用于异步视频设置中的自动候选者评估的系统和方法
1.相关申请
2.本技术要求2020年1月29日提交的美国临时申请序列号62/967,443的优先权,该临时申请题为“systems and methods for automatic candidate assessments in an asynchronous video setting”。本技术与2020年1月29日提交的美国临时申请序列号62/967,451相关,该申请题为“systems and methods for automating validation and quantification of interview question responses”。所有上述申请的全部内容在此引入作为参考。
背景技术:
3.操作面试是最古老和最常用的员工选拔方法之一。通常,面试包括候选者和一个或多个面试官之间的面对面会话。在会话期间,面试官试图获得关于候选者技能和操作适合性的真实信息,以便做出正确的雇佣决定。另一方面,候选者试图表明他们非常适合填补空缺职位。由于其会话和结构上的冲突性质,操作面试必须被描述为互动的事件。
4.技术深刻地影响着我们与他人互动的方式。纵观历史,新的沟通渠道塑造了个人互动,随着互联网和移动技术的出现,这种发展变得更快、更普遍。操作面试也不例外,并已适应新技术,以受益于降低成本和提高效率。电话面试和视频会议都是在操作面试中使用技术的众所周知的示例。
5.视频面试可以是单向的,也可以是双向的互动。在单向视频异步视频面试(avi)中,申请人不与现场面试官互动。面试问题虚拟地呈现在带有网络摄像头和音频功能的电脑、平板电脑或智能手机上。申请人通过一系列一个接一个提出的问题,他们必须在给定的时间内立即口头响应。然而,在所有人工评估机制中,不可能从评审者对候选者的评估中消除偏见。此外,由于在单向视频面试中没有针对候选者的即时反馈机制,因此很难防止候选者提交数据质量差或未能回答所提问题的响应。本发明人已经认识到单向视频采访和评估系统的这些困难,并且本公开针对不会遭受这些缺陷的视频评估的系统和方法。
技术实现要素:
6.在一些实施例中,用于执行自动化候选者视频评估的系统和方法包括经由网络从第一方的远程计算设备接收空缺职位的候选者视频提交。候选者视频提交可以包括一个或多个问题响应视频,其中每个视频对应与空缺职位相关联的相应面试问题。
7.在一些实施方式中,对于一个或多个问题响应视频中的每个问题响应视频,系统可以通过将语音到文本算法应用于相应问题响应视频的音频部分来生成相应问题响应视频的抄本。在一些示例中,利用与个性模型的多个个性方面相关联的术语的定制词典来训练语音到文本算法,个性方面指示候选者对于空缺职位的资质。在一些实施例中,系统可以在相应问题响应视频的抄本中检测多个标识符,每个标识符与个性模型的一个或多个个性方面相关联。在一些示例中,检测多个标识符可以包括将自然语言分类器应用于抄本。自然语言分类器可以被训练来检测与个性模型的多个个性方面相关联的单词和短语,并且检测
多个标识符可以包括根据相应标识符与多个个性方面中的哪个相关联来对多个标识符中的每个标识符进行分组。
8.该系统可以基于检测到的多个个性方面中的每个个性方面的标识符中的每个标识符的分组,基于相应个性方面与相应面试问题的相关性以及检测到的相应个性方面的分组内的标识符的数量,来计算多个个性方面中的每个个性方面的分数。在一些实施例中,系统可以根据一个或多个问题响应视频中的每个问题响应视频的多个个性方面中的每个个性方面的分数,生成包括一个或多个面试问题的整个面试的组合个性方面分数。响应于接收到查看候选者面试结果的请求,可以在第二方的第二远程计算设备的用户界面屏幕内呈现一个或多个问题响应视频的每个问题响应视频中的多个个性方面中的每个个性方面的至少一个组合个性方面分数或分数的部分。
9.说明性实施方式的前述一般描述及其以下详细描述仅仅是本公开教导的示例性方面,而不是限制性的。
附图说明
10.包含在说明书中并构成说明书一部分的附图示出了一个或多个实施例,并与说明书一起解释了这些实施例。附图不一定是按比例绘制的。附图中所示的任何数值尺寸仅用于说明目的,可能代表也可能不代表实际的或优选的数值或尺寸。在适用的情况下,一些或所有特征可能没有被示出以帮助描述基础特征。在附图中:
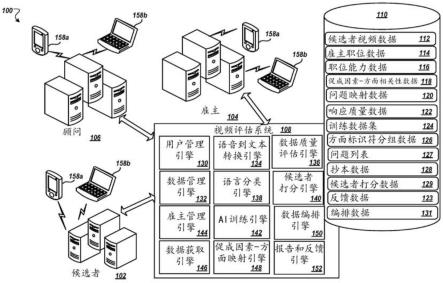
11.图1是用于视频评估系统的示例环境的框图;
12.图2是用于将职位能力映射到促成因素属性(enabler attribute)的表格;
13.图3是示出与职位能力相关联的面试问题的表格;
14.图4是用于选择面试问题并将其映射到促成因素属性的表格;
15.图5是示出个性模型中工作风格的个性方面的图;
16.图6是示出职位的个性方面到促成因素属性的映射的表格;
17.图7是显示个性方面到职位的能力的映射的表格;
18.图8是示出职位的面试问题到个性方面的映射的表格;
19.图9示出了问题概要用户界面屏幕;
20.图10示出了问题输入用户界面屏幕;
21.图11是用于个性方面的正面和负面标识符的表格;
22.图12示出了具有由自然语言分类器检测到的个性方面的面试问题抄本;
23.图13示出了在面试问题抄本中检测到的正面和负面标识符的方面分组;
24.图14是候选者分数数据表;
25.图15示出了报告和反馈用户界面屏幕;
26.图16是示出视频评估系统的组件之间的示例通信流的泳道图;
27.图17a示出了视频评估系统的数据架构和编排结构;
28.图17b-17c示出了视频评估系统的数据架构和操作流程;
29.图17d示出了视频评估系统的数据处理集群的操作流程配置;
30.图18示出了用于训练自然语言分类器的示例方法的流程图;
31.图19示出了用于为空缺职位生成问题/方面映射的示例方法的流程图;
32.图20示出了用于执行候选者视频评估的示例方法的流程图;
33.图21是示例计算系统的框图;
34.图22是包括云计算环境的示例分布式计算环境的框图;和
35.图23示出了问题选择用户界面屏幕。
具体实施方式
36.以下结合附图阐述的描述旨在描述所公开主题的各种说明性实施例。结合每个说明性实施例描述了具体的特征和功能;然而,对于本领域技术人员来说,显然可以在没有这些具体特征和功能的情况下实施所公开的实施例。
37.本公开的各方面涉及一种用于为雇主自动化候选者面试的视频评估系统。在一些实施例中,该系统被配置为从提交的视频面试中自动生成抄本,并使用经训练的自然语言分类器从抄本内的个性模型中检测预定的个性方面。在一些示例中,系统可以应用为个性模型定制的候选者分数方法,该方法考虑了抄本中的证据量、检测到的个性方面标识符的数量以及分数置信度。这些评估方法使用独特的模型和过程来自动识别操作的最佳候选者,而不会引入人为偏见和错误。在一些实施方式中,视频评估系统生成针对特定个性的面试问题的定制映射,其可以准确预测特定候选者是否非常适合特定操作。面试问题映射的定制的数据结构提高了系统候选者分数计算的处理效率。出于所有这些原因,本文提供的本公开的实现是对执行候选者视频评估的手动、传统方法的显著改进,并且必须植根于计算机技术。
38.图1是视频评估系统108的示例环境100的图。该图示出了用于收集、生成、组织、存储和分发自动、准确和高效地处理从一个或多个空缺职位的候选者接收的面试问题响应所必需的信息的关系、交互、计算设备、处理模块和存储实体,而没有来自人类输入的任何偏见。在一些实施方式中,视频评估系统108可以向雇主104提供为一个或多个可用操作定义定制的能力描述以及识别与所定义的操作能力相关联的面试问题的能力。在一些实施例中,系统108自动将所识别的操作能力和面试问题转换成定制的面试映射,该定制的面试映射将问题和能力映射到与个性模型相关联的一组个性方面。
39.当候选者102提交对所识别的面试问题的视频响应时,在一些实施方式中,视频评估系统108通过对每个视频文件的音频部分执行语音到文本转换以创建面试问题抄本来生成问题响应抄本。在一些示例中,自然语言分类器可以被专门训练来从面试问题抄本内检测个性模型中个性方面的正面和负面极性。在一些实施例中,视频评估系统108使用检测到的每个面试问题抄本中每个个性方面的出现来计算每个个性方面的分数。在一些示例中,基于所计算的分数,系统108可以确定候选者对于特定操作有多适合,或者候选者有多少资质。
40.在某些实施例中,候选者102可以经由分布在大型网络上的多个计算设备连接到视频评估系统108,该大型网络在范围上可以是国内或国际的。候选者102的网络可以与和视频评估环境100中的其他实体(诸如提供商104和顾问106)相关联的网络分离和独立。此外,由候选者102处理和存储的数据可以是与由视频评估环境100的其他实体处理和存储的数据不同的格式。在一些示例中,候选者102可以包括由提供商104在系统108中创建的任何可用操作的预期和实际工作申请人。
41.在一些实施方式中,雇主104包括分布在大型网络上的多个计算设备,该大型网络在范围上可以是国内或国际的。雇主网络104可以与和视频评估环境100中的其他实体(诸如候选者102和顾问106)相关联的网络分离和独立。此外,由雇主104处理和存储的数据可以是与由视频评估环境100中的其他参与者处理和存储的数据不同的格式。在一些实施方式中,雇主104可以包括希望使用视频评估系统108来自动筛选候选者视频面试提交和对候选者视频面试提交进行打分的大规模或小规模公司。在一些示例中,雇主104与一个或多个系统生成的用户界面屏幕进行交互,以识别面试问题并定义理想雇员的理想能力、属性和个性特征,系统可以使用这些来自动评估特定候选者对操作的适合程度。
42.在一些实施方式中,顾问106包括分布在大型网络上的多个计算设备,该大型网络在范围上可以是国内或国际的。顾问网络可以与和视频评估环境100中的其他实体(诸如候选者102和雇主104)相关联的网络分离和独立。此外,由顾问106处理和存储的数据可以是与由视频评估环境100中的其他参与者处理和存储的数据不同的格式。在一些示例中,顾问106可以是后端系统管理员,他们知道如何选择能力、促成因素属性和面试问题,以最好地识别非常适合雇主104提交的特定操作的候选者。在一些示例中,顾问106可以通过一个或多个系统提供的用户界面屏幕与雇主104交互,以帮助雇主104选择相应职位的能力、促成因素属性和面试问题。
43.在一些实施例中,视频评估系统108可以包括一个或多个引擎或处理模块130、132、134、136、138、140、142、146,其执行与生成针对空缺职位的问题的个性方面映射以及基于所生成的个性方面映射对提交的候选者面试视频执行视频评估相关联的过程。在一些示例中,由视频评估系统108的引擎执行的过程可以被实时执行,以提供对系统输入的即时响应,系统输入为诸如雇主104、顾问106和/或候选者102从系统108获得经处理的信息的请求。例如,系统108可以将视频提交转换成文本抄本,使用经训练的自然语言分类器从个性模型中检测个性方面,并且响应于接收到候选者视频面试提交来实时地对候选者面试响应进行打分。
44.在一些实施方式中,视频评估系统108可以包括用户管理引擎130,用户管理引擎130可以包括与提供接口以与视频评估环境100内的一个或多个用户(例如,由雇主104和顾问106以及候选者102雇用或以其他方式与之相关联的个人)进行交互相关联的一个或多个过程。例如,用户管理引擎130可以控制候选者102、雇主104和顾问106经由一个或多个外部设备158处的认证接口对视频评估系统108的连接和访问。在一些示例中,外部设备158可以包括但不限于个人计算机、膝上型/笔记本计算机、平板计算机和智能手机。在一些实施方式中,用户管理引擎130控制向哪个系统用户显示哪个系统数据。例如,用户管理引擎130将候选者面试对应与特定雇主104的空缺职位相关联,使得仅显示与相应雇主104提交的操作相关联的信息,以供特定雇主104基于接收到的认证证书进行查看和反馈。
45.在一些示例中,视频评估系统108还可以包括数据管理引擎132,其组织、存储和控制对数据储存库110中的数据的访问。例如,响应于从雇主104接收职位能力数据输入,数据管理引擎132可以将能力数据116链接到相应雇主职位数据114。类似地,数据管理引擎132还可以将促成因素方面相关性数据118和问题映射数据120链接到数据储存库110内的相应雇主职务数据114。在一些实施方式中,数据管理引擎132还可以链接与数据存储库110内的特定候选者面试和特定问题响应相关的所有信息。例如,数据存储库110可以将候选者分数
数据129链接到候选者视频面试提交的相应抄本数据128。此外,数据管理引擎132还可以被配置为将更新的训练数据(例如,来自新计算的候选者分数和来自雇主的提交反馈)编译到训练数据集124中。
46.在一些实施方式中,视频评估系统108还可以包括雇主管理引擎144,其控制系统108、雇主104和顾问106之间的交互。在一些实施例中,雇主管理引擎144经由一个或多个用户界面(ui)屏幕接收来自雇主的关于一个或多个可用就业职位的输入。在一些示例中,ui屏幕可以提供一系列下拉或选择窗口,允许雇主104从通常选择的或先前提供的职位列表中选择空缺职位。例如,金融公司可能重复出现金融分析师的空缺,或者零售公司可能经常征求店内收银员或客户服务代表的申请。在一些实施例中,ui屏幕还可以包括允许雇主104提供关于新空缺职位的信息的自由文本输入字段。在一些示例中,雇主104还可以提供关于所识别的空缺职位的管理细节,诸如经验年限、教育资格和预计开始日期。在通过ui屏幕提交后,空缺职位信息作为雇主职位数据114保存在数据储存库110中。在一些实施方式中,给定雇主104的雇主职位数据112可以包括雇主104当前和先前提供的所有职位的表格或列表。
47.在一些实施方式中,雇主管理引擎144还可以向雇主104的计算设备158提供ui屏幕,以识别与每个识别的空缺职位相关联的能力。特定职位的一组识别的能力可被称为该职位的能力模型,其作为职位能力数据116存储在数据存储库110中。基于定义职位能力模型的雇主104,职位能力数据116可以链接到相应雇主职位数据114。在一些示例中,能力可以是雇员应该拥有的任何技能或属性。例如,由雇主104识别的职位的能力可以包括但不限于动机、抱负、自我意识和韧性。在一些示例中,如果雇主104过去已经将视频评估系统108用于相同类型的职位,则雇主管理引擎144可以用先前识别的职位能力自动填充能力识别ui屏幕。雇主104进而可以通过从能力模型中添加或删除能力来修改能力模型中的能力列表,或者可以接受先前使用的能力列表。
48.在一些方面,能力可以与雇主104的所有职位相关(例如,诚信),但是另一个能力可以仅与一个或几个职位相关(例如,面向细节的数据分析师职位或领导的管理职位)。在一些实施方式中,存储的职位能力数据116可以包括关于哪些能力适用于给定雇主的所有、一些或一个职位的信息。此外,雇主管理引擎144可以基于职位能力数据116,用通常链接到与雇主104相关联的所有和/或某些类型的职位的能力来自动填充新创建职位的能力模型。在一些示例中,雇主管理引擎144还可以使用其他雇主104的职位的能力模型信息来识别空缺职位的能力建议。例如,雇主管理引擎144可以为使用视频评估系统108来处理和评估工作申请者面试的所有雇主104识别不同类型职位的能力趋势,并将任何识别的趋势提供给雇主104。例如,雇主管理引擎144可以确定雇主104将果断识别为管理员职位的能力,并且如果雇主104提交管理员的空缺职位信息,则反过来建议果断作为能力。
49.在一些实施例中,响应于从雇主104接收到针对空缺职位的一组能力,雇主管理引擎144可以生成一个或多个ui屏幕,用于将每个识别的能力映射到一个或多个促成因素属性。在一些示例中,促成因素属性是标准化属性的集合,其提供了用于将雇主识别的能力翻译成个性方面的翻译或转换机制,该个性方面可以由实现专门训练的自然语言分类器(nlc)的语言分类引擎138从面试抄本中自动识别。在一些示例中,雇主104和顾问106可以经由一个或多个系统提供的ui屏幕彼此交互,这允许顾问106教育和帮助雇主104识别职位
的能力模型中的每个能力的适当的促成因素属性。如果特定能力先前已经被雇主104识别用于另一个职位或相同职位的先前重复,则雇主管理引擎144可以提供先前的促成因素属性映射作为一个或多个所识别能力的建议促成因素属性。
50.图2示出了在ui屏幕上提供给雇主的空缺职位的能力-促成因素映射表200。对于为空缺职位识别的每个能力202,雇主104可以从ui屏幕中提供的下拉菜单中选择一个或多个促成因素属性204。促成因素属性204的示例包括“谦逊行事”、“适应个体差异”、“关注关键细节”、“灵活行事”、“建立关系”、“拥护变革”和“指导表现”。在一个示例中,识别的“自我意识”的能力可以被映射到“谦逊行事”的促成因素属性。
