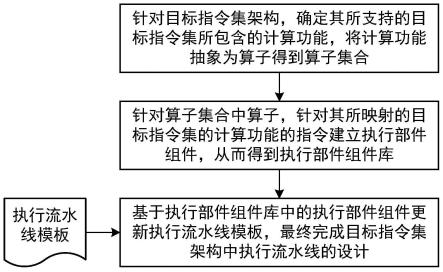
用于多个处理器的接口
1.相关申请的交叉引用
2.本技术要求于2021年3月1日提交的题为“用于多个处理器的接口(interface for multiple processors)”的美国专利申请第17/189,090号的优先权,其全部内容通过引用整体并入本文并用于所有目的。
技术领域
3.至少一个实施例涉及在多处理环境中管理工作负载。例如,至少一个实施例涉及用于将工作负载从处理器分配到多个加速器的机制。
背景技术:
4.响应于增加处理能力的需求,已经创建了各种计算技术。例如,处理器制造商试图通过提高指令可以顺序执行的速率来提高处理速度。然而,可以在单个处理器上执行可执行指令的速度存在限制。使用多个处理器来实现额外的计算会带来很大的复杂性,如果程序没有正确考虑复杂性,就会产生错误和其他问题的可能性。
附图说明
5.图1示出了根据至少一个实施例的到加速器对的接口的示例,其中每个加速器由应用程序通过对应的逻辑设备访问;
6.图2示出了根据至少一个实施例的到加速器的接口的示例,其中由应用程序使用两个逻辑设备来访问加速器;
7.图3示出了根据至少一个实施例的使用一对加速器的并行处理的示例,其中由应用程序使用单个逻辑设备访问两个加速器;
8.图4示出了根据至少一个实施例的使用一对加速器之间的直接通信的串行处理的示例;
9.图5示出了根据至少一个实施例的为多个加速器提供接口的组合库驱动器组件的示例;
10.图6示出了根据至少一个实施例的使用两个加速器对一组功能块进行串行处理的示例;
11.图7示出了根据至少一个实施例的使用两个加速器对一组功能块进行并行处理的示例;
12.图8示出了根据至少一个实施例的馈送逻辑设备的单独工作负载队列的示例;
13.图9示出了根据至少一个实施例的统一工作负载队列的示例;
14.图10示出了根据至少一个实施例的利用队列id的队列管理方案的示例;
15.图11示出了根据至少一个实施例的利用任务id的队列管理方案的示例;
16.图12示出了根据至少一个实施例的由于由计算机系统的一个或更多个处理器执行而使计算机系统并行地使用两个加速器来处理工作负载的过程的示例;
17.图13示出了根据至少一个实施例的由于由计算机系统的一个或更多个处理器执行而使计算机系统串行地使用两个加速器来处理工作负载的过程的示例;
18.图14示出了根据至少一个实施例的示例数据中心系统;
19.图15a示出了根据至少一个实施例的自主车辆的示例;
20.图15b示出了根据至少一个实施例的图15a的自主车辆的相机位置和视野的示例;
21.图15c是根据至少一个实施例的示出图15a的自主车辆的示例系统架构的框图;
22.图15d是根据至少一个实施例的示出用于一个或更多个基于云的服务器与图15a的自主车辆之间进行通信的系统的图;
23.图16是根据至少一个实施例的示出计算机系统的框图;
24.图17是根据至少一个实施例的示出计算机系统的框图;
25.图18示出了根据至少一个实施例的计算机系统;
26.图19示出了根据至少一个实施例的计算机系统;
27.图20a示出了根据至少一个实施例的计算机系统;
28.图20b示出了根据至少一个实施例的计算机系统;
29.图20c示出了根据至少一个实施例的计算机系统;
30.图20d示出了根据至少一个实施例的计算机系统;
31.图20e和图20f示出了根据至少一个实施例的共享编程模型;
32.图21示出了根据至少一个实施例的示例性集成电路和相关的图形处理器;
33.图22a和图22b示出了根据至少一个实施例的示例性集成电路和相关联的图形处理器;
34.图23a和图23b示出了根据至少一个实施例的附加的示例性图形处理器逻辑;
35.图24示出了根据至少一个实施例的计算机系统;
36.图25a示出了根据至少一个实施例的并行处理器;
37.图25b示出了根据至少一个实施例的分区单元;
38.图25c示出了根据至少一个实施例的处理集群;
39.图25d示出了根据至少一个实施例的图形多处理器;
40.图26示出了根据至少一个实施例的多图形处理单元(gpu)系统;
41.图27示出了根据至少一个实施例的图形处理器;
42.图28是根据至少一个实施例的示出用于处理器的处理器微架构的框图;
43.图29示出了根据一个或更多个实施例的图形处理器的至少部分;
44.图30示出了根据一个或更多个实施例的图形处理器的至少部分;
45.图31示出了根据一个或更多个实施例的图形处理器的至少部分;
46.图32是根据至少一个实施例的图形处理器的图形处理引擎的框图;
47.图33是根据至少一个实施例的图形处理器核心的至少部分的框图;
48.图34a和图34b示出了根据至少一个实施例的线程执行逻辑,其包括图形处理器核心的处理元件的阵列;
49.图35示出了根据至少一个实施例的并行处理单元(“ppu”);
50.图36示出了根据至少一个实施例的通用处理集群(“gpc”);
51.图37示出了根据至少一个实施例的并行处理单元(“ppu”)的存储器分区单元;
52.图38示出了根据至少一个实施例的流式多处理器;
53.图39示出了根据至少一个实施例的用于在5g无线通信网络内通信数据的网络;
54.图40示出了根据至少一个实施例的用于5g lte无线网络的网络架构;
55.图41是示出根据至少一个实施例的根据lte和5g原理操作的移动电信网络/系统的一些基本功能的图;
56.图42示出了根据至少一个实施例的可以是5g网络架构的部分的无线电接入网络;
57.图43提供了根据至少一个实施例的其中使用多个不同类型的设备的5g移动通信系统的示例图解;
58.图44示出了根据至少一个实施例的示例高级系统;
59.图45示出了根据至少一个实施例的网络系统的架构;
60.图46示出了根据至少一个实施例的设备的示例组件;
61.图47示出了根据至少一个实施例的基带电路的示例接口;
62.图48示出了根据至少一个实施例的上行链路信道的示例;
63.图49示出了根据至少一个实施例的网络系统的架构;
64.图50示出了根据至少一个实施例的控制平面协议栈;
65.图51示出了根据至少一个实施例的用户平面协议栈;
66.图52示出了根据至少一个实施例的核心网络的组件;以及
67.图53示出了根据至少一个实施例的支持网络功能虚拟化(nfv)的系统的组件。
具体实施方式
68.至少一个实施例适用于5g技术的实现。在基带单元(“bbu”)或分布式单元(“du”)部署的至少一个实施例中,一些物理层功能块由中央处理单元(“cpu”)处理,物理层(“phy”)算法的子集被卸载到一个或更多个硬件(“hw”)加速器。在至少一个实施例中,加速器是固定功能加速器,例如现场可编程门阵列(“fpga”)或专用集成电路(“asic”)。在至少一个实施例中,加速器是图形处理单元(“gpu”)。在至少一个实施例中,可以使用由物理处理器托管的库在软件中实现加速器,其中该库呈现提供处理服务的接口。在这种后备加速方法的至少一个实施例中,主机cpu调用加速器进行数据处理,将数据从主机存储器卸载/传输到加速器,并且在数据处理完成时,将结果接收回主机存储器。在至少一个实施例中,通过主机存储器交换数据施加了可扩展性限制,因为这种方法由于主机存储器和设备存储器之间的来回数据传输而产生显着的ddr i/o bw。
69.在至少一个实施例中,为了克服上述问题,使用内联加速方法,其中硬件加速器处理端到端流水线,从而避免来回数据传输。在至少一个实施例中,gpu被用作加速器来执行内联加速。在至少一个实施例中,使用支持固定功能加速器中的后备模式中的入队/出队工作负载的api来利用后备加速方法。至少一个实施例提供了现有标准api的替代方案,这些现有标准api无法有效地支持内联加速。在至少一个实施例中,为了解决上述限制,以与设备无关的方式将硬件加速器上的工作负载从cpu(主机设备)入队/出队。在至少一个实施例中,与设备无关的api允许cpu使用统一接口控制一个或更多个加速器,即使当加速器改变时也是如此。在至少一个实施例中,本文描述的技术使cpu能够利用单个统一接口来利用多个不同的加速资源。
70.至少一个实施例提供了一种机制,该机制允许应用计算机程序利用多个加速器来执行各种工作负载。在至少一个实施例中,应用计算机程序使用实现逻辑设备的应用程序编程接口。在至少一个实施例中,逻辑设备将工作负载分配给多个加速器。在至少一个实施例中,工作负载可以并行或串行分布和执行。在至少一个实施例中,一组工作负载被串行执行,并且中间结果从一个加速器传递到另一个加速器,而不需要应用程序或中央处理单元在加速器之间中继数据。
71.在至少一个实施例中,并行执行一组工作负载,并且基于每个个体工作负载和各个加速器的特性将各个工作负载分配给各种加速器。在至少一个实施例中,每个个体工作负载的特征在与工作负载相关联的加速分布中被描述。在至少一个实施例中,应用程序编程接口为逻辑设备实现单个工作负载队列,应用程序可以使用可选的工作负载特定标识符来获取有关各个工作负载或工作负载组的状态信息。在至少一个实施例中,应用程序将各种类型的工作负载提交到工作负载队列,并且逻辑设备将工作负载从队列中取出并在资源变得可用时将它们分派到适当的加速器。
72.至少一个实施例提供了优于先前方法的一个或更多个优点,包括:1)通过允许逻辑设备执行将各种工作负载路由到最合适的加速器来提高应用程序利用可用加速资源的能力,2)通过允许经由公共接口访问的逻辑设备利用中间结果的加速器到加速器传输来提高加速器操作的效率,3)提供对在多个加速器上运行的工作负载的改进监控。
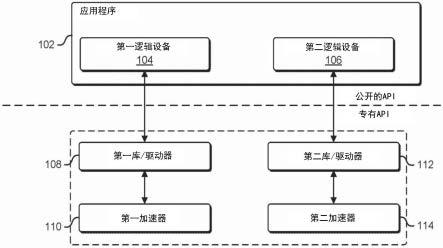
73.图1示出了根据至少一个实施例的到加速器对的接口的示例,其中每个加速器由应用程序通过对应的逻辑设备访问。在至少一个实施例中,托管在计算机系统上的应用程序102利用多个加速器来执行各种工作负载。在至少一个实施例中,逻辑设备是由存储在计算机可读存储器上的可执行指令创建的应用程序编程接口,作为被执行的结果,可执行指令呈现底层物理加速器或更多个加速器的逻辑抽象。在至少一个实施例中,应用程序与加速器的逻辑抽象的交互导致一个或更多个对应的物理加速器的对应改变。在至少一个实施例中,逻辑设备对操作或功能的执行被定义为一个或更多个处理器执行与逻辑设备相关联的可执行指令,从而使所描述的功能由一个或更多个处理器执行。在至少一个实施例中,逻辑设备被实现为逻辑对象或逻辑节点。
74.在至少一个实施例中,加速器可以是集成电路和专用集成电路、可编程门阵列、现场可编程门阵列、图形处理单元、数字信号处理器、处理器、网络或执行数字或模拟信息处理的一组组合逻辑或电路。在至少一个实施例中,计算机系统包括一个或更多个处理器和存储指令的计算机可读存储器,这些指令由于由一个或更多个处理器执行,导致计算机系统执行由应用程序定义的一系列操作。
75.在至少一个实施例中,应用程序102使用逻辑设备与多个加速器接口是到对应加速器的接口。在至少一个实施例中,第一逻辑设备104通过第一库/驱动器108向第一加速器110提供接口。在至少一个实施例中,第二逻辑设备106通过第二库/驱动器112向第二加速器114提供接口。在至少一个实施例中,通过将工作负载或工作流提交到对应的逻辑设备,经由应用程序控制将工作负载分发和分配给不同的加速器。
76.图2示出了根据至少一个实施例的到加速器的接口的示例,其中由应用程序使用两个逻辑设备来访问该接口。在至少一个实施例中,应用程序202利用多个逻辑设备作为到单个加速器的接口。在至少一个实施例中,第一逻辑设备204接受具有第一加速分布的工作
流,并且第二逻辑设备206接受具有第二加速分布的工作流。在至少一个实施例中,加速分布描述了要提交以在加速器上执行的工作负载、任务、作业、程序或子例程的特征和特性。在至少一个实施例中,加速分布可以描述工作负载可以并行执行的程度、完成工作负载所必需的特定操作、或存储器或资源要求。在至少一个实施例中,加速分布可以识别特定类型的加速器,相关的工作负载可以在该加速器上执行。在至少一个实施例中,通过队列为每个逻辑设备提供工作负载,该队列由应用程序使用入队操作填充并且由逻辑设备使用出队操作清空。在至少一个实施例中,入队操作将设备添加到队列的一端,而出队操作从队列的另一端移除工作负载。
77.在至少一个实施例中,第一逻辑设备204和第二逻辑设备206通过库/驱动器208将工作负载提交给加速器210以执行。在至少一个实施例中,库/驱动器是一组可执行指令,其被精心设计以形成应用程序202和加速器210之间的硬件特定接口。在至少一个实施例中,库/驱动器208包括存储在计算机可读存储器上的特定于加速器210的制造商的可执行指令。
78.图3示出了根据至少一个实施例的使用一对加速器的并行处理的示例,其中两个加速器都由应用程序使用单个逻辑设备来访问。在至少一个实施例中,应用程序302使用逻辑设备304作为到多个加速器的接口。在至少一个实施例中,逻辑设备304从应用程序302接收工作负载并将它们适当地分配给任一或两个加速器。在至少一个实施例中,工作负载可以是任务、子例程、函数或任何一组直接定义或指定为能够在加速器上执行的中间语言或源代码的可执行指令。在至少一个实施例中,逻辑设备304通过第一库/驱动器306将工作负载分配给第一加速器308,并且通过第二库/驱动器310将工作负载分配给第二加速器312。在至少一个实施例中,库/驱动器是特定于加速器的一组可执行指令,作为被执行的结果,该组可执行指令在制造商特定硬件和另一件软件之间创建接口。在至少一个实施例中,库/驱动器是设备驱动程序、静态库或动态库,其被除加速器制造商之外的实体开发的一件软件访问或合并到该件软件中。在至少一个实施例中,库/驱动器向另一件软件提供编程接口,该另一件软件向应用程序提供不同的应用程序编程接口。
79.在至少一个实施例中,这允许应用程序302将各种工作负载提交给逻辑设备304,而无需指定每个工作负载应该被分配到哪个加速器。在至少一个实施例中,逻辑设备304基于与每个工作负载相关联的加速分布来确定为每个工作负载使用哪个加速器。在至少一个实施例中,应用程序302向逻辑设备304提交多个工作负载,并且逻辑设备304在第一加速器308和第二加速器312之间划分工作负载,使得它们被并行执行。在至少一个实施例中,第一加速器308和第二加速器312之间的数据传输能力314未被使用。
80.图4示出了根据至少一个实施例的使用一对加速器之间的直接通信的串行处理的示例。在至少一个实施例中,应用程序402使用逻辑设备404作为到多个加速器的接口。在至少一个实施例中,逻辑设备404从应用程序402接收工作负载并将它们适当地分配给任一或两个加速器。在至少一个实施例中,工作负载可以是任务、子例程、函数或任何一组直接定义或指定为能够在加速器上执行的中间语言或源代码的可执行指令。在至少一个实施例中,逻辑设备404通过第一库/驱动器406将工作负载分配给第一加速器408,并且通过第二库/驱动器410将工作负载分配给第二加速器412。在至少一个实施例中,这允许应用程序402将各种工作负载提交给逻辑设备404,而无需指定每个工作负载应该被分配到哪个加速
器。在至少一个实施例中,应用程序通过逻辑设备(api)访问多个加速资源,该api处理跨可用资源分配工作负载的细节。至少在一个实施例中,工作负载被分配到一个加速器,该加速器又将中间结果和其他工作负载分配到另一个加速器,使得整个工作流以串行方式执行,而无需来自cpu或应用程序的交互。在至少一个实施例中,推进工作流所需的信息直接从一个加速器传递到下一个加速器,直到工作流完成。
81.在至少一个实施例中,逻辑设备404基于与每个工作负载相关联的加速分布来确定为每个工作负载使用哪个加速器。在至少一个实施例中,应用程序402向逻辑设备404提交多个工作负载,并且逻辑设备404利用第一加速器408和第二加速器412之间的物理通信链路,使得由第一加速器408产生的中间结果可以直接传递到第二加速器412,而无需通过应用程序402或使用应用程序402使用的cpu资源。在至少一个实施例中,逻辑设备404将多个工作负载提交给第一库/驱动器406,第一库/驱动器406将工作负载传递给第一加速器408。在至少一个实施例中,第一加速器408处理其中的一部分并通过直接通信机制414将中间结果和任何剩余的工作负载传递给第二加速器412。在至少一个实施例中,直接通信机制414可以是直接存储器访问(“dma”)、通信总线、串行链路或存储器中的共享区域。在至少一个实施例中,dma访问是从一个加速器经由总线、并行、串行或光学链路从一个加速器到另一个加速器的访问,该总线不通过诸如cpu之类的中央中间处理器进行转换。在至少一个实施例中,dma通过pci总线实现在个人计算机系统上。
82.图5示出了根据至少一个实施例的提供到多个加速器的接口的组合库驱动器组件的示例。在至少一个实施例中,应用程序502使用包括逻辑设备504的api访问一组加速资源。在至少一个实施例中,逻辑设备504访问组合库/驱动器506,其将工作负载的部分分配给第一加速器508和第二加速器510。在至少一个实施例中,组合库/驱动器506获得一个工作负载或一组工作负载,并将它们分配给第一加速器508和第二加速器510,从而并行地执行工作负载。在至少一个实施例中,组合库/驱动器506在加速器之间划分工作负载而无需来自应用程序502的干预。
83.图6示出了根据至少一个实施例的使用两个加速器对一组功能块进行串行处理的示例。在至少一个实施例中,在工作流604中处理的一组输入数据流602包括要加速的多个功能块(或工作负载)。在至少一个实施例中,使用多个加速器将输入数据流602处理成输出数据流606。在至少一个实施例中,输入数据流602是与5g网络相关联的蜂窝数据。
84.在至少一个实施例中,应用程序608获得输入数据流602并将工作流604提交给逻辑设备610进行处理。在至少一个实施例中,逻辑设备610检查工作流604并且至少部分地基于对工作流中一个或更多个工作负载的可用加速资源和加速分布的了解来确定使用通过第一库/驱动器612访问的第一加速器614和通过第二库/驱动器618访问的第二加速器620的组合串行处理工作流604。在至少一个实施例中,逻辑设备610通过将加速分布与各个加速器的特性相匹配并优化处理时间同时最小化与cpu处理应用程序608的进一步交互来做出确定。
85.在至少一个实施例中,逻辑设备610将工作流608(包括工作流608内的所有工作负载)分发到第一加速器614。在至少一个实施例中,逻辑设备610包括将第一加速器614引导两个前向工作流604的一部分两个第二加速器620的指令。在至少一个实施例中,第一加速器614处理第一工作流616,然后将第一工作流616和剩余工作流622的结果直接传递到第二
加速器620。在至少一个实施例中,该信息通过直接通信信道626传递。在至少一个实施例中,直接通信信道626可以是共享存储器、直接存储器访问操作、专用串行接口、通信总线或共享通信总线。在至少一个实施例中,第一加速器614和第二加速器620之间的信息交换不通过逻辑设备610中继。在至少一个实施例中,第二加速器620产生输出流606。在至少一个实施例中,输出流606被返回到应用程序608。在至少一个实施例中,输出流606被输出到另一计算机系统、物理网络接口或输出设备。
86.图7示出了根据至少一个实施例的使用两个加速器对一组功能块进行并行处理的示例。在至少一个实施例中,在工作流704中处理的一组输入数据流702包括要加速的多个功能块(或工作负载)。在至少一个实施例中,使用多个加速器将输入数据流702处理成输出数据流706。在至少一个实施例中,输入数据流702是与5g网络相关联的蜂窝数据。
87.在至少一个实施例中,应用程序708获得输入数据流702并将工作流704提交给逻辑设备710进行处理。在至少一个实施例中,逻辑设备710检查工作流704并且至少部分地基于对工作流中一个或更多个工作负载的可用加速资源和加速分布的了解来确定使用通过第一库/驱动器712访问的第一加速器714和通过第二库/驱动器718访问的第二加速器720的组合来并行处理工作流704。在至少一个实施例中,逻辑设备710通过将加速分布与各个加速器的特性相匹配并优化处理时间同时最小化与cpu处理应用程序708的进一步交互来做出确定。
88.在至少一个实施例中,逻辑设备710通过将工作流704发送到第一加速器714和第二加速器720并且使第一加速器714执行工作流716的一部分并且使第二加速器720执行工作流722的不同部分来将工作流704分发到第一加速器714和第二加速器720。在至少一个实施例中,由第一加速器714产生的输出与由第二加速器722产生的输出组合来产生输出流706。在至少一个实施例中,第一加速器714和第二加速器720并行执行工作流704的不同部分,导致工作流704的处理时间更短。在至少一个实施例中,逻辑设备710识别工作流704的哪些部分将由第一加速器714执行,其中工作流704的哪些部分将由第二加速器720执行。在至少一个实施例中,第一加速器714和第二加速器720各自基于每个加速器的不同能力执行工作流704的互补部分。在至少一个实施例中,不使用加速器之间的直接通信726。在至少一个实施例中,逻辑设备710将工作流714划分为两组工作负载,并且为每个加速器提供不同的工作负载组。
89.图8示出了根据至少一个实施例的馈送逻辑设备的单独工作负载队列的示例。在至少一个实施例中,应用程序802实现了将工作负载馈送到一个或更多个加速器的多个工作负载队列。在至少一个实施例中,第一队列804接受具有第一加速分布的工作负载并且第二队列806接受具有第二加速分布的工作负载。在至少一个实施例中,加速分布描述了工作负载的特性,例如加速器所需的操作特性、工作负载的处理需求、工作负载的存储器需求以及加速器的指令集需求。在至少一个实施例中,应用程序802将第一工作负载814、第二工作负载812、第三工作负载810和第四工作负载808添加到第一队列804。在至少一个实施例中,应用程序802将第五工作负载822、第六工作负载820、第七工作负载818和第八工作负载816添加到第二队列806。在至少一个实施例中,放置在第一队列804中的工作负载具有第一加速分布,以及放置在第二队列806中的工作负载具有第二加速分布。在至少一个实施例中,第一加速分布和第二加速分布是不同的分布。
90.在至少一个实施例中,第一队列804和第二队列806都被逻辑设备824使用。在至少一个实施例中,逻辑设备824从第一队列804和第二队列806中移除工作负载以由加速器处理。在至少一个实施例中,逻辑设备824从至少部分地基于与队列中的工作负载相关联的加速分布选择的队列中移除工作负载。在至少一个实施例中,逻辑设备824通过库/驱动器826将工作负载提交给加速器828。在至少一个实施例中,逻辑设备24通常将从队列获得的工作负载提交给多个加速器,所述多个加速器至少部分地基于相关工作负载的加速分布来选择。
91.图9示出了根据至少一个实施例的统一工作负载队列的示例。在至少一个实施例中,应用程序900生成具有多个加速分布的工作负载并将它们提交给单个队列902。在至少一个实施例中,单个队列902接受具有各种不同加速分布的工作负载。在至少一个实施例中,单个队列902包括共享共同的第一加速分布的第一工作负载904、第二工作负载906、第五工作负载912和第六工作负载914。在至少一个实施例中,单个队列902接受共享第二加速分布的第三工作负载908、第四工作负载910、第七工作负载916和第八工作负载918。在至少一个实施例中,八个工作负载904、906、908、910、912、914、916和918由应用程序900和单个队列插入操作(入队)放置在单个队列902中。
92.在至少一个实施例中,逻辑设备920在单个操作中从单个队列902中移除工作流项目(工作负载)组(出队)。在至少一个实施例中,单个队列902可以包含多个工作流,每个工作流包括多个工作负载,并且每个工作流具有具有各种加速分布的工作负载。在至少一个实施例中,逻辑设备920从单个队列902中提取工作流,检查工作流内的工作负载,并通过库/驱动器922将各个工作负载分发给一个或更多个加速器,例如加速器924。在至少一个实施例中,可以为多个加速器提供来自由逻辑设备920获得的单个工作流的工作负载。在至少一个实施例中,可以通过拆分关联的工作负载并并行或串行地执行它们来执行单独的工作流。在至少一个实施例中,可以使用从一个加速器到另一个加速器的直接传输来执行串行执行,而无需逻辑设备920的干预。
93.图10示出了根据至少一个实施例的利用队列id的队列管理方案的示例。在至少一个实施例中,应用程序1002将多个工作负载添加到队列1004。在至少一个实施例中,每个工作负载由应用程序在单个操作中添加到队列。在至少一个实施例中,包括多个工作负载1006、1008、1010和1012的工作流在多个操作中被添加到队列1004。在至少一个实施例中,队列1004中的每个工作负载是类似的加速分布。在至少一个实施例中,队列1004与特定的加速分布相关联,并且放置在队列1004中的所有工作负载都具有匹配的加速分布。在至少一个实施例中,如果使用不同的加速分布,则还使用多个队列,因为每个队列与不同的加速分布相关联。在至少一个实施例中,逻辑设备1014从一个或更多个队列中提取工作负载,每个队列与不同的加速分布相关联。在至少一个实施例中,逻辑设备1014一次仅从单个队列中提取单个工作负载。
94.在至少一个实施例中,逻辑设备1014从队列1004中一次移除一个工作负载,并通过库/驱动器1016在加速器1018上执行它们。在至少一个实施例中,可以使用多个加速器,并且逻辑设备1014将工作负载分发给多个加速器,同时将单个逻辑设备接口呈现给应用程序1002。
95.图11示出了根据至少一个实施例的利用任务id的队列管理方案的示例。在至少一
个实施例中,单个队列1102接受具有多种不同加速分布的工作负载。在至少一个实施例中,单个队列1102包括共享共同的第一加速分布的第一工作负载1104、第二工作负载1106、第五工作负载1112和第六工作负载1114。在至少一个实施例中,单个队列1102接受共享第二加速分布的第三工作负载1108、第四工作负载1110、第七工作负载1116和第八工作负载1118。在至少一个实施例中,八个工作负载1104、1106、1108、1110、1112、1114、1116和1118由应用程序1100和单个队列插入操作放置在单个队列1102中(入队)。
96.在至少一个实施例中,逻辑设备1120在单个操作中从单个队列1102中移除工作流项目(工作负载)组(出队)。在至少一个实施例中,单个队列1102可以包含多个工作流,每个工作流包括多个工作负载,并且每个工作流具有具有各种加速分布的工作负载。在至少一个实施例中,逻辑设备1120从单个队列1102中提取工作流,检查工作流内的工作负载,并通过库/驱动器1122将各个工作负载分发到诸如加速器1124的一个或更多个加速器。在至少一个实施例中,可以为多个加速器提供来自逻辑设备1120获得的单个工作流的工作负载。在至少一个实施例中,可以通过拆分相关联的工作负载并且并行或串行地执行它们来执行单独的工作流。在至少一个实施例中,可以使用从一个加速器到另一个加速器的直接传输来执行串行执行,而无需逻辑设备1120的干预。
97.在至少一个实施例中,单个队列1102中的每个工作负载与任务id相关联。在至少一个实施例中,应用程序1100可以通过向逻辑设备1120提供相应的任务id来请求关于特定工作负载的状态信息。在至少一个实施例中,任务id可以与个体工作负载或同一工作流内的多个工作负载相关联。在至少一个实施例中,应用程序1100可以通过识别具有相关联的任务id的单独工作负载来发布关于特定工作负载的管理的指令。在至少一个实施例中,应用程序1100可以启动、停止、中止或请求与特定工作负载相关联的状态。
98.图12示出了根据至少一个实施例的过程1200的示例,该过程作为由计算机系统的一个或更多个处理器执行的结果,使得计算机系统使用两个并行的加速器来处理工作负载。在至少一个实施例中,过程1200开始于框1202,其中逻辑设备经由由应用程序馈送的单个队列获得包括一个或更多个工作负载的工作流。在至少一个实施例中,单独的工作流可以包括具有多个不同加速分布的工作负载。在至少一个实施例中,加速分布可以识别适合用于执行相关工作负载的不同类型的加速器、指令集或加速器资源。
99.在至少一个实施例中,在框1204,逻辑设备确定第一加速器对于开始执行工作流是必要的,并且因此将其转发到适当的加速器。
100.在至少一个实施例中,在框1206,第一加速器从逻辑设备获得工作流。在至少一个实施例中,在框1208,第一加速器处理工作流的部分,该部分包括可由第一加速器执行的一组适当工作负载。在至少一个实施例中,在框1210,第一加速器将在框1208产生的中间结果以及工作流的任何剩余工作负载传送到第二加速器。
101.在至少一个实施例中,在框1212,第二加速器从第一加速器获得中间结果和要完成的工作流的一部分工作负载。在至少一个实施例中,在框1214,第二加速器处理工作流的剩余工作负载。在至少一个实施例中,在框1216,第二加速器提供工作流的完整结果,包括在框1214由第二加速器产生的结果和在框1208由第一加速器产生的结果。
102.图13示出了根据至少一个实施例的过程1300的示例,该过程作为由计算机系统的一个或更多个处理器执行的结果,使得计算机系统使用两个串联的加速器来处理工作负
载。在至少一个实施例中,在框1302,逻辑设备从应用程序获得工作流。在至少一个实施例中,逻辑设备通过从由应用程序填充的队列中移除工作流来获得工作流。在至少一个实施例中,工作流包括一个或更多个工作负载。在至少一个实施例中,每个工作负载具有关联的加速分布。在至少一个实施例中,在框1304,逻辑设备识别并分发要由第一加速器执行的工作流的一部分。在至少一个实施例中,在框1306,逻辑设备识别并分发要由第二加速器执行的工作流的一部分。
103.在至少一个实施例中,在框1308,逻辑设备使第一加速器获得工作流的一部分。在至少一个实施例中,在框1310,第一加速器执行在框1308获得的工作流的一部分。在至少一个实施例中,可以通过指定由第一加速器执行的功能或通过向工作流的一部分提供可执行指令来启动工作流的执行。在至少一个实施例中,在框1312,第一加速器提供与在框1308获得的工作流的一部分相对应的结果。
104.在至少一个实施例中,在框1314,逻辑设备使第二加速器获得工作流的一部分。在至少一个实施例中,可以通过逻辑设备传输能够在加速器上执行的可执行指令,或者通过识别加速器上的可执行指令,从逻辑设备传输工作流。在至少一个实施例中,在框1316,第二加速器处理在框1314提供的工作流的一部分。在至少一个实施例中,在框1318,第二加速器提供在框1316产生的结果。
105.在至少一个实施例中,使用图13所示和以上描述的技术,提供给逻辑设备的工作流被划分并使用多个加速器并行执行。在至少一个实施例中,由各个加速器产生的结果被组合以产生最终结果。在至少一个实施例中,在框1302接收的工作流包括具有多个不同加速分布的工作负载,并且逻辑设备基于与该工作负载相关联的加速分布为特定工作负载选择特定加速器。在至少一个实施例中,逻辑设备能够通过将工作流的不同部分分发到最适于执行那些单独部分的加速器来利用多个不同的加速器。在至少一个实施例中,这种复杂性对应用程序是隐藏的,因为应用程序只需要与具有公共接口的单个逻辑设备交互。在至少一个实施例中,应用程序只需要为每个工作负载提供适当的加速分布。在至少一个实施例中,可以使用独立于工作流的整体状态的任务id来获得与每个工作负载相关联的状态。
106.数据中心
107.图14示出了可以使用至少一个实施例的示例数据中心1400。在至少一个实施例中,数据中心1400包括数据中心基础设施层1410、框架层1420、软件层1430和应用程序层1440。
108.在至少一个实施例中,如图14所示,数据中心基础设施层1410可以包括资源协调器1412、分组的计算资源1414和节点计算资源(“节点c.r.”)1416(1)-1416(n),其中“n”表示任何整数、正整数。在至少一个实施例中,节点c.r.1416(1)-1416(n)可以包括但不限于任何数量的中央处理单元(“cpu”)或其他处理器(包括加速器、现场可编程门阵列(fpga)、图形处理器等),存储器设备(例如动态只读存储器),存储设备(例如固态硬盘或磁盘驱动器),网络输入/输出(“nw i/o”)设备,网络交换机,虚拟机(“vm”),电源模块和冷却模块等。在至少一个实施例中,节点c.r.1416(1)-1416(n)中的一个或更多个节点c.r.可以是具有一个或更多个上述计算资源的服务器。
109.在至少一个实施例中,分组的计算资源1414可以包括容纳在一个或更多个机架内的节点c.r.的单独分组(未示出),或者容纳在各个地理位置的数据中心内的许多机架(也
未示出)。在至少一个实施例中,分组的计算资源1414内的节点c.r.的单独分组可以包括可以被配置或分配为支持一个或更多个工作负载的分组的计算、网络、存储器或存储资源。在至少一个实施例中,可以将包括cpu或处理器的几个节点c.r.分组在一个或更多个机架内,以提供计算资源来支持一个或更多个工作负载。在至少一个实施例中,一个或更多个机架还可以包括任何数量的电源模块、冷却模块和网络交换机,以任意组合。
110.在至少一个实施例中,资源协调器1412可以配置或以其他方式控制一个或更多个节点c.r.1416(1)-1416(n)和/或分组的计算资源1414。在至少一个实施例中,资源协调器1412可以包括用于数据中心1400的软件设计基础结构(“sdi”)管理实体。在至少一个实施例中,资源协调器可以包括硬件、软件或其某种组合。
111.在至少一个实施例中,如图14所示,框架层1420包括作业调度器1432、配置管理器1434、资源管理器1436和分布式文件系统1438。在至少一个实施例中,框架层1420可以包括支持软件层1430的软件1432和/或应用程序层1440的一个或更多个应用程序1442的框架。在至少一个实施例中,软件1432或应用程序1442可以分别包括基于web的服务软件或应用程序,例如由amazon web services,google cloud和microsoft azure提供的服务或应用程序。在至少一个实施例中,框架层1420可以是但不限于一种免费和开放源软件网络应用程序框架,例如可以利用分布式文件系统1438来进行大范围数据处理(例如“大数据”)的apache sparktm(以下称为“spark”)。在至少一个实施例中,作业调度器1432可以包括spark驱动器,以促进对数据中心1400的各个层所支持的工作负载进行调度。在至少一个实施例中,配置管理器1434可以能够配置不同的层,例如软件层1430和包括spark和用于支持大规模数据处理的分布式文件系统1438的框架层1420。在至少一个实施例中,资源管理器1436能够管理映射到或分配用于支持分布式文件系统1438和作业调度器1432的集群或分组计算资源。在至少一个实施例中,集群或分组计算资源可以包括数据中心基础设施层1410上的分组计算资源1414。在至少一个实施例中,资源管理器1436可以与资源协调器1412协调以管理这些映射的或分配的计算资源。
112.在至少一个实施例中,包括在软件层1430中的软件1432可以包括由节点c.r.1416(1)-1416(n)的至少一部分,分组的计算资源1414和/或框架层1420的分布式文件系统1438使用的软件。在至少一个实施例中,一个或更多个类型的软件可以包括但不限于internet网页搜索软件、电子邮件病毒扫描软件、数据库软件和流视频内容软件。
113.在至少一个实施例中,应用程序层1440中包括的一个或更多个应用程序1442可以包括由节点c.r.1416(1)-1416(n)的至少一部分、分组计算资源1414和/或框架层1420的分布式文件系统1438使用的一个或更多个类型的应用程序。在至少一个实施例中,一个或更多个类型的应用程序可以包括但不限于任何数量的基因组学应用程序、认知计算和机器学习应用程序,包括训练或推理软件,机器学习框架软件(例如pytorch、tensorflow、caffe等)或其他与一个或更多个实施例结合使用的机器学习应用程序。
114.在至少一个实施例中,配置管理器1434、资源管理器1436和资源协调器1412中的任何一个可以基于以任何技术上可行的方式获取的任何数量和类型的数据来实现任何数量和类型的自我修改动作。在至少一个实施例中,自我修改动作可以减轻数据中心1400的数据中心操作员做出可能不好的配置决定并且可以避免数据中心的未充分利用和/或执行差的部分。
115.在至少一个实施例中,数据中心1400可以包括工具、服务、软件或其他资源,以根据本文所述的一个或更多个实施例来训练一个或更多个机器学习模型或者使用一个或更多个机器学习模型来预测或推理信息。例如,在至少一个实施例中,可以通过使用上文关于数据中心1400描述的软件和计算资源,根据神经网络架构通过计算权重参数来训练机器学习模型。在至少一个实施例中,通过使用通过本文所述的一个或更多个训练技术计算出的权重参数,可以使用上面与关于数据中心1400所描述的资源,使用对应于一个或更多个神经网络的经训练的机器学习模型来推理或预测信息。
116.在至少一个实施例中,数据中心可以使用cpu、专用集成电路(asic)、gpu、fpga或其他硬件来使用上述资源来执行训练和/或推理。此外,上述的一个或更多个软件和/或硬件资源可以配置成一种服务,以允许用户训练或执行信息推理,例如图像识别、语音识别或其他人工智能服务。
117.在至少一个实施例中,数据中心1400可以包括使用具有多种加速器的多处理的计算机系统。例如,在至少一个实施例中,数据中心1400内的计算机系统可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,数据中心1400可以实现如上所述的api,使得托管在数据中心1400内的应用程序可以以简单的方式有效地使用加速资源。
118.图15a示出了根据至少一个实施例的自动驾驶车辆1500的示例。在至少一个实施例中,自动驾驶车辆1500(在本文中可替代地称为“车辆1500”)可以是但不限于客运车辆,例如汽车、卡车、公共汽车和/或可容纳一个或更多个乘客的另一种类型的车辆。在至少一个实施例中,车辆1500可以是用于拖运货物的半牵引车-拖车。在至少一个实施例中,车辆1500可以是飞机、机器人车辆或其他类型的车辆。
119.可以根据由美国运输部下属的国家公路交通安全管理局(“nhtsa”)和汽车工程师学会(“sae”)“与用于道路机动车辆的驾驶自动化系统有关的术语(taxonomy and definitions for terms related to driving automation systems for on-road motor vehicles)”(例如,于2018年6月15日发布的标准号j3016-201806,于2016年9月30日发布的标准号j3016-201609,以及该版本的以前和将来的版本此标准)定义的自动化级别来描述自动驾驶汽车。在一个或更多个实施例中,车辆1500可能能够根据自动驾驶级别的级别1-级别5中的一个或更多个来进行功能。例如,在至少一个实施例中,根据实施例,车辆1500可能能够进行条件自动化(级别3)、高度自动化(级别4)和/或全自动(级别5)。
120.在至少一个实施例中,车辆1500可以包括但不限于组件,诸如底盘、车身、车轮(例如2、4、6、8、18等)、轮胎、车轴和车辆的其他组件。在至少一个实施例中,车辆1500可以包括但不限于推进系统1550,例如内燃机、混合动力装置、全电动发动机和/或另一种推进系统类型。在至少一个实施例中,推进系统1550可以连接至车辆1500的传动系,其可以包括但不限于变速器,以使得能够对车辆1500进行推进。在至少一个实施例中,可以响应于从油门/加速器1552接收信号以控制推进系统1550。
121.在至少一个实施例中,当推进系统1550正在运行时(例如,当车辆行驶时),转向系统1554(其可以包括但不限于方向盘)用于使车辆1500转向(例如,沿着期望的路径或路线)。在至少一个实施例中,转向系统1554可以从转向致动器1556接收信号。在至少一个实施例中,方向盘对于全自动化(级别5)功能可以是可选的。在至少一个实施例中,制动传感
器系统1546可以用于响应于从制动致动器1548和/或制动传感器接收到的信号来操作车辆制动器。
122.在至少一个实施例中,控制器1536可以包括但不限于一个或更多个片上系统(“soc”)(图15a中未示出)和/或图形处理单元(“gpu”)向车辆1500的一个或更多个组件和/或系统提供信号(例如,代表命令)。例如,在至少一个实施例中,控制器1536可以发送信号以通过制动致动器1548操作车辆制动,通过一个或更多个转向致动器1556操作转向系统1554,通过一个或更多个油门(throttle)/加速器1552操作推进系统1550。在至少一个实施例中,一个或更多个控制器1536可以包括一个或更多个机载(例如,集成)计算设备(例如,超级计算机),其处理传感器信号并输出操作命令(例如,表示命令的信号)以实现自动驾驶和/或协助驾驶员驾驶车辆1500。在至少一个实施例中,一个或更多个控制器1536可以包括用于自动驾驶功能的第一控制器1536,用于功能安全功能的第二控制器1536,用于人工智能功能(例如计算机视觉)的第三控制器1536,用于信息娱乐功能的第四控制器1536,用于紧急情况下的冗余的第五控制器1536和/或其他控制器。在至少一个实施例中,单个控制器1536可以处理上述功能中的两个或更多个,两个或更多控制器1536可以处理单个功能和/或其任何组合。
123.在至少一个实施例中,一个或更多个控制器1536响应于从一个或更多个传感器(例如,传感器输入)接收到的传感器数据,提供用于控制车辆1500的一个或更多个组件和/或系统的信号。在至少一个实施例中,传感器数据可以从传感器接收,传感器类型例如但不限于一个或更多个全球导航卫星系统(“gnss”)传感器1558(例如,一个或更多个全球定位系统传感器)、一个或更多个radar传感器1560、一个或更多个超声波传感器1562、一个或更多个lidar传感器1564、一个或更多个惯性测量单元(imu)传感器1566(例如,一个或更多个加速度计、一个或更多个陀螺仪、一个或更多个磁罗盘、一个或更多个磁力计等)、一个或更多个麦克风1596、一个或更多个立体声相机1568、一个或更多个广角相机1570(例如鱼眼相机)、一个或更多个红外相机1572、一个或更多个环绕相机1574(例如,360度相机)、远程相机(图15a中未示出)、中程相机(图15a中未示出)、一个或更多个速度传感器1544(例如,用于测量车辆1500的速度)、一个或更多个振动传感器1542、一个或更多个转向传感器1540、一个或更多个制动传感器(例如,作为制动传感器系统1546的一部分)和/或其他传感器类型接收。
124.在至少一个实施例中,一个或更多个控制器1536可以从车辆1500的仪表板1532接收输入(例如,由输入数据表示)并通过人机接口(“hmi”)显示器1534、声音信号器、扬声器和/或车辆1500的其他组件提供输出(例如,由输出数据、显示数据等表示)。在至少一个实施例中,输出可包括信息,诸如车速、速度、时间、地图数据(例如,高清晰度地图(图15a中未显示)、位置数据(例如,车辆1500的位置,例如在地图上)、方向、其他车辆的位置(例如,占用光栅)、关于对象的信息以及由一个或更多个控制器1536感知到的对象的状态等。例如,在至少一个实施例中,hmi显示器1534可以显示关于一个或更多个对象的存在的信息(例如,路牌、警告标志、交通信号灯变更等)和/或有关驾驶操作车辆已经、正在或将要制造的信息(例如,现在改变车道、在两英里内驶出34b出口等)。
125.在至少一个实施例中,车辆1500进一步包括网络接口1524,其可以使用一个或更多个无线天线1526和/或一个或更多个调制解调器通过一个或更多个网络进行通信。例如,
在至少一个实施例中,网络接口1524可能能够通过长期演进(“lte”)、宽带码分多址(“wcdma”)、通用移动电信系统(“umts”)、全球移动通信系统(“gsm”)、imt-cdma多载波(“cdma2000”)网络等进行通信。在至少一个实施例中,一个或更多个无线天线1526还可以使用一个或更多个局域网(例如bluetooth、bluetooth low energy(le)、z-wave、zigbee等)和/或一个或更多个低功耗广域网(以下简称“lpwan”)(例如lorawan、sigfox等协议),使环境中的对象(例如,车辆、移动设备)之间进行通信。
126.在至少一个实施例中,车辆1500可以包括使用具有多种加速器的多处理的计算机系统。例如,在至少一个实施例中,车辆1500内的计算机系统可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,车辆1500内的计算机系统可以实现如上所述的api,使得操作车辆1500的应用程序可以以简单的方式有效地使用加速器资源。
127.图15b示出了根据至少一个实施例的图15a的自动驾驶车辆1500的相机位置和视野的示例。在至少一个实施例中,相机和各自的视野是一个示例实施例,并且不旨在进行限制。例如,在至少一个实施例中,可以包括附加的和/或替代的相机和/或相机可以位于车辆1500上的不同位置。
128.在至少一个实施例中,用于相机的相机类型可以包括但不限于可以适于与车辆1500的组件和/或系统一起使用的数字相机。在至少一个实施例中,一个或更多个相机可以以汽车安全完整性等级(“asil”)b和/或其他asil进行操作。在至少一个实施例中,根据实施例,相机类型可以具有任何图像捕获速率,例如60帧每秒(fps)、120fps、240fps等。在至少一个实施例中,相机可以能够使用滚动快门、全局快门、另一种类型的快门或其组合。在至少一个实施例中,滤色器阵列可以包括红色透明透明(“rccc”)滤色器阵列、红色透明透明蓝色(“rccb”)滤色器阵列、红色蓝色绿色透明(“rbgc”)滤色器阵列、foveon x3滤色器阵列、拜耳(bayer)传感器(“rggb”)滤色器阵列、单色传感器滤色器阵列和/或其他类型的滤色器阵列。在至少一个实施例中,可以使用透明像素相机,例如具有rccc、rccb和/或rbgc滤色器阵列的相机,以努力提高光敏性。
129.在至少一个实施例中,一个或更多个相机可以用于执行先进驾驶员辅助系统(“adas”)功能(例如,作为冗余或故障安全设计的一部分)。例如,在至少一个实施例中,可以安装多功能单声道相机以提供包括车道偏离警告、交通标志辅助和智能大灯控制的功能。在至少一个实施例中,一个或更多个相机(例如,所有相机)可以同时记录并提供图像数据(例如,视频)。
130.在至少一个实施例中,可以将一个或更多个相机安装在安装组件中,例如定制设计的(三维(“3d”)打印的)组件,以便切出杂散光和来自在汽车内的反光(例如,仪表板的反射在挡风玻璃镜中反光),其可能会干扰相机的图像数据捕获能力。关于后视镜安装组件,在至少一个实施例中,后视镜组件可以是3d打印定制的,使得相机安装板匹配后视镜的形状。在至少一个实施例中,一个或更多个相机可以被集成到后视镜中。在至少一个实施例中,对于侧视相机,一个或更多个相机也可以集成在汽车的每个角落的四个支柱内。
