技术特征:
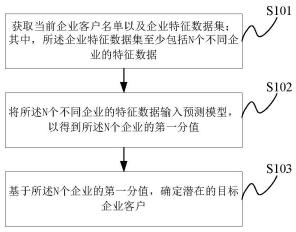
1.一种智能销售信息推荐方法,其特征在于,包括:获取当前企业客户名单以及企业特征数据集;其中,所述企业特征数据集至少包括n个不同企业的特征数据,所述企业客户名单包含所述n个不同企业中的m个企业,m小于n;将所述n个不同企业的特征数据输入预测模型,以得到所述n个不同企业的第一分值;其中,所述预测模型是基于第一样本数据集对xgboost模型训练得到的,所述第一样本数据集包括第一训练集和第一验证集,所述第一训练集包括第一正样本和第一负样本,所述第一验证集包括第二正样本和第二负样本,所述第一正样本包含从所述m个企业的特征数据中随机抽取的指定数量的特征数据,所述第二正样本包含从所述m个企业的特征数据中抽取后剩余数量的特征数据,所述指定数量小于所述剩余数量,所述第一负样本和第二负样本均包含以预设百分比r从所述n个不同企业的特征数据中随机抽取的p个特征数据得到的随机负样本以及难分负样本;其中,r=p/n=1-a,a表示所述n个不同企业中能够成为潜在意向企业客户的比值;基于所述n个不同企业的第一分值,确定潜在的目标企业客户。2.根据权利要求1所述的方法,其特征在于,所述n个不同企业的特征数据包括企业画像特征数据和企业基本特征数据;在使用所述第一训练集对所述xgboost模型的训练过程中,使用所述第一验证集对所述xgboost模型的输出结果进行验证,同时观测模型评价指标是否满足预设条件,若否,则调节所述xgboost模型的超参数以及增加所述企业画像特征数据来重新训练。3.根据权利要求1所述的方法,其特征在于,该方法还包括:获取所述n个不同企业各自的企业介绍文本;将所述n个不同企业各自的企业介绍文本输入命名实体识别模型,以识别得到所述n个不同企业对应的预设名词,所述预设名词包括至少一个业务名词和/或产品名词;其中,所述命名实体识别模型是基于样本企业介绍文本对bert模型预先训练得到的;计算所述n个不同企业对应的预设名词各自的第一逆向文件频率idf并形成第一idf字典,同时计算所述n个不同企业中每个企业对应的预设名词的第一词频tf并形成第一tf字典;基于所述第一idf字典、所述第一tf字典生成所述n个不同企业中每个企业对应的第一tf-idf以形成第一tf-idf字典;基于所述企业客户名单,从识别得到的所述n个不同企业的预设名词中选择确定所述m个企业对应的所有预设名词,计算所述m个企业对应的所有预设名词各自的第二词频tf并形成第二tf字典;基于所述第二tf字典、所述第一idf字典,生成所述m个企业对应的所有预设名词各自的第二tf-idf以形成第二tf-idf字典;基于所述第二tf-idf字典以及所述第一tf-idf字典,对所述n个不同企业中每个企业对应的预设名词的第一tf-idf和第二tf-idf进行加权求和计算,以得到所述n个不同企业中每个企业对应的第二分值;基于所述n个不同企业中每个企业的第二分值,以及所述n个不同企业的第一分值,确定所述n个不同企业中每个企业的最终分值;基于所述n个不同企业中每个企业的最终分值,确定潜在的目标企业客户。
4.根据权利要求3所述的方法,其特征在于,所述基于所述n个不同企业中每个企业的第二分值,以及所述n个不同企业的第一分值,确定所述n个不同企业中每个企业的最终分值,包括:基于所述n个不同企业中每个企业的第二分值以及所述n个不同企业的第一分值,确定所述n个不同企业各自的分值特征数据;将所述n个不同企业各自的分值特征数据输入逻辑回归模型,得到所述n个不同企业中每个企业的最终分值;其中,所述逻辑回归模型是基于第二样本数据集对原始的逻辑回归模型训练得到的,所述第二样本数据集包括第二训练集和第二验证集,所述第二训练集包括第三正样本和第三负样本,所述第二验证集包括第四正样本和第四负样本;其中,所述第三正样本包含从所述n个不同企业的分值特征数据中匹配的所述m个企业的分值特征数据中随机抽取的所述指定数量的分值特征数据;所述第四正样本包含从所述m个企业的分值特征数据中抽取后所述剩余数量的分值特征数据;所述第三负样本和第四负样本均包含以所述预设百分比r从所述n个不同企业的分值特征数据中随机抽取的p个分值特征数据得到的随机负样本以及难分负样本。5.根据权利要求1~4任一项所述的方法,其特征在于,所述指定数量与所述剩余数量的比值为3/7。6.根据权利要求2~4任一项所述的方法,其特征在于,各所述企业基本特征数据包括企业成立年限、注册资本、行业类别、经营范围、所在地区中的一个或多个。7.根据权利要求6所述的方法,其特征在于,该方法还包括:对所述n个不同企业各自的企业画像特征数据和企业基本特征数据进行预处理,以得到所述企业特征数据集;其中所述预处理至少包含数据分箱和/或独热one-hot编码。8.一种智能销售信息推荐系统,其特征在于,包括:获取模块,用于获取当前企业客户名单以及企业特征数据集;其中,所述企业特征数据集至少包括n个不同企业的特征数据,所述企业客户名单包含所述n个不同企业中的m个企业,m小于n;识别模块,用于将所述n个不同企业的特征数据输入预测模型,以得到所述n个不同企业的第一分值;其中,所述预测模型是基于第一样本数据集对xgboost模型训练得到的,所述第一样本数据集包括第一训练集和第一验证集,所述第一训练集包括第一正样本和第一负样本,所述第一验证集包括第二正样本和第二负样本,所述第一正样本包含从所述m个企业的特征数据中随机抽取的指定数量的特征数据,所述第二正样本包含从所述m个企业的特征数据中抽取后剩余数量的特征数据,所述指定数量小于所述剩余数量,所述第一负样本和第二负样本均包含以预设百分比r从所述n个不同企业的特征数据中随机抽取的p个特征数据得到的随机负样本以及难分负样本;其中,r=p/n=1-a,a表示所述n个不同企业中能够成为潜在意向企业客户的比值;确定模块,用于基于所述n个不同企业的第一分值,确定潜在的目标企业客户。9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1~7任一项所述智能销售信息推荐方法。10.一种电子设备,其特征在于,包括:处理器;以及
存储器,用于存储计算机程序;其中,所述处理器配置为经由执行所述计算机程序来执行权利要求1~7任一项所述智能销售信息推荐方法。
技术总结
本公开涉及智能销售信息推荐方法及系统,方法包括:获取企业客户名单及企业特征数据集,企业特征数据集包括N个企业的特征数据,企业客户名单包含N个企业中的M个企业;将N个企业的特征数据输入预测模型得到N个企业分值,预测模型是基于样本数据集对XGBoost模型和逻辑回归模型训练得到,样本数据集包含训练集和验证集,训练集的正样本是从M个企业的特征数据中随机抽取指定数量的特征数据,验证集的正样本是M个企业的特征数据中剩余数量的特征数据,指定数量小于剩余数量,训练集和验证集的负样本均是以预设百分比从N个不同企业的特征数据中随机抽取的P个特征数据得到的随机负样本及难分负样本;基于N个企业分值确定目标客户。户。户。
技术研发人员:卫晓祥 吴传文 唐绍祖
受保护的技术使用者:启客(北京)科技有限公司
技术研发日:2022.10.17
技术公布日:2022/11/11
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。