1.本发明涉及数据库系统查询优化的基数估计技术领域,具体地说,涉及一种平滑自回归基数估计方法。
背景技术:
2.基数估计是在真正执行查询前预先对sql查询的结果的条目数进行估计,是现代数据库系统查询优化器的基础和核心组成。基数估计为查询优化器预估查询代价,选择优秀的查询计划提供有力的依据,基数估计的准确性在相当的程度上影响了现代数据库系统的效率。尽管如此,随着大数据背景下数据之间相关性的增强,现代数据库系统在估计复杂表格数据和复杂查询时仍可能产生成千上万倍的估计误差,因此基数估计问题至今仍是数据库系统中一个重要的研究方向。
3.查询驱动的基数估计器将数据库系统工作产生的工作负载(查询)作为监督信息,学习查询条件和查询基数之间的关系模型。通过输入查询条件就可以得到基数估计的结果,是一类直接的基数估计方法。查询驱动方法的缺点是明显的,想要达到理想的估计效果需要大量的负载作为训练数据,尽管在基数估计问题上可以通过执行查询得到监督数据的标签,但是为了覆盖查询域往往在真实数据集上需要产生几十上百万的负载,这是一笔很大的开销。查询驱动方法的另一个致命缺陷是,当数据发生变化时,可能所有的训练数据都会无效。
4.数据驱动的基数估计方法,通过对真实数据的分布情况建模,从分布的角度回答基数估计问题。事实上,大多数传统基数估计方法几乎都是数据驱动的思想下进行工作,但是传统方法模拟分布是简单的、充满假设的。在数据建模时使用如直方图、草图以及采样等简单建模方式。在计算估计结果时也会受限于模型的独立性假设和均匀假设等,这在现实数据中是几乎不可能成立的。同时,在一些传统方法中,数据维度的提升会导致空间和时间开销呈现指数级增长,这无疑使基数估计变得低效且昂贵。
5.近年来,数据驱动的学习型方法受到众多研究人员的欢迎,取得了不错的效果。有一些数据驱动的学习方法(如反馈核密度估计、deepdb)削弱了传统方法做出的限制性假设,但仍会做出部分独立性或部分均匀性的假设,因此得到的联合分布是具有近似性的。深度自回归基数估计器被认为是当下最先进的基数估计器类别之一,自回归模型可以通过条件概率的计算捕获数据之间的相关性,这对处理复杂的关系表有很大的帮助,这使得估计器表现出高水平的准确度。现有先进估计器在中位误差、均值误差等反映平均估计水平的指标上的表现是令人满意的,但尾部误差仍是不理想的,即使是最先进的估计器最大误差也可能比平均误差大数十倍。对于自回归估计器,产生这些误差的原因有两点,首先,高维的表格数据相对于整个值域空间是稀疏的深度自回归模型在学习稀疏数据时可能会忽略一些小数量的点,但在查询条件筛选后这些小数量点的作用可能就会被放大。另外,因为自回归性质的特点以及回答范围查询时的采样需要依赖前一个属性列,估计误差会在估计器中发生错误传播现象。
技术实现要素:
6.本发明的内容是提供一种平滑自回归基数估计方法,其能够改进因为采样质量导致的自回归基数估计误差,提升基数估计效果。
7.根据本发明的一种平滑自回归基数估计方法,其包括以下步骤:
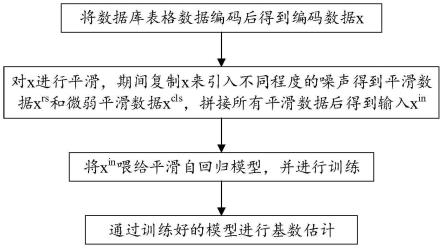
8.s1、将数据库表格数据编码后得到编码数据x;
9.s2、对x进行平滑,期间复制x来引入不同程度的噪声得到平滑数据x
rs
和微弱平滑数据x
cls
,拼接所有平滑数据后得到输入x
in
;
10.s3、将x
in
喂给平滑自回归模型,并进行训练;
11.s4、通过训练好的模型进行基数估计。
12.作为优选,编码过程如下:
13.s1.1、通过扫描所有属性列以获取每一列的属性域ai和不同值数量|ai|;
14.s1.2、离散的将ai中的元素以字典格式赋予[0,|ai|]范围的编号,将小的数据赋予小的编号,使编号的大小能反映数据的大小关系;
[0015]
s1.3、对数据进行输入编码来获得语义,采用二进制编码,二进制编码依次将需要编码的数据表示成其位置序号的二进制向量。
[0016]
作为优选,平滑操作公式为:
[0017][0018]
式中,p
data
代表了数据的原始分布,p
smoot h
是一个小方差平滑分布;将p
data
用p
smoot h
进行扰动从而得到一个基于p
data
的平滑分布p
new
;为加入过噪声的元组;
[0019]
将平滑后的分布输入模型的操作可以表示为:
[0020][0021]
