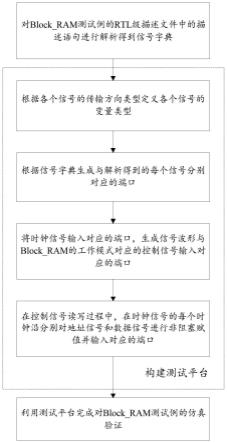
1.本发明属于高光谱图像分类技术领域,尤其涉及一种基于注意力的子域适应高光谱图像分类方法及系统。
背景技术:
2.高光谱图像(hyperspectral image,hsi)是遥感中的一种重要数据类型,广泛应用于与地球观测相关的应用,如智能农业和环境监测。hsi包含数百个光谱带,因此,为准确分类提供了丰富的信息。然而,标记遥感数据非常昂贵且耗时,缺乏标记样本对hsi分类构成了相当大的挑战。此外,在不同时间或不同位置获取的hsi之间存在光谱偏移。因此,传统的分类模型在一幅图像上训练,而在另一幅图像上训练时会出现光谱偏移,无法获得令人满意的性能。近年来,人们提出了大量的方法,其中域适应是最流行的方法。在域适配情况下,具有足够标签的数据被称为源域,具有很少标签或没有标签的待预测数据被称为目标域。目标是从源域转移知识,以改进目标域的分类。域适应方法将边缘分布、条件分布或两者在两个领域之间对齐,主要分为三类:基于实例、基于分类器和基于特征的方法。为了部分解决这个问题,基于实例的方法试图通过重新加权实例来减少域间的差异。然而,这些方法基于这样一个假设,即域仅在边缘分布上不同,这在大多数情况下是无法满足的。
3.近年来,基于特征的方法在三种域适应方法中最为流行,深度学习方法也属于这一类。基于特征的算法提取领域不变的特征表示,通过特征匹配或对抗性学习实现域适应。特征匹配方法通过最小化一些领域差异度量来减少特征分布之间的差异。
4.在现有的基于无监督域适应的方法中,对于源域分布和目标域分布不同的情况,大多数方法都考虑了边缘分布对齐。通过映射到同一个特征空间,拉近两个域的分布来达到对齐的目的;或者采用对抗的思想,通过学习一个域适应的特征嵌入空间来实现对齐。通过这些方法对齐后,两个域的边缘分布大致相同。然而,边缘分布对齐可能会导致一些不相关的数据过于接近,无法准确分类。与此同时会忽略类间的关系,即不考虑子域(子域为两个域同一类的样本)之间的关系,从而不能获得更好的性能。为了更好的捕获类内信息,进行两个域的条件对齐,在源域和目标域中,对齐同一类别内相关子域的分布。
5.综上所述,现有的很多基于无监督域适应的方法只从进行边缘分布对齐,将源域和目标域数据进行整体拉近,而忽略了两个域类别层面的关系,这可能会导致不相关的数据过于接近,无法准确分类,从而在目标域上不能获得更好的分类性能。
技术实现要素:
6.鉴于此,本发明公开提供了一种基于注意力的子域适应高光谱图像分类方法,以解决现有的无监督域适应方法中仅仅考虑了边缘分布对齐,分类效果严重依赖于源域数据,忽略了源域和目标域的类别相关性,导致不相关的数据过于接近,无法准确分类,从而在目标域上不能获得更好的分类性能的问题。
7.本发明提供的技术方案,具体为,一种基于注意力的子域适应高光谱图像分类方
法,包括如下步骤:
8.1)构建基于注意力网络的特征提取器提取特征;
9.2)预测目标样本的概率,将源域和目标域中的样本根据类别划分为多个子域,使用局部最大均值差异准则来计算每个样本对于每个类别的权重,实现每个子域的对齐,最终获得深度域适应网络对目标域的分类能力。
10.进一步地,所述特征提取器的网络结构包括空间特征提取和光谱特征提取。
11.进一步地,所述注意力网络采用卷积块注意模型分为空间注意力和通道注意力;其中空间注意力用于去除空间上干扰像元的影响,通道注意力用于去除光谱上冗余波段的影响。
12.进一步地,所述使用局部最大均值差异准则来计算每个样本对于每个类别的权重,具体为:
13.度量源域分布和目标域分布时,假设源域和目标域类别一致,二者的分布不同但相关;
14.使用l
l
mmd损失来测量局部差异,如公式(4)所示:
[0015][0016]
其中k是类别数,和是和属于类别k的权值,属于类别k的权值,权重计算公式如下(5)所示:
[0017][0018]
其中,yik表示yi属于类别k,在源域中使用真实标签的one-hot向量,为每个源域样本计算在目标域中,使用网络输出的预测概率来为每个目标域样本计算在每一个维度上进行归一化操作;考虑到不同样本的权重,l
lmmd