131.在至少一个实施例中,具有包括车辆1500前面的环境的部分的视野的相机(例如,前向相机)可以用于环视,以及在一个或更多个控制器1536和/或控制soc的帮助下帮助识别向前的路径和障碍物,从而提供对于生成占用网格和/或确定优选的车辆路径至关重要
的信息。在至少一个实施例中,前向相机可以用于执行许多与lidar相同的adas功能,包括但不限于紧急制动、行人检测和避免碰撞。在至少一个实施例中,前向相机也可以用于adas功能和系统,包括但不限于车道偏离警告(“ldw”)、自动巡航控制(“acc”)和/或其他功能(例如交通标志识别)。
132.在至少一个实施例中,各种相机可以用于前向配置,包括例如包括cmos(“互补金属氧化物半导体”)彩色成像器的单目相机平台。在至少一个实施例中,广角相机1570可以用于感知从外围进入的对象(例如,行人、过马路或自行车)。尽管在图15b中仅示出了一个广角相机1570,但是,在其他实施例中,车辆1500上可以有任何数量(包括零)的广角相机1570。在至少一个实施例中,任何数量的远程相机1598(例如,远程立体相机对)可用于基于深度的对象检测,尤其是对于尚未训练神经网络的对象。在至少一个实施例中,远程相机1598也可以用于对象检测和分类以及基本对象跟踪。
133.在至少一个实施例中,任何数量的立体声相机1568也可以包括在前向配置中。在至少一个实施例中,一个或更多个立体声相机1568可以包括集成控制单元,该集成控制单元包括可缩放处理单元,该可缩放处理单元可以提供可编程逻辑(“fpga”)和具有单个芯片上集成的控制器局域网(“can”)或以太网接口的多核心微处理器。在至少一个实施例中,这样的单元可以用于生成车辆1500的环境的3d地图,包括对图像中所有点的距离估计。在至少一个实施例中,一个或更多个立体相机1568可以包括但不限于紧凑型立体视觉传感器,其可以包括但不限于两个相机镜头(左右分别一个)和一个图像处理芯片,其可以测量从车辆1500到目标对象的距离并使用所生成的信息(例如,元数据)来激活自主紧急制动和车道偏离警告功能。在至少一个实施例中,除了本文所述的那些之外,还可以使用其他类型的立体相机1568。
134.在至少一个实施例中,具有包括车辆1500侧面的环境的一部分的视野的相机(例如,侧视相机)可以用于环绕查看,从而提供用于创建和更新占据网格的信息,以及产生侧面碰撞警告。例如,在至少一个实施例中,环绕相机1574(例如,如图15b所示的四个环绕相机1574)可以定位在车辆1500上。在至少一个实施例中,一个或更多个环绕相机1574可以包括但不限于,任意数量和组合的广角相机1570、一个或更多个鱼目镜头、一个或更多个360度相机和/或类似相机。例如,在至少一个实施例中,四个鱼目镜头相机可以位于车辆1500的前、后和侧面。在至少一个实施例中,车辆1500可以使用三个环绕相机1574(例如,左、右和后面),并且可以利用一个或更多个其他相机(例如,前向相机)作为第四个环视相机。
135.在至少一个实施例中,具有包括车辆1500后方的环境的一部分的视野的相机(例如,后视相机)可以用于停车辅助、环视、后方碰撞警告、以及创建和更新占用光栅。在至少一个实施例中,可以使用各种各样的相机,包括但不限于还适合作为一个或更多个前向相机的相机(例如,远程相机1598和/或一个或更多个中程相机1576、一个或更多个立体相机1568、一个或更多个红外相机1572等),如本文所述。
136.在至少一个实施例中,车辆1500可以包括使用具有多种加速器的多处理的计算机系统。例如,在至少一个实施例中,车辆1500内的计算机系统可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,车辆1500内的计算机系统可以实现如上所述的api,使得操作车辆1500的应用程序可以以简单的方式有效地使用加速器资源。
137.图15c示出了根据至少一个实施例的图15a的自动驾驶车辆1500的示例系统架构的框图。在至少一个实施例中,图15c中的车辆1500的一个或更多个组件、一个或更多个特征和一个或更多个系统中的每一个都示出为经由总线1502连接。在至少一个实施例中,总线1502可包括但不限于can数据接口(在本文中可替代地称为“can总线”)。在至少一个实施例中,can可以是车辆1500内部的网络,用于帮助控制车辆1500的各种特征和功能,例如制动器的致动、加速、制动、转向、雨刷等。在一个实施例中,总线1502可以配置成具有数十个甚至数百个节点,每个节点具有其自己的唯一识别符(例如,can id)。在至少一个实施例中,可以读取总线1502以找到方向盘角度、地面速度、发动机每分钟转动次数(“rpm”)、按钮位置和/或其他车辆状态指示器。在至少一个实施例中,总线1502可以是符合asil b的can总线。
138.在至少一个实施例中,除了can之外或来自can,可使用flexray和/或以太网(ethernet)。在至少一个实施例中,可以有任意数量的总线1502,其可以包括但不限于零或更多的can总线,零或更多的flexray总线,零或更多的以太网总线,和/或零或更多的使用其他协议的其他类型的总线。在至少一个实施例中,两个或更多个总线1502可以用于执行不同的功能,和/或可以用于冗余。例如,第一总线1502可以用于碰撞避免功能,并且第二总线1502可以用于致动控制。在至少一个实施例中,每个总线1502可以与车辆1500的任何组件通信,并且总线1502的两个或更多个可以与相同的组件通信。在至少一个实施例中,任何数量的片上系统(“soc”)1504中的每一个,一个或更多个控制器1536中的每一个和/或车辆内的每个计算机都可以访问相同的输入数据(例如,来自车辆1500的传感器的输入),并且可以连接到公共总线,例如can总线。
139.在至少一个实施例中,车辆1500可以包括一个或更多个控制器1536,诸如本文关于图15a所描述的那些。在至少一个实施例中,控制器1536可以用于多种功能。在至少一个实施例中,控制器1536可以耦合到车辆1500的各种其他组件和系统中的任何一个,并且可以用于控制车辆1500、车辆1500的人工智能、车辆1500的信息娱乐和/或其他功能。
140.在至少一个实施例中,车辆1500可以包括任何数量的soc 1504。soc 1504中的每一个可以包括但不限于中央处理单元(“一个或更多个cpu”)1506、图形处理单元(“一个或更多个gpu”)1508、一个或更多个处理器1510、一个或更多个高速缓存1512、一个或更多个加速器1514、一个或更多个数据存储1516和/或其他未显示的组件和特征。在至少一个实施例中,一个或更多个soc 1504可以用于在各种平台和系统中控制车辆1500。例如,在至少一个实施例中,一个或更多个soc 1504可以与高清晰度(“hd”)地图1522在系统(例如,车辆1500的系统)中组合,该高清晰度地图1522可以经由网络接口1524从一个或更多个服务器(图15c中未示出)获得地图刷新和/或更新。
141.在至少一个实施例中,一个或更多个cpu 1506可以包括cpu集群或cpu复合体(在本文中可替代地称为“ccplex”)。在至少一个实施例中,一个或更多个cpu 1506可以包括多个核心和/或二级(“l2”)高速缓存。例如,在至少一个实施例中,一个或更多个cpu 1506可以在相互耦合的多处理器配置中包括八个核心。在至少一个实施例中,一个或更多cpu 1506可以包括四个双核心集群,其中每个集群具有专用的l2高速缓存(例如,2mb l2高速缓存)。在至少一个实施例中,一个或更多cpu 1506(例如,ccplex)可以配置成支持同时的集群操作,使得一个或更多cpu 1506的集群的任何组合在任何给定的时间都可以是活跃的。
142.在至少一个实施例中,一个或更多个cpu 1506可以实现电源管理功能,这些功能包括但不限于以下特征中的一个或更多个:空闲时可以自动对各个硬件模块进行时钟门控以节省动态功率;当该核心由于执行等待中断(“wfi”)/事件等待(“wfe”)指令而未主动执行指令时,可以对每个核心时钟进行门控;每个核心都可以独立供电;当所有核心都被时钟门控或功率门控时,每个核心集群可以被独立地时钟门控;以及/或当所有核心都被功率门控时,每个核心集群可以被独立地功率门控。在至少一个实施例中,一个或更多cpu 1506可以进一步实现用于管理功率状态的增强算法,其中指定了允许的功率状态和预期的唤醒时间,并且硬件/微码确定了针对核心、集群和ccplex输入的最佳功率状态。在至少一个实施例中,处理核心可以在软件中支持简化的功率状态输入序列,其中工作被分担给微码。
143.在至少一个实施例中,一个或更多个gpu 1508可以包括集成的gpu(在本文中或者称为“igpu”)。在至少一个实施例中,一个或更多个gpu 1508可以是可编程的,并且对于并行工作负载可以是有效的。在至少一个实施例中,一个或更多个gpu 1508可以使用增强的张量指令集。在一个实施例中,一个或更多个gpu 1508可以包括一个或更多个流式微处理器,其中每个流式微处理器可以包括一级(“l1”)高速缓存(例如,具有至少96kb的存储容量的l1高速缓存),以及两个或更多个流式微处理器可以共享l2高速缓存(例如,具有512kb存储容量的l2高速缓存)。在至少一个实施例中,一个或更多个gpu 1508可以包括至少八个流式微处理器。在至少一个实施例中,一个或更多个gpu 1508可以使用计算应用程序编程接口(api)。在至少一个实施例中,一个或更多gpu 1508可以使用一个或更多个并行计算平台和/或编程模型(例如,nvidia的cuda)。
144.在至少一个实施例中,一个或更多个gpu 1508可以经功耗优化以在汽车和嵌入式用例中获得最佳性能。例如,在一个实施例中,可以在鳍式场效应晶体管(“finfet”)上制造一个或更多个gpu 1508。在至少一个实施例中,每个流式微处理器可以包含多个划分为多个块的混合精度处理核心。例如但不限于,可以将64个pf32核心和32个pf64核心划分为四个处理块。在至少一个实施例中,可以为每个处理块分配16个fp32核心、8个fp64核心、16个int32核心、两个用于深度学习矩阵算术的混合精度nvidia张量核心、零级(“l0”)指令缓存、线程束调度器、分派单元和/或64kb寄存器文件。在至少一个实施例中,流式微处理器可以包括独立的并行整数和浮点数据路径来提供混合了计算和寻址运算的工作量的有效执行。在至少一个实施例中,流式微处理器可以包括独立的线程调度能力,以实现更细粒度的同步和并行线程之间的协作。在至少一个实施例中,流式微处理器可以包括组合的l1数据高速缓存和共享存储器单元,以便在简化编程的同时提高性能。
145.在至少一个实施例中,一个或更多个gpu 1508可以包括高带宽存储器(“hbm”)和/或16gb hbm2存储器子系统,以在一些示例中提供约900gb/秒的峰值存储带宽。在至少一个实施例中,除了或替代于hbm存储器,可以使用同步图形随机存取存储器(“sgram”),例如图形双倍数据速率类型的五同步随机存取存储器(“gddr5”)。
146.在至少一个实施例中,一个或更多个gpu 1508可以包括统一存储器技术。在至少一个实施例中,地址转换服务(“ats”)支持可以用于允许一个或更多个gpu 1508直接访问一个或更多个cpu 1506页表。在至少一个实施例中,当一个或更多个gpu 1508存储器管理单元(“mmu”)经历未命中时,可以将地址转换请求发送到一个或更多个cpu 1506。作为响应,在至少一个实施例中,一个或更多个cpu 1506可以在其页面表中查找地址的虚拟-物理
的映射并将转换传送回一个或更多个gpu 1508。在至少一个实施例中,统一存储器技术可以允许单个统一虚拟地址空间用于一个或更多个cpu 1506和一个或更多个gpu 1508两者的存储器,从而简化了一个或更多个gpu 1508的编程以及将应用程序移植到一个或更多个gpu 1508。
147.在至少一个实施例中,一个或更多个gpu 1508可以包括任意数量的访问计数器,其可以跟踪一个或更多个gpu 1508对其他处理器的存储器的访问频率。在至少一个实施例中,一个或更多个访问计数器可以帮助确保将存储器页移动到最频繁访问页面的处理器的物理存储器中,从而提高处理器之间共享的存储器范围的效率。
148.在至少一个实施例中,一个或更多个soc 1504可以包括任何数量的高速缓存1512,包括本文所述的那些。例如,在至少一个实施例中,一个或更多个高速缓存1512可以包括可用于一个或更多个cpu 1506和一个或更多个gpu 1508(例如,连接到cpu 1506和gpu 1508)的三级(“l3”)高速缓存。在至少一个实施例中,一个或更多个高速缓存1512可以包括回写式高速缓存,该回写式高速缓存可以例如通过使用高速缓存相干协议(例如,mei、mesi、msi等)来跟踪线的状态。在至少一个实施例中,尽管可以使用较小的高速缓存大小,根据实施例,l3高速缓存可以包括4mb或更多。
149.在至少一个实施例中,一个或更多个soc 1504可以包括一个或更多个加速器1514(例如,硬件加速器、软件加速器或其组合)。在至少一个实施例中,一个或更多个soc 1504可以包括硬件加速集群,其可以包括优化的硬件加速器和/或大的片上存储器。在至少一个实施例中,大的片上存储器(例如4mb的sram)可以使硬件加速集群能够加速神经网络和其他计算。在至少一个实施例中,硬件加速集群可以用于补充一个或更多个gpu 1508并且卸载一个或更多个gpu 1508的一些任务(例如,释放一个或更多个gpu 1508的更多周期以执行其他任务)。在至少一个实施例中,一个或更多个加速器1514可以用于足够稳定以经得起加速检验的目标工作负载(例如,感知、卷积神经网络(“cnn”)、递归神经网络(“rnn”)等)。在至少一个实施例中,cnn可以包括基于区域或区域卷积神经网络(“rcnn”)和快速rcnn(例如,如用于对象检测)或其他类型的cnn。
150.在至少一个实施例中,一个或更多个加速器1514(例如,硬件加速集群)可以包括一个或更多个深度学习加速器(“dla”)。一个或更多个dla可以包括但不限于一个或更多个tensor处理单元(“tpu”),其可以配置成每秒提供额外的10万亿次操作用于深度学习应用程序和推理。在至少一个实施例中,tpu可以是配置成并被优化用于执行图像处理功能(例如,用于cnn、rcnn等)的加速器。可以针对神经网络类型和浮点运算以及推理的特定集合进一步优化一个或更多个dla。在至少一个实施例中,一个或更多个dla的设计可以提供比典型的通用gpu更高的每毫米性能,并且通常大大超过cpu的性能。在至少一个实施例中,一个或更多个tpu可执行若干功能,包括支持例如int8、int16和fp16数据类型以用于特征和权重的单实例卷积功能以及后处理器功能的。在至少一个实施例中,一个或更多个dla可以针对各种功能中的任何功能,在处理或未处理的数据上快速且有效地执行神经网络,尤其是cnn,包括例如但不限于:用于使用来自相机传感器的数据进行对象识别和检测的cnn;用于使用来自相机传感器的数据进行距离估算的cnn;用于使用来自麦克风1596的数据进行紧急车辆检测以及识别和检测的cnn;用于使用来自相机传感器的数据进行人脸识别和车主识别的cnn;以及/或用于安全和/或安全相关事件的cnn。
151.在至少一个实施例中,dla可以执行一个或更多个gpu 1508的任何功能,并且通过使用推理加速器,例如,设计者可以将一个或更多个dla或一个或更多个gpu 1508作为目标用于任何功能。例如,在至少一个实施例中,设计者可以将cnn的处理和浮点运算集中在一个或更多个dla上,并将其他功能留给一个或更多个gpu 1508和/或其他一个或更多个加速器1514。
152.在至少一个实施例中,一个或更多个加速器1514(例如,硬件加速集群)可以包括可编程视觉加速器(“pva”),其在本文中可以可替代地称为计算机视觉加速器。在至少一个实施例中,一个或更多个pva可以设计和配置为加速用于高级驾驶员辅助系统(“adas”)1538、自动驾驶、增强现实(“ar”)应用程序和/或虚拟现实(“vr”)应用程序的计算机视觉算法。在至少一个实施例中,一个或更多个pva可以在性能和灵活性之间取得平衡。例如,在至少一个实施例中,一个或更多个pva中的每一个可以包括例如但不限于任何数量的精简指令集计算机(“risc”)核心、直接存储器访问(“dma”)和/或任意数量的向量处理器。
153.在至少一个实施例中,risc核心可以与图像传感器(例如,本文描述的任意相机的图像传感器)、图像信号处理器等交互。在至少一个实施例中,每个risc核心可以包括任意数量的存储器。在至少一个实施例中,根据实施例,risc核心可以使用多种协议中的任意一种。在至少一个实施例中,risc核心可以执行实时操作系统(“rtos”)。在至少一个实施例中,可以使用一个或更多个集成电路设备、专用集成电路(“asic”)和/或存储设备来实现risc核心。例如,在至少一个实施例中,risc核心可以包括指令高速缓存和/或紧密耦合的ram。
154.在至少一个实施例中,dma可以使pva的组件能够独立于一个或更多个cpu 1506访问系统存储器。在至少一个实施例中,dma可以支持用于向pva提供优化的任何数量的特征,包括但不限于,支持多维寻址和/或循环寻址。在至少一个实施例中,dma可以支持多达六个或更多个寻址的维度,其可以包括但不限于块宽度、块高度、块深度、水平块步进、垂直块步进和/或深度步进。
155.在至少一个实施例中,向量处理器可以是可编程处理器,其可以设计为有效且灵活地执行用于计算机视觉算法并提供信号处理能力的编程。在至少一个实施例中,pva可以包括pva核心和两个向量处理子系统分区。在至少一个实施例中,pva核心可以包括处理器子系统、dma引擎(例如,两个dma引擎)和/或其他外围设备。在至少一个实施例中,向量处理子系统可以用作pva的主要处理引擎,并且可以包括向量处理单元(“vpu”)、指令高速缓存和/或向量存储器(例如“vmem”)。在至少一个实施例中,vpu核心可以包括数字信号处理器,例如,单指令多数据(“simd”)、超长指令字(“vliw”)数字信号处理器。在至少一个实施例中,simd和vliw的组合可以提高吞吐量和速度。
156.在至少一个实施例中,每个向量处理器可以包括指令高速缓存并且可以耦合到专用存储器。结果,在至少一个实施例中,每个向量处理器可以配置为独立于其他向量处理器执行。在至少一个实施例中,特定pva中包括的向量处理器可以配置为采用数据并行性。例如,在至少一个实施例中,单个pva中包括的多个向量处理器可以执行相同计算机视觉算法,除了在图像的不同区域上之外。在至少一个实施例中,包括在特定pva中的向量处理器可以在相同图像上同时执行不同的计算机视觉算法,或者甚至在序列图像或部分图像上执行不同的算法。在至少一个实施例中,除其他外,在硬件加速集群中可以包括任何数量的
pva,并且在每个pva中可以包括任何数量的向量处理器。在至少一个实施例中,pva可以包括附加的纠错码(“ecc”)存储器,以增强整体系统安全性。
157.在至少一个实施例中,一个或更多个加速器1514(例如,硬件加速集群)可以包括片上计算机视觉网络和静态随机存取存储器(“sram”),用于为一个或更多个加速器1514提供高带宽,低延迟sram。在至少一个实施例中,片上存储器可以包括至少4mb sram,其包括例如但不限于八个现场可配置的内存块,pva和dla均可以对其进行访问。在至少一个实施例中,每对存储块可以包括高级外围总线(“apb”)接口、配置电路、控制器和多路复用器。在至少一个实施例中,可以使用任何类型的存储器。在至少一个实施例中,pva和dla可以经由为pva和dla提供对存储器的高速访问的主干网来访问存储器。在至少一个实施例中,主干网可以包括片上计算机视觉网络,其将pva和dla互连到存储器(例如,使用apb)。
158.在至少一个实施例中,片上计算机视觉网络可以包括接口,该接口在传输任何控制信号/地址/数据之前确定pva和dla均提供就绪和有效信号。在至少一个实施例中,接口可以提供用于发送控制信号/地址/数据的单独的相位和单独的信道,以及用于连续数据传输的突发型通信。在至少一个实施例中,尽管可以使用其他标准和协议,但是接口可以符合国际标准化组织(“iso”)26262或国际电工委员会(“iec”)61508标准。
159.在至少一个实施例中,一个或更多个soc 1504可以包括实时视线追踪硬件加速器。在至少一个实施例中,实时视线追踪硬件加速器可以用于快速且有效地确定对象的位置和范围(例如,在世界模型内),以生成实时可视化模拟,以用于radar信号解释,用于声音传播合成和/或分析,用于sonar系统的模拟,用于一般的波传播模拟,与用于定位和/或其他功能的lidar数据进行比较,和/或用于其他用途。
160.在至少一个实施例中,一个或更多个加速器1514(例如,硬件加速集群)具有用于自动驾驶的广泛用途。在至少一个实施例中,pva可以是可编程视觉加速器,其用于adas和自动驾驶汽车中的关键处理阶段。在至少一个实施例中,在低功耗和低延迟下pva的能力与需要可预测的处理的算法域良好匹配。换句话说,pva在半密集或密集的常规计算中表现出色,即使在小型数据集上也是如此,这些数据集可能需要具有低延迟和低功耗的可预测的运行时间。在至少一个实施例中,自主车辆,诸如在车辆1500中pva可能被设计为运行经典的计算机视觉算法,因为它们可以在对象检测和整数数学运算方面是有效的。
161.例如,根据技术的至少一个实施例,pva被用于执行计算机立体视觉。在至少一个实施例中,可以在一些示例中使用基于半全局匹配的算法,尽管这并不意味着限制性。在至少一个实施例中,用于3-5级自动驾驶的应用程序在运行中使用动态的估计/立体匹配(例如,从运动中恢复结构、行人识别、车道检测等)。在至少一个实施例中,pva可以对来自两个单目相机的输入执行计算机立体视觉功能。
162.在至少一个实施例中,pva可以用于执行密集的光流。例如,在至少一个实施例中,pva可以处理原始radar数据(例如,使用4d快速傅立叶变换)以提供处理后的radar数据。在至少一个实施例中,例如,通过处理原始飞行时间数据以提供处理后的飞行时间数据,将pva用于飞行时间深度处理。
163.在至少一个实施例中,dla可用于运行任何类型的网络以增强控制和驾驶安全性,包括例如但不限于神经网络,其输出用于每个对象检测的置信度。在至少一个实施例中,可以将置信度表示或解释为概率,或者表示为提供每个检测相对于其他检测的相对“权重”。
在至少一个实施例中,置信度使系统能够做出进一步的决定,即关于哪些检测应当被认为是真正的阳性检测而不是假阳性检测。在至少一个实施例中,系统可以为置信度设置阈值,并且仅将超过阈值的检测视为真阳性检测。在使用自动紧急制动(“aeb”)系统的实施例中,假阳性检测将导致车辆自动执行紧急制动,这显然是不希望的。在至少一个实施例中,高度自信的检测可以被认为是aeb的触发。在至少一个实施例中,dla可以运行用于回归置信度值的神经网络。在至少一个实施例中,神经网络可以将参数的至少一些子集作为其输入,例如包围盒尺寸,获得的地平面估计(例如,从另一子系统),与从神经网络和/或其他传感器(例如,一个或更多个lidar传感器1564或一个或更多个radar传感器1560)等获得的对象的车辆1500方向、距离、3d位置估计相关的一个或更多个imu传感器1566的输出。
164.在至少一个实施例中,一个或更多个soc 1504(例如,硬件加速集群)可以包括一个或更多个数据存储装置1516(例如,存储器)。在至少一个实施例中,一个或更多个数据存储1516可以是一个或更多个soc 1504的片上存储器,其可以存储要在一个或更多个gpu 1508和/或dla上执行的神经网络。在至少一个实施例中,一个或更多个数据存储1516可以具有足够大的容量以存储神经网络的多个实例以用于冗余和安全。在至少一个实施例中,一个或更多个数据存储1512可以包括l2或l3高速缓存。
165.在至少一个实施例中,一个或更多个soc 1504可以包括任何数量的处理器1510(例如,嵌入式处理器)。在至少一个实施例中,一个或更多个处理器1510可以包括启动和电源管理处理器,该启动和电源管理处理器可以是专用处理器和子系统,以处理启动电源和管理功能以及相关的安全实施。在至少一个实施例中,启动和电源管理处理器可以是一个或更多个soc 1504启动序列的一部分,并且可以提供运行时电源管理服务。在至少一个实施例中,启动功率和管理处理器可以提供时钟和电压编程,辅助系统低功率状态转换,一个或更多个soc 1504热和温度传感器管理和/或一个或更多个soc 1504功率状态管理。在至少一个实施例中,每个温度传感器可以实现为其输出频率与温度成比例的环形振荡器,并且一个或更多个soc 1504可以使用环形振荡器来检测一个或更多个cpu 1506,一个或更多个gpu 1508和/或一个或更多个加速器1514的温度。在至少一个实施例中,如果确定温度超过阈值,则启动和电源管理处理器可以进入温度故障例程,并将一个或更多个soc 1504置于较低功耗状态和/或将车辆1500置于司机的安全停车图案(例如,使车辆1500安全停车)。
166.在至少一个实施例中,一个或更多个处理器1510可以进一步包括一组嵌入式处理器,其可以用作音频处理引擎。在至少一个实施例中,音频处理引擎可以是音频子系统,其能够通过多个接口以及广泛且灵活范围的音频i/o接口为硬件提供对多通道音频的完全硬件支持。在至少一个实施例中,音频处理引擎是专用处理器核心,其具有带专用ram的数字信号处理器。
167.在至少一个实施例中,一个或更多个处理器1510可以进一步包括始终在线的处理器引擎。在至少一个实施例中,自动处理引擎可以提供必要的硬件特征以支持低功率传感器管理和唤醒用例。在至少一个实施例中,始终在线的处理器引擎上的处理器可以包括但不限于处理器核心、紧密耦合的ram、支持外围设备(例如,定时器和中断控制器)、各种i/o控制器外围设备以及路由逻辑。
168.在至少一个实施例中,一个或更多个处理器1510可以进一步包括安全集群引擎,该安全集群引擎包括但不限于用于处理汽车应用程序的安全管理的专用处理器子系统。在
至少一个实施例中,安全集群引擎可以包括但不限于两个或更多个处理器核心、紧密耦合的ram、支持外围设备(例如,定时器、中断控制器等)和/或路由逻辑。在安全模式下,在至少一个实施例中,两个或更多个核心可以以锁步模式操作,并且可以用作具有用以检测其操作之间的任何差异的比较逻辑的单个核心。在至少一个实施例中,一个或更多个处理器1510可以进一步包括实时相机引擎,该实时相机引擎可以包括但不限于用于处理实时相机管理的专用处理器子系统。在至少一个实施例中,一个或更多个处理器1510可以进一步包括高动态范围信号处理器,该高动态范围信号处理器可以包括但不限于图像信号处理器,该图像信号处理器是作为相机处理管线的一部分的硬件引擎。
169.在至少一个实施例中,一个或更多个处理器1510可以包括视频图像合成器,该视频图像合成器可以是处理块(例如,在微处理器上实现),该处理块实现视频回放应用程序产生最终的视频所需要的视频后处理功能,以产生用于播放器窗口的最终图像。在至少一个实施例中,视频图像合成器可以在一个或更多个广角相机1570、一个或更多个环绕相机1574和/或一个或更多个舱内监控相机传感器上执行透镜畸变校正。在至少一个实施例中,优选地,由在soc 1504的另一实例上运行的神经网络来监控舱室内监控相机传感器,该神经网络被配置为识别舱室事件并相应地做出响应。在至少一个实施例中,舱室内系统可以执行但不限于唇读以激活蜂窝服务和拨打电话、指示电子邮件、改变车辆的目的地、激活或改变车辆的信息娱乐系统和设置、或者提供语音激活的网上冲浪。在至少一个实施例中,当车辆以自主模式运行时,某些功能对于驾驶员是可用的,否则将其禁用。
170.在至少一个实施例中,视频图像合成器可以包括用于同时空间和时间降噪的增强的时间降噪。例如,在至少一个实施例中,在运动发生在视频中的情况下,降噪适当地对空间信息加权,从而减小由相邻帧提供的信息的权重。在至少一个实施例中,在图像或图像的一部分不包括运动的情况下,由视频图像合成器执行的时间降噪可以使用来自先前图像的信息来降低当前图像中的噪声。
171.在至少一个实施例中,视频图像合成器还可以配置为对输入的立体透镜帧执行立体校正。在至少一个实施例中,当使用操作系统桌面时,视频图像合成器还可以用于用户接口合成,并且不需要一个或更多个gpu 1508来连续渲染新表面。在至少一个实施例中,当对一个或更多个gpu 1508供电并使其活跃地进行3d渲染时,视频图像合成器可以被用于卸载一个或更多个gpu 1508以改善性能和响应性。
172.在至少一个实施例中,soc 1504中的一个或更多个soc可以进一步包括用于从相机接收视频和输入的移动工业处理器接口(“mipi”)相机串行接口、高速接口和/或可用于相机和相关像素输入功能的视频输入块。在至少一个实施例中,一个或更多个soc 1504可以进一步包括输入/输出控制器,该输入/输出控制器可以由软件控制并且可以被用于接收未提交给特定角色的i/o信号。
173.在至少一个实施例中,soc 1504中的一个或更多个soc可以进一步包括广泛的外围接口,以使得能够与外围设备、音频编码器/解码器(“编解码器”),电源管理和/或其他设备通信。一个或更多个soc 1504可用于处理来自(例如,通过千兆位多媒体串行链路和以太网连接)相机、传感器(例如,一个或更多个lidar传感器1564,一个或更多个radar传感器1560等,其可以通过以太网连接)的数据,来自总线1502的数据(例如,车辆1500的速度、方向盘位置等),来自一个或更多个gnss传感器1558的数据(例如,通过以太网总线或can总线
连接)等。在至少一个实施例中,soc 1504中的一个或更多个可以进一步包括专用高性能海量存储控制器,其可以包括它们自己的dma引擎,并且可以用于使一个或更多个cpu 1506摆脱常规数据管理任务。
174.在至少一个实施例中,一个或更多个soc 1504可以是具有灵活架构的端到端平台,其跨越自动化级别3-5级,从而提供利用并有效使用计算机视觉和adas技术来实现多样性和冗余的综合的功能安全架构,其提供了可提供灵活、可靠的驾驶软件堆栈以及深度学习工具的平台。在至少一个实施例中,一个或更多个soc 1504可以比常规系统更快、更可靠,并且甚至在能量效率和空间效率上也更高。例如,在至少一个实施例中,一个或更多个加速器1514当与一个或更多个cpu 1506、一个或更多个gpu 1508以及一个或更多个数据存储装置1516结合时,可以提供用于3-5级自动驾驶车辆的快速、有效的平台。
175.在至少一个实施例中,计算机视觉算法可以在cpu上执行,cpu可以使用高级编程语言(例如c编程语言)配置为在多种视觉数据上执行多种处理算法。然而,在至少一个实施例中,cpu通常不能满足许多计算机视觉应用程序的性能要求,例如与执行时间和功耗有关的性能要求。在至少一个实施例中,许多cpu不能实时执行复杂的对象检测算法,该算法被用于车载adas应用程序和实际3-5级自动驾驶车辆中。
176.本文所述的实施例允许同时和/或序列地执行多个神经网络,并且允许将结果结合在一起以实现3-5级自动驾驶功能。例如,在至少一个实施例中,在dla或离散gpu(例如,一个或更多个gpu 1520)上执行的cnn可包括文本和单词识别,从而允许超级计算机读取和理解交通标志,包括神经网络尚未被专门训练的标志。在至少一个实施例中,dla还可包括神经网络,该神经网络能够识别、解释并提供符号的语义理解,并将该语义理解传递给在cpu complex上运行的路径规划模块。
177.在至少一个实施例中,对于3、4或5级的驱动,可以同时运行多个神经网络。例如,在至少一个实施例中,由“警告标志包括:闪烁的灯指示结冰状况(caution:flashing lights indicate icy conditions)”连通电灯一起组成的警告标志可以由多个神经网络独立地或共同地解释。在至少一个实施例中,可以通过第一部署的神经网络(例如,已经训练的神经网络)将该标志本身识别为交通标志,可以通过第二部署的神经网络来解释文本“闪烁的灯指示结冰状况(flashing lights indicate icy conditions)”,其通知车辆的路径规划软件(最好在cpu complex上执行):当检测到闪烁的灯光时,就会存在结冰状况。在至少一个实施例中,可以通过在多个帧上操作第三部署的神经网络来识别闪烁的灯,向车辆的路径规划软件通知存在(或不存在)闪烁的灯。在至少一个实施例中,所有三个神经网络可以同时运行,例如在dla内和/或在一个或更多个gpu 1508上。
178.在至少一个实施例中,用于面部识别和车辆所有者识别的cnn可以使用来自相机传感器的数据来识别授权驾驶员和/或车辆1500的所有者的存在。在至少一个实施例中,当所有者接近驾驶员门并打开灯时,常开传感器处理器引擎可用于解锁车辆,并且,在安全模式下,当所有者离开该车辆时,可用于禁用该车辆。以此方式,一个或更多个soc 1504提供防止盗窃和/或劫车的保障。
179.在至少一个实施例中,用于紧急车辆检测和识别的cnn可以使用来自麦克风1596的数据来检测和识别紧急车辆警报器。在至少一个实施例中,一个或更多个soc 1504使用cnn来对环境和城市声音进行分类,以及对视觉数据进行分类。在至少一个实施例中,训练
在dla上运行的cnn以识别紧急车辆的相对接近速度(例如,通过使用多普勒效应)。在至少一个实施例中,还可以训练cnn来识别针对车辆正在运行的区域的紧急车辆,如一个或更多个gnss传感器1558所识别。在至少一个实施例中,当在欧洲运行时,cnn将寻求检测欧洲警报器,而在美国时,cnn将寻求仅识别北美警报器。在至少一个实施例中,一旦检测到紧急车辆,就可以在一个或更多个超声波传感器1562的辅助下使用控制程序来执行紧急车辆安全例程、减速车辆、将车辆驶至路边、停车、和/或使车辆闲置,直到紧急车辆通过。
180.在至少一个实施例中,车辆1500可以包括一个或更多个cpu 1518(例如,一个或更多个离散cpu或一个或更多个dcpu),其可以经由高速互连(例如pcie)耦合到一个或更多个soc 1504。在至少一个实施例中,一个或更多个cpu 1518可以包括x86处理器,例如一个或更多个cpu 1518可用于执行各种功能中的任何功能,例如包括在adas传感器和一个或更多个soc 1504之间潜在的仲裁不一致的结果,和/或一个或更多个监控控制器1536的状态和健康和/或片上信息系统(“信息soc”)1530。
181.在至少一个实施例中,车辆1500可以包括一个或更多个gpu 1520(例如,一个或更多个离散gpu或一个或更多个dgpu),其可以经由高速互连(例如nvidia的nvlink)耦合到一个或更多个soc 1504。在至少一个实施例中,一个或更多个gpu 1520可以提供附加的人工智能功能,例如通过执行冗余和/或不同的神经网络,并且可以至少部分地基于来自车辆1500的传感器的输入(例如,传感器数据)来用于训练和/或更新神经网络。
182.在至少一个实施例中,车辆1500可以进一步包括网络接口1524,其可以包括但不限于一个或更多个无线天线1526(例如,用于不同通信协议的一个或更多个无线天线1526,诸如蜂窝天线、蓝牙天线等)。在至少一个实施例中,网络接口1524可以用于使能通过具有云的互联网(例如,采用服务器和/或其他网络设备)与其他车辆和/或计算设备(例如乘客的客户端设备)的无线连接。在至少一个实施例中,为了与其他车辆通信,可以在车辆1500和其他车辆之间建立直接链路和/或可以建立间接链路(例如,通过网络和互联网)。在至少一个实施例中,可以使用车辆到车辆的通信链路来提供直接链路。在至少一个实施例中,车辆到车辆的通信链路可以向车辆1500提供关于车辆1500附近的车辆的信息(例如,车辆1500前面、侧面和/或后面的车辆)。在至少一个实施例中,该前述功能可以是车辆1500的协作自适应巡航控制功能的一部分。
183.在至少一个实施例中,网络接口1524可以包括soc,其提供调制和解调功能并使一个或更多个控制器1536能够通过无线网络进行通信。在至少一个实施例中,网络接口1524可以包括射频前端,用于从基带到射频的上转换以及从射频到基带的下转换。在至少一个实施例中,可以以任何技术上可行的方式执行频率转换。例如,可以通过公知的过程和/或使用超外差过程来执行频率转换。在至少一个实施例中,射频前端功能可以由单独的芯片提供。在至少一个实施例中,网络接口可以包括用于通过lte、wcdma、umts、gsm、cdma2000、蓝牙、蓝牙le、wi-fi、z-wave、zigbee、lorawan和/或其他无线协议进行通信的无线功能。
184.在至少一个实施例中,车辆1500可以进一步包括一个或更多个数据存储1528,其可以包括但不限于片外(例如,一个或更多个soc 1504)存储。在至少一个实施例中,一个或更多个数据存储1528可以包括但不限于一个或更多个存储元件,包括ram、sram、动态随机存取存储器(“dram”)、视频随机存取存储器(“vram”)、闪存、硬盘和/或其他组件和/或可以存储至少一位数据的设备。
185.在至少一个实施例中,车辆1500可以进一步包括一个或更多个gnss传感器1558(例如,gps和/或辅助gps传感器),以辅助地图绘制、感知、占用光栅生成和/或路径规划功能。在至少一个实施例中,可以使用任何数量的gnss传感器1558,包括例如但不限于使用具有以太网的usb连接器连接到串行接口(例如rs-232)桥的gps。
186.在至少一个实施例中,车辆1500可以进一步包括一个或更多个radar传感器1560。一个或更多个radar传感器1560可以由车辆1500用于远程车辆检测,即使在黑暗和/或恶劣天气条件下。在至少一个实施例中,radar功能安全等级可以是asil b。一个或更多个radar传感器1560可以使用can总线和/或总线1502(例如,以传输由一个或更多个radar传感器1560生成的数据)来进行控制和访问对象跟踪数据,在某些示例中可以访问以太网通道以访问原始数据。在至少一个实施例中,可以使用各种各样的radar传感器类型。例如但不限于,radar传感器1560中的一个或更多个传感器可适合于前、后和侧面radar使用。在至少一个实施例中,一个或更多个radar传感器1560是脉冲多普勒radar传感器。
187.在至少一个实施例中,一个或更多个radar传感器1560可以包括不同的配置,例如具有窄视野的远程、具有宽事业的近程、近程侧面覆盖等。在至少一个实施例中,远程radar可以用于自适应巡航控制功能。在至少一个实施例中,远程radar系统可以提供通过两次或更多次独立扫描(例如在250m范围内)实现的宽广的视野。在至少一个实施例中,一个或更多个radar传感器1560可以帮助在静态对象和运动对象之间区分,并且可以被adas系统1538用于紧急制动辅助和向前碰撞警告。在至少一个实施例中,包括在远程radar系统中的一个或更多个传感器1560可以包括但不限于具有多个(例如六个或更多个)固定radar天线以及高速can和flexray接口的单基地多模式radar。在至少一个实施例中,具有六个天线、中央四个天线可以创建聚焦的波束图,该波束图设计为以较高的速度记录车辆1500的周围环境,而相邻车道的交通干扰最小。在至少一个实施例中,其他两个天线可以扩大视野,从而可以快速检测进入或离开车辆1500的车道。
188.在至少一个实施例中,作为示例,中程radar系统可包括例如高达160m(前)或80m(后)的范围,以及高达42度(前)或150度(后)的视野。在至少一个实施例中,短程radar系统可以包括但不限于设计成安装在后保险杠的两端的任意数量的radar传感器1560。当安装在后保险杠的两端时,在至少一个实施例中,radar传感器系统可以产生两个光束,该两个光束不断地监测车辆后部和附近的盲点。在至少一个实施例中,短程radar系统可以在adas系统1538中用于盲点检测和/或车道改变辅助。
189.在至少一个实施例中,车辆1500可以进一步包括一个或更多个超声传感器1562。在至少一个实施例中,可以定位在车辆1500的前、后和/或侧面的一个或更多个超声传感器1562可以用于停车辅助和/或创建和更新占用光栅。在至少一个实施例中,可以使用各种各样的超声传感器1562,并且可以将不同的超声传感器1562用于不同的检测范围(例如2.5m、4m)。在至少一个实施例中,超声传感器1562可以在asil b的功能安全等级下操作。
190.在至少一个实施例中,车辆1500可以包括一个或更多个lidar传感器1564。一个或更多个lidar传感器1564可以用于对象和行人检测、紧急制动、避免碰撞和/或其他功能。在至少一个实施例中,一个或更多个lidar传感器1564可以是功能安全等级asil b。在至少一个实施例中,车辆1500可以包括可以使用以太网的多个(例如,两个、四个、六个等)lidar传感器1564(例如,将数据提供给千兆以太网交换机)。
191.在至少一个实施例中,一个或更多个lidar传感器1564可能能够提供针对360度视野的对象及其距离的列表。在至少一个实施例中,市售的一个或更多个lidar传感器1564例如可以具有大约100m的广告范围,具有2cm-3cm的精度,并且支持100mbps的以太网连接。在至少一个实施例中,可以使用一个或更多个非突出的lidar传感器1564。在这样的实施例中,一个或更多个lidar传感器1564可以作为嵌入到车辆1500的前、后、侧面和/或拐角中的小型设备实施。在至少一个实施例中,一个或更多个lidar传感器1564,在这样的实施例中,即使对于低反射率的对象,也可以提供高达120度的水平视野和35度的垂直视野,并且具有200m的范围。在至少一个实施例中,可将前向一个或更多个lidar传感器1564配置为用于45度至135度之间的水平视野。
192.在至少一个实施例中,也可以使用lidar技术(诸如3d闪光lidar)。3d闪光lidar使用激光闪光作为传输源,以照亮车辆1500周围大约200m。在至少一个实施例中,闪光lidar单元包括但不限于接收器,该接收器记录激光脉冲传播时间和每个像素上的反射光,该像素又对应于从车辆1500到对象的范围。在至少一个实施例中,闪光lidar可以允许利用每个激光闪光生成周围环境的高度准确且无失真的图像。在至少一个实施例中,可以部署四个闪光lidar传感器,在车辆1500的每一侧部署一个传感器。在至少一个实施例中,3d闪光lidar系统包括但不限于除了风扇(例如非扫描lidar设备)以外没有移动部件的固态3d视线阵列lidar相机。在至少一个实施例中,闪光lidar设备可以每帧使用5纳秒的i类(人眼安全)激光脉冲,并且可以捕获反射激光,以3d测距点云的形式和共同登记的强度数据。
193.在至少一个实施例中,车辆还可包括一个或更多个imu传感器1566。在至少一个实施例中,一个或更多个imu传感器1566可位于车辆1500的后轴中心。在至少一个实施例中,一个或更多个imu传感器1566可以包括,例如但不限于,一个或更多个加速度计、一个或更多个磁力计、一个或更多个陀螺仪、一个或更多个磁罗盘和/或其他传感器类型。在至少一个实施例中,例如在六轴应用程序中,一个或更多个imu传感器1566可以包括但不限于加速度计和陀螺仪。在至少一个实施例中,例如在九轴应用程序中,一个或更多个imu传感器1566可以包括但不限于加速度计、陀螺仪和磁力计。
194.在至少一个实施例中,一个或更多个imu传感器1566可以实现为结合了微机电系统(“mems”)惯性传感器,高灵敏度gps接收器和先进的卡尔曼滤波算法的微型高性能gps辅助惯性导航系统(“gps/ins”),以提供位置、速度和姿态的估算;在至少一个实施例中,一个或更多个imu传感器1566可使车辆1500估算航向而无需来自磁传感器通过直接观测和关联从gps到一个或更多个imu传感器1566的速度变化来实现的输入。在至少一个实施例中,一个或更多个imu传感器1566和一个或更多个gnss传感器1558可以组合在单个集成单元中。
195.在至少一个实施例中,车辆1500可以包括放置在车辆1500内和/或周围的一个或更多个麦克风1596。在至少一个实施例中,此外,一个或更多个麦克风1596可以用于紧急车辆检测和识别。
196.在至少一个实施例中,车辆1500可以进一步包括任何数量的相机类型,包括一个或更多个立体相机1568、一个或更多个广角相机1570、一个或更多个红外相机1572、一个或更多个环绕相机1574、一个或更多个远程相机1598、一个或更多个中程相机1576和/或其他相机类型。在至少一个实施例中,相机可用于捕获车辆1500的整个外围周围的图像数据。在至少一个实施例中,所使用的相机的类型取决于车辆1500。在至少一个实施例中,相机类型
的任何组合可以是用于在车辆1500周围提供必要覆盖范围。在至少一个实施例中,部署的相机的数量可以根据实施例而不同。例如,在至少一个实施例中,车辆1500可以包括六个相机、七个相机、十个相机、十二个相机或其他数量的相机。在至少一个实施例中,相机可以作为示例但不限于支持千兆位多媒体串行链路(“gmsl”)和/或千兆位以太网。在至少一个实施例中,本文先前参照图15a和图15b可以更详细地描述了每个相机。
197.在至少一个实施例中,车辆1500可以进一步包括一个或更多个振动传感器1542。在至少一个实施例中,一个或更多个振动传感器1542可以测量车辆1500的部件(例如,轴)的振动。例如,在至少一个实施例中,振动的变化可以指示路面的变化。在至少一个实施例中,当使用两个或更多个振动传感器1542时,振动之间的差异可以用于确定路面的摩擦或打滑(例如,当在动力驱动轴和自由旋转轴之间存在振动差异时)。
198.在至少一个实施例中,车辆1500可以包括adas系统1538。adas系统1538可以包括但不限于soc。在至少一个实施例中,adas系统1538可以包括但不限于任何数量的自主/自适应/自动巡航控制(“acc”)系统、协作自适应巡航控制(“cacc”)系统、前撞警告(“fcw”)系统、自动紧急制动(“aeb”)系统、车道偏离警告(“ldw”)系统、车道保持辅助(“lka”)系统、盲区警告(“bsw”)系统、后方交叉交通警告(“rctw”)系统、碰撞警告(“cw”)系统、车道对中(“lc”)系统和/或其他系统、特征和/或功能及其组合。
199.在至少一个实施例中,acc系统可以使用一个或更多个radar传感器1560、一个或更多个lidar传感器1564和/或任何数量的相机。在至少一个实施例中,acc系统可以包括纵向acc系统和/或横向acc系统。在至少一个实施例中,纵向acc系统监控并控制到紧邻车辆1500的前面车辆的距离,并自动调节车辆1500的速度以保持与前方车辆的安全距离。在至少一个实施例中,横向acc系统执行距离保持,并在需要时建议车辆1500改变车道。在至少一个实施例中,横向acc与其他adas应用程序有关,例如lc和cw。
