1.本发明涉及肉类产品检测技术领域,尤其涉及一种利用拉曼光谱检测罗非鱼鱼肉脆度的方法。
背景技术:
2.脆肉罗非鱼因其肉质q弹、久煮不烂、口感爽脆等在市场上大受欢迎,这些鱼类脆度是这些鱼类的一个重要指标,且脆度是可以通过在饲养过程中添加特殊的饲料来提高的,但饲养过程中鱼肉的过度脆化会导致出现类似于溶血、缺氧、器官功能性病变等症状,甚至会由于血液循环障碍直接导致死亡。因此,脆肉鱼种脆度的检测不仅可以由此评判肉质的等级,更好地进行市场区分,还可通过检测鱼肉的脆度来控制饲料的投放种类和投放量,以达到科学饲养的目的。现有脆度的评价方法主要是感官评定以及tpa质构分析,感官评价的结果受人为因素的影响较大;而tpa质构分析用于鱼肉的脆度检测时,一般需要采用美国ftc质构仪,力量感应元500n,设置合适的测试参数,切割多块样品,测试样品需冷冻保存后再进行测试,每个样品需多次测量取平均值,再经过特定的分析软件得到测试数据,该操作存在操作繁琐,时间长,对样品破坏性大等问题。同时,不同的鱼种其肉质成分并不相同,适用的评价方法也不尽相同。
技术实现要素:
3.本发明的目的是克服上述现有技术的缺点,提供一种检测效率高、准确率高的利用拉曼光谱检测罗非鱼鱼肉脆度的方法。
4.本发明是通过以下技术方案来实现的:
5.一种利用拉曼光谱检测罗非鱼鱼肉脆度的方法,包括如下步骤:
6.数据采集:取脆肉罗非鱼鱼肉样品,通过共聚焦拉曼光谱仪采集该鱼肉样品的原始拉曼光谱,通过质构仪得到该鱼肉样品的脆度值,重复操作,得到多个鱼肉样品的原始拉曼光谱及其对应的脆度值;
7.数据集建立:对原始拉曼光谱进行预处理,得到各样品的拉曼光谱特征数据,建立包含各样品拉曼光谱特征数据和脆度值的数据集;
8.预测模型建立:对ssda进行预训练得到初始化权值,然后删除ssda的解码部分,连接elm网络,将数据作为多层elm网络的输入,再连接softmax,得到初始模型,将数据集中的数据输入初始模型中进行训练,得到ssda-helm-softmax预测模型,输入待测脆肉罗非鱼肉的拉曼光谱数据进行鱼肉脆度预测。
9.进一步地,所述ssda-helm-softmax预测模型的训练方法为:将数据集中的数据输入ssda自编码器(堆叠式稀疏去噪自动编码器)的输入层中,ssda隐藏层从复杂输入数据中提取相关特征,采用非监督学习方法,逐层预训练加微调得到初始化权值;将ssda的解码部分去掉,连接elm网络,将获取的初始化权值作为多层elm(多层极限学习机,hierarchical extreme learining machine,helm)的初始值进行赋值,在输出层采用softmax进行分类。
10.进一步地,所述鱼肉样品取自脆肉罗非鱼的鱼背中部,取长
×
宽
×
厚约为2cm
×
1.5cm
×
2cm的薄片进行共聚焦拉曼光谱采集,采集两次;每个样品通过质构仪得到脆度值的方法为:ftc质构仪采用直径为6mm圆柱形不锈钢探头,设置触发力为0.75n,测试速度为30mm/min,形变率分别为35%,将在4℃的环境下放置一定时间后的样品按照样品编号依次进行tpa模式检测,每个样品挤压2次,最后取平均值进行分析,脆度值由质构仪配套的tms-pro物性分析系统读取和计算。
11.所述共聚焦拉曼光谱仪采集鱼肉样品的原始拉曼光谱的参数设定为:50
×
倍物镜,532nm激光器,曝光时间10s,循环次数3次,波长范围500-2000cm-1
,光栅为1200刻线,滤光强度可设置为25%,狭缝宽度为100μm,针孔hole为300μm。
12.进一步地,对原始拉曼光谱进行预处理时,采用peakfit v4.12软件和ngslabspec5软件进行峰面积拟合,采用origin 2018b软件绘制模型图,采用matlab2017b软件和unscrambler x 10.4软件进行建模分析。
