1.本发明属于土壤重金属分析技术领域,涉及一种基于线性判别分析的土壤重金属来源解析方法。
背景技术:
2.近年来随着工业化的快速发展,土壤重金属污染愈发严重。进入土壤中的重金属,因其具有隐蔽性、难降解性、富集性等特点,不仅会对作物的正常生长产生影响,还会通过食物链进入人体,对人体健康造成危害。农田土壤重金属污染防治已经成为我国重大战略需求。农田土壤污染来源识别是农田土壤重金属污染预防和治理修复的基础。因此开展农田土壤重金属污染来源的定量解析方法,成为解决土壤重金属污染问题的关键和基础。
3.土壤重金属污染源解析一般指的是污染来源的定性解析和定量解析。当前运用较多的源解析模型主要有同位素比值解析法、正定矩阵因子分析模型、unmix模型以及有绝对因子分析/多元线性回归分析(apcs-mlr)模型等。
4.在现有的技术中文献编号为2022,38(03):212-219的论文公开了一种基于apcs-mlr受体模型的水田土壤重金属源解析方法,论文的创新点在于通过主成分分析进行源识别,将得到的主要污染因子与土壤污染元素浓度作线性回归,回归系数用于计算污染因子对污染元素的贡献率。但在研究中发现,apcs-mlr受体模型在进行主成分分析时,特征值的分解存在一定的局限性。而且如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
5.本发明通过lda在降维过程中可以使用类别的先验知识经验,克服了像pca这样的无监督学习无法使用类别先验知识的局限性。alds-mlr受体模型首先采用线性判别分析进行源识别,再将得到的主要污染因子与土壤污染元素浓度作线性回归,再结合地统计学方法探析了土壤中重金属的来源及其贡献率,以期为当地土壤重金属污染科学防控和修复治理提供理论依据。
技术实现要素:
6.本发明的目的是克服现有技术的不足,提供一种农田土壤重金属污染来源的定量解析方法,可解决pca这样无监督学习无法使用类别先验知识的局限性问题,降低不确定性。
7.为解决上述技术问题,本发明采用的技术方案为:
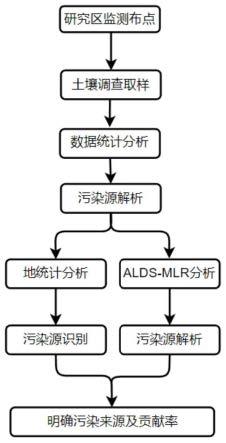
8.一种基于线性判别分析的土壤重金属来源解析方法,包括以下步骤:
9.步骤1:对研究区进行监测布点,并进行土壤样本采集以及土壤样品处理,测量土壤样本中重金属的含量;
10.步骤2:对所测研究区域的土壤重金属进行描述性统计分析;
11.步骤3:利用地统计学方法分析研究区域土壤重金属空间分布特征,识别出土壤污
染源;
12.步骤4:建立土壤重金属污染源解析alds-mlr受体模型,并采用土壤重金属污染源解析alds-mlr受体模型解析土壤重金属污染源及其贡献率;
13.步骤5:根据地统计分析的重金属空间分布特征识别的污染源及alds-mlr受体模型解析的污染源及其贡献率,得到明确的污染源及贡献率;
14.在步骤2中,通过直方图图检验重金属含量是否符合正态分布;
15.在步骤3中,不符合正态分布的重金属含量数据进行对数变换的操作,应用普通克里金插值方法绘制土壤重金属空间特征分布图,分析出污染源;
16.在步骤4中,在建立土壤重金属污染源解析alds-mlr受体模型时,采用以下子步骤:
17.步骤4-1:对所采集的各重金属浓度数据进行相关性分析得到各个重金属之间的相关性系数;
18.步骤4-2:采用线性判别分析lda降维,最大化类间距离,最小化类内距离,优化目标函数,得到最佳的投影矩阵ω;
19.步骤4-3:得到绝对线性判别得分,建立多元线性回归模型;
20.在步骤4-2中,包括以下子步骤:
21.步骤4-2-1:计算类内散度矩阵
[0022][0023][0024]
其中ci为第i个样本,μi为第i个样本的均值,x为样本的真实值。
[0025]