200.在至少一个实施例中,cacc系统使用来自其他车辆的信息,该信息可以经由网络接口1524和/或一个或更多个无线天线1526从其他车辆接收经由无线链路或者间接经由网络连接(例如,经由互联网)接收。在至少一个实施例中,直接链路可以由车辆到车辆(“v2v”)的通信链路提供,而间接链路可以由基础设施到车辆(“i2v”)的通信链路提供。通常,v2v通信概念提供关于紧接在前的车辆(例如,紧接在车辆1500之前并与之在同一车道上的车辆)的信息,而i2v通信概念提供关于更前方交通的信息。在至少一个实施例中,cacc系统可以包括i2v和v2v信息源之一或两者。在至少一个实施例中,在给定车辆1500之前的车辆的信息的情况下,cacc系统可以更可靠,并且具有改善交通流的平滑度并减少道路拥堵的潜力。
201.在至少一个实施例中,fcw系统被设计成警告驾驶员危险,以便该驾驶员可以采取纠正措施。在至少一个实施例中,fcw系统使用前向相机和/或一个或更多个radar传感器1560,其耦合至专用处理器、dsp、fpga和/或asic,其电耦合至驾驶员反馈,例如显示器、扬声器和/或振动组件。在至少一个实施例中,fcw系统可以提供警告,例如以声音、视觉警告,振动和/或快速制动脉冲的形式。
202.在至少一个实施例中,aeb系统检测到与另一车辆或其他对象的即将发生的向前碰撞,并且如果驾驶员在指定的时间或距离参数内未采取纠正措施,则可以自动施加制动。在至少一个实施例中,aeb系统可以使用耦合到专用处理器、dsp、fpga和/或asic的一个或
更多个前向相机和/或一个或更多个radar传感器1560。在至少一个实施例中,当aeb系统检测到危险时,aeb系统通常首先警告驾驶员采取纠正措施以避免碰撞,并且,如果该驾驶员没有采取纠正措施,则该aeb系统可以自动施加制动器以试图防止或至少减轻预测碰撞的影响。在至少一个实施例中,aeb系统可以包括诸如动态制动器支持和/或即将发生碰撞的制动的技术。
203.在至少一个实施例中,当车辆1500越过车道标记时,ldw系统提供视觉、听觉和/或触觉警告,例如方向盘或座椅振动,以警告驾驶员。在至少一个实施例中,当驾驶员诸如通过激活转向信号灯指示有意的车道偏离时,ldw系统不活跃。在至少一个实施例中,ldw系统可以使用耦合到专用处理器、dsp、fpga和/或asic的面向正面的相机,其被电耦合至诸如显示器、扬声器和/或振动组件之类的驾驶员反馈。在至少一个实施例中,lka系统是ldw系统的一种变型。如果车辆1500开始离开车道,则lka系统提供转向输入或制动以校正车辆1500。
204.在至少一个实施例中,bsw系统检测并警告汽车盲区中的车辆驾驶员。在至少一个实施例中,bsw系统可以提供视觉、听觉和/或触觉警报,以指示合并或改变车道是不安全的。在至少一个实施例中,当驾驶员使用转向灯时,bsw系统可以提供附加警告。在至少一个实施例中,bsw系统可以使用耦合到专用处理器、dsp、fpga和/或asic的一个或更多个朝后侧的相机和/或一个或更多个radar传感器1560,其电耦合到驾驶员反馈,例如显示器、扬声器和/或振动组件。
205.在至少一个实施例中,当在车辆1500倒车时在后相机范围之外检测到对象时,rctw系统可以提供视觉、听觉和/或触觉通知。在至少一个实施例中,rctw系统包括aeb系统,以确保应用程序车辆制动器以避免碰撞。在至少一个实施例中,rctw系统可以使用一个或更多个面向后方的radar传感器1560,其耦合到专用处理器、dsp、fpga和/或asic,其被电耦合至诸如显示器、扬声器和/或振动组件之类的驾驶员反馈。
206.在至少一个实施例中,常规的adas系统可能易于产生误报结果,这可能使驾驶员烦恼和分散注意力,但通常不是灾难性的,因为常规的adas系统会警告驾驶员并允许该驾驶员决定安全状况是否真正存在并采取相应动作。在至少一个实施例中,在结果冲突的情况下,车辆1500本身决定是否听从主计算机或副计算机(例如,第一控制器1536或第二控制器1536)的结果。例如,在至少一个实施例中,adas系统1538可以是用于将感知信息提供给备份计算机合理性模块的备用和/或辅助计算机。在至少一个实施例中,备用计算机合理性监控器可以在硬件组件上运行冗余的各种软件,以检测感知和动态驾驶任务中的故障。在至少一个实施例中,可以将来自adas系统1538的输出提供给监控mcu。在至少一个实施例中,如果来自主计算机和辅助计算机冲突的输出,则监督mcu决定如何协调冲突以确保安全操作。
207.在至少一个实施例中,主计算机可以配置为向监督mcu提供置信度分数,以指示该主计算机对所选结果的置信度。在至少一个实施例中,如果该置信度得分超过阈值,则该监督mcu可以遵循该主计算机的指示,而不管该辅助计算机是否提供冲突或不一致的结果。在至少一个实施例中,在置信度得分不满足阈值的情况下,并且在主计算机和辅助计算机指示不同的结果(例如,冲突)的情况下,监督mcu可以在计算机之间仲裁以确定适当的结果。
208.在至少一个实施例中,监督mcu可以配置为运行神经网络,该神经网络被训练和配
置为至少部分地基于来自主计算机和辅助计算机的输出来确定该辅助计算机提供错误警报的条件。在至少一个实施例中,监督mcu中的神经网络可以学习何时可以信任辅助计算机的输出,以及何时不能信任。例如,在至少一个实施例中,当该辅助计算机是基于radar的fcw系统时,该监督mcu中的神经网络可以学习fcw系统何时识别实际上不是危险的金属对象,例如会触发警报的排水格栅或井盖。在至少一个实施例中,当辅助计算机是基于相机的ldw系统时,当存在骑自行车的人或行人并且实际上车道偏离是最安全的操作时,监督mcu中的神经网络可以学会覆盖ldw。在至少一个实施例中,监督mcu可以包括适合于运行具有相关联的存储器的神经网络的dla或gpu中的至少一个。在至少一个实施例中,监督mcu可以包括和/或被包括为一个或更多个soc 1504的组件。
209.在至少一个实施例中,adas系统1538可以包括使用传统的计算机视觉规则执行adas功能的辅助计算机。在至少一个实施例中,该辅助计算机可以使用经典计算机视觉规则(如果-则),并且监督mcu中的神经网络的存在可以提高可靠性、安全性和性能。例如,在至少一个实施例中,多样化的实现方式和有意的非同一性使得整个系统更加容错,尤其是对于由软件(或软件-硬件接口)功能引起的故障。例如,在至少一个实施例中,如果在主计算机上运行的软件中存在软件漏洞或错误,并且在辅助计算机上运行的不相同的软件代码提供了相同的总体结果,则监督mcu可以更有把握地认为总体结果是正确,并且该主计算机上的软件或硬件中的漏洞不会导致重大错误。
210.在至少一个实施例中,可以将adas系统1538的输出输入到主计算机的感知模块和/或主计算机的动态驾驶任务模块中。例如,在至少一个实施例中,如果adas系统1538由于正前方的对象而指示向前碰撞警告,则感知块可以在识别对象时使用该信息。在至少一个实施例中,如本文所述,辅助计算机可以具有其自己的神经网络,该神经网络经过训练从而降低了误报的风险。
211.在至少一个实施例中,车辆1500可以进一步包括信息娱乐soc 1530(例如,车载信息娱乐系统(ivi))。尽管被示出和描述为soc,但是在至少一个实施例中,信息娱乐系统1530可以不是soc,并且可以包括但不限于两个或更多个分立组件。在至少一个实施例中,信息娱乐soc 1530可以包括但不限于硬件和软件的组合,其可以用于提供音频(例如,音乐、个人数字助理、导航指令、新闻、广播等)、视频(例如,电视、电影、流媒体等)、电话(例如,免提通话)、网络连接(例如,lte、wifi等)和/或信息服务(例如,导航系统、后停车辅助、无线电数据系统、与车辆相关的信息,例如燃油水平、总覆盖距离、制动燃油水平、油位、车门打开/关闭、空气滤清器信息等)到车辆1500。例如,信息娱乐soc 1530可以包括收音机、磁盘播放器、导航系统、视频播放器、usb和蓝牙连接、汽车、车载娱乐系统、wifi、方向盘音频控制、免提语音控制、抬头显示器(“hud”)、hmi显示器1534、远程信息处理设备、控制面板(例如,用于控制各种组件、特征和/或系统和/或与之交互)和/或其他组件。在至少一个实施例中,信息娱乐soc 1530可以进一步用于向车辆的用户提供信息(例如,视觉和/或听觉的),诸如来自adas系统1538的信息、自动驾驶信息(诸如计划的车辆操纵)、轨迹、周围环境信息(例如,交叉路口信息、车辆信息、道路信息等)和/或其他信息。
212.在至少一个实施例中,信息娱乐soc 1530可以包括任何数量和类型的gpu功能。在至少一个实施例中,信息娱乐soc 1530可以通过总线1502(例如,can总线、以太网等)与车辆1500的其他设备、系统和/或组件通信。在至少一个实施例中,信息娱乐soc 1530可以是
耦合到监控mcu,使得信息娱乐系统的gpu可以在主控制器1536(例如,车辆1500的主计算机和/或备用计算机)发生故障的情况下执行一些自动驾驶功能。在至少一个实施例中,信息娱乐soc 1530可以使车辆1500进入司机到安全停止模式,如本文所述。
213.在至少一个实施例中,车辆1500可以进一步包括仪表板1532(例如,数字仪表板、电子仪表板、数字仪表操纵板等)。在至少一个实施例中,仪表板1532可以包括但不限于控制器和/或超级计算机(例如,离散控制器或超级计算机)。在至少一个实施例中,仪表板1532可以包括但不限于一组仪表的任何数量和组合,例如车速表、燃料水平、油压、转速表、里程表、转弯指示器、换档位置指示器、一个或更多个安全带警告灯、一个或更多个驻车制动警告灯、一个或更多个发动机故障灯、辅助约束系统(例如安全气囊)信息、照明控件、安全系统控件、导航信息等。在某些示例中,信息可能是在信息娱乐soc 1530和仪表板1532之间显示和/或共享。在至少一个实施例中,仪表板1532可以被包括作为信息娱乐soc 1530的一部分,反之亦然。
214.在至少一个实施例中,车辆1500可以包括使用具有多种加速器的多处理的计算机系统。例如,在至少一个实施例中,车辆1500内的计算机系统可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,车辆1500内的计算机系统可以实现如上所述的api,使得操作车辆1500的应用程序可以以简单的方式有效地使用加速器资源。
215.图15d是根据至少一个实施例的在基于云的服务器与图15a的自动驾驶车辆1500之间进行通信的系统1576的图。在至少一个实施例中,系统1576可以包括但不限于一个或更多个服务器1578、一个或更多个网络1590以及任何数量和类型的车辆,包括车辆1500。一个或更多个服务器1578可以包括但不限于,多个gpu 1584(a)-1584(h)(在本文中统称为gpu 1584)、pcie交换机1582(a)-1582(d)(在本文中统称为pcie交换机1582),和/或cpu 1580(a)-1580(b)(在本文中统称为cpu 1580)、gpu 1584、cpu 1580和pcie交换机1582可以与高速连接线互连,例如但不限于,由nvidia开发的nvlink接口1588和/或pcie连接1586。gpu 1584通过nvlink和/或nvswitchsoc连接,gpu 1584和pcie交换机1582通过pcie互连连接。在至少一个实施例中,尽管示出了八个gpu 1584、两个cpu 1580和四个pcie交换机1582,但这并不旨在进行限制。在至少一个实施例中,一个或更多个服务器1578中的每一个可以包括但不限于任意数量的gpu 1584、cpu 1580和/或pcie交换机1582的任何组合。例如,在至少一个实施例中,一个或更多个服务器1578可各自包括八个、十六个、三十二个和/或更多个gpu 1584。
216.在至少一个实施例中,一个或更多个服务器1578可以通过一个或更多个网络1590并从车辆接收表示图像的图像数据,该图像示出了意外的或改变的道路状况,例如最近开始的道路工程。在至少一个实施例中,一个或更多个服务器1578可以通过一个或更多个网络1590并且向车辆传输神经网络1592,更新的神经网络1592,和/或地图信息1594,包括但不限于关于交通和道路状况的信息。在至少一个实施例中,对地图信息1594的更新可以包括但不限于对hd地图1522的更新,例如关于建筑工地、坑洼、便道、洪水和/或其他障碍物的信息。在至少一个实施例中,神经网络1592,更新的神经网络1592和/或地图信息1594可能是由从环境中的任何数量的车辆接收的数据中表示的新训练和/或经验产生的,和/或至少基于在数据中心执行的训练(例如,使用一个或更多个服务器1578和/或其他服务器)。
217.在至少一个实施例中,一个或更多个服务器1578可以用于至少部分地基于训练数据来训练机器学习模型(例如,神经网络)。在至少一个实施例中,训练数据可以由车辆产生,和/或可以在模拟中产生(例如,使用游戏引擎)。在至少一个实施例中,标记任何数量的训练数据(例如,在相关的神经网络受益于监督学习的情况下)和/或经历其他预处理。在至少一个实施例中,没有对任何数量的训练数据进行标记和/或预处理(例如,在相关联的神经网络不需要监督学习的情况下)。在至少一个实施例中,一旦机器学习模型被训练,机器学习模型就可以被车辆使用(例如,通过一个或更多个网络1590传输到车辆,和/或机器学习模型可以被一个或更多个服务器1578使用以远程监控车辆。
218.在至少一个实施例中,一个或更多个服务器1578可以从车辆接收数据并且将数据应用程序于最新的实时神经网络以用于实时智能推理。在至少一个实施例中,一个或更多个服务器1578可以包括由一个或更多个gpu 1584供电的深度学习超级计算机和/或专用ai计算机,例如由nvidia开发的dgx和dgx station机器。然而,在至少一个实施例中,一个或更多个服务器1578可以包括使用cpu供电的数据中心的深度学习基础设施。
219.在至少一个实施例中,一个或更多个服务器1578的深度学习基础结构可能能够进行快速、实时的推理,并且可以使用该能力来评估和验证车辆1500中处理器、软件和/或相关硬件的健康。例如,在至少一个实施例中,深度学习基础设施可以从车辆1500接收周期性更新,例如车辆1500在该图像序列中所定位的图像序列和/或对象(例如,通过计算机视觉和/或其他机器学习对象分类技术)。在至少一个实施例中,深度学习基础设施可以运行其自己的神经网络以识别对象并将它们与车辆1500所识别的对象进行比较,并且,如果结果不匹配和深度学习基础设施断定车辆1500中的ai正在发生故障,则一个或更多个服务器1578可以将信号发送到车辆1500,以指示车辆1500的故障安全计算机采取控制、通知乘客并完成安全停车操作。
220.在至少一个实施例中,一个或更多个服务器1578可以包括一个或更多个gpu 1584和一个或更多个可编程推理加速器(例如nvidia的tensorrt 3)。在至少一个实施例中,gpu驱动的服务器和推理加速的组合可以使实时响应成为可能。在至少一个实施例中,例如在性能不太关键的情况下,可以将由cpu、fpga和其他处理器驱动的服务器用于推理。
221.在至少一个实施例中,硬件结构1415用于执行一个或更多个实施例。本文结合图14a和/或图14b提供关于硬件结构1415的细节。
222.计算机系统
223.图16是示出根据至少一个实施例示例性计算机系统的框图,该示例性计算机系统可以是具有互连的设备和组件的系统,片上系统(soc)或它们的某种形成有处理器的组合,该处理器可以包括执行单元以执行指令。在至少一个实施例中,根据本公开,例如本文所述的实施例,计算机系统1600可以包括但不限于组件,例如处理器1602,其执行单元包括逻辑以执行用于过程数据的算法。在至少一个实施例中,计算机系统1600可以包括处理器,例如可从加利福尼亚圣塔克拉拉的英特尔公司(intel corporation of santa clara,california)获得的处理器家族、xeontm、xscaletm和/或strongarmtm,core
tm
或nervana
tm
微处理器,尽管也可以使用其他系统(包括具有其他微处理器的pc、工程工作站、机顶盒等)。在至少一个实施例中,计算机系统1600可以执行可从华盛顿州雷蒙德市的微软公司(microsoft corporation of redmond,wash.)
1616可以提供到存储器1620的高带宽存储器路径1618以用于指令和数据存储以及用于图形命令、数据和纹理的存储。在至少一个实施例中,mch 1616可以在处理器1602、存储器1620和计算机系统1600中的其他组件之间启动数据信号,并且在处理器总线1610、存储器1620和系统i/o 1622之间桥接数据信号。在至少一个实施例中,系统逻辑芯片可以提供用于耦合到图形控制器的图形端口。在至少一个实施例中,mch 1616可以通过高带宽存储器路径1618耦合到存储器1620,并且图形/视频卡1612可以通过加速图形端口(accelerated graphics port)(“agp”)互连1614耦合到mch 1616。
230.在至少一个实施例中,计算机系统1600可以使用系统i/o 1622其为专有集线器接口总线来将mch 1616耦合到i/o控制器集线器(“ich”)1630。在至少一个实施例中,ich 1630可以通过本地i/o总线提供与某些i/o设备的直接连接。在至少一个实施例中,本地i/o总线可以包括但不限于用于将外围设备连接到存储器1620、芯片组和处理器1602的高速i/o总线。示例可以包括但不限于音频控制器1629、固件集线器(“flash bios”)1628、无线收发器1626、数据存储1624、包含用户输入和键盘接口的传统i/o控制器1623、串行扩展端口1627(例如通用串行总线(usb))和网络控制器1634。在至少一个实施例中,数据存储1624可以包括硬盘驱动器、软盘驱动器、cd-rom设备、闪存设备或其他大容量存储设备。
231.在至少一个实施例中,图16示出了包括互连的硬件设备或“芯片”的系统,而在其他实施例中,图16可以示出片上系统(soc)。在至少一个实施例中,图16中示出的设备可以与专有互连、标准化互连(例如,pcie)或其某种组合互连。在至少一个实施例中,系统1600的一个或更多个组件使用计算快速链路(cxl)互连来互连。
232.在至少一个实施例中,计算机系统1600可以使用具有多种加速器的多处理。在至少一个实施例中,例如,计算机系统1600可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,计算机系统1600可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速器资源。
233.图17是示出根据至少一个实施例的用于利用处理器1710的电子设备1700的框图。在至少一个实施例中,电子设备1700可以是例如但不限于,笔记本电脑、塔式服务器、机架服务器、刀片服务器、膝上型计算机、台式机、平板电脑、移动设备、电话、嵌入式计算机或任何其他合适的电子设备。
234.在至少一个实施例中,系统1700可以包括但不限于通信地耦合到任何合适数量或种类的组件、外围设备、模块或设备的处理器1710。在至少一个实施例中,处理器1710使用总线或接口耦合,诸如i℃总线、系统管理总线(“smbus”)、低引脚计数(lpc)总线、串行外围接口(“spi”)、高清音频(“hda”)总线、串行高级技术附件(“sata”)总线、通用串行总线(“usb”)(1、2、3版等)或通用异步接收器/发送器(“uart”)总线。在至少一个实施例中,图17示出了系统,该系统包括互连的硬件设备或“芯片”,而在其他实施例中,图17可以示出示例性片上系统(soc)。在至少一个实施例中,图17中所示的设备可以与专有互连线、标准化互连(例如,pcie)或其某种组合互连。在至少一个实施例中,图17的一个或更多个组件使用计算快速链路(cxl)互连线来互连。
235.在至少一个实施例中,图17可以包括显示器1724、触摸屏1725、触摸板1730、近场通信单元(“nfc”)1745、传感器集线器1740、热传感器1746、快速芯片组(“ec”)1735、可信平台模块(“tpm”)1738、bios/固件/闪存(“bios,fw flash”)1722、dsp 1760、驱动器“ssd或
hdd”1720(例如固态磁盘(“ssd”)或硬盘驱动器(“hdd”))、无线局域网单元(“wlan”)1750、蓝牙单元1752、无线广域网单元(“wwan”)1756、全球定位系统(gps)1755、相机(“usb 3.0相机”)1754(例如usb 3.0相机)或以例如lpddr3标准实现的低功耗双倍数据速率(“lpddr”)存储器单元(“lpddr3”)1715。这些组件可以各自以任何合适的方式实现。
236.在至少一个实施例中,其他组件可以通过如上所述的组件通信地耦合到处理器1710。在至少一个实施例中,加速度计1741、环境光传感器(“als”)1742、罗盘1743和陀螺仪1744可以可通信地耦合到传感器集线器1740。在至少一个实施例中,热传感器1739、风扇1737、键盘1746和触摸板1730可以通信地耦合到ec 1735。在至少一个实施例中,扬声器1763、耳机1764和麦克风(“mic”)1765可以通信地耦合到音频单元(“音频编解码器和d类放大器”)1764,其又可以通信地耦合到dsp 1760。在至少一个实施例中,音频单元1764可以包括例如但不限于音频编码器/解码器(“编解码器”)和d类放大器。在至少一个实施例中,sim卡(“sim”)1757可以通信地耦合到wwan单元1756。在至少一个实施例中,组件(诸如wlan单元1750和蓝牙单元1752以及wwan单元1756)可以被实现为下一代形式因素(ngff)。
237.在至少一个实施例中,电子设备1700可以使用具有多种加速器的多处理。在至少一个实施例中,例如,电子设备1700可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,电子设备1700可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速器资源。
238.图18示出了根据至少一个实施例的计算机系统1800。在至少一个实施例中,计算机系统1800配置为实现贯穿本公开描述的各种过程和方法。
239.在至少一个实施例中,计算机系统1800包括但不限于至少一个中央处理单元(“cpu”)1802,该中央处理单元(“cpu”)1802连接到使用任何合适协议实现的通信总线1810,诸如pci(“外围设备互联”)、外围组件互连express(“pci-express”)、agp(“加速图形端口”)、超传输或任何其他总线或点对点通信协议。在至少一个实施例中,计算机系统1800包括但不限于主存储器1804和控制逻辑(例如,实现为硬件、软件或其组合),并且数据可以采取随机存取存储器(“ram”)的形式存储在主存储器1804中。在至少一个实施例中,网络接口子系统(“网络接口”)1822提供到其他计算设备和网络的接口,用于从计算机系统1800接收数据并将数据传输到其他系统。
240.在至少一个实施例中,计算机系统1800在至少一个实施例中包括但不限于输入设备1808、并行处理系统1812和显示设备1806,它们可以使用常规的阴极视线管(“crt”)、液晶显示器(“lcd”)、发光二极管(“led”)、等离子显示器或其他合适的显示技术实现。在至少一个实施例中,从输入设备1808(诸如键盘、鼠标、触摸板、麦克风等)接收用户输入。在至少一个实施例中,前述模块中的每一个可以位于单个半导体平台上以形成处理系统。
241.在至少一个实施例中,计算机系统1800可以使用具有多种加速器的多处理。在至少一个实施例中,例如,计算机系统1800可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,计算机系统1800可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速器资源。
242.图19示出了根据至少一个实施例的计算机系统1900。在至少一个实施例中,计算机系统1900包括但不限于计算机1910和usb棒1920。在至少一个实施例中,计算机1910可以包括但不限于任何数量和类型的处理器(未示出)和存储器(未示出)。在至少一个实施例
中,计算机1910包括但不限于服务器、云实例、膝上型计算机和台式计算机。
243.在至少一个实施例中,usb棒1920包括但不限于处理单元1930、usb接口1940和usb接口逻辑1950。在至少一个实施例中,处理单元1930可以是任何指令执行系统、装置或能够执行指令的设备。在至少一个实施例中,处理单元1930可以包括但不限于任何数量和类型的处理核心(未示出)。在至少一个实施例中,处理核心1930包括专用集成电路(“asic”),该专用集成电路被优化为执行与机器学习相关联的任何数量和类型的操作。例如,在至少一个实施例中,处理核心1930是张量处理单元(“tpc”),其被优化以执行机器学习推理操作。在至少一个实施例中,处理核心1930是视觉处理单元(“vpu”),其被优化以执行机器视觉和机器学习推理操作。
244.在至少一个实施例中,usb接口1940可以是任何类型的usb连接器或usb插座。例如,在至少一个实施例中,usb接口1940是用于数据和电源的usb 3.0type-c插座。在至少一个实施例中,usb接口1940是usb 3.0type-a连接器。在至少一个实施例中,usb接口逻辑1950可以包括使处理单元1930能够经由usb连接器1940与设备(例如计算机1910)相连接的任何数量和类型的逻辑。
245.在至少一个实施例中,计算机系统1900可以使用具有多种加速器的多处理。在至少一个实施例中,例如,计算机系统1900可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,计算机系统1900可以实现如上所述的api,从而应用程序可以以简单的方式有效地使用加速器资源。
246.图20a示出了示例性架构,其中多个gpu 2010-2013通过高速链路2040-2043(例如,总线/点对点互连等)通信地耦合到多个多核心处理器2005-2006。在一个实施例中,高速链路2040-2043支持4gb/s、30gb/s、80gb/s或更高的通信吞吐量。可以使用各种互连协议,包括但不限于pcie 4.0或5.0以及nvlink 2.0。
247.此外,在一个实施例中,两个或更多个gpu 2010-2013通过高速链路2029-2030互连,该高速链路可以使用与用于高速链路2040-2043的协议/链路相同或不同的协议/链路来实现。类似地,两个或更多个多核心处理器2005-2006可以通过高速链路2028连接,该高速链路可以是以20gb/s、30gb/s、120gb/s或更高的速度运行的对称多处理器(smp)总线。可替代地,可以使用相同的协议/链路(例如,通过公共互连结构)来完成图20a中所示的各种系统组件之间的所有通信。
248.在一个实施例中,每个多核心处理器2005-2006分别经由存储器互连2026-2027通信地耦合到处理器存储器2001-2002,并且每个gpu 2010-2013分别通过gpu存储器互连2050-2053通信地耦合到gpu存储器2020-2023。存储器互连2026-2027和2050-2053可以利用相同或不同的存储器访问技术。作为示例而非限制,处理器存储器2001-2002和gpu存储器2020-2023可以是易失性存储器,诸如动态随机存取存储器(dram)(包括堆叠的dram)、图形ddr sdram(gddr)(例如gddr5、gddr6),或高带宽存储器(hbm),和/或可以是非易失性存储器,例如3d xpoint或nano-ram。在一个实施例中,处理器存储器2001-2002的某些部分可以是易失性存储器,而另一部分可以是非易失性存储器(例如,使用两级存储器(2lm)层次结构)。
249.如本文所述,尽管各种处理器2005-2006和gpu 2010-2013可以分别物理地耦合到特定存储器2001-2002、2020-2023,可以实现统一存储器架构,其中相同虚拟系统地址空间
(也称为“有效地址”空间)分布在各个物理存储器之间。例如,处理器存储器2001-2002可以各自包含64gb的系统存储器地址空间,并且gpu存储器2020-2023可以各自包含32gb的系统存储器地址空间(在该示例中导致总计256gb的可寻址存储器大小)。
250.图20b示出了根据一个示例性实施例的用于多核心处理器2007和图形加速模块2046之间互连的附加细节。图形加速模块2046可以包括集成在线路卡上的一个或更多个gpu芯片,该线路卡经由高速链路2040耦合到处理器2007。可选地,图形加速模块2046可以集成在作为处理器2007的相同封装或芯片上。
251.在至少一个实施例中,示出的处理器2007包括多个核心2060a-2060d,每个核心都具有转换后备缓冲区2061a-2061d和一个或更多个高速缓存2062a-2062d。在至少一个实施例中,核心2060a-2060d可以包括未示出的各种其他组件,用于执行指令和处理数据。在至少一个实施例中,高速缓存2062a-2062d可以包括级别1(l1)和级别2(l2)高速缓存。此外,一个或更多个共享高速缓存2056可以被包括在高速缓存2062a-2062d中,并且由各组核心2060a-2060d共享。例如,处理器2007的一个实施例包括24个核心,每个核心具有其自己的l1高速缓存,十二个共享的l2高速缓存,和十二个共享的l3高速缓存。在该实施例中,两个相邻核心共享一个或更多个l2和l3高速缓存。处理器2007和图形加速模块2046与系统存储器2014连接,该系统存储器2014可以包括图20a中的处理器存储器2001-2002。
252.通过一致性总线2064经由核心间通信为存储在各个高速缓存2062a-2062d、2056和系统存储器2014中的数据和指令维护一致性。例如,每个高速缓存可以具有与其相关联的高速缓存一致性逻辑/电路,以响应于检测到对特定高速缓存行的读取或写入通过一致性总线2064进行通信。在一个实现中,通过一致性总线2064实现高速缓存监听协议,以监听(snoop)高速缓存访问。
253.在一个实施例中,代理电路2025将图形加速模块2046通信地耦合到一致性总线2064,从而允许图形加速模块2046作为核心2060a-2060d的对等方参与高速缓存一致性协议。特别地,在至少一个实施例中,接口2035通过高速链路2040(例如,pcie总线、nvlink等)提供到代理电路2025的连接,并且接口2037将图形加速模块2046连接到链路2040。
254.在一个实现中,加速器集成电路2036代表图形加速模块的多个图形处理引擎2031,2032,n提供高速缓存管理、存储器访问、上下文管理和中断管理服务。图形处理引擎2031,2032,n可各自包括单独的图形处理单元(gpu)。可选地,图形处理引擎2031,2032,n选择性地可以包括gpu内的不同类型的图形处理引擎,诸如图形执行单元、媒体处理引擎(例如,视频编码器/解码器)、采样器和blit引擎。在至少一个实施例中,图形加速模块2046可以是具有多个图形处理引擎2031-2032,n的gpu,或者图形处理引擎2031-2032,n可以是集成在通用封装、线路卡或芯片上的各个gpu。
255.在一个实施例中,加速器集成电路2036包括存储器管理单元(mmu)2039,用于执行各种存储器管理功能,例如虚拟到物理存储器转换(也称为有效到真实存储器转换),还包括用于访问系统存储器2014的存储器访问协议。mmu 2039还可包括转换后备缓冲区(“tlb”)(未示出),用于高速缓存虚拟/有效到物理/真实地址转换。在一个实现中,高速缓存2038可以存储命令和数据,用于图形处理引擎2031-2032,n有效地访问。在至少一个实施例中,将存储在高速缓存2038和图形存储器2033-2034,m中的数据与核心高速缓存2062a-2062d、2056和系统存储器2014保持一致。如前所述,可以经由代表高速缓存2038和图形存
储器2033-2034,m的代理电路2025来完成该任务(例如,将与处理器高速缓存2062a-2062d、2056上的高速缓存行的修改/访问有关的更新发送到高速缓存2038,并从高速缓存2038接收更新)。
256.一组寄存器2045存储由图形处理引擎2031-2032,n执行的线程的上下文数据,并且上下文管理电路2048管理线程上下文。例如,上下文管理电路2048可以执行保存和恢复操作,以在上下文切换期间保存和恢复各个线程的上下文(例如,其中保存第一线程并且存储第二线程,以便可以由图形处理引擎执行第二线程)。例如,上下文管理电路2048在上下文切换时,可以将当前寄存器值存储到存储器中的(例如,由上下文指针识别的)指定区域。然后,当返回上下文时可以恢复寄存器值。在一个实施例中,中断管理电路2047接收并处理从系统设备接收的中断。
257.在一个实现中,mmu 2039将来自图形处理引擎2031的虚拟/有效地址转换为系统存储器2014中的真实/物理地址。加速器集成电路2036的一个实施例支持多个(例如,4、8、16)图形加速器模块2046和/或其他加速器设备。图形加速器模块2046可以专用于在处理器2007上执行的单个应用程序,或者可以在多个应用程序之间共享。在一个实施例中,呈现了虚拟化的图形执行环境,其中图形处理引擎2031-2032,n的资源与多个应用程序或虚拟机(vm)共享。在至少一个实施例中,可以基于处理要求和与vm和/或应用程序相关联的优先级,将资源细分为“切片”,其被分配给不同的vm和/或应用程序。
258.在至少一个实施例中,加速器集成电路2036作为图形加速模块2046的系统的桥来执行,并提供地址转换和系统存储器高速缓存服务。另外,加速器集成电路2036可以为主机处理器提供虚拟化设施,以管理图形处理引擎2031-2032的虚拟化、中断和存储器管理。
259.由于图形处理引擎2031-2032,n的硬件资源被明确地映射到主机处理器2007看到的真实地址空间,因此任何主机处理器都可以使用有效地址值直接寻址这些资源。在至少一个实施例中,加速器集成电路2036的一个功能是物理分离图形处理引擎2031-2032,n,使得它们在系统看来为独立的单元。
260.在至少一个实施例中,一个或更多个图形存储器2033-2034,m分别耦合到每个图形处理引擎2031-2032,n。图形存储器2033-2034,m存储指令和数据,所述指令和数据由每个图形处理引擎2031-2032,n处理。图形存储器2033-2034,m可以是易失性存储器,例如dram(包括堆叠的dram)、gddr存储器(例如,gddr5,gddr6)或hbm,和/或可以是非易失性存储器,例如3d xpoint或nano-ram。
261.在一个实施例中,为了减少链路2040上的数据流量,可以使用偏置技术以确保存储在图形存储器2033-2034,m中的数据是图形处理引擎2031-2032,n最常使用的,并且最好核心2060a-2060d不使用(至少不经常使用)的数据。类似地,在至少一个实施例中,偏置机制试图将核心(并且优选地不是图形处理引擎2031-2032,n)需要的数据保持在核心的高速缓存2062a-2062d、2056和系统存储器2014中。
262.图20c示出了另一个示例性实施例,其中加速器集成电路2036被集成在处理器2007内。在该实施例中,图形处理引擎2031-2032,n经由接口2037和接口2035(同样可以利用任何形式的总线或接口协议)通过高速链路2040直接与加速器集成电路2036通信。加速器集成电路2036可以执行与关于图20b描述的操作相同的操作。但是由于它紧密靠近一致性总线2064和高速缓存2062a-2062d、2056,可能具有更高的吞吐量。一个实施例支持不同
的编程模型,包括专用进程编程模型(无图形加速模块虚拟化)和共享编程模型(具有虚拟化),所述编程模型可以包括由加速器集成电路2036控制的编程模型和由图形加速模块2046控制的编程模型。
263.在至少一个实施例中,图形处理引擎2031-2032,n专用于单个操作系统下的单个应用程序或进程。在至少一个实施例中,单个应用程序可以将其他应用程序请求汇聚(funnel)到图形处理引擎2031-2032,n,从而在vm/分区内提供虚拟化。
264.在至少一个实施例中,图形处理引擎2031-2032,n可以被多个vm/应用程序分区共享。在至少一个实施例中,共享模型可以使用系统管理程序来虚拟化图形处理引擎2031-2032,n,以允许每个操作系统进行访问。对于没有管理程序的单分区系统,操作系统拥有图形处理引擎2031-2032,n。在至少一个实施例中,操作系统可以虚拟化图形处理引擎2031-2032,n,以提供对每个进程或应用程序的访问。
265.在至少一个实施例中,图形加速模块2046或个体图形处理引擎2031-2032,n使用进程句柄来选择进程元素。在一个实施例中,进程元素被存储在系统存储器2014中,并且可使用本文所述的有效地址到真实地址转换技术来寻址。在至少一个实施例中,进程句柄可以是特定于实现方式的值,其在向图形处理引擎2031-2032,n注册其上下文时提供给主机进程(即,调用系统软件以将进程元素添加到进程元素链接列表)。在至少一个实施例中,进程句柄的较低16位可以是进程元素在进程元素链接列表中的偏移量。
266.图20d示出了示例性加速器集成切片2090。如这里所用的,“切片”包括加速器集成电路2036的处理资源的指定部分。应用程序是系统存储器2014中的有效地址空间2082,其存储进程元素2083。在一个实施例中,响应于来自在处理器2007上执行的应用程序2080的gpu调用2081,存储进程元素2083。进程元素2083包含相应的应用程序2080的进程状态。包含在进程元素2083中的工作描述符(wd)2084可以是由应用程序请求的单个作业,或者可以包含指向作业队列的指针。在至少一个实施例中,wd 2084是指向应用程序的地址空间2082中的作业请求队列的指针。
267.图形加速模块2046和/或各个图形处理引擎2031-2032,n可以由系统中所有进程或进程子集共享。在至少一个实施例中,可以包括用于设置进程状态并将wd 2084发送到图形加速模块2046以在虚拟化环境中开始作业的基础设施。
268.在至少一个实施例中,专用进程编程模型是特定于实现方式的。在该模型中,单个进程拥有图形加速模块2046或个体图形处理引擎2031。由于图形加速模块2046由单个进程拥有时,管理程序初始化用于所拥有的分区的加速器集成电路,当指派了图形加速模块2046时,操作系统初始化用于所拥有的进程的加速器集成电路2036。
269.在操作中,加速器集成切片2090中的wd获取单元2091获取下一个wd 2084,其包括要由图形加速模块2046的一个或更多个图形处理引擎完成的工作的指示。来自wd 2084的数据可以存储在寄存器2045中,并由mmu 2039、中断管理电路2047和/或上下文管理电路2048使用,如图所示。例如,mmu 2039的一个实施例包括用于访问os虚拟地址空间2085内的段/页表2086的段/页漫游电路。中断管理电路2047可以处理从图形加速模块2046接收的中断事件2092。当执行图形操作时,由图形处理引擎2031-2032,n生成的有效地址2093被mmu 2039转换为真实地址。
270.在一个实施例中,为每个图形处理引擎2031-2032,n和/或图形加速模块2046复制
寄存器2045的相同集合,并且所述寄存器2045可以由管理程序或操作系统初始化。这些复制的寄存器中的每一个可以被包括在加速器集成切片2090中。可以由管理程序初始化的示例性寄存器在表1中示出。
[0271][0272]
表2中示出了可由操作系统初始化的示例性寄存器。
[0273][0274][0275]
在一个实施例中,每个wd 2084特定于特定的图形加速模块2046和/或图形处理引擎2031-2032,n。它包含图形处理引擎2031-2032,n完成工作所需的所有信息,或者它可以是指向存储器位置的指针,在该存储器位置应用程序已经设置了要完成的工作的命令队列。
[0276]
图20e示出了共享模型的一个示例性实施例的附加细节。该实施例包括管理程序实地址空间2098,其中存储了进程元素列表2099。可经由管理程序2096来访问管理程序实地址空间2098,所述管理程序2096虚拟化用于操作系统2095的图形加速模块引擎。
[0277]
在至少一个实施例中,共享编程模型允许来自系统中全部分区或分区子集的全部进程或进程子集使用图形加速模块2046。存在两种编程模型,其中图形加速模块2046由多个进程和分区共享:时间切片共享和图形定向共享。
[0278]
在该模型中,系统管理程序2096拥有图形加速模块2046,并使其功能可用于所有
操作系统2095。对于图形加速模块2046通过系统管理程序2096支持虚拟化,图形加速模块2046可以遵守以下:(1)应用程序的作业请求必须是自主的(即,不需要在作业之间保持状态),或者图形加速模块2046必须提供上下文保存和恢复机制,(2)图形加速模块2046保证应用程序的作业请求在指定的时间量内完成,包括任何转换错误,或者图形加速模块2046提供了抢占作业处理的能力,(3)在有向共享编程模型中进行操作时,必须确保图形加速模块2046进程之间的公平性。
[0279]
在至少一个实施例中,需要应用程序2080使用图形加速模块2046类型、工作描述符(wd)、权限屏蔽寄存器(amr)值和上下文保存/恢复区域指针(csrp)进行操作系统2095系统调用。在至少一个实施例中,图形加速模块2046类型描述了用于系统调用的目标加速函数。在至少一个实施例中,图形加速模块2046类型可以是系统特定的值。在至少一个实施例中,wd是专门为图形加速模块2046格式化的,并且可以采用图形加速模块2046命令、指向用户定义的结构的有效地址指针、指向命令队列的有效地址指针的形式,或描述要由图形加速模块2046完成的工作的任何其他数据结构。在一个实施例中,amr值是用于当前进程的amr状态。在至少一个实施例中,传递给操作系统的值与设置amr的应用程序类似。如果加速器集成电路2036和图形加速模块2046的实现不支持用户权限屏蔽覆写寄存器(uamor),则在管理程序调用中传递amr之前,操作系统可以将当前uamor值应用于amr值。管理程序2096可以在将amr放入进程元素2083中之前选择性地应用当前权限屏蔽覆写寄存器(amor)值。在至少一个实施例中,csrp是寄存器2045中的一个,所述寄存器包含应用程序的地址空间2082中的区域的有效地址,供图形加速模块2046保存和恢复上下文状态。如果不需要在作业之间保存状态或者当作业被抢占时,则该指针是可选的。在至少一个实施例中,上下文保存/恢复区域可以是固定的系统存储器。
[0280]
在接收到系统调用时,操作系统2095可以验证应用程序2080已经注册并且被授予使用图形加速模块2046的权限。然后,操作系统2095使用表3中所示的信息来调用管理程序2096。
[0281][0282]
在接收到管理程序调用时,管理程序2096验证操作系统2095已注册并被授予使用图形加速模块2046的权限。然后,管理程序2096将进程元素2083放入相应的图形加速模块2046类型的进程元素链接列表中。进程元素可以包括表4中所示的信息。
[0283][0284][0285]
在至少一个实施例中,管理程序初始化多个加速器集成切片2090寄存器2045。
[0286]
如图20f所示,在至少一个实施例中,使用统一存储器,所述统一存储器可经由用于访问物理处理器存储器2001-2002和gpu存储器2020-2023的公共虚拟存储器地址空间来寻址。在该实现方式中,在gpu 2010-2013上执行的操作利用相同的虚拟/有效存储器地址空间来访问处理器存储器2001-2002,反之亦然,从而简化了可编程性。在至少一个实施例中,虚拟/有效地址空间的第一部分被分配给处理器存储器2001,第二部分被分配给第二处理器存储器2002,第三部分被分配给gpu存储器2020,以此类推。在至少一个实施例中,整个虚拟/有效存储器空间(有时称为有效地址空间)由此分布在处理器存储器2001-2002和gpu存储器2020-2023的每一个中,从而允许任何处理器或gpu采用映射到任何物理存储器的虚拟地址访问该存储器。
[0287]
在一个实施例中,一个或更多个mmu 2039a-2039e内的偏置/一致性管理电路2094a-2094e确保一个或更多个主机处理器(例如,2005)与gpu 2010-2013的高速缓存之间的高速缓存一致性,并实现指示应在其中存储某些类型的数据的物理存储器的偏置技术。虽然在图20f中示出了偏置/一致性管理电路2094a-2094e的多个实例,但可以在一个或更多个主机处理器2005的mmu内和/或在加速器集成电路2036内实现偏置/一致性电路。
[0288]
一个实施例允许将gpu附接存储器2020-2023映射为系统存储器的一部分,并使用共享虚拟存储器(svm)技术进行访问,但不会遭受与完整系统高速缓存一致性相关的性能缺陷。在至少一个实施例中,将gpu附接存储器2020-2023作为系统存储器来访问而无需繁重的高速缓存一致性开销的能力为gpu卸载提供了有利的操作环境。该布置允许主机处理器2005的软件设置操作数并访问计算结果,而没有传统的i/o dma数据拷贝的开销。这样的传统拷贝包括驱动程序调用、中断和存储器映射i/o(mmio)访问,相对于简单的存储器访问
而言,这些访问效率均较低。在至少一个实施例中,在没有高速缓存一致性开销的情况下访问gpu附接存储器2020-2023的能力对于卸载的计算的执行时间可能是关键的。例如,在具有大量流式写入存储器流量的情况下,高速缓存一致性开销可以显著降低gpu 2010-2013所看到的有效写入带宽。在至少一个实施例中,操作数设置的效率、结果访问的效率和gpu计算的效率可能会在确定gpu卸载的有效性方面发挥作用。
[0289]
在至少一个实施例中,gpu偏置和主机处理器偏置的选择由偏置跟踪器数据结构驱动。例如,可以使用偏置表,所述偏置表可以是页面粒度结构(例如,以存储器页面的粒度来控制),该页面粒度结构包括每个gpu附加的存储器页面1或2位。在至少一个实施例中,在gpu 2010-2013中具有或不具有偏置高速缓存(例如,用于高速缓存偏置表的频繁/最近使用的条目)的情况下,可以在一个或更多个gpu附接存储器2020-2023的被盗存储器范围中实现偏置表。替代地,可以在gpu内维护整个偏置表。
[0290]
