一种风机运维数据驱动的lstm-sa神经网络超短期功率预测方法
技术领域
1.本发明涉及风机功率预测技术领域,特别涉及一种风机运维数据驱动的lstm-sa神经网络超短期功率预测方法。
背景技术:
2.风能是重要的可再生能源,有助于我国弥补能源缺口,按期实现双碳目标。近年来,我国风力发电的规模不断扩大,稳居世界第一。但受到风资源等多因素的影响,风力发电具有波动性、间歇性和无序性,并网时会对电网稳定带来不利影响。为了减少风电波动,提高风能利用率,需要准确预测风电功率,采取合适的控制策略。
3.预测风电功率的方法包含物理方法、统计方法与人工智能方法。物理方法是根据风电场站地形地貌,将数值天气预报结果转化为实际环境条件下的风资源信息,根据风电机组性能参数计算预测功率。统计方法通过研究风电场的历史数据,建立数值天气预报气象要素与实际功率之间的统计关系,由此对风电功率进行预测。这两类方法依赖准确的天气预报和准确地统计关系,精度不高。
4.基于人工智能技术的功率预测方法无需建立物理模型,在拟合高维非线性样本空间时有很大优势。但人工智能的预测方法大部分由数据直接驱动,具备黑箱性质,物理可解释性差。文献【基于改进lstm的风电功率预测模型研究】提出了优化神经网络模型来提高预测精度,文献【基于时序分解及机器学习的风电功率组合预测模型】提出了使用模态分解的方法进行数据增强,通过提高数据质量来提高模型的预测精度,文献【基于注意力机制的卷积神经网络-长短期记忆网络的短期风电功率预测】使用cnn来增强数据,使用了注意力机制来优化模型参数权重,实现了更高精度的预测。
5.但这些方法仅利用单一数据变量搭建模型实现功率预测,没有考虑风机实际工作时,其他变量和功率的关系,存在预测精度不高、实用性不强等缺点。文献【ultra short-termprobabilityprediction ofwindpowerbased on lstm network and condition normal distribution】利用历史风速和功率数据进行功率预测,建立预测误差的正态分布模型。文献【wind turbine dataanalysis and lstm-based prediction in scada system】基于风和能量的关系,分别预测了功率相关的四个特征量:有功功率、风速、风向、理论功率。但并没有解决如何同时通过四个量来预测风机功率的问题。
6.文献【bansal j c,farswan p.wind farm layout using biogeography based optimization[j].renewable energy】在数据中加入气象因素和风机自身状态显著提高模型预测精度。但气象数据的加入会导致样本空间变大、计算复杂度增加、模型参数更加臃肿,造成lstm训练的效率下降、效果变差。
[0007]
因此,如何解决上述相关文献对风机功率预测存在的弊端,提供一种较为快速、准确的预测方法,成为同行从业人员亟需解决的问题。
技术实现要素:
[0008]
本发明的目的在于提供一种风机运维数据驱动的lstm-sa神经网络超短期功率预测方法,能解决风电训练数据较少,而精度要求较高的超短期功率预测难题。
[0009]
为实现上述目的,本发明采取的技术方案为:
[0010]
本发明提供一种风机运维数据驱动的lstm-sa神经网络超短期功率预测方法,包括以下步骤:
[0011]
获得目标风力发电机的运维数据,对所述运维数据进行预处理;所述运维数据包括:风速、叶片偏转角、偏航角、湿度和温度;
[0012]
将预处理后的风机运维数据,使用lasso算法和皮尔逊相关系数法进行特征筛选,获得对风电功率变化影响较大的筛选数据;
[0013]
基于所述筛选数据,训练fnn模型,获得风机发电功率与所述筛选数据的函数关系;
[0014]