度量了在源域和目标域中嵌入相关子域的核均值之间的差异。
[0019]
另一方面,本发明提供了一种基于注意力的子域适应高光谱图像分类系统,所述系统包括特征提取部和条件对齐部,其中所述特征提取部采用带有注意力的特征提取器,利用注意力来提取更具有判别性的特征;所述条件对齐部用于对齐源域和目标域的条件分布。
[0020]
本发明提供的一种基于注意力的子域适应高光谱图像分类方法,通过加权的条件对齐减小域间差异。本发明首先使用基于注意力的空谱特征提取网络提取特征,然后对目标域样本预测概率,从类别层面将源域和目标域划分为多个子域,设计lmmd准则来计算每个样本对于每个类别的权重,实现每个子域的对齐,进而获得深度域适应网络对目标域的分类能力。针对无监督域适应问题,使用条件分布对齐的方法进行域间类别层面的对齐,实现域间分布差异的缩减。构建基于注意力的空谱特征提取网络以提取更具判别性的特征。
[0021]
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明的公开。
附图说明
[0022]
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
[0023]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0024]
图1为本发明公开实施例提供的基于注意力的子域适应高光谱图像分类的整体框架;
[0025]
图2为本发明公开实施例提供的基于注意力的空谱特征提取网络结构;
[0026]
图3为本发明公开实施例提供的indiana数据集下,相关工作算法与本发明算法的预测映射图;
[0027]
图4为本发明公开实施例提供的houston数据集下,相关工作算法与本发明算法的预测映射图;
[0028]
图5为本发明公开实施例提供的pavia数据集下,相关工作算法与本发明算法的预测映射图;
[0029]
图6为本发明公开实施例提供的shanghai-hangzhou数据集下,相关工作算法与本发明算法的预测映射图。
具体实施方式
[0030]
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的系统的例子。
[0031]
为了解决现有技术中,基于无监督域适应的方法只从进行边缘分布对齐,将源域和目标域数据进行整体拉近,而忽略了两个域类别层面的关系,导致不相关的数据过于接近,无法准确分类,从而在目标域上不能获得更好的分类性能的问题。本实施方案提供了一种基于注意力的子域适应高光谱图像分类方法,包括如下步骤:
[0032]
1)构建基于注意力网络的特征提取器提取特征;
[0033]
2)预测目标样本的概率,将源域和目标域中的样本根据类别划分为多个子域,使用局部最大均值差异准则lmmd来计算每个样本对于每个类别的权重,实现每个子域的对齐,最终获得深度域适应网络对目标域的分类能力。
[0034]
本实施方案为了充分提取特征,使用空谱特征提取网络,具体来说特征提取网络分为空间特征提取和光谱特征提取两个部分,空间特征提取使网络专注空间邻域的相关性。光谱特征提取,去除冗余的光谱特征,更好地聚焦于在分类中重要的特征。
[0035]
为了使特征提取网络提取的特征更具有判别性,采用注意力网络,具体来说注意力网络分为空间注意力和通道注意力两个部分。空间注意力,去除空间上干扰像元的影响,通道注意力,去除光谱上冗余波段的影响。
[0036]
另外,本实施方案基于加权的条件实现对齐,直接进行边缘分布对齐的方法,简单地将信息从一个领域迁移到另一个领域可能导致域适应性能的降低,忽略每个域特有的特
征。当两个域的边缘分布对齐后,两个域的整体分布基本相同,但不同子域中的数据过于接近,无法准确分类。因此,源域和目标域进行整体对齐可能不适合不同的场景。此时考虑源域目标域中同类之间的对齐,即条件对齐。将源域和目标域中的样本根据类别划分为子域,使用lmmd进行子域间的对齐。
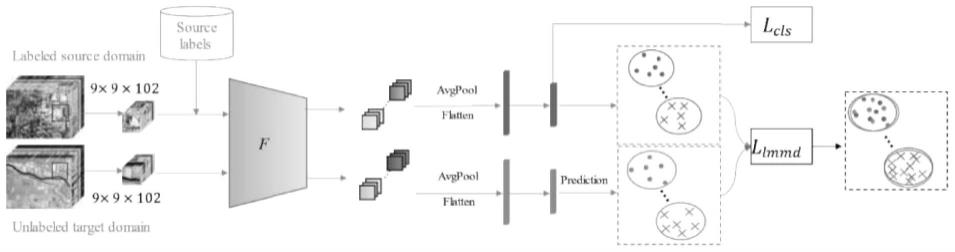
[0037]
