一种用于卷积神经网络快速卷积运算的fpga架构
技术领域
1.本发明涉及一种用于卷积神经网络快速卷积运算的fpga架构,属于fpga架构技术领域。
背景技术:
2.在过去十年中,用来加速机器学习(machine learning,ml)算法的fpga设计和架构层出不穷,例如地平线大脑处理器(brain processing unit,bpu),ibm truenorth,寒武纪diannaoyu,阿里含光800等,这些加速设计提供了越来越多的计算资源和内存带宽。除此之外,还有许多基于fpga的解决方案也在被不断提出。百度推出的ai云计算芯片xpu就是一款基于fpga的云计算加速芯片。xilinx的xdnn和英特尔的dla则被称为覆盖处理器,它们将基于脉动阵列的矩阵乘法器映射到通用fpga上。这些基于fpga的解决方案不会修改fpga本身的架构,它们使用当前fpga上存在的可编程逻辑,如逻辑块(logic blocks,lbs)、乘法器(digital signal process,dsp)和块存储单元(random access memory,ram)实现。
3.与上述设计不同,另一种研究方向则是改变fpga本身的架构来加速ml算法。eldafrawy等人对可编程逻辑块(configurable logic block,clb)的架构进行了修改,以减少使用软逻辑实现的乘法和加法的面积消耗。aman等人在现有的fpga上增添了精度可变的张量单元用于ml加速。此外还有一些文章改变了dsp的结构,以提加速性能。pir-dsp修改了dsp48e2的架构,并且还在增加了寄存器,使其能更好的达到低精度深度神经网络的计算要求。yuan dai等人提出了基于pir-dsp改进的apir-dsp,提高了计算速度的同时降低了面积消耗。
4.卷积神经网络中大约有80%到90%的操作是卷积计算,而winograd算法能够通过减少乘法次数有效的对卷积计算进行加速已经被广泛证实。专利cn111459877a就是使用winograd对yolo v2卷积神经网络进行了加速。专利cn113283587a则对卷积计算中非3
×
3大小的卷积核进行了拆分,再进行winograd计算加速。
5.另外,对于绝大数神经网络应用,输入定点类型的数据便可达到良好的实验结果,更能提高速度,降低功耗。通常,对于一些精度要求不高的网络和场景,8bit数据位宽就可以满足精度需求。
6.上面提到的张量单元适用于矩阵乘法计算,但在计算卷积时效果不如winograd算法。专利cn113283587a虽然对非3
×
3形状的卷积运算的卷积核进行了拆分,但拆分后的卷积核仍然可以由f(2
×
2,3
×
3)大小的winograd计算实现。winograd算法尽管能够通过减少乘法次数来有效的优化卷积计算。但使用软逻辑(fpga上的lbs和互连)设计的winograd速度慢,而且面积效率低。由于winograd计算相比于卷积计算删去了累加操作,使用dsp仅用来进行乘法计算也造成了面积的浪费。除了核心的域转换模块和乘法器外,设计中还具有一些控制逻辑。使用lbs和fpga互连来设计这些逻辑也会减慢设计的整体操作。这些都使得在fpga上实现winograd计算卷积要比专用的asic慢得多。
技术实现要素:
7.本发明要解决的技术问题是:如何提供一种以winograd算法实现fpga上现有的lbs、dsp和互联资源实现winograd计算加速效果,并使之达到并超越asic的计算加速效果的方法。
8.为了解决上述技术问题,本发明提出的技术方案是:一种用于卷积神经网络快速卷积运算的fpga架构,包括若干winograd硬核计算单元,winograd硬核计算单元在fpga中以宽松方式进行排布;
9.winograd硬核计算单元包括图像数据变换模块、权重变换模块、基于快速乘法器的点乘模块和输出变换模块;权重转换模块和图像转换模块的输入端接收数据,权重转换模块和图像转换模块的输出端输入到点乘模块,点乘模块的输出端输入到输出转换模块的输入端,输出转换模块的输出端向外输出;
