1.本发明涉及大数据技术领域,特别涉及一种用户的意图识别方法及系统。
背景技术:
2.在智能语音外呼技术领域中,用户的意图识别是影响用户语音交互体验的关键因素之一,其中,用户的意图识别可以归为自然语言处理领域的文本分类任务。
3.现有技术大部分将用户说话文本传输至模型的嵌入层,然后依次传入各编码层,将最后一层编码层输出的语义表征传入分类器,通过归一化指数函数得到各意图类别的置信度分布,输出置信度最大的意图标签作为预测结果。
4.然而,由于现有技术需要将用户的样本数据依次传输至模型内部的各个编码器中,再最终得到预测结果,在此过程中,所需耗费的推理时间较长,而语音外呼是一个和用户实时交互的过程,从而较高的推理时延会增加用户的等待时间,进而大幅降低了用户的交互体验。
技术实现要素:
5.基于此,本发明的目的是提供一种用户的意图识别方法及系统,以解决现有技术需要将用户的样本数据依次传输至模型内部的各个编码器中,导致所需耗费的推理时间较长的问题。
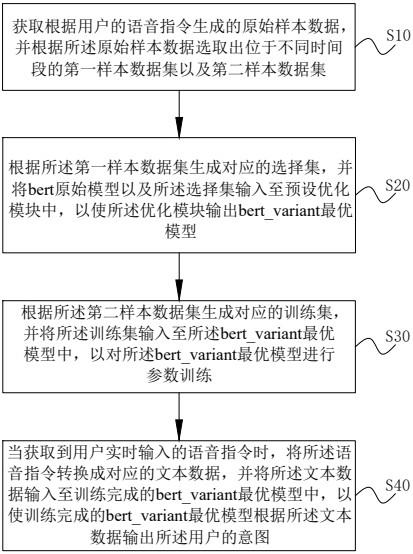
6.本发明实施例第一方面提出了一种用户的意图识别方法,所述方法包括:获取根据用户的语音指令生成的原始样本数据,并根据所述原始样本数据选取出位于不同时间段的第一样本数据集以及第二样本数据集;根据所述第一样本数据集生成对应的选择集,并将bert原始模型以及所述选择集输入至预设优化模块中,以使所述优化模块输出bert_variant最优模型,所述选择集包括正样本以及负样本,所述bert原始模型包括若干层编码器;根据所述第二样本数据集生成对应的训练集,并将所述训练集输入至所述bert_variant最优模型中,以对所述bert_variant最优模型进行参数训练;当获取到用户实时输入的语音指令时,将所述语音指令转换成对应的文本数据,并将所述文本数据输入至训练完成的bert_variant最优模型中,以使训练完成的bert_variant最优模型根据所述文本数据输出所述用户的意图。
7.本发明的有益效果是:通过首先获取根据用户的语音指令生成的原始样本数据,并根据该原始样本数据选取出位于不同时间段的第一样本数据集以及第二样本数据集;再根据第一样本数据集生成对应的选择集,并将bert原始模型以及选择集输入至预设优化模块中,以使优化模块输出bert_variant最优模型,在此基础之上,根据第二样本数据集生成对应的训练集,并将训练集输入至上述bert_variant最优模型中,以对该bert_variant最优模型进行参数训练;最后当获取到用户实时输入的语音指令时,将语音指令转换成对应的文本数据,并将文本数据输入至训练完成的bert_variant最优模型中,以使训练完成的
bert_variant最优模型根据当前文本数据输出用户的意图。通过上述方式能够在保证bert原始模型识别准确率的前提下,有效的降低推理时延,使之更加适用于实时交互场景,从而大幅缩短了推理的时间,提升了用户的使用体验,适用于大范围的推广与使用。
8.优选的,所述将bert原始模型以及所述选择集输入至预设优化模块中,以使所述优化模块输出bert_variant最优模型的步骤包括:将所述正样本以及所述负样本均输入至所述bert原始模型中,以对应获取到若干层所述编码器分别输出的若干特征向量;建立所述正样本和所述负样本与若干所述特征向量之间的索引关系,并根据若干所述特征向量生成对应的特征向量集合,以使所述优化模块根据所述特征向量集合输出所述bert_variant最优模型。
9.优选的,所述根据所述第一样本数据集生成对应的选择集的步骤包括:当获取到所述第一样本数据集时,识别出所述第一样本数据集中包含的若干用户意图,并根据若干所述用户意图生成对应的若干数据组,其中,同一所述数据组内的两个数据互为所述正样本,不同所述数据组内的任意两个数据互为所述负样本;根据若干所述数据组生成对应的若干样本集,其中,每一所述样本集均包括一待测样本、所述正样本以及所述负样本,且每一所述样本集均具有唯一性;对若干所述样本集进行整合处理,以生成所述选择集。