51.回到图1,在一些实施方式中,响应于接收到能力促成因素属性选择,雇主管理引擎144产生面试问题选择ui屏幕,该屏幕允许雇主104在有或没有顾问106的帮助下,为该职位选择与雇主识别的能力中的每个能力相匹配的面试问题。例如,图3提供了一组面试问题或提示300,其中每个问题/提示与来自职位的能力模型的特定能力相关联。例如,对于动机302a的能力,识别提示302b“描述你最有生产力并且给你最大满意度的操作环境(describe the work environment in which you are most productive and gives you the most satisfaction)”。一个问题304b“你为什么选择飞行作为职业,你为自己设定了什么职业目标?(why have you chosen flying as a career and what career goals have you set for yourself?)”对应于抱负304a的能力。问题306b“你认为要想在这个项目中取得成功,你需要在自己发展的哪些方面下功夫?(what areas of your own development do you think you will have to work on to succeed on this program?)”对应于自我意识306a的能力。提示308b“给我们你遇到的挫折的的示例和你如何恢复的?(give us an example of a setback you encountered and how you bounced back)”对应于韧性308a能力。在一些实施方式中,每个问题可以被映射到多个能力和/或促成因素属性,这允许系统108自动检测单个问题响应中的多个个性方面标识符。此外,如下面进一步讨论的,系统108可以基于能力与问题的相关性来不同地加权与问题相关联的每个能力,这进一步允许定制的、自动化的解决方案,用于以无偏见的方式准确地识别空缺职位的最佳候选者102。
52.在一些实施方式中,面试问题选择ui屏幕基于所识别的促成因素属性提供了用于选择的一组问题。例如,图4示出了问题-促成因素映射表400,其允许雇主104选择与每个识别的促成因素属性404相关联的面试问题402。对于为空缺职位识别的每个促成因素属性404,雇主104可以从ui屏幕中提供的下拉菜单中选择一个或多个面试问题402。例如,对于“参加”的雇主属性,下拉菜单406提供一组可能的面试问题,包括“描述你必须遵循详细指示来完成任务的时间(describe a time when you had to follow detailed instructions to complete a task)”和“描述你必须执行需要仔细注意细节和质量的任务的时间(describe a time when you had to perform a task that required careful attention to detail and quality)”。通过从能力-促成因素映射中选择针对已确定促成因素属性的面试问题,这些问题也将针对已确定的能力进行定制。另外,雇主104可以选择一个以上的促成因素属性来映射到单个面试问题。
53.在一些实施方式中,问题列表127存储在数据储存库110中,用于填充问题促成因素映射表400中每个问题选择器的下拉菜单406。在一些示例中,这些问题列表127被链接到特定的促成因素属性408、410、412,使得当促成因素属性被链接到职位的能力时,雇主管理
引擎144自动填充相应促成因素属性的下拉菜单中的可能问题列表。在一些实施方式中,问题列表127中的每个问题都存储有关于相应问题与每个可能的促成因素属性的相关性的信息。例如,问题“告诉我你支持同事解决复杂问题的时候(tell me about a time when you supported a colleague in solving a complex problem)”可以链接到“协作”408的促成因素属性。问题询问“告诉我你与他人分享你的成功的一次经历(tell me about a time you shared credit for your success with others)”的问题可以链接到“谦逊行事”410的促成因素属性。问题询问“描述你必须遵循详细指令来完成任务的时候(describe a time when you had to follow detailed instructions to complete a task)”的问题可以被链接到“关注关键细节”412的促成因素属性。在一些实施方式中,从下拉菜单406中选择的每个问题可以被映射到多个促成因素属性,这允许系统108自动检测单个问题响应中的多个个性方面标识符。此外,如下面进一步讨论的(例如,参见图8),系统108可以基于促成因素属性和/或能力与问题的相关性来不同地加权与问题相关联的每个促成因素属性,这进一步允许定制的、自动化的解决方案,用于以不偏不倚的方式准确地识别空缺职位的最佳候选者102。例如,问题询问“告诉我你与他人分享你的成功的一次经历”除了“谦逊行事”412之外,还可以链接到“建立关系”的促成因素属性。在一个示例中,在从3到5的范围内对相关性进行打分,其中5是高度相关的问题。可以理解的是,任何类型的分数尺度或范围都可以应用于面试问题与促成因素属性的相关性的量(例如,百分比、高/中/低、一到十、一到五)。当在问题-促成因素映射表400中选择问题402时,雇主管理引擎144自动填充与任何适用的促成因素404的相关性。例如,在表400中,问题“告诉我你支持同事解决复杂问题的时候”对于“协作”408的促成因素属性具有相关性值4。此外,问题“告诉我你与他人分享你的成功的一次经历”对于“行为谦逊”410的促成因素属性具有5的相关性值。在一个以上的启用属性链接到特定问题的示例中,雇主管理引擎144为每个启用属性确定各自的相关性值。
54.此外,雇主管理引擎144可以根据每个问题被选择用作面试问题的频率和/或该问题与一个或多个促成因素属性的相关性,在下拉菜单406中排列该组问题。在一些实施例中,雇主104和/或顾问106也可以提供他们自己的没有在下拉菜单之一中提供的面试问题。当雇主104提供这些手动输入的面试问题之一时,雇主104还提供该问题的促成因素属性映射信息。
55.此外,图23示出了问题选择用户界面屏幕2300,其允许雇主104定制面试问题,以适应他们在可用就业职位的候选者中寻找的个性特征。例如,用户界面2300可以显示一个或多个可选问题2302、2304、2306、2308,雇主104可以通过点击相应问题2302、2304、2306、2308来选择/取消选择这些问题。用户界面屏幕2300可以包括至少一个过滤器输入2310,其允许用户基于类型、能力和/或方面来过滤所显示的问题。此外,一旦选择了一组问题2302、2304、2306、2308,用户就可以选择问题并将其重新定位为期望的顺序。除了针对不同能力和/或个性方面的不同问题之外,雇主104可以在用户界面屏幕2300上选择不同的问题格式。例如,问题2302可以是询问候选者的一些基本背景信息问题的面试欢迎问题。问题2304是虚拟案例研究问题,其向候选者呈现要响应的案例研究场景。问题2306是视频问题,其提供视频供候选者观看和响应。例如,视频可以提供与候选者正在回答的问题相关联的历史、背景或场景。在一些实施方式中,问题2308是向候选者显示和/或读出(例如,音频输出)问
题的标准问题,候选者进而提供响应。
56.在一些示例中,问题可以包括宽泛的问题,该问题还包含多个附加的探查性问题,这些问题有助于引导候选者提供期望的信息。问题的一个示例是:“描述一次你通过运用你的沟通技巧解决了主要问题(describe a time you resolved a major problem by using your communication skills)”。为了帮助候选者精心设计包含相关信息的完整响应,这个问题还附带了以下四个附加问题:“当时的情况是怎样的?(what was the situation?)”,“信息是如何传达的?(how was the information communicated?)”、“您采取了什么措施来解决问题?(what did you do to resolve the issue?)”,以及“结果如何?(what was the outcome?)”。
57.回到图1,在一些实施方式中,视频评估系统108还具有促成因素-方面映射引擎148,该引擎自动将每个所识别的促成因素属性映射到可以使用经特殊训练的自然语言分类器从面试记录中检测到的个性方面。如下文进一步讨论的,ai训练引擎142训练由语言分类引擎138实现的自然语言分类器,以自动检测正面和负面个性方面的集合,这些集合可以指示候选者适合特定职位的程度。
58.图5示出了候选个性模型500中的一组个性方面,视频评估系统108被训练来检测这些个性方面。在一些示例中,相应工作风格类别502-512中的每个个性方面包括可由自然语言分类器检测的正面和负面指示。在一些实施方式中,个性模型500中的各方面可被组织成一个或多个工作风格类别502-512。例如,任务风格的工作风格类别502可包括“驱动”和“结构”的个性方面。适应风格类别504可以包括“概念性”、“灵活性”和“精通性”的个性方面。成就风格类别506可以包括“抱负”和“本领”的个性方面。交互风格类别508可以包括“自信”和“活跃”的个性方面。情绪风格类别510可以包括“沉着”、“积极”和“自我意识”的个性方面。团队风格类别512可以包括“合作”、“敏感”和“谦逊”的个性方面。
59.图6示出了促成因素-方面映射表600,其示出了促成因素-方面映射引擎148如何将与所识别的职位能力相关联的每个促成因素映射到个性模型500中的一个或多个方面。作为促成因素-方面映射过程的一部分,促成因素-方面映射引擎148还基于方面与相应促成因素的相关程度,将相关性值应用于每个促成因素-方面对。在一个示例中,每个促成因素属性-方面对的相关性以从1到5的等级分数,其中5表示促成因素-方面对之间的最高相关性。可以理解的是,任何类型的分数尺度或范围都可以应用于面试问题与促成因素属性的相关性的量(例如,百分比、高/中/低、一到十)。在一些实施方式中,促成因素-方面映射引擎148从存储在数据储存库110中的促成因素-方面相关性数据118中访问相应促成因素-方面对的相关性分数。在一些实施方式中,促成因素方面相关性数据118基于基于个性的研究,并且被手动加载到数据储存库110中。在一些实施方式中,促成因素相关方面数据118也可以基于从雇主104和/或顾问106接收的反馈以及自然语言分类器的更新的训练集数据随时间更新。如图6所示,方面“结构”的促成因素-方面对602具有与“关注关键细节”的促成因素相关联的相关性值5。另外,方面“合作”的促成因素-方面对604具有与“合作”的促成因素相关联的相关性值5,并且方面“谦逊”的促成因素-方面对606具有与“谦逊行事”的促成因素相关联的相关性值5。
60.在一些实施例中,促成因素-方面映射引擎148还可以将针对空缺职位的每个所识别的能力映射到个性模型500的一个或多个方面。在一些示例中,促成因素-方面映射引擎
148可以从促成因素-方面映射中导出能力-方面映射,如映射表600和能力-促成因素映射200(图2)。例如,图7示出了能力-方面映射表700,其示出了促成因素-方面映射引擎148如何将与所识别的职位能力相关联的每个能力映射到个性模型500中的一个或多个方面。类似于促成因素-方面映射表600,能力-方面映射表700也基于一个方面与职位的相应能力的相关程度,将相关性值应用于每个能力-方面对。例如,能力-方面映射表700为图2所示的能力-促成因素映射表200提供了技术基础。在一个示例中,每个能力-方面对的相关性也在从一到三的范围内分数,三表示能力-方面对之间的最高相关性。然而,可以理解,也可以应用其他分数范围(例如,高/中/低、一到五、一到十)。例如,在表700中,对于给定的职位,动机能力702可以基于相关性值为3的“驱动”方面和相关性值为1的“活跃”方面来定义。此外,抱负能力704可以基于相关性值为1的“概念性”方面、相关性值为2的“精通”方面以及相关性值为3的“抱负”方面来定义。
61.在一些实施方式中,使用问题-促成因素映射表400(图4)、促成因素-方面映射表600和/或能力-方面映射表700,促成因素-方面映射引擎148为雇主104提交的每个空缺职位生成问题-方面映射。这些问题-方面映射是定制的数据结构,其唯一有助于提高系统108实时或接近实时地执行候选者评估的能力。例如,图8示出了由雇主104提交给视频评估系统108的空缺职位的面试问题-方面映射表800。在这个示例中,该表包括对应于个性模型(例如,图5中的个性模型500)的十五个方面804中的每一个的职位的四个面试问题802。在一些实施方式中,表800中每个问题-方面对的值可以从能力-促成因素映射表200和问题-促成因素映射表400(图4)的逆矩阵中导出,并且反映每个个性方面与相应问题的相关性。在一些方面,表800中的累积相关性分数是独立于表800中所有其他分数的绝对分数。在类似于图8所示示例的其他示例中,促成因素-方面映射引擎148归一化所有相关性分数,使得表中的所有值都在0和1之间,其中1表示与相应问题高度相关的方面,0表示与相应问题相关性很小或没有相关性的方面。例如,对于问题“描述你操作效率最高并且给你最大满意度的操作环境”806,“驱动”方面808具有最高的相关性分数1.00,“活跃”方面812和“能力”方面814具有0.33的相关性分数,“自信”方面810和“自我意识”方面818具有0.11的相关性分数,并且所有其余方面具有0的相关性分数。
62.在一些实施例中,促成因素-方面映射引擎148将由系统108处理的每个职位的问题-方面映射表800和能力-方面映射表700作为问题映射数据120存储在数据储存库110中。问题映射表800的数据结构(除了促成因素-方面映射表600、能力-方面映射表700和问题-促成因素映射表400之外)通过提供简化面试分数计算和候选者评估的结构提高了视频评估系统800的处理效率,如下面进一步讨论的。具体地,具有包括每个面试问题的每个方面的相关性分数的单个数据结构使得候选者分数引擎140能够更快速地计算每个方面、每个问题和每个候选者的分数。
63.回到图1,视频评估系统108还可以包括数据获取引擎146,其控制、处理和管理从申请一个或多个雇主104的空缺职位的候选者102接收的面试提交。在一些实施方式中,数据获取引擎146向候选者102的计算设备158提供一个或多个ui屏幕,以允许他们与系统108交互,从而为一个或多个空缺职位提供面试提交视频。在一些示例中,在登录到系统108并选择要申请的空缺职位时,数据获取引擎146提供具有该职位的面试问题列表的问题概要ui屏幕(从该职位的问题映射数据120访问)和用于访问一个或多个问题记录ui屏幕的选择
器工具。在一些示例中,经由计算机处的基于ui的方法和/或通过经由电话递送的一组基于音频的提示,仅捕捉来自候选者102的音频数据。
64.例如,图9示出了“职位a”的问题概要ui屏幕900,其具有四个对应的面试问题902-908,候选者可以在选择其中一个问题之前查看这些问题以记录响应。在一些实施方式中,在问题概要ui屏幕900上列出的每个问题902-908还可以包括问题状态指示符910-916,其提供与每个问题902-908相关联的视频记录文件的完成状态。例如,问题902、908具有“完成”的相应完成状态910、916,这意味着候选者已经成功记录并链接了对相应面试问题902、908的响应的视频文件。问题904具有对应的状态指示符912“未开始”,这意味着候选者102还没有记录和附加相应问题的视频文件。在选择问题904后,数据获取引擎146提供视频捕捉ui屏幕,其为候选者102提供输入界面来记录和链接包含问题响应的视频文件。
65.图10示出了问题输入ui屏幕1000的示例,其中候选者102可以在诸如移动设备、平板电脑、可穿戴设备或膝上型电脑的外部计算设备158处记录面试问题响应。在一些实施方式中,除了记录显示窗口1004之外,数据获取引擎146还在ui屏幕1000中呈现所选择的问题1002,在记录显示窗口1004中,候选者102可以在记录视频响应时看到她自己。在一些示例中,ui屏幕1000还可以包括可视记录指示符1006,其允许候选者查看他们已经用了多少最大记录时间来回答问题。ui屏幕1000还可以包括其他控件,诸如开始/停止记录选择器1008以及结束并将视频文件链接到所选择的问题的选择器。
