1.本发明涉及一种用于优化板材件的生产的方法。本发明还涉及一种用于执行这种方法的设备。
背景技术:
2.板材件以极其不同的几何形状出现在极其不同的产品中。为了生产包含板材件的产品,从较大的板材板上裁切出板材件,然后进行分割、去毛刺、折弯、接合、涂覆和/或装配。
3.在此,板材件是在称为作业的过程中生产。作业包括:
4.i)生产经过切出、分割、折弯和/或装配的板材件,或
5.ii)生产多个经过切出、分割、折弯和/或装配的板材件
6.并且这在预定义的生产期限之前完成。
7.从板材板上切出单个的板材件应该使得尽可能少地在板材板上留下剩余材料(废料)作为废弃物。由于不同作业的板材件能够具有不同的几何形状,为了废料优化而能够有利的是,节省空间地在一个板材板上一起提供不同作业的板材件。
8.然而,作业的由此产生的时间上的混合增加了生产调度的复杂性。此外,板材件的生产能够在多个相同或相似的生产机器上进行。例如,能够提供多个相同或相似的折弯机用于折弯分割后的板材件。在此,生产机器应以尽可能高的能力运行。
9.由于所描述的变量,特别是在比如生产机器故障、紧急作业和/或生产机器能力被释放等事件的情况下,生产调度(即,对何时在哪个生产机器上加工哪个板材件的调度)变得非常复杂。
10.优化的生产调度被称为作业车间调度问题(job-shop-scheduling-problems,jssp)的解决方案。在此,解决方式和解决方案所采取的方法可以在以下出版物中找到:
11.[1]f.pfitzer,j.provost,c.mieth,and w.liertz,“event-driven production rescheduling in job shop environments”,in 2018ieee 14th international conference on automation science and engineering(case),ieee,2018,pp.939-944[f.pfitzer,j.provost,c.mieth和w.liertz,作业车间环境中的事件驱动生产重新调度,2018年ieee第14届自动化科学与工程国际会议(case),ieee,2018,第939-944页];
[0012]
[2]m.putz and a.schlegel,“simulationsbasierte untersuchung vonkommissionierregeln zur steuerung des materialflusses in der blechindustrie”[m.putz和a.schlegel,钣金行业物流控制优先级和拣选规则的模拟研究];
[0013]
[3]l.l.li,c.b.li,l.li,y.tang,and q.s.yang,“an integrated approach for remanufacturing job shop scheduling with routing alternatives.”,mathematical biosciences and engineering:mbe,vol.16,no.4,pp.2063-2085,2019[l.l.li,c.b.li,l.li,y.tang和q.s.yang,利用路由替代方案进行再制造作业车间调度的集成方法,数学生
物科学与工程:mbe,第16卷,第4期,第2063-2085页,2019];
[0014]
[4]m.gondran,m.-j.huguet,p.lacomme,and n.tchernev,“comparison between two approaches to solve the job-shop scheduling problem with routing”,2019[m.gondran,m.-j.huguet,p.lacomme和n.tchernev,利用路由解决作业车间调度问题的两种方法的比较,2019];
[0015]
[5]j.j.van hoorn,“the current state of bounds on benchmark instances of the job-shop scheduling problem”,journal of scheduling,vol.21,no.1,pp.127-128,2018[j.j.van hoorn,作业车间调度问题基准实例的界限的当前状态,调度杂志,第21卷,第1期,第127-128页,2018];
[0016]
[6]s.-c.lin,e.d.goodman,and w.f.punch iii,“a genetic algorithm approach to dynamic job shop scheduling problem”,in icga,1997,pp.481-488[s.-c.lin,e.d.goodman和w.f.punch iii,用于动态作业车间调度问题的遗传算法方法,icga,1997,第481-488页];