10.优选的,所述将bert原始模型以及所述选择集输入至预设优化模块中,以使所述优化模块输出bert_variant最优模型的步骤还包括:依次遍历若干所述样本集以及若干层所述编码器,并获取每一所述样本集中的待测样本对应的编码器输出的第一特征向量、每一所述正样本对应的编码器输出的第二特征向量以及每一所述负样本对应的编码器输出的第三特征向量;计算出所述第一特征向量与所述第二特征向量之间的第一余弦相似度、所述第一特征向量与所述第三特征向量之间的第二余弦相似度,并判断所述第一余弦相似度是否大于所述第二余弦相似度;若判断到所述第一余弦相似度大于所述第二余弦相似度,则判定预测结果正确;若判断到所述第一余弦相似度小于所述第二余弦相似度,则判定预测结果错误。
11.优选的,所述将所述文本数据输入至训练完成的bert_variant最优模型中,以使训练完成的bert_variant最优模型根据所述文本数据输出所述用户的意图的步骤之后,所述方法还包括:当识别出所述用户的意图时,根据所述意图生成对应的回复指令,所述回复指令包括若干关键词;响应于所述回复指令,调用出对应的文本数据库,并在所述文本数据库中查找出对应的回复文本,以将所述回复文本实时显示在显示终端。
12.本发明实施例第二方面提出了一种用户的意图识别系统,所述系统包括:获取模块,用于获取根据用户的语音指令生成的原始样本数据,并根据所述原始样本数据选取出位于不同时间段的第一样本数据集以及第二样本数据集;处理模块,用于根据所述第一样本数据集生成对应的选择集,并将bert原始模型以及所述选择集输入至预设优化模块中,以使所述优化模块输出bert_variant最优模型,
所述选择集包括正样本以及负样本,所述bert原始模型包括若干层编码器;训练模块,用于根据所述第二样本数据集生成对应的训练集,并将所述训练集输入至所述bert_variant最优模型中,以对所述bert_variant最优模型进行参数训练;输出模块,用于当获取到用户实时输入的语音指令时,将所述语音指令转换成对应的文本数据,并将所述文本数据输入至训练完成的bert_variant最优模型中,以使训练完成的bert_variant最优模型根据所述文本数据输出所述用户的意图。
13.其中,上述用户的意图识别系统中,所述处理模块具体用于:将所述正样本以及所述负样本均输入至所述bert原始模型中,以对应获取到若干层所述编码器分别输出的若干特征向量;建立所述正样本和所述负样本与若干所述特征向量之间的索引关系,并根据若干所述特征向量生成对应的特征向量集合,以使所述优化模块根据所述特征向量集合输出所述bert_variant最优模型。
14.其中,上述用户的意图识别系统中,所述处理模块还具体用于:当获取到所述第一样本数据集时,识别出所述第一样本数据集中包含的若干用户意图,并根据若干所述用户意图生成对应的若干数据组,其中,同一所述数据组内的两个数据互为所述正样本,不同所述数据组内的任意两个数据互为所述负样本;根据若干所述数据组生成对应的若干样本集,其中,每一所述样本集均包括一待测样本、所述正样本以及所述负样本,且每一所述样本集均具有唯一性;对若干所述样本集进行整合处理,以生成所述选择集。
15.其中,上述用户的意图识别系统中,所述处理模块还具体用于:依次遍历若干所述样本集以及若干层所述编码器,并获取每一所述样本集中的待测样本对应的编码器输出的第一特征向量、每一所述正样本对应的编码器输出的第二特征向量以及每一所述负样本对应的编码器输出的第三特征向量;计算出所述第一特征向量与所述第二特征向量之间的第一余弦相似度、所述第一特征向量与所述第三特征向量之间的第二余弦相似度,并判断所述第一余弦相似度是否大于所述第二余弦相似度;若判断到所述第一余弦相似度大于所述第二余弦相似度,则判定预测结果正确;若判断到所述第一余弦相似度小于所述第二余弦相似度,则判定预测结果错误。
16.其中,上述用户的意图识别系统中,所述用户的意图识别系统还包括显示模块,所述显示模块具体用于:当识别出所述用户的意图时,根据所述意图生成对应的回复指令,所述回复指令包括若干关键词;响应于所述回复指令,调用出对应的文本数据库,并在所述文本数据库中查找出对应的回复文本,以将所述回复文本实时显示在显示终端。
17.本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
18.图1为本发明第一实施例提供的用户的意图识别方法的流程图;
图2为本发明第二实施例提供的用户的意图识别系统的结构框图。
19.如下具体实施方式将结合上述附图进一步说明本发明。