在至少一个实施例中,在实际访问gpu存储器之前,访问与对gpu附加存储器2020-2023的每次访问相关联的偏置表条目,从而引起以下操作。首先,来自gpu 2010-2013的在gpu偏置中找到其页面的本地请求被直接转发到对应的gpu存储器2020-2023。来自gpu的在主机偏置中找到其页面的本地请求被转发至处理器2005(例如,通过如上所述的高速链路)。在一个实施例中,来自处理器2005的在主机处理器偏置中找到所请求页面的请求完成了与正常存储器读取类似的请求。替代地,可以将指向gpu偏置页面的请求转发到gpu 2010-2013。在至少一个实施例中,如果gpu当前不使用页面,则gpu可随后将页面迁移到主机处理器偏置。在至少一个实施例中,页面的偏置状态可以通过基于软件的机制、基于硬件辅助的软件的机制、或者在有限的情况下通过纯粹基于硬件的机制来改变。
[0291]
一种用于改变偏置状态的机制采用api调用(例如opencl),所述api调用随后调用gpu的设备驱动程序,所述设备驱动程序随后发送消息(或使命令描述符入队)到gpu,引导gpu改变偏置状态,并在某些迁移中在主机中执行高速缓存刷新操作。在至少一个实施例中,高速缓存刷新操作用于从主机处理器2005偏置到gpu偏置的迁移,但是不用于相反的迁移。
[0292]
在一个实施例中,高速缓存一致性是通过暂时渲染主机处理器2005无法高速缓存的gpu偏置页面来维护的。为了访问这些页面,处理器2005可以请求来自gpu 2010的访问,gpu 2010可以或可以不立即授予访问权限。因此,为了减少处理器2005和gpu 2010之间的通信,确保gpu偏置页面是gpu所需的页面而不是主机处理器2005所需的页面是有益的,反之亦然。
[0293]
一个或更多个硬件结构1415用于执行一个或更多个实施例。在本文中可以结合图14a和/或图14b提供关于一个或更多个硬件结构1415的细节。
[0294]
图21示出了根据本文所述的各个实施例的示例性集成电路和相关联的图形处理器,其可以使用一个或更多个ip核心来制造。除了图示之外,在至少一个实施例中可以包括其他逻辑和电路,包括附加的图形处理器/核心、外围接口控制器或通用处理器核心。
[0295]
图21是示出根据至少一个实施例的可使用一个或更多个ip核心制造的芯片集成电路2100上的示例性系统的框图。在至少一个实施例中,集成电路2100包括一个或更多个应用程序处理器2105(例如,cpu)、至少一个图形处理器2110,并且可以另外包括图像处理器2115和/或视频处理器2120,其中任意一个可能是模块化ip核心。在至少一个实施例中,
2120可以参与共享或统一的虚拟存储器系统。在至少一个实施例中,一个或更多个电路互连2230a-2230b使图形处理器2210能够经由soc的内部总线或经由直接连接与soc内的其他ip核心相连接。
[0301]
在至少一个实施例中,图形处理器2240包括图22a的图形处理器2210的一个或更多个mmu 2220a-2220b、高速缓存2225a-2225b和电路互连2230a-2230b。在至少一个实施例中,图形处理器2240包括一个或更多个着色器核心2255a-2255n(例如,2255a、2255b、2255c、2255d、2255e、2255f到2255n-1和2255n),其提供了统一的着色器核心架构,其中单个核心或类型或核心可以执行所有类型的可编程着色器代码,包括用于实现顶点着色器、片段着色器和/或计算着色器的着色器程序代码。在至少一个实施例中,多个着色器核心可以变化。在至少一个实施例中,图形处理器2240包括核心间任务管理器2245,其充当线程分派器以将执行线程分派给一个或更多个着色器核心2255a-2255n和分块单元2258,以加速基于图块渲染的分块操作,其中在图像空间中细分了场景的渲染操作,例如,以利用场景内的局部空间一致性或优化内部缓存的使用。
[0302]
在至少一个实施例中,使用如上所述的api访问图形处理器2210。在至少一个实施例中,图形处理器2210是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,图形处理器2210接收作为经由api从应用程序获得的工作流的一部分的工作负载。
[0303]
图23a-23b示出了根据本文描述的实施例的附加示例性图形处理器逻辑。在至少一个实施例中,图23a示出了可以包括在图21的图形处理器2110内的图形核心2300,并且在至少一个实施例中,其可以是如图22b所示的统一着色器核心2255a-2255n。图23b示出了在至少一个实施例中的适用于在多芯片模块上部署的高度并行的通用图形处理单元2330。
[0304]
在至少一个实施例中,图形核心2300包括共享指令高速缓存2302、纹理单元2318和高速缓存/共享存储器2320,它们对于图形核心2300内的执行资源是通用的。在至少一个实施例中,图形核心2300可包括多个切片2301a-2301n或每个核心的分区,并且图形处理器可包括图形核心2300的多个实例。切片2301a-2301n可包括支持逻辑,所述逻辑包括本地指令高速缓存2304a-2304n、线程调度器2306a-2306n、线程分派器2308a-2308n和一组寄存器2310a-2310n。在至少一个实施例中,切片2301a-2301n可以包括一组附加功能单元(afu 2312a-2312n)、浮点单元(fpu 2314a-2314n)、整数算术逻辑单元(alu 2316a-2316n)、地址计算单元(acu 2313a-2313n)、双精度浮点单元(dpfpu 2315a-2315n)和矩阵处理单元(mpu 2317a-2317n)。
[0305]
在至少一个实施例中,fpu 2314a-2314n可以执行单精度(32位)和半精度(16位)浮点运算,而dpfpu 2315a-2315n则执行双精度(64位)浮点运算点操作。在至少一个实施例中,alu 2316a-2316n可以以8位、16位和32位精度执行可变精度整数运算,并且可以配置为混合精度运算。在至少一个实施例中,mpu 2317a-2317n还可被配置用于混合精度矩阵运算,包括半精度浮点运算和8位整数运算。在至少一个实施例中,mpu 2317a-2317n可以执行各种矩阵运算以加速机器学习应用程序框架,包括使得能够支持加速的通用矩阵到矩阵乘法(gemm)。在至少一个实施例中,afu 2312a-2312n可以执行浮点数或整数单元不支持的附加逻辑运算,包括三角运算(例如,正弦,余弦等)。
[0306]
在至少一个实施例中,使用如上所述的api访问图形核心2300。在至少一个实施例中,图形核心2300是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,图形
核心2300接收作为通过api从应用程序获得的工作流的一部分的工作负载。
[0307]
图23b示出了在至少一个实施例中的通用处理单元(gpgpu)2330,其可以被配置为使得高度并行的计算操作能够由一组图形处理单元来执行。在至少一个实施例中,gpgpu 2330可以直接链接到gpgpu 2330的其他实例,以创建多gpu集群以提高用于深度神经网络的训练速度。在至少一个实施例中,gpgpu 2330包括主机接口2332,以实现与主机处理器的连接。在至少一个实施例中,主机接口2332是pci express接口。在至少一个实施例中,主机接口2332可以是厂商专用的通信接口或通信结构。在至少一个实施例中,gpgpu 2330接收主机处理器的命令,并使用全局调度器2334,以将与那些命令相关联的执行线程分配给一组计算集群2336a-2336h。在至少一个实施例中,计算群集2336a-2336h共享高速缓存存储器2338。在至少一个实施例中,高速缓存存储器2338可以用作计算群集2336a-2336h内的高速缓存存储器的更高级别的高速缓存。
[0308]
在至少一个实施例中,gpgpu 2330包括存储器2344a-2344b,所述存储器2344a-2344b经由一组存储器控制器2342a-2342b与计算集群2336a-2336h耦合。在至少一个实施例中,存储器2344a-2344b可以包括各种类型的存储器设备,包括动态随机存取存储器(dram)或图形随机存取存储器,例如同步图形随机存取存储器(sgram),其包括图形双倍数据速率(gddr)存储器。
[0309]
在至少一个实施例中,计算集群2336a-2336h每个都包括一组图形核心,例如图23a的图形核心2300,所述图形核心可以包括多种类型的整数和浮点逻辑单元,所述逻辑单元可以在计算机各种精度范围上执行计算操作,包括适用于机器学习计算的精度。例如,在至少一个实施例中,每个计算集群2336a-2336h中的浮点单元的至少一个子集可以被配置为执行16位或32位浮点运算,而浮点单元的不同子集可以配置为执行64位浮点运算。
[0310]
在至少一个实施例中,gpgpu 2330的多个实例可以被配置为用作计算集群。在至少一个实施例中,计算集群2336a-2336h用于同步和数据交换的通信在实施例之间变化。在至少一个实施例中,gpgpu 2330的多个实例通过主机接口2332进行通信。在至少一个实施例中,gpgpu 2330包括i/o集线器2339,所述集线器将gpgpu 2330与gpu链路2340耦合,使得能够直接连接到gpgpu 2330的其他实例。在至少一个实施例中,gpu链路2340耦合到专用gpu到gpu桥,所述桥使得gpgp 2330的多个实例之间能够通信和同步。在至少一个实施例中,gpu链路2340与高速互连耦合,以向其他gpgpu或并行处理器发送和接收数据。在至少一个实施例中,gpgpu 2330的多个实例位于单独的数据处理系统中,并通过可通过主机接口2332访问的网络设备进行通信。在至少一个实施例中,gpu链路2340可被配置为使得能够连接到主机除主机接口2332之外或作为其替代的处理器。
[0311]
在至少一个实施例中,gpgpu 2330可以被配置为训练神经网络。在至少一个实施例中,可以在推理平台内使用gpgpu 2330。在至少一个实施例中,在其中使用gpgpu 2330进行推理的情况下,相对于使用gpgpu训练神经网络时,gpgpu可以包括更少的计算集群2336a-2336h。在至少一个实施例中,与存储器2344a-2344b相关联的存储器技术可以在推理和训练配置之间有所不同,其中更高带宽的存储器技术专用于训练配置。在至少一个实施例中,gpgpu 2330的推理配置可以支持推理特定指令。例如,在至少一个实施例中,推理配置可以提供对一个或更多个8位整数点积指令的支持,该指令可以在部署的神经网络的推理操作期间使用。
[0312]
在至少一个实施例中,使用如上所述的api访问gpgpu 2330。在至少一个实施例中,gpgpu 2330是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,gpgpu 2330接收作为通过api从应用程序获得的工作流的一部分的工作负载。
[0313]
图24示出了根据至少一个实施例的计算机系统2400的框图。在至少一个实施例中,计算机系统2400包括具有一个或更多个处理器2402的处理子系统2401和系统存储器2404,所述系统存储器2404经由可包括存储器集线器2405的互连路径通信。在至少一个实施例中,存储器集线器2405可以是芯片组部件内的单独部件,或者可以集成在一个或更多个处理器2402内。在至少一个实施例中,存储器集线器2405通过通信链路2406与i/o子系统2411耦合。在一个实施例中,i/o子系统2411包括i/o集线器2407,所述i/o集线器可以使计算机系统2400能够接收来自一个或更多个输入设备2408的输入。在至少一个实施例中,i/o集线器2407可以使显示控制器向一个或更多个显示设备2410a提供输出,所述显示控制器可以包括在一个或更多个处理器2402中。在至少一个实施例中,与i/o集线器2407耦合的一个或更多个显示设备2410a可以包括本地,内部或嵌入式显示设备。
[0314]
在至少一个实施例中,处理子系统2401包括经由总线或其他通信链路2413耦合到存储器集线器2405的一个或更多个并行处理器2412中。在至少一个实施例中,通信链路2413可以是任何一种许多基于标准的通信链路技术或协议,例如但不限于pci express,或者可以是特定于供应商的通信接口或通信结构。在至少一个实施例中,一个或更多个并行处理器2412形成计算集中的并行或向量处理系统,所述系统可以包括大量处理核心和/或处理集群,例如多集成核心(mic)处理器。在至少一个实施例中,一个或更多个并行处理器2412形成图形处理子系统,所述图形处理子系统可以将像素输出到经由i/o集线器2407耦合的一个或更多个显示设备2410a之一。在至少一个实施例中,一个或更多个并行处理器2412还可以包括显示控制器和显示接口(未示出),以使得能够直接连接到一个或更多个显示设备2410b。
[0315]
在至少一个实施例中,系统存储单元2414可以连接到i/o集线器2407,以提供用于计算机系统2400的存储机制。在至少一个实施例中,i/o交换机2416可以用于提供一个接口机制,以实现i/o集线器2407与其他组件之间的连接,例如可以集成到平台中的网络适配器2418和/或无线网络适配器2419,以及可以通过一个或更多个附加设备2420添加的各种其他设备。在至少一个实施例中,网络适配器2418可以是以太网适配器或另一有线网络适配器。在至少一个实施例中,无线网络适配器2419可以包括wi-fi、蓝牙、近场通信(nfc)中的一个或更多个,或包括一个或更多个无线电设备的其他网络设备。
[0316]
在至少一个实施例中,计算机系统2400可以包括未明确示出的其他组件,所述其他组件包括usb或其他端口连接、光学存储驱动器、视频捕获设备等,所述其他组件也可以连接到i/o集线器2407。在至少一个实施例中,互连图24中的各种组件的通信路径可以使用任何合适的协议来实现,例如基于pci(外围组件互连)的协议(例如pci-express)或其他总线或点对点通信接口和/或协议,例如nv-link高速互连或互连协议。
[0317]
在至少一个实施例中,一个或更多个并行处理器2412包括为图形和视频处理而优化的电路,所述电路包括例如视频输出电路,并构成图形处理单元(gpu)。在至少一个实施例中,一个或更多个并行处理器2412包括为通用处理而优化的电路。在至少一个实施例中,计算机系统2400的组件可以与单个集成电路上的一个或更多个其他系统元件集成。例如,
在至少一个实施例中,一个或更多个并行处理器2412、存储器集线器2405、处理器2402和i/o集线器2407,可以被集成到片上系统(soc)集成电路中。在至少一个实施例中,计算机系统2400的组件可以被集成到单个封装中,以形成系统级封装(sip)配置。在至少一个实施例中,计算机系统2400的组件的至少一部分可以被集成到多芯片模块(mcm)中,所述多芯片模块可以与其他多芯片模块互连到模块化计算机系统中。
[0318]
在至少一个实施例中,计算系统2400可以使用具有多种加速器的多处理。例如,在至少一个实施例中,计算系统2400可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,计算系统2400可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0319]
处理器
[0320]
图25a示出了根据至少一个实施例的并行处理器2500。在至少一个实施例中,并行处理器2500的各种组件可以使用一个或更多个集成电路设备来实现,例如可编程处理器、专用集成电路(asic)或现场可编程门阵列(fpga)。在至少一个实施例中,所示的并行处理器2500是根据示例性实施例的图24所示的一个或更多个并行处理器2412的变体。
[0321]
在至少一个实施例中,并行处理器2500包括并行处理单元2502。在至少一个实施例中,并行处理单元2502包括i/o单元2504,其使得能够与其他设备进行通信,包括并行处理单元2502的其他实例。在至少一个实施例中,i/o单元2504可以直接连接到其他设备。在至少一个实施例中,i/o单元2504通过使用集线器或交换机接口(例如,存储器集线器2405)与其他设备连接。在至少一个实施例中,存储器集线器2405与i/o单元2504之间的连接形成通信链路2413。在至少一个实施例中,i/o单元2504与主机接口2506和存储器交叉开关2516连接,其中主机接口2506接收用于执行处理操作的命令,而存储器交叉开关2516接收用于执行存储器操作的命令。
[0322]
在至少一个实施例中,当主机接口2506经由i/o单元2504接收命令缓冲区时,主机接口2506可以引导工作操作以执行那些命令到前端2508。在至少一个实施例中,前端2508与调度器2510耦合,调度器2510配置成将命令或其他工作项分配给处理集群阵列2512。在至少一个实施例中,调度器2510确保在将任务分配给处理集群阵列2512之前,处理集群阵列2512被正确地配置并且处于有效状态。在至少一个实施例中,调度器2510通过在微控制器上执行的固件逻辑来实现。在至少一个实施例中,微控制器实现的调度器2510可配置成以粗粒度和细粒度执行复杂的调度和工作分配操作,从而实现对在处理阵列2512上执行的线程的快速抢占和上下文切换。在至少一个实施例中,主机软件可以证明用于通过多个图形处理门铃之一在处理阵列2512上进行调度的工作负载。在至少一个实施例中,工作负载然后可以由包括调度器2510的微控制器内的调度器2510逻辑在处理阵列2512上自动分配。
[0323]
在至少一个实施例中,处理集群阵列2512可以包括多达“n”个处理集群(例如,集群2514a、集群2514b到集群2514n)。在至少一个实施例中,处理集群阵列2512的每个集群2514a-2514n可以执行大量并发线程。在至少一个实施例中,调度器2510可以使用各种调度和/或工作分配算法将工作分配给处理集群阵列2512的集群2514a-2514n,其可以根据每种程序或计算类型产生的工作负载而变化。在至少一个实施例中,调度可以由调度器2510动态地处理,或者可以在配置为由处理集群阵列2512执行的程序逻辑的编译期间部分地由编译器逻辑来辅助。在至少一个实施例中,可将处理集群阵列2512的不同的集群2514a-2514n
分配用于处理不同类型的程序或用于执行不同类型的计算。
[0324]
在至少一个实施例中,处理集群阵列2512可以配置成执行各种类型的并行处理操作。在至少一个实施例中,处理集群阵列2512配置成执行通用并行计算操作。例如,在至少一个实施例中,处理集群阵列2512可以包括执行处理任务的逻辑,该处理任务包括对视频和/或音频数据的过滤,执行建模操作,包括物理操作以及执行数据转换。
[0325]
在至少一个实施例中,处理集群阵列2512配置成执行并行图形处理操作。在至少一个实施例中,处理集群阵列2512可以包括附加逻辑以支持这种图形处理操作的执行,包括但不限于执行纹理操作的纹理采样逻辑,以及镶嵌逻辑和其他顶点处理逻辑。在至少一个实施例中,处理集群阵列2512可以配置成执行与图形处理有关的着色器程序,例如但不限于顶点着色器、曲面细分着色器、几何着色器和像素着色器。在至少一个实施例中,并行处理单元2502可以经由i/o单元2504从系统存储器传送数据以进行处理。在至少一个实施例中,在处理期间,可以在处理期间将传送的数据存储到片上存储器(例如,并行处理器存储器2522),然后将其写回到系统存储器。
[0326]
在至少一个实施例中,当并行处理单元2502用于执行图形处理时,调度器2510可以配置成将处理工作负载划分为近似相等大小的任务,以更好地将图形处理操作分配给处理集群阵列2512的多个集群2514a-2514n。在至少一个实施例中,处理集群阵列2512的部分可以配置成执行不同类型的处理。例如,在至少一个实施例中,第一部分可以配置成执行顶点着色和拓扑生成,第二部分可以配置成执行镶嵌和几何着色,并且第三部分可以配置成执行像素着色或其他屏幕空间操作,以生成用于显示的渲染图像。在至少一个实施例中,可以将由集群2514a-2514n中的一个或更多个产生的中间数据存储在缓冲区中,以允许在集群2514a-2514n之间传输中间数据以进行进一步处理。
[0327]
在至少一个实施例中,处理集群阵列2512可以经由调度器2510接收要执行的处理任务,该调度器2510从前端2508接收定义处理任务的命令。在至少一个实施例中,处理任务可以包括要被处理的数据的索引,例如,表面(补丁)数据、原始数据、顶点数据和/或像素数据,以及状态参数和定义如何处理数据的命令(例如,要执行什么程序)。在至少一个实施例中,调度器2510可以配置成获取与任务相对应的索引,或者可以从前端2508接收索引。在至少一个实施例中,前端2508可以配置成确保在启动由传入命令缓冲区(例如,批缓冲区(batch-buffer)、推送缓冲区等)指定的工作负载之前,处理集群阵列2512配置成有效状态。
[0328]
在至少一个实施例中,并行处理单元2502的一个或更多个实例中的每一个可以与并行处理器存储器2522耦合。在至少一个实施例中,可以经由存储器交叉开关2516访问并行处理器存储器2522,所述存储器交叉开关2516可以接收来自处理集群阵列2512以及i/o单元2504的存储器请求。在至少一个实施例中,存储器交叉开关2516可以经由存储器接口2518访问并行处理器存储器2522。在至少一个实施例中,存储器接口2518可以包括多个分区单元(例如,分区单元2520a、分区单元2520b到分区单元2520n),其可各自耦合至并行处理器存储器2522的一部分(例如,存储器单元)。在至少一个实施例中,多个分区单元2520a-2520n为配置为等于存储器单元的数量,使得第一分区单元2520a具有对应的第一存储器单元2524a,第二分区单元2520b具有对应的存储器单元2524b,第n分区单元2520n具有对应的第n存储器单元2524n。在至少一个实施例中,分区单元2520a-2520n的数量可以不等于存储
器设备的数量。
[0329]
在至少一个实施例中,存储器单元2524a-2524n可以包括各种类型的存储器设备,包括动态随机存取存储器(dram)或图形随机存取存储器,例如同步图形随机存取存储器(sgram),包括图形双倍数据速率(gddr)存储器。在至少一个实施例中,存储器单元2524a-2524n还可包括3d堆叠存储器,包括但不限于高带宽存储器(hbm)。在至少一个实施例中,可以跨存储器单元2524a-2524n来存储诸如帧缓冲区或纹理映射的渲染目标,从而允许分区单元2520a-2520n并行地写入每个渲染目标的部分,以有效地使用并行处理器存储器2522的可用带宽。在至少一个实施例中,可以排除并行处理器存储器2522的本地实例,以有利于利用系统存储器与本地高速缓存存储器结合的统一存储器设计。
[0330]
在至少一个实施例中,处理集群阵列2512的集群2514a-2514n中的任何一个都可以处理将被写入并行处理器存储器2522内的任何存储器单元2524a-2524n中的数据。在至少一个实施例中,存储器交叉开关2516可以配置为将每个集群2514a-2514n的输出传输到任何分区单元2520a-2520n或另一个集群2514a-2514n,集群2514a-2514n可以对输出执行其他处理操作。在至少一个实施例中,每个集群2514a-2514n可以通过存储器交叉开关2516与存储器接口2518通信,以从各种外部存储设备读取或写入各种外部存储设备。在至少一个实施例中,存储器交叉开关2516具有到存储器接口2518的连接以与i/o单元2504通信,以及到并行处理器存储器2522的本地实例的连接,从而使不同处理集群2514a-2514n内的处理单元与系统存储器或不是并行处理单元2502本地的其他存储器进行通信。在至少一个实施例中,存储器交叉开关2516可以使用虚拟通道来分离集群2514a-2514n和分区单元2520a-2520n之间的业务流。
[0331]
在至少一个实施例中,可以在单个插入卡上提供并行处理单元2502的多个实例,或者可以将多个插入卡互连。在至少一个实施例中,并行处理单元2502的不同实例可以配置成相互操作,即使不同实例具有不同数量的处理核心,不同数量的本地并行处理器存储器和/或其他配置差异。例如,在至少一个实施例中,并行处理单元2502的一些实例可以包括相对于其他实例而言更高精度的浮点单元。在至少一个实施例中,结合并行处理单元2502或并行处理器2500的一个或更多个实例的系统可以以各种配置和形式因素来实现,包括但不限于台式机、膝上型计算机或手持式个人计算机、服务器、工作站、游戏机和/或嵌入式系统。
[0332]
图25b是根据至少一个实施例的分区单元2520的框图。在至少一个实施例中,分区单元2520是图25a的分区单元2520a-2520n之一的实例。在至少一个实施例中,分区单元2520包括l2高速缓存2521、帧缓冲区接口2525和rop 2526(光栅操作单元)。l2高速缓存2521是读/写高速缓存,其配置成执行从存储器交叉开关2516和rop 2526接收的加载和存储操作。在至少一个实施例中,l2高速缓存2521将读取未命中和紧急回写请求输出到帧缓冲区接口2525以进行处理。在至少一个实施例中,还可以经由帧缓冲区接口2525将更新发送到帧缓冲区以进行处理。在至少一个实施例中,帧缓冲区接口2525与并行处理器存储器中的存储器单元(诸如图25a的存储器单元2524a-2524n(例如,在并行处理器存储器2522内))之一相互作用。
[0333]
在至少一个实施例中,rop 2526是一种处理单元,其执行光栅操作,诸如模版、z测试、混合等。在至少一个实施例中,rop 2526然后输出存储在图形存储器中的处理后的图形
数据。在至少一个实施例中,rop 2526包括压缩逻辑以压缩被写入存储器的深度或颜色数据并解压缩从存储器读取的深度或颜色数据。在至少一个实施例中,压缩逻辑可以是利用多种压缩算法中的一个或更多个的无损压缩逻辑。在至少一个实施例中,rop 2526执行的压缩的类型可以基于要压缩的数据的统计特性而变化。例如,在至少一个实施例中,基于每图块基础上的深度和颜色数据执行增量颜色压缩。
[0334]
在至少一个实施例中,rop 2526包括在每个处理集群内(例如,图25a的集群2514a-2514n),而不是在分区单元2520内。在至少一个实施例中,通过存储器交叉开关2516而不是像素片段数据传输对像素数据的读取和写入请求。在至少一个实施例中,经处理的图形数据可以在显示设备上(诸如图24的一个或更多个显示设备2410之一)显示,由处理器2402路由以供进一步处理,或者由图25a的并行处理器2500内的处理实体之一路由以供进一步处理。
[0335]
图25c是根据至少一个实施例的并行处理单元内的处理集群2514的框图。在至少一个实施例中,处理集群是图25a的处理集群2514a-2514n之一的实例。在至少一个实施例中,处理集群2514可以配置成并行执行许多线程,其中术语“线程”是指在特定的一组输入数据上执行的特定程序的实例。在至少一个实施例中,单指令多数据(simd)指令发布技术用于支持大量线程的并行执行而无需提供多个独立的指令单元。在至少一个实施例中,使用单指令多线程(simt)技术来支持并行执行大量一般同步的线程,这使用了公共指令单元,该公共指令单元配置成向每个处理集群内的一组处理引擎发出指令。
[0336]
在至少一个实施例中,可以通过将处理任务分配给simt并行处理器的管线管理器2532来控制处理集群2514的操作。在至少一个实施例中,管线管理器2532从图25a的调度器2510接收指令,通过图形多处理器2534和/或纹理单元2536管理这些指令的执行。在至少一个实施例中,图形多处理器2534是simt并行处理器的示例性实例。然而,在至少一个实施例中,处理集群2514内可以包括不同架构的各种类型的simt并行处理器。在至少一个实施例中,在处理集群2514内可以包括图形多处理器2534的一个或更多个实例。在至少一个实施例中,图形多处理器2534可以处理数据,并且数据交叉开关2540可以用于将处理后的数据分发到多个可能的目的(包括其他着色器单元)地之一。在至少一个实施例中,管线管理器2532可以通过指定要经由数据交叉开关2540分配的处理后的数据的目的地来促进处理后的数据的分配。
[0337]
在至少一个实施例中,处理集群2514内的每个图形多处理器2534可以包括相同的一组功能执行逻辑(例如,算术逻辑单元、加载存储单元等)。在至少一个实施例中,可以以管线方式配置功能执行逻辑,其中可以在先前的指令完成之前发出新的指令。在至少一个实施例中,功能执行逻辑支持多种操作,包括整数和浮点算术、比较操作、布尔运算、移位和各种代数函数的计算。在至少一个实施例中,可以利用相同的功能单元硬件来执行不同的操作,并且可以存在功能单元的任何组合。
[0338]
在至少一个实施例中,传送到处理集群2514的指令构成线程。在至少一个实施例中,跨一组并行处理引擎执行的一组线程是线程组。在至少一个实施例中,线程组在不同的输入数据上执行程序。在至少一个实施例中,线程组内的每个线程可被分配给图形多处理器2534内的不同处理引擎。在至少一个实施例中,线程组可包括比图形多处理器2534内的多个处理引擎更少的线程。在至少一个实施例中,当线程组包括的线程数少于处理引擎的
数量时,一个或更多个处理引擎在正在处理该线程组的循环期间可能是空闲的。在至少一个实施例中,线程组还可以包括比图形多处理器2534内的多个处理引擎更多的线程。在至少一个实施例中,当线程组包括比图形多处理器2534内的处理引擎的数量更多的线程时,可以在连续的时钟周期内执行处理。在至少一个实施例中,可以在图形多处理器2534上同时执行多个线程组。
[0339]
在至少一个实施例中,图形多处理器2534包括内部高速缓存存储器,以执行加载和存储操作。在至少一个实施例中,图形多处理器2534可以放弃内部高速缓存并使用处理集群2514内的高速缓存存储器(例如,l1高速缓存2548)。在至少一个实施例中,每个图形多处理器2534还可以访问分区单元(例如,图25a的分区单元2520a-2520n)内的l2高速缓存,这些分区单元在所有处理集群2514之间共享并且可以用于在线程之间传输数据。在至少一个实施例中,图形多处理器2534还可以访问片外全局存储器,其可以包括本地并行处理器存储器和/或系统存储器中的一个或更多个。在至少一个实施例中,并行处理单元2502外部的任何存储器都可以用作全局存储器。在至少一个实施例中,处理集群2514包括图形多处理器2534的多个实例,它们可以共享可以存储在l1高速缓存2548中的公共指令和数据。
[0340]
在至少一个实施例中,每个处理集群2514可以包括配置成将虚拟地址映射为物理地址的存储器管理单元(“mmu”)2545。在至少一个实施例中,mmu 2545的一个或更多个实例可以驻留在图25a的存储器接口2518内。在至少一个实施例中,mmu 2545包括一组页表条目(pte),其用于将虚拟地址映射到图块(更多地谈论平铺)的物理地址以及可选地映射到高速缓存行索引。在至少一个实施例中,mmu 2545可以包括地址转换后备缓冲区(tlb)或可以驻留在图形多处理器2534或l1高速缓存或处理集群2514内的高速缓存。在至少一个实施例中,处理物理地址以分配表面数据访问局部性,以便在分区单元之间进行有效的请求交织。在至少一个实施例中,高速缓存行索引可以用于确定对高速缓存线的请求是命中还是未命中。
[0341]
在至少一个实施例中,可以配置处理集群2514,使得每个图形多处理器2534耦合到纹理单元2536,以执行纹理映射操作,所述操作确定纹理样本位置、读取纹理数据以及过滤纹理数据。在至少一个实施例中,根据需要从内部纹理l1高速缓存(未示出)或从图形多处理器2534内的l1高速缓存中读取纹理数据,并从l2高速缓存、本地并行处理器存储器或系统存储器中获取纹理数据。在至少一个实施例中,每个图形多处理器2534将处理后的任务输出到数据交叉开关2540,以将处理后的任务提供给另一处理集群2514以进行进一步处理或将处理后的任务存储在l2高速缓存、本地并行处理器存储器、或经由存储器交叉开关2516的系统存储器中。在至少一个实施例中,prerop 2542(光栅前操作单元)配置成从图形多处理器2534接收数据,将数据引导至rop单元,该rop单元可以与本文所述的分区单元(例如,图25a的分区单元2520a-2520n)一起定位。在至少一个实施例中,prerop 2542单元可以执行用于颜色混合的优化、组织像素颜色数据以及执行地址转换。
[0342]
在至少一个实施例中,并行处理器2500使用如上所述的api来访问。在至少一个实施例中,并行处理器2500是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,并行处理器2500接收作为经由api从应用程序获得的工作流的一部分的工作负载。
[0343]
图25d示出了根据至少一个实施例的图形多处理器2534。在至少一个实施例中,图形多处理器2534与处理集群2514的管线管理器2532耦合。在至少一个实施例中,图形多处
理器2534具有执行管线,该执行管线包括但不限于指令高速缓存2552、指令单元2554、地址映射单元2556、寄存器文件2558、一个或更多个通用图形处理单元(gpgpu)核心2562和一个或更多个加载/存储单元2566。gpgpu核心2562和加载/存储单元2566与高速缓存存储器2572和共享存储器2570通过存储器和高速缓存互连2568耦合。
[0344]
在至少一个实施例中,指令高速缓存2552从管线管理器2532接收要执行的指令流。在至少一个实施例中,将指令高速缓存在指令高速缓存2552中并将其分派以供指令单元2554执行。在一个实施例中,指令单元2554可以分派指令作为线程组(例如,线程束),将线程组的每个线程分配给gpgpu核心2562内的不同执行单元。在至少一个实施例中,指令可以通过在统一地址空间内指定地址来访问任何本地、共享或全局地址空间。在至少一个实施例中,地址映射单元2556可以用于将统一地址空间中的地址转换成可以由加载/存储单元2566访问的不同的存储器地址。
[0345]
在至少一个实施例中,寄存器文件2558为图形多处理器2534的功能单元提供了一组寄存器。在至少一个实施例中,寄存器文件2558为连接到图形多处理器2534的功能单元(例如,gpgpu核心2562、加载/存储单元2566)的数据路径的操作数提供了临时存储。在至少一个实施例中,在每个功能单元之间划分寄存器文件2558,使得为每个功能单元分配寄存器文件2558的专用部分。在至少一个实施例中,寄存器文件2558在图形多处理器2534正在执行的不同线程束之间划分。
[0346]
在至少一个实施例中,gpgpu核心2562可以各自包括用于执行图形多处理器2534的指令的浮点单元(fpu)和/或整数算术逻辑单元(alu)。gpgpu核心2562在架构上可以相似或架构可能有所不同。在至少一个实施例中,gpgpu核心2562的第一部分包括单精度fpu和整数alu,而gpgpu核心的第二部分包括双精度fpu。在至少一个实施例中,fpu可以实现用于浮点算法的ieee 754-2008标准或启用可变精度浮点算法。在至少一个实施例中,图形多处理器2534可以另外包括一个或更多个固定功能或特殊功能单元,以执行特定功能,诸如复制矩形或像素混合操作。在至少一个实施例中,gpgpu核心中的一个或更多个也可以包括固定或特殊功能逻辑。
[0347]
在至少一个实施例中,gpgpu核心2562包括能够对多组数据执行单个指令的simd逻辑。在一个实施例中,gpgpu核心2562可以物理地执行simd4、simd8和simd16指令,并且在逻辑上执行simd1、simd2和simd32指令。在至少一个实施例中,用于gpgpu核心的simd指令可以在编译时由着色器编译器生成,或者在执行针对单程序多数据(spmd)或simt架构编写和编译的程序时自动生成。在至少一个实施例中,可以通过单个simd指令来执行为simt执行模型配置的程序的多个线程。例如,在至少一个实施例中,可以通过单个simd8逻辑单元并行执行执行相同或相似操作的八个simt线程。
[0348]
在至少一个实施例中,存储器和高速缓存互连2568是将图形多处理器2534的每个功能单元连接到寄存器文件2558和共享存储器2570的互连网络。在至少一个实施例中,存储器和高速缓存互连2568是交叉开关互连,其允许加载/存储单元2566在共享存储器2570和寄存器文件2558之间实现加载和存储操作。在至少一个实施例中,寄存器文件2558可以以与gpgpu核心2562相同的频率操作,从而在gpgpu核心2562和寄存器文件2558之间进行数据传输的延迟非常低。在至少一个实施例中,共享存储器2570可以用于启用在图形多处理器2534内的功能单元上执行的线程之间的通信。在至少一个实施例中,高速缓存存储器
2572可以用作例如数据高速缓存,以高速缓存在功能单元和纹理单元2536之间通信的纹理数据。在至少一个实施例中,共享存储器2570也可以用作程序管理的高速缓存。在至少一个实施例中,除了存储在高速缓存存储器2572中的自动高速缓存的数据之外,在gpgpu核心2562上执行的线程还可以以编程方式将数据存储在共享存储器中。
[0349]
在至少一个实施例中,如本文所述的并行处理器或gpgpu通信地耦合到主机/处理器核心,以加速图形操作、机器学习操作、图案分析操作以及各种通用gpu(gpgpu)功能。在至少一个实施例中,gpu可以通过总线或其他互连(例如,诸如pcie或nvlink的高速互连)通信地耦合到主机处理器/核心。在至少一个实施例中,gpu可以与核心集成在相同封装或芯片上,并通过内部处理器总线/互连(即,封装或芯片的内部)通信地耦合到核心。在至少一个实施例中,不管gpu连接的方式如何,处理器核心可以以工作描述符中包含的命令/指令序列的形式向该gpu分配工作。在至少一个实施例中,该gpu然后使用专用电路/逻辑来有效地处理这些命令/指令。
[0350]
在至少一个实施例中,使用如上所述的api访问图形多处理器2534。在至少一个实施例中,图形多处理器2534是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,图形多处理器2534接收作为经由api从应用程序获得的工作流的一部分的工作负载。
[0351]
图26示出了根据至少一个实施例的多gpu计算系统2600。在至少一个实施例中,多gpu计算系统2600可以包括经由主机接口交换机2604耦合到多个通用图形处理单元(gpgpu)2606a-d的处理器2602。在至少一个实施例中,主机接口交换机2604是将处理器2602耦合到pci express总线的pci express交换机设备,处理器2602可以通过pci express总线与gpgpu 2606a-d通信。gpgpu 2606a-d可以经由一组高速p2p gpu到gpu链路2616互连。在至少一个实施例中,gpu到gpu链路2616经由专用gpu链路连接到gpgpu 2606a-d中的每一个。在至少一个实施例中,p2p gpu链路2616使得能够在每个gpgpu 2606a-d之间进行直接通信,而无需通过处理器2602所连接的主机接口总线2604进行通信。在至少一个实施例中,在gpu到gpu业务定向到p2p gpu链路2616的情况下,主机接口总线2604保持可用于系统存储器访问或例如经由一个或更多个网络设备与多gpu计算系统2600的其他实例进行通信。虽然在至少一个实施例中,gpgpu 2606a-d经由主机接口交换机2604连接到处理器2602,但是在至少一个实施例中,处理器2602包括对p2p gpu链路2616的直接支持,并且可以直接连接到gpgpu 2606a-d。
[0352]
在至少一个实施例中,多gpu计算系统2600可以使用具有多种加速器的多处理。例如,在至少一个实施例中,多gpu计算系统2600可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,多gpu计算系统2600可以实现如上所述的api,使得应用可以以简单的方式有效地使用加速资源。
[0353]
图27是根据至少一个实施例的图形处理器2700的框图。在至少一个实施例中,图形处理器2700包括环形互连2702、管线前端2704、媒体引擎2737和图形核心2780a-2780n。在至少一个实施例中,环形互连2702将图形处理器2700耦合到其他处理单元,所述处理单元包括其他图形处理器或一个或更多个通用处理器核心。在至少一个实施例中,图形处理器2700是集成在多核心处理系统内的许多处理器之一。
[0354]
在至少一个实施例中,图形处理器2700经由环形互连2702接收多批命令。在至少一个实施例中,输入的命令由管线前端2704中的命令流转化器(command streamer)2703解
释。在至少一个实施例中,图形处理器2700包括可扩展执行逻辑,用于经由图形核心2780a-2780n执行3d几何处理和媒体处理。在至少一个实施例中,对于3d几何处理命令,命令流转化器2703将命令提供给几何管线2736。在至少一个实施例中,对于至少一些媒体处理命令,命令流转化器2703将命令提供给视频前端2734,该视频前端与媒体引擎2737耦合。在至少一个实施例中,媒体引擎2737包括用于视频和图像后处理的视频质量引擎(vqe)2730,以及用于提供硬件加速的媒体数据编码和解码的多格式编码/解码(mfx)2733引擎。在至少一个实施例中,几何管线2736和媒体引擎2737各自生成用于由至少一个图形核心2780a提供的线程执行资源的执行线程。
[0355]
在至少一个实施例中,图形处理器2700包括具有(featuring)模块化核心2780a-2780n(有时被称为核心切片)的可扩展线程执行资源,每个图形核心具有多个子核心2750a-2750n,2760a-2760n(有时称为核心子切片)。在至少一个实施例中,图形处理器2700可以具有任意数量的图形核心2780a至2780n。在至少一个实施例中,图形处理器2700包括具有至少第一子核心2750a和第二子核心2760a的图形核心2780a。在至少一个实施例中,图形处理器2700是具有单个子核心(例如2750a)的低功率处理器。在至少一个实施例中,图形处理器2700包括多个图形核心2780a-2780n,每个图形核心包括一组第一子核心2750a-2750n和一组第二子核心2760a-2760n。在至少一个实施例中,第一子核心2750a-2750n中的每个子核心至少包括第一组执行单元2752a-2752n和媒体/纹理采样器2754a-2754n。在至少一个实施例中,第二子核心2760a-2760n中的每个子核心至少包括第二组执行单元2762a-2762n和采样器2764a-2764n。在至少一个实施例中,每个子核心2750a-2750n,2760a-2760n共享一组共享资源2770a-2770n。在至少一个实施例中,共享资源包括共享高速缓存存储器和像素操作逻辑。
[0356]
在至少一个实施例中,使用如上所述的api访问图形处理器2700。在至少一个实施例中,图形处理器2700是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,图形处理器2700接收作为通过api从应用程序获得的工作流的一部分的工作负载。
[0357]
图28是根据至少一个实施例的说明用于处理器2800的微架构的框图,该处理器2800可以包括用于执行指令的逻辑电路。在至少一个实施例中,处理器2800可以执行指令,包括x86指令、arm指令、用于专用集成电路(asic)的专用指令等。在至少一个实施例中,处理器2810可以包括用于存储封装数据的寄存器,例如作为加利福尼亚州圣克拉拉市英特尔公司采用mmx技术启用的微处理器中的64位宽mmx
tm
寄存器。在至少一个实施例中,整数和浮点数形式可用的mmx寄存器可以与封装的数据元素一起运行,所述封装的数据元素伴随单指令多数据(“simd”)和流式simd扩展(“sse”)指令。在至少一个实施例中,与sse2、sse3、sse4、avx或更高版本(一般称为“ssex”)技术有关的128位宽xmm寄存器可以保存此类封装数据操作数。在至少一个实施例中,处理器2810可以执行指令以加速机器学习或深度学习算法、训练或推理。
[0358]
在至少一个实施例中,处理器2800包括有序前端(“前端”)2801,以提取要执行的指令并准备稍后在处理器管线中使用的指令。在至少一个实施例中,前端2801可以包括几个单元。在至少一个实施例中,指令预取器2826从存储器中获取指令并将指令提供给指令解码器2828,指令解码器2828又对指令进行解码或解释。例如,在至少一个实施例中,指令解码器2828将接收到的指令解码为机器可执行的所谓的“微指令”或“微操作”(也称为“微
操作”或“微指令”)的一个或更多个操作。在至少一个实施例中,指令解码器2828将指令解析为操作码以及相应的数据和控制字段,其可以由微架构用来使用以根据至少一个实施例来执行操作。在至少一个实施例中,跟踪高速缓存2830可以将解码的微指令组装成微指令队列2834中的程序排序的序列或追踪以供执行。在至少一个实施例中,当追踪高速缓存2830遇到复杂指令时,微码rom 2832提供完成操作所需的微指令。
[0359]
在至少一个实施例中,可以将一些指令转换成单个微操作,而另一些指令则需要几个微操作来完成全部操作。在至少一个实施例中,如果需要多于四个的微指令来完成一条指令,则指令解码器2828可以访问微码rom 2832以执行该指令。在至少一个实施例中,可以将指令解码为少量的微指令以在指令解码器2828处进行处理。在至少一个实施例中,如果需要多个微指令完成该操作,则可以将指令存储在微码rom 2832中。在至少一个实施例中,追踪高速缓存器2830参考入口点可编程逻辑阵列(“pla”)以确定正确的微指令指针,用于根据至少一个实施例从微码rom 2832读取微码序列以完成一个或更多个指令。在至少一个实施例中,在微码rom 2832完成对指令的微操作排序之后,机器的前端2801可以恢复从追踪高速缓存2830获取微操作。
[0360]