步骤4-2-2:计算每个类均值点相对于样本中心的散列情况,得到间散度矩阵sb[0026][0027]
其中c为样本的类别数,μi为第i个样本的均值,μ是所有样本的均值。
[0028][0029]
步骤4-2-3:优化目标函数,使其类间距离最大,类内方差最小,最大化目标函数,使其达到最大;
[0030][0031]
其中ω为投影矩阵,ci为第i个样本,μi为第i个样本的均值,x为样本的真实值。将步骤4-2-1与步骤4-2-2中的与sb带入上式目标函数可以简化为:
[0032][0033]
其中sb、分别为类间距离散度和类内距离散度。
[0034]
步骤4-2-4:计算矩阵对矩阵进行特征分解;
[0035]
步骤4-2-5:根据步骤4-2-4计算所得到的特征值,计算最大的d个特征值和对应的特征值向量(ω1、ω2、ω3,
…
ωd)得到投影矩阵ω;
[0036]
步骤4-2-6:对样本集中的每一个样本特征xi,转化为新的样本zi=ω
t
xi;
[0037]
步骤4-2-7得到输出样本集。d`={(z1,y1),(z2,y2),λ,(zi,yi),λ,(zn,yn)},其中zi为转化后的第i个新样本,yi为第i个样本所属于的类别,n代表样本的个数;
[0038]
在步骤4-3中,包括以下子步骤:
[0039]
步骤4-3-1:计算得到绝对线性判别得分;
[0040]
步骤4-3-2:将绝对线性判别得分作为自变量,金属浓度作为因变量做回归分析得到回归系数与回归常数项;
[0041]
步骤4-3-3:将绝对线性判别得分作为自变量,金属浓度作为因变量做回归分析得到回归系数与回归常数项;由线性判别分析得到的主因子得分减去0浓度样本的主因子分数得到每个样本的alds;alds为自变量,重金属元素含量作因变量,作多元线性回归,得到的回归系数可将alds转化为主因子对应的污染源对每个样本的浓度贡献,公式为:
[0042]
式中:z
i0
为重金属元素i的0浓度样本,mg
·
kg-1
;为重金属元素i含量的平均值,mg
·
kg-1
;δi为重金属元素i含量的标准偏差,mg
·
kg-1
。b
io
为多元线性回归的常数项,b
pi
为多元线性回归的回归系数,aldsp为因子p的绝对线性判别得分,bpi
×
aldsp为因子p对于ci的含量贡献,所有样本的bpi
×
aldsp平均值即为因子p对应的污染源平均绝对贡献量。其中因子p对应的污染源贡献率为其平均绝对贡献量与所有源贡献量的比值。
[0043]
在步骤5中,根据地统计分析的重金属空间分布特征识别的污染源及alds-mlr受体模型解析的污染源及其贡献率,得到明确的污染源及贡献率。
[0044]
与现有技术相比,本发明具有如下技术效果:
[0045]
本发明提出的是一种基于线性判别分析的多元线性回归的算法,是一种改进的土壤源解析的受体模型。能够快速、准确的分析出农田土壤中重金属各污染来源及其贡献率。以期为当地土壤重金属污染科学防控和修复治理提供理论依据。
[0046]
以往的土壤重金属来源解析研究中都没有使用过lda降维,lda在降维过程中可以使用类别的先验知识经验,克服了像pca这样的无监督学习则无法使用类别先验知识的局限性。alds-mlr受体模型首先采用线性判别分析进行源识别,再将得到的主要污染因子与土壤污染元素浓度作线性回归,回归系数用于计算污染因子对污染元素的贡献率。
[0047]
alds-mlr模型是线性判别分析和多元线性回归两种统计方法相结合的受体模型,解析结果更加可靠与准确,克服了pca这样无监督学习无法使用类别先验知识的局限性。测定土壤中重金属的含量,分析重金属的污染水平,并采用混合方法,包括相关分析、线性判别分析、绝对线性判别分析/多元线性回归分析(alds-mlr),结合地统计学方法探析了土壤中重金属的来源及其贡献率,从而为农田土壤重金属污染防治和治理提供科学防控和修复治理提供理论依据。
