1.本发明涉及多媒体和大数据分析技术领域,尤其涉及一种基于内容与兴趣学习的短视频推荐方法及装置。
背景技术:
2.随着短视频逐渐成为了人们新型的信息获取方式,短视频推荐在多媒体计算研究领域受到广泛关注。合理高效地给用户推荐喜爱的短视频是推荐系统的关键。然而,在面对大量的短视频数据时,如何更好地从候选短视频序列中选择出用户可能喜欢的短视频,依然是困扰很多人的难题。
3.如今,深度学习在各个领域已经取得突飞猛进的发展,其也被广泛应用到短视频推荐领域当中。利用深度学习的优势在于它能够自动拟合用户与短视频之间的关系,以达到视频推荐的目的。
技术实现要素:
4.本发明提供了一种基于内容与兴趣学习的短视频推荐方法及装置,本发明利用短视频的多模态信息来获取短视频内容信息的同时引导短视频特征学习,利用用户历史行为信息来获取用户兴趣特征的同时学习用户特征,融合学习的特征实现短视频推荐,详见下文描述:
5.一种基于内容与兴趣学习的短视频推荐方法,所述方法包括:
6.构建用户行为序列,从用户行为序列中发掘用户兴趣特征;
7.将短视频的基本信息通过嵌入层将高维独热编码特征映射为低维特征向量,用于发掘短视频特征;
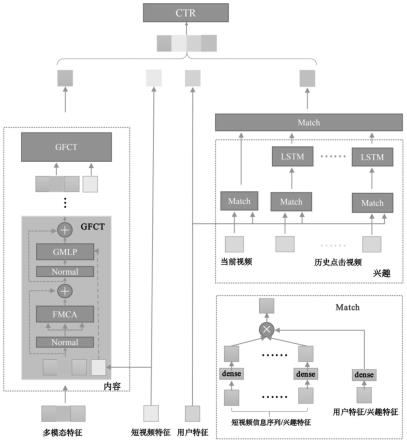
8.关注特定模态的跨模态多头注意力网络增强图像模态的特征,并引导短视频特征的学习;
9.通过引导用户特征学习的时序兴趣提取网络引导用户兴趣特征学习;
10.通过上述学习的短视频特征和用户兴趣特征经过点击率预测网络预测用户点击短视频的概率,基于预测的概率对短视频进行推荐。
11.其中,所述跨模态多头注意力网络为:
12.用于学习模态内的自注意力特征和学习模态间的跨模态注意力特征;在非线性变换层采用输入的短视频特征引导短视频特征的学习;
13.将多模态特征作为输入,xm是任意多种模态,dm是模态m的特征维度,m∈{v,a,t}分别代表短视频的图像特征、声音特征和文本特征;
14.将每个模态都分成n块对这些模态块做线性变换,映射到相同的维度;
15.在变换后,对相应的特征做了位置编码,以保留各个模态内的空间位置信息,最终
得到gfct的输入
[0016][0017]
其中,模态m的位置编码,是模态m第i块特征向量,是vit中的类别标记向量,c为gfct输入的特征维度,fc代表全连接层。
[0018]
其中,所述跨模态多头注意力网络包括:关注特定模态的多头自注意力模块,所述多头自注意力模块从自身角度学习每个模态内的特征块之间的联系:
[0019][0020]
其中,l=1,2,
…
,l表示fct模块第l层,l表示一种l层fct模块,第一层的输入为的输入为表示第l层输出的模态m内特征表示,msa表示多头自注意力机制;
[0021][0022][0023]
其中,分别表示第l层视觉模态v与文本模态t,声音模态a的跨模态交互特征,c代表特征的维度,n代表特征长度;
[0024]
这两种交互特征用于对图像特征的增强,以增加视觉信息的表达;
[0025][0026]
其中,表示第l层增强视觉特征;
[0027][0028]
其中,代表经过fmca的声音特征,代表经过fmca的文本特征。
[0029]
其中,所述方法还包括:提出一引导特征学习的gmlp,gmlp输入是经过fmca模块的三种模态上一层的短视频内容特征
[0030][0031]
其中,gfct(
·
)代表能够引导短视频特征学习同时关注特定模态的跨模态多头注意力网络,代表gfct的第l层模态m的输出特征,代表第l层内容特征,代表第l层短视频内容特征,代表第l层文本特征,代表第l层声音特征,代表增强后的视频特征。
[0032]
所述:
[0033][0034][0035]
其中,wi代表学习参数;b代表偏置。
[0036]
所述引导用户特征学习的时序兴趣提取网络为:
[0037]s