具体实施方式
20.为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的若干实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容更加透彻全面。
21.需要说明的是,当元件被称为“固设于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
22.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
23.由于现有技术需要将用户的样本数据依次传输至模型内部的各个编码器中,再最终得到预测结果,在此过程中,所需耗费的推理时间较长,而语音外呼是一个和用户实时交互的过程,从而较高的推理时延会增加用户的等待时间,进而大幅降低了用户的交互体验。
24.请参阅图1,所示为本发明第一实施例提供的用户的意图识别方法,本实施例提供的用户的意图识别方法能够在保证bert原始模型识别准确率的前提下,有效的降低推理时延,使之更加适用于实时交互场景,从而大幅缩短了推理的时间,提升了用户的使用体验,适用于大范围的推广与使用。
25.具体的,本实施例提供的用户的意图识别方法具体包括以下步骤:步骤s10,获取根据用户的语音指令生成的原始样本数据,并根据所述原始样本数据选取出位于不同时间段的第一样本数据集以及第二样本数据集;具体的,在本实施例中,首先需要说明的是,本实施例提供的用户的意图识别方法具体应用在车机系统、音箱以及智能手机等可以与用户进行语音交互的设备中,用于根据用户发出的语音指令执行对应的动作,以方便人们的生活。
26.另外,在本实施例中,还需要指出的是,本实施例提供的用户的意图识别方法是基于设置在后台的识别服务器实施的,与此同时,在该识别服务器的内部预先设置有若干算法以及模型,从而能够有效的提升用户意图的识别效率,以缩短用户的等待时间,对应提升用户的使用体验。
27.因此,在本步骤中,需要说明的是,本步骤首先通过上述识别服务器获取到用户在一段时间内已经发出的语音指令所对应生成的原始样本数据,优选的,在本实施例中,可以获取用户在一年时间内已经发出的语音指令所对应生成的原始样本数据。
28.在此基础之上,上述识别服务器根据实时获取到的原始样本数据选取出位于不同时间段的第一样本数据集以及第二样本数据集,优选的,在本实施例中,该第一样本数据集可以为1-6月的数据,对应的,该第二样本数据集可以为7-12月的数据。
29.步骤s20,根据所述第一样本数据集生成对应的选择集,并将bert原始模型以及所
述选择集输入至预设优化模块中,以使所述优化模块输出bert_variant最优模型,所述选择集包括正样本以及负样本,所述bert原始模型包括若干层编码器;进一步的,在本步骤中,需要说明的是,上述识别服务器在获取到第一样本数据集以及第二样本数据集之后,当前识别服务器会调用出其内部预先设置好的bert原始模型,以及预先设置好的优化模块。在此基础之上,当前识别服务器根据上述第一样本数据集生成对应的选择集,与此同时,将上述bert原始模型以及当前选择集一起输入至上述优化模块中,从而能够使该优化模块基于当前选择集对当前bert原始模型进行优化处理,以最终使该优化模块输出bert_variant最优模型。
30.其中,在本步骤中,需要指出的是,上述根据所述第一样本数据集生成对应的选择集的步骤包括:具体的,在本步骤中,需要说明的是,当上述识别服务器获取到上述第一样本数据集时,当前识别服务器会立即识别出当前第一样本数据集中包含的若干用户意图,并根据若干用户意图生成对应的若干数据组,其中,同一所述数据组内的两个数据互为所述正样本,不同所述数据组内的任意两个数据互为所述负样本;进一步的,根据若干所述数据组生成对应的若干样本集,其中,每一所述样本集均包括一待测样本、所述正样本以及所述负样本,且每一所述样本集均具有唯一性;最后对若干所述样本集进行整合处理,以生成所述选择集。
31.进一步的,在本步骤中,需要指出的是,上述将bert原始模型以及所述选择集输入至预设优化模块中,以使所述优化模块输出bert_variant最优模型的步骤包括:上述识别服务器会立即将上述正样本以及上述负样本均输入至上述bert原始模型中,以对应获取到若干层所述编码器分别输出的若干特征向量;进一步的,建立所述正样本和所述负样本与若干所述特征向量之间的索引关系,并根据若干所述特征向量生成对应的特征向量集合,以使所述优化模块根据所述特征向量集合输出所述bert_variant最优模型。