基于训练获得的fnn模型,使用链式求导法则求得发电功率的变化率;
[0015]
将所述发电功率的变化率和历史功率值一起作为训练集,对lstm网络进行训练,采用注意力机制对lstm网络模型进行优化,得lstm-sa神经网络模型;
[0016]
基于lstm-sa神经网络模型对所述目标风力发电机的下一时刻输出功率进行预测。
[0017]
进一步地,获得目标风力发电机的运维数据,对所述运维数据进行预处理,包括:
[0018]
周期性的间隔预设时间采集目标风力发电机的运维数据;
[0019]
去除所述运维数据的空值、异常值,并进行归一化处理。
[0020]
进一步地,预处理后的风机运维数据使用lasso算法进行特征选择,将特征系数近似0或者等于0的运维数据筛除。
[0021]
进一步地,所述lasso算法公式如下:
[0022][0023][0024]
(1)式中,s表示调和参数;yi为目标函数值,为风力发电机在i时刻输出的有功功率,α为yi的估计值,x
ij
为在i时刻,风机的状态特征数值,β为特征值x的系数,argmin意思是使得右式的值最小的取值。
[0025]
进一步地,预处理后的风机运维数据使用皮尔逊相关系数法进行特征选择,保留相关系数接近1的运维数据。
[0026]
进一步地,所述皮尔逊相关系数法公式如下:
[0027][0028]
(2)式中,xi为特征值,为该特征值的平均值,yi为目标值,为目标值的平均值。
[0029]
进一步地,基于训练获得的fnn模型,使用链式求导法则求得发电功率的变化率,包括:
[0030]
通过fnn求得功率p对风速s的偏导:
[0031][0032]
(11)式中,f(s,θ)表示隐函数;s表示风速;θ表示叶片偏转角;p'表示发电功率p的导数;
[0033]
使用反向传播算法,损失函数loss对全局求偏导,求得损失函数对风速s的偏导和损失函数对p的偏导;通过链式求导法则,进而求得p',作为发电功率的变化率。
[0034]
进一步地,对lstm网络进行训练时:
[0035]
梯度下降优化算法使用adam,损失函数选择mse,设置lstm-sa隐藏层为2层,隐藏层神经元为6个,lstm层为1层,lstm层后接sa层和全连接层。
[0036]
与现有技术相比,本发明具有如下有益效果:
[0037]
本发明实施例提供的一种风机运维数据驱动的lstm-sa神经网络超短期功率预测方法,使用风机的运维数据来提取发电功率与客观环境之间的关系,推导出了神经网络的对输入值的求导公式,以此公式来求得这种关系,用lstm神经网络处理历史功率数据,用自注意力机制优化了lstm的隐藏层,提高了模型的精度和泛化能力。与传统的深度学习模型lstm、gru、rnn对比,lstm-sa模型具备更高的预测准确度和泛化能力,且收敛效率更高,基于该lstm-sa模型对风电功率的预测更准确。
附图说明
[0038]
图1为风机运维数据驱动的lstm-sa神经网络超短期功率预测方法流程图;
[0039]
图2为lstm的门控机制示意图;
[0040]
图3为自注意力模型计算过程示意图;
[0041]
图4为lstm self-attention的模型结构图;
[0042]
图5为风机运维数据驱动的lstm-sa神经网络超短期功率预测算法流程图;
[0043]
图6为风速、叶片角度、功率三维散点图;
[0044]
图7为风速、叶片角度、功率二维散点图;
[0045]
图8为fnn损失函数下降趋势图;
[0046]
图9为fnn回归预测示意图;
[0047]
图10为lstm-sa结构图;
[0048]
图11为lstm-sa损失函数下降过程;
attention)对lstm模型隐藏层进行优化。测试结果表明,与其他预测算法比较,具有更高的预测精度、更快的收敛速度以及较好的稳定性等优点,能解决风电训练数据较少,而精度要求较高的超短期功率预测难题。