13.进一步地,对原始拉曼光谱进行预处理的方法为:先对原始拉曼光谱进行归一化后求平均值,并标记峰位,提取的特征值为拉曼峰的波峰值,包括波峰波数和波峰面积。
14.进一步地,在对ssda-helm-softmax预测模型进行训练时,采用k折交叉验证法。
15.进一步地,所述ssda-helm-softmax预测模型的算法为:
16.s1、选择ssda网络的隐藏层数,初始化网络深度k,x1=x;x=[x
(1)
,x
(2)
,
…
,x
(m)
]
t
,是隐藏层的节点数,将ssda网络的解码部分删除,与helm网络对接,构建ssda-helm网络;
[0017]
s2、从第一隐藏层开始,训练得到各隐藏层的输入权重wi和隐层偏置bi,并将权重wi和隐层偏置bi作为输入权值对ssda-helm网络进行初始化;
[0018]
s3、由预训练得到的输入权重wi和隐层偏置bi,计算隐藏层输出矩阵a:ai=h
i-1wli
,其中ai为第i层节点输出;h
i-1
为第i层节点输入;w
li
为权值矩阵;
[0019]
s4、根据elm理论:
[0020][0021][0022]
其中,h是隐层节点的输出,β为输出权重,t为期望输出,g(x)为激活函数,wi=[w
i,1
,w
i,2
,...,w
i,n
]
t
为输入节点和第i个隐节点之间的权重,βi为第i个隐节点和输出节点之间的权重,bi是第i个隐层节点的偏置;wi·
xj表示的是wi和xj的内积;
[0023]
计算神经网络输出权重矩阵计算神经网络输出权重矩阵其中,为矩阵a的广义逆矩阵;
[0024]
s5、计算输出结果:其中为第i层输出,h
i-1
为第i层输入,g(
·
)为隐藏层的激活函数;
[0025]
s6、重复上述步骤s2-s5,直至完成最后一层隐藏层的输出计算,得到特征值;
[0026]
s7、将提取的特征作为输入值,送入softmax分类器进行分类预测。
[0027]
进一步地,所述s2步骤中ssda网络训练得到隐藏层的输入权重wi和隐层偏置bi的方法为:
[0028]
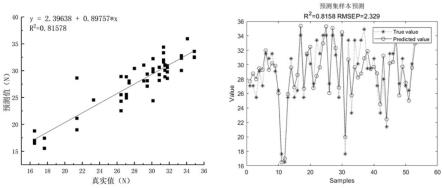
构建多个自编码器,每一个自编码器对应一个隐藏层,用于预训练θi∈{wi,bi}参数;每一层自编码器隐藏层的输入层为上一层自编码器的隐藏层输出,输出层是上一层隐藏层的重构;采用贪婪逐层训练法进行逐层非监督训练每一个自编码器,得到ssda网络各层的权值,再通过反向传播算法整体逐层微调权重,训练出ssda网络最优权重;
[0029]
自编码器的编码过程为:
[0030]
其中,w1是输入层到隐含层和隐含层到输出层的权重矩阵,b1是隐含层和输出层的单位偏置系数;σ(
·
)表示激活函数,选取logsig函数;θ表示网络的参数矩阵,θi∈{wi,bi}。
[0031]
进一步地,所述ssda网络训练的网络参数设置为:学习速率为0.1,预训练最大迭代次数为400,微调最大迭代次数为300,稀疏参数为0.5,稀疏惩罚项参数为3,激活函数采用sigmoid函数,微调损失函数为:
[0032][0033]
本发明通过采集鱼肉的拉曼光谱数据以及质构分析得到的脆度值,以此训练ssda-helm-softmax预测模型,由得到的拉曼光谱预测鱼肉的脆度值,预测效果好,适用于脆肉罗非鱼脆度的检测;拉曼光谱检测的信息多,前处理方法简单,仪器设备携带方便,且检测速度快,检测效率高,不受环境干扰,不会对检测样品产生损伤,为产品的质量分级检测和科学养殖提供技术支撑。
附图说明
[0034]
图1为本发明实施例中的原始拉曼光谱图。
[0035]
图2为本发明实施例中归一化预处理的拉曼光谱图。