inp1和inp2都是原始输入的副本,对两个副本进行不同程度的平滑操作;inp1和inp2的对应位置具有相同的位置编码;在输入时将inp1与inp2拼接为一个向量喂给模型,最终模型输出联合概率分布。
[0022]
作为优选,采用自回归方式计算联合概率时,将联合概率分布p(x)分解为一组连续的条件概率乘积,而不做任何独立性假设:
[0023]
p(x1,x2,...,xn)=p(x1)
·
p(x2|x1)
·
...p(xn|x1,x2,...,x
n-1
)
[0024]
自回归模型的每一位置上的输出代表了一个条件概率p(x1)
·
p(x2|x1),该条件概率只依赖于顺序在其前面的属性,自回归模型的每个输出的乘积即是对联合概率的一个无偏估计。
[0025]
作为优选,平滑自回归模型的训练方法为:使用模型输出p
out
的梯度进行去除由平滑分布带来的噪声,具体为:当对加入过噪声的元组的降噪过程表示为:
[0026][0027]
为正态分布,σ2为方差,表示求导;
[0028]
为了让学习到的分布p
θ
→
p
data
,在模型训练过程是要最大化以下代价函数:
[0029][0030]
表示交叉熵。
[0031]
本发明提出了一种通用的随机平滑基数估计策略,针对稀疏性问题,我们尝试使用噪声将原始分布变得平滑,从而更容易被学习,然后,通过反转噪声的损失函数,让模型学会自己拿掉这些加入的噪声。另外,因为我们的随机平滑操作可以帮助模型获得更优质的采样样本,因此我们提出了一种平滑采样策略提升采样质量减小了错误传播造成的误差。最后,因为随机平滑策略是建立在数据分布上的,因此对于估计器中的自回归模型,我们可以进行自由的替换。本发明能够改进因为采样质量导致的自回归基数估计误差,提升基数估计效果,在快速高效的同时,具有优秀的准确度。
附图说明
[0032]
图1为实施例中一种平滑自回归基数估计方法的流程图;
[0033]
图2为实施例中sam-ce的工作流程图;
[0034]
图3(a)为实施例中sam-ce学习到的数据分布情况示意图;
[0035]
图3(b)为实施例中naru学习到的数据分布情况示意图;
[0036]
图3(c)为实施例中uae学习到的数据分布情况示意图;
[0037]
图4(a)为实施例中sam-ce估计结果分布情况示意图;
[0038]
图4(b)为实施例中naru估计结果分布情况示意图;
[0039]
图4(c)为实施例中uae估计结果分布情况示意图;
[0040]
图5(a)为实施例中dmv数据集上平滑程度对sam-ce基数估计效果的影响示意图;
[0041]
图5(b)为实施例中census数据集上平滑程度对sam-ce基数估计效果的影响示意图;
[0042]
图5(c)为实施例中forest10数据集上平滑程度对sam-ce基数估计效果的影响示意图;
[0043]
图5(d)为实施例中cup98数据集上平滑程度对sam-ce基数估计效果的影响示意图;
[0044]
图6(a)为实施例中dmv数据集上渐进采样个数s对sam-ce基数估计效果的影响示意图;
[0045]
图6(b)为实施例中census数据集上渐进采样个数s对sam-ce基数估计效果的影响示意图;
[0046]
图6(c)为实施例中forest10数据集上渐进采样个数s对sam-ce基数估计效果的影响示意图;
[0047]
图6(d)为实施例中cup98数据集上渐进采样个数s对sam-ce基数估计效果的影响示意图;
[0048]
图7(a)为实施例中dmv数据集上sam-ce随着训练epoch的增加估计相同2000条查询的max-error的变化情况示意图;
[0049]
图7(b)为实施例中census数据集上sam-ce随着训练epoch的增加估计相同2000条查询的max-error的变化情况示意图;
[0050]
图7(c)为实施例中forest10数据集上sam-ce随着训练epoch的增加估计相同2000条查询的max-error的变化情况示意图;
[0051]
图7(d)为实施例中cup98数据集上sam-ce随着训练epoch的增加估计相同2000条查询的max-error的变化情况示意图。
具体实施方式
[0052]
为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。