66.回到图9,问题概要ui屏幕900还可以呈现问题状态指示符914,其指示所链接的视频文件具有一种或多种类型的错误,这些错误使得该文件不适合由视频评估系统108处理。在一些示例中,文件大小错误指示链接的视频文件小于最小文件大小或大于最大文件大小。在一些实施例中,文件格式错误指示链接的视频文件的文件类型不是视频文件或者是与系统108不兼容的文件类型。在一些实施方式中,视频评估系统108还可以在提交之前预处理链接的视频文件,以检测质量错误。
67.在一些示例中,数据质量评估引擎136和/或语音到文本转换引擎134可以对每个上传的视频文件执行一个或多个数据质量测试,以确定是否满足一个或多个数据质量标准。在一个示例中,数据质量评估引擎136执行音频数据可用性测试,包括确定相应视频文件的信噪比,并且语音到文本转换引擎确定语音到文本转录结果的置信度分数。此外,数据质量评估引擎136可以对抄本进行单词计数统计,以确定抄本中是否有足够的数据来产生可靠的结果。在一些示例中,数据质量评估引擎136还可以执行平均(例如,均值或中值)字长测试,以确定候选者102是否试图蒙骗系统108。如果检测到任何质量错误,则可以在问题概要ui屏幕900中的相应问题的状态指示符中显示错误。关于由数据质量评估引擎136执行的质量测试的细节将在下面进一步详细讨论。在一些示例中,响应于当检测到低质量音频或视频时产生数据质量错误,数据获取引擎136还可以在问题概要ui屏幕900和/或问题输入ui屏幕1000中向候选者102提供记录提醒或建议,以提高记录的质量。例如,提醒可以告诉候选者102在具有低背景噪声的安静环境中记录他们的响应,并使用功能良好的麦克风。
68.在将视频文件链接到各个问题902-908中的每一个之后,候选者902可以选择提交选择器918来将面试问题视频文件传输到视频评估系统108。在一些示例中,问题概要ui屏幕900上的提交选择器918不可用于选择,直到视频文件已经链接到每个问题而没有任何检测到的错误。在接受到视频文件时,数据获取引擎146扫描、处理视频文件,并将视频文件作
为候选者视频数据112存储在数据储存库110中。在一些示例中,候选者视频数据112可以是链接到相应候选者102、雇主104和候选者102所申请的相关职位的问题的视频文件的数据结构。在一些实施方式中,数据获取引擎146还可以执行其他类型的预处理,以提高视频评估系统108生成语音到文本抄本的效率。例如,数据获取引擎146可以从每个接收到的视频文件中自动提取音频数据,并将提取的音频数据与其对应的视频一起保存在单独的文件中,作为候选者视频数据112的一部分。
69.回到图1,视频评估系统108还可以包括语音到文本(stt)转换引擎134,其将每个捕捉的视频面试问题的音频数据实时转换成书面文本。在一些实施方式中,stt转换引擎134使用语音到文本服务来执行stt转换。在其他实施例中,也可以将音频数据转换成书面抄本的其他stt服务也可以被语言分类引擎138用来检测用于评估候选者102对于特定职位的适合性的个性方面。在一些实施方式中,stt转换引擎134使用机器学习算法来组合语法、语言结构以及音频和语音信号的组成的知识,以准确地转录所接收的面试问题文件中的人类语音。在一些实施例中,stt转换引擎134可以通过应用宽带或窄带模型来处理不同质量和采样率的一系列音频文件格式。在一些实施方式中,由stt转换引擎134生成的面试问题的抄本可以作为抄本数据128存储在数据储存库110中。在一些方面,特定面试问题响应的抄本数据128可以链接到数据储存库110内其对应的候选者视频数据112。
70.在一些实施方式中,人工智能(ai)训练引擎142可以训练stt转换引擎134所使用的机器学习算法,以比其他单词更准确地检测与个性模型500(图5)中的方面相关联的关键词、短语和同义词,这进而提高了被训练来检测个性方面的自然语言分类器的性能。在一些示例中,ai训练引擎142用训练数据124的部分来训练stt算法,训练数据124的部分用于训练由语言分类引擎138用来检测个性方面的自然语言分类器。例如,定制的单词、短语和同义词的训练数据124构成了用于stt算法的定制的词典。在一些示例中,定制词典中的条目被分配了比其他单词更高的识别优先级(权重),使得条目更能防止遗漏检测。在一个示例中,用于训练stt算法的定制词典包括超过16,000个单词和短语以及与每个条目相关联的同义词。在一些示例中,可以通过用一个或多个语言模型数据集和/或声学模型数据集进行训练来进一步定制stt算法。在一些实施方式中,语言模型可以被训练来检测与每个个性方面相关联的关键词的替换单词和短语。在一些实施例中,声学模型可以用声学数据来训练,以便能够区分单词的不同类型的发音和口音。
71.在一些实施方式中,stt转换引擎134所使用的stt算法可以被配置为基于所计算的抄本的置信度分数来确定stt抄本质量。在一些示例中,stt转换引擎134计算每个单词和每个最终抄本的置信度分数。在一些实施例中,置信度分数指示stt算法对给定抄本准确到其所基于的音频信息的估计。在一个示例中,置信度分数的范围从0.0到1.0(或0到100%),其中1.0(100%)表示当前抄本反映了最可能的结果。在一些实施方式中,可以执行附加的人工质量评估,以确保stt算法满足等效的人为错误标准。此外,计算出的单词错误率与stt算法计算出的置信度分数具有大约0.73的相关性,表明计算出的置信度分数可以用作单词错误率和抄本准确性的度量。在一些实施方式中,当置信度分数小于0.65时,stt转换引擎134生成面试问题抄本的质量错误。
72.在一些实施例中,视频评估系统108还可以包括ai训练引擎142,其将训练数据应用于由stt转换引擎134和语言分类引擎138使用的机器学习算法。例如,ai训练引擎142使
用定制的训练数据集124来训练由语言分类引擎138用来检测个性模型(例如,图5中的个性模型500)的正面和负面的自然语言分类器。在一些示例中,系统108可以使用检测到的正面和负面方面指示符的实例来评估候选者在空缺职位的一个或多个能力方面出类拔萃的资质。在一些实施方式中,训练数据集124可以包括关键词、短语和其他同义词,其可以指示与个性模型500相关联的正面和负面个性方面。这些训练数据集124可以应用于如上所述的stt转换引擎134以及语言分类引擎138的机器学习算法。在一些示例中,ai训练引擎142可以用相应语言的训练数据集来训练多个自然语言分类器。因此,视频评估系统108可以适应以任何可检测语言提交的候选者面试响应。
73.在一些实施例中,训练数据集124还可以包括由人工评级人应用的面试抄本和相关联的个性方面评级。在一些方面,人工评级数据与来自自然语言分类器的评级数据相结合。在一些示例中,人工评级数据和分类器评级数据的比较被反馈到语言分类引擎138的自然语言分类器中作为训练数据124。在某些情况下,非常高的分数(例如,在1到5的范围内大于4.5)和非常低的分数(例如,在1到5的范围内小于1.5)的比较数据也包括为什么评级人给候选者如此高或如此低的分数的原因。这些分数基本原理叙述可以与人类和自然语言分类器分数之间的比较数据相结合,作为用于训练自然语言分类器的训练数据集124的一部分。
74.在一些实施方式中,训练数据集124还可以包括与特定个性方面相关联的完整短语或句子,而不是仅捕捉相应个性方面的核心特征的短短语或除此之外的短语。例如,在训练数据集124中包括来自面试抄本的整个句子,诸如“当目标对我非常重要时,我专注于实现它”,可以允许自然语言分类器比仅仅短语“专注于实现”更准确地检测“驱动”个性方面的标识符。在一些实施例中,训练数据集124还可以包括描述和解释模型中每个个性方面的叙述。在一些示例中,训练数据集124还可以包括候选受访者所做的陈述,这些陈述强烈预测了特定的个性方面。在一些实施方式中,训练数据集124中的每个数据项可以被标记到相应个性方面。在一些示例中,训练数据集124中的部分项目可以链接到两个或更多个性方面,这进一步提高了自然语言分类器的准确性。
75.此外,从雇主104和/或顾问102接收的关于由系统108计算的能力和个性方面分数的反馈可以作为更新的训练数据集124被连续反馈,该训练数据集124可以用于改进定制的自然语言分类器的性能。在一些示例中,ai训练引擎142持续更新训练数据集124并重新训练自然语言分类器。以这种方式,语言分类引擎138使用的自然语言分类器在检测系统108用来评估候选者面试问题抄本的个性模型的每个个性方面的正面负面极性标识符方面被高度定制。训练数据的这种连续更新提高了自然语言分类器的准确性。
76.图11示出了与“责任心”的个性方面相关联的正面1102和负面1104标识符单词的表格1100。在一些实施方式中,标识符1102、1104是与相应个性方面(在这种情况下为“责任心”)相关联的单词或短语。在一些示例中,正面标识符1102可以对应于相应个性方面的同义词,并且负面标识符可以对应于相应个性方面的反义词。在一些实施方式中,标识符1102、1104可以被包括作为训练数据集124的一部分,用于训练自然语言分类器来检测面试问题抄本中的责任心指示符。例如,责任心1102的正面极性标识符可以包括诸如“有组织的”、“精确的”、“负责的”、“彻底的”、“有效的”、“有序的”、“自律的”、“实用的”、“系统的”和“可靠的”等术语。在一个示例中,责任心1104的负面极性标识符可以包括诸如“无序的”、“粗心的”、“低效的”、“不切实际的”、“不可靠的”、“不一致”、“不可依赖的”、“无目的的”、“不合逻辑的”和“草率的”的术语。个性模型的其他方面还可以包括多组相应正面和负面指示符,ai训练引擎142可以使用这些指示符来训练语言分类引擎138所使用的自然语言分类器。
77.回到图1,在一些实施例中,视频评估系统108还可以包括语言分类引擎138,其由ai训练引擎142训练以检测候选者102提交的面试问题抄本中的个性方面标识符。在一些示例中,语言分类引擎138使用商业自然语言分类器,诸如ibm watson、google cloud speech或amazon polly,其已经被专门训练来检测面试问题抄本中的个性方面。在其他示例中,语言分类引擎138使用定制的、专有的自然语言分类器。在一些实施方式中,语言分类引擎138访问由stt转换引擎134生成的抄本数据128,并将抄本数据128作为输入提供给经训练的自然语言分类器。在一些实施方式中,语言分类引擎138可以检测采访抄本的语言,并将抄本应用于该语言的相应自然语言分类器。
78.例如,图12示出了作为输入提供给自然语言分类器的面试问题抄本1200。在该示例中,抄本包括对问题的响应,该问题要求候选者讨论他或她在团队环境中操作的时间。图12还示出了由自然语言分类器检测并输出的突出显示的正面和负面个性方面标识符1202-1226。在一些实施例中,自然语言分类器输出映射到相应面试问题的个性方面的标识符(例如,图8中的问题-方面映射800)。在其他示例中,自然语言分类器输出所有检测到的个性方面,无论它们是否与相应问题相关联。如图12所示,自然语言分类器输出与“面向团队”方面相关联的标识符1202-1210,与“富有同情心”方面相关联的标识符1212-1218,以及与“谦逊”方面相关联的标识符1220-1226。
79.在一些实施例中,语言分类引擎138的自然语言分类器基于相应标识符是与个性方面的正面特征还是负面特征相关联,向每个检测到的标识符分配正面极性或负面极性。例如,在图12中,标识符1202(“第一步是讨论(first step was to discuss)”)、1204(“对齐我们的想法(align our ideas)”)、1206(“民主过程(democratic process)”)和1208(“内部平等(equality within)”)是“面向团队”或“合作”的个性方面的正面标识符,而标识符1210(“独立地在我们的每个部分操作(worked on each of our segments independently)”)是“面向团队”的负面标识符。对于“富有同情心”或“敏感”的个性方面,正面标识符包括标识符1212(“兴趣和专长领域(areas of interest and expertise)”)、1214(“关于你的团队成员的信息(information about your team members)”)和1216(“我非常喜欢的(that i quite liked)”),负面标识符包括标识符1218(“我最感兴趣的部分(part that i was most interested)”)。对于“谦逊”方面,正面标识符包括标识符1220(“我不想(i did not want to)”)和1226(“不想大惊小怪(did not want to make a fuss)”),负面标识符包括标识符1222(“带头(take the lead)”)和1224(“我没有(i did not)”)。在一些实施方式中,由自然语言分类器检测的这些检测到的正面和负面标识符1202-1226可以被候选者分数引擎用来计算每个方面、能力和面试问题的候选者分数。
80.在一些实施例中,语言分类引擎138基于每个标识符所关联的个性方面将检测到的个性方面1202-1226组织成组。例如,图13示出了由面试问题抄本1200的方面以及每个方面与问题的相关性1308-1312组织的标识符分组1302-1306的集合1300。例如,对于“面向团队”或“合作”方面1302,标识符1202-1210被分组在一起,对于“富有同情心”或“敏感”方面
1304,标识符1212-1218被分组在一起,对于“谦逊”方面1306,标识符1220-1226被分组在一起。在一些实施方式中,语言分类引擎138将标识符分组1302-1306作为方面标识符分组数据126存储在数据储存库110中。在一些示例中,与特定候选者102相关联的每个面试问题的标识符分组数据126在数据存储库110内彼此链接或关联。
81.回到图1,在一些实施方式中,视频评估系统108还可以包括候选者分数引擎140,其为向系统108提交对一组面试问题的响应的候选者102计算每个问题和每次面试的每个方面的分数。在一些示例中,所计算的分数可以考虑每个方面的正面和负面指示符的相对数量、每个问题的stt抄本的准确性的置信度、面试抄本中每个个性方面的原始证据的数量以及每个个性方面与每个面试问题的相关性。在一些示例中,对于每次面试在标识符分组数据126中评估的每个个性方面,候选者分数引擎140使用等式ind=(pind
–
nind)(1/3)计算每个方面的指示分数,其中ind表示个性方面的指示分数,pind表示正面标识符的数量,并且nind表示负面标识符的数量。例如,对于图13中的“敏感”标识符分组1304,pind是3,并且nind是1。在一些示例中,指示值ind用于使用等式sq=ind
–
((((1-pind)*relevance)2)*(1
–
(abs(ind)))来计算每个问题的分数(sq),其中相关性(relevance)是个性方面与问题的相关性,其可以从职位的问题映射数据120中获得。在一些实施方式中,基于问题响应内映射的个性方面的检测的实例,为个性方面计算能力分数。可以根据等式性方面的检测的实例,为个性方面计算能力分数。可以根据等式计算问题的每个能力分数(competency score),这确保了具有更多证据的方面分数在能力分数计算中具有更高的权重。在一些示例中,能力分数是在问题级别计算和显示的,并且也可以经由简单的平均计算汇总为面试的总分数。在多个问题衡量单个能力的一些示例中,候选者的总体能力分数可以作为与相应能力相关联的所有问题分数的平均值来计算。在一些示例中,分数也可以被调整以反映一个或多个数据质量指示符(dqi)分数(例如,抄本质量/置信度分数、信息量、可信度或两个或更多dqi的合计),使得具有最高质量和信息量的问题响应比具有较低质量分数的其他响应接收更高的分数。
82.在一些示例中,候选者分数引擎140还可以使用等式re=pind ((1
–
