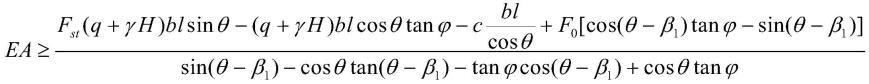
1.本技术涉及电力数据处理技术领域,尤其涉及一种基于多源异构电力数据的数据关联方法。
背景技术:
2.在电网系统中数据复杂多样,还具有实时性、分布式等特性,不仅数据来源多样,而且数据也存在很大差异,结构化数据、半结构化数据和非结构化数据共存。在不同的数据源中同一数据可能存在不同的表示方法,在融合不同数据源的时,需要将同一数据识别出来,这一问题被称为数据关联问题。如果能够识别不同数据源中的数据,并融合数据属性,就能获取更完整和准确的信息。
3.相关技术中,数据关联方法一般基于字符串匹配,此类数据关联方法能够覆盖的维度(一般仅限名称、地址)较为单一,而电力档案数据和其他非电力数据的质量一般都参差不齐,需要尽可能使用多个维度进行关联并交叉校验,基于字符串匹配的数据关联方法难以保证数据关联的准确率。
技术实现要素:
4.为了解决电力数据在不同数据源中表示不同的问题,本技术实施例提供一种基于多源异构电力数据的数据关联方法,包括如下步骤:步骤1:获取锚点数据源中的数据和待匹配数据源中的数据,所述锚点数据源包括电力营销档案,所述待匹配数据源包括机构工商信息档案和个人信息档案;步骤2:通过特征工程对各数据源中的各项数据分别进行属性提取,得到各项数据所对应的属性;步骤3:将各项数据的属性分别进行特征向量化处理,生成与各项数据的属性相对应的特征向量;步骤4:将锚点数据源中各项数据的属性的特征向量分别通过量化映射到离散子空间,生成与各项数据的属性相对应的代表向量和离散子空间的倒排列表;步骤5:将待匹配数据源中各项数据的属性相对应的特征向量与锚点数据源中各项数据的属性相对应的代表向量进行匹配;若不存在相同属性,则将待匹配数据源中的数据与锚点数据源中的数据进行融合;若存在相同属性,则将待匹配数据源中相同属性的特征向量与锚点数据源中相同属性的代表向量取点积,再根据离散子空间的倒排列表,匹配相应子空间的特征向量,选取点积最大的特征向量对应的数据作为待融合数据,执行步骤6;步骤6:通过属性相似度度量公式分别计算待匹配数据源中相同属性的待融合数据的相似度得分和锚点数据源中相同属性数据的相似度得分,舍弃相似度得分低的数据,保留相似度得分高的数据,再执行步骤5;
其中,属性相似度度量公式为:式中,表示数据源一中的第条数据与数据源二中的第条数据的属性相似度得分,数据源一包含条属性,数据源二包含条属性,和的取值范围分别为和;数据源一的第条数据拥有属性,,
…
,分别对应值为,,
…
,,数据源二的第条数据拥有属性,,
…
,分别对应值为,,
…
,;表示数据源一的属性集合与数据源二的属性集合中意义相同且存在对应关系的两个属性组成的属性对,两个属性分别为数据源一中的属性和数据源二中的属性,;是区间的值,对属性和属性的相似度进行正则化,为属性的可能取值,是数据源一中属性的总量,是数据源一中值等于的数量;为属性的可能取值,是数据源二中属性的总量,是数据源二中值等于的数量。
5.在其中一种可能的实施方式中,本技术实施提供的一种基于多源异构电力数据的数据关联方法,所述步骤3:将各项数据的属性分别进行特征向量化处理,生成与各项数据的属性相对应的特征向量包括:将文本类属性使用gpt-3语言模型生成1024维的向量,数值类属性离散化后作为id类特征使用one-hot生成固定维度向量。