[0053]
实施例
[0054]
如图1所示,本实施例提供了一种平滑自回归基数估计方法,其包括以下步骤:
[0055]
s1、将数据库表格数据编码后得到编码数据x;
[0056]
s2、对x进行平滑,期间复制x来引入不同程度的噪声得到平滑数据x
rs
和微弱平滑数据x
cls
,拼接所有平滑数据后得到输入x
in
;
[0057]
s3、将x
in
喂给平滑自回归模型,并进行训练;
[0058]
s4、通过训练好的模型进行基数估计。
[0059]
问题定义
[0060]
基数和选择性:假定在数据库中存在一个有n类属性的关系t的属性域表示为{a1,
…
,an}。针对t的一系列工作负载(查询)表示为对于查询qi的基数card(qi)就是求t中满足该查询条件的元组的个数。与基数定义相似的一个概念叫做选择性,选择性表示了满足查询条件的元组在整个表格中的占比。也就是说查询qi的选择性
[0061]
基数估计:当明确了查询的基数这一概念之后,关于基数估计的目标函数可以定义为:
[0062][0063]
直观的理解就是,训练一个模型来估计查询的基数,最小化其估计值与真实查询基数之间的误差。
[0064]
随机平滑自回归基数估计器
[0065]
基数估计作为基于代价的查询优化器核心组成之一,最重要的目标就是获得准确的基数估计结果。因此首要目标是设计一个比现有估计器更加准确的先进基数估计器,为了应对不同的工作场景(表格、负载)理想的估计器应该是精确并具有鲁邦性的。与此同时,理想估计器应当对估计时延、模型大小和估计精度之间做出合适的权衡,精度提升后模型大小以及时延的增加应当是微量的,换句话说就是,采用更具性价比的模型结构来获取更准确的基数估计结果。
[0066]
sam-ce是本实施例提出的一种先进的平滑深度自回归估计器,它让原本的自回归估计器对联合分布的学习变得更加容易和精确,在现有基数估计器中具有较强的竞争性。
这里将对sam-ce的技术原理和训练过程进行详细的阐述。
[0067]
图2展示了sam-ce的工作流程,将数据库表格数据编码后得到编码数据x,接下来通过平滑过程将x变得更容易学习,期间复制了x来引入不同程度的噪声得到平滑数据x
rs
和微弱平滑数据x
cls
,拼接所有平滑数据后得到自回归模型的输入x
in
喂给自回归模型(本实施例中采用了made自回归网络模型)
[0068]
编码策略
[0069]
使用深度学习方法对数据进行编码和对输出进行解码的操作是必不可少的。sam-ce模型要求编码后的表格数据可以适应神经网络输入并最终可以被自回归模型成功将输出解码为的同时,保留必要的信息来保证数据相关性不丢失。
[0070]
为了应对范围查询我们需要让模型可以判断数据之间的大小关系,因此大小关系是自回归估计器需要保留的信息。通过确定顺序编码保留大小信息。具体过程如下:通过扫描所有属性列以获取每一列的属性域ai和不同值数量|ai|。离散的将ai中的元素以字典格式赋予[0,|ai|)范围的编号,将较小的数据赋予较小的编号,这样一来编号的大小就能反映数据的大小关系。例如,ai={lebron,jordan,stephen},编码后的字典会是:{lebron
→
1,jordan
→
0,stephen
→
2}。顺序编码操作是双射,不会带来任何损失。
[0071]
进行完位置编码后需要再对数据进行输入编码来获得语义。在机器学习领域有许多常见的编码方式。最简单的策略就是one-hot编码,one-hot为ai生成|ai|
×
|ai|的编码矩阵,因此在|ai|变大时会带来很大空间开销。另一种广泛应用的编码策略是embedding编码,其需要学习一个嵌入矩阵通过梯度下降进行更新,这在一定程度上解决了|ai|较大时空间开销问题,但是学习嵌入矩阵的过程会带来额外开销。与前两种编码策略不同,在sam-ce中采用了二进制编码,二进制编码依次将需要编码的数据表示成其位置序号的二进制向量,是一种log2|ai|大小空间开销的策略。举例来说,当ai存在三个不同值{0,1,2}时,二进制编码将其表示为{(00),(01),(10)}。这是一种比embedding更加低成本且稠密的编码策略,在工作中,嵌入矩阵的h默认大小设置为了64,但在一般工作上log2|ai|<<64。
[0072]
自回归基数估计