pind)*nind)来计算每个方面和问题的原始证据分数re。在一些示例中,原始证据分数re指示候选者102为每个面试问题的每个方面提供了多少信息。图14示出了不同pind、nind和相关性值的re和sq分数的表格1400。图14所示的示例代表极端示例的边界情况,其中自然语言分类器没有检测到标识符,或者只检测到负面标识符。对于问题1402,其中pind是0,nind是0,相关性是0,sq是0,并且re也是0。在一些示例中,分数0表示范围从-1到1的平均值或中间值。这意味着,对于为问题分配的相关性为0且未被触发的个性特征,分数sq保持为0。对于问题1404,其中pind是0,nind是0,相关性是1,sq是-1,并且re是1。这意味着如果一个方面是相关的(例如,相关性分数为1),但是自然语言分类器没有检测到任何指示,则分数sq为0。对于问题1406,其中pind是0,nind是1,相关性是0,sq是-1,并且是1。这意味着,如果一个方面的分配相关性为0,但有一个负面的指示,那么该方面的分数sq为-1。对于问题1408,其中pind是0,nind是1,相关性是1,sq是-1,并且re是1。这意味着,如果个性方面是相关的,并且自然语言分类器检测到负面标识符,则该方面的分数sq是-1。
83.回到图1,在一些实施方式中,候选者分数引擎可以使用原始证据分数re、正面标
识符pind以及该方面与问题的相关性,来使用等式es=re ((1
–
re)*(1
–
pind)*relevance)计算分数的置信度分数es。在一些示例中,置信度分数es提供了关于相应问题的分数准确性的确定性的度量。例如,如果问题的个性方面的相关性高,但是候选者102提供了很少或没有提供与该方面相关的信息,则置信度分数es降低该方面的总问题分数(tsq)。即使方面与特定问题几乎没有相关性,候选者分数引擎140仍然可以计算该方面的原始证据分数re和置信度分数es。
84.在一些实施方式中,使用每个问题的置信度分数es,候选者分数引擎140可以计算包括多个面试问题的整个面试的每个方面的总置信度(tes)。在一些示例中,候选者分数引擎根据等式tes=(∑
qx=1
es
x
)/q来计算tes,其中q表示面试中的问题数量。在一些实施例中,tes可以被计算为独立于面试中的问题数量的每个个性方面的绝对置信度。绝对tes可以根据等式tes=(∑
qx=1
es
x
)来计算。
85.此外,候选者分数引擎140可以从所有问题级方面分数(sq)和置信度分数计算每个方面的总分数(tsq)。在一些示例中,相对于置信度分数来计算tsq,以便说明候选者102已经提供了多少与每个个性方面相关的信息。例如,可以根据等式tsq=(∑
qx=1sqx
)*es
x
/(∑
qx=1
es
x
)计算tsq。在一些实施方式中,所有分数信息(例如,pind、nind、ind、re、sq、es、tes、tsq)可以作为候选者分数数据129存储在数据储存库110中。
86.在一些实施方式中,候选者分数引擎140可以使用每个问题每个方面的计算分数sq和每个方面的总分数tsq来计算空缺职位的每个雇主识别的能力的分数。在一些实施方式中,候选者分数引擎140可以访问职位的问题映射数据120(例如,图8中的问题-方面映射表800和图7中的能力-方面映射表700),并且可以将每个方面的计算分数转换为每个能力的分数。在一些示例中,每个能力的分数也可以作为候选者分数数据129存储在数据储存库110中。
87.在一些实施例中,候选者分数引擎140还可以根据一个或多个分数标准将申请空缺职位的每个候选者102相对于其他候选者进行排名。在一些示例中,候选者分数引擎140可以生成总面试排名,其中候选者102基于每个方面的总分数(tsq)被排名,这也可以考虑每个方面的总置信度(tes)。候选者102也可以基于计算的能力分数来排名。此外,候选者分数引擎140可以使用分数sq对每个方面和每个问题的候选者102进行排名。因为视频评估系统108独立于其他候选者执行自动候选者评估,并且没有将任何主观偏见插入到评估和排名过程中,所以候选者分数引擎140能够在接收到面试问题响应提交时实时对候选者102进行排名。使用人类评估员和评级人的面试方法不能执行这种实时评估,因为人类不能不带任何主观偏见地评估候选者,并且不能在评估过程中插入比较假设。由候选者分数引擎140生成的排名也可以作为候选者存储数据129存储在数据储存库110中。在一些示例中,当用于接收工作申请提交的预定时间框架已经过去时,候选者分数引擎140可以将候选者分数和排名数据传递给报告和反馈引擎152,用于处理和呈现给雇主104。
88.在一些实施方式中,基于给定候选者102的分数tsq和sq,候选者分数引擎140可以识别候选者102可能非常适合同一雇主104或已经向系统108提交了雇主职位数据114的另一雇主104的一个或多个其他空缺职位。例如,如果候选者102已经提交了数据分析师职位的面试问题响应,但是对于面向领导的方面具有非常高的方面分数(例如,个性模型500中社交大胆和外向的交互风格508的高分数),则候选者分数引擎140可以识别社交大胆和外
向的交互风格与该职位高度相关的一个或多个职位。在一些示例中,这些附加的职位建议可以由报告和反馈引擎152经由一个或多个ui屏幕提供给候选者102和/或雇主104。在一些实施方式中,即使职位当前没有被广告为可用,候选者分数引擎140也可以向雇主104建议候选者102的先前广告的职位,以防雇主104寻求在将来为申请使该职位空缺。
89.在一些示例中,“正面”的个性方面不一定意味着“好”或“最好”,并且“负面”的个性方面不一定意味着“坏”或“最差”。相反,个性方面的正面或负面可能反而表明个性方面在范围上的相对位置。例如,对于“灵活性”的个性方面,该方面的高分数(例如,在1到5的标度上的4或5)可以指示候选者102能够容易地适应改变的情况并且在非结构化环境中表现出色。另一方面,“灵活性”的个性方面的低分数(例如,在1到5的范围内的1或2)可以指示候选者102在要求严格遵守程序和准则的结构化环境中表现出色。例如,对于数据分析师或核电站操作员职位,灵活性分数较低的候选者可能是理想的人选。因此,对于这些类型的职位,灵活性方面分数较低的候选者可能比灵活性分数较高的候选者排名更高。
90.在一些实施方式中,视频评估系统108还可以包括数据质量评估引擎136,其可以分析由stt转换引擎134生成的面试问题抄本,以检测抄本质量问题和潜在的欺诈性提交。如上所述,在一些示例中,数据质量评估引擎136和/或语音到文本转换引擎134可以对每个上传的视频文件执行一个或多个数据质量测试,以确定是否满足数据质量标准。在一些示例中,一个或多个数据质量测试可被组合成称为数据质量指示符(dqi)的单个分数,该分数可用于自动触发计算机生成的对候选者的另一响应的请求。在一个示例中,数据质量评估引擎136执行音频数据可用性测试以确定抄本质量,包括确定相应视频文件的信噪比,并且stt转换引擎134确定语音到文本抄本结果的置信度分数。在其他示例中,数据质量评估引擎136可以代替stt转换引擎134或者除了其之外执行置信度分数确定。如上所述,置信度分数对应于反映近似单词错误率的抄本的准确度分数。在一些示例中,置信度分数可以被称为抄本质量分数,其是纳入dqi的分数之一。在一些示例中,可以应用多个阈值来指示抄本质量是否落入一个或多个分数级别(例如,“红色”、“黄色”、“绿色”,如下面进一步讨论的)。例如,大于60(0.6分数值)的置信度分数可能落入“绿色”分数区,从50到60(0.5到0.6分数值)的置信度分数可能落入“黄色”分数区,而小于50(0.5分数值)的置信度分数可能落入“红色”分数区。
91.此外,数据质量评估引擎136可以执行附加的数据质量测试,包括对由stt转换引擎134生成的抄本的分析,以检测候选者102试图通过提交获得人为高分数的面试响应来“欺骗”系统108的情况。在一些实例中,当候选者102猜测候选者分数引擎140应用的分数规则时,这可能发生。例如,候选者102可能试图欺骗系统108的一种方式是通过陈述候选者102认为指示期望的特征和分数的某些关键词。在一些示例中,这种类型的蒙骗试图会导致候选者102使用断断续续的、不自然的语音模式。因为面试问题可以提示候选者102提供具有完整句子的令人满意的响应,并且在单个问题响应中谈论不同的主题,所以数据质量评估引擎136可以被配置为检测问题抄本中的自然语音模式的证据。
92.在一个示例中,数据质量引擎136测量面试问题抄本的总单词计数,以确定测量抄本中信息量的分数。在一些示例中,数据质量引擎136为每个问题生成信息量分数,该分数是纳入dqi确定的测试之一。在一个示例中,如果抄本的单词计数小于预定阈值,诸如185个字,则数据质量评估引擎136可以向候选者102和/或雇主104输出已经检测到单词计数质量
错误的警告或通知。在其他示例中,可以应用多个阈值来指示信息量是否落入一个或多个分数级别(例如,“红色”、“黄色”、“绿色”,如下面进一步讨论的)。例如,具有超过130个单词的抄本可能落入“绿色”分数区域,具有80到130个单词的抄本可能落入“黄色”分数区域,而具有少于80个单词的抄本可能落入“红色”区域。在一些示例中,候选者102可能试图通过仅仅连续陈述与相应面试问题相关联的某些关键词来蒙骗系统108。例如,候选者102可以列举他/她认为指示该职位的理想候选者的特征的关键词。这可能导致非对话性的短且不连贯的响应,这可能被指示为问题单词计数少于预定阈值。在一些示例中,即使候选者102没有试图蒙骗系统108,单词计数少于预定阈值的问题抄本可能缺少足够的信息以供视频评估系统108检测足够的个性方面特征来计算问题的可靠分数。
93.在一些实施方式中,数据质量评估引擎136还可以基于面试问题抄本的平均单词长度(例如,均值或中值单词长度)来检测诚实和不诚实的面试问题响应。在一些示例中,对包括几个完整句子和自然语音模式的问题的候选者响应可以具有每个单词大约4.79个字符的平均单词长度。在一些实施例中,显著大于或小于该类型问题的典型单词长度的平均单词长度可以指示候选者102没有提供令人满意的响应,并且可能试图蒙骗系统。在一个示例中,如果问题抄本的平均单词长度少于3个字符或多于8个字符,则质量评估引擎136可以生成质量错误通知。例如,当候选者102试图通过连续使用某些关键词而不是以完整的句子说话来蒙骗系统108时,响应的平均字符长度可能大于最大单词长度阈值,因为他没有散布作为完整句子一部分的较短的冠词、连词和介词。在其他示例中,可以使用其他阈值来指示抄本的平均单词长度是否落入一个或多个分数级别(例如,“红”、“黄”、“绿”,如下面进一步讨论的)。例如,3到5个字母的平均单词长度可能落入“绿色”分数区,2.5到3个字母和5到6个字母的平均单词长度可能落入“黄色”分数区,小于2.5或大于6个字母的平均单词长度可能落入“红色”分数区。
94.在一些实施方式中,数据质量评估引擎136还可以基于问题中特定关键短语的重复使用来检测响应中的可信度错误,这可以指示候选者102试图提交对面试问题的欺诈性响应。在一个示例中,数据质量评估引擎136可以检测到短语“我是”(i am)、“我为”(i’m)和“我曾经是”的重复使用,这可以指示候选者102试图通过在一组关键词之前放置类似“我是”的短语来掩盖他的欺诈性使用关键词和形容词(例如,“我是负责的”、“我是自信的”)。在一些示例中,在对采访问题的响应中重复使用“我是”的变体(例如,大于预定阈值)可以增加抄本的单词计数,并且还将平均单词长度减少到最大阈值以下。在一些实施例中,当结合单词计数和单词长度测试使用时,应用关键短语检测允许数据质量评估引擎136更准确地检测蒙骗情况。
95.在一些示例中,如果检测到任何单词计数和/或平均单词长度质量错误,也称为可信度错误,则数据质量评估引擎136可以向候选者102、雇主104和/或顾问106输出错误通知。在一些方面,如果向候选者102提供错误通知,则可以向候选者102提供另一个机会来记录对产生错误的问题的面试问题响应。在一些实施方式中,如果在候选者102提交的多于一个的面试问题抄本中检测到一种类型的质量错误(单词计数、单词长度、关键短语),则数据质量评估引擎136可以向候选者102、雇主104和/或顾问106输出质量错误通知。例如,如果四个问题中只有一个与检测到的质量错误相关联,则可能不会产生错误通知,因为该单个错误可能仅指示异常状况,而不是试图蒙骗系统108。然而,如果多个问题检测到质量错误,
则可能产生错误通知。在一些实施方式中,如果检测到一个或多个质量错误,则数据质量评估引擎136可以标记该响应,以供雇主104和/或顾问106进行人工审查。在一些示例中,数据质量评估引擎136可以向审阅者的外部设备输出错误审阅ui屏幕。作为响应,雇主104和/或顾问106可以经由ui屏幕向系统108提供输入,以指示候选者102是否试图在响应中蒙骗系统108。
96.在一些示例中,数据质量评估引擎136可以使用从评论者接收的响应来更新单词计数、单词长度和关键短语阈值。在一些实施方式中,基于来自雇主104和/或顾问106在手动审阅面试成绩单时的响应,数据质量评估引擎136可以针对特定问题和/或候选者102更新和定制一个或多个数据质量测试阈值。例如,如果候选者102已经记录了对小于单词计数阈值的多个面试问题的响应,并且人工审查显示候选者102没有试图欺骗系统108,则该候选者的单词计数阈值可以被降低,因为候选者102可能不像大多数其他候选者102那样冗长。在其他示例中,候选者102还可以从系统108接收警告通知,该警告通知表明持续提交对面试问题的简短响应可能导致较低的分数。在一些示例中,如果大部分候选者对特定面试问题提供了比平均时间更长的响应,则数据质量评估引擎136可以增加单词计数阈值。类似地,对于低于平均问题单词计数的响应,也可以降低单词计数阈值。在一些示例中,每个面试问题可以有它自己的一组质量测试度量(例如,单词计数、单词长度和关键短语度量)。
97.在一些实施方式中,数据质量评估引擎136可以被配置为计算每个问题响应抄本的dqi,其是抄本数据质量的计算机生成的量化。由于候选者提供的面试问题响应没有结构化的格式,并且数据的质量在很大程度上取决于候选者提供的信息,因此dqi提供了一种基于计算机的技术解决方案,可以自动量化候选者的响应,无需人工参与。此外,dqi生成和计算进一步自动化了候选者面试评估和分数,使得除非系统检测到异常,否则人工质量审查变得不必要。
98.在一些实施方式中,dqi基于数据质量的三个度量:抄本质量(置信度分数)、信息量分数和可信度分数。这些度量中的每一个都具有两个或更多个定义的阈值,用于分隔两个或更多个(例如,三个)dqi标记水平(即,红色、黄色或绿色)。在其他示例中,不同的分数方案可以用于dqi(例如,从1到5、1到10或1到100的分数)。在一些示例中,被分配“绿色”dqi分数绿色的响应抄本可以指示抄本具有高质量的数据,并且不需要招聘管理员的进一步动作(即,分数可以被视为可靠和有效)。在一些实施例中,黄色dqi分数可以指示可能的数据质量问题,并且系统108可以输出建议对相应问题响应进行人工审查的通知。如果响应抄本的一个或多个dqi因素(置信度分数、信息量和/或可信度)的dqi分数为红色,则可能存在严重的数据质量问题。当“红色”dqi分数出现时,系统108可以避免生成和/或呈现自动分数,并且可能需要人工审核。由于每个问题响应都提供了dqi分数,招聘人员和/或雇主104可以容易地辨别红色标签是否是例外,这可能暗示技术困难或不可预见的中断,或者面试的整体质量是否保证了更彻底的审查。在一个说明性的示例中,对于问题响应,大约70-80%的dqi分数得到“绿色”分数,而只有大约10%的dqi分数得到“红色”分数,并且需要人工审核,因此极大地减少了与评估过程的人工交互量。在一些示例中,可以使用dqi的一个或多个方面来调整每个问题抄本的分数。例如,对于抄本数据质量、信息量和/或可信度具有“绿色”级别的抄本可用于在正面的或负面的方向上调整计算的问题分数。
99.在一些实施方式中,数据质量评估引擎136生成并呈现每个问题的总体dqi分数,
该分数是置信度分数、信息量分数和可信度分数的组合。在其他示例中,每个dqi保持彼此分离,并且可以单独触发来自候选者102的警告或审查请求或另一响应提交。例如,具有小于50的置信度(抄本质量)分数的任何问题抄本接收最低的dqi分数(例如,“红色”),而不管作为dqi确定的因素的其他数据质量测试的分数。
100.在一些示例中,数据质量评估引擎136可以在向系统108提交完整的一组面试问题响应时或者在问题概要ui屏幕900(图9)处链接每个单独的面试问题响应视频文件时执行质量测试。在一些实施方式中,数据质量评估引擎136可以在问题概要ui屏幕900处链接视频文件时执行数据质量评估测试的部分,并且一旦视频评估系统108已经接收到所有面试问题的视频文件,则执行测试的其余部分。例如,背景噪声和信噪比测试可以在问题概要ui屏幕900处链接视频文件时执行,而其余测试可以在向系统108提交整组视频文件时执行。这样,数据获取引擎146可以立即通知候选者102一个或多个噪声标准未被满足,并且候选者102可以在较低噪声条件下重新记录响应。在一些实施方式中,任何面试问题响应的任何检测到的质量错误可以作为响应质量数据122存储在数据储存库110中。
