,提取并行多尺度融合模块输出特征图中该目标所在区域的特征块;
[0100]
6.4)将所有目标特征块通过现有技术roi align转换为目标轨迹模板特征,并将每个目标轨迹模板特征存放至目标轨迹测试模板集合,完成目标轨迹测试模板集合初始化。
[0101]
步骤7,使用训练好的基于无锚孪生神经网络的一体化检测与跟踪网络进行多目标跟踪。
[0102]
7.1)将测试集当前帧数据和测试集轨迹模板集合同时输入到训练好的基于无锚孪生神经网络的一体化检测与跟踪网络,输出检测与跟踪结果;
[0103]
7.2)计算检测结果与跟踪结果每个目标之间的iou值,选取iou最大的检测与跟踪对,记为匹配成功的结果对;
[0104]
7.3)根据匹配结果更新测试集轨迹模板集合
[0105]
对匹配成功的结果对,将其跟踪结果中目标位置的预测值替换为检测结果中目标位置的预测值,并根据其检测结果,提取并行多尺度融合模块输出特征图中该目标所在区域的特征块,通过现有技术roi align将这些特征块转换为目标轨迹模板特征,再将轨迹模板集合中的内容替换为该目标轨迹模板特征;
[0106]
对没有匹配成功的检测,将其作为新的目标轨迹,根据新的轨迹的检测结果,提取并行多尺度融合模块输出特征图中该目标所在区域的特征块,通过现有技术roi align将这些特征块转换为目标轨迹模板特征,并将其轨迹模板特征加入轨迹模板集合中;
[0107]
7.4)输出检测与跟踪结果
[0108]
将匹配成功的结果对的检测结果和新的目标轨迹的检测结果,作为当前帧的检测结果输出;
[0109]
将匹配成功的结果对的跟踪结果和新的目标轨迹的检测结果,作为当前帧的跟踪结果输出;
[0110]
7.5)重复步骤7.1)到7.4),输出完整的检测与跟踪结果。
[0111]
下面结合仿真实验对本发明的效果做进一步的描述。
[0112]
1.仿真条件:
[0113]
本发明的仿真的硬件平台为:处理器为intel(r)core(tm)i7,主频3.6ghz,内存为64g,显卡为geforce rtx 2080。
[0114]
本发明的仿真实验的软件平台为:windows10操作系统,pycharm2020软件,python3.7和pytorch深度学习框架。
[0115]
本发明所用的仿真实验数据为公开数据集mot17,其中包括七个带有行人的室内外公共场所场景,每个场景的视频被分为两个片段,分别用于训练和测试。
[0116]
2.仿真内容及结果分析:
[0117]
本发明仿真实验是采用本发明与现有技术的三种方法分别对mot17数据集进行实验验证,实验结果如表1:
[0118]
表1本发明与三种现有技术在mot17数据集上的实验验证结果
[0119]
算法指标本发明siammotcentertrackctrackermota(%)68.165.967.866.6fps201617.56.8
[0120]
表1中的三种现有方法出处如下:
[0121]
siammot是指,shuai b等人在“siammot:siamese multi-object tracking[c]//pro-ceedings of the ieee/cvf conference on computer vision and pattern recognition.2021:12372-12382.”中提出的多目标跟踪算法,简称siammot算法。
[0122]
centertrack是指,zhou x等人在“tracking objects as points[c]//european conference on computer vision.springer,cham,2020:474-490.”中提出的多目标跟踪算法,简称centertrack算法。
[0123]
ctracker是指,peng j等人在“chained-tracker:chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking[c]//european conference on computer vision.springer,cham,2020:145-161.”中提出的多目标跟踪算法,简称ctracker算法。
[0124]
表1中mota为跟踪精度指标,fps为跟踪实时性指标,其计算公式如下:
[0125][0126]
fps=每秒钟网络完成跟踪的图像数量
[0127]
其中m
t
为第t帧中错检数量,为第t帧中漏检数量,mme
t
为第t帧中的目标id切换次数。
[0128]
从表1可以看出,在mot17数据库上,本发明的mota为68.1%,fps为20;siammot方法的mota为65.9%,fps为16;centertrack的mota为65.9%,fps为17.5;ctracker的mota为66.6%,fps为6.8。本发明无论是mota还是fps均高于其余三个现有技术,证明了本发明能在mot17数据集上取得更好的跟踪效果,这主要是因为本发明能够通过多尺度融合模块增强目标特征表征能力,在利用了孪生神经网络强大的跟踪能力同时,搭建了可端到端训练的网络结构,同步优化了网络的检测性能与跟踪性能,取得更好的检测与跟踪性能,同时,使用基于无锚的网络结构,能够极大降低网络的计算损耗,因此得到了高效率、准确的跟踪效果。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。