[0017]
[7]t.yamada and r.nakano,“scheduling by genetic local search with multi-step crossover”,in international conference on parallel problem solving from nature,springer,1996,pp.960-969[t.yamada和r.nakano,通过利用多步交叉的遗传局部搜索进行调度,源于自然的并行问题解决国际会议,施普林格出版社,1996,第960-969页];
[0018]
[8]b.m.ombuki and m.ventresca,“local search genetic algorithms for the job shop scheduling problem”,applied intelligence,vol.21,no.1,pp.99-109,2004[b.m.ombuki和m.ventresca,用于作业车间调度问题的局部搜索遗传算法,应用智能,第21卷,第1期,第99-109页,2004];
[0019]
[9]e.s.nicoara,f.g.filip,and n.paraschiv,“simulation-based optimization using genetic algorithms for multi-objective flexible jssp”,studies in informatics and control,vol.20,no.4,pp.333-344,2011[e.s.nicoara,f.g.filip和n.paraschiv,使用遗传算法进行多目标灵活jssp的基于模拟的优化,信息学与控制的研究.第20卷,第4期,第333-344页,2011];
[0020]
[10]l.asadzadeh,“a local search genetic algorithm for the job shop scheduling problem with intelligent agents”,computers&industrial engineering,vol.85,pp.376-383,2015[l.asadzadeh,利用智能体的用于作业车间调度问题的局部搜索遗传算法,计算机与工业工程,第85卷,第376-383页,2015];
[0021]
[11]b.waschneck,a.reichstaller,l.belzner,t.altenm
ü
ller,t.bauernhansl,a.knapp,and kyek,“optimization of global production scheduling with deep reinforcement learning”,procedia cirp,vol.72,pp.1264-1269,2018[b.waschneck,a.reichstaller,l.belzner,t.altenm
ü
ller,t.bauernhansl,a.knapp和kyek,利用深度强化学习的全球生产调度优化,程序cirp,第72卷,第1264-1269页,2018];
[0022]
[12]m.botvinick,s.ritter,j.x.wang,z.kurth-nelson,c.blundell,and d.hassabis,“reinforcement learning,fast and slow”,trends in cognitive sciences,2019[m.botvinick,s.ritter,j.x.wang,z.kurth-nelson,c.blundell和
d.hassabis,强化学习的快与慢,认知科学趋势,2019]。
[0023]
此外,wo 2017/157809 a1已知借助优化单元和与其分离的分配单元来提供生产调度。
[0024]
然而,尽管付出了巨大的努力,但由于作业的复杂性迄今为止还无法实现令人满意的生产调度。
技术实现要素:
[0025]
因此,本发明的目的是提供一种用于优化板材件的生产的方法和设备。
[0026]
该目的是根据本发明通过根据权利要求1所述的方法和根据权利要求13所述的设备来实现的。从属的权利要求提出了优选的扩展方案。
[0027]
因此,根据本发明的解决方案包括一种用于优化板材件的生产的方法。该方法至少包括以下工艺步骤(在随后的工艺步骤之前、之后和/或之间能够提供一个或多个另外的工艺步骤):
[0028]
a)切出和分割板材件(特别是借助于冲压或激光切割);
[0029]
b)折弯板材件。
[0030]