101.在一些实施例中,视频评估系统108可以包括报告和反馈引擎152,其经由一个或多个ui屏幕向雇主104和/或顾问106提供候选者分数结果。在一些示例中,报告和反馈引擎152可以在ui屏幕中呈现每个问题的个性方面分数,并为雇主104提供输入字段以提供关于分数和响应的反馈。例如,图15示出了报告和反馈ui屏幕1500,其响应于对候选者102提供的每个提交的面试响应的分析和分数而呈现给雇主104的外部设备158。在一些实施方式中,报告和反馈ui屏幕1500可以包括视频回放窗口1510,其允许雇主104查看候选者对面试问题1512的响应。例如,在选择重放窗口1510时,报告和反馈引擎152使得与问题1512相关联的候选者视频数据112播放。在一些实施方式中,ui屏幕1500还可以包括由面试问题1512评估的每个个性方面1502-1506的分数汇总。例如,对于要求候选者描述他们在团队中操作的最近情况的问题1512,ui屏幕1500呈现合作1502、敏感1504和谦逊1506的个性方面的分数汇总。
102.在一些实施例中,个性方面1502-1506的分数概要可以各自包括分数字段1518,其中报告和反馈引擎152呈现由候选者分数引擎计算的问题的方面分数(例如,分数sq)。例如,对于合作分数概况1502,分数字段1518a呈现计算的方面分数3(在1到5的范围内)。此外,敏感分数概要1504的分数字段1518b显示计算的方面分数5,谦逊分数概要1506的分数字段1518c显示计算的方面分数4。在一些实施方式中,个性方面1502-1506的分数字段1518允许雇主104基于对面试响应的视频的人工审查来人工调整问题的方面分数。
103.另外,分数概要1502-1506还可以包括评论输入字段1502,其允许雇主104提供关于计算的分数和/或进行手动分数调整的原因的评论。例如,如果雇主104在分数字段1518b手动降低敏感方面1504的分数,雇主104也可以在评论输入字段1520b提供关于雇主104为什么认为候选者102应该具有较低分数的评论。在一些示例中,如果雇主104手动调整方面分数,则报告和反馈ui屏幕1500可以要求雇主104在评论输入栏提供评论。在其他示例中,报告和反馈ui屏幕1500可以允许雇主104在评论输入字段1520提供评论,而不管分数是否已经在分数字段1518被手动调整。在一些实施例中,ui屏幕1500还可以为每个个性方面分数概要1502-1506提供无评级输入1522,这允许雇主104从候选者评估中手动移除相应方面分数1518。例如,如果雇主104认为个性方面与问题不相关和/或认为候选者102没有提供足
够的信息来评估响应中的个性方面,则雇主104可以选择无评级输入1522。在一些示例中,报告和反馈引擎1512可以锁定分数字段1518、评论字段1520和无评级输入1522的手动调整特征,直到雇主104已经观看了窗口1510中显示的视频。在一些实施方式中,雇主104在ui屏幕1500上提供的任何反馈可以作为反馈数据123存储在数据储存库110中。
104.在一些示例中,每个方面分数概要1502-1506还可以包括分数提示1514、1516,以指导雇主104关于高分数(例如,5)或低分数(例如,1)关于候选者102说了什么。在一些示例中,提示1514、1516可以帮助雇主104确定是否在分数字段1518手动调整分数和/或在评论字段1520提供评论。例如,合作个性方面1502可以包括低分数提示1514a,该低分数提示1514a解释了该方面的低分数意味着候选者“倾向于更加独立,并且通常对团队操作和合作不太感兴趣”。在分数范围的另一端,合作的高分数提示1516a可能意味着候选者“倾向于面向团队和乐于助人,但有时会被利用”。在一些实施方式中,“高”分数和“低”分数不一定表示“好”或“坏”,而是可以仅反映候选者在相应个性方面处于范围的哪一端。
105.在一些实施例中,报告和反馈引擎152可以向雇主104呈现具有附加分数信息的附加ui屏幕。例如,报告和反馈引擎152可以生成ui屏幕,其呈现所有面试问题的每个被评估的个性方面的总分数(tsq)。此外,报告和反馈ui屏幕可以提供与该职位的每个已识别的能力相关的分数和评估信息。在一些示例中,ui屏幕还可以提供申请特定职位的一个或多个候选者102的排名信息。例如,报告和反馈ui屏幕可以包括候选者102与申请该职位的所有其他候选者相比的每个方面的排名和总体排名。在一些示例中,ui屏幕还可以提供关于候选者的分数如何与该职位的历史分数相比较的数据(例如,与雇主102为同一职位聘用的其他时间相比较)。在一些实施方式中,附加的报告和反馈ui屏幕还可以向雇主104提供关于由数据质量评估引擎136检测到的任何数据质量错误的数据。在一些示例中,报告和反馈ui屏幕还可以向雇主104和/或候选者提供关于候选者102可能非常适合的由候选者分数引擎140识别的任何其他职位的信息。
106.此外,由报告和反馈引擎152生成的ui屏幕可以向候选者102提供关于候选者为什么被选择或没有被选择该职位的面试后和选择反馈。例如,报告和反馈引擎152可以使用包括由候选者分数引擎140生成的排名信息的候选者分数数据129以及由雇主104在ui屏幕1500提供的反馈数据123来生成净化的候选者报告概况。在一些实施方式中,生成净化的候选者报告概况可以包括将雇主104提供的任何过度负面的评论转换成稍微更正面的语言,该语言仍然传达给候选者102他有改进的空间。例如,如果雇主已经在敏感方面1504的评论输入字段1520b中提供了评论,指示候选者102看起来“粗鲁且不体贴”,则报告和反馈引擎152可以在候选者报告概况中提供关于如何提高候选者的敏感方面的提示和建议。
107.在一些实施方式中,每个面试问题的抄本、问题映射数据、计算出的分数和接收到的关于分数的反馈(例如,分数字段1518处的调整后的分数、评论输入字段1520处的评论和无评级输入1522)可以被添加到训练数据集124,该训练数据集124由ai训练引擎142在训练语言分类引擎138的自然语言分类器和/或stt转换引擎134的stt算法时使用。
108.回到图1,在一些实施方式中,视频评估引擎108还可以包括数据编排引擎150,其控制用于执行系统操作的处理资源的供应、分配和指派。在一些实施例中,由处理引擎130-152中的每一个执行的过程可以从各种基于云和非基于云的处理资源和/或数据存储资源中执行。在一些示例中,编排引擎150协调与接收、处理和分析候选问题响应视频相关联的
数据处理请求的划分;识别与分配给每个处理请求相关联的可用处理资源;管理从处理资源获得的结果的接收和组织;并协调向雇主104呈现候选者评估信息。在一些实施方式中,由数据编排引擎150执行的功能和数据编排引擎150控制的数据架构的结构提高了视频评估系统108的整体处理效率。在一些示例中,与数据编排引擎150对操作和处理任务的编排相关联的数据可以作为编排数据131存储在数据储存库110中。
109.图17a示出了视频评估系统108的数据架构和编排结构1700。在一些实施方式中,数据编排结构1700包括编排器1706,该编排器1706组织系统108的所有处理操作,并确定如何分配处理资源和激活处理步骤以有效地生成候选者视频评估。在一些实施例中,当系统108接收到包含候选者102的面试问题响应的一个或多个视频文件时,用于处理视频面试文件的操作请求作为ai请求1702经由初始化器1714被发送到编排器1706。在一些示例中,初始化器1714启动用于在编排器1706处处理视频文件的一组操作。
110.在一些实施例中,数据编排结构1700可以包括功能目录1708,其中处理资源或服务可以通告它们的存在、健康、位置和配置选项。在一些示例中,处理资源和服务可以包括现成的处理资源,诸如microsoft azure和/或amazon aws处理资源以及其他本地和区域性处理资源。在一些实施方式中,当编排器1706试图将资源分配给特定处理任务时,编排器1706查看功能目录1708以检索可用服务的服务端点、位置和其他识别信息。在完成视频面试处理任务时,编排器1706可以编译和组织所有处理过的数据,从而可以在提交一组视频面试文件时实时呈现给系统用户(例如,候选者102、雇主104和/或顾问106)。在一些示例中,由视频评估系统108的后处理器1712生成的一组编译结果对应于数据编排结构1700中的ai响应1704。在一些示例中,编排器1706、功能目录1708和处理服务可以使用诸如kubernetes的容器管理系统来容器化。
111.在一些实施例中,在编排器1706指派服务来处理候选者视频评估过程的一个或多个步骤时,该服务与关联于数据存储1710的数据代理通信,以获得执行一个或多个所指派的步骤所需的任何数据,并且在处理任务完成时向其相应数据代理提供任何结果和输出数据。在一些示例中,数据存储1710对应于图1中的数据储存库110。在一些方面,与数据存储器1710相关联的每个数据代理知道服务执行分配的任务所需的数据的存储位置,使得处理服务不必执行任何数据获取和/或存储操作。
112.在一些实施方式中,由所分配的服务执行的处理操作可以被分组为与视频评估系统108相关联的不同类型的步骤1742。例如,步骤1742可以包括将接收到的视频文件转换成用于处理的预定格式的视频转换器1724、用于从视频文件中提取音频数据的视频分割器1726、以及用于将提取的音频文件转换成用于处理的预定格式的音频转换器1728。步骤1742还可以包括stt代理和标准化器1730,标准化器1730管理用于通过经训练的stt转换算法生成面试问题抄本的stt转换过程。在一些示例中,stt代理和标准化器1730控制与视频评估系统108中的stt转换引擎134(图1)相关联的处理的性能。在一些实施方式中,stt代理和规范器1730可以访问一组操作者模块或功能1736,这些操作者模块或功能1736为所分配的处理服务转换、处理和/或发送数据。在一些实施方式中,stt代理和标准化器1730还通过第二数据代理层1716向stt应用编程接口(api)1718传送一组stt子步骤,该api 1718与被训练来将从视频面试文件提取的音频数据转换成面试问题抄本的stt服务接口。
113.数据编排结构1700的步骤1742还可以包括自然语言分类器代理和标准化器1734,
其控制与系统108的语言分类引擎138和ai训练引擎142(图1)相关联的过程的性能。在一些示例中,自然语言分类器和代理1734被配置为检测面试问题抄本中的个性方面标识符,这些标识符可用于评估候选者102有多适合空缺职位。在一些实施例中,自然语言分类器代理和标准化器1734可以具有一组操作者模块或功能1740,其为所分配的处理服务转换、处理和/或发送数据。在一些实施方式中,自然语言分类器代理和标准化器1734还通过第二数据代理层1716向语言分类api 1722传送一组语言分类子步骤,该语言分类api 1722与被训练来检测面试问题抄本中的个性方面的自然语言分类服务接口。
114.在一些示例中,数据编排结构1700的步骤1742还可以包括个性洞察代理和规范器1732,其被配置为执行与数据质量评估引擎136、候选者分数引擎140和/或报告和反馈引擎152相关联的功能。例如,个性洞察代理和标准化器1732可以执行一个或多个数据质量测试(例如,抄本单词计数、平均字符长度、关键短语使用),计算每个问题和面试的个性方面分数,并生成候选者报告信息供雇主104审查。在一些实施例中,个性洞察代理和规范器1732可以具有一组操作者模块或功能1738,其为所分配的处理服务转换、处理和/或发送数据。在一些实施方式中,个性洞察代理和标准化器1732还通过第二数据代理层1716向个性洞察api 1720传送一组语言分类子步骤,个性洞察api 1720可以被配置为执行与计算候选者个性方面分数和配置分数以呈现给雇主104相关联的一个或多个任务。
115.在一些实施方式中,由执行一个或多个处理步骤1742(例如,步骤1724-1740)和/或子步骤1718-1722的每个处理服务生成的处理可以由数据代理层1710存储,并被传送回编排器1706,用于链接、组织和准备由后处理器1712呈现。在一些示例中,准备呈现给雇主104、候选者102和/或顾问106的输出由后处理器1712输出作为ai响应1704。另外,当每个处理服务完成其分配的任务时,相应服务信息被添加到功能目录1708,作为可用于任务分配的服务。
116.转向图17b,示出了视频评估系统108的示例数据架构和操作流程。在一些实施方式中,系统用户(例如,候选者102、雇主104和/或顾问106)通过web api 1744与视频评估系统108交互。在一些示例中,当候选者102在web api 1744处向系统108提交一组面试问题响应视频时,在编排器1746处为操作初始化数据管道。在一些示例中,当候选者经由系统ui屏幕提交一组面试视频文件时,在通知服务1762处注册对应的url,该通知服务1762被配置为在由编排器1762触发时向外部系统组件(例如,系统前端)发送系统通知。在一些实施例中,数据流水线包括由编排器1746监控的一组属性,该组属性可以包括流水线标识(id)、状态(例如,排队、运行、完成)、当前操作号、结果url(将结果推到哪里)、以及流水线的配置信息。在一些示例中,数据流水线的属性可以由数据代理存储和/或存储在与系统108相关联的数据存储区域(例如,图1的数据储存库110中的编排数据131)中。
117.在一些示例中,在初始化数据流水线时,编排器1746还可以初始化与web api 1744的url相关联的操作1746。在一些示例中,操作包括一组处理任务,这些处理任务与处理视频文件、使用stt转换算法生成面试问题抄本、使用经训练的自然语言分类器检测面试抄本中的个性方面、基于检测到的个性方面对面试问题抄本进行打分以及根据计算出的分数生成候选者评估报告相关联。在一些示例中,操作的属性可以包括对应的流水线id、操作号、数据类型(例如,自然语言分类器、音频、转录等)。在一些示例中,操作的属性可以由数据代理存储和/或存储在与系统108相关联的数据存储区域(例如,图1的数据储存库110中
的编排数据131)中。在一些实施方式中,编排数据131还可以包括操作配置数据,该操作配置数据可以包括关于与特定操作相关联的任务的信息。例如,操作配置数据可以包括操作号、数据源(例如,自然语言分类器、音频等)、操作者/操作步骤(例如,翻译、抄本等)、以及配置数据(例如,处理特定于任务的服务配置数据)。
118.在一些示例中,当编排器1746开始向操作分配处理资源时,在编排器1746、操作开始消息总线1750和操作完成消息总线1748之间发起和交换消息。在一些示例中,编排器1746可以发送和/或接收来自一个或多个工作者处理节点的消息,这些工作者处理节点执行与处理接收到的面试视频文件相关联的一个或多个任务。在一些示例中,工作者处理节点可以包括自然语言分类器节点1752和转录节点1752。自然语言分类器节点1752可以被配置为执行与检测面试问题抄本中的个性方面相关联的一个或多个过程。在一些实施例中,自然语言分类器节点1752可以与机器学习服务1758通信,机器学习服务1758已经被专门训练来检测面试问题抄本中的个性方面。在一些方面,机器学习服务1758可以被配置为执行与对操作候选者面试进行视频评估相关联的多于一种类型的机器学习算法(例如,自然语言分类、语音到文本转换)。在一些示例中,自然语言分类器节点1752可以将分类器训练数据应用于机器学习服务1758,向机器学习服务1758提供面试问题抄本,并处理接收到的个性方面检测结果。
119.在一些实施方式中,工作者处理节点还可以包括转录节点1754,转录节点1754可以被配置为执行与从接收到的候选者视频文件生成面试问题转录本相关联的一个或多个过程。在一些实施例中,转录节点1754还可以与机器学习服务1758通信,机器学习服务1758已经被专门训练来执行语音到文本转录,其中可以比其他单词和短语更准确地检测与个性方面相关联的单词和短语。在一些示例中,转录节点1754可以将stt训练数据应用于机器学习服务1758,向机器学习服务1758提供音频数据,并处理接收到的面试问题抄本。在一些实施方式中,由机器学习服务1758生成的stt转换结果可以经由服务连接节点1756被传输到转录节点1754。