6.在其中一种可能的实施方式中,本技术实施提供的一种基于多源异构电力数据的数据关联方法,所述步骤4:将锚点数据源中各项数据的属性的特征向量分别通过量化映射到离散子空间,生成与各项数据的属性相对应的代表向量和离散子空间的倒排列表包括:将锚点数据源中各项数据的属性的特征向量粗分为若干个子向量空间,对各子向量空间分别进行点积量化,取误差函数最小子向量空间的质心作为该项数据的代表向量,误差函数为:式中,为锚点数据源的特征向量,为对应的近似特征向量;在子向量空间中对每个特征向量计算与代表向量的欧拉距离,欧拉距离公式为:式中,为特征向量, 为代表向量所组成的矩阵。为代表向量的总数,为数据的属性。
7.每个子向量空间根据欧拉距离按从小到大的顺序分别维护一个倒排列表,跟踪各离散子空间中的特征向量。
8.本技术的有益效果是:本技术提出了一种基于多源异构电力数据的数据关联方法,能够将多个不同维度数据源中的数据进行特征向量化处理,再利用平滑加权杰卡德(jaccard)算法提升其准确率。使用局部向量量化的方法压缩特征向量,能够大大减少计算量,快速找到相似向量。同时,通过使用平滑加权杰卡德(jaccard)算法计算属性得分能解决数据对齐过程中可能存在的属性冲突问题。
附图说明
9.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
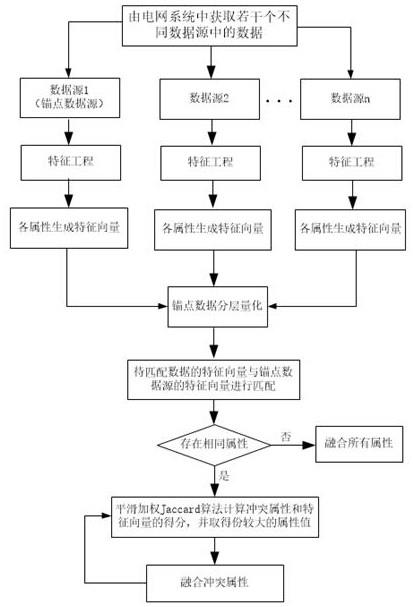
10.图1是本技术实施例提供的一种基于多源异构电力数据的数据关联方法的工作流程图。
具体实施方式
11.下面将对本技术实施例的实施方式进行详细描述。
12.本技术实施例提供一种基于多源异构电力数据的数据关联方法,用于解决电力数据在不同数据源中表示不同的问题。
13.参见图1所示,此方法包括如下步骤:步骤1:获取锚点数据源中的数据和待匹配数据源中的数据,锚点数据源包括电力营销档案,待匹配数据源包括机构工商信息档案和个人信息档案,其中:电力营销档案中的数据包括企业规模、核心词、户主姓氏、用电行为特征等。
14.机构工商信息档案中的数据包括:纳税人识别号、行业分类、经营行为信息等。
15.个人信息档案中的数据包括:姓名、年龄、家庭住址等。
16.当然,可以理解的是,锚点数据源也可以为由电网系统中获得的其他电力数据源,待匹配数据源也可以为非电力数据的其他数据源。
17.步骤2:通过特征工程对各数据源中的各项数据分别进行属性提取,得到各项数据所对应的属性。
18.步骤3:将各项数据的属性分别进行特征向量化处理,生成与各项数据的属性相对应的特征向量,其中:将文本类属性使用gpt-3语言模型生成1024维的向量,数值类属性离散化后作为id类特征使用one-hot生成固定维度向量。
19.步骤4:为了减少计算量,提升运行速度,以及防止最终的特征向量过大,导致计算相似度时的区分度过小,在向量生成后,使用向量量化的方式,将向量空间降维,将锚点数据源中各项数据的属性的特征向量分别通过量化映射到离散子空间,生成与各项数据的属性相对应的代表向量和离散子空间的倒排列表。因为数据是异构的,向量空间中的数据一定是不均匀的。因此进行了多层量化。先对全局进行量化,粗略地切分向量空间。然后以每
个子向量空间为单位,将粗分的向量空间质心视为代表向量,对子向量空间分别进行点积量化。
20.具体地,将锚点数据源中各项数据的属性的特征向量粗分为若干个子向量空间,对各子向量空间分别进行点积量化,取误差函数最小子向量空间的质心作为该项数据的代表向量,误差函数为:式中,为锚点数据源的特征向量,为对应的近似特征向量;在子向量空间中对每个特征向量计算与代表向量的欧拉距离,匹配的数据源先从粗聚类中心的代表向量选出最接近的,然后在相应的子向量空间中选取距离最接近的向量进行匹配,欧拉距离公式为:式中,为特征向量, 为代表向量所组成的矩阵。为代表向量的总数,为数据的属性。