=gtin(s,e
video
,eu)
[0038]
其中,s={s1,
…st
,
…
,s
t
}代表用户行为序列特征,gtin(
·
)代表引导用户特征学
习的时序兴趣提取网络,s
t
代表t时刻用户行为特征,e
video
表示当前视频embedding特征,eu表示用户的embedding特征,s
为用户对当前视频的兴趣特征。
[0039]
提取每条历史视频的兴趣特征s
t
,和当前点击视频的兴趣特征s
τ
:
[0040]st
=match(e
video,t
,eu)
[0041]sτ
=match(e
video
,eu)
[0042]
其中,e
video,t
表示历史点击过的t时刻的视频embedding特征,s
τ
表示用户与当前视频构建的兴趣特征,match为注意力匹配机制:
[0043][0044][0045]
其中,similary(γk,β)为第k个激活权重,γk代表第k个特征,wk代表可学习参数,β可为兴趣特征也可为用户id特征;match(γ,β)为最终匹配的特征,利用lstm提取用户是高层次的时间兴趣特征:
[0046]
[h1,
…
,h
t
,
…
,h
t
]=lstm([s1,s2,
…
,s
t
])
[0047]
其中,h
t
代表t时刻对应构建的历史兴趣,s
t
代表第t个用户行为特征,利用match网络对历史兴趣对建模,获得用户对当前视频最终的兴趣特征。
[0048]
一种基于内容与兴趣学习的短视频推荐装置,所述装置包括:处理器和存储器,所述存储器中存储有程序指令,所述处理器调用存储器中存储的程序指令以使装置执行第一方面中的任一项所述的方法步骤。
[0049]
本发明提供的技术方案的有益效果是:
[0050]
1、本发明利用一种能够引导短视频特征学习,同时关注特定模态的跨模态多头注意力网络实现了短视频多模态内容特征的挖掘利用,同时对短视频特征学习进行引导;
[0051]
2、本发明利用时序兴趣提取网络实现了用户兴趣的建模,同时对用户特征学习进行引导。
附图说明
[0052]
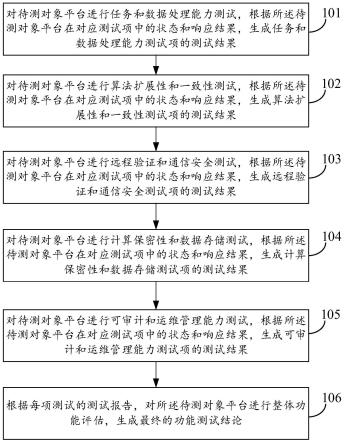
图1为一种基于内容与兴趣学习的短视频推荐方法的流程图。
具体实施方式
[0053]
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
[0054]
实施例1
[0055]
一种基于内容与兴趣学习的短视频推荐方法,该方法包括以下步骤:
[0056]
步骤101:构建出用户行为序列,从用户行为序列中发掘用户兴趣特征;
[0057]
步骤102:将短视频的基本信息通过embedding layer(嵌入层)将高维one-hot(独热编码)特征映射为低维特征向量,用于发掘短视频特征;
[0058]
步骤103:利用一种能够引导短视频特征学习同时关注特定模态的跨模态多头注
意力网络增强图像模态的特征,并且引导短视频特征的学习;
[0059]
步骤104:利用引导用户特征学习的时序兴趣提取网络来引导用户兴趣特征学习;
[0060]
步骤105:利用上述学习的短视频特征和用户兴趣特征经过点击率预测网络预测用户点击短视频的概率,基于预测的概率对短视频进行推荐。
[0061]
在上述步骤101中,利用已有数据集构建出一个由用户历史点击的短视频构成的用户行为序列,其中每条点击过的视频包含:视频作者,视频时长等信息。利用历史点击视频序列来发掘用户点击兴趣;利用短视频的多模态信息(文本,图片,音乐等)提取短视频内容特征。
[0062]
在上述步骤102中,使用embedding layer将(作者id,短视频时长等)高维向量投影到低维特征空间中。
[0063][0064]
其中,vn代表第n个字段的嵌入矩阵,代表第n个字段的嵌入向量。是输入的短视频的基本信息,vector代表向量,scalar代表常量。