在至少一个实施例中,乱序执行引擎(“乱序引擎”)2803可以准备用于执行的指令。在至少一个实施例中,乱序执行逻辑具有多个缓冲区,以使指令流平滑并重新排序,以在指令沿管线下降并被调度执行时优化性能。乱序执行引擎2803包括但不限于分配器/寄存器重命名器2840、存储器微指令队列2842、整数/浮点微指令队列2844、存储器调度器2846、快速调度器2802、慢速/通用浮点调度器(“慢速/通用fp调度器”)2804和简单浮点调度器(“简单fp调度器”)2806。在至少一个实施例中,快速调度器2802、慢速/通用浮点调度器2804和简单浮点调度器2806也统称为“微指令调度器2802、2804、2806”。在至少一个实施例中,分配器/寄存器重命名器2840分配每个微指令按序列执行所需要的机器缓冲区和资源。在至少一个实施例中,分配器/寄存器重命名器2840将逻辑寄存器重命名为寄存器文件中的条目。在至少一个实施例中,分配器/寄存器重命名器2840还为两个微指令队列之一中的每个微指令分配条目,存储器微指令队列2842用于存储器操作和整数/浮点微指令队列2844用于非存储器操作,在存储器调度器2846和微指令调度器2802、2804、2806的前面。在至少一个实施例中,微指令调度器2802、2804、2806基于它们的从属输入寄存器操作数源的就绪性和需要完成的执行资源微指令的可用性来确定何时准备好执行微指令。至少一个实施例的快速调度器2802可以在主时钟周期的每个一半上调度,而慢速/通用浮点调度器2804和简单浮点调度器2806可以在每个主处理器时钟周期调度一次。在至少一个实施例中,微指令调度器2802、2804、2806对调度端口进行仲裁,以调度用于执行的微指令。
[0361]
在至少一个实施例中,执行块b11包括但不限于整数寄存器文件/支路网络2808、浮点寄存器文件/支路网络(“fp寄存器文件/支路网络”)2810、地址生成单元(“agu”)2812和2814、快速算术逻辑单元(“快速alu”)2816和2818、慢速算术逻辑单元(“慢速alu”)2820、浮点alu(“fp”)2822和浮点移动单元(“fp移动”)2824。在至少一个实施例中,整数寄存器文件/支路网络2808和浮点寄存器文件/旁路网络2810在本文中也称为“寄存器文件2808、2810”。在至少一个实施例中,agu 2812和2814、快速alu 2816和2818、慢速alu 2820、浮点alu 2822和浮点移动单元2824在本文中也称为“执行单元2812、2814、2816、2818、2820、2822和2824”。在至少一个实施例中,执行块2811可以包括但不限于任意数量(包括零)和类
型的寄存器文件、支路网络、地址生成单元和执行单元(以任何组合)。
[0362]
在至少一个实施例中,寄存器文件2808、2810可以布置在微指令调度器2802、2804、2806与执行单元2812、2814、2816、2818、2820、2822和2824之间。在至少一个实施例中,整数寄存器文件/支路网络2808执行整数运算。在至少一个实施例中,浮点寄存器文件/支路网络2810执行浮点操作。在至少一个实施例中,寄存器文件2808、2810中的每一个可以包括但不限于支路网络,该支路网络可以绕过或转发尚未写入寄存器文件中的刚刚完成的结果到新的从属对象。在至少一个实施例中,寄存器文件2808、2810可以彼此通信数据。在至少一个实施例中,整数寄存器文件/支路网络2808可以包括但不限于两个单独的寄存器文件、一个寄存器文件用于低阶32位数据,第二寄存器文件用于高阶32位数据。在至少一个实施例中,浮点寄存器文件/支路网络2810可以包括但不限于128位宽的条目,因为浮点指令通常具有宽度为64至128位的操作数。
[0363]
在至少一个实施例中,执行单元2812、2814、2816、2818、2820、2822、2824可以执行指令。在至少一个实施例中,寄存器文件2808、2810存储微指令需要执行的整数和浮点数据操作数值。在至少一个实施例中,处理器2800可以包括但不限于任何数量的执行单元2812、2814、2816、2818、2820、2822、2824及其组合。在至少一个实施例中,浮点alu 2822和浮点移动单元2824,可以执行浮点、mmx、simd、avx和sse或其他操作,包括专门的机器学习指令。在至少一个实施例中,浮点alu 2822可以包括但不限于64位乘64位浮点除法器,以执行除法、平方根和余数微操作。在至少一个实施例中,可以用浮点硬件来处理涉及浮点值的指令。在至少一个实施例中,可以将alu操作传递给快速alu 2816、2818。在至少一个实施例中,快速alu 2816、2818可以以半个时钟周期的有效延迟执行快速操作。在至少一个实施例中,大多数复杂的整数运算进入慢速alu 2820,因为慢速alu 2820可以包括但不限于用于长延迟类型操作的整数执行硬件,例如乘法器、移位、标志逻辑和分支处理。在至少一个实施例中,存储器加载/存储操作可以由agus 2812、2814执行。在至少一个实施例中,快速alu 2816、快速alu 2818和慢速alu 2820可以对64位数据操作数执行整数运算。在至少一个实施例中,可以实现快速alu 2816、快速alu 2818和慢速alu 2820以支持包括十六、三十二、128、256等的各种数据位大小。在至少一个实施例中,浮点alu 2822和浮点移动单元2824可以实现为支持具有各种宽度的位的一定范围的操作数。在至少一个实施例中,浮点alu 2822和浮点移动单元2824可以结合simd和多媒体指令对128位宽封装数据操作数进行操作。
[0364]
在至少一个实施例中,微指令调度器2802、2804、2806在父加载完成执行之前调度从属操作。在至少一个实施例中,由于可以在处理器2800中推测性地调度和执行微指令,处理器2800还可以包括用于处理存储器未命中的逻辑。在至少一个实施例中,如果数据高速缓存中的数据加载未命中,则可能存在在管线中正在运行的从属操作,其使调度器暂时没有正确的数据。在至少一个实施例中,一种重放机制追踪踪并重新执行使用不正确数据的指令。在至少一个实施例中,可能需要重放从属操作并且可以允许完成独立操作。在至少一个实施例中,处理器的至少一个实施例的调度器和重放机制也可以设计为捕获用于文本串比较操作的指令序列。
[0365]
在至少一个实施例中,术语“寄存器”可以指代可以用作识别操作数的指令的一部分的机载处理器存储位置。在至少一个实施例中,寄存器可以是那些可以从处理器外部使用的寄存器(从程序员的角度来看)。在至少一个实施例中,寄存器可能不限于特定类型的
电路。相反,在至少一个实施例中,寄存器可以存储数据、提供数据并执行本文描述的功能。在至少一个实施例中,本文描述的寄存器可以通过处理器内的电路使用多种不同技术来实现,例如专用物理寄存器、使用寄存器重命名动态分配的物理寄存器、专用和动态分配的物理寄存器的组合等。在至少一个实施例中,整数寄存器存储32位整数数据。至少一个实施例的寄存器文件还包含八个用于封装数据的多媒体simd寄存器。
[0366]
在至少一个实施例中,处理器2800使用如上所述的api来访问。在至少一个实施例中,处理器2800是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,处理器2800接收作为经由api从应用程序获得的工作流的一部分的工作负载。
[0367]
图29示出了根据至少一个实施例的处理系统的框图。在至少一个实施例中,系统2900包括一个或更多个处理器2902和一个或更多个图形处理器2908,并且可以是单处理器台式机系统、多处理器工作站系统或具有大量处理器2902或处理器核心2907的服务器系统。在至少一个实施例中,系统2900是结合在片上系统(soc)集成电路内的处理平台,以在移动、手持或嵌入式设备使用。
[0368]
在至少一个实施例中,系统2900可以包括或结合在基于服务器的游戏平台中,包括游戏和媒体控制台的游戏控制台、移动游戏控制台、手持游戏控制台或在线游戏控制台。在至少一个实施例中,系统2900是移动电话、智能电话、平板计算设备或移动互联网设备。在至少一个实施例中,处理系统2900还可包括与可穿戴设备耦合或集成在可穿戴设备中,例如智能手表可穿戴设备、智能眼镜设备、增强现实设备或虚拟现实设备。在至少一个实施例中,处理系统2900是电视或机顶盒设备,其具有一个或更多个处理器2902以及由一个或更多个图形处理器2908生成的图形界面。
[0369]
在至少一个实施例中,一个或更多个处理器2902每个包括一个或更多个处理器核心2907,以处理指令,该指令在被执行时执行针对系统和用户软件的操作。在至少一个实施例中,一个或更多个处理器核心2907中的每一个被配置为处理特定指令集2909。在至少一个实施例中,指令集2909可以促进复杂指令集计算(cisc)、精简指令集计算(risc),或通过超长指令字(vliw)进行计算。在至少一个实施例中,处理器核心2907可以各自处理不同的指令集2909,该指令集可以包括有助于仿真其他指令集的指令。在至少一个实施例中,处理器核心2907还可以包括其他处理设备,例如数字信号处理器(dsp)。
[0370]
在至少一个实施例中,处理器2902包括高速缓存存储器2904。在至少一个实施例中,处理器2902可以具有单个内部高速缓存或更多个级别的内部高速缓存。在至少一个实施例中,高速缓存存储器在处理器2902的各个组件之间共享。在至少一个实施例中,处理器2902还使用外部高速缓存(例如,三级(l3)高速缓存或最后一级高速缓存(llc))(未示出),可以使用已知的高速缓存一致性技术在处理器核心2907之间共享该外部高速缓存。在至少一个实施例中,处理器2902中另外包括寄存器文件2906,处理器可以包括用于存储不同类型的数据的不同类型的寄存器(例如,整数寄存器、浮点寄存器、状态寄存器和指令指针寄存器)。在至少一个实施例中,寄存器文件2906可以包括通用寄存器或其他寄存器。
[0371]
在至少一个实施例中,一个或更多个处理器2902与一个或更多个接口总线2910耦合,以在处理器2902与系统2900中的其他组件之间传输通信信号,例如地址、数据或控制信号。在至少一个实施例中,接口总线2910在一个实施例中可以是处理器总线,例如直接媒体接口(dmi)总线的版本。在至少一个实施例中,接口2910不限于dmi总线,并且可以包括一个
或更多个外围组件互连总线(例如,pci,pci express)、存储器总线或其他类型的接口总线。在至少一个实施例中,处理器2902包括集成存储器控制器2916和平台控制器集线器2930。在至少一个实施例中,存储器控制器2916促进存储器设备与处理系统2900的其他组件之间的通信,而平台控制器集线器(pch)2930通过本地i/o总线提供到输入/输出(i/o)设备的连接。
[0372]
在至少一个实施例中,存储器设备2920可以是动态随机存取存储器(dram)设备、静态随机存取存储器(sram)设备、闪存设备、相变存储设备或具有适当的性能以用作处理器存储器。在至少一个实施例中,存储设备2920可以用作处理系统2900的系统存储器,以存储数据2922和指令2921,以在一个或更多个处理器2902执行应用程序或过程时使用。在至少一个实施例中,存储器控制器2916还与可选的外部图形处理器2912耦合,其可以与处理器2902中的一个或更多个图形处理器2908通信以执行图形和媒体操作。在至少一个实施例中,显示设备2911可以连接至处理器2902。在至少一个实施例中,显示设备2911可以包括内部显示设备中的一个或更多个,例如在移动电子设备或膝上型设备或通过显示器接口(例如显示端口(displayport)等)连接的外部显示设备中。在至少一个实施例中,显示设备2911可以包括头戴式显示器(hmd),诸如用于虚拟现实(vr)应用或增强现实(ar)应用中的立体显示设备。
[0373]
在至少一个实施例中,平台控制器集线器2930使外围设备能够通过高速i/o总线连接到存储设备2920和处理器2902。在至少一个实施例中,i/o外围设备包括但不限于音频控制器2946、网络控制器2934、固件接口2928、无线收发器2926、触摸传感器2925、数据存储设备2924(例如,硬盘驱动器、闪存等)。在至少一个实施例中,数据存储设备2924可以经由存储接口(例如,sata)或经由外围总线来连接,诸如外围组件互连总线(例如,pci、pcie)。在至少一个实施例中,触摸传感器2925可以包括触摸屏传感器、压力传感器或指纹传感器。在至少一个实施例中,无线收发器2926可以是wi-fi收发器、蓝牙收发器或移动网络收发器,诸如3g、4g或长期演进(lte)收发器。在至少一个实施例中,固件接口2928使能与系统固件的通信,并且可以是例如统一可扩展固件接口(uefi)。在至少一个实施例中,网络控制器2934可以启用到有线网络的网络连接。在至少一个实施例中,高性能网络控制器(未示出)与接口总线2910耦合。在至少一个实施例中,音频控制器2946是多通道高清晰度音频控制器。在至少一个实施例中,处理系统2900包括可选的传统(legacy)i/o控制器2940,用于将传统(例如,个人系统2(ps/2))设备耦合到系统2900。在至少一个实施例中,平台控制器集线器2930还可以连接到一个或更多个通用串行总线(usb)控制器2942,该控制器连接输入设备,诸如键盘和鼠标2943组合、相机2944或其他usb输入设备。
[0374]
在至少一个实施例中,存储器控制器2916和平台控制器集线器2930的实例可以集成到离散的外部图形处理器中,例如外部图形处理器2912。在至少一个实施例中,平台控制器集线器2930和/或存储器控制器2916可以在一个或更多个处理器2902的外部。例如,在至少一个实施例中,系统2900可以包括外部存储器控制器2916和平台控制器集线器2930,其可以配置成在与处理器2902通信的系统芯片组中的存储器控制器集线器和外围控制器集线器。
[0375]
在至少一个实施例中,系统2900可以使用具有多种加速器的多处理。例如,在至少一个实施例中,系统2900可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实
施例中,为了有效地使用加速器,系统2900可以实现如上所述的api,使得应用可以以简单的方式有效地使用加速资源。
[0376]
图30是根据至少一个实施例的具有一个或更多个处理器核心3002a-3002n、集成存储器控制器3014和集成图形处理器3008的处理器3000的框图。在至少一个实施例中,处理器3000可以包含附加核心,多达并包括以虚线框表示的附加核心3002n。在至少一个实施例中,每个处理器核心3002a-3002n包括一个或更多个内部高速缓存单元3004a-3004n。在至少一个实施例中,每个处理器核心还可以访问一个或更多个共享高速缓存单元3006。
[0377]
在至少一个实施例中,内部高速缓存单元3004a-3004n和共享高速缓存单元3006表示处理器3000内的高速缓存存储器层次结构。在至少一个实施例中,高速缓存存储器单元3004a-3004n可以包括每个处理器核心内的至少一级指令和数据高速缓存以及共享中级高速缓存中的一级或更多级缓存,例如2级(l2)、3级(l3)、4级(l4)或其他级别的高速缓存,其中将外部存储器之前的最高级别的高速缓存归类为llc。在至少一个实施例中,高速缓存一致性逻辑维持各种高速缓存单元3006和3004a-3004n之间的一致性。
[0378]
在至少一个实施例中,处理器3000还可包括一组一个或更多个总线控制器单元3016和系统代理核心3010。在至少一个实施例中,一个或更多个总线控制器单元3016管理一组外围总线,例如一个或更多个pci或pcie总线。在至少一个实施例中,系统代理核心3010为各种处理器组件提供管理功能。在至少一个实施例中,系统代理核心3010包括一个或更多个集成存储器控制器3014,以管理对各种外部存储器设备(未示出)的访问。
[0379]
在至少一个实施例中,一个或更多个处理器核心3002a-3002n包括对多线程同时进行的支持。在至少一个实施例中,系统代理核心3010包括用于在多线程处理期间协调和操作核心3002a-3002n的组件。在至少一个实施例中,系统代理核心3010可以另外包括电源控制单元(pcu),该电源控制单元包括用于调节处理器核心3002a-3002n和图形处理器3008的一个或更多个电源状态的逻辑和组件。
[0380]
在至少一个实施例中,处理器3000还包括用于执行图处理操作的图形处理器3008。在至少一个实施例中,图形处理器3008与共享高速缓存单元3006和包括一个或更多个集成存储器控制器3014的系统代理核心3010耦合。在至少一个实施例中,系统代理核心3010还包括用于驱动图形处理器输出到一个或更多个耦合的显示器的显示器控制器3011。在至少一个实施例中,显示器控制器3011也可以是经由至少一个互连与图形处理器3008耦合的独立模块,或者可以集成在图形处理器3008内。
[0381]
在至少一个实施例中,基于环的互连单元3012用于耦合处理器3000的内部组件。在至少一个实施例中,可以使用替代性互连单元,例如点对点互连、交换互连或其他技术。在至少一个实施例中,图形处理器3008经由i/o链路3013与环形互连3012耦合。
[0382]
在至少一个实施例中,i/o链路3013代表多种i/o互连中的至少一种,包括促进各种处理器组件与高性能嵌入式存储器模块3018(例如edram模块)之间的通信的封装i/o互连。在至少一个实施例中,处理器核心3002a-3002n和图形处理器3008中的每一个使用嵌入式存储器模块3018作为共享的最后一级高速缓存。
[0383]
在至少一个实施例中,处理器核心3002a-3002n是执行公共指令集架构的同质核心。在至少一个实施例中,处理器核心3002a-3002n在指令集架构(isa)方面是异构的,其中一个或更多个处理器核心3002a-3002n执行公共指令集,而一个或更多个其他处理器核心
3002a-3002n执行公共指令集的子集或不同指令集。在至少一个实施例中,就微架构而言,处理器核心3002a-3002n是异构的,其中具有相对较高功耗的一个或更多个核心与具有较低功耗的一个或更多个功率核心耦合。在至少一个实施例中,处理器3000可以在一个或更多个芯片上实现或被实现为soc集成电路。
[0384]
在至少一个实施例中,使用如上所述的api访问图形处理器3008。在至少一个实施例中,图形处理器3008是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,图形处理器3008接收作为通过api从应用程序获得的工作流的一部分的工作负载。
[0385]
图31是图形处理器3100的框图,该图形处理器可以是分立的图形处理单元,或者可以是与多个处理核心集成的图形处理器。在至少一个实施例中,图形处理器3100经由存储器映射的i/o接口与图形处理器3100上的寄存器以及放置在存储器中的命令进行通信。在至少一个实施例中,图形处理器3100包括用于访问存储器的存储器接口3114。在至少一个实施例中,存储器接口3114是到本地存储器、一个或更多个内部高速缓存、一个或更多个共享的外部高速缓存和/或到系统存储器的接口。
[0386]
在至少一个实施例中,图形处理器3100还包括用于将显示输出数据驱动到显示设备3120的显示控制器3102。在至少一个实施例中,显示控制器3102包括用于显示设备3120的一个或更多个覆盖平面的硬件以及多层视频或用户接口元素的组合。在至少一个实施例中,显示设备3120可以是内部或外部显示设备。在至少一个实施例中,显示设备3120是头戴式显示设备,例如虚拟现实(vr)显示设备或增强现实(ar)显示设备。在至少一个实施例中,图形处理器3100包括视频编解码器引擎3106,以将媒体编码、解码或转码为一个或更多个媒体编码格式,从一个或更多个媒体编码格式编码、解码或转码,或在一个或更多个媒体编码格式之间进行编码、解码或转码,所述媒体编码格式包括但不限于运动图像专家组(mpeg)格式(例如mpeg-2),高级视频编码(avc)格式(例如h.264/mpeg-4avc,以及美国电影电视工程师协会(smpte)421m/vc-1)和联合图像专家组(jpeg)格式(例如jpeg)和motion jpeg(mjpeg)格式。
[0387]
在至少一个实施例中,图形处理器3100包括块图像传送(blit)引擎3104,以执行二维(2d)光栅化器操作,包括例如位边界块传送。但是,在至少一个实施例中,使用图形处理引擎(gpe)3110的一个或更多个组件来执行2d图形操作。在至少一个实施例中,gpe 3110是用于执行图形操作(包括三维(3d)图形操作和媒体操作)的计算引擎。
[0388]
在至少一个实施例中,gpe 3110包括用于执行3d操作的3d管线3112,例如使用对3d图元形状(例如,矩形、三角形等)进行操作的处理功能来渲染三维图像和场景。3d管线3112包括执行各种任务和/或产生到3d/媒体子系统3115的执行线程的可编程和固定功能元素。虽然3d管线3112可用于执行媒体操作,但是在至少一个实施例中,gpe 3110还包括媒体管线3116,其用于执行媒体操作,诸如视频后处理和图像增强。
[0389]
在至少一个实施例中,媒体管线3116包括固定功能或可编程逻辑单元,用于执行一个或更多个专门的媒体操作,例如视频解码加速,视频去隔行和视频编码加速,代替或代表视频编解码器引擎3106。在至少一个实施例中,媒体管线3116还包括线程产生单元,用于产生线程以在3d/媒体子系统3115上执行。在至少一个实施例中,产生的线程在3d/媒体子系统3115中包含的一个或更多个图形执行单元上执行媒体操作的计算。
[0390]
在至少一个实施例中,3d/媒体子系统3115包括用于执行3d管线3112和媒体管线
3116产生的线程的逻辑。在至少一个实施例中,3d管线3112和媒体管线3116将线程执行请求发送到3d/媒体子系统3115,其包括用于仲裁各种请求并将其分派给可用线程执行资源的线程分派逻辑。在至少一个实施例中,执行资源包括用于处理3d和媒体线程的图形执行单元的阵列。在至少一个实施例中,3d/媒体子系统3115包括用于线程指令和数据的一个或更多个内部高速缓存。在至少一个实施例中,子系统3115还包括共享存储器,其包括寄存器和可寻址存储器,以在线程之间共享数据并存储输出数据。
[0391]
在至少一个实施例中,使用如上所述的api访问图形处理器3100。在至少一个实施例中,图形处理器3100是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,图形处理器3100接收作为通过api从应用程序获得的工作流的一部分的工作负载。
[0392]
图32是根据至少一个实施例的图形处理器的图形处理引擎3210的框图。在至少一个实施例中,图形处理引擎(gpe)3210是图31中所示的gpe 3110的版本。在至少一个实施例中,媒体管线3216是可选的,并且可以不显式地包括在gpe 3210中。在至少一个实施例中,单独的媒体和/或图像处理器耦合到gpe 3210。
[0393]
在至少一个实施例中,gpe 3210耦合到或包括命令流转化器3203,其向3d管线3212和/或媒体管线3216提供命令流。在至少一个实施例中,命令流转化器3203耦合到存储器,所述存储器可以是系统存储器,也可以是内部高速缓存存储器和共享高速缓存存储器中的一个或更多个。在至少一个实施例中,命令流转化器3203从存储器接收命令,并且将命令发送到3d管线3212和/或媒体管线3216。在至少一个实施例中,命令是从环形缓冲区中获取的指令、基元或微操作,该环形缓冲区存储用于3d管线3212和媒体管线3216的命令。在至少一个实施例中,环形缓冲区还可以包括存储各批多个命令的批命令缓冲区。在至少一个实施例中,用于3d管线3212的命令还可以包括对存储在存储器中的数据的引用,例如但不限于用于3d管线3212的顶点和几何数据和/或用于媒体管线3216的图像数据和存储器对象。在至少一个实施例中,3d管线3212和媒体管线3216通过执行操作或通过将一个或更多个执行线程分派到图形核心阵列3214,来处理命令和数据。在至少一个实施例中,图形核心阵列3214包括一个或更多个图形核心块(例如,一个或更多个图形核心3215a、一个或更多个图形核心3215b),每个块包括一个或更多个图形核心。在至少一个实施例中,每个图形核心包括一组图形执行资源,所述图形执行资源包括通用和图形特定的执行逻辑,用于执行图形和计算操作,以及固定功能纹理处理和/或机器学习和人工智能加速逻辑。
[0394]
在至少一个实施例中,3d管线3212包括固定功能和可编程逻辑,用于通过处理指令并将执行线程分派到图形核心阵列3214,来处理一个或更多个着色器程序,例如顶点着色器、几何着色器、像素着色器、片段着色器、计算着色器或其他着色器程序。在至少一个实施例中,图形核心阵列3214提供统一的执行资源块,所述执行资源块用于处理着色器程序。在至少一个实施例中,在图形核心阵列3214的图形核心3215a-3215b内的多用途执行逻辑(例如,执行单元)包括对各种3d api着色器语言的支持,并且可以执行与多个着色器关联的多个同时执行线程。
[0395]
在至少一个实施例中,图形核心阵列3214还包括执行逻辑,用于执行媒体功能,诸如视频和/或图像处理。在至少一个实施例中,除了图形处理操作之外,执行单元还包括可编程以执行并行通用计算操作的通用逻辑。
[0396]
在至少一个实施例中,输出数据可以将数据输出到统一返回缓冲区(urb)3218中
的存储器,所述输出数据由在图形核心阵列3214上执行的线程生成。在至少一个实施例中,urb 3218可以存储多个线程的数据。在至少一个实施例中,urb 3218可以用于在图形核心阵列3214上执行的不同线程之间发送数据。在至少一个实施例中,urb 3218还可用于图形核心阵列3214上的线程与共享功能逻辑3220内的固定功能逻辑之间的同步。
[0397]
在至少一个实施例中,图形核心阵列3214是可缩放的,使得图形核心阵列3214包括可变数量的图形核心,每个图形核心具有基于gpe 3210的目标功率和性能水平的可变数量的执行单元。在至少一个实施例中,执行资源是动态可伸缩的,使得执行资源可以根据需要被启用或禁用。
[0398]
在至少一个实施例中,图形核心阵列3214耦合到共享功能逻辑3220,该共享功能逻辑包括在图形核心阵列3214中的图形核心之间共享的多个资源。在至少一个实施例中,由共享功能逻辑3220执行的共享功能体现在向图形核心阵列3214提供专门的补充功能的硬件逻辑单元中。在至少一个实施例中,共享功能逻辑3220包括但不限于采样器3221、数学3222和线程间通信(itc)逻辑3223。在至少一个实施例中,一个或更多个高速缓存3225被包含在或耦合到共享功能逻辑3220中。
[0399]
在至少一个实施例中,如果对专用功能的需求不足以包含在图形核心阵列3214中,则使用共享功能。在至少一个实施例中,专用功能的单个实例在共享功能逻辑3220中使用,并且在图形核心阵列3214内的其他执行资源之间共享。在至少一个实施例中,特定共享功能可以包括在图形核心阵列3214内的共享功能逻辑3220内,所述特定共享功能在图形核心阵列3214广泛使用的共享功能逻辑3216内。在至少一个实施例中,图形核心阵列3214内的共享功能逻辑3216可包括共享功能逻辑3220内的一些或全部逻辑。在至少一个实施例中,共享功能逻辑3220内的所有逻辑元件可在图形核心阵列3214的共享功能逻辑3216内复制。在至少一个实施例中,排除共享功能逻辑3220,以支持图形核心阵列3214内的共享功能逻辑3216。
[0400]
在至少一个实施例中,使用如上所述的api访问图形核心阵列3214。在至少一个实施例中,图形核心阵列3214是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,图形核心阵列3214接收作为经由api从应用程序获得的工作流的一部分的工作负载。
[0401]
图33是根据本文所述的至少一个实施例的图形处理器核心3300的硬件逻辑的框图。在至少一个实施例中,图形处理器核心3300被包括在图形核心阵列内。在至少一个实施例中,图形处理器核心3300(有时称为核心切片)可以是模块化图形处理器内的一个或更多个图形核心。在至少一个实施例中,图形处理器核心3300是一个图形核心切片的示例,并且本文所述的图形处理器可以基于目标功率和性能包络线包括多个图形核心切片。在至少一个实施例中,每个图形核心3300可以包括与多个子核心3301a-3301f耦合的固定功能块3330,也称为子切片,其包括通用和固定功能逻辑的模块块。
[0402]
在至少一个实施例中,固定功能块3330包括几何和固定功能管线3336,例如,在较低性能和/或较低功率的图形处理器实施方式中,该几何和固定功能管线3336可以由图形处理器3300中的所有子核心共享。在至少一个实施例中,几何和固定功能管线3336包括3d固定功能管线、视频前端单元,线程产生器和线程分派器以及管理统一返回缓冲区的统一返回缓冲区管理器。
[0403]
在固定的至少一个实施例中,固定功能块3330还包括图形soc接口3337、图形微控
制器3338和媒体管线3339。图形soc接口3337提供了图形核心3300以及片上集成电路系统中的其他处理器核心之间的接口。在至少一个实施例中,图形微控制器3338是可编程子处理器,其可配置为管理图形处理器3300的各种功能,包括线程分派、调度和抢占。在至少一个实施例中,媒体管线3339包括有助于对包括图像和视频数据的多媒体数据进行解码、编码、预处理和/或后处理的逻辑。在至少一个实施例中,媒体管线3339经由对子核心3301-3301f内的计算或采样逻辑的请求来实现媒体操作。
[0404]
在至少一个实施例中,soc接口3337使图形核心3300能够与通用应用程序处理器核心(例如,cpu)和/或soc内的其他组件通信,包括存储器层次结构元素,诸如共享的最后一级高速缓存、系统ram和/或嵌入式片上或封装dram。在至少一个实施例中,soc接口3337还可以使得能够与soc内的固定功能设备(例如,相机成像管线)进行通信,并且使得能够使用和/或实现可以在图形核心3300和soc内部的cpu之间共享的全局存储器原子。在至少一个实施例中,soc接口3337还可以实现用于图形核心3300的电源管理控制,并且启用图形核心3300的时钟域与soc内的其他时钟域之间的接口。在至少一个实施例中,soc接口3337使得能够从命令流转化器和全局线程分派器接收命令缓冲区,其配置为向图形处理器内的一个或更多个图形核心中的每一个提供命令和指令。在至少一个实施例中,当要执行媒体操作时,可以将命令和指令分派给媒体管线3339,或者当要执行图形处理操作时,可以将其分配给几何形状和固定功能管线(例如,几何形状和固定功能管线3336,和/或几何形状和固定功能管线3314)。
[0405]
在至少一个实施例中,图形微控制器3338可以配置为对图形核心3300执行各种调度和管理任务。在至少一个实施例中,图形微控制器3338可以在子核心3301a-3301f中的执行单元(eu)阵列3302a-3302f、3304a-3304f内的各种图形并行引擎上执行图形和/或计算工作负载调度。在至少一个实施例中,在包括图形核心3300的soc的cpu核心上执行的主机软件可以提交多个图形处理器门铃之一的工作负载,其调用适当的图形引擎上的调度操作。在至少一个实施例中,调度操作包括确定接下来要运行哪个工作负载、将工作负载提交给命令流转化器、抢先在引擎上运行的现有工作负载、监控工作负载的进度以及在工作负载完成时通知主机软件。在至少一个实施例中,图形微控制器3338还可以促进图形核心3300的低功率或空闲状态,从而为图形核心3300提供在图形核心3300内独立于操作系统和/或系统上的图形驱动程序软件的跨低功率状态转换的保存和恢复寄存器的能力。
[0406]
在至少一个实施例中,图形核心3300可以具有比所示的子核心3301a-3301f多或少达n个模块化子核心。对于每组n个子核心,在至少一个实施例中,图形核心3300还可以包括共享功能逻辑3310、共享和/或高速缓存存储器3312、几何/固定功能管线3314以及附加的固定功能逻辑3316以加速各种图形和计算处理操作。在至少一个实施例中,共享功能逻辑3310可以包括可由图形核心3300内的每个n个子核心共享的逻辑单元(例如,采样器、数学和/或线程间通信逻辑)。在至少一个实施例中,共享和/或高速缓存存储器3312可以是图形核心3300内的n个子核心3301a-3301f的最后一级高速缓存,并且还可以用作可由多个子核心访问的共享存储器。在至少一个实施例中,可以包括几何/固定功能管线3314来代替固定功能块3330内的几何/固定功能管线3336,并且可以包括相同或相似的逻辑单元。
[0407]
在至少一个实施例中,图形核心3300包括附加的固定功能逻辑3316,其可以包括供图形核心3300使用的各种固定功能加速逻辑。在至少一个实施例中,附加的固定功能逻
辑3316包括用于仅位置着色中使用的附加的几何管线。在仅位置着色中,存在至少两个几何管线,而在几何和固定功能管线3316、3336内的完整几何管线和剔除管线中,其是可以包括在附加的固定功能逻辑3316中的附加几何管线。在至少一个实施例中,剔除管线是完整几何管线的修整版。在至少一个实施例中,完整管线和剔除管线可以执行应用程序的不同实例,每个实例具有单独的环境。在至少一个实施例中,仅位置着色可以隐藏被丢弃的三角形的长剔除运行,从而在某些情况下可以更早地完成着色。例如,在至少一个实施例中,附加固定功能逻辑3316中的剔除管线逻辑可以与主应用程序并行执行位置着色器,并且通常比完整管线更快地生成关键结果,因为剔除管线获取并遮蔽顶点的位置属性,无需执行光栅化和将像素渲染到帧缓冲区。在至少一个实施例中,剔除管线可以使用生成的临界结果来计算所有三角形的可见性信息,而与这些三角形是否被剔除无关。在至少一个实施例中,完整管线(在这种情况下可以称为重播管线)可以消耗可见性信息来跳过剔除的三角形以仅遮盖最终传递到光栅化阶段的可见三角形。
[0408]
在至少一个实施例中,附加的固定功能逻辑3316还可包括机器学习加速逻辑,例如固定功能矩阵乘法逻辑,用于实现包括用于机器学习训练或推理的优化。
[0409]
在至少一个实施例中,在每个图形子核心3301a-3301f内包括一组执行资源,其可用于响应于图形管线、媒体管线或着色器程序的请求来执行图形、媒体和计算操作。在至少一个实施例中,图形子核心3301a-3301f包括多个eu阵列3302a-3302f、3304a-3304f,线程分派和线程间通信(td/ic)逻辑3303a-3303f,3d(例如,纹理)采样器3305a-3305f,媒体采样器3306a-3306f,着色器处理器3307a-3307f和共享本地存储器(slm)3308a-3308f。在至少一个实施例中,eu阵列3302a-3302f、3304a-3304f每个都包含多个执行单元,这些执行单元是通用图形处理单元,能够为图形、媒体或计算操作提供服务,执行浮点和整数/定点逻辑运算,包括图形、媒体或计算着色器程序。在至少一个实施例中,td/ic逻辑3303a-3303f为子核心内的执行单元执行本地线程分派和线程控制操作,并促进在子核心的执行单元上执行的线程之间的通信。在至少一个实施例中,3d采样器3305a-3305f可以将与纹理或其他3d图形相关的数据读取到存储器中。在至少一个实施例中,3d采样器可以基于与给定纹理相关联的配置的采样状态和纹理格式来不同地读取纹理数据。在至少一个实施例中,媒体采样器3306a-3306f可以基于与媒体数据相关联的类型和格式来执行类似的读取操作。在至少一个实施例中,每个图形子核心3301a-3301f可以可替代地包括统一的3d和媒体采样器。在至少一个实施例中,在每个子核心3301a-3301f内的执行单元上执行的线程可以利用每个子核心内的共享本地存储器3308a-3308f,以使在线程组内执行的线程能够使用片上存储器的公共池来执行。
[0410]
在至少一个实施例中,使用如上所述的api访问图形核心3300。在至少一个实施例中,图形核心3300是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,图形核心3300接收作为通过api从应用程序获得的工作流的一部分的工作负载。
[0411]
图34a-34b示出了根据至少一个实施例的包括图形处理器核心的处理元件的阵列的线程执行逻辑3400。图34a示出了至少一个实施例,其中使用了线程执行逻辑3400。图34b示出了根据至少一个实施例的执行单元的示例性内部细节。
[0412]
如图34a中所示,在至少一个实施例中,线程执行逻辑3400包括着色器处理器3402、线程分派器3404、指令高速缓存3406、包括多个执行单元3408a-3408n的可缩放执行
单元阵列、采样器3410、数据高速缓存3412和数据端口3414。在至少一个实施例中,可缩放执行单元阵列可以例如基于工作负载的计算要求,通过启用或禁用一个或更多个执行单元(例如,执行单元3408a,3408b,3408c,3408d,至3408n-1和3408n中的任意一个)来动态缩放。在至少一个实施例中,可缩放执行单元通过链路到每个执行单元的互连结构互连。在至少一个实施例中,线程执行逻辑3400包括通过指令高速缓存3406、数据端口3414、采样器3410和执行单元3408a-3408n中的一个或更多个到存储器(诸如系统存储器或高速缓存存储器)的一个或更多个连接。在至少一个实施例中,每个执行单元(例如3408a)是独立的可编程通用计算单元,其能够执行多个同时的硬件线程,同时针对每个线程并行处理多个数据元素。在至少一个实施例中,执行单元3408a-3408n的阵列可缩放以包括任意数量的单独执行单元。
[0413]
在至少一个实施例中,执行单元3408a-3408n主要用于执行着色器程序。在至少一个实施例中,着色器处理器3402可以处理各种着色器程序并经由线程分派器3404来分派与着色器程序相关联的执行线程。在至少一个实施例中,线程分派器3404包括用于仲裁来自图形和媒体管线的线程初始化庆祝以及在执行单元3408a-3408n中的一个或更多个执行单元上实例化请求的线程的逻辑。例如,在至少一个实施例中,几何管线可以将顶点、镶嵌或几何着色器分派到线程执行逻辑以进行处理。在至少一个实施例中,线程分派器3404还可以处理来自执行着色器程序的运行时线程产生请求。
[0414]
在至少一个实施例中,执行单元3408a-3408n支持一种指令集,该指令集包括对许多标准3d图形着色器指令的本机支持,从而使图形库(例如direct 3d和opengl)中的着色器程序只需最少的转换即可执行。在至少一个实施例中,执行单元支持顶点和几何处理(例如,顶点程序、几何程序、顶点着色器)、像素处理(例如,像素着色器、片段着色器)和通用处理(例如,计算和媒体着色器)。在至少一个实施例中,每个执行单元3408a-3408n包括一个或更多个算术逻辑单元(alu),能够执行多发出单指令多数据(simd),并且多线程操作实现了高效的执行环境尽管有更高的延迟存储器访问。在至少一个实施例中,每个执行单元内的每个硬件线程具有专用的高带宽寄存器文件和相关的独立线程状态。在至少一个实施例中,执行是每个时钟到管线的多次发出,管线能够进行整数、单精度和双精度浮点运算、simd分支功能、逻辑运算、先验运算和其他其他运算。在至少一个实施例中,在等待来自存储器或共享功能之一的数据时,执行单元3408a-3408n内的依赖性逻辑使等待线程休眠直到返回了所请求的数据。在至少一个实施例中,当等待线程正在休眠时,硬件资源可以专用于处理其他线程。例如,在至少一个实施例中,在与顶点着色器操作相关联的延迟期间,执行单元可以对像素着色器、片段着色器或另一类型的着色器程序(包括不同的顶点着色器)执行操作。
[0415]
在至少一个实施例中,执行单元3408a-3408n中的每一个执行单元在数据元素的阵列上进行操作。在至少一个实施例中,多个数据元素是“执行大小”或指令的通道数。在至少一个实施例中,执行通道是用于指令内的数据元素访问、屏蔽和流控制的执行的逻辑单元。在至少一个实施例中,多个通道可以独立于用于特定图形处理器的多个物理算术逻辑单元(alu)或浮点单元(fpu)。在至少一个实施例中,执行单元3408a-3408n支持整数和浮点数据类型。
[0416]
在至少一个实施例中,执行单元指令集包括simd指令。在至少一个实施例中,各种
数据元素可以作为封装数据类型存储在寄存器中,并且执行单元将基于那些元素的数据大小来处理各种元素。例如,在至少一个实施例中,当对256位宽的向量进行操作时,将向量的256位存储在寄存器中,并且执行单元对向量进行操作,作为四个单独的64位封装数据元素(四字(qw)大小数据元素)、八个单独的32位封装数据元素(双字(dw)大小数据元素)、十六个单独的16位封装数据元素(单词(w)大小数据元素)或三十二个单独的8位数据元素(字节(b)大小的数据元素)。然而,在至少一个实施例中,不同的向量宽度和寄存器大小是可能的。
[0417]
在至少一个实施例中,一个或更多个执行单元可以被组合成具有通常融合eu的线程控制逻辑(3407a-3407n)的融合执行单元3409a-3409n。在至少一个实施例中,可以将多个eu融合成一个eu组。在至少一个实施例中,融合eu组中的eu的数量可以配置为执行单独的simd硬件线程。融合的eu组中的eu的数量可能根据各个实施例而变化。在至少一个实施例中,每个eu可以执行各种simd宽度,包括但不限于simd8、simd16和simd32。在至少一个实施例中,每个融合图形执行单元3409a-3409n包括至少两个执行单元。例如,在至少一个实施例中,融合执行单元3409a包括第一eu 3408a、第二eu 3408b以及第一eu 3408a和第二eu 3408b共有的线程控制逻辑3407a。在至少一个实施例中,线程控制逻辑3407a控制在融合图形执行单元3409a上执行的线程,从而允许融合执行单元3409a-3409n内的每个eu使用公共指令指针寄存器来执行。
[0418]
在至少一个实施例中,一个或更多个内部指令高速缓存(例如3406)被包括在线程执行逻辑3400中以高速缓存用于执行单元的线程指令。在至少一个实施例中,包括一个或更多个数据高速缓存(例如3412)以在线程执行期间高速缓存线程数据。在至少一个实施例中,包括采样器3410以提供用于3d操作的纹理采样和用于媒体操作的媒体采样。在至少一个实施例中,采样器3410包括专门的纹理或媒体采样功能,以在将采样数据提供给执行单元之前在采样过程中处理纹理或媒体数据。
[0419]
在执行期间,在至少一个实施例中,图形和媒体管线通过线程产生和分派逻辑将线程发起请求发送到线程执行逻辑3400。在至少一个实施例中,一旦一组几何对象已经被处理并光栅化成像素数据,则在着色器处理器3402内的像素处理器逻辑(例如,像素着色器逻辑、片段着色器逻辑等)被调用以进一步计算输出信息并且导致将结果写入输出表面(例如,颜色缓冲区、深度缓冲区、模板缓冲区等)。在至少一个实施例中,像素着色器或片段着色器计算要在光栅化对象上插值的各种顶点属性的值。在至少一个实施例中,着色器处理器3402内的像素处理器逻辑然后执行应用程序接口(api)提供的像素或片段着色器程序。在至少一个实施例中,为了执行着色器程序,着色器处理器3402经由线程分派器3404将线程分派到执行单元(例如3408a)。在至少一个实施例中,着色器处理器3402使用采样器3410中的纹理采样逻辑来访问存储在存储器中的纹理贴图中的纹理数据。在至少一个实施例中,对纹理数据和输入几何数据的算术运算为每个几何片段计算像素颜色数据,或者丢弃一个或更多个像素以进行进一步处理。
[0420]
在至少一个实施例中,数据端口3414提供了一种用于线程执行逻辑3400的存储器访问机制,以将处理后的数据输出到存储器以在图形处理器输出管线上进行进一步处理。在至少一个实施例中,数据端口3414包括或耦合到一个或更多个高速缓存存储器(例如,数据高速缓存3412)以高速缓存数据以便经由数据端口进行存储器访问。
[0421]
如图34b所示,在至少一个实施例中,图形执行单元3408可以包括指令获取单元3437、通用寄存器文件阵列(grf)3424、架构寄存器文件阵列(arf)3426、线程仲裁器3422、发送单元3430、分支单元3432、一组simd浮点单元(fpu)3434,以及在至少一个实施例中一组专用整数simd alu 3435。在至少一个实施例中,grf 3424和arf 3426包括一组与可以在图形执行单元3408中活跃的每个同时硬件线程相关联的通用寄存器文件和架构寄存器文件。在至少一个实施例中,在arf 3426中维护每个线程架构状态,而在线程执行期间使用的数据存储在grf 3424中。在至少一个实施例中,每个线程的执行状态,包括每个线程的指令指针,可以被保存在arf 3426中的线程专用寄存器中。
[0422]
在至少一个实施例中,图形执行单元3408具有一种架构,该架构是同时多线程(smt)和细粒度交错多线程(imt)的组合。在至少一个实施例中,架构具有模块化配置,该模块化配置可以在设计时基于同时线程的目标数量和每个执行单元的寄存器数量来进行微调,其中执行单元资源在用于执行多个同时线程的逻辑上分配。
[0423]
在至少一个实施例中,图形执行单元3408可以共同发布多个指令,每个指令可以是不同的指令。在至少一个实施例中,图形执行单元线程3408的线程仲裁器3422可以将指令分派到发送单元3430、分支单元3442或simd fpu 3434之一以供执行。在至少一个实施例中,每个执行线程可以访问grf 3424中的128个通用寄存器,其中每个寄存器可以存储32个字节,可以作为32位数据元素的simd 8元素向量进行访问。在至少一个实施例中,每个执行单元线程可以访问grf 3424中的4kb,尽管实施例不限于此,并且在其他实施例中可以提供更多或更少的寄存器资源。在至少一个实施例中,尽管每个执行单元的线程数量也可以根据实施例而变化,但是最多可以同时执行七个线程。在其中七个线程可以访问4kb的至少一个实施例中,grf 3424可以存储总共28kb。在至少一个实施例中,灵活的寻址模式可以允许将寄存器一起寻址以有效地建立更宽的寄存器或表示跨步的矩形块数据结构。
[0424]
在至少一个实施例中,经由由消息传递发送单元3430执行的“发送”指令来调度存储器操作、采样器操作和其他更长延迟的系统通信。在至少一个实施例中,将分支指令分派到专门的分支单元3432促进simd发散和最终收敛。
[0425]
在至少一个实施例中,图形执行单元3408包括一个或更多个simd浮点单元(fpu)3434,以执行浮点操作。在至少一个实施例中,一个或更多个fpu 3434还支持整数计算。在至少一个实施例中,一个或更多个fpu 3434可以simd执行多达m个32位浮点(或整数)运算,或者simd执行多达2m个16位整数或16位浮点运算。在至少一个实施例中,至少一个fpu提供扩展的数学能力以支持高吞吐量的先验数学函数和双精度64位浮点。在至少一个实施例中,还存在一组8位整数simd alu 3435,并且可以被专门优化以执行与机器学习计算相关的操作。
[0426]
在至少一个实施例中,可以在图形子核心分组(例如,子切片)中实例化图形执行单元3408的多个实例的阵列。在至少一个实施例中,执行单元3408可以跨多个执行通道执行指令。在至少一个实施例中,在图形执行单元3408上执行的每个线程在不同的通道上执行。
[0427]