附图说明
[0048]
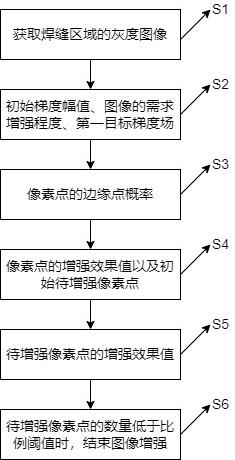
图1为本发明实施例提供的土壤重金属来源解析方法流程图;
[0049]
图2为本发明实施例枝江、当阳市土壤重金属as含量空间分布图;
[0050]
图3为本发明实施例枝江、当阳市土壤重金属hg含量空间分布图;
[0051]
图4为本发明实施例枝江、当阳市土壤重金属cr含量空间分布图;
[0052]
图5为本发明实施例枝江、当阳市土壤重金属hg含量空间分布图;
[0053]
图6为本发明实施例枝江、当阳市土壤重金属pb含量空间分布图;
[0054]
图7为本发明实施例提供的不同因子对重金属累积的贡献示意图。
具体实施方式
[0055]
一种基于线性判别分析的土壤重金属来源解析方法,包括以下步骤:
[0056]
步骤1:对研究区进行监测布点,并进行土壤样本采集以及土壤样品处理,测量土壤样本中重金属的含量;
[0057]
步骤2:对所测研究区域的土壤重金属进行描述性统计分析;
[0058]
步骤3:利用地统计学方法分析研究区域土壤重金属空间分布特征,识别出土壤污染源;
[0059]
步骤4:采用土壤重金属污染源解析alds-mlr受体模型解析土壤重金属污染源及其贡献率;
[0060]
步骤5:根据地统计分析的重金属空间分布特征识别的污染源及alds-mlr受体模型解析的污染源及其贡献率,得到明确的污染源及贡献率;
[0061]
在步骤1中,采集耕作层土样,种植一般农作物采0-20cm。为了保证样品的代表性,采取采集混合样的方案,每个土壤单元设3-7个采样区,单个采样区可以是自然分割的一个田块。也可以由多个田块所构成,其范围以200m
×
200m左右为宜;
[0062]
在步骤2中,土壤重金属的描述性统计分析包含:最大值、最小值、平均值、标准差、方差变异系数cv,通过直方图图检验重金属含量是否符合正态分布;
[0063]
在步骤3中,对于步骤2中,不符合正态分布的重金属含量数据进行对数对数变换的操作,应用普通克里金插值方法绘制土壤重金属空间特征分布图,分析出污染源;
[0064]
在步骤4中,在建立alds-mlr受体模型时,包含以下子步骤:
[0065]
步骤4.1:对所采集的各重金属浓度数据进行相关性分析得到各个重金属之间的相关性系数。相关性越接近1,表明变量之间的相关性越强,当相关性越接近0,表明变量之间的相关性越弱。显著性水平p值一般得小于0.05才具有统计学意义。一般以p《0.05为显著,p《0.01为非常显著。
[0066]
步骤4.2:采用线性判别分析lda降维,最大化类间距离,最小化类内距离,优化目标函数,得到最佳的投影矩阵ω;
[0067]
在步骤4.2中,也包括以下子步骤:
[0068]
步骤4.2.1:计算类内散度矩阵
[0069]
[0070][0071]
其中ci为第i个样本,μi为第i个样本的均值,x为样本的真实值。
[0072]
步骤4.2.2:计算每个类均值点相对于样本中心的散列情况,得到间散度矩阵sb[0073][0074]
其中c为样本的类别数,μi为第i个样本的均值,μ是所有样本的均值。
[0075][0076]
步骤4.2.3:优化目标函数,使其类间距离最大,类内方差最小,最大化目标函数,使其达到最大。
[0077][0078]
其中ω为投影矩阵,ci为第i个样本,μi为第i个样本的均值,x为样本的真实值。将步骤4.2.1与步骤4.2.2中的与sb带入上式目标函数可以简化为:
[0079][0080]
其中sb、分别为类间距离散度和类内距离散度。
[0081]
步骤4.2.4:计算矩阵对矩阵进行特征分解;
[0082]