[0065]
同时,将用户id和短视频id映射到低维特征空间:
[0066]eu
=vuu
[0067]ei
=vii
[0068]
其中,u代表用户id、i代表短视频id,vu和vi分别是用户id和视频id的映射字典矩阵,eu和ei分别代表用户和短视频的低维特征表示。
[0069]
构建的用户行为特征s={s1,
…st
,
…
,s
t
},t时刻用户行为特征s
t
包含所有短视频信息特征,即信息特征,即代表用户第j个短视频信息特征。
[0070]
在上述步骤103中,利用短视频的文本,图像,声音等多模态信息来获得短视频内容增强特征,同时引导短视频特征学习。
[0071][0072]
其中,gfct(
·
)代表能够引导短视频特征学习同时关注特定模态的跨模态多头注意力网络,代表gfct的第l层模态m的输出特征,代表第l层内容特征,代表第l层短视频内容特征,代表第l层文本特征,代表第l层声音特征,代表增强后的视频特征。
[0073]
在上述步骤104中,利用用户历史点击视频信息特征(例如:视频作者id、作品城市id、音乐id等)挖掘用户的兴趣特征,同时引导用户特征的学习。
[0074]s
=gtin(s,e
video
,eu)
[0075]
其中,s={s1,
…st
,
…
,s
t
}代表用户行为序列特征,gtin(
·
)代表能够引导用户特征学习的时序兴趣提取网络,s
t
代表t时刻用户行为特征,e
video
表示当前视频embedding特征,eu表示用户的embedding特征,s
为用户对当前视频的兴趣特征。
[0076]
在上述步骤105中,融合学习到的短视频内容特征用户兴趣特征d,用户特征eu和视频特征ei预测出点击该条短视频的概率。
[0077][0078]
其中,为最终的输出的点击率概率,sigmoid(
·
)是激活函数,mlp代表多层感知机,concat代表级联操作。
[0079]
实施例2
[0080]
下面结合具体的计算公式对实施例1中的方案进行进一步地介绍,详见下文描述:
[0081]
步骤201:利用已有数据集构建出一个由用户历史点击的短视频构成的用户行为序列用于挖掘用户兴趣特征;
[0082]
其中,每条点击过的视频包含视频作者,视频时长等信息。利用历史点击视频序列特征s={s1,
…st
,
…
,s
t
}来发掘用户点击兴趣s
同时引导短视频学习;利用短视频的多模态信息xm提取短视频内容特征同时引导用户特征学习。其中m∈{v,a,t},分别代表文本特征,图片特征,音乐特征。
[0083]
步骤202:使用embedding layer将(作者id,短视频时长等)高维向量投影到低维特征空间中;
[0084][0085]
其中,vn代表第n个字段的嵌入矩阵,代表第n个字段的嵌入向量。是输入的短视频的基本信息。这样的话,经过嵌入层后短视频信息特征其中j代表短视频信息特征包含j特征字段。
[0086]
同时,将用户id和短视频id映射到低维特征空间:
[0087]eu
=vuu
[0088]ei
=vii
[0089]
其中,u代表用户id和i代表短视频id,vu和vi分别是用户id和视频id的映射字典矩阵,eu和ei分别代表用户和短视频的低维特征表示。
[0090]
构建的用户行为特征s={s1,
…st
,
…
,s
t
},t时刻用户行为特征s
t
包含所有短视频信息特征,即
[0091]
步骤203:利用一种能够引导短视频特征学习同时关注特定模态的跨模态多头注意力网络(gfct)来增强图像模态的特征,并且引导短视频特征的学习;
[0092]