在至少一个实施例中,图形执行单元3408可以使用具有多种加速器的多处理。例如,在至少一个实施例中,图形执行单元3408可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,图形执行单元3408可以实现如上所
述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0428]
图35示出了根据至少一个实施例的并行处理单元(“ppu”)3500。在至少一个实施例中,ppu 3500配置有机器可读代码,该机器可读代码如果由ppu 3500执行,则使得ppu 3500执行贯穿本公开描述的一些或全部过程和技术。在至少一个实施例中,ppu 3500是在一个或更多个集成电路设备上实现的多线程处理器,并且利用多线程作为被设计为处理在多个线程上并行执行的计算机可读指令(也称为机器可读指令或简单的指令)的延迟隐藏技术。在至少一个实施例中,线程是指执行线程,并且是被配置为由ppu 3500执行的一组指令的实例。在至少一个实施例中,ppu 3500是图形处理单元(“gpu”),图形处理单元配置为实现用于处理三维(“3d”)图形数据的图形渲染管线,以便生成用于在显示设备(诸如液晶显示器(“lcd”)设备)上显示的二维(“2d”)图像数据。在至少一个实施例中,ppu 3500用于执行计算,诸如线性代数运算和机器学习运算。图35仅出于说明性目的示出了示例并行处理器,并且应被解释为在本公开的范围内设想的处理器架构的非限制性示例,并且可以采用任何适当的处理器来对其进行补充和/或替代。
[0429]
在至少一个实施例中,一个或更多个ppu 3500配置成加速高性能计算(“hpc”)、数据中心和机器学习应用程序。在至少一个实施例中,ppu 3500配置成加速深度学习系统和应用程序,包括以下非限制性示例:自动驾驶汽车平台、深度学习、高精度语音、图像、文本识别系统、智能视频分析、分子模拟、药物发现、疾病诊断、天气预报、大数据分析、天文学、分子动力学模拟、财务建模、机器人技术、工厂自动化、实时语言转换、在线搜索优化以及个性化用户推荐等。
[0430]
在至少一个实施例中,ppu 3500包括但不限于输入/输出(“i/o”)单元3506、前端单元3510、调度器单元3512、工作分配单元3514、集线器3516、交叉开关(“xbar”)3520、一个或更多个通用处理集群(“gpc”)3518和一个或更多个分区单元(“存储器分区单元”)3522。在至少一个实施例中,ppu 3500通过一个或更多个高速gpu互连(“gpu互连”)3508连接到主机处理器或其他ppu 3500。在至少一个实施例中,ppu 3500通过互连3502连接到主机处理器或其他外围设备。在一个实施例中,ppu 3500连接到包括一个或更多个存储器设备(“存储器”)3504的本地存储器。在至少一个实施例中,存储器设备3504包括但不限于一个或更多个动态随机存取存储器(“dram”)设备。在至少一个实施例中,一个或更多个dram设备配置和/或可配置为高带宽存储器(“hbm”)子系统,并且在每个设备内堆叠有多个dram管芯。
[0431]
在至少一个实施例中,高速gpu互连3508可以指代系统使用其来进行缩放的基于线的多通道通信链路,并包括与一个或更多个中央处理单元结合的一个或更多个ppu 3500(“cpu”),支持ppu 3500和cpu之间的缓存相干以及cpu主控。在至少一个实施例中,高速gpu互连3508通过集线器3516将数据和/或命令传输到ppu 3500的其他单元,例如一个或更多个复制引擎、视频编码器、视频解码器、电源管理单元和/或在图35中可能未明确示出的其他组件。
[0432]
在至少一个实施例中,i/o单元3506配置为通过系统总线3502从主机处理器(图35中未示出)发送和接收通信(例如,命令、数据)。在至少一个实施例中,i/o单元3506直接通过系统总线3502或通过一个或更多个中间设备(例如存储器桥)与主机处理器通信。在至少一个实施例中,i/o单元3506可以经由系统总线3502与一个或更多个其他处理器(例如一个或更多个ppu 3500)通信。在至少一个实施例中,i/o单元3506实现外围组件互连express
(“pcie”)接口,用于通过pcie总线进行通信。在至少一个实施例中,i/o单元3506实现用于与外部设备通信的接口。
[0433]
在至少一个实施例中,i/o单元3506对经由系统总线3502接收的分组进行解码。在至少一个实施例中,至少一些分组表示被配置为使ppu 3500执行各种操作的命令。在至少一个实施例中,i/o单元3506如命令所指定的那样将解码的命令发送到ppu 3500的各种其他单元。在至少一个实施例中,命令被发送到前端单元3510和/或被发送到集线器3516或ppu 3500的其他单元,例如一个或更多个复制引擎、视频编码器、视频解码器、电源管理单元等(图35中未明确示出)。在至少一个实施例中,i/o单元3506配置为在ppu 3500的各种逻辑单元之间路由通信。
[0434]
在至少一个实施例中,由主机处理器执行的程序在缓冲区中对命令流进行编码,该缓冲区将工作负载提供给ppu 3500以进行处理。在至少一个实施例中,工作负载包括指令和要由那些指令处理的数据。在至少一个实施例中,缓冲区是可由主机处理器和ppu 3500两者访问(例如,读/写)的存储器中的区域—主机接口单元可以配置为访问经由i/o单元3506通过系统总线3502传输的存储器请求连接到系统总线3502的系统存储器中的缓冲区。在至少一个实施例中,主机处理器将命令流写入缓冲区,然后将指示命令流开始的指针发送给ppu 3500,使得前端单元3510接收指向一个或更多个命令流指针并管理一个或更多个命令流,从命令流中读取命令并将命令转发到ppu 3500的各个单元。
[0435]
在至少一个实施例中,前端单元3510耦合到调度器单元3512,该调度器单元3512配置各种gpc 3518以处理由一个或更多个命令流定义的任务。在至少一个实施例中,调度器单元3512配置为跟踪与调度器单元3512管理的各种任务有关的状态信息,其中状态信息可以指示任务被分配给哪个gpc 3518,任务是活跃的还是非活跃的,与任务相关联的优先级等等。在至少一个实施例中,调度器单元3512管理在一个或更多个gpc 3518上执行的多个任务。
[0436]
在至少一个实施例中,调度器单元3512耦合到工作分配单元3514,该工作分配单元3514配置为分派任务以在gpc 3518上执行。在至少一个实施例中,工作分配单元3514跟踪从调度器单元3512接收到的多个调度任务并且工作分配单元3514管理每个gpc 3518的待处理任务池和活动任务池。在至少一个实施例中,待处理任务池包括多个时隙(例如32个时隙),这些时隙包含分配给要由特定的gpc 3518处理的任务;活动任务池可包括用于由gpc 3518主动处理的任务的多个时隙(例如4个时隙),以使随着gpc 3518中的一个完成任务的执行,该任务将从gpc 3518的活动任务池中逐出,并且从待处理任务池中选择另一个任务,并安排其在gpc 3518上执行。在至少一个实施例中,如果活动任务在gpc 3518上处于空闲状态,例如在等待数据依赖性解决时,则活动任务从gpc 3518中驱逐并返回到待处理任务池,同时选择了待处理任务池中的另一个任务并调度在gpc 3518上执行。
[0437]
在至少一个实施例中,工作分配单元3514经由xbar 3520与一个或更多个gpc 3518通信。在至少一个实施例中,xbar 3520是互连网络,其将ppu 3500的许多单元耦合到ppu 3500的其他单元,并且可以配置为将工作分配单元3514耦合到特定的gpc 3518。在至少一个实施例中,一个或更多个ppu 3500的其他单元也可以通过集线器3516连接到xbar 3520。
[0438]
在至少一个实施例中,任务由调度器单元3512管理,并由工作分配单元3514分派
给gpc 3518之一。在至少一个实施例中,gpc 3518配置为处理任务并产生结果。在至少一个实施例中,结果可以由gpc 3518中的其他任务消耗,通过xbar 3520路由到不同的gpc 3518或存储在存储器3504中。在至少一个实施例中,结果可以通过分区单元3522写到存储器3504中,其实现了用于向存储器3504写入数据或从存储器3504读取数据的存储器接口。在至少一个实施例中,结果可以经由高速gpu互连3508传输到另一ppu 3504或cpu。在至少一个实施例中,ppu 3500包括但不限于u个分区单元3522,其等于耦合到ppu 3500的分离且不同的存储器设备3504的数量。在至少一个实施例中,分区单元3522将结合图37更详细地描述。
[0439]
在至少一个实施例中,主机处理器执行驱动器核心,该驱动程序核心实现应用程序编程接口(api),该应用程序编程接口使在主机处理器上执行的一个或更多个应用程序能够调度操作以在ppu 3500上执行。在一个实施例中,多个计算应用程序由ppu 3500同时执行,并且ppu 3500为多个计算应用程序提供隔离、服务质量(“qos”)和独立的地址空间。在至少一个实施例中,应用程序生成指令(例如,以api调用的形式),该指令使驱动器核心生成一个或更多个任务以供ppu 3500执行,并且驱动器核心将任务输出至由ppu 3500处理的一个或更多个流。在至少一个实施例中,每个任务包括一个或更多个相关线程组,其可以被称为线程束(warp)。在至少一个实施例中,线程束包括可以并行执行的多个相关线程(例如32个线程)。在至少一个实施例中,协作线程可以指代多个线程,包括用于执行任务并且通过共享存储器交换数据的指令,结合图37根据至少一个实施例更详细地描述了线程和协作线程。
[0440]
在至少一个实施例中,ppu 3500可以使用具有多种加速器的多处理。例如,在至少一个实施例中,ppu 3500可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,ppu 3500可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0441]
图36示出了根据至少一个实施例的通用处理集群(“gpc”)3600。在至少一个实施例中,gpc 3600是图35的gpc 3518。在至少一个实施例中,每个gpc 3600包括但不限于用于处理任务的多个硬件单元,并且每个gpc 3600包括但不限于管线管理器3602、预光栅操作单元(“prop”)3604、光栅引擎3608、工作分配交叉开关(“wdx”)3616、存储器管理单元(“mmu”)3618、一个或更多个数据处理集群(“dpc”)3606,以及部件的任何合适组合。
[0442]
在至少一个实施例中,gpc 3600的操作由管线管理器3602控制。在至少一个实施例中,管线管理器3602管理一个或更多个dpc 3606的配置,以处理分配给gpc 3600的任务。在至少一个实施例中,管线管理器3602配置一个或更多个dpc 3606中的至少一个以实现图形渲染管线的至少一部分。在至少一个实施例中,dpc 3606配置为在可编程流式多处理器(“sm”)3614上执行顶点着色器程序。在至少一个实施例中,管线管理器3602配置为将从工作分配单元接收的数据分组路由到gpc 3600内的适当逻辑单元,以及在至少一个实施例中,可以将一些数据分组路由到prop 3604和/或光栅引擎3608中的固定功能硬件单元,而可以将其他数据分组路由到dpc 3606以由原始引擎3612或sm 3614进行处理。在至少一个实施例中,管线管理器3602配置dpc 3606中的至少一个以实现神经网络模型和/或计算管线。
[0443]
在至少一个实施例中,prop单元3604配置为在至少一个实施例中将由光栅引擎
3608和dpc 3606生成的数据路由到分区单元3522中的光栅操作(“rop”)单元,上面结合图35更详细地描述。在至少一个实施例中,prop单元3604配置为执行用于颜色混合的优化、组织像素数据、执行地址转换等等。在至少一个实施例中,光栅引擎3608包括但不限于配置为执行各种光栅操作的多个固定功能硬件单元,并且在至少一个实施例中,光栅引擎3608包括但不限于设置引擎、粗光栅引擎、剔除引擎、裁剪引擎、精细光栅引擎、图块合计引擎及其任意合适的组合。在至少一个实施例中,设置引擎接收变换后的顶点并生成与由顶点定义的几何图元相关联的平面方程;平面方程式被传送到粗光栅引擎以生成基本图元的覆盖信息(例如,图块的x、y覆盖范围掩码);粗光栅引擎的输出将传输到剔除引擎,在剔除引擎中与z测试失败的图元相关联的片段将被剔除,并传输到剪切引擎,在剪切引擎中剪切位于视锥范围之外的片段。在至少一个实施例中,将经过裁剪和剔除的片段传递给精细光栅引擎,以基于设置引擎生成的平面方程式生成像素片段的属性。在至少一个实施例中,光栅引擎3608的输出包括将由任何适当的实体(例如,由在dpc 3606内实现的片段着色器)处理的片段。
[0444]
在至少一个实施例中,包括在gpc 3600中的每个dpc 3606包括但不限于m管线控制器(“mpc”)3610;图元引擎3612;一个或更多个sm 3614;及其任何合适的组合。在至少一个实施例中,mpc 3610控制dpc 3606的操作,将从管线管理器3602接收的分组路由到dpc 3606中的适当单元。在至少一个实施例中,将与顶点相关联的分组路由到图元引擎3612,图元引擎3612配置为从存储器中获取与顶点关联的顶点属性;相反,可以将与着色器程序相关联的数据分组发送到sm 3614。
[0445]
在至少一个实施例中,sm 3614包括但不限于可编程流式处理器,其配置为处理由多个线程表示的任务。在至少一个实施例中,sm 3614是多线程的并且配置为同时执行来自特定线程组的多个线程(例如32个线程),并且实现单指令、多数据(“simd”)架构,其中将一组线程(例如,线程束)中的每个线程配置为基于相同的指令集来处理不同的数据集。在至少一个实施例中,线程组中的所有线程执行相同指令。在至少一个实施例中,sm 3614实施单指令、多线程(“simt”)架构,其中一组线程中的每个线程配置为基于相同指令集来处理不同的数据集,但是其中线程组中的各个线程允许在执行期间发散。在至少一个实施例中,为每个线程束维护程序计数器、调用栈和执行状态,从而当线程束中的线程发散时,实现线程束和线程束内的串行执行之间的并发性。在另一个实施例中,为每个单独的线程维护程序计数器、调用栈和执行状态,从而使得在线程束内和线程束之间的所有线程之间具有相等的并发性。在至少一个实施例中,为每个单独的线程维持执行状态,并且可以收敛并并行地执行执行相同指令的线程以提高效率。本文更详细地描述sm 3614的至少一个实施例。
[0446]
在至少一个实施例中,mmu 3618在gpc 3600和存储器分区单元(例如,图35的分区单元3522)之间提供接口,并且mmu 3618提供虚拟地址到物理地址的转换、存储器保护以及存储器请求的仲裁。在至少一个实施例中,mmu 3618提供一个或更多个转换后备缓冲区(“tlb”),用于执行虚拟地址到存储器中的物理地址的转换。
[0447]
在至少一个实施例中,使用如上所述的api访问ppu 3500。在至少一个实施例中,ppu 3500是cpu用来执行给定任务的多个加速器之一。在至少一个实施例中,ppu 3500接收作为通过api从应用程序获得的工作流的一部分的工作负载。
[0448]
图37示出了根据至少一个实施例的并行处理单元(“ppu”)的存储器分区单元
3700。在至少一个实施例中,存储器分区单元3700包括但不限于光栅操作(“rop”)单元3702;二级(“l2”)高速缓存3704;存储器接口3706;及其任何合适的组合。在至少一个实施例中,存储器接口3706耦合到存储器。在至少一个实施例中,存储器接口3706可以实现32、64、128、1024位数据总线,或者类似的实现方式用于高速数据传输。在至少一个实施例中,ppu包括u个存储器接口3706,每对分区单元3700一个存储器接口3706,其中每对分区单元3700连接到对应的存储器设备。例如,在至少一个实施例中,ppu可以连接至多达y个存储器设备,例如高带宽存储器堆栈或图形双数据速率版本5同步动态随机存取存储器(“gddr5 sdram”)。
[0449]
在至少一个实施例中,存储器接口3706实现高带宽存储器第二代(“hbm2”)存储器接口,并且y等于u的一半。在至少一个实施例中,hbm2存储器堆栈位于相同物理封装上作为ppu,与传统的gddr5 sdram系统相比,可提供大量功率并节省面积。在至少一个实施例中,每个hbm2堆栈包括但不限于四个存储器管芯,且y=4,每个hbm2堆栈包括每个管芯两个128位通道,用于总共8个通道和1024位的数据总线宽度。在至少一个实施例中,存储器支持单错误校正双错误检测(“secded”)错误校正码(“ecc”)以保护数据。ecc可以为对数据损坏敏感的计算应用程序提供更高的可靠性。
[0450]
在至少一个实施例中,ppu实现了多级存储器层次结构。在至少一个实施例中,存储器分区单元3700支持统一存储器以为中央处理单元(“cpu”)和ppu存储器提供单个统一虚拟地址空间,从而实现虚拟存储器系统之间的数据共享。在至少一个实施例中,追踪ppu对位于其他处理器上的存储器的访问频率,以确保将存储器页面移动到更频繁地访问页面的ppu的物理存储器。在至少一个实施例中,高速gpu互连3508支持地址转换服务,其允许ppu直接访问cpu的页表,并通过ppu提供对cpu存储器的完全访问。
[0451]
在至少一个实施例中,复制引擎在多个ppu之间或ppu与cpu之间传输数据。在至少一个实施例中,复制引擎可以为未被映射到页表中的地址生成页面错误,并且存储器分区单元3700然后为页面错误提供服务,将地址映射到页表中,之后复制引擎执行传输。在至少一个实施例中,为多个处理器之间的多个复制引擎操作固定(即不可分页)存储器,从而实质上减少了可用存储器。在至少一个实施例中,在硬件页面故障的情况下,可以将地址传递给复制引擎,而无需考虑是否驻留存储器页,并且复制过程是透明的。
[0452]
根据至少一个实施例,来自图35的存储器3504或其他系统存储器的数据由存储器分区单元3700获取,并将其存储在l2高速缓存3704中,l2高速缓存3704位于芯片上并且在各种gpc之间共享。在至少一个实施例中,每个存储器分区单元3700包括但不限于与对应的存储器设备相关联的l2高速缓存的至少一部分。在至少一个实施例中,在gpc内的各个单元中实现较低级别的高速缓存。在至少一个实施例中,每个sm 3614可以实现一级(“l1”)高速缓存,其中l1高速缓存是专用于特定sm 3614的私有存储器,并且从l2高速缓存3704中获取数据并将其存储在每个l1高速缓存中,用于在sm 3614的功能单元中进行处理。在至少一个实施例中,l2高速缓存3704耦合到存储器接口3706和xbar 3520。
[0453]
在至少一个实施例中,rop单元3702执行与像素颜色有关的图形光栅操作,诸如颜色压缩、像素混合等。在至少一个实施例中,rop单元3702结合光栅引擎3608实施深度测试,从光栅引擎3608的剔除引擎接收与像素片段相关联的样本位置的深度。在至少一个实施例中,针对在与片段关联的样本位置的深度缓冲区中的相应深度测试深度。在至少一个实施
例中,如果该片段通过了针对该样本位置的该深度测试,则rop单元3702更新深度缓冲区,并将该深度测试的结果发送给光栅引擎3608。将意识到,分区单元3700的数量可以不同于gpc的数量,因此,可以在至少一个实施例中将每个rop单元3702耦合到每个gpc。在至少一个实施例中,rop单元3702追踪从不同gpc接收到的分组,并且确定rop单元3702生成的结果是否要通过xbar 3520路由到。
[0454]
图38示出了根据至少一个实施例的流式多处理器(“sm”)3800。在至少一个实施例中,sm 3800是图36的sm。在至少一个实施例中,sm 3800包括但不限于指令高速缓存3802;一个或更多个调度器单元3804;寄存器文件3808;一个或更多个处理核心(“核心”)3810;一个或更多个特殊功能单元(“sfu”)3812;一个或更多个加载/存储单元(“lsu”)3814;互连网络3816;共享存储器/一级(“l1”)高速缓存3818;以及/或其任何合适的组合。在至少一个实施例中,工作分配单元调度任务以在并行处理单元(“ppu”)的通用处理集群(“gpc”)上执行,并且每个任务被分配给gpc内部的特定数据处理集群(“dpc”),并且如果任务与着色器程序相关联,则将该任务分配给sm 3800之一。在至少一个实施例中,调度器单元3804从工作分配单元接收任务并管理分配给sm 3800的一个或更多个线程块的指令调度。在至少一个实施例中,调度器单元3804调度线程块以作为并行线程的线程束来执行,其中每个线程块被分配至少一个线程束。在至少一个实施例中,每个线程束执行线程。在至少一个实施例中,调度器单元3804管理多个不同的线程块,将线程束分配给不同的线程块,然后在每个时钟周期内将来自多个不同的协作组的指令分派给各种功能单元(例如,处理核心3810、sfu 3812和lsu 3814)。
[0455]
在至少一个实施例中,协作组可以指用于组织通信线程组的编程模型,其允许开发者表达线程正在通信的粒度,从而能够表达更丰富、更有效的并行分解。在至少一个实施例中,协作启动api支持线程块之间的同步以执行并行算法。在至少一个实施例中,常规编程模型的应用程序提供了用于同步协作线程的单一、简单的构造:跨线程块的所有线程的屏障(例如,syncthreads()函数)。但是,在至少一个实施例中,程序员可以在小于线程块粒度的情形下来定义线程组,并在所定义的组内进行同步,以实现更高的性能、设计灵活性以及以集合组范围功能接口的形式实现软件重用。在至少一个实施例中,协作组使程序员能够以子块(即,小到单个线程)和多块粒度明确定义线程组,并执行集合操作,例如对协作组中的线程进行同步。在至少一个实施例中,该编程模型支持跨软件边界的干净组合,从而库和实用程序功能可以在其本地环境中安全地同步,而不必进行关于收敛的假设。在至少一个实施例中,协作组图元使协作并行的新图案成为可能,包括但不限于生产者-消费者并行,机会主义并行以及整个线程块网格上的全局同步。
[0456]
在至少一个实施例中,调度单元3806配置为将指令发送到功能单元中的一个或更多个,并且调度器单元3804并包括但不限于两个调度单元3806,该两个调度单元3806使得来自相同线程束的两个不同指令能够在每个时钟周期被调度。在至少一个实施例中,每个调度器单元3804包括单个调度单元3806或附加调度单元3806。
[0457]
在至少一个实施例中,每个sm 3800在至少一个实施例中包括但不限于寄存器文件3808,该寄存器文件3808为sm 3800的功能单元提供了一组寄存器。在至少一个实施例中,寄存器文件3808在每个功能单元之间划分,从而为每个功能单元分配寄存器文件3808的专用部分。在至少一个实施例中,寄存器文件3808在由sm 3800执行的不同线程束之间划
分,并且寄存器文件3808为连接到功能单元的数据路径的操作数提供临时存储。在至少一个实施例中,每个sm 3800包括但不限于多个l个处理核心3810,其中l是正整数。在至少一个实施例中,sm 3800包括但不限于大量(例如128个或更多)不同的处理核心3810。在至少一个实施例中,每个处理核心3810包括但不限于全管线、单精度、双精度和/或混合精度处理单元,其包括但不限于浮点算术逻辑单元和整数算术逻辑单元。在至少一个实施例中,浮点算术逻辑单元实现用于浮点算术的ieee 754-2008标准。在至少一个实施例中,处理核心3810包括但不限于64个单精度(32位)浮点核心、64个整数核心、32个双精度(64位)浮点核心和8个张量核心。
[0458]
根据至少一个实施例,张量核心配置为执行矩阵运算。在至少一个实施例中,一个或更多个张量核心包括在处理核心3810中。在至少一个实施例中,张量核心配置为执行深度学习矩阵算术,例如用于神经网络训练和推理的卷积运算。在至少一个实施例中,每个张量核心在4
×
4矩阵上操作并且执行矩阵乘法和累加运算d=a
×
b c,其中a、b、c和d是4
×
4矩阵。
[0459]
在至少一个实施例中,矩阵乘法输入a和b是16位浮点矩阵,并且累加矩阵c和d是16位浮点或32位浮点矩阵。在至少一个实施例中,张量核心对16位浮点输入数据进行32位浮点累加运算。在至少一个实施例中,16位浮点乘法使用64个运算,并得到全精度乘积,然后使用32位浮点加法与其他中间乘积累加起来,以进行4x4x4矩阵乘法。在至少一个实施例中,张量核心用于执行由这些较小元件构成的更大的二维或更高维度的矩阵运算。在至少一个实施例中,api(诸如cuda 9c api)公开专门的矩阵加载、矩阵乘法和累加以及矩阵存储操作,以有效地使用来自cuda-c 程序的张量核心。在至少一个实施例中,在cuda级别,线程束级别接口假定跨越所有32个线程束线程的16
×
16大小的矩阵。
[0460]
在至少一个实施例中,每个sm 3800包括但不限于执行特殊功能(例如,属性评估、倒数平方根等)的m个sfu 3812。在至少一个实施例中,sfu 3812包括但不限于配置为遍历分层树数据结构的树遍历单元。在至少一个实施例中,sfu 3812包括但不限于配置为执行纹理映射过滤操作的纹理单元。在至少一个实施例中,纹理单元配置为从存储器中加载纹理映射(例如,纹理像素的2d阵列)和采样纹理映射,以产生采样的纹理值以供由sm 3800执行的着色器程序使用。在至少一个实施例中,将纹理映射存储在共享存储器/l1高速缓存3818中。在至少一个实施例中,根据至少一个实施例,纹理单元使用mip映射(mip-maps)(例如,细节级别不同的纹理映射)来实现纹理操作(诸如过滤操作)。在至少一个实施例中,每个sm 3800包括但不限于两个纹理单元。
[0461]
在至少一个实施例中,每个sm 3800包括但不限于实现共享存储器/l1高速缓存3818与寄存器文件3808之间的加载和存储操作的n个lsu 3814。在至少一个实施例中,每个sm 3800包括但不限于互连网络3816,其将每个功能单元连接到寄存器文件3808,并且lsu 3814连接到寄存器文件3808和共享存储器/l1高速缓存3818。在至少一个实施例中,互连网络3816是交叉开关,其可以配置为将任何功能单元连接到寄存器文件3808中的任何寄存器,并且将lsu 3814连接到寄存器文件3808和共享存储器/l1高速缓存3818中的存储器位置。
[0462]
在至少一个实施例中,共享存储器/l1高速缓存3818是片上存储器的阵列,其在至少一个实施例中允许sm 3800与图元引擎之间以及sm 3800中的线程之间的数据存储和通
信。在至少一个实施例中,共享存储器/l1高速缓存3818包括但不限于128kb的存储容量,并且位于从sm 3800到分区单元的路径中。在至少一个实施例中,共享存储器/l1高速缓存3818在至少一个实施例中用于高速缓存读取和写入。在至少一个实施例中,共享存储器/l1高速缓存3818、l2高速缓存和存储器中的一个或更多个是后备存储。
[0463]
在至少一个实施例中,将数据高速缓存和共享存储器功能组合到单个存储器块中,为两种类型的存储器访问提供了改进的性能。在至少一个实施例中,容量由不使用共享存储器的程序使用或将其用作高速缓存,例如如果共享存储器配置为使用一半容量,并且纹理和加载/存储操作可以使用剩余容量。根据至少一个实施例,在共享存储器/l1高速缓存3818内的集成使共享存储器/l1高速缓存3818能够用作用于流传输数据的高吞吐量管线,同时提供对频繁重用的数据的高带宽和低延迟访问。在至少一个实施例中,当配置用于通用并行计算时,与图形处理相比,可以使用更简单的配置。在至少一个实施例中,绕过固定功能图形处理单元,从而创建了更加简单的编程模型。在至少一个实施例中,在通用并行计算配置中,工作分配单元直接将线程的块分配和分布给dpc。在至少一个实施例中,块中的线程执行相同程序,在计算中使用唯一的线程id以确保每个线程生成唯一的结果,使用sm 3800执行程序并执行计算,使用共享存储器/l1高速缓存3818在线程之间进行通信,以及使用lsu 3814通过共享存储器/l1高速缓存3818和存储器分区单元来读写全局存储器。在至少一个实施例中,当被配置用于通用并行计算时,sm 3800向调度器单元3804写入可以用来在dpc上启动新工作的命令。
[0464]
在至少一个实施例中,ppu被包括在台式计算机、膝上型计算机、平板电脑、服务器、超级计算机、智能电话(例如,无线、手持设备)、个人数字助理(“pda”)、数码相机、车辆、头戴式显示器、手持式电子设备等中或与之耦合。在至少一个实施例中,ppu被实现在单个半导体衬底上。在至少一个实施例中,ppu与一个或更多个其他设备(例如附加的ppu、存储器、精简指令集计算机(“risc”)cpu,一个或更多个存储器管理单元(“mmu”)、数模转换器(“dac”)等)一起被包括在片上系统(“soc”)中。
[0465]
在至少一个实施例中,ppu可以被包括在包括一个或更多个存储设备的图形卡上。在至少一个实施例中,该图形卡可以配置为与台式计算机主板上的pcie插槽相连接。在至少一个实施例中,该ppu可以是包括在主板的芯片组中的集成图形处理单元(“igpu”)。
[0466]
在至少一个实施例中,ppu 3500可以使用具有多种加速器的多处理。例如,在至少一个实施例中,ppu 3500可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,ppu 3500可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0467]
在至少一个实施例中,单个半导体平台可以指唯一的单一基于半导体的集成电路或芯片。在至少一个实施例中,可以使用具有增加的连接性的多芯片模块,其模拟芯片上的操作,并且相对于利用传统的中央处理单元(“cpu”)和总线实现方式进行了实质性的改进。在至少一个实施例中,根据用户的需求,各种模块也可以分开放置或以半导体平台的各种组合放置。
[0468]
在至少一个实施例中,机器可读的可执行代码或计算机控制逻辑算法形式的计算机程序被存储在主存储器1804和/或辅助存储中。根据至少一个实施例,如果由一个或更多个处理器执行,则计算机程序使系统1800能够执行各种功能。在至少一个实施例中,存储器
1804、存储和/或任何其他存储是计算机可读介质的可能示例。在至少一个实施例中,辅助存储可以指代任何合适的存储设备或系统,例如硬盘驱动器和/或可移除存储驱动器,其代表软盘驱动器、磁带驱动器、光盘驱动器、数字多功能盘(“dvd”)驱动器、记录设备、通用串行总线(“usb”)闪存等。在至少一个实施例中,各个先前附图的架构和/或功能是在cpu 1802;并行处理系统1812;能够具有两个cpu 1802的至少部分能力的集成电路;并行处理系统1812;芯片组(例如,设计成作为执行相关功能的单元工作并出售的一组集成电路等);以及集成电路的任何适当组合的环境中实现的。
[0469]
在至少一个实施例中,各个先前附图的架构和/或功能在通用计算机系统、电路板系统、专用于娱乐目的的游戏控制台系统、专用系统等的环境中实现。在至少一个实施例中,计算机系统1800可以采取台式计算机、膝上型计算机、平板电脑、服务器、超级计算机、智能电话(例如,无线、手持设备)、个人数字助理(“pda”)、数码相机、车辆、头戴式显示器、手持式电子设备、移动电话设备、电视、工作站、游戏机、嵌入式系统和/或任何其他类型的逻辑的形式。
[0470]
在至少一个实施例中,并行处理系统1812包括但不限于多个并行处理单元(“ppu”)1814和相关联的存储器1816。在至少一个实施例中,ppu 1814经由互连1818和交换机1820或多路复用器连接到主机处理器或其他外围设备。在至少一个实施例中,并行处理系统1812在可并行化的ppu 1814上分配计算任务,例如,作为跨多个图形处理单元(“gpu”)线程块的计算任务分布的一部分。在至少一个实施例中,在ppu 1814中的一些或全部之间共享和访问存储器(例如,用于读取和/或写入访问),尽管这种共享存储器可能引发相对于使用本地存储器和驻留在ppu 1814上的寄存器的性能损失。在至少一个实施例中,通过使用命令(诸如__syncthreads())来同步ppu 1814的操作,其中块中的所有线程(例如,跨多个ppu 1814执行)在进行之前到达某个代码执行点。
[0471]
网络
[0472]
图39示出了根据至少一个实施例的用于在5g无线通信网络内传送数据的网络3900。在至少一个实施例中,网络3900包括具有覆盖区域3904的基站3906、多个移动设备3908和回程网络3902。在至少一个实施例中,如图所示,基站3906建立上行链路和/或下行链路与移动设备3908连接,用于将数据从移动设备3908传送到基站3906,反之亦然。在至少一个实施例中,通过上行链路/下行链路连接承载的数据可以包括在移动设备3908之间传送的数据,以及通过回程网络3902的方式传送到/来自远程端(未示出)的数据。在至少一个实施例中,术语“基站”是指被配置为提供对网络的无线接入的任何组件(或组件的集合),例如增强型基站(enb)、宏小区、毫微微小区、wi-fi接入点(ap)或其他启用无线功能的设备。在至少一个实施例中,基站可以根据一种或更多种无线通信协议提供无线接入,例如长期演进(lte)、高级lte(lte-a)、高速分组接入(hspa)、wi-fi 802.11a/b/g/n/ac等。在至少一个实施例中,术语“移动设备”是指能够与基站建立无线连接的任何组件(或组件的集合),例如用户设备(ue)、移动站(sta)和其他启用无线功能的设备。在一些实施例中,网络3900可以包括各种其他无线设备,例如中继、低功率节点等。
[0473]
在至少一个实施例中,移动设备3908可以使用具有多种加速器的多处理。例如,在至少一个实施例中,移动设备3908可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,移动设备3908可以实现如上所述的api,使得应
用程序可以以简单的方式有效地使用加速资源。
[0474]
图40示出了根据至少一个实施例的用于5g无线网络的网络架构4000。在至少一个实施例中,如图所示,网络架构4000包括无线电接入网(ran)4004、演进分组核心(epc)4002,其可以被称为核心网络,以及ue 4008的归属网络4016尝试接入ran 4004。在至少一个实施例中,ran 4004和epc 4002形成服务无线网络。在至少一个实施例中,ran 4004包括基站4006,并且epc 4002包括移动性管理实体(mme)4012、服务网关(sgw)4010和分组数据网络(pdn)网关(pgw)4014。在至少一个实施例中,归属网络4016包括应用服务器4018和归属用户服务器(hss)4020。在至少一个实施例中,hss 4020可以是归属网络4016、epc 4002和/或其变体的一部分。
[0475]
在至少一个实施例中,mme 4012是网络中的终端点,用于nas信令的加密/完整性保护并处理安全密钥管理。在至少一个实施例中,应当理解,术语“mme”用在4g lte网络中,并且5g lte网络可以包括执行类似功能的安全锚节点(sean)或安全访问功能(seaf)。在至少一个实施例中,术语“mme”、“sean”和“seaf”可以互换使用。在至少一个实施例中,mme 4012还提供用于lte和2g/3g接入网络之间的移动性的控制平面功能,以及到漫游ue的归属网络的接口。在至少一个实施例中,sgw 4010路由和转发用户数据分组,同时在切换期间还充当用户平面的移动锚点。在至少一个实施例中,pgw 4014通过作为ue业务的出口和入口点来提供从ue到外部分组数据网络的连接性。在至少一个实施例中,hss 4020是包含用户相关和订阅相关信息的中央数据库。在至少一个实施例中,应用服务器4018是中央数据库,其包含关于可以利用网络架构4000并经由网络架构4000进行通信的各种应用的用户相关信息。
[0476]
图41是示出根据至少一个实施例的根据lte和5g原理操作的移动电信网络/系统的一些基本功能的图。在至少一个实施例中,移动电信系统包括基础设施设备,该基础设施设备包括连接到核心网络4102的基站4114,核心网络4102根据熟悉通信技术的人将理解的常规布置进行操作。在至少一个实施例中,基础设施设备4114也可以被称为例如基站、网元、增强型节点b(enodeb)或协调实体,并且为覆盖区域内的一个或更多个通信设备提供无线接入接口或由虚线4104表示的小区,其可以称为无线接入网。在至少一个实施例中,一个或更多个移动通信设备4106可以使用无线接入接口经由表示数据的信号的发送和接收来传送数据。在至少一个实施例中,核心网络4102还可以为网络实体所服务的通信设备提供包括认证、移动性管理、计费等功能。
[0477]
在至少一个实施例中,图41的移动通信设备还可以被称为通信终端、用户设备(ue)、终端设备等,并且被配置为经由网络实体与由相同或不同覆盖区域服务的一个或更多个其他通信设备进行通信。在至少一个实施例中,这些通信可以通过使用无线接入接口在双向通信链路上发送和接收表示数据的信号来执行。
[0478]
在至少一个实施例中,如图41所示,更详细地示出了enodeb 4114a之一包括用于经由无线接入接口向一个或更多个通信设备或ue 4106发送信号的发射器4112,以及用于从覆盖区域4104内的一个或更多个ue接收信号的接收器4110。在至少一个实施例中,控制器4108控制发送器4112和接收器4110通过无线接入接口发送和接收信号。在至少一个实施例中,控制器4108可以执行控制无线接入接口的通信资源元素的分配的功能,并且在一些示例中可以包括用于调度经由无线接入接口用于上行链路和下行链路的传输的调度器。
[0479]
在至少一个实施例中,示例ue 4106a被更详细地示出为包括用于在无线接入接口的上行链路上向enodeb 4114发送信号的发射器4120和用于经由无线接入接口在下行链路上接收由enodeb 4114发送的信号的接收器4118。在至少一个实施例中,发射器4120和接收器4118由控制器4116控制。
[0480]
图42示出了根据至少一个实施例的可以是5g网络架构的一部分的无线电接入网络4200。在至少一个实施例中,无线电接入网络4200覆盖地理区域,该地理区域划分为多个蜂窝区域(小区(cell)),用户设备(ue)基于从一个接入点或者基站在地理区域上广播的标识来唯一地标识这些蜂窝区域(小区)。在至少一个实施例中,宏小区4240、4228和4216以及小小区4230可以包括一个或更多个扇区。在至少一个实施例中,扇区是小区的子区域并且一个小区内的所有扇区都由同一个基站服务。在至少一个实施例中,属于该扇区的单个逻辑标识可以标识扇区内的无线电链路。在至少一个实施例中,小区内的多个扇区可以由天线组形成,每个天线负责与小区的一部分中的ue进行通信。
[0481]
在至少一个实施例中,每个小区由基站(bs)服务。在至少一个实施例中,基站是无线电接入网络中的网络元件,负责在一个或更多个小区中去往或来自ue的无线电传输和接收。在至少一个实施例中,基站还可以称为基站收发台(bts)、无线电基站、无线电收发机、收发功能、基本服务集(bss)、扩展服务集(ess))、接入点(ap)、节点b(nb)、enodeb(enb)、gnodeb(gnb)或一些其他合适的术语。在至少一个实施例中,基站可以包括用于与网络的回程部分进行通信的回程接口。在至少一个实施例中,基站具有集成天线或通过馈电电缆连接到天线或远程无线电头端(rrh)。
[0482]
在至少一个实施例中,回程可以提供基站和核心网络之间的链路,并且在一些示例中,回程可以提供各个基站之间的互连。在至少一个实施例中,核心网络是无线通信系统的一部分,其通常独立于无线电接入网络中使用的无线电接入技术。在至少一个实施例中,可以采用各种类型的回程接口,例如使用任何合适的传输网络的直接物理连接、虚拟网络等。在至少一个实施例中,一些基站可以被配置为集成接入和回程(iab)节点,其中无线频谱既可以用于接入链路(即与ue的无线链路),也可以用于回程链路,这有时是称为无线自回程。在至少一个实施例中,通过无线自回程,用于基站和ue之间通信的无线频谱可以被用于回程通信,从而能够快速和容易地部署高密度小小区网络,而不是需要每个新基站站部署配备自己的硬线回程连接。
[0483]
在至少一个实施例中,高功率基站4236和4220显示在小区4240和4228中,并且高功率基站4210显示为控制小区4216中的远程无线电头端(rrh)4212。在至少一个实施例中,小区4240、4228和4216可以被称为大尺寸小区或宏小区。在至少一个实施例中,低功率基站4234示于小型小区4230(例如,微小区、微微小区、毫微微小区、家庭基站、家庭节点b、家庭enodeb等)中,其可以与一个或更多个宏小区重叠,并且可以被称为小小区或小尺寸小区。在至少一个实施例中,可以根据系统设计以及组件约束来确定小区尺寸。在至少一个实施例中,可以部署中继节点以扩展给定小区的尺寸或覆盖区域。在至少一个实施例中,无线电接入网络4200可以包括任意数量的无线基站和小区。在至少一个实施例中,基站4236、4220、4210、4234为任意数量的移动装置提供到核心网络的无线接入点。
[0484]
在至少一个实施例中,四轴飞行器或无人机4242可以被配置为用作基站。在至少一个实施例中,小区不一定是静止的,小区的地理区域可以根据移动基站(诸如四轴飞行器
4242)的位置而移动。
[0485]
在至少一个实施例中,无线电接入网络4200支持多个移动装置的无线通信。在至少一个实施例中,移动装置通常被称为用户设备(ue),但也可以被称为移动站(ms)、用户站、移动单元、用户单元、无线单元、远程单元、移动设备、无线设备、无线通信设备、远程设备、移动用户站、接入终端(at)、移动终端、无线终端、远程终端、手机、终端、用户代理、移动客户端、客户端或其他一些合适的术语。在至少一个实施例中,ue可以是向用户提供对网络服务的访问的装置。
[0486]
在至少一个实施例中,“移动”装置不必具有移动的能力,并且可以是静止的。在至少一个实施例中,移动装置或移动设备泛指各种不同的设备和技术。在至少一个实施例中,移动装置可以是手机、蜂窝(cell)电话、智能电话、会话发起协议(sip)电话、膝上型计算机、个人计算机(pc)、笔记本、上网本、智能本、平板电脑、个人数字助理(pda)、广泛的嵌入式系统,例如对应于“物联网”(iot)、汽车或其他交通工具、远程传感器或执行器、机器人或机器人设备、卫星无线电、全球定位系统(gps)设备、对象跟踪设备、无人机、多旋翼飞行器、四旋翼飞行器、遥控设备、消费者和/或可穿戴设备,例如眼镜、可穿戴相机、虚拟现实设备、智能手表、健康或健身追踪器、数字音频播放器(例如mp3播放器)、相机、游戏机、数字家庭或智能家居设备(例如家庭)音频、视频和/或多媒体设备、电器、自动售货机、智能照明、家庭安全系统、智能手机等,安全设备,太阳能电池板或太阳能电池板,控制电力(例如,智能电网),照明,水等的市政基础设施设备,工业自动化和企业设备,物流控制器,农业设备,军事防御设备、车辆、飞机、船舶和武器等。在至少一个实施例中,移动装置可以提供连接的医学或远程医疗支持,即远距离的医疗保健。在至少一个实施例中,远程医疗设备可以包括远程医疗监控设备和远程医疗管理设备,其通信可以被给予优先处理或优先于其他类型信息的访问,例如,在关键服务数据传输的优先访问方面,和/或用于传输关键服务数据的相关qos。
[0487]
在至少一个实施例中,无线电接入网络4200的小区可以包括可以与每个小区的一个或更多个扇区通信的ue。在至少一个实施例中,ue 4214和4208可以通过rrh 4212与基站4210通信;ue 4222和4226可以与基站4220通信;ue 4232可以与低功率基站4234通信;ue 4238和4218可以与基站4236通信;ue 4244可以与移动基站4242通信。在至少一个实施例中,每个基站4210、4220、4234、4236和4242可以被配置为为各个小区中的所有ue提供到所有的核心网络(未示出)的接入点以及从基站(例如,基站4236)到一个或更多个ue(例如,ue 4238和4218)的传输可以称为下行链路(dl)传输,而从ue(例如,ue 4238)到基站可以被称为上行链路(ul)传输。在至少一个实施例中,下行链路可以指点对多点传输,其可以被称为广播信道复用。在至少一个实施例中,上行链路可以指点对点传输。
[0488]
在至少一个实施例中,可以被称为移动网络节点的四轴飞行器4242可以被配置为通过与基站4236通信来充当小区4240内的ue。在至少一个实施例中,多个ue(例如,ue 4222和4226)可以使用对等(p2p)或旁链路信号4224彼此通信,其可以绕过基站(诸如基站4220)。
[0489]
在至少一个实施例中,ue在移动时与其位置无关地进行通信的能力被称为移动性。在至少一个实施例中,移动性管理实体(mme)建立、维护和释放ue和无线电接入网络之间的各种物理信道。在至少一个实施例中,无线电接入网络4200可以利用基于dl的移动性
或基于ul的移动性来实现移动性和切换(即,将ue的连接从一个无线电信道转移到另一无线电信道)。在至少一个实施例中,ue在配置用于基于dl的移动性的网络中可以监视来自其服务小区的信号的各种参数以及相邻小区的各种参数,并且根据这些参数的质量,ue可以保持与一个或更多个相邻小区的通信。在至少一个实施例中,如果在给定的时间量内来自相邻小区的信号质量超过来自服务小区的信号质量,或者如果ue从一个小区移动到另一小区,则ue可以进行从服务小区到相邻(或目标)小区的切换或切换。在至少一个实施例中,ue 4218(图示为车辆,但可以使用任何合适形式的ue)可以从对应于小区(例如服务小区4240)的地理区域移动到对应于相邻小区(例如相邻小区4216)的地理区域。在至少一个实施例中,在给定的时间内,当来自相邻小区4216的信号强度或质量超过其服务小区4240的信号强度或质量时,ue 4218可以向其服务基站4236发送报告消息以指示其状况。在至少一个实施例中,ue 4218可以接收切换命令,并且可以经历切换到小区4216。
[0490]