120.在一些示例中,在完成处理操作或任务时,操作者节点1752、1754可以将处理结果传输到完成操作消息总线1748。在一些实施方式中,完成操作消息总线1748可以作为后处理节点来操作,该后处理节点链接、组织和准备视频面试评估结果,以便在被传输到编排器1746之前呈现给雇主104、候选者102和/或顾问106。当处理操作完成时(例如,候选者面试问题抄本已经被生成、处理和打分),在一些示例中,编排器1746通知通知服务节点1762,通知服务节点1762又通知外部计算系统和/或系统用户。此外,当处理操作的流水线完成时,编排器1746还可以通知结果数据服务1760,结果数据服务1760生成呈现给系统用户(例如,候选者102、雇主104和/或顾问106)的结果。
121.图17c示出了视频评估系统108的另一示例数据架构。在一些示例中,当候选者102向系统108提交一组面试问题响应视频时,在编排器1768处为操作初始化数据管道。在一些实施方式中,编排器1768将与每个数据流水线相关联的信息(例如,流水线标识、状态(例如,排队、运行、完成)、当前操作号、结果url、配置识别信息)存储到流水线数据库1770。另外,对于每个数据流水线初始化,编排器1768还可以初始化包括一个或多个处理任务的一组操作。在一些示例中,与每组操作相关联的数据可以存储在操作数据库1796中。为操作数据库1796中的每个操作存储的数据可以包括流水线标识、操作号、数据类型(例如,自然语
言分类器、音频、转录)以及数据/有效载荷信息。在一些方面,操作数据还可以包括配置信息,例如操作号、数据源(例如,自然语言分类器、音频、转录)、操作者/操作步骤(例如,翻译、转录)以及操作特定的配置。在一些实施例中,存储在操作数据库1796中的数据可以由数据代理1784、1786、1788访问,以传输到接收器处理节点1790、1792、1794。
122.在一些示例中,当编排器1768开始向操作分配处理资源时,在编排器1768、操作开始消息总线1772、数据传输消息总线1774和操作完成消息总线1776之间发起和交换消息。在一些实施方式中,当针对数据流水线初始化一组处理操作时,编排器1768可以向开始操作消息总线1772发送消息,以生成数据访问消息,用于传输到数据代理1784、1786、1788,以开始收集由工作者处理节点1790、1792、1794使用的数据。在一些实施例中,数据代理可以包括访问提取的音频数据的音频数据代理1784、访问面试问题抄本的抄本数据代理1786和访问最后生成的视频评估结果以准备和呈现给系统用户的最后结果数据代理1768。数据代理1784、1786、1788中的每一个将与处理任务相关联的任何被访问的数据传输到数据传输消息总线1774,数据传输消息总线1774又将具有用于处理的数据的消息传输到相应工作者处理节点1790、1792、1794。
123.在一些示例中,数据传输消息总线1774发送和/或接收来自一个或多个工作者处理节点1790、1792、1794的消息,这些工作者处理节点执行与处理接收到的采访视频文件相关联的一个或多个任务。在一些示例中,工作者处理节点可以包括自然语言分类器节点1790、转录节点1792和结果生成节点1794。自然语言分类器节点1790可以被配置为执行与检测面试问题抄本中的个性方面相关联的一个或多个过程。在一些实施例中,自然语言分类器节点1790可以与机器学习服务1782通信,机器学习服务1782已经被专门训练来检测面试问题抄本中的个性方面。在一些方面,机器学习服务1782可以被配置为执行与对操作候选者面试进行视频评估相关联的多于一种类型的机器学习算法(例如,自然语言分类、语音到文本转换)。在一些示例中,自然语言分类器节点1790可以将分类器训练数据应用于机器学习服务1782,向机器学习服务1782提供面试问题抄本,并处理接收到的个性方面检测结果。
124.在一些实施方式中,工作者处理节点还可以包括转录节点1792,转录节点1792可以被配置为执行与从接收到的候选者视频文件生成面试问题转录本相关联的一个或多个过程。在一些实施例中,转录节点1792还可以与机器学习服务1782通信,机器学习服务1782已经被专门训练来执行语音到文本转录,其中可以比其他单词和短语更准确地检测与个性方面相关联的单词和短语。在一些示例中,转录节点1792可以将stt训练数据应用于机器学习服务1782,向机器学习服务1782提供音频数据,并处理接收到的面试问题抄本。
125.在一些示例中,在完成处理操作或任务时,操作者节点1790、1792和/或机器学习服务1782可以经由数据接收器节点1780将处理结果传输到完成操作消息总线1776。在一些实施方式中,完成操作消息总线1776和/或接收器节点1780可以作为一个或多个后处理节点来操作,该后处理节点链接、组织和准备视频面试评估结果以呈现给雇主104、候选者102和/或顾问106。当处理操作完成时(例如,已经生成、处理和打分了候选者面试问题抄本),在一些示例中,编排器1768生成通知开始操作消息总线1772,以通知结果生成数据代理1788访问评估结果数据以呈现给系统用户。在一些示例中,结果生成数据代理1788将所访问的结果数据传输到数据传输消息总线1774,数据传输消息总线1774通知结果生成操作者
节点1794准备视频面试评估结果以呈现给用户(例如,候选者102、雇主104和/或顾问106)。在一些实施方式中,结果生成操作者节点1794可以执行候选者个性方面分数计算、排名和评估,并准备计算的结果以在一个或多个用户界面屏幕上呈现。
126.在一些实施例中,图17b和图17c中所示的操作流1742和1766的组件(例如,编排器、数据代理、消息总线、操作者节点等)可以通过以预定格式配置的消息相互通信。在一些示例中,生成的消息可以在一个或多个消息总线(例如,开始操作消息总线、操作完成消息总线、数据传输消息总线)的消息队列中维护。还可以为系统组件之间的直接通信维护消息队列(例如,在操作者节点、接收者节点和/或机器学习服务之间)。例如,从客户机系统发送到编排器以启动流水线的消息可以包括用户界面识别、流水线标识、客户机认证令牌、状态和/或数据端点、状态类型和正式数据结构属性(例如,数据位置、实际数据本身)。类似地,当客户端系统从编排器请求数据时,在一些实施方式中,相关联的消息可以包括用户界面识别、流水线标识和认证令牌。
127.在一些实施方式中,从编排器传输到数据代理的消息可以包括流水线标识、操作号、操作者和操作特定的配置。从数据代理传输到操作者节点的消息(通过数据传输消息总线)可以包括流水线标识、操作号、数据/有效载荷和操作特定的配置信息。在一些示例中,从操作者节点到接收器节点或机器学习服务的消息可以包括流水线标识、操作号、数据类型和数据/有效载荷。此外,从接收器传输到编排器的消息可以包括流水线标识、操作号和成功完成指示符。
128.图17d示出了视频评估系统108(图1)的数据处理集群1771的操作流程配置。在一些实施方式中,数据处理集群1771可以包括编排服务1773、消息队列服务1783、私有数据存储1787和公共数据存储1785。在一些实施方式中,编排服务1773包括编排器节点1775,其管理和控制处理资源的分配,以执行与执行候选者视频评估相关联的一个或多个处理任务(例如,从视频文件中提取音频数据、执行stt转换、检测问题抄本中的个性方面、对候选响应打分)。在一些示例中,编排服务1773可以包括负载平衡器1779,其帮助编排器1775在一个或多个工作者处理节点1777之间平衡处理任务。工作者处理节点1777可以包括如上在图17b和图17c中所述的自然语言分类器节点、转录节点和结果生成节点。在一些实施方式中,工作者处理节点1777可以将处理输出传递给结果处理器1781用于后处理,以准备处理输出用于呈现给系统用户。
129.在一些实施例中,数据处理集群1771还可以包括管理与数据处理集群1771的组件相关联的一个或多个数据队列的消息队列服务1783。在一个示例中,消息队列服务1783是rabbitmq消息服务。在一些实施方式中,消息排队服务1783可以管理和处理来自编排服务1773和/或一个或多个公共数据存储1785(诸如公共docker hub)的消息队列。在一些示例中,编排服务1773还可以从私有(例如,内部)数据存储1787和公共(例如,外部)数据存储1785接收数据,以供工作者处理节点1777处理。
130.回到图1,在一些示例中,视频评估系统108可以包括通过从候选者视频数据112中提取和处理附加特征来增强候选面试问题视频的评估特征的数量的其他处理引擎。在一个示例中,系统108可以包括视频处理引擎,该视频处理引擎在响应面试问题时检测与候选者102的面部表情和肢体语言相关的特征。视频评估系统108可以使用身体语言特征来通知针对相应问题的stt抄本数据128的个性方面检测和打分。例如,视频处理引擎可以被训练来
检测与个性模型500(图5)的每个个性方面相关联的身体语言和面部表情标识符。例如,面试的部分期间候选者瞳孔的大小、手势以及响应问题期间的姿势都是可检测特征的一部分,这可用于个性方面的分析。此外,系统108可以被配置为基于事件发生的时间将从视频中检测到的非语言特征与面试问题抄本中检测到的个性方面标识符进行匹配。在一些示例中,当非语言标识符(来自视频)与检测到的语言标识符(来自抄本)一致时,则候选者分数引擎140可以基于语言和非语言标识符的一致性来增加(或减少)相应个性方面的分数。在一些实施方式中,视频处理引擎可以被配置为检测对一些面试问题的响应。例如,如果面试问题具有“是”或“否”的方面,则视频处理引擎可以被配置为检测候选者是否以“是”或“否”的回答进行了响应。除了检测对封闭式问题(例如,“是/否”问题)的响应之外,系统108可以被配置为检测响应的非语言方面(例如韵律和面部表情特征),其可以是响应的指示。
131.在一些示例中,除了检测个性方面之外,视频评估系统108还可以包括响应分类器,该响应分类器采用经训练的自然语言分类器来确定候选者102是否已经实际响应了所提出的面试问题。因为候选者102在无监督的环境中提交他们的响应(例如,如果他们未能回答问题,没有面试官实时观看他们的响应以提供即时反馈),所以候选者102可能能够通过提交不回答对应的问题的面试问题响应来无意地或有意地欺骗系统108。在一些实施方式中,对于每个面试问题,可以训练自然语言分类器来检测指示候选者已经响应了该问题的关键词和短语。例如,对于要求候选者102描述她遇到的挫折以及她如何恢复的示例的面试问题,自然语言分类器可以被配置为检测与描述操作环境中的挫折、困难或失败相关联的单词和短语。如果分类器以预定的置信度确定候选者102没有充分响应面试问题,则在一些示例中,会产生数据质量错误。在一些示例中,系统108可以向候选者102输出通知,请求她重新提交对相应问题的响应。在其他示例中,该响应可以被标记以供雇主104人工审查。
132.转向图16,示出了示出视频评估过程1600期间处理组件和参与者之间的通信流的图,参与者包括候选者102、雇主104、顾问106、处理引擎和视频评估系统108的数据储存库。例如,图1600示出了系统平台1608、候选者1602和客户端1604之间的通信流。例如,视频评估过程1600可以由图1的环境100支持,其中平台1608代表系统108,候选者1602代表候选者计算系统102,客户端1604代表雇主计算系统1604和/或顾问计算系统106。
133.在一些实施方式中,视频评估过程1600开始于客户端1604,诸如雇主希望向平台1608发布一个或多个可用操作职位,向平台提交关于一个或多个候选职位以及与每个相应职位相关联的能力的信息(1610)。在一些示例中,客户端1604经由一个或多个系统提供的ui屏幕向平台1608提供可用操作职位信息。在一些示例中,ui屏幕可以提供一系列下拉或选择窗口,这些窗口允许客户端1604从通常选择的或先前提供的职位列表中选择空缺职位。例如,金融公司可能会重复出现财务分析师的空缺,或者零售公司可能经常征求店内助理或客户服务代表的申请。在一些实施例中,ui屏幕还可以包括允许客户端1604提供关于新空缺职位的信息的自由文本输入字段。在一些示例中,客户端1604还可以提供关于所识别的空缺职位的管理细节,诸如经验年限、教育资格和预计开始日期。在一些实施方式中,平台1608还可以向客户端1604的计算设备提供ui屏幕,以识别与每个识别的空缺职位相关联的能力。在一些示例中,能力可以是雇员应该拥有的任何技能或属性。例如,由客户1604识别的职位的能力可以包括但不限于动机、抱负、自我意识和韧性。
134.在一些实施例中,响应于从客户端1604接收到针对一个或多个空缺职位的所识别
的职位和能力,平台1608可以提供能力映射ui屏幕(1612),其允许客户端1604将所识别的能力映射到一个或多个促成因素属性(1614)(参见图2中的能力-促成因素属性映射表200)。在一些示例中,促成因素属性是标准化属性的集合,其提供了用于将雇主识别的能力翻译成个性方面的翻译或转换机制,该个性方面可以由实现专门训练的自然语言分类器(nlc)的平台1608从面试抄本中自动识别。
135.在一些实施方式中,响应于从客户端1604接收所提交的能力/促成因素属性映射,平台1608向客户端1604提供一个或多个问题选择ui屏幕(1618),其允许客户端选择与所识别的能力和促成因素属性相关联的面试问题(1620)。在一些示例中,映射的促成因素属性允许平台1608将客户识别的操作能力转换成可由经训练的自然语言分类器检测的个性模型的个性方面。在一些实施方式中,响应于接收到能力促成因素属性选择,平台1608产生面试问题选择ui屏幕,该屏幕允许客户端1604为该职位选择与雇主识别的能力中的每个能力相一致的面试问题(参见图3中的面试问题300)。在一些实施方式中,面试问题选择ui屏幕基于所识别的促成因素属性提供一组问题以供选择(参见图4中的问题-促成因素映射表400)。通过从能力-促成因素映射中选择针对已确定促成因素属性的面试问题,这些问题也将针对已识别的能力进行定制。
136.基于所选择的面试问题,在一些实施方式中,平台1608从个性模型中识别与每个映射的促成因素属性中的每个属性相关联的正面和负面个性方面(1622)(参见图6中的促成因素-方面映射表600)。此外,平台1608可以基于方面与相应促成因素的相关程度来确定每个所识别的个性方面与相应促成因素属性的相关性。在一个示例中,每个促成因素-方面对的相关性以从1到5的等级分数,5表示促成因素-方面对之间的最高相关性。可以理解的是,任何类型的分数尺度或范围都可以应用于面试问题与促成因素属性的相关性的量(例如,百分比、高/中/低、一到十)。在一些实施例中,平台1608还可以将针对空缺职位的每个所识别的能力映射到个性模型(例如,图5中的个性模型500)的一个或多个方面。在一些示例中,平台1608可以从促成因素-方面映射中导出能力-方面映射,如映射表600和能力-促成因素映射200(图2),以生成能力-方面映射表(例如,图7中的表700)。
137.在一些实施例中,使用为每个促成因素属性识别的个性方面,平台1604可以为每个识别的面试问题生成个性方面映射(1624)。在一些实施方式中,使用问题-促成因素映射表400(图4)、促成因素-方面映射表600和/或能力-方面映射表700,平台1608为客户端1604提交的每个空缺职位生成问题-方面映射(参见图8中的问题-方面映射表800)。
138.在一些示例中,当候选者1602访问视频评估系统108来申请一个或多个空缺职位时,平台1608向候选者1602提供面试输入ui屏幕。例如,图9所示的面试输入ui屏幕900允许候选者1602查看职位的面试问题,记录面试问题响应,并将每个记录的响应链接到相应面试问题。在将视频响应文件链接到每个相应面试问题后,在一些示例中,候选者1602提交视频文件,该视频文件由平台1608接收(1636)。
139.在一些实施方式中,平台1608可以从接收到的视频文件中提取音频部分,并对每个面试问题响应执行stt转换过程和自然语言分类过程(1630)。在一些实施方式中,平台1608使用机器学习算法来组合语法、语言结构以及音频和语音信号的组成的知识,以准确地转录所接收的面试问题文件中的人类语音。在一些实施方式中,平台1608所使用的机器学习算法可以被训练成以比其他单词更高的准确度来检测与个性模型500(图5)中的方面
相关联的关键词、短语和同义词,这进而提高了自然语言分类器检测经转换的抄本内的个性方面的性能。