在gfct中,这个模块不仅能同时学习模态内的自注意力特征,还能学习模态间的跨模态注意力特征,来强化某一特定模态的学习。同时,在gfct的非线性变换层可以输入的短视频特征以此来引导短视频特征的学习。将多模态特征作为输入,xm可以是任意多种模态,dm是模态m的特征维度。在这里m∈{v,a,t}分别代表短视频的图像特征、声音特征和文本特征。将每个模态都分成n块然后对这些模态块做线性变换,将它们映射到相同的维度。
[0093]
在变换后,对相应的特征做了位置编码,以保留各个模态内的空间位置信息,最终得到gfct的输入
[0094][0095]
其中,模态m的位置编码,是模态m第i块特征向量,是vit中的类别标记向量,c为gfct输入的特征维度,fc代表全连接层。
[0096]
类似于transformer,gfct同样包含三种主要数据处理模块:关注特定模态多头自注意力模块(focus specific modality cross-modality multi-head attention,fmca),引导特征学习的多层感知机模块(guide multi-layer perceptron,gmlp),和层归一化模
块(layer normalization,ln)。
[0097]
在fmca中,首先使用多头自注意力模块(mca)学习从自身角度学习每个模态内的特征块(embedding words)之间的联系:
[0098][0099]
其中,l=1,2,
…
,l表示fct模块第l层,l表示一种l层fct模块,第一层的输入为的输入为表示第l层输出的模态m内特征表示,msa表示多头自注意力机制。这部分变换可以看作是模态自身潜在信息的提取过程。
[0100]
同时,从模态间的内在联系出发,使用跨模态的多头注意力机制(mca)来探索各个模态之间的联系,来进一步提出模态潜在高级语义特征。
[0101][0102][0103]
其中,分别表示第l层视觉模态v与文本模态t,声音模态a的跨模态交互特征,c代表特征的维度,n代表特征长度。
[0104]
这两种交互特征用于对图像特征的增强,以增加视觉信息的表达。
[0105][0106]
其中,表示第l层增强视觉特征。总的来说,fmca输入为多模态特征,利用msa和mca建立模态之间的联系,以此增强视觉模态的模块,公式如下:
[0107][0108]
其中,代表经过fmca的声音特征,代表经过fmca的文本特征。
[0109]
同时为了引导短视频ei学习到更高级的嵌入特征,提出了一种能够引导特征学习的mlp(guide mlp,gmlp)。使用gmlp替换transformer中的mlp,以达到引导学习高级特征的目的。
[0110][0111]
其中,gmlp输入是经过fmca模块的三种模态上一层的短视频内容特征当在第一层时通过这种方式利用短视频内容特征来引导ei特征的学习。经过gmlp的变换后输出为第l层增强后模态特征和多模态内容引导学习后的短视特征
[0112][0113][0114]
其中,wi代表学习参数;b代表偏置。
[0115]
那么,基于内容引导关注特定模态的跨模态多头多注意力机制的transformer可以表示为:
[0116][0117]
在gfct中,提出的fmca模块可以更加关注图像模态的特征,利用模态之间的内在联系来增强某一模态特征(图像模态特征)的表达。同时gmlp模块能利用增强的模态特征引
导短视频特征学习。
[0118]
步骤204:利用用户历史点击视频信息特征(如视频作者id、作品城市id、音乐id等)挖掘用户的兴趣特征,同时引导用户特征的学习。在这个模块中,使用了一种时序兴趣提取网络(gtin):
[0119]s
=gtin(s,e
video
,eu)
[0120]
其中,s={s1,
…st
,
…
,s
t
}用户行为序列特征,s
t
代表t时刻用户行为特征,共t个用户行为特征,e
video
代表短视频id特征,eu代表用户id特征。
[0121]
具体地,首先提取每条历史视频的兴趣特征s