在至少一个实施例中,来自每个ue的ul参考信号可以被配置用于基于ul的移动性的网络用来为每个ue选择服务小区。在至少一个实施例中,基站4236、4220和4210/4212可以广播统一同步信号(例如统一主同步信号(pss)、统一次同步信号(sss)和统一物理广播信道(pbch))。在至少一个实施例中,ue 4238、4218、4222、4226、4214和4208可以接收统一的同步信号,从同步信号中导出载频和时隙定时,并且响应于导出的定时,发送上行链路导频或参考信号。在至少一个实施例中,无线电接入网络4200内的两个或更多个小区(例如,基站4236和4210/4212)可以同时接收由ue(例如,ue 4218)发送的上行链路导频信号。在至少一个实施例中,小区可以测量导频信号的强度,并且无线电接入网络(例如,基站4236和4210/4212中的一个或更多个和/或核心网络内的中央节点)可以确定ue 4218的服务小区。在至少一个实施例中,当ue 4218通过无线电接入网络4200移动时,网络可以继续监视由ue 4218发送的上行链路导频信号。在至少一个实施例中,当相邻小区测量的导频信号的信号强度或质量超过服务小区测量的信号强度或质量时,网络4200可以将ue 4218从服务小区切换给相邻小区,通知或不通知ue 4218。
[0491]
在至少一个实施例中,由基站4236、4220和4210/4212发送的同步信号可以是统一的,但是可以不识别特定小区,而是可以识别以相同频率和/或在相同的时间操作的多个小区的区域。在至少一个实施例中,5g网络或其他下一代通信网络中的区域启用基于上行链路的移动性框架并提高ue和网络的效率,因为需要在ue和网络之间交换的移动性消息的数量可能被减少。
[0492]
在至少一个实施例中,无线电接入网络4200中的空中接口可以利用未授权频谱、授权频谱或共享频谱。在至少一个实施例中,未授权频谱提供频谱的一部分的共享使用而无需政府授予的许可,然而,虽然通常仍然需要遵守一些技术规则才能访问未授权频谱,通常,任何运营商或设备可能获得访问权限。在至少一个实施例中,授权频谱提供对频谱的一部分的排他使用,通常依靠移动网络运营商从政府监管机构购买许可。在至少一个实施例中,共享频谱可能介于授权频谱和未授权频谱之间,其中可能需要技术规则或限制来访问频谱,但频谱仍可能由多个运营商和/或更多个rat共享。例如,在至少一个实施例中,授权频谱的一部分的许可的持有者可以提供许可共享接入(lsa)以与其他方共享该频谱,例如,以合适许可确定条件来获得接入。
[0493]
在至少一个实施例中,基站4236、4220和4210/4212可以使用具有多种加速器的多
处理。在至少一个实施例中,例如,基站4236、4220和4210/4212可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,基站4236、4220和4210/4212可以实现如上所述的api,使得应用可以以简单的方式有效地使用加速资源。
[0494]
图43提供了根据至少一个实施例的其中使用多种不同类型的设备的5g移动通信系统的示例图示。在至少一个实施例中,如图43所示,第一基站4318可以被提供给信号传输超过几公里的大型小区或宏小区。然而,在至少一个实施例中,系统还可以支持经由非常小的小区的传输,例如由第二基础设施设备4316传输,第二基础设施设备4316在数百米的距离上发送和接收信号,从而形成所谓的“微微”小区。在至少一个实施例中,第三类基础设施设备4312可以在数十米的距离上发送和接收信号,因此可以用于形成所谓的“毫微微”小区。
[0495]
在至少一个实施例中,也在图43中示出,不同类型的通信设备可以用于经由不同类型的基础设施设备4312、4316、4318来发送和接收信号,并且可以根据使用不同通信参数的不同类型的基础设施设备来适配数据通信。在至少一个实施例中,传统上,移动通信设备可以被配置为经由网络的可用通信资源向和从移动通信网络传送数据。在至少一个实施例中,无线接入系统被配置为向诸如智能电话4306的设备提供最高数据速率。在至少一个实施例中,可以提供“物联网”,其中低功率机器类型通信设备以非常低的功率、低带宽和可能具有低复杂性发送和接收数据。在至少一个实施例中,这种机器类型通信设备4314的示例可以经由微微小区4316进行通信。在至少一个实施例中,非常高的数据速率和低移动性可以是与例如电视4304通信的特征,它可以通过微微(pico)小区进行通信。在至少一个实施例中,虚拟现实耳机4308可能需要非常高的数据速率和低延迟。在至少一个实施例中,可以部署中继设备4310以扩展给定小区或网络的大小或覆盖区域。
[0496]
在至少一个实施例中,基础设施设备4312、4316、4318可以使用具有多种加速器的多处理。在至少一个实施例中,例如,基础设施设备4312、4316、4318可以具有cpu以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,基础设施设备4312、4316、4318可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0497]
图44示出了示例高级系统4400,其中可以使用至少一个实施例。在至少一个实施例中,高级系统4400包括应用程序4402、系统软件 库4404、框架软件4406和数据中心基础设施 资源协调器4408。在至少一个实施例中,高级系统4400可以被实现为云服务、物理服务、虚拟服务、网络服务和/或其变体。
[0498]
在至少一个实施例中,如图44所示,数据中心基础设施 资源协调器4408可以包括5g无线电资源协调器4410、gpu分组处理和i/o 4412、以及节点计算资源(“节点c.r.”)4416(1)-4416(n),其中“n”代表任何整数,正整数。在至少一个实施例中,节点c.r.4416(1)-4416(n)可以包括但不限于任何数量的中央处理单元(“cpu”)或其他处理器(包括加速器、现场可编程门阵列(fpga)、图形处理器(“gpu”)等)、内存设备(例如,动态只读内存)、存储设备(例如,固态或磁盘驱动器)、网络输入/输出(“nw i/o”)设备、网络交换机、虚拟机(“vm”)、电源模块和冷却模块等。在至少一个实施例中,节点c.r.4416(1)-4416(n)中的一个或更多个节点cr可以是服务器具有上述一种或更多种计算资源。
[0499]
在至少一个实施例中,5g无线电资源协调器4410可以配置或以其他方式控制一个
或更多个节点c.r.4416(1)-4416(n)和/或5g网络架构可以包括的其他各种组件和资源。在至少一个实施例中,5g无线电资源协调器4410可以包括用于高级系统4400的软件设计基础设施(“sdi”)管理实体。在至少一个实施例中,5g无线电资源协调器4410可以包括硬件、软件或其某种组合。在至少一个实施例中,5g无线电资源协调器4410可用于配置或以其他方式控制各种媒体接入控制子层、无线电接入网络、物理层或子层、和/或其变体,其可为5g网络架构的一部分。在至少一个实施例中,5g无线电资源协调器4410可以配置或分配分组的计算、网络、存储器或存储资源以支持可以作为5g网络架构的一部分执行的一个或更多个工作负载。
[0500]
在至少一个实施例中,gpu分组处理和i/o 4412可以配置或以其他方式处理各种输入和输出,以及诸如数据分组的分组,其可以作为5g网络架构的一部分被发送/接收,可以由高层系统4400实现。在至少一个实施例中,分组可以是格式化为由网络提供的数据,并且通常可以分为控制信息和有效载荷(即,用户数据)。在至少一个实施例中,数据分组的类型可以包括互联网协议版本4(ipv4)数据分组、互联网协议版本6(ipv6)数据分组和以太网ii帧数据分组。在至少一个实施例中,数据分组的控制数据可以分为数据完整性字段和语义字段。在至少一个实施例中,可以在其上接收数据分组的网络连接包括局域网、广域网、虚拟专用网、因特网、内联网、外联网、公共交换电话网、红外网络、无线网络、卫星网络及其任意组合。
[0501]
在至少一个实施例中,框架软件4406包括ai模型架构 训练 用例4422。在至少一个实施例中,ai模型架构 训练 用例4422可以包括工具、服务、软件或其他资源以根据一个或更多个实施例使用一个或更多个机器学习模型训练一个或更多个机器学习模型或预测或推理信息。例如,在至少一个实施例中,机器学习模型可以通过使用上文关于高级系统4400描述的软件和计算资源根据神经网络架构计算权重参数来训练。在至少一个实施例中,通过使用通过一种或更多种训练技术计算的权重参数,对应于一个或更多个神经网络的训练的机器学习模型可以用于使用上文关于高级系统4400描述的资源来推理或预测信息。在至少一个实施例中,框架软件4406可以包括支持系统软件 库4404和应用程序4402的框架。
[0502]
在至少一个实施例中,系统软件 库4404或应用程序4402可分别包括基于网络的服务软件或应用程序,例如由亚马逊网络服务、谷歌云和微软azure提供的那些。在至少一个实施例中,框架软件4406可以包括但不限于一种类型的免费和开源软件网络应用程序框架,例如apache spark
tm
(以下简称“spark”)。在至少一个实施例中,系统软件 库4404可以包括由节点c.r.4416(1)-4416(n)的至少部分使用的软件。在至少一个实施例中,一种或更多种类型的软件可以包括但不限于互联网网页搜索软件、电子邮件病毒扫描软件、数据库软件和流媒体视频内容软件。
[0503]
在至少一个实施例中,phy 4418是一组系统软件和库,被配置为提供与无线技术的物理层的接口,该物理层可以是诸如5g新无线电(nr)物理层的物理层。在至少一个实施例中,nr物理层利用灵活且可扩展的设计并且可以包括各种组件和技术,例如调制方案、波形结构、帧结构、参考信号、多天线传输和信道编码。
[0504]
在至少一个实施例中,nr物理层支持正交相移键控(qpsk)、16正交幅度调制(qam)、64qam和256qam调制格式。在至少一个实施例中,nr物理层中还可以包括针对不同用
户实体(ue)类别的不同调制方案。在至少一个实施例中,nr物理层可以在上行链路(ul)和下行链路(dl)中利用的具有可扩展的数字(子载波间隔,循环前缀)循环前缀正交频分复用(cp-ofdm)高达至少52.6吉赫兹。在至少一个实施例中,nr物理层可以支持ul中的离散傅立叶变换扩展正交频分复用(dft-sofdm),用于覆盖受限的场景,具有单流传输(即,没有空间复用)。
[0505]
在至少一个实施例中,nr帧支持时分双工(tdd)和频分双工(fdd)传输以及在授权和未授权频谱中的操作,这实现了非常低的延迟、快速的混合自动重传请求(harq)确认、动态tdd、与lte共存和可变长度传输(例如,超可靠低延迟通信(urllc)的短持续时间和增强型移动宽带(embb)的长持续时间)。在至少一个实施例中,nr帧结构遵循三个关键设计原则以增强前向兼容性并减少不同特征之间的交互。
[0506]
在至少一个实施例中,第一原则是传输是自包含的,这可以指一种方案,其中时隙和波束中的数据可独立解码而不依赖于其他时隙和波束。在至少一个实施例中,这意味着数据解调所需的参考信号被包括在给定的时隙和给定的波束中。在至少一个实施例中,第二原则是传输在时间和频率上被很好地限制,这导致可以引入与传统传输并行的新型传输的方案。在至少一个实施例中,第三原则是避免跨时隙和跨不同传输方向的静态和/或严格定时关系。在至少一个实施例中,第三原则的使用可能需要利用异步混合自动重传请求(harq)而不是预定义的重传时间。
[0507]
在至少一个实施例中,nr帧结构还允许快速harq确认,其中当从dl接收切换到ul传输时,在dl数据的接收期间执行解码并且由ue在保护时段期间准备harq确认。在至少一个实施例中,为了获得低延迟,在时隙(或时隙组)的开始处,时隙(或时隙聚合的情况下的一组时隙)被前置加载有控制信号和参考信号。
[0508]
在至少一个实施例中,nr具有超精简设计,其最小化始终在线的传输以提高网络能效并确保前向兼容性。在至少一个实施例中,仅在必要时才传输nr中的参考信号。在至少一个实施例中,四个主要参考信号是解调参考信号(dmrs)、相位跟踪参考信号(ptrs)、探测参考信号(srs)和信道状态信息参考信号(csi-rs)。
[0509]
在至少一个实施例中,dmrs用于估计用于解调的无线电信道。在至少一个实施例中,dmrs是特定于ue的,可以波束成形,限制在调度资源中,并且仅在必要时在dl和ul中传输。在至少一个实施例中,为了支持多层多输入多输出(mimo)传输,可以调度多个正交dmrs端口,每层一个。在至少一个实施例中,基本dmrs模式是前置的,因为dmrs设计考虑了早期解码要求以支持低延迟应用。在至少一个实施例中,对于低速场景,dmrs在时域中使用低密度。然而,在至少一个实施例中,对于高速场景,增加dmrs的时间密度以跟踪无线电信道中的快速变化。
[0510]
在至少一个实施例中,在nr中引入ptrs以实现振荡器相位噪声的补偿。在至少一个实施例中,典型地,相位噪声作为振荡器载波频率的函数而增加。在至少一个实施例中,因此可以在高载波频率(例如毫米波)下利用ptrs来减轻相位噪声。在至少一个实施例中,ptrs是特定于ue的,被限制在调度的资源中并且可以被波束成形。在至少一个实施例中,ptrs可根据振荡器的质量、载波频率、ofdm子载波间隔以及用于传输的调制和编码方案来配置。
[0511]
在至少一个实施例中,srs在ul中传输以执行主要用于调度和链路自适应的信道
状态信息(csi)测量。在至少一个实施例中,对于nr,srs还用于大规模mimo和ul波束管理的基于互易性的预编码器设计。在至少一个实施例中,srs具有模块化和灵活的设计以支持不同的过程和ue能力。在至少一个实施例中,信道状态信息参考信号(csi-rs)的方法是类似的。
[0512]
在至少一个实施例中,nr根据频谱的哪一部分用于其操作而采用不同的天线解决方案和技术。在至少一个实施例中,对于较低频率,假设有低到中等数量的有源天线(多达约32个发射机链)并且fdd操作是常见的。在至少一个实施例中,csi的获取需要dl中的csi-rs的传输和ul中的csi报告。在至少一个实施例中,在该频率区域中可用的有限带宽需要通过多用户mimo(mu-mimo)和更高阶空间复用实现的高频谱效率,与lte相比,这是通过更高分辨率的csi报告实现的。
[0513]
在至少一个实施例中,对于更高的频率,可以在给定孔径中采用更多数量的天线,这增加了波束成形和多用户(mu)-mimo的能力。在至少一个实施例中,本文,频谱分配是tdd类型并且假设基于互易的操作。在至少一个实施例中,通过ul信道探测获取显式信道估计形式的高分辨率csi。在至少一个实施例中,这种高分辨率csi使得能够在基站(bs)处采用复杂的预编码算法。在至少一个实施例中,对于更高的频率(在毫米波范围内),当前通常需要模拟波束成形实现,这将传输限制为每个时间单位和无线电链的单个波束方向。在至少一个实施例中,由于载波波长短,各向同性天线元件在该频率区域中非常小,因此需要大量天线元件来保持覆盖。在至少一个实施例中,需要在发射器和接收器端应用波束成形以对抗增加的路径损耗,即使对于控制信道传输也是如此。
[0514]
在至少一个实施例中,为了支持这些不同的用例,nr具有高度灵活但统一的csi框架,其中与lte相比,在nr中减少了csi测量、csi报告和实际dl传输之间的耦合。在至少一个实施例中,nr还支持更高级的方案,例如多点传输和协调。在至少一个实施例中,控制和数据传输遵循自包含原则,其中解码传输所需的所有信息(例如伴随的dmrs)包含在传输本身内。在至少一个实施例中,因此,网络可以随着ue在网络中移动而无缝地改变传输点或波束。
[0515]
在至少一个实施例中,mac 4420是一组系统软件和库,被配置为提供具有媒体访问控制(mac)层的接口,其可以是5g网络架构的一部分。在至少一个实施例中,mac层控制负责与有线、光或无线传输介质交互的硬件。在至少一个实施例中,mac为传输介质提供流量控制和复用。
[0516]
在至少一个实施例中,mac子层提供物理层的抽象,使得物理链路控制的复杂性对于逻辑链路控制(llc)和网络堆栈的上层是不可见的。在至少一个实施例中,任何llc子层(和更高层)可以与任何mac一起使用。在至少一个实施例中,任何mac都可以与任何物理层一起使用,而与传输介质无关。在至少一个实施例中,mac子层在向网络上的另一设备发送数据时,将高层帧封装成适合传输介质的帧,添加帧校验序列以识别传输错误,然后在适当的信道访问方法允许时将数据转发到物理层。在至少一个实施例中,如果检测到拥塞信号,mac还负责补偿冲突,其中mac可以发起重传。
[0517]
在至少一个实施例中,应用程序4402可以包括由节点c.r.4416(1)-4416(n)和/或框架软件4406的至少部分使用的一种或更多种类型的应用程序。在至少一个实施例中,一种或更多种类型的应用程序可以包括但不限于任何数量的基因组学应用程序、认知计算和
机器学习应用程序,包括训练或推理软件、机器学习框架软件(例如、pytorch、tensorflow、caffe等)或与一个或更多个实施例结合使用的其他机器学习应用程序。
[0518]
在至少一个实施例中,ran api 4414可以是一组子例程定义、通信协议和/或软件工具,其提供与无线电接入网络(ran)的组件通信的方法,该组件可以是5g网络架构的一部分。在至少一个实施例中,无线电接入网络是网络通信系统的一部分并且可以实现无线电接入技术。在至少一个实施例中,无线电接入网络功能通常由位于核心网络和用户设备两者中的硅芯片提供。关于无线电接入网络的更多信息可以在图42的描述中找到。
[0519]
在至少一个实施例中,高级系统4400可以使用cpu、专用集成电路(asic)、gpu、fpga或其他硬件来使用上述资源来执行训练、推理和/或其他各种过程。此外,在至少一个实施例中,上述一个或更多个软件和/或硬件资源可以被配置为允许用户训练或执行信息推理的服务,例如图像识别、语音识别或其他人工智能服务,以及其他服务,例如允许用户配置和实施5g网络架构各个方面的服务。
[0520]
在至少一个实施例中,高级系统4400可以使用具有多种加速器的多处理。在至少一个实施例中,例如,高级系统4400可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,高级系统4400可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速器资源。
[0521]
图45示出了根据至少一个实施例的网络系统4500的架构。在至少一个实施例中,系统4500被示为包括用户设备(ue)4502和ue 4504。在至少一个实施例中,ue 4502和4504被示为智能手机(例如,可连接到一个或更多个蜂窝网络的手持触摸屏移动计算设备),但也可以包括任何移动或非移动计算设备,例如个人数据助理(pda)、寻呼机、膝上型计算机、台式计算机、无线手机或任何包括无线通信接口的计算设备。
[0522]
在至少一个实施例中,ue 4502和4504中的任一个可以包括物联网(iot)ue,其可以包括为利用短暂ue连接的低功率iot应用而设计的网络接入层。在至少一个实施例中,iot ue可以利用诸如机器对机器(m2m)或机器类型通信(mtc)之类的技术来通过公共陆地移动网络(plmn)、基于临近服务(prose)或设备到设备(d2d)通信、传感器网络或iot网络与mtc服务器或设备交换数据。在至少一个实施例中,m2m或mtc数据交换可以是机器发起的数据交换。在至少一个实施例中,iot网络描述了互连iot ue,其可以包括具有短期连接的唯一可识别的嵌入式计算设备(在互联网基础设施内)。在至少一个实施例中,iot ue可以执行后台应用程序(例如,保持活动消息、状态更新等)以促进iot网络的连接。
[0523]
在至少一个实施例中,ue 4502和4504可以被配置为与无线电接入网络(ran)4516连接,例如,通信耦合。在至少一个实施例中,ran 4516可以是,例如,演进的通用移动电信系统(umts)陆地无线电接入网络(e-utran)、下一代ran(ngran)或某种其他类型的ran。在至少一个实施例中,ue 4502和4504分别利用连接4512和4514,每个连接包括物理通信接口或层。在至少一个实施例中,连接4512和4514被示为空中接口以实现通信耦合,并且可以与蜂窝通信协议一致,例如全球移动通信系统(gsm)协议、码分多址(cdma)网络协议、一键通(ptt)协议、蜂窝上ptt(poc)协议、通用移动电信系统(umts)协议、3gpp长期演进(lte)协议、第五代(5g)协议、新无线电(nr)协议及其变体。
[0524]
在至少一个实施例中,ue 4502和4504可以进一步经由prose接口4506直接交换通信数据。在至少一个实施例中,prose接口4506可以替代地被称为包括一个或更多个逻辑信
道的侧链接口,包括但不限于物理侧链控制信道(pscch)、物理侧链共享信道(pssch)、物理侧链发现信道(psdch)和物理侧链广播信道(psbch)。
[0525]
在至少一个实施例中,ue 4504被示为经配置以经由连接4508接入接入点(ap)4510。在至少一个实施例中,连接4508可包括本地无线连接,例如与任何ieee 802.11协议,其中ap 4510将包括无线保真路由器。在至少一个实施例中,ap 4510被示为连接到因特网而不连接到无线系统的核心网络。
[0526]
在至少一个实施例中,ran 4516可以包括启用连接4512和4514的一个或更多个接入节点。在至少一个实施例中,这些接入节点(an)可以被称为基站(bs)、nodeb、演进nodeb(enb)、下一代nodeb(gnb)、ran节点等等,并且可以包括提供地理区域(例如,小区)内的覆盖的地面站(例如,地面接入点)或卫星站。在至少一个实施例中,ran 4516可以包括一个或更多个用于提供宏小区的ran节点,例如宏ran节点4518,以及一个或更多个用于提供毫微微小区或微微小区的ran节点(例如,具有较小覆盖区域、较小用户容量、或与宏小区相比更高的带宽),例如低功率(lp)ran节点4520。
[0527]
在至少一个实施例中,ran节点4518和4520中的任一个可以终止空中接口协议并且可以是ue 4502和4504的第一接触点。在至少一个实施例中,ran节点4518和4520中的任一个可以实现ran 4516的各种逻辑功能,包括但不限于无线网络控制器(rnc)功能,例如无线承载管理、上行链路和下行链路动态无线资源管理和数据分组调度以及移动性管理。
[0528]
在至少一个实施例中,ue 4502和4504可以被配置为根据各种通信技术使用正交频分复用(“ofdm”)通信信号在多载波通信信道上彼此通信或者与ran节点4518和4520中的任一个通信,例如但不限于正交频分多址(ofdma)通信技术(例如,用于下行链路通信)或单载波频分多址(sc-fdma)通信技术(例如,用于上行链路和prose或侧链通信),和/或其变体。在至少一个实施例中,ofdm信号可以包括多个正交子载波。
[0529]
在至少一个实施例中,下行链路资源网格可以用于从ran节点4518和4520中的任一个到ue 4502和4504的下行链路传输,而上行链路传输可以利用类似的技术。在至少一个实施例中,网格可以是时频网格,称为资源网格或时频资源网格,是每个时隙下行链路中的物理资源。在至少一个实施例中,这样的时频平面表示是ofdm系统的常见做法,这使得无线电资源分配直观。在至少一个实施例中,资源网格的每一列和每一行分别对应一个ofdm符号和一个ofdm子载波。在至少一个实施例中,时域中资源网格的持续时间对应于无线电帧中的一个时隙。在至少一个实施例中,资源网格中的最小时频单元被表示为资源元素。在至少一个实施例中,每个资源网格包括多个资源块,其描述了某些物理信道到资源元素的映射。在至少一个实施例中,每个资源块包括资源元素的集合。在至少一个实施例中,在频域中,这可以表示当前可以分配的最小资源量。在至少一个实施例中,存在使用这样的资源块传送的若干不同的物理下行链路信道。
[0530]
在至少一个实施例中,物理下行链路共享信道(pdsch)可以携带用户数据和到ue 4502和4504的高层信令。在至少一个实施例中,物理下行链路控制信道(pdcch)可以携带关于与pdsch信道等相关的传输格式和资源分配的信息。在至少一个实施例中,它还可以将与上行链路共享信道相关的传输格式、资源分配和harq(混合自动重传请求)信息通知给ue 4502和4504。在至少一个实施例中,典型地,可以基于从ue 4502和4504中的任一个反馈的信道质量信息在ran节点4518和4520中的任一个处执行下行链路调度(向小区内的ue 4502
分配控制和共享信道资源块)在至少一个实施例中,可以在用于(例如,分配给)ue 4502和4504中的每一个的pdcch上发送下行链路资源分配信息。
[0531]
在至少一个实施例中,pdcch可以使用控制信道元素(cce)来传达控制信息。在至少一个实施例中,在被映射到资源元素之前,pdcch复值符号可以首先被组织成四元组,然后可以使用子块交织器对其进行置换以进行速率匹配。在至少一个实施例中,可以使用这些cce中的一个或更多个来传送每个pdcch,其中每个cce可以对应于被称为资源元素组(reg)的九组四个物理资源元素。在至少一个实施例中,四个正交相移键控(qpsk)符号可以映射到每个reg。在至少一个实施例中,取决于下行链路控制信息(dci)的大小和信道条件,可以使用一个或更多个cce来发送pdcch。在至少一个实施例中,lte中可以定义具有不同数量的cce(例如,聚合级别,l=1、2、4或8)的四种或更多种不同的pdcch格式。
[0532]
在至少一个实施例中,使用pdsch资源的增强型物理下行链路控制信道(epdcch)可以用于控制信息传输。在至少一个实施例中,可以使用一个或更多个增强控制信道元素(ecce)来传送epdcch。在至少一个实施例中,每个ecce可以对应于被称为增强资源元素组(ereg)的九组四个物理资源元素。在至少一个实施例中,ecce在一些情况下可以具有其他数量的ereg。
[0533]
在至少一个实施例中,ran 4516被示为经由s1接口4522通信地耦合到核心网络(cn)4538。在至少一个实施例中,cn 4538可以是演进分组核心(epc)网络,nextgen分组核心(npc)网络或某些其他类型的cn。在至少一个实施例中,s1接口4522被分成两部分:s1-u接口4526,其在ran节点4518和4520与服务网关(s-gw)4530之间承载流量数据,以及s1-移动性管理实体(mme)接口4524,其是ran节点4518和4520与mme 4528之间的信令接口。
[0534]
在至少一个实施例中,cn 4538包括mme 4528、s-gw 4530、分组数据网络(pdn)网关(p-gw)4534和归属用户服务器(hss)4532。在至少一个实施例中,mme 4528在功能上可以类似于传统服务通用分组无线电服务(gprs)支持节点(sgsn)的控制平面。在至少一个实施例中,mme 4528可以管理接入中的移动性方面,例如网关选择和跟踪区域列表管理。在至少一个实施例中,hss 4532可以包括用于网络用户的数据库,包括订阅相关信息以支持网络实体对通信会话的处理。在至少一个实施例中,cn 4538可以包括一个或更多个hss 4532,这取决于移动用户的数量、设备的容量、网络的组织等。在至少一个实施例中,hss 4532可以提供支持路由/漫游、身份验证、授权、命名/寻址解析、位置依赖等。
[0535]
在至少一个实施例中,s-gw 4530可以终止通向ran 4516的s1接口4522,并且在ran 4516和cn 4538之间路由数据分组。在至少一个实施例中,s-gw 4530可以是本地移动锚ran间节点切换点,也可以为3gpp间移动性提供锚点。在至少一个实施例中,其他职责可以包括合法拦截、收费和一些策略执行。
[0536]
在至少一个实施例中,p-gw 4534可以终止朝向pdn的sgi接口。在至少一个实施例中,p-gw 4534可以在epc网络4538和外部网络(诸如包括应用服务器4540(或者称为应用功能(af)))之间经由互联网协议(ip)接口4542路由数据分组。在至少一个实施例中,应用服务器4540可以是提供使用具有核心网络的ip承载资源的应用的元件(例如,umts分组服务(ps)域、lteps数据服务等)。在至少一个实施例中,p-gw 4534被示为经由ip通信接口4542通信地耦合到应用服务器4540。在至少一个实施例中,应用服务器4540还可以被配置为经由cn 4538为ue 4502和4504提供支持一种或更多种通信服务(例如,网络电话(voip)会话、
ptt会话、群组通信会话、社交网络服务等)。
[0537]
在至少一个实施例中,p-gw 4534还可以是用于策略实施和计费数据收集的节点。在至少一个实施例中,策略和计费执行功能(pcrf)4536是cn 4538的策略和计费控制元件。在至少一个实施例中,在非漫游场景中,家庭公共土地移动网络(hplmn)中可能存在单个pcrf与ue的互联网协议连接接入网络(ip-can)会话相关联。在至少一个实施例中,在具有本地流量中断的漫游场景中,可能存在与ue的ip-can会话相关联的两个pcrf:hplmn内的归属pcrf(h-pcrf)和访问公共陆地移动网络(vplmn)内的拜访pcrf(v-pcrf)。在至少一个实施例中,pcrf 4536可以通过p-gw 4534通信耦合到应用服务器4540。在至少一个实施例中,应用服务器4540可以用信号通知pcrf 4536以指示新的服务流并选择适当的服务质量(qos))和充电参数。在至少一个实施例中,pcrf 4536可以将该规则提供到策略和计费执行功能(pcef)(未示出)中,并具有适当的业务流模板(tft)和标识符的qos类别(qci),其开始qos和计费由应用程序服务器4540指定。
[0538]
在至少一个实施例中,ran节点4518和4520可以使用具有多种加速器的多处理。在至少一个实施例中,例如,ran节点4518和4520可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,ran节点4518和4520可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0539]
图46示出了根据至少一个实施例的设备4600的示例组件。在至少一个实施例中,设备4600可以包括至少如图所示耦合在一起的应用电路4604、基带电路4608、射频(rf)电路4610、前端模块(fem)电路4602、一个或更多个天线4612和电源管理电路(pmc)4606。在至少一个实施例中,所示设备4600的组件可以包括在ue或ran节点中。在至少一个实施例中,设备4600可以包括更少的元件(例如,ran节点可以不利用应用电路4604,而是包括处理器/控制器来处理从epc接收的ip数据)。在至少一个实施例中,设备4600可以包括附加元件,例如存储器/存储、显示器、相机、传感器或输入/输出(i/o)接口。在至少一个实施例中,以下描述的组件可以被包括在一个以上的设备中(例如,对于云-ran(c-ran)实现,所述电路可以被单独地包括在一个以上的设备中)。
[0540]
在至少一个实施例中,应用电路4604可以包括一个或更多个应用处理器。在至少一个实施例中,应用电路4604可以包括电路,诸如但不限于一个或更多个单核或多核处理器。在至少一个实施例中,处理器可以包括通用处理器和专用处理器(例如,图形处理器、应用处理器等)的任意组合。在至少一个实施例中,处理器可以与存储器/存储器耦合或者可以包括存储器/存储器并且可以被配置为执行存储在存储器/存储器中的指令以使得各种应用或操作系统能够在设备4600上运行。在至少一个实施例中,处理器应用电路4604可以处理从epc接收的ip数据分组。
[0541]
在至少一个实施例中,基带电路4608可以包括电路,诸如但不限于一个或更多个单核或多核处理器。在至少一个实施例中,基带电路4608可以包括一个或更多个基带处理器或控制逻辑以处理从rf电路4610的接收信号路径接收的基带信号并且为rf电路4610的发射信号路径生成基带信号。在至少一个实施例中,基带处理电路4608可以与应用电路4604接口以用于生成和处理基带信号以及用于控制rf电路4610的操作。在至少一个实施例中,基带电路4608可以包括第三代(3g)基带处理器4608a、第四代(4g)基带处理器4608b、第五代(5g)基带处理器4608c或用于其他现有代、正在开发或将被开发的代(例如,第二代
(2g),第六代(6g)等)的其他基带处理器4608d。在至少一个实施例中,基带电路4608(例如,基带处理器4608a-d中的一个或更多个)可以处理各种无线电控制功能,这些功能使得能够通过rf电路4610与一个或更多个无线电网络进行通信。在至少一个实施例中,基带处理器4608a-d的一些或全部功能可以包括在存储在存储器4608g中的模块中并且经由中央处理单元(cpu)4608e执行。在至少一个实施例中,无线电控制功能可以包括但不限于信号调制/解调、编码/解码、射频移位等。在至少一个实施例中,基带电路4608的调制/解调电路可以包括快速傅立叶变换(fft)、预编码或星座映射/解映射功能。在至少一个实施例中,基带电路4608的编码/解码电路可以包括卷积、咬尾卷积、turbo、viterbi或低密度奇偶校验(ldpc)编码器/解码器功能。
[0542]
在至少一个实施例中,基带电路4608可以包括一个或更多个音频数字信号处理器(dsp)4608f。在至少一个实施例中,音频dsp 4608f可以包括用于压缩/解压缩和回声消除的元件,并且在其他实施例中可以包括其他合适的处理元件。在至少一个实施例中,基带电路的组件可以适当地组合在单个芯片、单个芯片组中,或者在一些实施例中设置在同一电路板上。在至少一个实施例中,基带电路4608和应用电路4604的一些或所有组成组件可以一起实现,例如在片上系统(soc)上。
[0543]
在至少一个实施例中,基带电路4608可以提供与一种或更多种无线电技术兼容的通信。在至少一个实施例中,基带电路4608可以支持与演进通用陆地无线电接入网(eutran)或其他无线城域网(wman)、无线局域网(wlan)、无线个域网(wpan)的通信。在至少一个实施例中,基带电路4608被配置为支持一种以上无线协议的无线电通信并且可以被称为多模基带电路。
[0544]
在至少一个实施例中,rf电路4610可以通过非固体介质使用调制电磁辐射来实现与无线网络的通信。在至少一个实施例中,rf电路4610可以包括交换机、滤波器、放大器等以促进与无线网络的通信。在至少一个实施例中,rf电路4610可以包括接收信号路径,该接收信号路径可以包括对从fem电路4602接收的rf信号进行下转换并将基带信号提供给基带电路4608的电路。在至少一个实施例中,rf电路4610还可以包括发射信号路径,其可以包括用于对由基带电路4608提供的基带信号进行上转换并将rf输出信号提供给fem电路4602以用于发射的电路。
[0545]
在至少一个实施例中,rf电路4610的接收信号路径可以包括混频器电路4610a、放大器电路4610b和滤波器电路4610c。在至少一个实施例中,rf电路4610的发射信号路径可以包括滤波器电路4610c和混频器电路4610a。在至少一个实施例中,rf电路4610还可包括用于合成频率以供接收信号路径和发射信号路径的混频器电路4610a使用的合成器电路4610d。在至少一个实施例中,接收信号路径的混频器电路4610a可以被配置为基于合成器电路4610d提供的合成频率对从fem电路4602接收的rf信号进行下转换。在至少一个实施例中,放大器电路4610b可以被配置为放大下转换信号并且滤波器电路4610c可以是低通滤波器(lpf)或带通滤波器(bpf),被配置为从下转换信号中去除不需要的信号产生输出基带信号。在至少一个实施例中,可以将输出基带信号提供给基带电路4608以供进一步处理。在至少一个实施例中,输出基带信号可以是零频基带信号,尽管这不是必需的。在至少一个实施例中,接收信号路径的混频器电路4610a可以包括无源混频器。
[0546]
在至少一个实施例中,发射信号路径的混频器电路4610a可以被配置为基于由合
成器电路4610d提供的合成频率对输入基带信号进行上转换以生成用于fem电路4602的rf输出信号。在一个实施例中,基带信号可以由基带电路4608提供并且可以由滤波器电路4610c滤波。
[0547]
在至少一个实施例中,接收信号路径的混频器电路4610a和发射信号路径的混频器电路4610a可以包括两个或更多个混频器并且可以分别被布置用于正交下转换和上转换。在至少一个实施例中,接收信号路径的混频器电路4610a和发射信号路径的混频器电路4610a可以包括两个或更多个混频器并且可以被布置用于镜像抑制(例如,哈特利图像抑制)。在至少一个实施例中,接收信号路径的混频器电路4610a和混频器电路4610a可以分别布置用于直接下转换和直接上转换。在至少一个实施例中,接收信号路径的混频器电路4610a和发射信号路径的混频器电路4610a可以被配置用于超外差操作。
[0548]
在至少一个实施例中,输出基带信号和输入基带信号可以是模拟基带信号。在至少一个实施例中,输出基带信号和输入基带信号可以是数字基带信号。在至少一个实施例中,rf电路4610可以包括模数转换器(adc)和数模转换器(dac)电路,并且基带电路4608可以包括与rf电路4610通信的数字基带接口。
[0549]
在至少一个实施例中,可以提供单独的无线电ic电路来处理每个频谱的信号。在至少一个实施例中,合成器电路4610d可以是分数n合成器或分数n/n 1合成器。在至少一个实施例中,合成器电路4610d可以是delta-sigma合成器、倍频器或包括具有分频器的锁相环的合成器。
[0550]
在至少一个实施例中,合成器电路4610d可以被配置为基于频率输入和分频器控制输入合成供rf电路4610的混频器电路4610a使用的输出频率。在至少一个实施例中,合成器电路4610d可以是分数n/n 1合成器。
[0551]
在至少一个实施例中,频率输入可以由压控振荡器(vco)提供。在至少一个实施例中,分频器控制输入可以由基带电路4608或应用处理器4604根据期望的输出频率提供。在至少一个实施例中,分频器控制输入(例如,n)可以基于应用处理器4604所指示的信道从查找表中确定。
[0552]
在至少一个实施例中,rf电路4610的合成器电路4610d可以包括分频器、延迟锁定环(dll)、多路复用器和相位累加器。在至少一个实施例中,分频器可以是双模分频器(dmd)并且相位累加器可以是数字相位累加器(dpa)。在至少一个实施例中,dmd可以被配置为将输入信号除以n或n 1(例如,基于进位)以提供小数除法比。在至少一个实施例中,dll可以包括一组级联的可调延迟元件、相位检测器、电荷泵和d型触发器。在至少一个实施例中,延迟元件可以被配置为将vco周期分成nd个相等的相位分组,其中nd是延迟线中的延迟元件的数量。在至少一个实施例中,以此方式,dll提供负反馈以帮助确保通过延迟线的总延迟为一个vco周期。
[0553]
在至少一个实施例中,合成器电路4610d可以被配置为生成载波频率作为输出频率,而在其他实施例中,输出频率可以是载波频率的倍数(例如,载波频率的两倍,四倍载波频率)并与正交发生器和分频器电路结合使用,以在载波频率上生成多个信号,这些信号彼此之间具有多个不同的相位。在至少一个实施例中,输出频率可以是lo频率(flo)。在至少一个实施例中,rf电路4610可以包括iq/极性转换器。
[0554]
在至少一个实施例中,fem电路4602可以包括接收信号路径,该接收信号路径可以
包括被配置为对从一个或更多个天线4612接收的rf信号进行操作、放大接收信号并且将接收信号的放大版本提供给rf电路4610的电路作进一步处理。在至少一个实施例中,fem电路4602还可以包括发射信号路径,该发射信号路径可以包括被配置为放大由rf电路4610提供的用于发射的信号以便由一个或更多个天线4612中的一个或更多个发射的电路。在至少一个实施例中,通过发射或接收信号路径的放大可以单独在rf电路4610中、单独在fem 4602中或在rf电路4610和fem 4602两者中完成。
[0555]
在至少一个实施例中,fem电路4602可以包括tx/rx交换机以在发射模式和接收模式操作之间切换。在至少一个实施例中,fem电路可以包括接收信号路径和发射信号路径。在至少一个实施例中,fem电路的接收信号路径可以包括lna以放大接收的rf信号并且提供放大的接收的rf信号作为输出(例如,到rf电路4610)。在至少一个实施例中,fem电路4602的发射信号路径可以包括功率放大器(pa)以放大输入rf信号(例如,由rf电路4610提供),以及一个或更多个滤波器以生成用于后续发射的rf信号(例如,通过一个或更多个天线4612中的一个或更多个)。
[0556]
在至少一个实施例中,pmc 4606可以管理提供给基带电路4608的功率。在至少一个实施例中,pmc 4606可以控制电源选择、电压缩放、电池充电或dc-dc转换。在至少一个实施例中,当设备4600能够由电池供电时,例如,当设备被包括在ue中时,可以经常包括pmc 4606。在至少一个实施例中,pmc 4606可以提高功率转换效率同时提供期望的实现尺寸和散热特性。
[0557]
在至少一个实施例中,pmc 4606可以附加地或替代地与其他组件(例如但不限于应用电路4604、rf电路4610或fem 4602)耦合,并为其执行类似的功率管理操作。
[0558]
在至少一个实施例中,pmc 4606可以控制设备4600的各种省电机制或以其他方式为其一部分。在至少一个实施例中,如果设备4600处于rrc连接状态,则它仍然连接到ran节点预计很快就会接收流量,然后它可能会在一段时间不活动后进入称为不连续接收模式(drx)的状态。在至少一个实施例中,在该状态期间,设备4600可以在短暂的时间间隔断电,从而节省电力。
[0559]
在至少一个实施例中,如果在延长的时间段内没有数据业务活动,则设备4600可以转换到rrc空闲状态,在那里它与网络断开连接并且不执行操作(诸如信道质量反馈、切换等)。在至少一个实施例中,设备4600进入非常低的功率状态并且它执行寻呼,其中它再次周期性地唤醒以收听网络,然后再次断电。在至少一个实施例中,设备4600在该状态下可能不接收数据,为了接收数据,它必须转换回rrc连接状态。
[0560]
在至少一个实施例中,附加的省电模式可以允许设备在比寻呼间隔长的时间段内(范围从几秒到几小时)对网络不可用。在至少一个实施例中,在此期间,设备完全无法接入网络并且可能完全断电。在至少一个实施例中,在此期间发送的任何数据都会导致大延迟,并且假设延迟是可以接受的。
[0561]
在至少一个实施例中,应用电路4604的处理器和基带电路4608的处理器可用于执行协议栈的一个或更多个实例的元素。在至少一个实施例中,基带电路4608的处理器可以单独或组合地用于执行第3层、第2层或第1层功能,而应用电路4608的处理器可以利用从这些接收到的数据(例如,分组数据)层并进一步执行第4层功能(例如,传输通信协议(tcp)和用户数据报协议(udp)层)。在至少一个实施例中,第3层可以包括无线电资源控制(rrc)层。
在至少一个实施例中,第2层可以包括媒体访问控制(mac)层、无线电链路控制(rlc)层和分组数据会聚协议(pdcp)层。在至少一个实施例中,第1层可以包括ue/ran节点的物理(phy)层。
[0562]
在至少一个实施例中,基带电路4608可以使用具有多种加速器的多处理。例如,在至少一个实施例中,基带电路4608可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,基带电路4608可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0563]
图47示出了根据至少一个实施例的基带电路的示例接口。在至少一个实施例中,如上所述,图46的基带电路4608可以包括处理器4608a-4608e和由所述处理器使用的存储器4608g。在至少一个实施例中,处理器4608a-4608e中的每一个可以分别包括存储器接口4702a-4702e,以向/从存储器4608g发送/接收数据。
[0564]
在至少一个实施例中,基带电路4608还可以包括一个或更多个接口以通信地耦合到其他电路/设备,例如存储器接口4704(例如,向/从基带电路4608外部存储器发送/接收数据的接口)、应用电路接口4706(例如,向/从图46的应用电路4604发送/接收数据的接口)、rf电路接口4708(例如,向/从图46的rf电路4610发送/接收数据的接口)、无线硬件连接接口4710(例如,向/从近场通信(nfc)组件、组件(例如low energy)、组件和其他通信组件),以及电源管理接口4712(例如,向/从pmc 4606发送/接收电源或控制信号的接口。
[0565]
在至少一个实施例中,基带电路4608可以使用具有多种加速器的多处理。例如,在至少一个实施例中,基带电路4608可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,基带电路4608可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0566]
图48示出了根据至少一个实施例的上行链路信道的示例。在至少一个实施例中,图48示出了在5g nr中的物理上行链路共享信道(pusch)内发送和接收数据,其可以是移动设备网络的物理层的一部分。
[0567]
在至少一个实施例中,5g nr中的物理上行链路共享信道(pusch)被指定为承载复用控制信息和用户应用数据。在至少一个实施例中,5g nr与其前身相比提供了更多的灵活性和可靠性,在一些示例中可以称为4g lte,包括更具弹性的导频布置和对循环前缀(cp)-ofdm和离散傅立叶变换扩展(dft-s)-ofdm波形的支持。在至少一个实施例中,标准引入的滤波ofdm(f-ofdm)技术被用来添加额外的滤波以减少带外发射并提高更高调制阶的性能。在至少一个实施例中,前向纠错(fec)中的修改被强加于用准循环低密度奇偶校验(qc-ldpc)码替换4g lte中使用的turbo码,这被证明可以实现更好的传输速率并提供机会以获得更高效的硬件实现。
[0568]
在至少一个实施例中,5g nr下行链路和上行链路数据的传输被组织成持续时间为10毫秒的帧,每个帧被分成10个子帧,每个子帧为1毫秒。在至少一个实施例中,子帧由可变数量的时隙组成,这取决于在5g nr中参数化的所选子载波间隔。在至少一个实施例中,时隙是由14个ofdma符号构建的,每个符号都带有循环前缀。在至少一个实施例中,位于通带内并被指定用于传输的子载波被称为资源元素(re)。在至少一个实施例中,同一符号中的一组12个相邻re形成物理资源块(prb)。
[0569]