除此之外,本发明选择4个不同的高光谱数据集(indiana,houston,pavia,shanghai-hangzhou),与5个相关工作算法(transudative support vector machine,tsvm;domain adaptation network,dan;domain-adversarial neural networks,dann;ed-dmm-uda;class-wise distribution adaptation,cda)进行对比,证明了本发明的有效性。
[0038]
本发明提出一种基于注意力的子域适应(attention based subdomain adaptation,asda)的高光谱图像分类方法,重点通过条件对齐来缩减域间分布差异。首先构建注意力网络来引导特征提取器提取更有效的特征,具体通过空间注意力去除空间上干扰像元的影响,通过通道注意力去除光谱上冗余波段的影响。然后从类别层面将源域和目标域样本划分为多个子域,并设计局部最大均值差异(local maximum mean difference,lmmd)准则来实现每个子域的对齐,进而获得深度域适应网络对目标域的分类能力。
[0039]
为更好阐释本发明的技术手段及产品效果,以下对本发明的优选实施例进行说明。
[0040]
实施例1
[0041]
特征提取网络
[0042]
基于注意力的特征提取器的网络结构图分为空间特征提取和光谱特征提取两个部分,以pavia数据集为例,输入数据块大小为9
×9×
102,9
×
9是空间邻域大小,102为波段数。
[0043]
空间特征提取部分,使用二维卷积层来提取空间特征,在每次卷积操作后使用批处理范数(batch normalization,bn)层和relu(rectified liner unit,relu)激活函数。首先,将输入的三维立方体与1
×1×
176核进行卷积,以将具有多个波段的hsi映射到仅具有一个光谱波段的灰度图像。使网络专注空间邻域的相关性。生成的9
×
9的特征图被送到一个残差块,保留重要的空间信息,该残差块由两个连续的卷积层和24个3
×
3核组成。
[0044]
光谱特征提取部分,使用1
×1×
7核学习光谱特征。在每次卷积操作后使用批处理范数(bn)层和relu激活函数。在第一个卷积层中,使用了24个1
×1×
7的核以及子采样步长(1,1,2),去除冗余的光谱特征,并更好地聚焦于在分类中重要的特征。然后将原始输入映射到24个大小为1
×1×
48的更精简的三维立方体。将特征图送入由两个连续的卷积层和24个1
×1×
7核组成的残差块中,强调了重要区域。在残差块之后,其他的立方体与128个1
×1×
48的核进行卷积,生成128个9
×
9的二维空间块。通过光谱和空间通道分别进行处理后,光谱特征与空间特征进行串联。因此,在将128个9
×
9光谱特征和24个9
×
9空间特征连接起来之后,总共获得了152个包含丰富的空间和光谱信息的特征。
[0045]
实施例2
[0046]
注意力网络
[0047]
本实施例中使用卷积块注意模型(convolutional block attention module,cbam)依次分别计算通道和空间注意模块。具体来说,通过空谱特征提取器f提取特征图,送
入注意机制模块,将注意力沿特征图的通道维度与空间维度进行输入,然后将注意力乘以输入特征映射图,对输入的特征图进行自适应特征细化。以pavia数据集为例,将特征提取器f的中的空间光谱融合特征i(i∈r
152
×9×9)作为输入,总体分为两个模块,通道注意力模块和空间注意力模块。首先将输入特征送入通道注意力模块中,对输入通道进行全局最大池化和均值池化,将池化后的两个一维向量送入全连接层得到一维特征,将这两个特征进行融合相加,生成一维通道注意力mc(mc∈r
152
×1×1),此时将通道注意力与输入元素相乘,获得通道注意力调整后的特征体ic(ic∈r
152
×9×9)。然后将ic按空间进行全局最大池化和均值池化,将池化生成的两个二维向量拼接后进行卷积操作,最终生成二维空间注意力ms(ms∈r1×9×9),将空间注意力与ic按元素相乘得到最终的加完空间和光谱注意力的特征i
cs
(i