步骤4.2.5:根据步骤4.2.4计算所得到的特征值,计算最大的d个特征值和对应的特征值向量(v1、ω2、ω3,
…
ωd)得到投影矩阵ω。
[0083]
步骤4.2.6:对样本集中的每一个样本特征xi,转化为新的样本zi=ω
t
xi。
[0084]
步骤4.2.7得到输出样本集。d`={(z1,y1),(z2,y2),λ,(zi,yi),λ,(zn,yn)},其中zi为转化后的第i个新样本,yi为第i个样本所属于的类别,n代表样本的个数;
[0085]
步骤4.3得到绝对线性判别得分,建立多元线性回归模型;
[0086]
在步骤4.3中,包含以下子步骤:
[0087]
步骤4.3.1:计算得到绝对线性判别得分;
[0088]
步骤4.3.2:将绝对线性判别得分作为自变量,金属浓度作为因变量做回归分析得到回归系数与回归常数项;
[0089]
步骤4.3.3:将绝对线性判别得分作为自变量,金属浓度作为因变量做回归分析得到回归系数与回归常数项;由线性判别分析得到的主因子得分减去0浓度样本的主因子分数得到每个样本的alds;alds为自变量,重金属元素含量作因变量,作多元线性回归,得到的回归系数可将alds转化为主因子对应的污染源对每个样本的浓度贡献,公式为:
[0090]
式中:z
i0
为重金属元素i的0浓度样本,mg
·
kg-1
;为重金属元素i含量的平均值,mg
·
kg-1
;δi为重金属元素i含量的标准偏差,mg
·
kg-1
。b
io
为多元线性回归的常数项,b
pi
为多元线性回归的回归系数,aldsp为因子p的绝对线性判别得分,bpi
×
aldsp为因子p对于ci的含量贡献,所有样本的bpi
×
aldsp平均值即为因子p对应的污染源平均绝对贡献量。其中因子p对应的污染源贡献率为其平均绝对贡献量与所有源贡献
量的比值。
[0091]
在步骤5中,根据地统计分析的重金属空间分布特征识别的污染源及alds-mlr受体模型解析的污染源及其贡献率,得到明确的污染源及贡献率。
[0092]
其中,alds是绝对线性判别分析;mlr是多元线性回归。
[0093]
下面通过一个实施例说明本发明的技术方案:
[0094]
如图1所示,一种基于线性判别分析的土壤重金属来源解析方法,包括以下步骤:
[0095]
步骤1:采集表层土壤样品,采集耕作层土样,种植农作物采0-20cm.采取采集混合样的方案,以保证样品的代表性。
[0096]
步骤2:对所测研究区域的土壤重金属进行描述性统计分析;
[0097]
土壤样品中重金属浓度的描述性统计数据如下表所示:可以看出土壤中不同重金属和含量差异较大其平均值大小依次为as(11.98mg
·
kg-1
)、hg(0.06mg
·
kg-1
)、cr(74.86mg
·
kg-1
)、cd(0.17mg
·
kg-1
)、pb(28.81mg
·
kg-1
)。其中cd、as、pb的平均值是湖北省省背景值的1.54、1.14、1.12倍,cr和hg的平均值均接近于背景值。重金属含量的平均值均未超过《土壤环境质量农用地土壤污染风险管控标准(试行)》(gb 15618—2018)所规定的对应重金属的农用地土壤污染风险筛选值。宜昌市农田土壤重金属变异系数大小依次为hg》cd》as》pb》cr,其中,hg变异系数最大,其次是cd,空间异质性较强,这可能是人为活动造成的。
[0098]
表1土壤样品中重金属浓度的描述性统计(n=721)
[0099][0100]
步骤3:利用地统计学方法分析研究区域土壤重金属空间分布特征,识别出土壤污染源;
[0101]