21.每个子向量空间根据欧拉距离按从小到大的顺序分别维护一个倒排列表,跟踪各离散子空间中的特征向量。
22.步骤5:将待匹配数据源中各项数据的属性相对应的特征向量与锚点数据源中各项数据的属性相对应的代表向量进行匹配,若不存在相同属性,则将待匹配数据源中的数据与锚点数据源中的数据进行融合;若存在相同属性,则将待匹配数据源中相同属性的特征向量与锚点数据源中相同属性的代表向量取点积,再根据离散子空间的倒排列表,匹配相应子空间的特征向量,选取点积最大的特征向量对应的数据作为待融合数据,执行步骤6。
23.步骤6:不同数据源融合时可能存在相同属性冲突或值缺失的问题,使用属性相似度度量公式(平滑加权jaccard算法)来计算属性得分,选择得分高的数据源进行融合。通过属性相似度度量公式分别计算待匹配数据源中相同属性的待融合数据的相似度得分和锚点数据源中相同属性数据的相似度得分,舍弃相似度得分低的数据,保留相似度得分高的数据,再执行步骤5,具体地,假设数据源一的第条数据拥有属性,,
…
,分别对应值为,,
…
,,数据源二的第条数据拥有属性,,
…
,分别对应值为,,
…
,;属性相似度度量公式为:度量公式为:表示对齐的两个属性,即数据源一的属性集合与数据源二的属性集合中意义相同且存在对应关系的两个属性组成的属性对,两个属性分别为数据源一中的属性和数据
源二中的属性,;是区间的值,对属性和属性的相似度进行正则化,为属性的可能取值,是数据源一中属性的总量,是数据源一中值等于的数量;为属性的可能取值,是数据源二中属性的总量,是数据源二中值等于的数量。
24.实施案例:步骤1:假设有数据源a,b,c,三个数据源对应的数据分别为a,b,c,其中a有i条数据,b有j条数据,c有k条数据。其中,数据源a为锚点数据源,数据源b和数据源c为待匹配数据源。
25.步骤2:对a,b,c分别进行特征工程,a选择属性,,
…
,,b选择属性,,
…
,,c选择属性,,
…
,。
26.步骤3:a,b,c分别对不同类型的属性用不同方法生成特征向量,文本类属性使用gpt-3生成1024维的向量,数值类属性离散化后作为id类特征使用one-hot生成固定维度向量。对于,,个数据,生成的特征向量分别为,,
…
,,,,
…
,,,,
…
,。
27.步骤4:将a的每个属性的特征向量通过量化映射到离散子空间。先粗分成个子向量空间,将每个子空间的质心和子空间的各个向量做点积量化,取误差函数最小的作为代表向量。用,,
…
,代表这个代表向量。在子空间中对每个向量计算和代表向量的欧拉距离,根据欧拉距离按从小到大的顺序维护一个倒排列表。每个子向量空间维护一个倒排列表,跟踪各离散子空间中的原始特征向量。
28.步骤5:待匹配数据b,c分别和相应属性的a中的代表向量进行匹配,选取点积最大的特征向量,然后根据离散子空间的倒排列表,匹配相应子空间的特征向量。选取点积最大的进行数据融合。
29.步骤6:如果与匹配成功,数据融合时发现属性和相同,但是数值不同。通过平滑加权jaccard计算a和b的属性、的得分,如果的得分高,则选择接收的值。反之则选择接收的值。
30.最后应说明的是:以上各实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述各实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依
然可以对前述各实施例所记载的技术方案进修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。