[0062]
1、对在上述步骤s20-s50中的模型构建原理进行说明:
[0063]
1.1、在步骤s20中,lasso和皮尔逊系数法实现特征筛选:
[0064]
lasso回归,lasso(least absolute shrinkage and selection operator,tibshirani(1996))回归方法的实质是一种压缩估计。它通过惩罚函数使得模型更加精炼,在特征很多的时候,可以把一些特征的系数压缩或者置零,相关性越小的特征,被其系数置零的可能性越大,留下的非零系数则对应相关性更大的特征,从而实现对特征的筛选。
[0065]
对于一般的回归模型,各个特征一般被认为彼此独立,为了消除不同特征的不同量纲对回归效果的干扰,需要对全部自变量做标准化处理。即,使自变量的均值为0,方差为1。一般回归模型的lasso回归公式为:
[0066][0067][0068]
(1)式中,s表示调和参数;yi为目标函数值,为风力发电机在i时刻输出的有功功率,α为yi的估计值,x
ij
为在i时刻,风机的状态特征数值,β为特征值x的系数,argmin意思是使得右式的值最小的取值。
[0069]
其中,s≥0是调和参数,对于任意的s有α的估计值通过调整s,可以使得总体的回归系数减小。令s0=∑j|βj|,当s≥s0时,某些特征的系数会减小,甚至近似于0或者等于0,这些无关的或关系极小的自变量将会被筛除,从而使回归模型的精度及可解释性提高。
[0070]
皮尔逊相关系数法(pearson correlation)是衡量向量相似度的一种方式。输出范围为-1到 1,其中0代表无相关性,负值代表负相关,正值代表正相关。皮尔逊相关系数法的公式如下:
[0071][0072]
一般认为person越接近1相关性越高。
[0073]
在本公式中,xi为特征值,为该特征值的平均值,yi为目标值,为目标值的平均值。
[0074]
使用lasso算法和person算法对风电数据进行运维数据筛选,可以获得对风电功
率变化起主要作用的特征。
[0075]
1.2、在步骤s30中,fnn原理
[0076]
fnn是一种最基础的bp神经网络,其特点在于使用反向传播(backpropagation,bp)算法来调整模型权重,该算法核心是当网络输出的值与实际值有偏差时,可以将这一差值从后往前传递,使得每一层网络的权值朝着减小偏差(梯度下降)的方向调整,达到调整全局的目的。经过不断地前向计算求误差,反向计算求导数,调整模型参数,使偏差降低到预计范围。
[0077]
根据通用近似定理(universal approximation theorem,cybenko(1989)),fnn具有很强的拟合能力,可以拟合任何连续的非线性函数。运维数据与风电功率的关系为高维的非线性函数,使用fnn可以高精度拟合。
[0078]
1.3、在步骤s50中,lstm self-attention原理
[0079]
上述内容提及的方法为搭建第一阶段的回归模型提供了思路和方法,而为了搭建第二阶段的预测模型,本发明选择了lstm self-attention。
[0080]
lstm是循环神经网络(recurrent neural network,rnn)的一种变体,其特点是在处理长时间序列的同时,通过引入门控机制,避免了长程依赖问题。lstm神经元门控机制示意图如图2所示。
[0081]
lstm的“门”是一种软门,取值在(0,1)之间,表示以一定的比例筛选信息。图2中lstm循环单元结构中有遗忘门f
t
,输入门i
t
,输出门o
t
,实现对信息有选择的保存。遗忘门f
t
控制上一时刻内部状态c
t-1
中需要舍弃多少信息;输入门i
t
控制当前时刻的输入中有多少信息需要保存;输出门o
t
控制当前时刻的内部状态c
t
