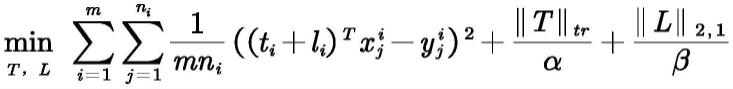
1.本发明涉及光谱分析领域,尤其涉及一种用于近红外光谱仪测量光谱预测的评估模型构建方法,是基于多任务学习机制的评估模型构建方法。
背景技术:
2.目前,近红外光谱分析技术在农业、石化、制药、食品等多个行业广泛应用,近红外光谱仪器也不再是高精尖的科研设备,而是工厂不可或缺的生产设备。
3.近红外光谱仪在使用过程中,例如:在多条线并行水果检测线上,每条线都要用近红外光谱仪测试水果的某项品质,为了保障检测的精确度,就需要建立待测产品的物理化学特征与其近红外光谱之间的评估关系模型,通过模型对每一次获取的光谱进行标定。为此,需要借助标准样品进行这种模型的建立,标准样品是一批已经测得物理或化学特征的产品,它们往往需要大量的时间来收集,并且对于水果类样本难以使其物理和化学特征始终保持稳定。对于每一批被测产品,参与测试的近红外光谱仪都需要一批数量相当大标准样品参与模型的建立,通常建模的过程需要参与检测的每一台仪器都要对全部标准样品进行检测,这就导致整个的建模测试周期相当漫长,降低了评估关系模型的准确性,并且也降低了工作效率。因此,急需解决这一问题。
技术实现要素:
4.本发明的目的是提出一种用于近红外光谱仪测量光谱预测的评估模型构建方法,是基于多任务学习机制的评估模型构建方法,通过该方法不需要每一台检测仪对所有标准样品进行数据采集,加快了评估模型构建速度。
5.为了实现上述目的,本发明的技术方案是:
6.用于近红外光谱仪测量光谱预测的评估模型构建方法,包括多台参与产品检测的近红外光谱仪和已经获取的多个标准样本,其中:所述评估模型构建方法包括:
7.第一步:参与产品检测的多台近红外光谱仪对多个标准样本分别进行采集得到各近红外光谱仪对多个标准样本的光谱数据,其中一台近红外光谱仪采集的标准样本多于其余近红外光谱仪采集的标准样本;
8.第二步:分别对多台近红外光谱仪所采集的光谱数据进行去噪声处理;
9.第三步:对多台近红外光谱仪所采集的光谱数据进行一致化处理,其过程是:以采集测量标准样本最多的光谱仪光谱数据的平均光谱为理想光谱,用所述理想光谱对其余光谱仪的光谱数据进行多元散射矫正;
10.第四步:对多台近红外光谱仪一致化处理后的光谱数据使用多任务学习模型并行训练,利用寻优算法优化模型参数得到各波长权重;
11.第五步:由权重得到评估模型:
12.y
forecast
=w*s
13.其中:
14.y
forecast
为预测对象,
15.w为波长权重,
16.s为这台光谱仪的测量光谱。
17.方案进一步是:
18.所述多任务学习模型公式为:
[0019][0020]
其中:
[0021]
m是作为任务数量的近红外光谱仪数量,n为每个任务的标准样本光谱数量,x为每条光谱数据,y为待建立联系的参量,||t||
tr
与||l||
2,1
为迹范数l
2,1
范数,用于建立任务间的联系与约束,α,β为第一、第二权重系数范围在1e-6到1e6之间选取,ti与li为待求的波长权重。
[0022]
方案进一步是:所述利用寻优算法优化模型参数是使用粒子群寻优、遗传算法、贝叶斯优化方法对所述第一、第二权重系数寻优。
[0023]
方案进一步是:所述去噪声处理是利用savitzky-golay卷积法消除各仪器光谱数据的噪声,所述savitzky-golay卷积法表达式为:
[0024][0025]
其中:
[0026]
m为加窗宽度,ps为波长点s的平滑系数;
[0027]
ps=x
′
l s
/x
l s
;
[0028]
x
′
l s
为波长点l s的光谱吸光度拟合值,x
l s
为波长点l s的光谱吸光度真实值,x
′
l s
通过最小二乘法对样本光谱拟合获得;其中的加窗宽度为7,最小二乘拟合阶次为2。
[0029]
方案进一步是:所述平均光谱的求解公式为:
[0030][0031]
其中为光谱数据a
st
的平均光谱,为第i个样本的光谱,n为样本集光谱数量。
[0032]
方案进一步是:用所述理想光谱对其余光谱仪的光谱数据进行多元散射矫正的过程是:
[0033]
首先将光谱仪中每个样本的光谱与所述平均光谱进行一元线性回归,求解最小二乘问题得到每个样本的基线平移量和偏移量;随后对每个样本的光谱减去求得的基线平移量后除以偏移量,得到矫正后的光谱。
[0034]
方案进一步是:所述方法进一步包括:在完成第一步后,将各近红外光谱仪对多个标准样本的光谱数据进行标准化处理,公式为:
[0035][0036]
s为原始光谱,s
st
为标准化后的光谱,μ为所有标准样本光谱的平均值,σ为标准样本光谱间的标准差。
[0037]
本发明的有益效果是:减少了参与检测的近红外光谱仪对标准样本检测的工作量,通过多任务学习机制,达成利用各个仪器数据集之间的相关性,加快了评估模型构建速度,提高了评估关系模型的准确性以及工作效率。
[0038]
下面结合附图和实施例对本发明作一详细描述。
附图说明
[0039]
图1为方法流程示意图;
[0040]
图2为m5、mp5、mp6三台光谱仪光谱数据进行消噪后的光谱;
[0041]
图3为三台光谱仪预测值在测试集上的表现。
具体实施方式
[0042]
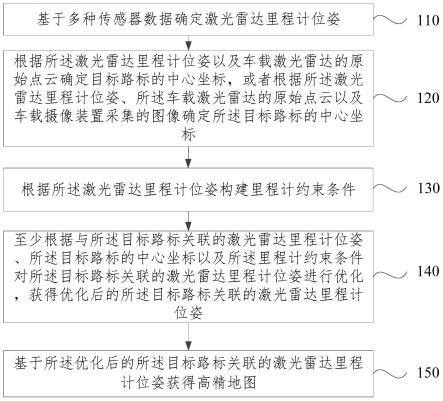
一种用于近红外光谱仪测量光谱预测的评估模型构建方法,包括多台参与产品检测的近红外光谱仪和已经获取的多个标准样本,其中:如图1所示,所述评估模型构建方法包括:
[0043]
第一步:光谱数据准备,参与产品检测的多台近红外光谱仪对多个标准样本分别进行采集得到各近红外光谱仪对多个标准样本的光谱数据,其中一台近红外光谱仪采集的标准样本多于其余近红外光谱仪采集的标准样本;
[0044]
第二步:分别对多台近红外光谱仪所采集的光谱数据进行去噪声处理;
[0045]
第三步:对多台近红外光谱仪所采集的光谱数据进行一致化处理,其过程是:以采集测量标准样本最多的光谱仪光谱数据的平均光谱为理想光谱,用所述理想光谱对其余光谱仪的光谱数据进行多元散射矫正,提高光谱数据集的特征一致性;
[0046]
第四步:对多台近红外光谱仪一致化处理后的光谱数据使用多任务学习模型并行训练,利用寻优算法优化模型参数得到各波长权重;
[0047]
第五步:由权重得到评估模型:
[0048]yforecast
=w*s
[0049]
其中:
[0050]yforecast
为预测对象,
[0051]
w为波长权重,
[0052]
s为这台光谱仪的测量光谱。
[0053]
方法中的所述多任务学习模型公式为:
[0054][0055]
其中:
[0056]
m是作为任务数量的近红外光谱仪数量,n为每个任务的标准样本光谱数量,x为每
条光谱数据,y为待建立联系的参量,||t||
tr
与||l||
2,1
为迹范数l
2,1
范数,用于建立任务间的联系与约束,α,β为第一、第二权重系数范围在1e-6到1e6之间选取,ti与li为待求的波长权重。
[0057]
所述多任务学习模型公式是一个最小化求解,因此没有等号,公式的求解可以通过公知的梯度下降法求取,这与神经网络的求解方法一样。ti与li即为公式待求的参量,普遍意义上可以通过梯度下降法求取。其中的“||t||
tr
与||l||
2,1
为迹范数l
2,1
范数,是两种矩阵范数,是公知的,是高数和线性代数基础知识;具体表现形式如下:
[0058][0059]
迹范数是矩阵奇异值的和,l21范数是矩阵列向量l2范数的和。
[0060]
其中的所述利用寻优算法优化模型参数是使用但不限于粒子群寻优、遗传算法、贝叶斯优化方法对所述第一、第二权重系数寻优,随后利用加速近端算法求解多任务学习。寻优是对模型公式结果进行的,过程可以理解为寻找可以使模型公式最优的第一、第二权重系数。通过不断对权重系数赋值,得到模型公式的结果,从而通过一定的规则选取模型公式值最小的权重系数。