t
,和当前点击视频的兴趣特征s
τ
:
[0122]st
=match(e
video,t
,eu)
[0123]sτ
=match(e
video
,eu)
[0124]
其中,s
t
代表用户与在过去t时刻视频构建的兴趣特征,e
video,t
表示历史点击过的t时刻的视频embedding特征,eu表示用户的embedding特征,e
video
表示当前视频embedding特征,s
τ
表示用户与当前视频构建的兴趣特征,match是一种注意力匹配机制:
[0125][0126][0127]
其中,similary(γk,β)为第k个激活权重,γk代表第k个特征,wk代表可学习参数,β可为兴趣特征也可为用户id特征;match(γ,β)为最终匹配的特征。
[0128]
然后,利用lstm来提取用户是高层次的时间兴趣特征:
[0129]
[h1,
…
,h
t
,
…
,h
t
]=lstm([s1,s2,
…
,s
t
])
[0130]
其中,h
t
代表t时刻对应构建的历史兴趣,s
t
代表第t个用户行为特征。
[0131]
最后,利用match网络对历史兴趣对建模,获得用户对当前视频最终的兴趣特征s
。
[0132]s
=match(h,s
τ
)
[0133]
其中,h代表lstm构建的历史兴趣特征的隐藏状态。
[0134]
步骤205:融合学习到的短视频内容特征用户兴趣特征d,用户特征eu和视频特征ei预测出点击该条短视频的概率,基于预测的概率对短视频进行推荐。
[0135][0136]
其中,为最终的输出的点击率概率,sigmoid(
·
)是激活函数。
[0137]
实施例3
[0138]
下面结合具体算例对实施例1和2中的方案进行可行性验证,详见下文描述:
[0139]
使用来自从今日头条的短视频推荐数据集作为实施样本,它总共包含大约1962万条交互信息,其中共有70711个用户、3687157条短视频。而且每条短视频包含其图像、文本、声音和一些短视频描述信息。利用这些交互信息构建出用户行为序列信息。随机地将整个数据集分为三个子集:按照80%作为训练集,10%作为验证集,10%作为测试集划分数据集,且分别用p
train
、p
valid
和p
test
来表示。将p
train
、p
valid
分别作为训练过程的训练集和验证集,用本发明提出方法进行训练。
[0140]
本发明实施例的检测性能使用平均精度均值(auc)作为模型的评价指标。auc的计算如下:
[0141][0142][0143]
其中,p为正样本数量,n为负样本数量,p
pos
为正样本预测得分,p
neg
为负样本预测得分。
[0144]
实施例4
[0145]
基于内容与兴趣学习的短视频推荐装置,该装置包括:处理器和存储器,存储器中存储有程序指令,处理器调用存储器中存储的程序指令以使装置执行以下方法步骤:
[0146]
构建用户行为序列,从用户行为序列中发掘用户兴趣特征;
[0147]
将短视频的基本信息通过嵌入层将高维独热编码特征映射为低维特征向量,用于发掘短视频特征;
[0148]
关注特定模态的跨模态多头注意力网络增强图像模态的特征,并引导短视频特征的学习;
[0149]
通过引导用户特征学习的时序兴趣提取网络引导用户兴趣特征学习;
[0150]
通过上述学习的短视频特征和用户兴趣特征经过点击率预测网络预测用户点击短视频的概率,基于预测的概率对短视频进行推荐。
[0151]
其中,所述跨模态多头注意力网络为:
[0152]
用于学习模态内的自注意力特征和学习模态间的跨模态注意力特征;在非线性变换层采用输入的短视频特征引导短视频特征的学习;
[0153]
将多模态特征作为输入,xm是任意多种模态,dm是模态m的特征维度,m∈{v,a,t}分别代表短视频的图像特征、声音特征和文本特征;