10.图像数据变换模块、权重变换模块和输出变换模块基于快速乘法器并通过位移和加法运算实现;
11.点乘模块通过基4-booth编码器和wallace树实现;
12.宽松方式进行排布,各winograd硬核计算单元之间均设有fpga的lbs以进行间隔。
13.上述方案的进一步改进是:点乘模块的输入端所接收到的两个8bit数分别为被乘数和乘数,乘数通过基4-booth编码器编码,编码后再与被乘数产生4个部分积,部分积送入wallace树进行4:2压缩,压缩结果通过超前进位加法器相加得到最终结果并从输出端向输出变换模块输出。
14.本发明带来的有益效果是:本发明通过设计winograd硬核计算单元并将其加入到fpga上,不同于直接使用fpga上资源实现winograd算法,减少了计算时lb、dsp和fpga的互联依赖,提高了最大时钟频率。
15.此外,fpga上特定功能的电路由各种模块通过互联资源连接实现,宽松的拓扑结构减小了winograd算法计算卷积时需要的通道数和开关盒的大小,从而减小了面积延时积。
附图说明
16.下面结合附图对本发明作进一步说明。
17.图1本发明实施例的一种用于卷积神经网络快速卷积运算的fpga架构的winograd硬核计算单元示意图。
18.图2本发明实施例的一种用于卷积神经网络快速卷积运算的fpga架构的点乘模块的示意图。
19.图3本发明实施例提到的快速乘法器编码方式。
20.图4本发明实施例提到的脉动阵列、使用fpga现有资源实现和含有winograd硬核的fpga实现设计的面积对比,面积分为逻辑块面积和布线面积。
21.图5本发明实施例的含有winograd硬核的fpga实现相比fpga现有资源实现设计面积减少百分比。
22.图6本发明实施例中脉动阵列、使用fpga现有资源实现和含有winograd硬核的fpga实现设计的频率对比。
23.图7本发明实施例中含有winograd硬核的fpga实现相比fpga现有资源实现设计频率提升百分比。
24.图8本发明实施例中宽松、柱状和密集三种拓扑结构的部分示意图(仅为整体架构的左下角)。
25.图9本发明实施例中宽松、柱状和密集三种拓扑结构实现设计消耗面积。
26.图10本发明实施例中宽松和柱状拓扑结构实现面积相比密集减少百分比。
27.图11本发明实施例中宽松、柱状和密集三种拓扑结构实现设计通道数。
28.图12本发明实施例中宽松和柱状拓扑结构实现设计通道数相比密集减少百分比。
29.图13本发明实施例中宽松、柱状和密集三种拓扑结构实现设计频率。
30.图14本发明实施例中宽松和柱状拓扑结构实现频率相比密集提升百分比。
31.图15本发明实施例中宽松、柱状和密集三种拓扑结构实现设计面积延时积及与密集相比面积延时积按减少百分比。
具体实施方式
32.实施例
33.本实施例的一种用于卷积神经网络快速卷积运算的fpga架构,包括若干winograd硬核计算单元,winograd硬核计算单元在fpga中以宽松方式进行排布。
34.winograd硬核计算单元包括图像数据变换模块、权重变换模块、基于快速乘法器的点乘模块和输出变换模块;权重转换模块和图像转换模块的输入端接收数据,权重转换模块和图像转换模块的输出端输入到点乘模块,点乘模块的输出端输入到输出转换模块的输入端,输出转换模块的输出端向外输出;
35.图像数据变换模块、权重变换模块和输出变换模块基于快速乘法器并通过位移和加法运算实现;
36.点乘模块通过基4-booth编码器和wallace树实现;
37.宽松方式进行排布,各winograd硬核计算单元之间均设有fpga的lb以进行间隔。
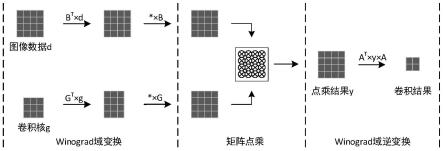
38.其中,winograd硬核计算单元基于二维winograd算法公式如下:
39.y=a
t
[(ggg
t
)
⊙
(b
t
db)]a
[0040]