中有多少信息可以输出给外部状态h
t
。三个门的计算公式为:
[0082]ft
=σ(wf[h
t-1
,x
t
] bf)
ꢀꢀ
(3)
[0083]it
=σ(w
it
[h
t-1
,x
t
] bi)
ꢀꢀ
(4)
[0084]ot
=σ(w
ot
[h
t-1
,x
t
] bo)
ꢀꢀ
(5)
[0085]
其中,σ为logistic函数(sigmoid函数),x
t
为当前时刻的输入,h
t-1
为上一时刻的输出。
[0086]
用矩阵表达为:
[0087]
c'
t
=σ(wc[h
t-1
,x
t
] bc)
ꢀꢀ
(6)
[0088][0089]ct
=f
t
·ct-1
i
t
·
c'
t
ꢀꢀ
(8)
[0090]ht
=o
t
·
tanh(c
t
)
ꢀꢀ
(9)
[0091]
其中,x
t
为当前的输入,w和b为网络参数。
[0092]
标准的lstm采用的是传统编码-解码器结构。输入lstm的数据序列无论长短都被编码成固定长度的向量表示。虽然lstm的记忆功能可以保存长期状态,但是在实际应用过
程中,面对庞大的高维数据集时不能很好地加以处理,在训练时模型可能会忽略某些重要的时序信息或者关注某些不重要的信息,造成模型的性能变差,影响预测精度。针对lstm自身存在的缺陷,文章在lstm的隐状态层加入self-attention(自注意力)机制,让模型能够判断输入时序信息的不同时刻的重要程度,提高lstm的收敛速度,且不会增加模型的计算复杂度。自注意力模型采用查询-键-值(query-key-value,qkv)模式。具体计算过程如下:
[0093]
对于公式(9)得到的外部输出h
t
,将其线性映射到三个不同的空间:
[0094]
q=w
qht
[0095]
k=w
kht
[0096]
v=w
vht
ꢀꢀ
(10)
[0097]
q,k,v分别是查询向量、键向量、值向量构成的矩阵。
[0098]
对于每一个查询向量qn∈q,利用键值对注意力机制,求得输出向量。
[0099]hn
=att((k,v),qn)
[0100]
让hn代替h
t
输出到外部空间参与下一轮运算,计算过程如图3所示。
[0101]
综上,lstm self-attention的模型结构如图4所示,fc层为全连接层。
[0102]
1.4、fnn对输入层变量求偏导的算法设计
[0103]
fnn能够拟合非线性连续的函数关系。本文所针对的数据对象为风速s、叶片偏转角θ和功率p,无法突变,都是连续的,而连续必可导,理论上,可以通过fnn求得功率p对风速s的偏导:
[0104][0105]
(11)式中,s表示风速;θ表示叶片偏转角;p'表示发电功率p的导数;在以上公式中,f(s,θ)为隐函数,无法直接求导,但在使用反向传播算法时,损失函数loss会对全局求偏导,可以求得损失函数对风速s的偏导和损失函数对p的偏导,设loss函数为均方差损失函数mse:
[0106][0107]
其中i为数据序号,n为数据总数目。
[0108]
pi为常数,通过链式求导法则,进而求得p':
[0109][0110]
[0111]
记为s
grad
,则有:
[0112][0113]
n为数据量,但在公式(14)中取n=1,由此可得功率p在某s下的变化率和变化趋势,为预测p的下一步变化提供具体的依据。
[0114]
1.5运维数据驱动的预测模型结构
[0115]
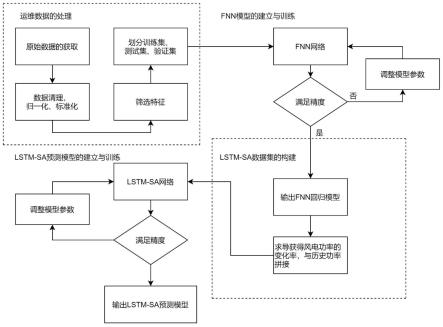
综上,本发明所提供的风机运维数据驱动的lstm-sa神经网络超短期功率预测算法流程如图5所示。通过对风机运维数据的分析,确定风速、叶片偏转角与功率之间的相关性,然后建立fnn模型,由风速、叶片偏转角计算得到的功率变化率,最后将功率变化率和历史功率值一起对lstm神经网络进行训练,并采用自注意力机制提高训练效果。