[0154]
将每个模态都分成n块对这些模态块做线性变换,映射到相同的维度;
[0155]
在变换后,对相应的特征做了位置编码,以保留各个模态内的空间位置信息,最终得到gfct的输入
[0156][0157]
其中,模态m的位置编码,是模态m第i块特征向量,是vit中的类别标记向量,c为gfct输入的特征维度,fc代表全连接层。
[0158]
其中,所述跨模态多头注意力网络包括:关注特定模态的多头自注意力模块,所述多头自注意力模块从自身角度学习每个模态内的特征块之间的联系:
[0159][0160]
其中,l=1,2,
…
,l表示fct模块第l层,l表示一种l层fct模块,第一层的输入为,l表示fct模块第l层,l表示一种l层fct模块,第一层的输入为表示第l层输出的模态m内特征表示,msa表示多头自注意力机制;
[0161][0162][0163]
其中,分别表示第l层视觉模态v与文本模态t,声音模态a的跨模态交互特征,c代表特征的维度,n代表特征长度;
[0164]
这两种交互特征用于对图像特征的增强,以增加视觉信息的表达;
[0165][0166]
其中,表示第l层增强视觉特征;
[0167][0168]
其中,代表经过fmca的声音特征,代表经过fmca的文本特征。
[0169]
其中,所述方法还包括:提出一引导特征学习的gmlp,gmlp输入是经过fmca模块的三种模态上一层的短视频内容特征
[0170][0171]
其中,gfct(
·
)代表能够引导短视频特征学习同时关注特定模态的跨模态多头注意力网络,代表gfct的第l层模态m的输出特征,代表第l层内容特征,代表第l层短视频内容特征,代表第l层文本特征,代表第l层声音特征,代表增强后的视频特征。
[0172]
所述:
[0173][0174][0175]
其中,wi代表学习参数;b代表偏置。
[0176]
所述引导用户特征学习的时序兴趣提取网络为:
[0177]s
=gtin(s,e
video
,eu)
[0178]
其中,s={s1,
…st
,
…
,s
t
}代表用户行为序列特征,gtin(
·
)代表引导用户特征学习的时序兴趣提取网络,s
t
代表t时刻用户行为特征,e
video
表示当前视频embedding特征,eu表示用户的embedding特征,s
为用户对当前视频的兴趣特征。
[0179]
提取每条历史视频的兴趣特征s
t
,和当前点击视频的兴趣特征s
τ
:
[0180]st
=match(e
video,t
,eu)
[0181]sτ
=match(e
video
,eu)
[0182]
其中,e
video,t
表示历史点击过的t时刻的视频embedding特征,s
τ
表示用户与当前视频构建的兴趣特征,match为注意力匹配机制:
[0183][0184][0185]
其中,similary(γk,β)为第k个激活权重,γk代表第k个特征,wk代表可学习参数,β可为兴趣特征也可为用户id特征;match(γ,β)为最终匹配的特征,利用lstm提取用户是
高层次的时间兴趣特征:
[0186]
[h1,
…
,h
t
,
…
,h
t
]=lstm([s1,s2,
…
,s
t
])
[0187]
其中,h
t
代表t时刻对应构建的历史兴趣,s
t
代表第t个用户行为特征,利用match网络对历史兴趣对建模,获得用户对当前视频最终的兴趣特征。
[0188]
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
[0189]
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0190]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。