32.具体的,在本步骤中,还需要指出的是,上述将bert原始模型以及所述选择集输入至预设优化模块中,以使所述优化模块输出bert_variant最优模型的步骤还包括:依次遍历若干所述样本集以及若干层所述编码器,并获取每一所述样本集中的待测样本对应的编码器输出的第一特征向量、每一所述正样本对应的编码器输出的第二特征向量以及每一所述负样本对应的编码器输出的第三特征向量;计算出所述第一特征向量与所述第二特征向量之间的第一余弦相似度、所述第一特征向量与所述第三特征向量之间的第二余弦相似度,并判断所述第一余弦相似度是否大于所述第二余弦相似度;若判断到所述第一余弦相似度大于所述第二余弦相似度,则判定预测结果正确;若判断到所述第一余弦相似度小于所述第二余弦相似度,则判定预测结果错误。
33.步骤s30,根据所述第二样本数据集生成对应的训练集,并将所述训练集输入至所述bert_variant最优模型中,以对所述bert_variant最优模型进行参数训练;具体的,在本步骤中,需要说明的是,当上述识别服务器获取到上述第二样本数据集之后,当前识别服务器会立即根据当前第二样本数据集生成对应的训练集,与此同时,将该训练集实时输入至上述bert_variant最优模型中,以实时对该bert_variant最优模型进
行参数训练。
34.步骤s40,当获取到用户实时输入的语音指令时,将所述语音指令转换成对应的文本数据,并将所述文本数据输入至训练完成的bert_variant最优模型中,以使训练完成的bert_variant最优模型根据所述文本数据输出所述用户的意图。
35.最后,在本步骤中,需要说明的是,在实际的使用过程中,当上述识别服务器获取到用户实时输入的语音指令时,当前识别服务器会立即将接收到的语音指令转换成对应的文本数据,与此同时,将实时转换好的文本数据传输至上述训练完成的bert_variant最优模型中,以最终使该训练完成的bert_variant最优模型根据实时接收到的文本数据输出当前用户的意图。
36.另外,在本实施例中,还需要指出的是,上述将所述文本数据输入至训练完成的bert_variant最优模型中,以使训练完成的bert_variant最优模型根据所述文本数据输出所述用户的意图的步骤之后,该方法还包括:当识别出所述用户的意图时,根据所述意图生成对应的回复指令,所述回复指令包括若干关键词;响应于所述回复指令,调用出对应的文本数据库,并在所述文本数据库中查找出对应的回复文本,以将所述回复文本实时显示在显示终端。
37.另外,在本实施例中,为了便于理解,具体以欠费催缴语音外呼业务场景为例,进行详细说明,其中,将该场景下的分类意图简化为三大类:同意缴费(agree)、拒绝缴费(refuse)、已经缴费(already)。
38.业务数据部分属性举例如表1所示:表1进一步的,将准备好的原始样本数据按意图进行分组,其中,同一组内的任意两个数据样本互为正样本,不同组内的任意两个数据样本互为负样本;然后,从一个数据组中选择组内一条数据作为待测样本(e),随机选择当前组内的另一样本作为正样本(e_p),再在其它组内分别各选出一个样本作为负样本(e_n_i,i为组号),这样就组成了选择集中的一条数据:《e, e_p, e_n_1, e_n_2》,举例:《“我上午已经交了呀”,
ꢀ“
我儿子帮我交好了”,
ꢀ“
嗯好的,明天交”,“没钱,交不起了”》;最后,循环遍历每个数据组的每个样本,丢弃与已经构造好的选择数据重复了的组合,只保留未重复的组合,最终形成选择集。
39.在此基础之上,选择bert原始模型。如bert base版(12 layers,110m 参数)、bert large版(24 layers,340m参数)等等,优选的,在本实施例中,选择有24层的bert large版为例。
40.根据上述步骤可知,每条数据的格式为:(待测样本,正样本,负样本1,...,负样本l-1),参数化表示为(e, e_p, e_n_1, ..., e_n_l-1), l为总意图类别数。如果不符合,则