该方法至少包括以下方法步骤(在随后的方法步骤之前、之后和/或之间能够提供另一个方法步骤或能够提供多个另外的方法步骤):
[0031]
a)训练神经网络,这借助于监督学习以及自博弈与强化学习的方式在蒙特卡罗树搜索框架上执行;
[0032]
b)检测所述板材件的边界条件,其中,所述边界条件至少包括这些板材件的几何数据;
[0033]
c)通过所述神经网络创建优化的生产调度;
[0034]
d)输出该生产调度。
[0035]
根据本发明,因此提供了借助神经网络(nn)来提供优化。神经网络对于本领域技术人员来说是已知的,例如从以下文献获知:
[0036]
[13]g
ü
nter daniel rey,karl f.wender,“neuronale netze”,2nd edition,2010,huber[g
ü
nter daniel rey,karl f.wender,神经网络,第二版,2010,huber]。
[0037]
神经网络具有经由边连接的决策节点。在当前情况下,这些是蒙特卡罗树搜索(mcts)框架的一部分,即,具有决策树的算法的一部分。在此涉及在决策树中选择有希望的路径(selection),扩展路径(expansion),基于扩展路径执行模拟(simulation),以及基于模拟结果向决策树提供特别是呈增强或减弱形式的反馈(backpropagation)。与mcts框架的实施方式有关的细节能够从以下出版物中获得:
[0038]
[14]g.chaslot,s.bakkes,i.szita,and p.spronck,“monte-carlo treesearch:a new framework for game ai.”,in aiide,2008[g.chaslot,s.bakkes,i.szita和p.spronck,蒙特卡罗树搜索:游戏ai的新框架,aiide,2008]。
[0039]
在当前情况下,mcts由神经网络执行,其中,神经网络通过监督学习的方式接收初步训练。决策和进一步的训练借助于自博弈和强化学习进行。
[0040]
强化学习(reinforcement-learning,rl)被理解为是指基于反馈的学习过程,该过程特别是包括增强或减弱mcts框架的决策树。强化学习通常表示涉及智能体(agent)独
立学习策略以最大化所获得奖励(rewards)的一系列机器学习方法。在此,智能体不会事先示出在哪种情况下哪个动作最佳,而是会在特定时间点接收奖励,该奖励也能够是负面的。该智能体借助这些奖励来近似描述特定状态或动作的价值的收益函数。与该实施方式有关的细节能够从以下出版物中获得:
[0041]
[15]w.zhang and t.g.dietterich,“a reinforcement learning approach to job-shop scheduling”,in ijcai,citeseer,vol.95,1995,pp.1114-1120[w.zhang和t.g.dietterich,用于作业车间调度的强化学习方法,ijcai,citeseer,第95卷,1995,第1114-1120页];
[0042]
[16]r.s.sutton,a.g.barto,et al.,introduction to reinforcement learning,4th mit press cam-bridge,1998,vol.2[r.s.sutton,a.g.barto等人,强化学习简介,剑桥市mit出版社第四版,1998,第2卷];
[0043]
[17]s.mahadevan and g.theocharous,“optimizing production manufacturing using reinforcement learning.”,in flairs conference,1998,pp.372-377[s.mahadevan和g.theocharous,使用强化学习优化生产制造,flairs会议,1998,第372-377页];
[0044]
[18]s.j.bradtke and m.o.duff,“reinforcement learning methods for continuous-time markov decision problems”,in advances in neural information processing systems,1995,pp.393-400[s.j.bradtke and m.o.duff,用于连续时间马尔可夫决策问题的强化学习方法,神经信息处理系统进展,1995,第393-400页];
[0045]