[0073]
联合概率与基数估计:联合概率代表了多个因素同时满足时事件发生的概率。因此,将整个数据库表看作一个样本空间,针对一条查询的基数估计看作一个事件,那么事件发生的概率就是满足所有查询条件的联合概率。
[0074][0075]
自回归联合概率计算:自回归基数估计器在数据表上工作时,每一条元组(x1,x2,....,xn)∈a1×
a2×…×an
会参与到计算联合概率分布中来,如果能够存储所有元组的分布数据,那么势必会得到准确的结果,然而随着属性的增加,元组的个数会呈现指数型的增长,在最坏的情况下我们甚至需要存储与表格数据相同大小的分布记录,而现实中的表格往往会有几十万甚至几千万条元组,要记录如此多数量的分布几乎有不可接受的代价,而且如果数据发生变化,对分布的更新的开销更是无法想象的。
[0076]
采用的自回归方式计算联合概率时,将联合概率分布p(x)分解为一组连续的条件概率乘积,而不做任何独立性假设:
[0077]
p(x1,x2,...,xn)=p(x1)
·
p(x2|x1)
·
...p(xn|x1,x2,...,x
n-1
)
[0078]
自回归模型的每一位置上的输出代表了一个条件概率p(x1)
·
p(x2|x1)等,该条件概率只依赖于顺序在其前面的属性。自回归模型的每个输出的乘积即是对联合概率的一个无偏估计。
[0079]
分布上的随机平滑过程
[0080]
自回归模型依靠表格数据作为非监督信息,表格数据所构成的值域范围往往远大于表格元组数,这意味着表格数据在值域空间中的分布是稀疏且有很大的概率是锐减的,在接近数据点的位置的导数是巨大的。这样一来,数据分布就会有一个比较高的lipschitz常数。在拥有高lipschitz常数的数据分布中,一些标准化流模型会有着病理性的表现。由于自回归模型的自回归流其实是标准化流的一种,因此从表格数据上进行自回归模型的学习是可能受到阻碍的。为了克服这个困难,引入了如下的平滑操作:
[0081][0082]
公式中,p
data
代表了数据的原始分布,p
smoot h
是一个小方差平滑分布。将p
data
用p
smoot h
进行扰动从而得到一个基于p
data
的平滑分布p
new
。p
smoot h
在实验中选择了小方差的正态分布,它是平滑、对称、稳定的,这意味着对p
data
加入高斯噪声进行扰动,能够使得p
data
变得更加平滑,模型对于平滑的分布学习起来是更加轻松的。
[0083]
sam-ce中,将平滑后的分布输入模型的操作可以表示为:
[0084][0085]
inp1和inp2都是原始输入的副本,对两个副本进行了不同程度的平滑操作(与inp1相比inp2只加入非常微弱的噪声)。inp1和inp2的对应位置具有相同的位置编码,这保证了对应位置的分布信息会进入到相同的神经元进行计算。在输入时将inp1与inp2拼接为一个向量喂给模型,最终模型输出联合概率分布。
[0086]
平滑自回归模型的训练
[0087]
sam-ce中原始分布p
data
经过平滑过程,会得到一个新的平滑的分布p
new
,将p
new
作为无监督信息输入给自回归模型进行训练。经过了平滑过程的分布会更容易被学习,但噪声的加入必然会引入偏差。深度自回归基数估计的目的是为了得到原始分布的联合概率分布,这样才能取得理想的估计效果。因此还需要让自回归模型学会去除由平滑分布带来的噪声。使用模型输出p
out
的梯度进行去噪的原理。具体来说,当对加入过噪声的元组的降噪过程表示为:
[0088][0089]
这样的方法是十分方便的,只需要p
out
的相关知识就可以进行去噪。然而为了具有更加泛化的能力,sam-ce中数据分布进行了复制操作,模型的实际输入包含了两个经过不同程度平滑处理的原始分布。因此为了让学习到的分布p
θ
→
p
data
,在模型训练过程是要最大化以下代价函数:
[0090]
[0091]
表示交叉熵。
[0092]
sam-ce通过引入了噪声再进行降噪以完成较高水平的基数估计。基于这一方案,需要考虑一个新的问题:如何对模型学习平滑后分布的难易程度与反平滑过程的难易程度进行权衡。假设p
smoot h
是引入的噪声分布,考虑极限情况当p
smoot h
的方差时,相当于几乎没有对原始分布加入任何噪声,那么进行平滑过程后的分布p
new
与学习原始分布p