分析重金属浓度含量在研究区域空间上的变化,识别出土壤重金属潜在的污染来源。通过采用普通克里金插值生成各总金属的空间分布图,普通克里格插值平均误差(me)接近于0,证明预测值是精确的。均方根标准误差(rmsse)值在0.968-1.032之间,表明标准误差是准确的。重金属的空间分布结果如图2—图6所示。pb和as的空间分布特征相似,呈现出明显的点源污染,pb高值主要分布在南部,最明显就是在东南处;hg空间分布均匀,且与湖北省土壤hg背景值相近,该区域hg污染情况良好,主要在东部存在部分高值区;cr和cd的空间分布特征相似,研究区域重金属cd污染最严重,呈现面源污染,高值区域由北向南,且南部含量最高。cr高值区域主要分布在东南部,且呈东北到西南的趋势。
[0102]
步骤4:采用土壤重金属污染源解析alds-mlr受体模型解析土壤重金属污染源及其贡献率。
[0103]
步骤4.1:通过分析各个重金属两两之间的相关系数,相关性系数越大就说明重金属之间的关系越强,就越有可能具有相似的污染源;相关性分析结果如下表所示:
[0104]
表2宜昌市土壤重金属相关性分析
[0105][0106]
注:**表示在0.01水平(双尾)下,相关性显著;*表示在0.05水平下相关性显著。
[0107]
步骤4.2:线性判别分析lda降维,最大化类间距离,最小化类内距离,优化目标函数,得到最佳的投影矩阵ω。得到投影系数矩阵如下表所示:
[0108]
表3土壤重金属投影系数矩阵
[0109][0110]
步骤4.3:得到绝对线性判别得分,建议多元线性回归模型;根据得到的回归系数与回归常数项,通过计算得到各重金属的最终贡献率。实验结果如下表所示:
[0111]
表4各重金属污染源贡献率
[0112][0113]
得到各重金属污染来源绘图,如图7所示:
[0114]
步骤5:根据地统计分析的重金属空间分布特征识别的污染源及alds-mlr受体模型解析的污染源及其贡献率,得到明确的污染源及贡献率;
[0115]
源1对于as、pb和cr具有较大的贡献率占比。由相关性可知,as、pb和cr两两之间具有显著的相关关系;由图2、图4和图6可知,3种重金属的空间分布既有相似之处,也有差异。由于pb为汽车尾气排放物,而研究区域南部为交通枢纽中心,pb的空间分布图(图6)分布特征也呈现出南部递增的趋势,故推断源1为交通污染源。cr和as变化趋势高度一致,且该地区被长江支流所贯穿,且高值区域有大量的化工活动,“化工围江”问题严重,因此源1为交通源及河流灌溉水的混合源。
[0116]
源2载荷较大的重金属有cd,由图5可知研究区域重金属cd污染最严重,呈现面源污染,高值区域由北向南,且南部含量最高。经调查南部支流附近存在大量化工厂,cd广泛应用于各种化工业,故推断源2为“工业源”。
[0117]
源3载荷较大的重金属有hg,从空间分布看,由图3可以看出,hg高值区分布集中,
主要分布在研究区域东部,与低值区有明显界限,hg元素变异系数为47%,属于中高度变异,表明污染区域受人为因素较大。调研发现高值区有河流以及灌溉渠经过,河流周边存在排放hg废水的企业,故推测高值区土壤hg的累积可能是长期河流污灌造成的。研究表明hg和as是农药的重要组成元素,多次施用含含hg或无机as类农药在禁用之前广泛应用于农业,但由于重金属的难降解性,至今还在土壤中有所累积留存。故源3为“农业源”。
[0118]
通过相关性分析、线性判别分析和地统计学分析,宜昌农田土壤中这5种重金属的污染源大致分为交通源及河流灌溉水的混合源、工业源和农业源这3种主要来源。由alds-mlr受体模型的定量源解析可知,混合源对as、cr、pb具有较大贡献率,分别为71.08%、97.44%和73.07%。工业源对as、cd和pb具有较大贡献率,分别为12.20%、11.80%、9.19%。农业源对hg、cd具有较大贡献率,分别为68.17%和33.69%。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。