[19]s.riedmiller and m.riedmiller,“a neural reinforcement learning approach to learn local dispatching policies in production scheduling”,in ijcai,vol.2,1999,pp.764-771[s.riedmiller和m.riedmiller,用于学习生产调度中的局部分派策略的神经强化学习方法,ijcai,第2卷,1999,第764-771页];
[0046]
[20]c.d.paternina-arboleda and t.k.das,“a multi-agent reinforcement learning approach to obtaining dynamic control policies for stochastic lot scheduling problem”,simulation modelling practice and theory,vol.13,no.5,pp.389-406,2005[c.d.paternina-arboleda和t.k.das,用于获得随机批次调度问题的动态控制策略的多智能体强化学习方法,模拟建模实践与理论,第13卷,第5期,第389-406页,2005];
[0047]
[21]t.gabel and m.riedmiller,“scaling adaptive agent-based reactive job-shop scheduling to large-scale problems”,in 2007ieee symposium oncomputational intelligence in scheduling,ieee,2007,pp.259-266[t.gabel和m.riedmiller,将基于自适应智能体的反应式作业车间调度扩展到大规模问题,2007年ieee调度计算智能研讨会,ieee,2007,第259-266页];
[0048]
[22]y.c.f.reyna,y.m.jim
′
enez,j.m.b.cabrera,and b.m.m.hern
á
ndez,“a reinforcement learning approach for scheduling problems”,investigaci
ó
n operacional,vol.36,no.3,pp.225-231,2015[y.c.f.reyna,y.m.jim
′
enez,j.m.b.cabrera和b.m.m.hern
á
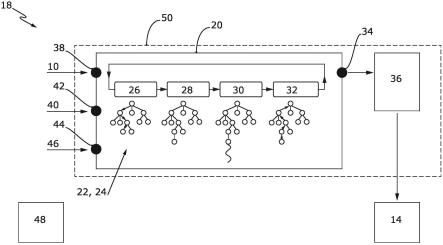
ndez,用于调度问题的强化学习方法,运筹学,第36卷第3期,第225-231页,2015];
[0049]
[23]s.qu,j.wang,s.govil,and j.o.leckie,“optimized adaptive scheduling of a manufacturing process system with multi-skill workforce and multiple machine types:an ontology-based,multi-agent reinforcement learningapproach”,procedia cirp,vol.57,pp.55-60,2016[s.qu,j.wang,s.govil和j.o.leckie,利用多技能劳动力和多种机器类型的制造工艺系统的优化自适应调度:一种基于本体的多智能体强化学习方法,程序cirp,第57卷,第55-60页,2016];
[0050]
[24]v.mnih,k.kavukcuoglu,d.silver,a.graves,i.antonoglou,d.wierstra,and m.ried-miller,“playing atari with deep reinforcement learning”,arxiv preprint arxiv:1312.5602,2013[v.mnih,k.kavukcuoglu,d.silver,a.graves,i.antonoglou,d.wierstra和m.ried-miller,利用深度强化学习玩雅达利,arxiv预印本arxiv:1312.5602,2013];
[0051]
[25]a.kuhnle,l.n.stricker,and g.lanza,“design,implementation and evaluation of reinforcement learning for an adaptive order dispatching in job shop manufacturing systems”,procedia cirp,vol.81,pp.234-239,2019[a.kuhnle,l.n.stricker和g.lanza,用于作业车间制造系统中自适应订单分派的强化学习的设计、实施和评估,程序cirp,第81卷,第234-239页,2019];