data
是一样困难的,但因为其无限接近与原始分布,所以很容易就可以完成反转过程。另一种情况进行平滑过程后的分布p
new
几乎与p
smoot h
相同,是一个易于学习的平滑分布,但这样一来几乎失去了p
data
的全部信息,几乎不可能恢复。
[0093]
因此,sam-ce进行基数估计时为p
smoot h
找到一个合适的方差是非常有必要的。
[0094]
应对范围查询
[0095]
sam-ce使用了渐进采样策略来应对范围查询。一般来说,在基数估计问题中,因为渐进采样需要依赖于对前一列数据的估计结果p
out
(xi|s
<i
),采样质量好坏与模型学习到每一列条件分布的质量成正比。模型对于原始分布的学习是困难的,很难保证每一个条件概率的学习都是准确的,如果前序的条件分布学习出现错误,那么对后续的采样和估计都会产生不断增大的干扰,导致错误传播。最近的工作表明了随机平滑处理可以增强模型在采样中的抗干扰能力。为此改进了渐进采样策略,提出了一种平滑渐进采样算法。
[0096]
algorithm1平滑渐进采样(sps)
[0097]
input:平滑分布的方差:σ2;采样个数:s;
[0098]
查询域:r;数据列数:n
[0099]
output:对查询q的选择性的估计值:
[0100]
[0101][0102]
在算法中展示了平滑渐进采样的过程,该算法的核心是对原始分布的平滑过程,因为在训练过程后,模型已经具备了分辨这些平滑噪音了能力。另外,在实验中发现在预测过程中,即便引入了和训练时不同程度的平滑操作,模型仍然可以取得比现有先进估计器更准确的估计结果(除非选择了一个非常大的平滑程度)。发生这样现象的主要原因是在平滑策略的帮助下,sam-ce学习到了一个更准确的分布,基于准确分布的采样质量肯定是更好的。
[0103]
实验设置
[0104]
数据集
[0105]
我们使用了以下四个具有不同特点的真实数据集进行实验:
[0106]
dmv此数据具有较为倾斜的数据和较为复杂的关系,它包含了纽约市的车辆注册信息。
[0107]
census此数据集记录了收入信息,属性之间相对独立,具有较小的数据倾斜程度,相对于其他数据集具有较小的值域和条目数,可以很好的验证模型在小数据集上的表现。
[0108]
forest10此数据集被广泛应用于测试基数估计方法,数据集只包含了整数类型的属性,具有较多的不同值,可以用来验证组合数目较为复杂情况下模型的表现。
[0109]
cup98此数据集被用于kdd cup98挑战中。相较其他实验数据集cup98具有更多的列和更大的值域,但数据之间相对独立,我们选择了其中100个维度,以此来展示模型在列数较多的表中的效果。
[0110]
表1数据集
[0111]
datasetssize(mb)rowscols/catdomaindma972.811.6m11/1010
15
census5.0749k14/910
16
forest1021.8581k10/010
27
cup9811198k100/5010
220
[0112]
在实验中,我们借鉴了以前的工作,对数据集进行了剪裁。表1展示了实验中使用数据集的属性,包括了数据集大小、元组数、属性列数/属性中字典类型的列数、属性域大小。
[0113]
估计器
[0114]
我们将sam-ce与以下基数估计方法进行了比较:
[0115]
1)mysql,mysql被用来代表真实数据库系统的表现,我们使用mysql 8.0.27社区服务mysql其中采用了最简单的1-d histogram作为基数估计器,为了使其达到比较好的性
能我们将直方图桶设置为1024,postgres、sql server等常见数据库系统使用了同样的估计器,因此不再做多余对比。
[0116]
2)sample:采样被广泛应用于基数估计问题,通过从数据集中均匀的采样p%的数据来模拟数据集真实分布,将对样本的估计结果作为整个数据集的估计结果。
[0117]
3)maxdiff:我们选择maxdiff作为多维直方图估计方法的代表,maxdiff在此类方法中具有最优的表现。
[0118]
4)bayesnet:使用基于chow-tree的贝叶斯网络,它已经被调整到适合基数估计任务的形式。
[0119]
5)kde-fb:此方法使用高斯核密度估计器来估计数据分布,核密度估计的边界宽度采用了scott