在至少一个实施例中,5g nr标准定义了与pusch信道内的传输相关联的两种类型的参考信号。在至少一个实施例中,解调参考信号(dmrs)是具有高频率密度的用户特定参考信号。在至少一个实施例中,dmrs仅在专用正交频分多址(ofdma)符号内传输并且被指定用于频率选择性信道估计。在至少一个实施例中,根据配置,一个时隙内的dmrs符号数量可以在1和4之间变化,其中更密集的dmrs符号时间间隔被指定用于快速时变信道,以在信道的相干时间内获得更准确的估计。在至少一个实施例中,在频域中,dmrs prb被映射在整个传输分配内。在至少一个实施例中,为同一个天线端口(ap)分配的dmrs资源元素(re)之间的间距可以在2和3之间选择。在至少一个实施例中,在2-2多输入多输出(mimo)的情况下,标准允许在ap之间正交分配re。在至少一个实施例中,接收器可以在mimo均衡之前基于dmrs re执行部分单输入多输出(simo)信道估计,忽略空间相关。
[0570]
在至少一个实施例中,第二类型的参考信号是相位跟踪参考信号(ptrs)。在至少一个实施例中,ptrs子载波以在时域中具有高密度的梳状结构排列。在至少一个实施例中,它主要用于毫米波频段以跟踪和校正相位噪声,这是性能损失的一个重要来源。在至少一个实施例中,ptrs的使用是可选的,因为当相位噪声的影响可以忽略时,它可能会降低传输的总频谱效率。
[0571]
在至少一个实施例中,对于数据的传输,可以从mac层生成传输块并且将其提供给物理层。在至少一个实施例中,传输块可以是要被传输的数据。在至少一个实施例中,物理层中的传输以分组的资源数据开始,其可以被称为传输块。在至少一个实施例中,传输块由循环冗余校验(crc)4802接收。在至少一个实施例中,循环冗余校验被附加到每个传输块以用于错误检测。在至少一个实施例中,循环冗余校验用于传输块中的错误检测。在至少一个实施例中,使用整个传输块来计算crc奇偶校验位,然后将这些奇偶校验位附加到传输块的末尾。在至少一个实施例中,最小和最大代码块大小被指定以便块大小与进一步的处理兼容。在至少一个实施例中,当输入块大于最大代码块大小时,输入块被分段。
[0572]
在至少一个实施例中,传输块由低密度奇偶校验(ldpc)编码4804接收和编码。在至少一个实施例中,nr采用低密度奇偶校验(ldpc)码用于数据信道和控制信道的极化码。在至少一个实施例中,ldpc码由它们的奇偶校验矩阵定义,每一列代表一个编码位,每一行代表一个奇偶校验方程。在至少一个实施例中,通过以迭代方式在变量和奇偶校验之间交换消息来解码ldpc码。在至少一个实施例中,为nr提出的ldpc码使用准循环结构,其中奇偶校验矩阵由较小的基矩阵定义。在至少一个实施例中,基矩阵的每个条目表示zxz零矩阵或移位的zxz单位矩阵。
[0573]
在至少一个实施例中,编码传输块由速率匹配4806接收。在至少一个实施例中,编码块用于创建具有期望码率的输出位流。在至少一个实施例中,速率匹配4806用于创建要以期望的码率传输的输出位流。在至少一个实施例中,从缓冲器中选择和修剪位以创建具有期望码率的输出位流。在至少一个实施例中,结合了混合自动重复请求(harq)纠错方案。
[0574]
在至少一个实施例中,在加扰4808中,输出位被加扰,这可以有助于隐私。在至少一个实施例中,码字与正交序列和ue特定加扰序列逐位相乘。在至少一个实施例中,加扰4808的输出可以被输入到调制/映射/预编码和其他过程4810中。在至少一个实施例中,执行各种调制、映射和预编码过程。
[0575]
在至少一个实施例中,从加扰4808输出的位用调制方案进行调制,从而产生调制
符号块。在至少一个实施例中,加扰码字使用调制方案qpsk、16qam、64qam之一进行调制,从而产生调制符号块。在至少一个实施例中,可以利用信道交织器过程来实现调制符号到发射波形的第一时间映射,同时确保harq信息存在于两个时隙上。在至少一个实施例中,调制符号基于发射天线被映射到各个层。在至少一个实施例中,符号可以被预编码,其中它们被分成组,并且可以执行快速傅立叶逆变换。在至少一个实施例中,可以执行传输数据和控制复用,使得harq确认(ack)信息存在于两个时隙中并且被映射到解调参考信号周围的资源。在至少一个实施例中,执行各种预编码过程。
[0576]
在至少一个实施例中,符号被映射到资源元素映射4812中分配的物理资源元素。在至少一个实施例中,分配大小可以被限制为质因数为2、3和5的值。在至少一个实施例中,符号以从副载波开始的递增顺序进行映射。在至少一个实施例中,子载波映射的调制符号数据是通过ofdma调制4814中的ifft操作进行正交频分多址(ofdma)调制的。在至少一个实施例中,每个符号的时域表示使用发射fir滤波器进行连接和滤波,以衰减由于相位不连续性和使用不同数字学而导致的相邻频带的不需要的带外发射。在至少一个实施例中,ofdma调制4814的输出可以被传送以被另一系统接收和处理。
[0577]
在至少一个实施例中,传输可以由ofdma解调4816接收。在至少一个实施例中,传输可以通过蜂窝网络从用户移动设备发起,但是可能存在其他情况。在至少一个实施例中,可以通过ifft处理来解调传输。在至少一个实施例中,一旦完成通过ifft处理的ofdma解调,就可以执行残余采样时间偏移(sto)和载波频率偏移(cfo)的估计和校正。在至少一个实施例中,cfo和sto校正都必须在频域中执行,因为接收信号可以是来自在频率上复用的多个ue的传输的叠加,每个ue遭受特定的残余同步错误。在至少一个实施例中,残余cfo被估计为属于不同ofdm符号的导频子载波之间的相位旋转并且通过频域中的循环卷积操作来校正。
[0578]
在至少一个实施例中,ofdma解调4816的输出可以由资源元素解映射4818接收。在至少一个实施例中,资源元素解映射4818可以从分配的物理资源元素确定符号和解映射符号。在至少一个实施例中,在信道估计4820中执行信道估计和均衡以补偿多径传播的影响。在至少一个实施例中,可以利用信道估计4820来最小化源自各种传输层和天线的噪声的影响。在至少一个实施例中,信道估计4820可以从资源元素解映射4818的输出生成均衡符号。在至少一个实施例中,解调/解映射4822可以从信道估计4820接收均衡符号。在至少一个实施例中,均衡符号是通过层解映射操作进行解映射和置换。在至少一个实施例中,最大后验概率(map)解调方法可用于产生表示关于接收位为0或1的置信度的值,以对数似然比(llr)的形式表达。
[0579]
在至少一个实施例中,软解调位使用各种操作来处理,包括在ldpc解码之前使用循环缓冲器解扰、解交织和与llr软组合的速率不匹配。在至少一个实施例中,解扰4824可以涉及反转加扰4808的一个或更多个过程的过程。在至少一个实施例中,速率不匹配4826可以涉及反转速率匹配4806的一个或更多个过程的过程。在至少一个实施例中,解扰器4824可以接收来自解调/解映射4822的输出,并对接收到的位进行解扰。在至少一个实施例中,速率不匹配4826可以接收解扰位,并且在ldpc解码4828之前利用循环缓冲器利用llr软组合。
[0580]
在至少一个实施例中,在实际应用中对ldpc码的解码是基于迭代置信传播算法来
完成的。在至少一个实施例中,ldpc码可以以二部图的形式表示,其中大小为m
×
n的奇偶校验矩阵h是定义图节点之间的连接的双邻接矩阵。在至少一个实施例中,矩阵h的m行对应于奇偶校验节点,而n列对应于变量节点,即接收的码字位。在至少一个实施例中,置信传播算法的原理基于迭代消息交换,其中更新变量和校验节点之间的后验概率,直到获得有效码字。在至少一个实施例中,ldpc解码4828可以输出包括数据的传输块。
[0581]
在至少一个实施例中,crc校验4830可以基于附加到接收的传输块的奇偶校验位来确定错误并执行一个或更多个动作。在至少一个实施例中,crc校验4830可以分析和处理附加到接收的传输块的奇偶校验位,或者与crc相关联的任何信息。在至少一个实施例中,crc校验4830可以将处理后的传输块发送到mac层以供进一步处理。
[0582]
应当注意,在各种实施例中,可以是传输块或其其他变体的发送和接收数据可以包括图48中未描绘的各种过程。在至少一个实施例中,图48中描绘的过程并非旨在是详尽无遗的,并且进一步处理(诸如附加调制、映射、复用、预编码、星座映射/解映射、mimo检测、检测、解码及其变体)可以在作为网络的一部分发送和接收数据中利用。
[0583]
图49示出了根据一些实施例的网络的系统4900的架构。在至少一个实施例中,系统4900被示为包括ue 4902、5g接入节点或ran节点(示为(r)an节点4908)、用户平面功能(示为upf 4904)、数据网络(dn4906),例如可以是运营商服务、互联网接入或第3方服务,以及5g核心网(5gc)(显示为cn 4910)。
[0584]
在至少一个实施例中,cn 4910包括认证服务器功能(ausf 4914);核心访问和移动性管理功能(amf 4912);会话管理功能(smf 4918);网络暴露功能(nef 4916);策略控制功能(pcf 4922);网络功能(nf)存储库功能(nrf 4920);统一数据管理(udm 4924);以及应用程序功能(af 4926)。在至少一个实施例中,cn 4910还可以包括未示出的其他元素,例如结构化数据存储网络功能(sdsf)、非结构化数据存储网络功能(udsf)及其变体。
[0585]
在至少一个实施例中,upf 4904可以充当rat内和rat间移动性的锚点、与dn 4906互连的外部pdu会话点以及支持多宿主pdu会话的分支点。在至少一个实施例中,upf 4904还可以执行分组路由和转发、分组检查、执行策略规则的用户平面部分、合法拦截分组(up收集);流量使用报告,为用户平面执行qos处理(例如数据分组过滤、门控、ul/dl速率执行)、执行上行链路流量验证(例如,sdf到qos流映射)、上行链路和下行链路中的传输级数据分组标记以及下行链路数据分组缓冲和下行数据通知触发。在至少一个实施例中,upf 4904可以包括上行链路分类器以支持将业务流路由到数据网络。在至少一个实施例中,dn 4906可以代表各种网络运营商服务、因特网接入或第三方服务。
[0586]
在至少一个实施例中,ausf 4914可以存储用于ue 4902的认证的数据并且处理认证相关的功能。在至少一个实施例中,ausf 4914可以促进用于各种访问类型的通用认证框架。
[0587]
在至少一个实施例中,amf 4912可以负责注册管理(例如,用于注册ue 4902等)、连接管理、可达性管理、移动性管理和amf相关事件的合法拦截,以及接入认证和授权。在至少一个实施例中,amf 4912可以为smf 4918的sm消息提供传输,并且充当用于路由sm消息的透明代理。在至少一个实施例中,amf 4912还可以为ue 4902和sms功能(smsf)(图49未示出)之间的短消息服务(sms)消息提供传输。在至少一个实施例中,amf 4912可以充当安全锚定功能(sea),其可以包括与ausf 4914和ue 4902的交互以及作为ue 4902认证过程的结
果而建立的中间密钥的接收。在使用基于usim的认证的至少一个实施例中,amf 4912可以从ausf 4914检索安全材料。在至少一个实施例中,amf 4912还可以包括安全上下文管理(scm)功能,其从sea接收密钥,它用于导出访问网络特定的密钥。此外,在至少一个实施例中,amf 4912可以是rancp接口的终结点(n2参考点)、nas(ni)信令的终结点,并执行nas加密和完整性保护。
[0588]
在至少一个实施例中,amf 4912还可以支持通过n3互通功能(iwf)接口与ue 4902的nas信令。在至少一个实施例中,n3iwf可用于提供对不可信实体的访问。在至少一个实施例中,n3iwf可以分别是用于控制平面和用户平面的n2和n3接口的终止点,并且因此可以处理来自smf和amf的用于pdu会话和qos的n2信令,用于ipsec和n3隧道的封装/解封装分组,在上行链路中标记n3用户平面数据分组,并考虑与通过n2接收的此类标记相关的qos要求,强制执行与n3数据分组标记相对应的qos。在至少一个实施例中,n3iwf还可以在ue 4902和amf 4912之间中继上行链路和下行链路控制平面nas(ni)信令,并且在ue 4902和upf 4904之间中继上行链路和下行链路用户平面分组。在至少一个实施例中,n3iwf还提供了与ue 4902建立ipsec隧道的机制。
[0589]
在至少一个实施例中,smf 4918可以负责会话管理(例如,会话建立、修改和释放,包括upf和an节点之间的隧道维护);ueip地址分配和管理(包括可选的授权);up功能的选择与控制;在upf配置流量转向以将流量路由到正确的目的地;终止对策略控制功能的接口;控制部分策略执行和qos;合法拦截(用于sm事件和li系统接口);终止nas消息的sm部分;下行数据通知;an特定sm信息的发起者,通过n2上的amf发送到an;确定会话的ssc模式。在至少一个实施例中,smf 4918可以包括以下漫游功能:处理本地实施以应用qosslab(vplmn);计费数据采集和计费接口(vplmn);合法拦截(在vplmn中用于sm事件和与li系统的接口);支持与外部dn交互,以传输外部dn的pdu会话授权/认证信令。
[0590]
在至少一个实施例中,nef 4916可以提供用于安全地暴露由3gpp网络功能为第三方提供的服务和能力、内部暴露/再暴露、应用功能(例如,af 4926)、边缘计算或雾计算系统等的手段。在至少一个实施例中,nef 4916可以认证、授权和/或节流af。在至少一个实施例中,nef 4916还可以翻译与af 4926交换的信息和与内部网络功能交换的信息。在至少一个实施例中,nef 4916可以在af-服务-标识符和内部5gc信息之间进行转换。在至少一个实施例中,nef 4916还可以基于其他网络功能的暴露能力从其他网络功能(nf)接收信息。在至少一个实施例中,该信息可以作为结构化数据存储在nef 4916中,或者使用标准化接口存储在数据存储nf中。在至少一个实施例中,存储的信息然后可以被nef 4916重新暴露给其他nf和af,和/或用于其他目的,例如分析。
[0591]
在至少一个实施例中,nrf 4920可以支持服务发现功能,从nf实例接收nf发现请求,并且将发现的nf实例的信息提供给nf实例。在至少一个实施例中,nrf 4920还维护可用nf实例及其支持的服务的信息。
[0592]
在至少一个实施例中,pcf 4922可以向控制平面功能提供策略规则以实施它们,并且还可以支持统一的策略框架来管理网络行为。在至少一个实施例中,pcf 4922还可以实现前端(fe)以访问与udm 4924的udr中的策略决定相关的订阅信息。
[0593]
在至少一个实施例中,udm 4924可以处理订阅相关信息以支持网络实体对通信会话的处理,并且可以存储ue 4902的订阅数据。在至少一个实施例中,udm 4924可以包括两
个部分,应用程序fe和用户数据存储库(udr)。在至少一个实施例中,udm可以包括udmfe,负责凭证的处理、位置管理、订阅管理等。在至少一个实施例中,几个不同的前端可以在不同的交易中为同一用户服务。在至少一个实施例中,udm-fe访问存储在udr中的订阅信息并进行认证凭证处理;用户身份处理;访问授权;注册/移动管理;以及订阅管理。在至少一个实施例中,udr可以与pcf 4922交互。在至少一个实施例中,udm 4924还可以支持sms管理,其中sms-fe实现与之前讨论的类似的应用逻辑。
[0594]
在至少一个实施例中,af 4926可以提供对流量路由、对网络能力暴露(nce)的访问的应用影响,并且与用于策略控制的策略框架交互。在至少一个实施例中,nce可以是一种允许5gc和af 4926通过nef 4916相互提供信息的机制,其可以用于边缘计算实现。在至少一个实施例中,网络运营商和第三方服务可以托管在ue 4902接入点附近,以通过减少端到端延迟和传输网络上的负载来实现高效的服务交付。在至少一个实施例中,对于边缘计算实现,5gc可以选择靠近ue 4902的upf 4904并通过n6接口执行从upf 4904到dn 4906的流量导向。在至少一个实施例中,这可以基于ue订阅数据、ue位置和af 4926提供的信息。在至少一个实施例中,af 4926可以影响upf(重)选择和业务路由。在至少一个实施例中,基于运营商部署,当af 4926被认为是可信实体时,网络运营商可以允许af 4926直接与相关nf交互。
[0595]
在至少一个实施例中,cn 4910可以包括smsf,其可以负责sms订阅检查和验证,以及向/从ue 4902向/从其他实体中继sm消息,例如sms-gmsc/iwmsc/sms-路由器。在至少一个实施例中,sms还可以与amf 4912和udm 4924交互以用于通知过程ue 4902可用于sms传输(例如,设置ue不可达标志,并在ue 4902可用于sms时通知udm 4924)。
[0596]
在至少一个实施例中,系统4900可以包括以下基于服务的接口:namf:amf展示的基于服务的接口;nsmf:smf展示的基于服务的接口;nnef:nef展示的基于服务的接口;npcf:pcf展示的基于服务的接口;nudm:udm展示的基于服务的接口;naf:af展示的基于服务的接口;nnrf:nrf展示的基于服务的接口;以及nausf:ausf展示的基于服务的接口。
[0597]
在至少一个实施例中,系统4900可以包括以下参考点:n1:ue和amf之间的参考点;n2:(r)an和amf之间的参考点;n3:(r)an和upf之间的参考点;n 4:smf和upf之间的参考点;以及n6:upf和数据网络之间的参考点。在至少一个实施例中,在nf中的nf服务之间可以有更多的参考点和/或基于服务的接口,然而,为了清楚起见省略了这些接口和参考点。在至少一个实施例中,ns参考点可以在pcf和af之间;n7参考点可能在pcf和smf之间;n11参考点在amf和smf之间;等。在至少一个实施例中,cn 4910可以包括nx接口,其是mme和amf 4912之间的cn间接口,以实现cn 4910和cn 7249之间的互通。
[0598]
在至少一个实施例中,系统4900可以包括多个ran节点(例如(r)an节点4908),其中xn接口被定义在连接到5gc 410的两个或更多个(r)an节点4908(例如gnb)之间,在连接到cn 4910和enb(例如,宏ran节点)的(r)an节点4908(例如,gnb)之间,和/或在连接到cn 4910的两个enb之间。
[0599]
在至少一个实施例中,xn接口可以包括xn用户平面(xn-u)接口和xn控制平面(xn-c)接口。在至少一个实施例中,xn-u可以提供用户平面pdu的无保证递送并且支持/提供数据转发和流量控制功能。在至少一个实施例中,xn-c可以提供管理和错误处理功能、管理xn-c接口的功能;ue 4902在连接模式(例如,cm-connected)中的移动性支持,包括管理一
个或更多个(r)an节点4908之间的连接模式的ue移动性的功能。在至少一个实施例中,移动性支持可以包括来自旧(源)服务(r)an节点4908到新(目标)服务(r)an节点4908的上下文转移;以及控制旧(源)服务(r)an节点4908到新(目标)服务(r)an节点4908之间的用户平面隧道。
[0600]
在至少一个实施例中,xn-u的协议栈可以包括建立在互联网协议(ip)传输层上的传输网络层,以及在udp和/或ip层之上的gtp-u层,用于承载用户平面pdu。在至少一个实施例中,xn-c协议栈可以包括应用层信令协议(称为xn应用协议(xn-ap))和建立在sctp层上的传输网络层。在至少一个实施例中,sctp层可以在ip层之上。在至少一个实施例中,sctp层提供应用层消息的有保证的传递。在至少一个实施例中,在传输ip层中使用点对点传输来传递信令pdu。在至少一个实施例中,xn-u协议栈和/或xn-c协议栈可以与在本文示出和描述的用户平面和/或控制平面协议栈相同或相似。
[0601]
在至少一个实施例中,系统4900可以使用具有多种加速器的多处理。例如,在至少一个实施例中,系统4900可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,系统4900可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速器资源。
[0602]
图50是根据一些实施例的控制平面协议栈的图示。在至少一个实施例中,控制平面5000被示为ue 4502(或备选地,ue 4504)、ran 4516和mme 4528之间的通信协议栈。
[0603]
在至少一个实施例中,phy层5002可以通过一个或更多个空中接口发送或接收mac层5004使用的信息。在至少一个实施例中,phy层5002可以进一步执行链路自适应或自适应调制和编码(amc)、功率控制、小区搜索(例如,用于初始同步和切换目的)以及由更高层使用的其他测量,例如rrc层5010。在至少一个实施例中,phy层5002还可以进一步对传输信道执行错误检测、传输信道的前向纠错(fec)编码/解码、物理信道的调制/解调、交织、速率匹配、映射到物理信道,以及多输入多输出(mimo)天线处理。
[0604]
在至少一个实施例中,mac层5004可以执行逻辑信道和传输信道之间的映射,将来自一个或更多个逻辑信道的mac服务数据单元(sdu)复用到传输块(tb)上以经由传输信道传输到phy,将mac sdu从通过传输信道从phy传送的传输块(tb)解复用到一个或更多个逻辑信道,将mac sdu复用到tb,调度信息报告,通过混合自动重复请求(hard)进行纠错,以及逻辑信道优先排序。
[0605]
在至少一个实施例中,rlc层5006可以在多种操作模式下操作,包括:透明模式(tm)、未确认模式(um)和确认模式(am)。在至少一个实施例中,rlc层5006可以执行上层协议数据单元(pdu)的传输、通过用于am数据传输的自动重复请求(arq)的纠错以及用于um和am数据的rlc sdu的级联、分段和重组转让。在至少一个实施例中,rlc层5006还可以执行用于am数据传输的rlc数据pdu的重新分段、为um和am数据传输重新排序rlc数据pdu、检测用于um和am数据传输的重复数据、丢弃用于um和am数据传输的rlc sdu,检测am数据传输的协议错误,并执行rlc重建。
[0606]
在至少一个实施例中,pdcp层5008可以执行ip数据的报头压缩和解压缩、维护pdcp序列号(sn)、在重建下层时执行上层pdu的顺序传送、消除重复重新建立映射在rlcam上的无线电承载的低层sdu,加密和解密控制平面数据,执行控制平面数据的完整性保护和完整性验证,控制基于定时器的数据丢弃,并执行安全操作(例如、加密、解密、完整性保护、
完整性验证等)。
[0607]
在至少一个实施例中,rrc层5010的主要服务和功能可以包括系统信息的广播(例如,包括在与非接入层(nas)相关的主信息块(mib)或系统信息块(sib)中)、与接入层(as)相关的系统信息的广播、ue和e-utran之间rrc连接的寻呼、建立、维护和释放(例如,rrc连接寻呼、rrc连接建立、rrc连接修改,和rrc连接释放),点对点无线承载的建立、配置、维护和释放,安全功能包括密钥管理、无线接入技术(rat)间移动性和用于ue测量报告的测量配置。在至少一个实施例中,所述mib和sib可以包括一个或更多个信息元素(ie),其每个可以包括单独的数据字段或数据结构。
[0608]
在至少一个实施例中,ue 4502和ran 4516可以利用uu接口(例如,lte-uu接口)经由包括phy层5002、mac层5004、rlc层5006、pdcp层5008和rrc层5010的协议栈交换控制平面数据。
[0609]
在至少一个实施例中,非接入层(nas)协议(nas协议5012)形成ue 4502和mme 4528之间的控制平面的最高层。在至少一个实施例中,nas协议5012支持ue 4502的移动性和会话管理过程,以在ue 4502和p-gw 4534之间建立和维护ip连接。
[0610]
在至少一个实施例中,si应用协议(s1-ap)层(si-ap层5022)可以支持si接口的功能并且包括基本过程(ep)。在至少一个实施例中,ep是ran 4516和cn 4528之间的交互单元。在至少一个实施例中,s1-ap层服务可以包括两组:ue相关服务和非ue相关服务。在至少一个实施例中,这些服务执行的功能包括但不限于:e-utran无线接入承载(e-rab)管理、ue能力指示、移动性、nas信令传输、ran信息管理(rim)和配置传输。
[0611]
在至少一个实施例中,流控制传输协议(sctp)层(或者称为流控制传输协议/互联网协议(sctp/ip)层)(sctp层5020)可以确保信令消息在ran 4516和mme 4528部分地基于ip协议可靠地传送,由ip层5018支持。在至少一个实施例中,l2层5016和l1层5014可以指通信链路(例如,有线或无线)被ran节点和mme用来交换信息。
[0612]
在至少一个实施例中,ran 4516和mme 4528可以利用s1-mme接口经由包括l1层5014、l2层5016、ip层5018、sctp层5020和si-ap层5022的协议栈来交换控制平面数据。
[0613]
在至少一个实施例中,控制平面5000上的系统可以使用具有多种加速器的多处理。在至少一个实施例中,例如,控制平面5000可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,片上系统集成电路2100可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速器资源。
[0614]
图51是根据至少一个实施例的用户平面协议栈的图示。在至少一个实施例中,用户平面5100被示为ue 4502、ran 4516、s-gw 4530和p-gw4534之间的通信协议栈。在至少一个实施例中,用户平面5100可以使用相同的协议层作为控制平面5000。例如,在至少一个实施例中,ue 4502和ran 4516可以利用uu接口(例如,lte-uu接口)经由包括phy层5002、mac层5004、rlc层5006、pdcp层5008的协议栈来交换用户平面数据。
[0615]
在至少一个实施例中,用于用户平面(gtp-u)层(gtp-u层5104)的通用分组无线服务(gprs)隧道协议可用于在gprs核心网络内以及在无线接入网络和核心网之间承载用户数据。在至少一个实施例中,传输的用户数据可以是例如ipv4、ipv6或ppp格式中的任一种的分组。在至少一个实施例中,udp和ip安全(udp/ip)层(udp/ip层5102)可以提供用于数据完整性的校验和、用于在源和目的地寻址不同功能的端口号以及对选定数据流的加密和认
证。在至少一个实施例中,ran 4516和s-gw 4530可以利用s1-u接口经由包括l1层5014、l2层5016、udp/ip层5102和gtp-u层5104的协议栈来交换用户平面数据。在至少一个实施例中,s-gw 4530和p-gw 4534可以利用s5/s8a接口经由包括l1层5014、l2层5016、udp/ip层5102和gtp-u层5104的协议栈来交换用户平面数据。在至少一个实施例中,如上文关于图50所讨论的,nas协议支持ue 4502的移动性和会话管理过程,以在ue 4502和p-gw 4534之间建立和维持ip连接。
[0616]
在至少一个实施例中,用户平面5100可以使用具有多种加速器的多处理。在至少一个实施例中,例如,用户平面5100可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,用户平面5100可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0617]
图52示出了根据至少一个实施例的核心网络的组件5200。在至少一个实施例中,cn 4538的组件可以在一个物理节点或单独的物理节点中实现,包括从机器可读或计算机可读介质(例如,非暂时性机器可读存储介质)读取和执行指令的组件。在至少一个实施例中,网络功能虚拟化(nfv)用于经由存储在一个或更多个计算机可读存储介质中的可执行指令来虚拟化上述网络节点功能中的任何一个或所有(下面进一步详细描述)。在至少一个实施例中,cn 4538的逻辑实例可以被称为网络切片5202(例如,网络切片5202被示为包括hss 4532、mme 4528和s-gw 4530)。在至少一个实施例中,cn 4538的一部分的逻辑实例可以被称为网络子切片5204(例如,网络子切片5204被示为包括p-gw 4534和pcrf 4536)。
[0618]
在至少一个实施例中,nfv架构和基础设施可用于将一个或更多个网络功能虚拟化,或者由专有硬件执行到物理资源上,该物理资源包括行业标准服务器硬件、存储硬件或交换机的组合。在至少一个实施例中,nfv系统可用于执行一个或更多个epc组件/功能的虚拟或可重新配置的实现。
[0619]
在至少一个实施例中,组件5200可以使用具有多种加速器的多处理。例如,在至少一个实施例中,组件5200可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,组件5200可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速资源。
[0620]
图53是说明根据至少一个实施例的支持网络功能虚拟化(nfv)的系统5300的组件的框图。在至少一个实施例中,系统5300被示为包括虚拟化基础设施管理器(示为vim 5302)、网络功能虚拟化基础设施(示为nfvi 5304)、vnf管理器(示为vnfm 5306)、虚拟化网络功能(示为vnf 5308)、元素管理器(示为em 5310)、nfvo协调器(示为nfvo 5312)和网络管理器(示为nm 5314)。
[0621]
在至少一个实施例中,vim 5302管理nfvi 5304的资源。在至少一个实施例中,nfvi 5304可以包括用于执行系统5300的物理或虚拟资源和应用程序(包括管理程序)。在至少一个实施例中,vim 5302可以使用nfvi 5304管理虚拟资源的生命周期(例如,与一个或更多个物理资源相关联的虚拟机(vm)的创建、维护和拆除),跟踪vm实例,跟踪vm实例的性能、故障和安全性和关联的物理资源,并将vm实例和关联的物理资源暴露给其他管理系统。
[0622]
在至少一个实施例中,vnfm 5306可以管理vnf 5308。在至少一个实施例中,vnf 5308可以用于执行epc组件/功能。在至少一个实施例中,vnfm 5306可以管理vnf 5308的生
命周期并跟踪vnf 5308的虚拟方面的性能、故障和安全性。在至少一个实施例中,em 5310可以跟踪vnf 5308的功能方面的性能、故障和安全性。在至少一个实施例中,来自vnfm 5306和em 5310的跟踪数据可以包括,例如,由vim 5302或nfvi 5304使用的性能测量(pm)数据。在至少一个实施例中,vnfm 5306和em 5310都可以扩展上/下系统5300的vnf数量。
[0623]
在至少一个实施例中,nfvo 5312可以协调、授权、释放和使用nfvi 5304的资源以提供请求的服务(例如,执行epc功能、组件或切片)。在至少一个实施例中,nm 5314可以提供负责管理网络的最终用户功能包,其可以包括具有vnf、非虚拟化网络功能或两者的网络元素(vnf的管理可以通过em 5310)。
[0624]
在至少一个实施例中,系统5300可以使用具有多种加速器的多处理。例如,在至少一个实施例中,系统5300可以具有cpu,以及协助处理的多个dsp、asic或gpu。在至少一个实施例中,为了有效地使用加速器,系统5300可以实现如上所述的api,使得应用程序可以以简单的方式有效地使用加速器资源。
[0625]
本公开的至少一个实施例可以考虑以下条款来描述:
[0626]
1.一种其上存储有应用程序编程接口(api)的机器可读介质,如果所述应用程序编程接口由一个或更多个处理器执行,则使所述一个或更多个处理器至少:使存储在分配给第一处理器的第一存储器位置中的信息与第二处理器共享。
[0627]
2.如条款1所述的机器可读介质,其中,所述应用程序编程接口的执行还使所述一个或更多个处理器:从队列中移除由应用程序生成的工作流,所述工作流具有多个工作负载;使得在所述第一处理器上执行所述多个工作负载中的第一工作负载;以及使得在所述第二处理器上执行所述多个工作负载中的第二工作负载。
[0628]
3.如条款2所述的机器可读介质,其中,所述多个工作负载中的每个工作负载具有由所述应用程序提供的关联加速分布;以及所述应用程序编程接口至少部分地基于与所述多个工作负载中的个体工作负载相关联的加速分布将所述个体工作负载引导到特定处理器。
[0629]
4.如条款3所述的机器可读介质,其中,所述多个工作负载包括具有第一加速分布的第一工作负载和具有第二加速分布的第二工作负载;以及所述第一加速分布不同于所述第二加速分布。
[0630]
5.如条款1至4中任一项所述的机器可读介质,其中,所述信息使用直接存储器访问从所述第一处理器传送到所述第二处理器。
[0631]
6.如条款1至5中任一项所述的机器可读介质,其中,所述应用程序编程接口实现向所述第一处理器和所述第二处理器两者提供接口的逻辑设备。
[0632]
7.如条款1至6中任一项所述的机器可读介质,其中,所述第一处理器或所述第二处理器是现场可编程门阵列、专用集成电路、数字信号处理器、图形处理单元或中央处理单元。
[0633]
8.如条款1至7中任一项所述的机器可读介质,其中,所述信息包括要由所述第二处理器执行的指令。
[0634]
9.如条款2至8中任一项所述的机器可读介质,其中,所述应用程序编程接口在单个出队操作中从所述队列获得所述工作流。
[0635]
10.一种计算机系统,包括一个或更多个处理器和用于存储可执行指令的机器可
读介质,所述可执行指令由于由所述一个或更多个处理器执行,使所述计算机系统实现应用程序编程接口(api),所述应用程序编程接口使存储在分配给第一处理器的第一存储器位置中的信息与第二处理器共享。
[0636]
11.如条款10所述的计算机系统,其中,所述应用程序编程接口的执行还使所述一个或更多个处理器:从工作流队列中移除应用程序提交的单个工作流形式的多个工作负载;在所述第一处理器上执行所述多个工作负载中的第一工作负载;以及使所述第一处理器在所述第二处理器上执行所述多个工作负载中的第二工作负载。
[0637]
12.如条款11所述的计算机系统,其中,所述多个工作负载中的每个工作负载具有关联加速分布,所述关联加速分布识别执行关联工作负载所需的加速器的能力。
[0638]
13.如条款12所述的计算机系统,其中,所述多个工作负载中的第一工作负载和所述多个工作负载中的第二工作负载具有不同的加速分布。
[0639]
14.如条款12或13所述的计算机系统,其中,所述应用程序编程接口至少部分地基于与所述多个工作负载中的个体工作负载相关联的加速分布,使所述个体工作负载由特定处理器执行。
[0640]
15.如条款10至14中任一项所述的计算机系统,其中,所述应用程序编程接口实现能够将工作负载分派到所述第一处理器和所述第二处理器两者的单个逻辑设备。
[0641]
16.如条款10至15中任一项所述的计算机系统,其中,所述第一处理器或所述第二处理器并行地执行工作流的部分。
[0642]
17.如条款10至16中任一项所述的计算机系统,其中,与所述第二处理器共享的所述信息包括要由所述第二处理器执行的可执行指令。
[0643]
18.如条款11至17中任一项所述的计算机系统,其中,所述第一处理器或所述第二处理器串行地执行所述工作流的部分。
[0644]
19.一种计算机实现的方法,包括执行应用程序编程接口(api),所述应用程序编程接口使得存储在分配给第一处理器的第一存储器位置中的信息与第二处理器共享。
[0645]
20.如条款19所述的计算机实现的方法,其中,所述应用程序编程接口的执行进一步:从队列中移除由应用程序生成的工作流,所述工作流具有多个工作负载;使所述多个工作负载中的第一工作负载在所述第一处理器上执行;以及使所述多个工作负载中的第二工作负载在所述第二处理器上执行。
[0646]
21.如条款20所述的计算机实现的方法,其中,所述多个工作负载中的每个工作负载具有关联加速分布,所述关联加速分布描述能够执行所述工作负载的加速器的特性。
[0647]
22.如条款21所述的计算机实现的方法,其中,所述多个工作负载包括具有第一加速分布的第一工作负载和具有第二加速分布的第二工作负载;以及所述第一加速分布不同于所述第二加速分布。
[0648]
23.如条款21或22所述的计算机实现的方法,其中,所述应用程序编程接口至少部分地基于与所述多个工作负载中的个体工作负载相关联的加速分布将所述个体工作负载引导到特定处理器。
[0649]
24.如条款19至23中任一项所述的计算机实现的方法,其中,所述应用程序编程接口包括将工作负载分配给所述第一处理器和所述第二处理器两者的逻辑设备。
[0650]
25.如条款24所述的计算机实现的方法,其中,第一工作负载和第二工作负载由所
述第一处理器和所述第二处理器串行地执行。
[0651]
26.如条款19至25中任一项所述的计算机实现的方法,其中,所述信息标识要由所述第二处理器执行的指令。
[0652]
27.如条款20至26中任一项所述的计算机实现的方法,其中,所述应用程序编程接口在单个出队操作中从所述队列获得所述工作流。
[0653]
28.一种处理器,包括:实现应用程序编程接口(api)的一个或更多个电路,如果所述应用程序编程接口由所述处理器执行,则使存储在分配给第一处理器的第一存储器位置中的信息与第二处理器共享。
[0654]
29.如条款28所述的处理器,其中,所述应用程序编程接口的执行还使所述处理器:从队列中移除由应用程序生成的工作流,所述工作流具有多个工作负载;使所述多个工作负载中的第一工作负载在所述第一处理器上执行;以及使所述多个工作负载中的第二工作负载在所述第二处理器上执行。
[0655]
30.如条款29所述的处理器,其中,所述多个工作负载中的每个工作负载与所述应用程序编程接口可访问的关联加速分布相关联。
[0656]
31.如条款30所述的处理器,其中,所述多个工作负载中的各个工作负载具有不同的加速分布;以及所述不同的加速分布导致所述多个工作负载由不同类型的加速器执行。
[0657]
32.如条款30或31所述的处理器,其中,所述应用程序编程接口至少部分地基于与所述多个工作负载中的个体工作负载相关联的加速分布将所述个体工作负载引导到特定处理器。
[0658]
33.如条款28至32中任一项所述的处理器,其中,所述应用程序编程接口实现与所述第一处理器和所述第二处理器两者接口的逻辑设备。
[0659]
34.如条款28至33中任一项所述的处理器,其中,所述信息包括由所述第一处理器产生的中间结果。
[0660]
35.如条款29至35中任一项所述的处理器,其中,应用程序在单个入队操作中将整个工作流添加到所述队列。
[0661]
36.如条款28至35中任一项所述的处理器,其中,所述第一处理器是虚拟处理器。
[0662]
其他变化在本公开的精神内。因此,虽然所公开的技术易于进行各种修改和替代构造,但其某些图示实施例在附图中示出并且已经在上面详细描述。然而,应当理解,无意将公开内容限制于所公开的特定形式或形式,而是相反,意图是涵盖落入公开内容的精神和范围内的所有修改、替代构造和等同物,如所附权利要求所定义的。
[0663]
除非本文另有说明,否则在描述公开的实施例的上下文中(尤其是在以下权利要求的上下文中)使用术语“一个(a)”和“一个(an)”和“该(the)”以及类似的指代应被解释为涵盖单数和复数。显然与上下文矛盾,而不是作为术语的定义。除非另有说明,否则术语“包括(comprising)”、“具有(having)”、“包括(including)”和“包含(containing)”应被解释为开放式术语(意为“包括但不限于”)。术语“连接”,当未经修改并指物理连接时,应被解释为部分或全部包含在内部、连接到或连接在一起,即使有一些干预。除非本文另有说明,否则本文对数值范围的引用仅旨在作为单独提及落入范围内的每个单独值的速记方法,并且将每个单独值并入说明书中,就好像它在本文中单独引用一样。在至少一个实施例中,除非另有说明或与上下文相矛盾,否则术语“集合”(例如,“一组项目”)或“子集”的使用将被解
释为包括一个或更多个成员的非空集合。此外,除非另有说明或与上下文相矛盾,否则对应集合的术语“子集”不一定表示对应集合的真子集,而子集与对应集合可以相等。
[0664]
连接语言,例如“a、b和c中的至少一个”或“a、b和c中的至少一个”形式的短语,除非另有特别说明或与上下文明显矛盾,否则为结合上下文理解为一般用于表示项目、术语等可以是a或b或c,或a和b和c的集合的任何非空子集。例如,在具有以下特征的集合的说明性示例中三个成员,连词“a、b和c中的至少一个”和“a、b和c中的至少一个”是指以下任一集合:{a}、{b}、{c}、{a,b}、{a,c}、{b,c}、{a,b,c}。因此,这样的连词一般不旨在暗示某些实施例需要a中的至少一个、b中的至少一个和c中的至少一个每个都存在。此外,除非另有说明或与上下文相矛盾,否则术语“多个”表示复数的状态(例如,“多个项目”表示多个项目)。在至少一个实施例中,多个项目的数量至少为两个,但是当明确地或通过上下文如此指示时可以更多。此外,除非另有说明或上下文清楚,否则短语“基于”是指“至少部分基于”而不是“仅基于”。
[0665]
除非本文另有说明或与上下文明显矛盾,否则本文描述的过程的操作可以以任何合适的顺序执行。在至少一个实施例中,诸如本文描述的那些过程(或其变体和/或组合)的过程在配置有可执行指令的一个或更多个计算机系统的控制下执行并且被实现为代码(例如,可执行指令、一个或更多个)多个计算机程序或一个或更多个应用程序)通过硬件或其组合在一个或更多个处理器上共同执行。在至少一个实施例中,代码例如以包括可由一个或更多个处理器执行的多个指令的计算机程序的形式存储在计算机可读存储介质上。在至少一个实施例中,计算机可读存储介质是不包括瞬时信号(例如,传播的瞬时电或电磁传输)但包括非瞬时数据存储电路(例如,缓冲器、缓存和队列)在瞬态信号的收发器内。在至少一个实施例中,代码(例如,可执行代码或源代码)被存储在其上存储了可执行指令(或用于存储可执行指令的其他存储器)的一组一个或更多个非暂时性计算机可读存储介质上,当由计算机系统的一个或更多个处理器执行(即,作为被执行的结果)导致计算机系统执行本文描述的操作。一组非暂时性计算机可读存储介质,在至少一个实施例中,包括多个非暂时性计算机可读存储介质和多个非暂时性计算机可读存储介质中的一个或更多个单独的非暂时性存储介质。所有代码,而多个非暂时性计算机可读存储介质共同存储所有代码。在至少一个实施例中,可执行指令被执行以使得不同的指令由不同的处理器执行——例如,非暂时性计算机可读存储介质存储指令并且主中央处理单元(“cpu”)执行一些指令,同时图形处理单元(“gpu”)执行其他指令。在至少一个实施例中,计算机系统的不同组件具有单独的处理器并且不同的处理器执行不同的指令子集。
[0666]
因此,在至少一个实施例中,计算机系统被配置为实现一种或更多种服务,这些服务单独或共同执行本文描述的过程的操作,并且这样的计算机系统被配置有能够执行操作的适用硬件和/或软件。此外,实现本公开的至少一个实施例的计算机系统是单个设备,并且在另一个实施例中,是分布式计算机系统,包括多个操作不同的设备,使得分布式计算机系统执行本文描述的操作并且使得单个设备不执行所有操作。
[0667]
本文提供的任何和所有示例或示例性语言(例如,“诸如”)的使用仅旨在更好地阐明公开的实施例并且不对公开的范围构成限制,除非另有声明。说明书中的任何语言都不应被解释为表明任何未要求保护的元素对于公开的实践是必不可少的。
[0668]
在此引用的所有参考文献,包括出版物、专利申请和专利,都以相同的程度并入本
文作为参考,就好像每篇参考文献被单独地和具体地指示为以引用方式并入并在此整体阐述一样。
[0669]
在描述和权利要求中,可以使用术语“耦合”和“连接”及其派生词。应当理解,这些术语可能并非旨在作为彼此的同义词。相反,在特定示例中,“连接”或“耦合”可用于指示两个或更多个元件彼此直接或间接物理或电接触。“耦合”也可能意味着两个或更多个元件彼此不直接接触,但仍然相互合作或相互作用。
[0670]
除非另外特别说明,否则可以理解,贯穿说明书的术语诸如“处理”、“计算(computing)”、“计算(calculating)”、“确定”等,指的是计算机或计算系统的动作和/或过程或类似的电子计算设备,用于操作和/或转换表示为物理量的数据,例如计算系统的寄存器和/或存储器中的电子量,转换为类似地表示为计算系统的存储器、寄存器或其他此类信息存储、传输或显示设备中的物理量的其他数据。
[0671]
以类似的方式,术语“处理器”可以指处理来自寄存器和/或存储器的电子数据并将该电子数据转换成可以存储在寄存器和/或存储器中的其他电子数据的任何设备或设备的一部分。记忆。作为非限制性示例,“处理器”可以是cpu或gpu。“计算平台”可以包括一个或更多个处理器。如本文所使用的,“软件”进程可以包括例如随时间执行工作的软件和/或硬件实体,例如任务、线程和智能代理。此外,每个进程可以指多个进程,用于依次或并行、连续或间歇地执行指令。术语“系统”和“方法”在本文中可互换使用,只要系统可以体现一种或更多种方法并且方法可以被认为是系统。
[0672]
在本文件中,可以参考获得、获取、接收模拟或数字数据或将模拟或数字数据输入到子系统、计算机系统或计算机实现的机器中。获取、获得、接收或输入模拟和数字数据的过程可以通过多种方式来完成,例如通过接收数据作为函数调用的参数或对应用程序接口的调用。在一些实施方式中,可以通过串行或并行接口传输数据来完成获取、获得、接收或输入模拟或数字数据的过程。在另一种实现方式中,获取、获得、接收或输入模拟或数字数据的过程可以通过计算机网络从提供实体向获取实体传输数据来完成。还可以参考提供、输出、传输、发送或呈现模拟或数字数据。在各种示例中,提供、输出、传输、发送或呈现模拟或数字数据的过程可以通过将数据作为函数调用的输入或输出参数、应用程序编程接口的参数或进程间通信机制的参数传输来完成。
[0673]
虽然上面的讨论阐述了所描述技术的示例实现,但是其他架构可以用于实现所描述的功能,并且旨在落入本公开的范围内。此外,虽然以上为了讨论的目的定义了具体的职责分配,但是根据情况,各种功能和职责可能以不同的方式分配和划分。
[0674]
此外,虽然主题已经以结构特征和/或方法行为特定的语言进行了描述,但是应当理解,在所附权利要求中要求保护的主题不一定限于所描述的特定特征或行为。相反,具体特征和动作被公开为实施权利要求的示例性形式。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。