[0116]
最后,步骤s60,基于lstm-sa神经网络模型对目标风力发电机的下一时刻输出功率进行预测;预测的准确性较高。
[0117]
2、算例分析
[0118]
2.1数据集说明
[0119]
本实施例中的实验数据为百度kdd cup 2022竞赛数据(https://aistudio.baidu.com/aistudio/competition/detail/152/0/task-definition),选用龙源风电场的5号风机,每10分钟采样一次,共26470条数据。数据名称含义如表1。
[0120]
特征名特征含义wspd(m/s)风速仪采集的风速wdir(
·
)风向etmp(℃)风机周围环境的温度itmp(℃)涡轮机的温度ndir(
·
)风机的偏航角pad(
·
)叶片偏转的角度prtv(kw)无功功率patv(kw)有功功率
[0121]
表1
[0122]
2.2数据预处理
[0123]
2.2.1归一化处理
[0124]
本数据集中,不同的特征有着不同的量纲,有些量纲之间的数值和物理意义有很大的差别,在训练时可能会对结果造成负面影响。因此需要对历史数据进行最大最小值归一化来消除量纲,把数据压缩到[0,1]之间。最大最小值归一化公式为:
[0125][0126]
其中,xi为数据集中任意数,为该数据集的平均数,max(x)为数据集最大值,min
(x)为数据集最小值。
[0127]
2.2.2使用lasso和person算法进行数据筛选
[0128]
而在本数据集中,存在较多的特征且某些特征与标签相关性较低时,往往会对模型的性能产生负面影响,造成模型的预测精度降低。因此,需要对数据特征加以分析,剔除无价值的特征,降低数据维度。
[0129]
本实施例中,采用相关系数法和lasso算法对特征进行筛选,发现风速s和叶片转向角θ和功率p的相关性更高。相关性数值如表2所示。
[0130]
特征名称lasso算法person法风速wspd147.7720.964叶片偏转角pad-534.4770.033周围环境温度etmp-20.740-0.027风机内部温度itmp21.6040.153风向wdir0.714-0.069偏航角ndir0.006-0.182
[0131]
表2相关性对比
[0132]
如图6所示,为风速、叶片角度、功率三维散点图;如图7所示,为风速、叶片角度、功率二维散点图。
[0133]
2.3模型评价指标
[0134]
为了评估模型的预测性能,本实施例采用均方根误差(rmse)和决定系数r2来作为模型预测性能评估标准。
[0135][0136][0137]
其中yi为目标风力发电机输出功率的真实值,为目标风力发电机输出功率的预测值,为运维数据测试集中对应的风力发电机输出功率的平均数,n为样本数量。mse可以反映模型预测值与真实值的差异,r2能反映因变量的全部变异能通过回归关系被自变量解释的比例。mse越小,模型拟合效果越好,而r2越接近于1,模型拟合效果越好。
[0138]
2.4、fnn风功率拟合模型的搭建与训练
[0139]
以[st,θt]作为输入空间,[pt]作为输出空间,设置训练集、验证集、测试集的数量比值为8:1:1。搭建2
×
500
×
50
×
1的fnn,优化算法选择adam(自适应学习率的梯度下降),损失函数选择mse(均方误差损失函数),进行训练,设置早停法,即当训练集的loss和测试集的loss误差小于5%时停止迭代,fnn梯度下降趋势如图8所示。
[0140]
获得的fnn记为f(s
t
,θ
t
)=p
t
,在测试集上f(s
t
,θ
t
)的校正决定决定系数r2为
0.984,均方误差rmse为0.0398。
[0141]
f(s
t
,θ
t
)回归预测结果如图9所示。
[0142]
2.5、预测模型的搭建与训练.