[0036]
图3为本发明实施例中四种预处理方法预处理后的拉曼光谱图,其中a为s-g预处理,b为msc预处理,c为snv预处理,d为normalize预处理。
[0037]
图4为本发明实施例中ssda预训练模型图。
[0038]
图5为本发明实施例中elm算法的结构图。
[0039]
图6为本发明实施例中预测模型的预测效果。
具体实施方式
[0040]
一种利用拉曼光谱检测罗非鱼鱼肉脆度的方法,包括如下步骤:
[0041]
(1)数据采集:取脆肉罗非鱼的鱼肉样品,通过共聚焦拉曼光谱仪采集该鱼肉样品的原始拉曼光谱,通过质构仪得到该鱼肉样品的脆度值,重复操作,得到多个鱼肉样品的原始拉曼光谱及其对应的脆度值。
[0042]
取脆肉罗非鱼背中部的肉块,削取表面长
×
宽
×
厚约为2cm
×
1.5cm
×
2cm的鱼肉薄片并置于载玻片上,将样品进行编号,样品聚焦清晰后进行拉曼光谱采集,每个薄片样品采集两次,剩余样品用于tpa检测。
[0043]
tpa检测的步骤和方法为:采用美国ftc质构仪,力量感应元500n,实验采用直径为
6mm圆柱形不锈钢探头,设置触发力为0.75n,测试速度为30mm/min,形变率分别为35%;样品放置在4℃的冰箱中保存一定的时间后,按照样品编号依次进行tpa模式检测,在减少实验误差并且确保脆肉鱼肉不变形的情况下,每个样品挤压2次,最后取平均值进行分析,脆性值由质构仪配套的tms-pro物性分析系统读取和计算。
[0044]
本实施例中,共聚焦拉曼光谱仪(horiba,法国)采集鱼肉样品的原始拉曼光谱的参数设定为:50
×
倍物镜,532nm激光器,曝光时间10s,循环次数3次,波长范围500-2000cm-1
,光栅为1200刻线,滤光强度25%,狭缝宽度slit为100μm,针孔hole为300μm。
[0045]
蛋白质是鱼类含量最丰富的营养物质,本技术人研究发现,脆肉罗非的质构脆度与蛋白质含量及结构有紧密关系,而拉曼光谱可利用蛋白质分子振动水平的指纹图谱来确定特定蛋白质的主链构象和二级结构,能够反映样品中非极性基团振动变化,从而反映氨基酸残基和蛋白二级结构信息,而鱼肉肉质的脆度和营养成分均是物质结构的直观反映,拉曼光谱与可见-近红外光谱相比,虽然同属振动光谱,但拉曼光谱是散射光谱,能检测到更多的蛋白质信息,因而可利用拉曼光谱信息进行脆度的检测,且能立体全面地探究脆肉鱼种的脆性本质。同时,拉曼光谱无损,简单快速,无需样品准备,样品量少,样品可直接通过光纤探头或者通过玻璃、石英和光纤测量;且由于水的拉曼散射很微弱,检测可不受水环境的干扰,其空间分辨率为0.5-1.0μm,拉曼一次可以同时覆盖50-4000波数的区间,谱峰清晰尖锐,适合定量研究和差异分析;共振拉曼效应可以用来有选择性地增强大生物分子特个发色基团的振动,这些发色基团的拉曼光强能被选择性地增强1000到10000倍。
[0046]
(2)数据集建立:对原始拉曼光谱进行预处理,得到各样品的拉曼光谱特征数据,建立包含各样品拉曼光谱特征数据和脆度值的数据集。
[0047]
(3)预测模型建立:对ssda进行预训练得到初始化权值,然后删除ssda的解码部分,连接elm网络,将数据作为多层elm网络的输入,再连接softmax,得到初始模型,将数据集中的数据输入初始模型中进行训练,得到ssda-helm-softmax预测模型,输入待测鱼肉的拉曼光谱数据进行鱼肉脆度预测。
[0048]
对原始拉曼光谱进行预处理的方法为:先对原始拉曼光谱进行归一化后求平均值,并标记峰位。对原始拉曼光谱进行预处理时,可采用peakfit v4.12软件和ngslabspec5软件进行峰面积拟合。同时,采用origin 2018b软件绘制模型图,采用matlab2017b软件和unscrambler x 10.4软件进行建模分析。