“⊙”
代表矩阵点乘,y作为卷积结果,g为卷积核变换矩阵,b
t
为输入图像数据变换矩阵,a
t
为输出变换矩阵,g为大小为3*3的卷积核,d是大小为4*4的输入图像数据。
[0041]
对于二维卷积,设输出的尺寸为m
×
m,卷积核的尺寸为r
×
r,二维卷积可以用f(m
×
m,r
×
r)表示。本发明采用的f(2
×
2,3
×
3)尺寸的winograd的g、b
t
和a
t
如下所示:
[0042][0043]
设计的winograd硬核计算单元如图1所示,包括图像数据变换模块、权重变换模块、点乘模块和输出变换模块。
[0044]
f(2
×
2,3
×
3)尺寸的winograd的所有变换电路都可以通过加法和移位实现,不需要使用乘法,能有效减少资源消耗。
[0045]
矩阵点乘电路部分由16个8位快速乘法器组成。乘法器结构如图2所示,a为被乘数b为乘数,包括基4-booth编码模块(booth enc),部分积产生单元(gen pord),部分积(partial pord),4:2压缩器(4:2compressor,4:2csa),进位数据(carry),伪和(sum),超前进位加法器(lookahead carry adder,lca)。计算过程如下:先用基4-booth编码器对乘数b编码,编码结果再与被乘数相乘产生4个部分积,然后将部分积送入4-2压缩器进行压缩,压缩结果由lca相加得到最终的乘法结果。
[0046]
对8位宽乘数b进行编码(encode,enc),如图3所示取数,在最右边增加一位辅助位0,相邻3位为一组,从低位到高位逐次取数,前后相邻分组重叠一比特位,enc
1-enc4为取得的4组数,每个enc取得的三位数分别为b
i 1
、bi和b
i-1
。按照如下公式进行编码,得到4个编码结果,编码后的结果送入gen pord按公式分别与被乘数a生成4个部分积p
1-p4,因为enc编码结果仅为-2、-1、0、1、2,所以与a相乘仅用移位便可实现。
[0047]
enc=-2*b
i 1
bi b
i-1
[0048]
partiaprod=enc*a
[0049]
4:2csa有4个输出端口:包括4个待压缩数据p1、p2、p3、p4;2个输出端口:包括进位数据carry,伪和sum。
[0050][0051][0052]
最后的16位超前进位加法器采用4个4位超前进位加法器级联构成。
[0053]
对winograd计算单元verilog代码进行dc综合,使用freepdk45库,获得的延时和面积被缩放到20nm的fpga架构中,用于fpga架构设计。本专利将硬核的形状设计成与dsp相同的矩形,以便在fpga架构中进行排列布局。硬核的输入输出引脚定义为均匀分布,以达到更好的可路由性。
[0054]
本实施例的winograd硬核计算单元放置在fpga上的方式是通过vtr进行设计。vtr中的fpga架构以xml结构描述文件表示。
[0055]
xml架构描述文件顶层为《architecture》,顶层下有7个模块,分别为《models》、《tiles》、《layout》、《device》、《switchlist》、《segmentlist》、《directlist》和《complexblocklist》。
[0056]
fpga架构在stratixiv的xml结构描述文件基础上进行修改,加入winograd硬核计算单元需要修改顶层下的4个模块建模。
[0057]
①
《models》
[0058]
《model》用来声明bilf网表文件中使用的模型名称。要在网表中实例化winograd硬核计算单元,必须先在xml中声明model名称和引脚名称。
[0059]
在定义引脚的同时,还需要使用combinational_sink_ports来对引脚时序依赖进行建模,对输入输出建立依赖关系。
[0060]
②
《complexblocklist》
[0061]
