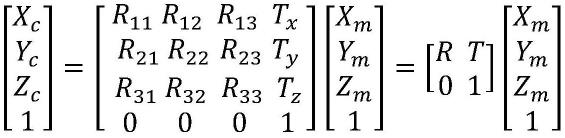
1.本发明涉及信息检索技术领域,具体是一种融合主题模型的图书 馆平台语义检索方法。
背景技术:
2.随着数字化环境的形成和信息技术的飞速发展,图书馆的信息资 源持续不断增加。面对数字时代的各类信息资源,用户期望能够准确 搜索、便捷获取、远程利用海量的信息资源,为了更好地满足用户的 需求,图书馆界积极努力地改进和完善自己的信息资源检索平台。
3.当前图书馆平台信息资源检索方法主要采用关键词检索技术,通 过严格地匹配文献中的查询词统计文献中查询词的次数得到查询结 果。利用传统的关键词检索技术在图书馆平台进行信息检索时因为参 与匹配的是固定的关键词,忽略了其所要延伸表达的含义,导致在面 对同样的检索意图时由于不同用户关键词的不同返回了多样的检索 结果。自然语言中一词多义和一义多词的现象,更加影响了用户的检 索质量。
4.关键词匹配技术在信息的语义和语用的揭示上存在局限性,无法 满足用户日益提高的检索需求,这为语义检索的提出提供了条件。语 义检索就是让用户在输入所需信息作为检索词的时候,检索结果中能 包含检索词的相关的或者更多的信息。随着语义网的出现和信息技术 的发展,基于语义的检索方式逐渐被应用于各类检索系统中,语义检 索在图书馆的应用也开始成为国内外学者研究的焦点。
5.近些年语义检索以主题模型和深度学习方法为主。主题模型是一 种用来在一系列文档中发现抽象主题的统计模型,其能够从主题相关 词的角度实现语义检索。深度学习模型抽取文本深层语义特征,在此 基础上实现更高质量的科学数据集检索。深度学习虽然能够提高检索 效果,但是其计算量大,硬件需求高,模型设计复杂,可解释性差。
技术实现要素:
6.本发明的目的在于提供一种融合主题模型的图书馆平台语义检 索方法,以解决上述背景技术中提出的问题。
7.本发明的技术方案是:一种融合主题模型的图书馆平台语义检索 方法,包括以下步骤:
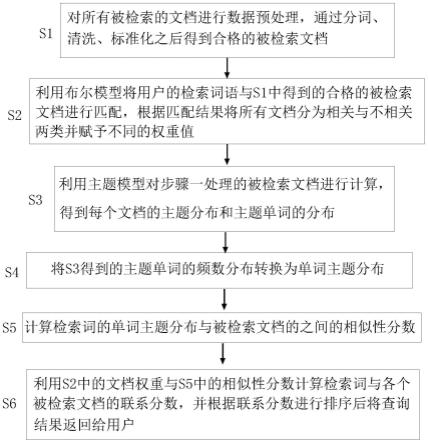
8.s1、对所有被检索的文档进行数据预处理,通过分词、清洗、标 准化之后得到合格的被检索文档;
9.s2、利用布尔模型将用户的检索词语与s1中得到的合格的被检 索文档进行匹配,根据匹配结果将所有文档分为相关与不相关两类并 赋予不同的权重值;
10.s3、利用主题模型对s1处理的被检索文档进行计算,得到每个 文档的主题分布和主题单词的分布;
11.s4、将s3得到的主题单词的频数分布转换为单词主题分布;
12.s5、计算检索词的单词主题分布与被检索文档的之间的相似性分 数;
13.s6、利用s2中的文档权重与s5中的相似性分数计算检索词与各 个被检索文档的联系分数,并根据联系分数进行排序后将查询结果返 回给用户。
14.优选的,所述s1中,数据预处理包括:将文档集合d进行分词 操作,对文档dn分词后得到dn=(w1,w2,
……
);接着对分词后的文 档进行清洗操作,清洗过程中去掉无用的标签、特殊符号和停用词; 最后对文本内容进行标准化,将部分文本中的同一个单词具有不同的 形态转化为同一种形式。
15.优选的,所述s2中,在基于布尔模型的匹配中,被检索文档d可 表示为:d=(d1,d2,d3,...,dn),用户的检索q可表示为:q= (q1,q2,q3,...),其中dn表示第n个被检索文档,q1表示第一个检索词; 布尔模型中有三个主要逻辑算符,分别是与(and),或(or),非(not), 假设用户查询包含两个检索词q1和q2,考虑不同逻辑算符下单词的条 件,条件有四个:(1)q
1 and q2;(2)q
1 or q2;(3) q
1 not q2,(4)q
2 not q1,为不同文档赋予权重的公式可以表示为:
[0016][0017]
其中,表示文档dn的权重,因此,被检索文档具有不同的权 重系数。
[0018]
优选的,所述s3中,主题模型的生成过程共分为四步:
[0019]
s31、对于主题z,根据dirichlet分布dir(β)得到该主题上的 一个单词多项式分布向量φ;
[0020]
s32、根据泊松分布p得到文本的单词数目n;
[0021]
s33、根据dirichlet分布dir(α)得到该文本的一个主题分 布概率向量θ;
[0022]
s34、对于该文本m个单词中的每一个单词wm,先从θ的多项式 分布multinomial(θ)随机选择一个主题z;再从主题z的多项式条 件概率分布multinomial(φ)选择一个单词作为wm;
[0023]
利用gibbs抽样方法对上面的生成过程进行计算,主题模型的联 合概率分布函数为:
[0024][0025]
gibbs抽样算法通过积分避开了实际待估计的参数,转而对每个 单词的主题进行采样,每个单词的主题确定下来后,参数可以在统计 频次后计算出来,故参数估计问题变为计算单词序列下主题序列的条 件概率,其公式如下:
[0026][0027]
其中,z
nm
表示对文档n中第m个单词对应的主题变量;-nm表 示不包括其中的第m项;表示k主题中出现词v的次数;βv是词 v的dirichlet先验;表示文档n出现主题k的
次数;αk是主题k 的dirichlet先验;gibbs采样的基本思想是固定某一维度z
nm
,然 后通过其他维度z-nm
的值来抽样该维度的值,马尔科夫链通过转移概 率矩阵可以收敛到稳定的概率分布;当马尔科夫链在迭代阶段消除初 始参数的影响,到达算法收敛时,根据当前z的分布计算文档在主题 上的分布θ和主题在单词上的分布φ,公式为:
[0028][0029][0030]
其中,φ
k,v
表示主题k中词v的概率,θ
n,k
表示文档n中主题k 的概率。
[0031]
优选的,所述s4中,单词-主题频数分布表示为:
[0032][0033]
优选的,所述s5中,当用户输入检索词v时,得到分布 和 为了计算检索词与被检索文档中的 关系,通过下列公式计算相似性:
[0034][0035]
优选的,所述s6中,返回的检索结果表示为:
[0036][0037]
根据值的大小的排序,将被检索文档的结果返回给用户,的值越大,返回结果越靠前;值越小,返回结果越靠后。
[0038]
本发明通过改进在此提供一种融合主题模型的图书馆平台语义 检索方法,与现有技术相比,具有如下改进及优点:
[0039]
本发明利用布尔模型区分文档的重要性并给每一个文档赋予重 要性权重,缓解了布尔检索中只考虑关键词匹配文档的问题;将文档 重要性权重与基于主题的文档和检索词相似性有机融合,同时考虑了 关键词检索与语义检索,可以大大提高图书馆平台语义检索效率,有 效满足用户检索知识服务的需求。
附图说明
[0040]
下面结合附图和实施例对本发明作进一步解释:
[0041]
图1是本发明的流程框图;
[0042]
图2本发明在不同主题数目下的平均coherence指标值的变化图;
[0043]
图3为本发明在主题数目为10时不同迭代次数下的coherence指 标值的变化图;
[0044]
图4为本发明在检索词为“艺术”下的检索效果precision值的变 化图;
[0045]
图5为本发明在检索词为“艺术”下的检索效果recall值的变化 图;
[0046]
图6为本发明在检索词为“艺术”下的检索效果f值的变化图。
具体实施方式
[0047]
下面对本发明进行详细说明,对本发明实施例中的技术方案进行 清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施 例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术 人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于 本发明保护的范围。
[0048]
本发明通过改进在此提供一种融合主题模型的图书馆平台语义 检索方法,本发明的技术方案是:
[0049]
如图1所示,一种融合主题模型的图书馆平台语义检索方法,包 括以下步骤:
[0050]
s1、对n个被检索文档集合d进行数据预处理的操作:首先,将 文档集合d进行分词操作,分词是将文档划分为一系列的单词或者短 语,选择结巴进行分词,对文档dn分词后得到dn=(w1,w2,
……
); 然后,对分词后的文档进行清洗操作,清洗过程中去掉无用的标签、 特殊符号和停用词;最后,对文本内容进行标准化,将部分文本中的 同一个单词具有不同的形态转化为同一种形式;
[0051]
s2、利用布尔模型将检索词与预处理的文档集合d进行匹配,在 基于布尔模型的匹配中,被检索文档d可表示为: d=(d1,d2,d3,
…
,dn),用户的检索q可表示为:q=(q1,q2,q3,
…
), 其中dn表示第n个被检索文档,q1表示第一个检索词。布尔模型中有 三个主要逻辑算符,分别是与(and),或(or),非(not)。假设用户查 询包含两个检索词q1和q2,考虑不同逻辑算符下单词的条件。条件有 四个:(1)q
1 and q2;(2)q1or q2;(3)q
1 not q2,(4)q2not q1,为 不同文档赋予权重的公式可以表示为:
[0052][0053]
其中,表示文档dn的权重。因此,被检索文档具有不同的权重系 数;
[0054]
s3、利用主题模型对预处理文档集合d进行计算,d中共有n 个文档,主题模型的生成过程共分为四步,第一步对于主题z,根据 dirichlet分布dir(β)得到该主题上的一个单词多项式分布向量 φ;第二步根据泊松分布p得到文本的单词数目n;第三步根据 dirichlet分布dir(α)得到该文本的一个主题分布概率向量θ; 第四步对于该文本m个单词中的每一个单词wm,先从θ的多项式分 布multinomial(θ)随机选择一个主题z;再从主题z的多项式条件 概率分布multinomial(φ)选择一个单词作为wm。利用gibbs抽样 方法对上面的生成过程进行计算,主题模型的联合概率分布函数为:
[0055]
[0056]
gibbs抽样算法通过积分避开了实际待估计的参数,转而对每个 单词的主题进行采样,一旦每个单词的主题确定下来,参数就可以 在统计频次后计算出来。因此,参数估计问题变为计算单词序列下 主题序列的条件概率,其公式如下:
[0057][0058]
其中,z
nm
表示对文档n中第m个单词对应的主题变量;-nm表 示不包括其中的第m项;表示k主题中出现词v的次数;βv是词 v的dirichlet先验;表示文档n出现主题k的次数;αk是主题k 的dirichlet先验。gibbs采样的基本思想是固定某一维度z
nm
,然 后通过其他维度z-nm
的值来抽样该维度的值,马尔科夫链通过转移 概率矩阵可以收敛到稳定的概率分布。当马尔科夫链在迭代阶段消 除初始参数的影响,到达算法收敛时,根据当前z的分布计算文档 在主题上的分布θ和主题在单词上的分布φ,公式为:
[0059][0060][0061]
其中,表示主题k中词v的概率,θ
n,k
表示文档n中主题k的概 率;
[0062]
s4、通过s3的计算,可以得到θ和φ分布,计算过程中的中间 结果为和单词-主题频数分布表示为:
[0063][0064]
s5、根据s4计算的单词-主题频数分布和s3得到的文档-主 题的分布θ
n,k
,计算两个分布中基于主题的相似性。当用户输入检索 词v时,得到分布和 为了计算检索词与被检索文档中的关 系,通过下列公式计算相似性:
[0065][0066]
需要进一步说明的是,本发明为了验证提出的融合主题模型的 图书馆平台语义检索方法的检索效果,在复旦大学提供的中文语料 上进行实验。为保证实验的平衡性,从中文语料中选取9800个文档 作为实验数据集,共包含20个类别。每个文档包含文献号、原文出 处、原刊期号、标题正文等信息。对所有文档进行文本预处理,通 过分词、清洗、标准化之后得到不同词汇的实验数据集。在清洗过 程中去掉无用的标签、特殊符号和停用词。
[0067]
为了评估本发明提出算法的性能,本发明通过调节重要系数a 的值,比较不同重
要系数a值下的检索性能。选取检索性能评价指 标为precision,recall和f值,利用如下公式进行相关计算。
[0068][0069][0070][0071]
在三个公式中,num
total
为总共检索到的文档数量, num
actual
为提出方法得出的检索词与被检索文档相关的文档数 量,num
correct
为正确的检索出的文档数量,为正确的检索出的文档数量,
[0072]
实验结果如图4到图6所示。横轴表示检索结果展示数目,纵 轴分别表示precision,recall和f值。其中,不同的曲线表示不同 重要系数a下的评价指标值。可以看出,本发明在利用关键词匹配 和语义检索的情况下能够取得最佳结果,意味着本发明有效地解决 了图书馆平台的检索问题。
[0073]
s6、根据s2得到的不同文档的权重分数和s5得到的相似性结 果,得到不同文档与检索词的关系,将被检索文档进行相关排序, 最终给用户展示返回的检索结果。
[0074]
返回的检索结果表示为:
[0075][0076]
根据值的大小的排序,将被检索文档的结果返回给用户。的值越大,返回结果越靠前;值越小,返回结果越靠后。
[0077]
本发明设计实验来比较不同重要系数a下的检索效果。图2显示 了在不同主题数目下的coherence指标值的变化图,图3显示了在不 同迭代次数下的coherence指标值的变化图。根据图2和图3的结果 确定实验中主题模型的主题数目和迭代次数的设置。图4、5、6显示 了在检索词为“艺术”下的检索效果precision、recall、f值的变 化图。因为检索结果的展示数目根据不同平台的设置存在一定的差 别,因此横轴表示不同数目的检索结果展示,从1到20。图4到图6 中,不同的指标值曲线表示不同的重要系数a。可以看出本发明在同 时考虑关键词匹配和语义检索的情况下,利用不相关文档的检索性能 低于利用相关文档的检索性能,同时考虑关键词匹配和语义检索能够 取得最佳的语义检索效果。
[0078]
上述说明,使本领域专业技术人员能够实现或使用本发明。对 这些实施例的多种修改对本领域的专业技术人员来说将是显而易见 的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的 情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相 一致的最宽的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。