[0052]
[26]n.stricker,a.kuhnle,r.sturm,and s.friess,“reinforcement learning for adaptive order dispatching in the semiconductor industry”,cirp annals,vol.67,no.1,pp.511-514,2018[n.stricker,a.kuhnle,r.sturm和s.friess,用于半导体行业中自适应订单分派的强化学习,cirp年报,第67卷,第1期,第511-514页,2018];
[0053]
[27]j.schulman,s.levine,p.abbeel,m.jordan,and p.moritz,“trust region policy optimization”,in international conference on machine learning,2015,pp.1889-1897[j.schulman,s.levine,p.abbeel,m.jordan和p.moritz,信任区域策略优化,机器学习国际会议,2015,第1889-1897页]。
[0054]
监督学习被理解为是指借助预定义的解决方案进行训练。这种监督学习通常是机器学习的分支。在此,学习是指人工智能模仿规律性的能力。结果是从自然规律或专家知识中获知的,并用于教导系统。学习算法试图找到能够实现最准确的预测的假设。“假设”在此被理解为是指表示将假定的输出值分配给每个输入值的映射(abbildung)。即,该方法基于预先规定的并且其结果已知的要学习的输出。学习过程的结果能够与已知的正确结果进行比较,即,“被监督”。与该实施方式有关的细节能够从以下出版物中获得:
[0055]
[28]m.gombolay,r.jensen,j.stigile,s.-h.son,and j.shah,“apprenticeship scheduling:learning to schedule from human experts”,aaai press/international joint conferences on artificial intelligence,2016[m.gombolay,r.jensen,j.stigile,s.-h.son和j.shah,学徒调度:向来自人类专家的调度学习,aaai出版社/国际人工智能联合会议,2016];
[0056]
[29]h.ingimundardottir and t.p.runarsson,“supervised learning linear priority dispatch rules for job-shop scheduling”,in international conference on learning and intelligent optimization,springer,2011,pp.263-277[h.ingimundardottir和t.p.runarsson,作业车间调度的监督学习线性优先级分派规则,
学习与智能优化国际会议,施普林格,2011,第263-277页]。
[0057]
该算法优选地以单人游戏的形式执行。
[0058]
将基于蒙特卡罗树搜索框架的神经网络与借助于监督学习和自博弈与强化学习的方式进行的神经网络训练相结合,产生显著胜过板材加工中已知的优化的优化。
[0059]
优选的实施方式
[0060]
在方法步骤d)中的输出能够提供给制造执行系统(manufacturing-execution-system,mes)。这允许直接在生产机器上实施生产调度。
[0061]
除了已经提到的那些步骤之外,根据本发明的方法还能够包括以下工艺步骤中的一个或多个:
[0062]
c)对板材件进行去毛刺;
[0063]
d)对板材件进行接合、特别是熔焊和/或钎焊;
[0064]
e)对板材件进行涂覆,特别是通过涂漆和/或粉末涂覆;
[0065]
f)对板材件进行装配。
[0066]
这些工艺步骤中的每一个都能够通过生产机器执行并且通过根据本发明的方法优化。
[0067]
在本发明的优选配置中,根据本发明的方法使用算法alphago执行,在特别优选的配置中使用算法alphago zero执行。在这种情况下,该算法包括上述蒙特卡罗树搜索框架以及借助于监督学习和自博弈与强化学习的方式训练的神经网络。alphago或alphago zero在本发明的实施方式的框架内被发现是用于优化板材件制造的非常强大的算法。
[0068]
alphago zero算法能够在以下网页上查看:
[0069]
·
https://tmoer.github.io/alphazero/
[0070]
·
[0071]