《complexblocklist》下级的《pb_type》用来描述winograd硬核计算单元内部结构,对其内部进行建模。
[0062]
《pb_type》的建模包含两个层次:顶层模块和建模原语。
[0063]
顶层模块中需要声明模块名称和全部的端口信息。
[0064]
建模原语是层次结构中的最底层。原语对应打包阶段之前的映射中用户网表中出现的元素,blif中的模型必须在pb_type里的建模原语进行描述。winograd硬核计算单元以黑盒形式进行描述,黑盒指的是不对其内部进行详细描述,只描述端口和内部延时。通过dc综合得到的电路关键路径延时在建模原语中使用delay_constant属性来进行设置。
[0065]
顶层模块和原语模块之间还需要模块内互连《interconnect》。原语模块中用到的的端口和引脚与顶层模块声明的端口通过互连元件相互连接。《interconnect》与建模原语处在同一级别。
[0066]
③
《tiles》
[0067]
《tiles》描述winograd硬核计算单元外部结构。《tile》中包含计算单元的名字,长宽,面积,输入输出引脚数量,引脚位置还有引脚多少条导线相连。通过dc综合得到的电路面积在《tile》中进行设置。
[0068]
④
《layout》
[0069]
《layout》定义了fpga架构的布局信息,《tiles》中的各种物理块都会按照规定的顺序布置在网格中。网格内单元有优先级,高优先级覆盖低优先级。最外面围一圈io优先级最高,内部由lbs填满优先级最低,再用将次搞优先级的硬核核安置在网格中。需要将winograd硬核计算单元按照一定规则布置在fpga架构中。
[0070]
为验证winograd硬核计算单元效果的测试电路与脉动阵列在计算卷积时有相同的计算能力,在相同的时钟周期能够计算的卷积框数量一致,winograd电路的实现分别由只含有dsp、lbs和输入输出端口(io port,io)的fpga和含有winograd硬核计算单元的fpga实现,比较内容为fpga上消耗的面积和关键路径延时。
[0071]
通道宽度意为不影响电路最大频率的情况下所需的fpga最小通道数,采用二分查找法寻找所需的最小通道数。由于数组元素的有序性和互异性,通过得到数组内元素间相对的大小关系,定义三个变量:两个边界变量确定查找范围,一个取值是两个边界变量中间值的中间变量用于同被查找值比较大小、在保证右边界最大时钟频率不变得到前提下改变边界变量的值进而缩小查找区间的范围、重新确定中间值,并重复这一过程直到最大时钟频率不变时通道宽度最小,退出循环。
[0072]
图4、图5、图6和图7展示了与脉动阵列具有相同卷积计算能力的winograd在计算卷积时的结果,展示了使用不同大小的脉动阵列和f(2
×
2,3
×
3)大小的winograd硬核在实现卷积计算时(使用宽松放置策略)的频率和面积变化。在计算卷积时,对于与32
×
32大小的脉动阵列有相同卷积计算能力的winograd设计来说,当使用f(2
×
2,3
×
3)winograd硬核时比软逻辑实现总面积减少了53%,时钟频率加快了72%。在图3中可以看到,winograd硬核实现减少的面积大多为互连消耗的面积。
[0073]
图8为winograd硬核计算单元再fpga上的三种不同的拓扑结构,从左到右依次为宽松、柱状和密集。如图9、图10所示,密集架构有最大的总面积消耗,宽松架构则有3种拓扑结构中最低的总面积消耗,相比密集架构总面积最大降低了43%。如图11、图12所示,柱状架构比宽松架构通道宽度大,因为winograd硬核进出数据量很大,柱状架构彼此贴近导致更高的路由拥塞,更大的通道宽度也导致了面积消耗增大,但同时由于路径变短延时也会相应减小,相比密集架构最大时钟频率提升28%,如图13、图14所示。如图15所示,以面积延
时积为评价标准,可见宽松架构有最小的面积延时积。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。