′
s规则来计算,可以将查询反馈结果作为监督信息进行进一步的学习,在其上面进行修改使其支持》10列的估计,从而满足forest10数据集的实验需求。
[0120]
6)lw-nn:此方法是查询驱动的经典学习方法之一,与lw-xgb出自同一项工作,但采用了不同的网络结构,精确度实验中我们仅展示了lw-nn的估计结果,因为它比lw-xgb更加准确。实验中,我们采用100k条查询作为模型训练的监督数据。
[0121]
7)mscn:mscn是查询驱动的基数估计算法领跑者之一,是一种多集卷积神经网络的深度网络学习方法,我们使用了对于mscn的部署,并使其应用于我们的实验数据集。我们尝试从数据集中随机生成50k、100k、200k条查询作为查询驱动监督信息,最终选择100k作为训练数据进行展示,根据对比效果我们认为此量级的训练数据足够代表mscn模型的表现。同时,因为我们只在单表估计任务上与mscn进行对比,因此我们将连接模块去掉以保证实验的公平性。
[0122]
8)deepdb:其基础网络为sum product networks(spn),是一种基于树形的非神经网络结构。我们使用了开源的代码,并使用验证过的1m作为采样数量大小。deepdb因为其树形结构,很自然的符合逻辑上将各列的估计结果进行乘加来得到联合估计结果,此类工作与神经网络方法进行对比或许是当下最主要的关注方向。
[0123]
9)naru:naru是神经网络方法的代表之作,他首次将数据驱动的深度非监督学习方式用于基数估计问题的解决,并在准确度方面至今仍能表现出sota的水平。
[0124]
10)uae:uae使用gumbel-softmax trick首次将监督信息和非监督信息用于同一个模型训练中,我们将其归于混合模型类别,我们使用单表代码进行对比实验,uae模型由uae-d和uae-q两部分组成可以单独进行实验,但因为uae的效果最好,我们只与uae进行了对比。
[0125]
参数设置
[0126]
衡量指标:给定一个查询q,我们令选择性估计结果为一种被广泛应用的度量估计效果好坏的指标是q-error。q-error反映了估计值与真实值的正向倍数(≥1),当估计值等于真实值时q-error等于1。下面展示了q-error的计算公式。
[0127][0128]
实验环境:我们的实验环境是teslav100(16g显存)gpu以及10核心xeonsilver4210r@2.4ghzcpu。
[0129]
实验参数:我们在dmv、census、forest10、cup98数据集上分别使用了256*5、128*5、256*5、128*5的made网络架构进行了准确度实验。分别将平滑程度noise参数设置为了0.1、0.1、0.1、0。
[0130]
准确度研究
[0131]
对于所有实验,我们使用了q-error作为准确度指标。我们随机生成了2k条查询作为工作负载。准确度实验的结果表明sam-ce在在准确度方面不论在中位值、平均值还、尾部值或者最大值上均与之前的大多数估计器有了显著的提升。
[0132]
传统方法普遍产生了巨大误差并表现出较差的稳定性。以真实数据库系统mysql为基准,传统基数估计方法普遍会产生大于100x最大误差。maxdiff表现出优于mysql的效果,但在数据相关性强的数据集上(dmv、forest10)尾部误差表现糟糕,尤其在forest10数据集上表现最差这主要因为forest10数据集有更多的不同值,这不利于直方图的划分。另一种基于采样的传统方法,随机采样有很强的不稳定性,样本优秀时(dmv、cup98)可能会有接近先进估计器的效果,样本糟糕时(forest10)甚至会比基准更差。
[0133]
监督学习查询驱动方法尾部误差较大。lw-nn的过程是直观的,直接建立了查询和基数之间的网络估计模型。在forest10、dmv这样复杂的数据集上,lw-nn表现较差,主要因为强相关性的数据集上随机生成的查询与测试查询很难保证相关性。mscn是先进的查询驱动估计器,整体上比lw-nn更准确,但仍可能产生100x的尾部误差,这是因为当mscn采样得来的监督数据没有命中查询的依赖项。因此,不难看出,查询驱动的监督型基数估计方法需要依赖大量的训练数据来保证整体估计的鲁棒性。另外,即使是少量的数据更新,都很大可能导致大量训练样本的标签失效。