[0061]
前述方法中:所述去噪声处理是利用savitzky-golay卷积法消除各仪器光谱数据的噪声,所述savitzky-golay卷积法表达式为:
[0062][0063]
其中:
[0064]
m为加窗宽度,ps为波长点s的平滑系数;
[0065]
ps=x
′
l s
/x
l s
;
[0066]
x
′
l s
为波长点l s的光谱吸光度拟合值,x
l s
为波长点l s的光谱吸光度真实值,x
′
l s
通过最小二乘法对样本光谱拟合获得;其中的加窗宽度为7,最小二乘拟合阶次为2。
[0067]
前述方法中:所述平均光谱的求解公式为:
[0068][0069]
其中为光谱数据a
st
的平均光谱,为第i个样本的光谱,n为样本集光谱数量。
[0070]
其中:用所述理想光谱对其余光谱仪的光谱数据进行多元散射矫正的过程是:
[0071]
首先将光谱仪中每个样本的光谱与所述平均光谱进行一元线性回归,求解最小二乘问题得到每个样本的基线平移量和偏移量;随后对每个样本的光谱减去求得的基线平移量后除以偏移量,得到矫正后的光谱。
[0072]
所述方法进一步包括:在完成第一步后,将各近红外光谱仪对多个标准样本的光谱数据进行标准化处理,公式为:
[0073][0074]
s为原始光谱,s
st
为标准化后的光谱,μ为所有标准样本光谱的平均值,σ为标准样本光谱间的标准差。
[0075]
下面是一个通过三台近红外光谱仪实现测量光谱预测的评估模型构建案例:案例使用真实的玉米光谱数据集,玉米数据集包含40个样本,由光谱仪m5,mp5和mp6测量得到的从1100nm到2400nm的连续光谱数据,每2nm一个波长点,待测特征为脂肪含量,从9.3%-10.1%。其中,选择m5所测光谱中的20个样本为训练集,mp5所测光谱中的10个样本为训练集,mp6所测光谱中10个样本为训练集,其余样本作为测试集;上述采样说明:所述采集测量标准样本最多的光谱仪采集的标准样本是其余近红外光谱仪采集的标准样本的2倍。
[0076]
首先,利用savitzky-golay卷积法消除各仪器光谱数据的噪声,经过savitzky-golay卷积法消噪地光谱如图2所示。
[0077]
利用寻优算法优化模型参数,将多个光谱仪的数据集使用多任务学习方法并行训练。利用贝叶斯优化对多任务学习中地第一权重系数、第二权重系数进行优化。利用加速近端算法,求解多任务学习方法。提取多任务学习得到的各波长的权重,得到最终模型,其中,对于某台光谱仪,提取得到其波长权重,w=t l,得到评估模型:
[0078]yforecast
=w*s
[0079]
其中,y
forecast
为预测对象,w为波长权重,s为这台光谱仪的测量光谱。
[0080]
模型预测性能的评价指标,采用均方根误差rmse的计算公式为:
[0081][0082]
其中,为样本待测物理化学性质的预测值,为样本待测物理化学性质的实际值,三台光谱仪同时标定的模型在测试集上的表现如图3所示,与每台单独建模的pls方法rmse比较结果如下表1所示。
[0083]
表1
[0084][0085]
上述用于近红外光谱仪测量光谱预测的评估模型构建方法实施例,利用了任务间的相关性,即相同物质特征的近红外光谱波段变化的一致性,在各个仪器样本数都较少的情况下,提高模型的泛化能力和评估性能。并且,减少了参与检测的近红外光谱仪对标准样本检测的工作量,通过多任务学习机制,达成利用各个仪器数据集之间的相关性,加快了评估模型构建速度,提高了评估关系模型的准确性以及工作效率。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。