https://towardsdatascience.com/alphazero-implementation-and-tutorial-f4324d65fdfc
[0072]
·
[0073]
https://medium.com/applied-data-science/how-to-build-your-own-alphazero-ai-using-python-and-keras-7f664945c188
[0074]
优选地,alphago或alphago zero用python和/或tensorflow来实施。与alphago或alphago zero的实施方式有关的更多细节能够从以下出版物中获得:
[0075]
[30]d.silver,a.huang,c.j.maddison,a.guez,l.sifre,g.van den driessche,j.schrittwieser,i.antonoglou,v.panneershelvam,m.lanctot,et al.,“mastering the game of go with deep neural networks and tree search”,nature,vol.529,no.7587,p.484,2016[d.silver,a.huang,c.j.maddison,a.guez,l.sifre,g.van den driessche,j.schrittwieser,i.antonoglou,v.panneershelvam,m.lanctot等人,利用深度神经网络和树搜索掌握围棋游戏,自然,第529卷,第7587期,第484页,2016]。
[0076]
[31]g.chaslot,s.bakkes,i.szita,and p.spronck,“monte-carlo treesearch:a new framework for game ai.”,in aiide,2008[g.chaslot,s.bakkes,i.szita和p.spronck,蒙特卡罗树搜索:游戏ai的新框架,aiide,2008]。
[0077]
[32]d.silver,j.schrittwieser,k.simonyan,i.antonoglou,a.huang,a.guez,
t.hubert,l.baker,m.lai,a.bolton,et al.,“mastering the game of gowithout human knowledge”,nature,vol.550,no.7676,p.354,2017[d.silver,j.schrittwieser,k.simonyan,i.antonoglou,a.huang,a.guez,t.hubert,l.baker,m.lai,a.bolton等人,在没有人类知识的情况下掌握围棋游戏,自然,第550卷,第7676期,第354页,2017]。
[0078]
[33]d.silver,t.hubert,j.schrittwieser,i.antonoglou,m.lai,a.guez,m.lanctot,l.sifre,d.kumaran,t.graepel,et al.,“mastering chess and shogi by self-play with a general reinforcement learning algorithm”,arxiv preprint arxiv:1712.01815,2017[d.silver,t.hubert,j.schrittwieser,i.antonoglou,m.lai,a.guez,m.lanctot,l.sifre,d.kumaran,t.graepel等人,通过利用强化学习算法进行自博弈来掌握国际象棋和将棋,arxiv预印本arxiv:1712.01815,2017]。
[0079]
在此引用的所有出版物和网站的披露内容的全范围都包括在本说明书中(通过引用并入本说明书)。
[0080]
更优选地,方法步骤a)中的训练是借助从该优化的生产调度启发式求取的解决方案进行的。这为神经网络的进一步优化提供了良好的起点。
[0081]
特别地,在此能够使用最早到期日(earliest-due-date,edd)解决方案形式的优化的生产调度。已经发现这些解决方案特别有利,因为在实践中经常出现使先前的生产调度过时的紧急作业。
[0082]
该方法的特别优选的配置涉及下述情况:优化包括废料最少化和生产时间优化两者的情况。这实现了既快速又便宜并且节省资源的制造。生产时间优化的目标特别是实现最小的总延迟和/或最小的总生产时间。
[0083]
方法步骤b)中的边界条件能够包括板材件的生产期限。生产时间优化在此能够考虑生产期限的满足。生产期限的满足能够具有比其他目标更高的优先级。
[0084]