返回重制。
41.将选择集中的每条数据的每个样本均输入至bert原始模型中,以获取每层编码器输出的特征向量,再建立样本和特征向量之间的索引,以便访问,并缓存以上特征向量集合,得到vec_cache。部分举例如表2所示:表2从低到高低遍历每层编码器,其索引记作encoder_i,i = [1,2,..., 24]。
[0042]
遍历选择集中的每条数据 data_j,j= [1, 2, ..., select_set_size],select_set_size为选择集的数据量。
[0043]
获取数据data_j 中的待测样本 e 对应的第 i-th 层编码器输出的特征向量 e_vector_i;获取数据 data_j 中的正样本 e_p 对应的第 i-th 层编码器输出的特征向量 e_p_vector_i;获取数据 data_j中的每条负样本 e_n_k 对应的第 i-th 层编码器输出的特征向量 e_n_k_vector_i,k = [1, ..., l-1]。
[0044]
计算待测样本 e 的特征向量与 data_j 中剩余的每个样本的特征向量的余弦相似度:cos(e_vector_i, e_p_vector_i);cos(e_vector_i, e_n_k_vector_i);k = [1, ..., l-1]。
[0045]
比较相似度,更新预测结果计数。如果待测样本与正样本之间的相似度,不小于待测样本与任何一个负样本之间的相似度,那么,模型预测正确的情况计数加1,否则,模型预测错误的情况计数加1。
[0046]
计算正确率和层数开销性价比。具体的,计算仅使用第i层编码器的特征输出时,模型的正确率i-th-accuracy =预测正确计数/选择集总样本量。计算仅使用第i层编码器的特征输出时,性价比i-th-xjb = i-th-accuracy / i。
[0047]
举例说明,如果仅使用第4层编码器输出的特征向量,在选择集为10000条时正确地预测了其中3500条,那么此时,模型的正确率4-th-accuracy = 3500 / 10000 = 0.35, 模型性价比4-th-xjb = 0.35 / 4 = 0.0875。
[0048]
保存上述步骤中遍历的每一层编码器的评价结果: 《i-th-accuracy, i-th-xjb 》, i = [1,2,..., 24]。
[0049]
分析上述步骤保存的编码器的评价结果的分布函数fun(x=编码器id,y=仅用该编码器时的正确率,z=对应的性价比)。选出正确率不小于人工预设阈值 acc-threshold(即最低预期值,比如0.80,在分布函数的y轴最大值在0.82附近时)的所有编码器层数id,存于encoder_id_list,encoder_id_list中的编码层id按性价比(xjb) 降序排序,如果有超过3个以上的单个编码器对应的阈值都超过了人工阈值(如0.80),那么取前三个 id值作为
ꢀ“
胜出”的编码器,进入候选编码器,记作 top_3_candidate_ids;不超过3个则全保留作为候选编码器。
[0050]
遍历上述步骤中得到的所有候选编码器的索引encoder_m,(m from top_3_candidate_ids)。
[0051]
搜索与层数低于encoder_m的编码器进行融合的融合策略。遍历每个融合策略 integration, integration = [平均融合mean,拼接融合cat]。前者是求和sum再平均mean策略,即两个特征向量v1和v2的各对应位置数值相加再平均,得到的融合特征向量v3的维度和v1、v2一样;而后者则是在v1拼接v2,得到的v3长度增加1倍。举例说明:v1 = [0.1,0.2,0.3];v2 = [0.4,0.5,0.6];求和sum再平均mean策略:v3 = [0.25, 0.35, 0.45];拼接cat策略:v3 = [0.1,0.2,0.3,0.4,0.5,0.6];从低到高地遍历每个编码器索引 encoder_n,n=[1,2, ..., m-1],将第 n-th 层编码器输出的特征向量和第 m-th的特征向量执行融合策略integration,在选择集上,评价计算integration_n_m 策略的正确率 integration_n_m_ acc。比如,cat_2_12_acc = 0.76 表示将bert模型的第2层编码器输出的特征向量和第12层输出的特征向量进行拼接,得拼接后的语义特征向量,使用该特征向量在选择集上去执行cos相似度计算,并得到预测正确率为0.76。