[0049]
拉曼光谱在采集过程中,由于样品的特性、仪器自身等原因会产生不同程度的基线漂移和噪音,对光谱进行归一化处理,可消除这些影响,降低样本间相关性的同时,增加样本之间的差异,从而达到提高预测模型的重临性和预测能力的效果。
[0050]
由图1的原始拉曼光谱图可看到,由于光谱数量多,并且存在仪器或者肉类样品表面不光滑的原因而产生基线漂移和噪声,使得峰位信息不明显,可以粗略看到在波数范围为500-2000cm-1
内,有7-9个指纹峰出现。
[0051]
为了更加清晰观察不同脆化时间段的脆肉罗非的光谱变化趋势,对原始光谱进行归一化后求平均值,并采用origin 2018b软件标记峰位,如图2所示,可以看出光谱图中有许多细节峰。
[0052]
预处理方法除了上述归一化(normalize)外,还可分别采用平滑滤波(s-g)、标准正态变换(snv)和多元散射校正(msc)等方法分别对原始光谱进行预处理,处理效果如图3
所示。通过图3可看出,经过s-g预处理的拉曼光谱的噪音减少,但是光谱基线漂移仍然没有被消除,各波段的特征峰不明显(如图3a);经过msc和snv预处理效果比较相似,波谱变得更加紧凑,特征峰清晰,光散射被消除,但是500-800cm-1
波段范围内的噪音仿佛变大,波谱区分度不高,说明这两种方法在一定程度上消除了基线漂移和光散射的干扰(图3b和图3c);经过normalize预处理的拉曼光谱的变得更加紧密有序,基线干扰被消除,特征峰信号较强但是不如msc和snv的特征峰信号强(图3d)。
[0053]
通过对拉曼光谱图的处理,可得到波峰波数和波峰面积,采用深度学习方法,可以将每个波数的波峰值作为输入去提取特征(波峰波数和波峰面积等都是由每个波数的波峰值组成),这样能找到更深层差异点特征。由图2可看出,不同脆化时间(0天、40天等)代表了不同脆度,不同脆度的光谱图有明显的差异。
[0054]
elm模型(极限学习机)是依据广义逆矩阵理论计算直接求出输出,不用通过多次前导、反向训练最优值,且受训练样本的干扰少,因此极限学习机具有训练参数少、学习速度快、泛化能力强的优点。但由于其初始参数都是随机产生,随机初始参数的好坏直接影响输出结果。多层极限学习机(hierarchical extreme learning machine,helm)是一种建立在多层上的算法,基于随机特征映射而充分利用elm的泛化逼近能力。为优化随机初始参数,稀疏自编码sae作为前端进行预训练以提供初始化权值,训练后的参数作为多层elm模型的初始化参数以得到最优解。
[0055]
具体地,ssda-helm-softmax预测模型的训练方法为:将数据集中的数据输入ssda自编码器(stacked sparse denoising auto-encoder,堆叠式稀疏去噪自动编码器)的输入层中,ssda隐藏层从复杂输入数据中提取相关特征,采用非监督学习方法,逐层预训练加微调得到初始化权值;将ssda的解码部分去掉,连接elm网络,将获取的初始化权值作为多层elm(多层极限学习机,hierarchical extreme learining machine,helm)的初始值进行赋值,在输出层采用softmax进行分类。
[0056]
所述ssda-helm-softmax预测模型的算法为:
[0057]
s1、选择ssda网络的隐藏层数,初始化网络深度k,x1=x;x=[x
(1)
,x
(2)
,...,x
(m)
]
t
,是隐藏层的节点数,将ssda网络的解码部分删除,与helm网络对接,构建ssda-helm网络;
[0058]