对此替代地或附加地,在方法步骤b)中的边界条件能够包括板材件的价值,即,货币价值或价格。由此能够根据相应板材件的价值优化生产。通常,这能够使得板材件的价值、例如其制造延迟的代价在根据本发明的优化的框架内被评定。
[0085]
更优选地,该废料被分配废料分数,并且该生产期限的满足被分配生产期限分数,该分数基于这些板材件的价值,其中,该优化最小化废料分数和生产期限分数两者。分数的分配能够以与废料最少化同等的尺度处置或优化所述生产时间。
[0086]
在这种情况下,估计的最大可实现总分数值优选存储在决策节点中;优选地,将决策节点的相应决策是最好的概率(=权重)存储在连接决策节点的边沿上。
[0087]
例如,能够以价格的形式使用废料分数和生产期限分数。在此,能够将废料的价格与过晚地生产的板材件的价格进行权衡。
[0088]
在该方法的框架中允许基于以下函数进行优化:
[0089][0090]
其中,c(w)是所使用的总的材料(包括废料,即废弃物)的价值,ti和vi分别是作业部分i的延迟和价值。λ是惩罚延迟的参数。r
abs
反映了板材件的总和(相应地与生产期限成比例地减少)减去总材料成本。借助该公式能够用于生成神经网络的奖励,该奖励特别是缩
放到[0,1],其中,最大可能分数为r
max
(无延迟且无废料)。
[0091]
方法步骤b)到d)能够根据需要地由事件的发生而触发,其中,该事件经由事件接口读入。
[0092]
在此,事件的形式优选为:请求板材件的另外的加工,生产机器能力被释放,生产机器故障和/或紧急作业。
[0093]
在此,事件能够自动化地被触发并经由事件接口读入。特别优选地,事件由生产机器、室内定位系统和/或制造执行系统触发并经由事件接口读入。在室内定位系统的情况下,能够通过由室内定位系统的标签发送的事件以自动化方式进一步优化调度。
[0094]
为了进一步改进神经网络,在方法步骤e)中能够涉及读入在方法步骤d)中输出的生产调度的用户评价。
[0095]
本发明还涉及一种用于生产板材件的方法,其中,执行上述方法,并且接着基于优化的生产调度执行工艺步骤a)和b)。
[0096]
这种用于生产板材件的方法能够涉及在工艺步骤a)和b)之后基于优化的生产调度执行工艺步骤c)、d)、e)和/或f)。
[0097]
根据本发明的任务还通过一种用于执行如本文所述的方法的设备来实现,其中,该设备包括用于存储和执行神经网络的计算机、用于读入边界条件的边界条件接口和用于输出生产调度的生产调度接口。
[0098]
用户评价接口能够设置用于读入用户评价。神经网络能够呈基于云的形式,以便利用特别是匿名的用户评价进行训练。
[0099]
根据本发明的设备能够具有事件接口,并且还具有生产机器、室内定位系统(具有发送事件的多个标签)和/或制造执行系统,其中,由生产机器、室内定位系统和/或制造执行系统触发的事件能够经由事件接口读入。在这种情况下,能够以自动化方式或半自动化方式优化该设备。
[0100]
本发明的其他优点将从说明和附图中显现。同样,根据本发明,以上提及的特征和仍将进一步说明的那些特征能够分别自身单独地使用、或者以任何期望的组合作为多个使用。所示出和描述的实施例不应被理解为穷举,而是具有用于概述本发明的说明性特性。
附图说明
[0101]
图1示意性地示出了制造板材件的生产序列。
[0102]
图2示意性地示出了生产序列的优化。
具体实施方式
[0103]
图1示意性地示出了各种作业的制造。图1通过示例的方式示出了作业a
01
到a
10
。作业a
01
至a
10
包括生产产品p
01
至p
10
,这些产品是以它们相应的几何数据由多个、特别是不同的板材件制造的。为清楚起见,在图1中仅为板材件b1和b2提供了附图标记。
[0104]
如图1中的时钟符号所指示的,单个的板材件b1、b2具有不同的制造时间。此外,作业a
01
至a
10
具有不同的生产期限f
01
至f
10
。小猪存钱罐指示板材件b1、b2具有不同的(货币)价值。所描述的规定是板材件b1、b2的边界条件10。
[0105]
板材件b1、b2布置在金属板12上,使得废料尽可能地最少。从图1可见,这会导致不
同作业a
01
至a
10
的板材件b1、b2混合。板材件b1、b2在生产机器14上进行加工,在生产机器中,图1示出了用于裁切和分割板材件b1、b2的生产机器c1、c2(cut)、用于折弯板材件的生产机器b1、b2(bend)以及用于装配板材件的生产机器a1、a2(assemble)。此外,能够提供用于加工板材件b1、b2(例如,用于对板材件b1、b2进行去毛刺、接合和/或涂覆)的另外的生产机器14(图1中未示出)。具有板材件b1、b2的成品在图1中以附图标记16示出。
[0106]
在板材件b1、b2的不同边界条件10的情况下,在生产机器14上划分板材件b1、b2是高度复杂的问题。这尤其是因为各个工艺步骤会花费不同的时间长度,生产机器14会发生故障,和/或会出现紧急作业。