cs
∈r
152
×9×9)。cbam生成注意力过程如公式(1),公式(2)所示:
[0048][0049][0050]
其中表示逐元素相乘,在相乘操作之前,通道注意力与空间注意力分别需要按照空间维度与通道维度进行广播。
[0051]
使用注意力模块,能使网络多关注于局部信息,更加适合条件分布对齐。而且cbam是一种端到端的通用模块,它可以无缝的集成到神经网络中,可以与神经网络一起端到端进行训练。
[0052]
实施例3
[0053]
基于加权的条件对齐
[0054]
直接进行边缘分布对齐的方法,简单地将信息从一个领域迁移到另一个领域可能导致域适应性能的降低,忽略每个域特有的特征。当两个域的边缘分布对齐后,两个域的整体分布基本相同,但不同子域中的数据过于接近,无法准确分类。因此,源域和目标域进行整体对齐可能不适合不同的场景。此时考虑源域目标域中同类之间的对齐,即条件对齐。
[0055]
在针对源域分布和目标域分布进行度量时,假设源域和目标域类别一致,二者的分布不同但相关。对两个分布之间的非参数距离估计,mmd已被用来测量源分布和目标分布之间的差异,度量不同但相关的两个分布之间的距离。如公式(3)所示:
[0056][0057]
其中,其中h是再生核希尔伯特空间(rkhs)。这里φ(.)表示将原始样本映射到rkhs的特征映射。在实践中,对mmd的估计通过比较经验核均值嵌入之间的平方距离。然而mmd度量主要关注边缘分布的对齐,忽略了同一类别中两个子域之间的关系。考虑到相关子域之间的关系,使用l
lmmd
损失来测量局部差异,如公式(4)所示:
[0058][0059]
其中k是类别数,和是和属于类别k的权值。值得注意的是,权重计算公式如下(5)所示:
[0060][0061]
其中,y
ik
表示yi属于类别k,在源域中使用真实标签的one-hot向量,为每个源域样本计算在目标域中,由于没有标签,使用网络输出的预测概率来为每个目标域样本计算在每一个维度上进行归一化操作。考虑到不同样本的权重,l
lmmd
度量了在源域和目标域中嵌入相关子域的核均值之间的差异。
[0062]
条件域适应的目的是对齐具有相同标签的样本的相关域的分布。主要根据类别进行划分,有四个输入,源域特征和目标域特征,源域原始标签和目标域的预测概率。通过多次迭代,目标样本的标记通常会变得更准确。
[0063]
实施例4
[0064]
本实施例的一种基于注意力的子域适应高光谱图像分类系统由两个主要部分组成:特征提取部分和条件对齐部分。在特征提取部分使用带有注意力的特征提取器,注意力用来提取更具有判别性的特征。条件对齐部分用于对齐源域和目标域的条件分布。
[0065]
具体来说,有两个输入,有标签的源域样本和无标签的目标域样本。以pavia数据集为例,输入的patch大小取9
×9×
102,102为波段数,9
×
9是空间维度。首先将两个域的样本送入特征提取器f中提取特征,除此之外,加入注意力机制使其提取的特征更具有判别性。然后将提取的特征送入一个均值池化层,将特征展平为一维向量,通过全连接进行最终的分类。在损失部分,除了源域的分类损失之外,使用源域特征和目标域特征进行条件对齐操作。值得注意的是,目标域没有标记样本,此时把softmax的预测输出作为伪标记。因此,asda的总损失函数如公式(6)所示:
[0066]
l=l
cls
λl
lmmd
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0067]
其中l
cls
是源域分类损失,l
lmmd
是条件对齐损失。λ>0是损失权重。
[0068]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本技术旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本发明未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由权利要求指出。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。