s2、从第一隐藏层开始,训练得到各隐藏层的输入权重wi和隐层偏置bi,并将权重wi和隐层偏置bi作为输入权值对ssda-helm网络进行初始化;
[0059]
s3、由预训练得到的输入权重wi和隐层偏置bi,计算隐藏层输出矩阵a:ai=h
i-1wli
,其中ai为第i层节点输出;h
i-1
为第i层节点输入;w
li
为权值矩阵;
[0060]
s4、根据elm理论:
[0061][0062][0063]
其中,h是隐层节点的输出,β为输出权重,t为期望输出,g(x)为激活函数,wi=
[w
i,1
,w
i,2
,...,w
i,n
]
t
为输入节点和第i个隐节点之间的权重,βi为第i个隐节点和输出节点之间的权重,bi是第i个隐层节点的偏置;wi·
xj表示的是wi和xj的内积;
[0064]
计算神经网络输出权重矩阵输出权重矩阵其中,为矩阵a的广义逆矩阵;
[0065]
s5、计算输出结果:其中为第i层输出,h
i-1
为第i层输入,g(
·
)为隐藏层的激活函数;
[0066]
s6、重复上述步骤s2-s5,直至完成最后一层隐藏层的输出计算,得到特征值;
[0067]
s7、将提取的特征作为输入值,送入softmax分类器进行分类预测。
[0068]
其中,所述s2步骤中ssda预训练的方法为:
[0069]
构建多个自编码器,每一个自编码器对应于一个隐藏层,用于预训练θi∈{wi,bi}参数,每一层自编码器隐藏层的输入层为上一层自编码器的隐藏层输出,输出层是上一层隐藏层的重构。
[0070]
采用贪婪逐层训练法进行逐层非监督训练每一个自编码器,得到ssda网络各层的权值,再通过反向传播算法整体逐层微调权重,训练出ssda网络最优权重,用训练后的最优参数作为helm模型的初始化参数。网络参数设置为:学习速率为0.1,预训练最大迭代次数为400,微调最大迭代次数为300,稀疏参数为0.5,稀疏惩罚项参数为3,激活函数采用sigmoid函数,微调损失函数为:
[0071][0072]
ssda预训练模型图如图4所示。
[0073]
自编码器的编码过程为:
[0074]
其中,w1是输入层到隐含层和隐含层到输出层的权重矩阵,b1是隐含层和输出层的单位偏置系数;σ(
·
)表示激活函数,选取logsig函数;θ表示网络的参数矩阵,θi∈{wi,bi}。
[0075]
elm算法的结构图和算法描述如图5。
[0076]
本发明采用ssda-helm-softmax模型算法,是深度学习中的一种优化算法,深度学习算法一般都是通过反复训练参数得到网络模型,极限学习(elm)是不需要训练参数,直接计算而得,速度快,准确率跟初始参数有关,所以ssda-helm算法就是通过ssda去预训练初始参数,保证初始参数接近最优,从而确保elm算法的准确率,优点就是尽量保证准确率和计算速度达到最优。
[0077]
采用ssda-helm建模方法建立模型,建模过程中随机选取三分之二左右的数据作为校正集,余下的数据作为预测集,采用k折交叉验证法增加训练结果的可信度,通过k的取值调试,发现k为10的模型泛化性更好,k为10的建模结果如表一和图6所示。
[0078]
表一基于拉曼光谱ssda-helm建模结果
[0079][0080]
由图6可看出,相比于其它算法模型,本发明构建的ssda-helm预测模型在预测误差上具有较好的表现,其预测集准确度最高可以达到0.8158,适用于脆肉罗非鱼的鱼肉脆度无损检测,对脆肉罗非鱼进行脆度预测具有实际应用意义。
[0081]
上列详细说明是针对本发明可行实施例的具体说明,该实施例并非用以限制本发明的专利范围,凡未脱离本发明所为的等效实施或变更,均应包含于本案的专利范围中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。