[0107]
图2中示出了根据本发明的生产序列的优化。图2示出了用于图1中的板材件b1、b2的优化制造或优化制造调度的设备18。为此,提供了算法20。算法20优选地可用作alphago或alphago zero。算法20包括蒙特卡罗树搜索框架22。蒙特卡罗树搜索框架22由神经网络24修改。这首先执行监督学习,即,基于启发式求取的问题解决方案进行训练。
[0108]
接着将自博弈与强化学习作为单人游戏进行。这在图2中的步骤26(selection)、28(expansion)、30(simulation)和32(backpropagation)中示出。在此,在步骤26中选择经由特定决策节点的决策路径,在步骤28中基于随机原则借助决策节点扩展决策树,在步骤30中模拟其结果,以及在步骤32中基于该模拟结果重新加权(增强或减弱)决策节点。多次重复步骤26至32。
[0109]
优选地,鉴于废料最少化(nesting)并且鉴于生产时间优化(scheduling)来执行如此进行的对制造步骤的尽可能最佳的划分的求取。该程序能被描述为通过嵌套(nesting)智能体和调度(scheduling)智能体进行的优化,其中,智能体在模拟环境中做出决策,并且根据决策的质量而获得其奖励(reward)。在此,模拟是钣金制造的反映。
[0110]
优化的生产调度经由生产调度接口34输出,特别是输出到制造执行系统36。制造执行系统36借助优化的生产调度来控制生产机器14,即,实际的板材制造。
[0111]
经由边界条件接口38向算法20提供边界条件10。经由用户评价接口42能够向算法20提供用户评价40。
[0112]
替代地或附加地能够提供事件接口44,经由该接口能够读入事件46。事件46能够由制造执行系统36、一个或多个生产机器14和/或室内定位系统48触发。事件46能够包括例如生产机器14的故障、生产机器14的能力被释放、生产期间的错误、新作业和/或作业修改。特别地,事件46包括刚刚在生产机器14中完成生产步骤的板材件b1、b2(参见图1)的进一步生产调度。
[0113]
算法20在计算机50上执行。计算机50能够呈基于云的形式,以便促进使用来自不同用户的用户评价40。制造执行系统36能够(如所指示的)在同一计算机上执行,或在不同计算机上执行。
[0114]
结合所有附图,总而言之,本发明涉及一种用于优化板材件b1、b2的制造的方法。该方法优化了为在不同的生产机器14上加工而进行的板材件b1、b2的分配,并且输出优化的生产调度。为此,提供了具有呈蒙特卡罗树搜索框架22形式的决策树和神经网络24的算法20。算法20借助自博弈和强化学习的方式用每个新查询进行训练。算法20的初步训练是通过监督学习的方式来实现的。算法20优选地主要关于板材件b1、b2的生产期限f
01
至f
10
的最小延迟,其次关于最少废料来优化生产调度。分数的分配能够对两个目标一起评分。该方法能够
包括接收查询触发事件46和/或根据生产调度来运行生产机器14。本发明还涉及一种用于执行该方法的设备18。
[0115]
附图标记清单
[0116]a01
至a
10
ꢀꢀ
作业
[0117]
p
01
至p
10
ꢀꢀ
产品
[0118]
b1、b2ꢀꢀꢀꢀ
板材件
[0119]f01
至f
10
ꢀꢀ
生产期限
[0120]
c1、c2ꢀꢀꢀꢀ
裁切生产机器
[0121]
b1、b2ꢀꢀꢀꢀ
折弯生产机器
[0122]
a1、a2ꢀꢀꢀꢀ
装配生产机器
[0123]
10
ꢀꢀꢀꢀꢀꢀꢀꢀ
边界条件
[0124]
12
ꢀꢀꢀꢀꢀꢀꢀꢀ
金属板
[0125]
14
ꢀꢀꢀꢀꢀꢀꢀꢀ
生产机器
[0126]
16
ꢀꢀꢀꢀꢀꢀꢀꢀ
产品
[0127]
18
ꢀꢀꢀꢀꢀꢀꢀꢀ
设备
[0128]
20
ꢀꢀꢀꢀꢀꢀꢀꢀ
算法
[0129]
22
ꢀꢀꢀꢀꢀꢀꢀꢀ
蒙特卡罗树搜索框架
[0130]
24
ꢀꢀꢀꢀꢀꢀꢀꢀ
神经网络
[0131]
26
ꢀꢀꢀꢀꢀꢀꢀꢀ
步骤-选择
[0132]
28
ꢀꢀꢀꢀꢀꢀꢀꢀ
步骤-扩展
[0133]
30
ꢀꢀꢀꢀꢀꢀꢀꢀ
步骤-模拟
[0134]
32
ꢀꢀꢀꢀꢀꢀꢀꢀ
步骤-反向传播
[0135]
34
ꢀꢀꢀꢀꢀꢀꢀꢀ
生产调度接口
[0136]
36
ꢀꢀꢀꢀꢀꢀꢀꢀ
制造执行系统
[0137]
38
ꢀꢀꢀꢀꢀꢀꢀꢀ
边界条件接口
[0138]
40
ꢀꢀꢀꢀꢀꢀꢀꢀ
用户评价
[0139]
42
ꢀꢀꢀꢀꢀꢀꢀꢀ
用户评价接口
[0140]
44
ꢀꢀꢀꢀꢀꢀꢀꢀ
事件接口
[0141]
46
ꢀꢀꢀꢀꢀꢀꢀꢀ
事件
[0142]
48
ꢀꢀꢀꢀꢀꢀꢀꢀ
室内定位系统
[0143]
50
ꢀꢀꢀꢀꢀꢀꢀꢀ
计算机
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