[0134]
sum product networks(spn)不利于估计器准确度的发挥。deepdb和naru是典型的数据驱动学习估计器,相比于早先提出的基数估计方法均有很大的准确度提升。不同的是deepdb采用的spn网络在底层使用的仍然是直方图等结构,因此,其估计效果多少会有与传统方法近似的限制,在forest10上表现最差的原因也是因为不同值数量多直方图效果差。
[0135]
自回归基数估计器受限于数据稀疏性。整体上看自回归基数估计器(naru,uae,sam-ce)有着最准确的估计结果,可以达到single-digit误差,平均误差保持在2x以内。但不难看到最大误差与平均误差仍有着数倍的差距。对比不同的数据集我们可以看到,在cup98上表现比其他数据集更差,主要是因为cup98在10
220
的值域空间内仅有不到100k条数据,这是极度稀疏的,所以尽管cup98数据相对独立是有利于估计的但仍表现出最差的效果。
[0136]
对数据加入“噪声”有助于基数估计任务。uae使用gumbel-max策略利用监督和非监督信息共同训练一个模型,如果以非监督信息为主体,那么监督信息就帮助模型补全了难以学习的分布信息,我们可以将监督信息看作另类的“噪声”。与naru相比uae之所以有着更高的准确度受益于这些“噪声”。而我们的估计器sam-ce有着最准确的准确度,在全部数据集上sam-ce都保持了接近于1.10x以内的误差,甚至在经典的dmv上能够将最大误差降低至平均误差的水平附近。这更加证明了引入“噪声”对基数估计任务是有帮助的。
[0137]
学到的分布
[0138]
图3(a)、图3(b)和图3(c)向我们展示了sam-ce与实验中最准确的的估计器(naru、
uae)分别学习到的数据分布情况,我们在dmv数据集的hillshade_3pm属性上进行了实验,虚线表示真实的数据分布,实线代表了估计器学习到的数据分布。
[0139]
我们可以看到naru学习到的数据分布与真实分布的基本趋势已比较拟合,这也是为什么他有着较高准确度的原因。但仔细观察,我们不难发现,naru学到的分布于真实分布在数量峰值开始下降时(150-175附近)有着明显的偏移或偏差。这就可能导致针对这部分区域的负载可能会有较差的估计效果。
[0140]
uae学到的数据分布直观上看与原始分布有明显的不一致,可能由于gumbel-softmax加入的不合适的噪声,使得本应容易学习的区域(峰值区域125-150)反而产生了较大的误差,在数据波动时也可能因为坏噪声的加入使波动过大。另一方面,我们可以观察到在数据量低的区域uae与naru相比有着更好的拟合度,这是因为uae通过监督和非监督信息的结合能够更好的“看到”数据分布中的不明显区域。
[0141]
直观的看出,使用随机平滑的sam-ce学到了最好的分布情况,无论是在峰值还是边缘区域只产生了很小的偏移。这主要得益于随机平滑机制通过降噪机制在保存了容易习得的特征的前提下,对不明显区域的学习也进行了强化。
[0142]
确定性研究
[0143]
渐进采样被自回归方法用来支持范围查询,但其采样过程引入了更多的随机性,从而使得估计结果变得不稳定,这种不稳定性主要表现为同一个训练好的模型在对同一条查询进行多次估计时会得到不同的估计值。现有先进基数估计器中只有自回归类别的估计器会产生不确定性,因此,我们设计的确定性实验只在使用了渐进采样的估计器(naru,uae)上进行比较。
[0144]
我们在forest数据集上选择一条查询结果为36的工作负载用三个估计器各自估计2000次,图4(a)图4(b)和图4(c)展示了实验结果,可以看到自回归估计器每一次估计,结果是不同的,这反应了自回归方法的不确定性。
[0145]
为了衡量不确定性,我们使用了多次估计产生的q-error的方差和标准差,我们认为这能够反映出估计效果的确定性。我们在naru、uae、sam-ce上使用forest10数据集随机产生的2000条相同查询,并各自估计500次,均值误差计算了2000条查询500次估计的平均误差。表2展示了我们的实验结果,可以看到自回归方法中准确度和确定性是一个权衡问题,当模型准确性提升时,稳定性会有一定程度的下降。在三种方法中我们的sam-ce似乎做出了更好的权衡策略,它在只牺牲了一点确定性的情况下获得了较为明显的估计质量提升。