[0143]
2.5.1、数据集的构建与划分
[0144]
选用龙源风电场的5号风机的历史发电数据,对于每一个时刻的运维数据使用公式(14),求得该时刻下的发电功率对风速的变化率p'
t
,将对应时刻的功率p
t
和变化率p'
t
进行向量拼接[p'
t
,p
t
]。
[0145]
计算所得p'
t
示例如下表3:
[0146][0147][0148]
表3
[0149]
3.5.2 lstm-sa预测模型的训练
[0150]
对当下风电发电功率和历史数据的分析,发现当前功率输出受前6个步长时刻的历史功率影响更大,选取当前时刻的前6个时刻的xi=[p'i,pi]作为输入空间,当前时刻的发电功率pt作为输出空间,记为
[0151]
lstmsa(x
t-6
,x
t-5
,x
t-4
,x
t-3
,x
t-2
,x
t-1
)=p
t
,
[0152]
数据集共有18926条数据,选择前80%作为训练集,中间10%作为验证集,后10%作为测试集,梯度下降优化算法使用adam,损失函数选择mse,设置lstm-sa隐藏层为2层,隐藏层神经元为6个,lstm层为1层,lstm层后接sa层和全连接层,如图10所示。
[0153]
训练lstm-sa预测模型,lstm-sa在训练集与验证集上的损失函数下降过程如图11所示,当训练集的损失函数值与验证集的损失函数值误差小于5%时停止训练。
[0154]
2.6预测结果与分析
[0155]
2.6.1预测结果评估标准
[0156]
比如根据国家能源局湖南监管办公室在2022年2月18日印发的《湖南电网并网考核细则》(以下简称《细则》)第十一条,风电场应该建立科学的功率预测模型,包括未来15分
钟~4小时超短期风电功率预测模型,超短期功率预测准确度应不低于87%,准确率计算公式如下:
[0157][0158]
上式中cap为风电场可用容量。
[0159]
另外使用决定系数r2来衡量模型的回归精度,决定系数r2计算方法见公式(16)。
[0160]
2.6.2预测模型的结果
[0161]
使用lstm-sa预测模型输出的预测结果与实际功率结果对比如图12,表4为评估函数的打分结果。
[0162]
r2acc0.9654498.8%
[0163]
表4
[0164]
可以看出,基于风电运维数据的lstm-sa预测结果接近实际的风电功率曲线,且在预测准确度上满足了《细则》要求。
[0165]
2.6.3与不同模型的对照比较
[0166]
将基于风电运维数据的lstm-sa模型与传统的lstm网络、gru网络、rnn网络的预测效果进行对照比较,图13为不同模型的预测结果对比,表5为不同模型的评价指标数值。
[0167] r2acclstm0.9252396.8%gru0.9250694.4%rnn0.9258894.1%
[0168]
表5
[0169]
从图13和表5可以看到,在相同的风电运维测试集中,lstm-sa模型最接近接近实际风电功率曲线。与传统的lstm、gru、rnn相比,lstm-sa模型的误差分别减少了约2.0%,4.4%,4.7%。
[0170]
与传统的预测方法相比,深度学习的方法具备解析数据、高度抽象的优势,但深度学习的方法有时忽略的实际客观环境对风力发电造成的影响,可解释性差。本发明提出的一种风机运维数据驱动的lstm-sa神经网络超短期功率预测方法,使用风机的运维数据来提取发电功率与客观环境之间的关系,推导出了神经网络的对输入值的求导公式,以此公式来求得这种关系,用lstm神经网络处理历史功率数据,用自注意力机制优化了lstm的隐藏层,提高了模型的精度和泛化能力。与传统的深度学习模型lstm、gru、rnn对比,lstm-sa模型具备更高的预测准确度和泛化能力,且收敛效率更高。这证明了基于运维数据驱动的lstm-sa风电功率预测算法在风电功率预测问题中的实用性。
[0171]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。