[0052]
保存上述步骤中所有尝试使用的策略组合的正确率,记作 integration_n_m_ acc_list。
[0053]
另外,上述步骤中获得的top_3_candidate_ids中各id对应的正确率保存为single_m_acc_list。
[0054]
比较并获取以上两个列表(list)中的最大的正确率(max-acc),及其对应的策略 encoders_use_strategy。
[0055]
举例:encoders_use_strategy = single[m],它代表仅使用bert模型的第m层编码层输出的特征向量作为最终特征向量。
[0056]
或者:encoders_use_strategy = sum[n, m],它代表使用bert模型的第n层和第m层编码层输出的特征向量求和再取平均后,作为最终特征向量。
[0057]
或者:encoders_use_strategy = cat[n, m],它代表使用bert模型的第n层和第m层编码层输出的特征向量拼接后,作为最终特征向量。
[0058]
根据上述步骤中获得的最大正确率对应的使用策略encoders_use_strategy 去搭建最优变种模型(bert_variant)。
[0059]
举例说明:encoders_use_strategy = sum[4, 13]时,加载bert模型时,从低到高仅需加载至第13层编码器的参数,第14层到第24层的参数可以丢弃不用,然后,通过编写程序将4th-layer的输出和13th-layer的输出传入一个按对应位求和并取平均值的函数,将该函数返回的维度不变的融合特征向量作为最终的用户文本语义表征,用于后续计算cos相似度,保存该代码程序供后续训练和推理使用。
[0060]
使用时,通过首先获取根据用户的语音指令生成的原始样本数据,并根据该原始样本数据选取出位于不同时间段的第一样本数据集以及第二样本数据集;再根据第一样本数据集生成对应的选择集,并将bert原始模型以及选择集输入至预设优化模块中,以使优化模块输出bert_variant最优模型,在此基础之上,根据第二样本数据集生成对应的训练集,并将训练集输入至上述bert_variant最优模型中,以对该bert_variant最优模型进行
参数训练;最后当获取到用户实时输入的语音指令时,将语音指令转换成对应的文本数据,并将文本数据输入至训练完成的bert_variant最优模型中,以使训练完成的bert_variant最优模型根据当前文本数据输出用户的意图。通过上述方式能够在保证bert原始模型识别准确率的前提下,有效的降低推理时延,使之更加适用于实时交互场景,从而大幅缩短了推理的时间,提升了用户的使用体验,适用于大范围的推广与使用。
[0061]
需要说明的是,上述的实施过程只是为了说明本技术的可实施性,但这并不代表本技术的用户的意图识别方法只有上述唯一一种实施流程,相反的,只要能够将本技术的用户的意图识别方法实施起来,都可以被纳入本技术的可行实施方案。
[0062]
综上,本发明上述实施例提供的用户的意图识别方法能够在保证bert原始模型识别准确率的前提下,有效的降低推理时延,使之更加适用于实时交互场景,从而大幅缩短了推理的时间,提升了用户的使用体验,适用于大范围的推广与使用。
[0063]
请参阅图2,所示为本发明第二实施例提供的用户的意图识别系统,所述系统包括:获取模块12,用于获取根据用户的语音指令生成的原始样本数据,并根据所述原始样本数据选取出位于不同时间段的第一样本数据集以及第二样本数据集;处理模块22,用于根据所述第一样本数据集生成对应的选择集,并将bert原始模型以及所述选择集输入至预设优化模块中,以使所述优化模块输出bert_variant最优模型,所述选择集包括正样本以及负样本,所述bert原始模型包括若干层编码器;训练模块32,用于根据所述第二样本数据集生成对应的训练集,并将所述训练集输入至所述bert_variant最优模型中,以对所述bert_variant最优模型进行参数训练;输出模块42,用于当获取到用户实时输入的语音指令时,将所述语音指令转换成对应的文本数据,并将所述文本数据输入至训练完成的bert_variant最优模型中,以使训练完成的bert_variant最优模型根据所述文本数据输出所述用户的意图。