140.此外,平台1608可以使用经训练的自然语言分类器来检测每个面试问题抄本中的正面和负面个性方面。在一些实施方式中,平台1608使用定制的训练数据集124来训练自然语言分类器,以检测个性模型(例如,图5中的个性模型500)的正面和负面方面。在一些示例中,平台1608可以使用检测到的正面和负面方面指示符的实例来评估候选者在空缺职位的一个或多个能力方面出类拔萃的资质。在一些实施方式中,训练数据集124可以包括关键词、短语和其他同义词,其可以指示与个性模型500相关联的正面和负面个性方面。
141.在一些实施例中,平台1608可以对接收到的视频文件和/或转换后的面试问题抄本执行一次或多次提交质量评估(1632)。在一个示例中,平台1608执行音频数据可用性测试,包括确定相应视频文件的信噪比,并确定语音到文本转录结果的置信度分数。在一些示例中,置信度分数对应于反映近似单词错误率的抄本的准确度分数。此外,平台1608可以执行附加的数据质量测试,包括对由stt算法生成的抄本的分析,以检测候选者102试图通过提交获得人为高分数的面试响应来欺骗或蒙骗系统108的情况。在一些示例中,平台1608可以被配置为检测问题抄本中的自然语音模式的证据,以检测候选者使用仅包括候选者102认为将获得更高分数的关键词的短而不连贯的语音的出现。在一个示例中,平台1608测量面试问题抄本的总单词计数。如果单词计数小于预定阈值,诸如185个字,则可以检测到质量错误。在一些实施方式中,平台1608还可以基于面试问题抄本的平均单词长度来检测诚实和不诚实的面试问题响应。在一个示例中,如果问题抄本的平均单词长度少于3个字符或多于8个字符,则平台1608可以检测到质量错误。在一些实施方式中,平台1608还可以检测问题中特定关键短语的重复使用,这可以指示候选者102试图提交对面试问题的欺诈性响应。在一个示例中,平台1608可以检测到短语“我是”、“我为”和“我曾经是”的重复使用,这可以指示候选者102试图通过在一组关键词之前放置类似“我是”的短语来掩盖他的欺诈性使用关键词和形容词(例如,“我是负责的”、“我是自信的”)。
142.在一些实施方式中,如果平台1608检测到候选者的面试问题响应的一个或多个质量错误,则平台1608可以向候选者1602提供质量反馈ui屏幕(1634),以允许候选者修正并重新提交一个或多个面试问题响应提交(1636)。在一些示例中,如果检测到任何单词计数和/或平均单词长度质量错误,则平台1608可以向相应候选者1602输出错误通知。在一些方面,可以向候选者1602提供另一个机会来记录对产生错误的问题的面试问题响应。在一些实施方式中,当检测到的质量错误与蒙骗系统的尝试无关时,平台1608可以仅向候选者1602提供针对这些错误重新提交面试问题响应的机会。
143.在一些实施方式中,平台1608将检测到的正面和负面个性方面中的每一个添加到每个方面的组中,并使用方面分组(例如,图13中的分组1302、1304、1306),计算候选者1602的每个方面的分数、每个问题的总分数和/或每次面试的总分数(1638)。在一些示例中,所计算的分数可以考虑每个方面的正面和负面指示符的相对数量、每个问题的stt抄本的准确性的置信度、面试抄本中每个个性方面的原始证据的数量以及每个个性方面与每个面试问题的相关性。平台1608还可以基于计算的分数生成候选排名。
144.在一些实施例中,平台1608向客户端1604提供一个或多个面试概要屏幕(1640),其允许客户端1604查看候选者分数、查看候选者面试响应视频并提供关于分数的反馈
(1642)(例如,图15中的报告和反馈ui屏幕1500)。在一些示例中,客户端1604可以提供自由文本书面评论和/或基于对面试响应视频的人工审核来调整候选者分数。在一些示例中,平台1608可以将任何接收到的评论和/或手动调整的分数合并到为训练自然语言分类器和/或stt转换算法而发布的训练数据中。
145.在一些示例中,平台1608可以利用客户端1604提供的反馈来更新用于训练自然语言分类器的训练数据(1644)。在一些示例中,平台还可以基于接收到的反馈来更新促成因素/个性方面相关性映射数据。更新训练数据和映射数据可以提高自然语言分类器的整体检测准确度,并为准确自动化评估操作候选者视频响应的技术问题提供了技术解决方案。
146.在一些方面,平台1608可以基于计算出的分数和接收到的客户端反馈向候选者提供选择结果和面试反馈(1646)。在一些示例中,选择结果包括关于候选者1602为什么被选择或没有被选择担任该职位的反馈。例如,平台1608可以使用计算的候选者分数和排名信息以及由评估面试响应的客户端1604提供的反馈数据123来生成净化的候选者报告概况。在一些实施方式中,生成净化的候选者报告概况可以包括将客户端1604提供的任何过度负面的评论转换成稍微更正面的语言,该语言仍然传达给候选者1602他有改进的空间。
147.在一些示例中,视频评估过程1600的通信流的排序可以以不同于图16所示的顺序发生。例如,平台1608可以在将stt和自然语言分类器算法应用于响应(1630)之前和/或在计算候选方面分数(1638)之后,向候选者1602提供提交质量反馈信息(1634)。此外,图16所示的一个或多个通信流程可以同时或并行发生。例如,提交质量确定(1632)可以与候选分数计算(1638)并行进行。
148.转向图18,示出了用于训练自然语言分类器和/或stt转换算法的示例方法1800的流程图。在一些实施方式中,方法1800可以由视频评估系统108(图1)的数据管理引擎132、用户管理引擎130、候选者分数引擎140和/或ai训练引擎142来执行。在一些实施方式中,方法1800开始于编译与个性模型(例如,图5中的个性模型500)的正面消息极性个性方面相关联的训练数据集(例如,图1中的训练数据集124)(1802)。在一些实施方式中,训练数据集可以包括关键词、短语和其他同义词,它们可以指示与个性模型(例如,图5中的个性模型500)相关联的正面和负面个性方面。在一些实施方式中,训练数据集124可以包括多个数据集,每个数据集与不同的语言和/或方言相关联。在一些示例中,ai训练引擎142可以用相应语言的训练数据集来训练多个自然语言分类器。因此,视频评估系统108可以适应以任何可检测语言提交的候选者面试响应。
149.在一些实施例中,编译的训练数据集被应用于与视频评估系统108相关联的一个或多个机器学习算法(1804)。例如,ai训练引擎142可以将训练数据集应用于自然语言分类器,以训练分类器检测面试问题抄本中的个性方面。另外,训练数据集的部分也可以应用于stt转换算法,以提高与个性方面相关联的单词的stt转换的准确性。例如,定制的单词、短语和同义词的训练数据124构成了用于stt算法的定制的词典。在一些示例中,定制的词典中的条目被分配了比其他单词更高的识别优先级(权重),使得条目更能防止遗漏检测。在一个示例中,用于训练stt算法的定制的词典包括超过16,000个单词和短语以及与每个条目相关联的同义词。
150.当候选者提交对职位的一组面试问题的视频响应时(1806),那么在一些示例中,与候选者响应的自动评估相关联的信息以及来自人工评级人的手动反馈可以被合并到训
练数据集中。例如,对于由候选者分数引擎140为候选者的响应生成的每组分数(1808),在一些示例中,报告和反馈引擎152可以从雇主104和/或顾问106获得人工打分数数据(1810)。在一些实施方式中,ai训练引擎142可以获得提交面试问题响应的所有候选者的人工评级。在其他示例中,ai训练引擎142可以获得预定数量或百分比的候选者的人工评级。
151.在一些实施方式中,系统108(例如,ai训练引擎142和/或候选者分数引擎140)可以计算候选者的自动和人工(手动)评级之间的相关性(1812),其指示自动和人工评级彼此跟踪得有多好。在一些示例中,人工评级数据和分类器评级数据的比较/相关性被反馈到语言分类引擎138和stt转换引擎134的自然语言分类器中作为训练数据124。
152.如果自动和/或手动评级中的至少一个在预定范围之外(1814),则ai训练引擎142可以获得关于评级人为什么如何对候选者进行打分的评级反馈(1816)。在自动评级的情况下,在一些实施例中,该反馈信息可以包括在每个问题抄本中检测到的个性方面指示符。在手动评级的情况下,在一些实施方式中,反馈信息可以包括来自评审者的自由文本评论,该评论关于各自的评审为什么以他们所做的方式对候选者分数。在一些情况下,当人工和/或自动分数数据非常高(例如,在1到5的范围内大于4.5)或非常低(例如,在1到5的范围内小于1.5)时,ai训练引擎142可以获得关于为什么人工评级人和/或自动评级人(例如,由候选者分数引擎140用来计算候选者分数的自然语言分类器检测到的个性方面)给候选者如此高或如此低的分数的附加信息。
153.在一些实施方式中,ai训练引擎142用自动和手动候选分数、相关性和反馈来更新训练数据集(1818),并将更新的训练数据集应用于自然语言分类器和/或stt转换算法。
154.尽管在特定的一系列事件中示出,但是在其他实施方式中,机器学习分类器训练过程1800的步骤可以以不同的顺序执行。例如,候选者评级分数的生成(1808)可以在接收候选者的人工评级分数(1810)之前、之后或同时执行。此外,在其他实施例中,推荐过程可以包括更多或更少的步骤,同时保持在机器学习分类器训练过程1800的范围和精神内。
155.图19示出了用于为空缺职位生成问题-方面映射的示例方法1900的流程图。在一些实施方式中,方法1900可以由视频评估系统108(图1)的雇主管理引擎144和促成因素方面映射引擎148来执行。
156.在一些实施方式中,方法1900开始于视频评估系统108经由一个或多个系统提供的ui屏幕从雇主104接收空缺职位信息(1902)。在一些示例中,ui屏幕可以提供一系列下拉或选择窗口,允许雇主104从通常选择的或先前提供的职位列表中选择空缺职位。例如,金融公司可能会重复出现财务分析师的空缺,或者零售公司可能会经常征求店内助理或客户服务代表的申请。在一些实施例中,ui屏幕还可以包括允许雇主104提供关于新空缺职位的信息的自由文本输入字段。在一些示例中,雇主104还可以提供关于所识别的空缺职位的管理细节,诸如经验年限、教育资格和预计开始日期。
157.如果在提交的职位信息中检测到任何预定的关键词(1904),则在一些示例中,雇主管理引擎144可以为职位生成一个或多个能力/促成因素属性建议(1906)。在一些示例中,如果雇主104过去已经将视频评估系统108用于相同类型的职位,则雇主管理引擎144可以在能力选择ui屏幕上为该职位建议先前识别的能力。雇主104进而可以通过从能力模型中添加或删除能力来修改能力模型中的能力列表,或者可以接受先前使用的能力列表。此外,雇主管理引擎144可以基于职位能力数据116,用通常链接到与雇主104相关联的所有
和/或某些类型的职位的能力来自动填充新创建职位的能力模型。在一些示例中,雇主管理引擎144还可以使用其他雇主104的职位的能力模型信息来识别空缺职位的能力建议。例如,雇主管理引擎144可以为使用视频评估系统108来处理和评估工作申请者面试的所有雇主104识别不同类型职位的能力趋势,并将任何识别的趋势提供给雇主104。例如,雇主管理引擎144可以确定雇主104将果断识别为管理员职位的能力,并且如果雇主104提交管理员的空缺职位信息,则反过来建议果断作为能力。类似地,雇主管理引擎144可以生成先前已经映射到任何建议能力的多组建议促成因素属性。在一些实施例中,雇主管理引擎144接收能力/促成因素属性选择能力选择ui屏幕(1907)。
158.在一些实施方式中,雇主管理引擎144可以在一个或多个ui屏幕(例如,图2中的能力-促成因素映射表200)上接收每个识别的能力的促成因素属性映射输入(1908)。在一些实施例中,响应于从雇主104接收到针对空缺职位的一组能力,雇主管理引擎144可以生成一个或多个ui屏幕,用于将每个识别的能力映射到一个或多个促成因素属性。在一些示例中,促成因素属性是标准化属性的集合,其提供了用于将雇主识别的能力翻译成个性方面的翻译或转换机制,该个性方面可以由实现专门训练的自然语言分类器(nlc)的语言分类引擎138从面试抄本中自动识别。在一些示例中,雇主104和顾问106可以经由一个或多个系统提供的ui屏幕彼此交互,这允许顾问106教育和帮助雇主104识别职位的能力模型中的每个能力的适当的促成因素属性。如果特定能力先前已经被雇主104识别用于另一个职位或相同职位的先前重复,则雇主管理引擎144可以提供先前的促成因素属性映射作为一个或多个所识别能力的建议促成因素属性。
159.在一些实施方式中,基于接收到的能力/促成因素属性提交,促成因素-方面映射引擎148可以生成与为该职位选择的能力/促成因素属性一致的多组可能的面试问题(1910),并将问题可能性呈现给雇主104以在一个或多个ui屏幕(例如,图4中的问题选择ui屏幕400)上进行选择。对于为空缺职位识别的每个促成因素属性,雇主104可以从ui屏幕中提供的菜单中选择一个或多个面试问题。通过从能力-促成因素映射中选择针对已确定促成因素属性的面试问题,这些问题也将针对已确定的能力进行定制。
160.响应于从雇主104接收到对该职位的面试问题选择(1912),在一些示例中,促成因素-方面映射引擎148可以确定每个能力和促成因素属性与和每个问题相关联的个性方面的相关性(例如,图6中的促成因素-方面映射表600)(1914)。在一些实施方式中,促成因素-方面映射引擎148基于方面与相应促成因素的相关程度,将相关性值应用于每个促成因素属性-方面对。在一个示例中,每个促成因素属性-方面对的相关性以从1到5的等级分数,5表示促成因素-方面对之间的最高相关性。在一些实施方式中,存储的促成因素方面相关性数据可以基于基于个性的研究。在一些实施方式中,基于从雇主104和/或顾问106接收的反馈以及自然语言分类器的更新的训练集数据,促成因素相关方面数据也可以随时间更新。在一些实施例中,促成因素方面映射引擎148还可以将针对空缺职位的每个所识别的能力映射到个性模型500(图5)的一个或多个个性方面。在一些示例中,促成因素-方面映射引擎148可以从促成因素-方面映射中导出能力-方面映射,如映射表600(图6)和能力-促成因素映射200(图2)(参见图7中的能力-方面映射表700)。
161.在一些实施方式中,使用能力-方面和/或促成因素-方面映射,促成因素-方面映射引擎148可以为空缺职位生成问题/方面映射,其中每个选择的面试问题被映射到个性模
型中的每个个性方面(参见图8中的问题-方面映射表800)(1916)。在一些实施方式中,表800中每个问题-方面对的相关性值可以反映与特定问题相关联的所有促成因素属性的累积相关性分数。在一些示例中,问题映射表800的数据结构(除了促成因素-方面映射表600、能力-方面映射表700和问题-促成因素映射表400之外)通过提供简化面试分数计算和候选者评估的结构来提高视频评估系统800的处理效率,如下面进一步讨论的。具体地,具有包括每个面试问题的每个方面的相关性分数的单个数据结构使得候选者分数引擎140能够更快速地计算每个方面、每个问题和每个候选者的分数。
162.尽管在特定的一系列事件中示出,但是在其他实施方式中,问题方面映射生成过程1900的步骤可以以不同的顺序执行。例如,接收能力/促成因素属性映射选择(1908)可以在生成每个能力/促成因素属性的可能问题(1910)之前、之后或同时执行。另外,在其他实施例中,推荐过程可以包括更多或更少的步骤,同时保持在问题方面映射生成过程1900的范围和精神内。
163.图20示出了用于执行候选者视频评估的示例方法2000的流程图。在一些实施方式中,方法2000由视频评估系统108(图1)的用户管理引擎130、数据获取引擎146、stt转换引擎134、语言分类引擎138、候选者分数引擎140以及报告和反馈引擎152来执行。
164.在一些实施方式中,方法2000从用户管理引擎130接收来自候选者102的面试兴趣输入开始,该面试兴趣输入指示候选者102希望申请系统108广告的至少一个空缺职位(2002)。响应于接收到面试兴趣输入,在一些实施方式中,数据获取引擎146向候选者提供面试输入ui屏幕(例如,图9中的问题概要ui屏幕900),其允许候选者记录并链接视频面试问题对该职位的每个问题的响应(2004)。
165.在一些实施方式中,在接收到候选者面试提交后,数据获取引擎146扫描、处理、组织和存储提交的视频文件(2006)。在一些实施方式中,数据获取引擎146还可以执行其他类型的预处理,以提高视频评估系统108生成语音到文本抄本的效率。例如,数据获取引擎146可以从每个接收到的视频文件中自动提取音频数据,并将提取的音频数据与其对应的视频一起保存在单独的文件中,作为候选者视频数据112的一部分。