[0146]
表2确定性表现
[0147]
estimatorvars.dmean-errornaru0.0170.0061.48uae0.0220.0411.46sam-ce0.0220.0171.28
[0148]
超参数研究
[0149]
平滑程度对sam-ce基数估计效果的影响。
[0150]
我们使用平滑分布的方差σ2来反映平滑程度,σ2越大证明我们对原始分布加入的噪声越大,处理后的分布就会越平滑。我们为每组超参数随机生成了10k条相同的查询作为
工作负载。鉴于大部分参数的平均误差和中位误差仅在0.001单位上有所区别,我们选择最大误差为指标绘制曲线图主要是因为我们的估计器有着较高的准确度,有些数据集上对中位误差和均值误差的影响只在千分位或万分位上反映,这在图上的表现是不明显的。图5(a)、图5(b)、图5(c)和图5(d)展示了我们的实验结果,可以看到平滑程度对基数估计效果的影响基本呈现先提升后降低的影响。可以看到当方差接近于0时,因为原始分布学习起来的困难性,导致估计器有较大的误差,随着我们平滑程度的增加,我们将原始分布变得更容易学习,同时,因为此时加入的噪声是适度的,模型能够较为容易的掌握反转平滑的方法。从方差》0.8开始,随着我们加入的噪声过大,模型的降噪能力开始衰退,此时估计效果开始快速降低。
[0151]
通过实验,我们证明了使用随机平滑方法可以很好的帮助基数估计器提升估计效果,但选择合适的平滑程度是需要权衡的重要问题。同时根据多次实验后的经验,我们不建议选择较大程度的平滑操作,因为这样做可能取得的效果甚至不如不引入任何噪声。
[0152]
渐进采样个数s对sam-ce基数估计效果的影响
[0153]
为了探究sps中渐进采样的个数s对估计效果产生的影响,我们将采样个数依次设置为{50,100,200,400,800}。在实验过程中我们发现,在census、forest数据集上最大误差并没有随着s的变化而变化,在dmv、cup98的多个s值下也存在相同的最大误差。因此,我们在图6(a)、图6(b)、图6(c)和图6(d)中展示的是平均误差的变化情况,尽管多数变化发生在千分位上。我们可以看到,随着s的增加,在全部实验数据集上sam-ce的估计效果会逐渐提升但提升效果会逐渐减小,因为sps进行了不放回的采样策略,因此采样数量的提升并不能保证采样质量一定会上升,这一点在cup98数据集上反映的较为明显。
[0154]
时间开销研究
[0155]
这里主要探讨了sam-ce的训练时间以及估计速度,我们分别进行阐述:
[0156]
训练时间
[0157]
sam-ce在当batchsize设置为1024时,dmv、census、forest10和cup98上训练一个epoch分别需要236s,2s,13.6s,5.9s。图7(a)、图7(b)、图7(c)和图7(d)展示了sam-ce随着训练epoch的增加估计相同2000条查询的max-error的变化情况。我们可以看到sam-ce能在几个回合内就收敛到高精度的估计水平。在dmv数据集上甚至只使用了2个epooch就将最大误差减小至2,这比sota还要精确。在forest10数据集上进行实验时因为小节5.4中提到的不确定性因素最大误差会有较大的波动情况,但仍然能在10个epoch内将最大误差稳定在个位数水平。这意味着sam-ce只需要通过几分钟甚至几十秒的训练就能达到先进估计器的准确度。当数据发生改变时,sam-ce也可以在短时间内训练得到一个新的准确的估计器。
[0158]
估计时延
[0159]
sam-ce的估计时延基本维持在个位数毫秒,虽然还无法与真实数据库系统代表mysql还存在较大差距,但在学习型基数估计器中除了mscn之外,sam-ce在时延上还是能取得与大部分优质方法相近的水平。在相同时延下我们能够实现更准确的估计,这也能够反映我们方法的卓越性。
[0160]
我们提出了一种通用的平滑自回归基数估计方法可以改善模型对数据库表联合概率分布的学习质量。实验表明,sam-ce在快速高效的同时,将准确度提升至最先进的结果。
[0161]
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。