[0064]
其中,上述用户的意图识别系统中,所述处理模块22具体用于:将所述正样本以及所述负样本均输入至所述bert原始模型中,以对应获取到若干层所述编码器分别输出的若干特征向量;建立所述正样本和所述负样本与若干所述特征向量之间的索引关系,并根据若干所述特征向量生成对应的特征向量集合,以使所述优化模块根据所述特征向量集合输出所述bert_variant最优模型。
[0065]
其中,上述用户的意图识别系统中,所述处理模块22还具体用于:当获取到所述第一样本数据集时,识别出所述第一样本数据集中包含的若干用户意图,并根据若干所述用户意图生成对应的若干数据组,其中,同一所述数据组内的两个数据互为所述正样本,不同所述数据组内的任意两个数据互为所述负样本;根据若干所述数据组生成对应的若干样本集,其中,每一所述样本集均包括一待测样本、所述正样本以及所述负样本,且每一所述样本集均具有唯一性;对若干所述样本集进行整合处理,以生成所述选择集。
[0066]
其中,上述用户的意图识别系统中,所述处理模块22还具体用于:依次遍历若干所述样本集以及若干层所述编码器,并获取每一所述样本集中的待测样本对应的编码器输出的第一特征向量、每一所述正样本对应的编码器输出的第二特征
向量以及每一所述负样本对应的编码器输出的第三特征向量;计算出所述第一特征向量与所述第二特征向量之间的第一余弦相似度、所述第一特征向量与所述第三特征向量之间的第二余弦相似度,并判断所述第一余弦相似度是否大于所述第二余弦相似度;若判断到所述第一余弦相似度大于所述第二余弦相似度,则判定预测结果正确;若判断到所述第一余弦相似度小于所述第二余弦相似度,则判定预测结果错误。
[0067]
其中,上述用户的意图识别系统中,所述用户的意图识别系统还包括显示模块52,所述显示模块52具体用于:当识别出所述用户的意图时,根据所述意图生成对应的回复指令,所述回复指令包括若干关键词;响应于所述回复指令,调用出对应的文本数据库,并在所述文本数据库中查找出对应的回复文本,以将所述回复文本实时显示在显示终端。
[0068]
综上所述,本发明上述实施例提供的用户的意图识别方法及系统能够在保证bert原始模型识别准确率的前提下,有效的降低推理时延,使之更加适用于实时交互场景,从而大幅缩短了推理的时间,提升了用户的使用体验,适用于大范围的推广与使用。
[0069]
需要说明的是,上述各个模块可以是功能模块也可以是程序模块,既可以通过软件来实现,也可以通过硬件来实现。对于通过硬件来实现的模块而言,上述各个模块可以位于同一处理器中;或者上述各个模块还可以按照任意组合的形式分别位于不同的处理器中。
[0070]
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,“计算机可读介质”可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。
[0071]
计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(ram),只读存储器(rom),可擦除可编辑只读存储器(eprom或闪速存储器),光纤装置,以及便携式光盘只读存储器(cdrom)。另外,计算机可读介质甚至可以是可在其上打印所述程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得所述程序,然后将其存储在计算机存储器中。
[0072]
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
[0073]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示
例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0074]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。