166.在一些实施例中,stt转换引擎134实时地将每个捕捉的视频面试问题的音频数据转换成书面文本(2008)。在一些实施方式中,stt转换引擎134使用语音到文本服务来执行stt转换。在一些实施方式中,stt转换引擎134使用机器学习算法来组合语法、语言结构以及音频和语音信号的组成的知识,以准确地转录所接收的面试问题文件中的人类语音。
167.在一些实施方式中,stt转换引擎134和/或数据质量评估引擎136对面试问题抄本执行一个或多个数据质量测试(2009)。在一些实施例中,执行一个或多个数据质量测试可以包括基于抄本质量分数(置信度分数)、信息量分数和/或可信度分数来计算每个面试问题抄本的dqi。在一些示例中,如果抄本不符合一个或多个预定质量标准(2010),则在一些示例中,数据获取引擎146从候选者获得重新记录的提交(2012)。在一个示例中,由数据质量评估引擎136执行的数据质量测试包括音频数据可用性测试、stt置信度分数(例如,单词错误率)测试和其他测试,以确定候选者102是否试图通过提交欺诈性响应来欺骗系统108。例如,数据质量评估引擎136可以被配置为检测问题抄本内的自然语音模式的证据,以检测候选者使用短的、不连贯的语音的出现。在一个示例中,数据质量评估引擎136测量面试问题抄本的总单词计数、平均单词长度和/或预定短语的重复使用。如果这些数据质量度量中
的任何一个超出预定范围,则数据质量评估引擎136可以生成数据质量错误,并请求响应重新提交。
168.在一些实施方式中,语言分类引擎138可以将经训练的自然语言分类器应用于面试问题抄本,以检测抄本中的正面和负面个性方面标识符(2014)。在一些示例中,语言分类引擎138使用自然语言分类器,该自然语言分类器已经被专门训练来检测面试问题抄本中的个性方面(例如,图12所示的抄本1200中的识别的个性方面标识符1202-1226)。在一些实施例中,语言分类引擎138的自然语言分类器基于相应标识符是与个性方面的正面特征还是负面特征相关联,向每个检测到的标识符分配正面极性或负面极性。在一些实施例中,语言分类引擎138基于每个标识符所关联的个性方面将检测到的个性方面(例如,图12中的个性方面1202-1226)组织成组(例如,参见图13中的分组1302-1306)。
169.在一些实施例中,候选者分数引擎140基于面试问题抄本中检测到的个性方面标识符计算每个问题的方面分数(2016)和每个问题的总分数(2018)。在一些示例中,所计算的分数可以考虑每个方面的正面和负面指示符的相对数量、每个问题的stt抄本的准确性的置信度、面试抄本中每个个性方面的原始证据的数量以及每个个性方面与每个面试问题的相关性。在一些示例中,候选者分数引擎140还可以为每个方面和问题计算原始证据分数,该原始证据分数指示候选者102为每个面试问题的每个方面提供了多少信息。在一些实施方式中,候选者分数引擎可以使用原始证据分数、正面标识符以及该方面与问题的相关性来计算置信度分数,该置信度分数测量关于相应问题的分数的准确性的确定性。例如,如果问题的个性方面的相关性高,但是候选者102提供了很少或没有提供与该方面相关的信息,则置信度分数降低该方面的总问题分数(tsq)。即使一个方面与特定问题几乎没有相关性,候选者分数引擎140仍然可以计算该方面的原始证据分数和置信度分数。
170.在一些实施方式中,当已经生成了所有问题的方面分数时(2020),候选者分数引擎140可以使用计算出的每个问题的每个方面的分数sq和每个方面的总分数tsq来计算空缺职位的每个雇主识别的能力的分数(2022)。在一些实施方式中,使用每个问题的置信度分数,候选者分数引擎140可以计算包括多个面试问题的整个面试的每个方面的总置信度。此外,候选者分数引擎140可以根据所有问题级方面分数和置信度分数来计算每个方面的总分数。在一些示例中,相对于置信度分数计算tsq,以便说明候选者102已经提供了多少与每个个性方面相关的信息。在一些实施方式中,候选者分数引擎140可以访问职位的问题映射数据120(例如,图8中的问题-方面映射表800和图7中的能力-方面映射表700),并且可以将每个方面的计算分数转换为每个能力的分数。
171.在一些实施方式中,报告和反馈引擎152可以生成候选者报告,该候选者报告经由一个或多个ui屏幕向雇主104和/或顾问106提供候选者分数结果(2024)。在一些示例中,报告和反馈引擎152可以在ui屏幕中呈现每个问题的个性方面分数,并为雇主104提供输入字段以提供关于分数和响应的反馈(例如,图15中的报告和反馈ui屏幕1500)。在一些示例中,在ui屏幕上提供的反馈可以包括对所提供的候选者分数结果的自由文本评论,以及雇主104可以响应于观看视频面试问题响应而做出的任何手动分数调整(2026)。在一些示例中,ai训练引擎142用系统生成的分数数据以及由雇主104和/或顾问106提供的任何人工调整和/或反馈意见来更新训练数据集(2028)。
172.尽管在特定的一系列事件中示出,但是在其他实施方式中,候选者视频评估过程
2000的步骤可以以不同的顺序执行。例如,对面试问题抄本执行数据质量测试(2009)可以在将经训练的自然语言分类器应用于响应抄本(2014)之前、之后或同时执行。此外,在其他实施例中,推荐过程可以包括更多或更少的步骤,同时保持在候选者视频评估过程2000的范围和精神内。
173.接下来,参考图21描述根据示例性实施例的计算设备、移动计算设备、计算系统或服务器的硬件描述。例如,计算设备可以代表候选者102、雇主104和/或顾问106,或者支持视频评估系统108的功能的一个或多个计算系统,如图1所示。在图21中,计算设备、移动计算设备或服务器包括执行上述过程的cpu 2100。过程数据和指令可以存储在存储器2102中。在一些示例中,处理电路和存储的指令可以使计算设备能够执行图18、图19和图20的方法1800、1900和2000。这些过程和指令也可以存储在诸如硬盘驱动器(hdd)或便携式存储介质的存储介质盘2104上,或者可以远程存储。此外,所要求的进步不受存储本发明过程的指令的计算机可读介质的形式的限制。例如,指令可以存储在cd、dvd、闪存、ram、rom、prom、eprom、eeprom、硬盘或计算设备、移动计算设备或诸如服务器或计算机的服务器与之通信的任何其他信息处理设备中。在一些示例中,存储介质盘2104可以存储图1的数据存储库110的内容,以及由候选者102、雇主104和/或顾问106在由视频评估系统108访问并传输到数据存储库110之前维护的数据。
174.此外,所要求保护的进步的一部分可以被提供为与cpu 2100和诸如微软windows 7、8、10、unix、solaris、linux、apple mac-os和本领域技术人员已知的其他系统的操作系统结合执行的实用程序、后台守护程序或操作系统的组件或其组合。
175.cpu 2100可以是来自美国intel的xeon或core处理器或来自美国amd的opteron处理器,或者可以是本领域普通技术人员将认识到的其他处理器类型。或者,如本领域普通技术人员将认识到的,cpu 2100可以在fpga、asic、pld上实现或使用分立逻辑电路实现。此外,cpu 2100可以被实现为并行合作操作的多个处理器,以执行上述发明过程的指令。
176.图21中的计算设备、移动计算设备或服务器还包括网络控制器2106,诸如来自美国英特尔公司的英特尔以太网pro网络接口卡,用于与网络2128接口。可以理解,网络2128可以是公共网络,诸如因特网,或者专用网络,诸如lan或wan网络,或者它们的任意组合,并且还可以包括pstn或isdn子网络。网络2128也可以是有线的,诸如以太网,或者可以是无线的,诸如包括edge、3g、4g和5g无线蜂窝系统的蜂窝网络。无线网络也可以是wi-fi、蓝牙或任何其他已知的无线通信形式。例如,网络2128可以支持视频评估系统108和候选者102、雇主104和/或顾问106中的任何一个之间的通信。
177.计算设备、移动计算设备或服务器还包括显示控制器2108,诸如来自美国nvidia公司的nvidia geforce gtx或quadro图形适配器,用于与诸如惠普hpl2445w lcd监视器的显示器2110接口。通用i/o接口2112与键盘和/或鼠标2114以及显示器2110上或与其分离的触摸屏面板2116接口。通用i/o接口还连接到各种外围设备2118,包括打印机和扫描仪,诸如来自惠普的officejet或deskjet。显示控制器2108和显示器2110可以实现用于向视频评估系统108提交请求的用户界面的呈现。
178.声音控制器2120也被提供在计算设备、移动计算设备或服务器中,诸如来自creative的sound blaster x-fi titanium,以与扬声器/麦克风2122接口,从而提供声音和/或音乐。
179.通用存储控制器2124用通信总线2126连接存储介质盘2104,通信总线2126可以是isa、eisa、vesa、pci或类似的,用于互连计算设备、移动计算设备或服务器的所有组件。为了简洁起见,本文省略了对显示器2110、键盘和/或鼠标2114以及显示控制器2108、存储控制器2124、网络控制器2106、声音控制器2120和通用i/o接口2112的一般特征和功能的描述,因为这些特征是已知的。
180.除非另有明确说明,否则可以利用一个或多个处理器来实现本文描述的各种功能和/或算法。此外,除非另外明确说明,否则本文描述的任何功能和/或算法可以在一个或多个虚拟处理器上执行,例如在一个或多个物理计算系统上,诸如计算机群或云驱动器。
181.已经参考了根据本公开的实现的方法、系统和计算机程序产品的流程图和框图。其各方面由计算机程序指令来实现。这些计算机程序指令可以被提供给通用计算机、专用计算机或其他可编程数据处理设备的处理器以产生机器,使得经由计算机或其他可编程数据处理设备的处理器执行的指令创建用于实现流程图和/或框图的一个或多个框中指定的功能/动作的部件。
182.这些计算机程序指令也可以存储在计算机可读介质中,该计算机可读介质可以指导计算机或其他可编程数据处理装置以特定方式运行,使得存储在计算机可读介质中的指令产生包括指令部件的制品,该指令部件实现流程图和/或框图的一个或多个框中指定的功能/动作。
183.计算机程序指令也可以被加载到计算机或其他可编程数据处理设备上,以使一系列操作步骤在计算机或其他可编程设备上执行,从而产生计算机实现的过程,使得在计算机或其他可编程设备上执行的指令提供用于实现流程图和/或框图的一个或多个框中指定的功能/动作的过程。
184.此外,本公开不限于本文描述的特定电路元件,本公开也不限于这些元件的特定尺寸和分类。例如,本领域技术人员将会理解,本文描述的电路可以基于电池尺寸和化学性质的变化或者基于要供电的预期备用负载的要求而进行调整。
185.本文描述的功能和特征也可以由系统的各种分布式组件来执行。例如,一个或多个处理器可以执行这些系统功能,其中处理器分布在网络中通信的多个组件上。除了各种人机接口和通信设备(例如,显示监视器、智能电话、平板电脑、个人数字助理(pda))之外,分布式组件可以包括一个或多个客户端和服务器机器,它们可以共享处理,如图22所示。该网络可以是诸如lan或wan的专用网络,或者可以是诸如因特网的公共网络。对系统的输入可以通过直接的用户输入接收,并且可以实时地或者作为批处理远程接收。此外,一些实现可以在与所描述的不同的模块或硬件上执行。因此,其他实现也在要求保护的范围内。
186.在一些实施方式中,本文描述的计算设备可以与云计算环境2230(诸如google cloud platform
tm
)接口,以执行上文详述的方法或算法的至少一部分。与本文描述的方法相关联的过程可以在计算处理器上执行,例如数据中心2234的google compute engine。例如,数据中心2234还可以包括应用处理器,例如google app engine,其可以用作与本文描述的系统的接口,以接收数据并输出相应信息。云计算环境2230还可以包括一个或多个数据库2238或其他数据存储,诸如云存储和查询数据库。在一些实施方式中,云存储数据库2238,诸如google cloud storage,可以存储由本文描述的系统提供的已处理和未处理的数据。例如,候选者视频数据112、雇主职位数据114、职位能力数据116、促成因素方面相关
性数据118、问题映射数据120、响应质量数据122、训练数据集124、方面标识符分组数据126、问题列表127、抄本数据128、候选者分数数据129、反馈数据123和编排数据131可以由图1的视频评估系统108在诸如数据库2238的数据库结构中维护。
187.本文描述的系统可以通过安全网关2232与云计算环境2230通信。在一些实施方式中,安全网关2232包括数据库查询接口,例如google bigquery平台。例如,数据查询接口可以支持视频评估系统108访问存储在候选者102、雇主104和/或顾问106中的任何一个上的数据。
188.云计算环境2230可以包括用于资源管理的供应工具2240。供应工具2240可以连接到数据中心2234的计算设备,以便于供应数据中心2234的计算资源。供应工具2240可以经由安全网关2232或云控制器2236接收对计算资源的请求。供应工具2240可以促进到数据中心2234的特定计算设备的连接。
189.网络2202表示将云环境2230连接到多个客户端设备的一个或多个网络,诸如因特网,在一些示例中,客户端设备诸如蜂窝电话2210、平板计算机2212、移动计算设备2214和台式计算设备2216。网络2202还可以使用各种移动网络服务2220经由无线网络进行通信,移动网络服务2220诸如wi-fi、蓝牙、包括edge、3g、4g和5g无线蜂窝系统的蜂窝网络,或者任何其他已知的无线通信形式。在一些示例中,无线网络服务2220可以包括中央处理器2222、服务器2224和数据库2226。在一些实施例中,网络2202对于与客户端设备相关联的本地接口和网络是不可知的,以允许被配置为执行本文描述的过程的本地接口和网络的集成。此外,诸如蜂窝电话2210、平板计算机2212和移动计算设备2214的外部设备可以经由基站2256、接入点2254和/或卫星2252与移动网络服务2220通信。
190.在整个说明书中提到“一个实施例”或“实施例”意味着结合实施例描述的特定特征、结构或特性包括在所公开主题的至少一个实施例中。因此,在说明书各处出现的短语“在一个实施例中”或“在实施例中”不一定指同一实施例。此外,在一个或多个实施例中,特定的特征、结构或特性可以以任何合适的方式组合。此外,旨在所公开主题的实施例涵盖其修改和变化。
191.必须注意,如在说明书和所附权利要求中所使用的,单数形式“一”、“一个”和“该”包括复数指示物,除非上下文另外明确指出。也就是说,除非另有明确说明,否则本文使用的词语“一”、“一个”、“该”等具有“一个或多个”的含义。此外,应当理解的是,本文中可能使用的诸如“左”、“右”、“顶”、“底”、“前”、“后”、“侧”、“高度”、“长度”、“宽度”、“上”、“下”、“内部”、“外部”、“内部”、“外部”等术语仅描述参考点,并不一定将本公开的实施例限制于任何特定的方位或配置。此外,诸如“第一”、“第二”、“第三”等术语仅识别本文公开的多个部分、组件、步骤、操作、功能和/或参考点中的一个,并且同样不一定将本公开的实施例限于任何特定的配置或方向。
192.此外,术语“近似”、“大约”、“约”、“微小变化”和类似术语通常指的是包括在某些实施例中的20%、10%或优选5%的范围内的确定值以及其间的任何值的范围。
193.结合一个实施例描述的所有功能都旨在适用于下面描述的附加实施例,除非明确声明或者特征或功能与附加实施例不兼容。例如,在结合一个实施例明确描述了给定的特征或功能,但没有结合替代实施例明确提及的情况下,应该理解的是,发明人意图结合替代实施例部署、利用或实现该特征或功能,除非该特征或功能与替代实施例不兼容。
194.虽然已经描述了某些实施例,但是这些实施例仅通过示例的方式呈现,并且不旨在限制本公开的范围。实际上,本文描述的新颖方法、装置和系统可以以各种其他形式来体现;此外,在不脱离本公开的精神的情况下,可以对本文描述的方法、装置和系统的形式进行各种省略、替换和改变。所附权利要求及其等同物旨在覆盖落入本公开的范围和精神内的这些形式或修改。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。