1.本发明涉及处理器(cpu),具体涉及risc-v处理器中不同寄存器堆之间的数据交换技术。
背景技术:
2.risc-v指令集架构是开源的精简指令集架构,符合该架构的处理器在实现上的特征、趋势和理念是按照risc-v指令集架构的要求(ratified)实现基础通用功能,并在此基础上增加和实现自定义扩展指令集以提高专用领域能力(计算性能和计算效率)。就具体的专用领域而言,risc-v指令集架构在深度学习领域被学术界和商业届广泛的应用,又由于不同的深度学习算法普遍依赖和使用相同或类似的算子,例如矩阵乘累加算子(gemm)、池化算子(pooling)等,为此以risc-v指令集架构提供的自定义扩展指令集能力为基础构建的,用于计算深度神经网络(deep neural network,dnn)算子执行的指令集(以下简称自定义扩展指令集)已经被广泛的探索、实现与应用。
3.精简指令集处理器的指令特征在于单条指令的功能简单明了,执行单元执行算术和逻辑指令的操作数从一个或多个寄存器获得,并将指令的执行结果写入一个或多个寄存器。寄存器通常的硬件实现方式是寄存器阵列,称为寄存器堆。高性能的精简指令处理器中存在多个功能独立、完备且各异的执行单元,不同的执行单元根据其操作数的种类或数据结构访问特定的寄存器和寄存器堆获取操作数。根据risc-v指令集架构的设计理念,深度学习领域算法的计算任务在符合risc-v指令集架构的处理器(以下简称risc-v处理器)上的主要执行单元是:1)向量执行单元:执行risc-v指令集架构中向量扩展指令集部分的指令执行单元;2)自定义扩展指令集执行单元:执行以risc-v指令集架构为基础用于计算深度神经网络算子执行的指令集的执行单元;处理器在执行深度学习领域算法前,会将整个复杂的算法拆分成大量简单算子的顺序执行过程,即由大量1.来自向量指令集的向量指令;2.来自自定义扩展指令集的自定义扩展指令,构成的程序序列。在执行程序序列时,向量指令由向量执行单元完成执行,自定义扩展指令集指令由自定义扩展指令集执行单元完成执行。
4.执行向量指令集指令时,向量执行单元读写操作数和执行结果的主要寄存器堆是向量寄存器堆(少量指令需要访问通用寄存器堆),risc-v指令集架构规定了向量寄存器堆的容量、结构和访问方式。执行自定义扩展指令集指令时,自定义扩展指令集执行单元读写操作数和执行结果的寄存器堆,通常都需要访问能更好满足深度学习领域算法的特征额外增加的瓦片(tile)寄存器堆。深度学习领域算法的特征包括大模型尺寸、大数据量和大计算量。为此,在指令集设计和硬件实现过程中,主流指令集都选择增加专用寄存器堆以满足深度学习领域算法的计算任务特征。前述新增专用寄存器堆中的寄存器,通常容量较大且呈2维形状,因此新增的专用寄存器通常称为瓦片寄存器,新增的专用寄存器堆通常称为瓦
片寄存器堆。举例来说,为了提高处理器在深度学习领域的适用性,intel公司在其amx指令集中新增了瓦片寄存器和瓦片寄存器堆,arm公司在其sme指令集中也增加了瓦片寄存器和瓦片寄存器堆。
5.由大量向量指令集和自定义扩展指令集的指令构成的程序序列的指令顺序并不固定,通常来说来自向量指令集的指令和来自自定义扩展指令集的指令之间存在大量的交叉,为此执行单元需要交叉访问寄存器堆来获取操作数:1)当自定义扩展指令集执行单元完成计算并将执行结果存入瓦片寄存器堆之后,如果下一条指令调用向量执行单元,向量执行单元就需要从瓦片寄存器堆获取操作数;2)当向量执行单元完成计算并将执行结果存入向量寄存器堆之后,如果下一条指令调用自定义扩展指令集执行单元,自定义扩展指令集执行单元就需要从向量寄存器堆获取操作数。
6.在现有的技术方案中,执行单元交叉访问寄存器堆的技术方案通常有以下两种。
7.第一种:如果逻辑上不同的寄存器堆在物理实现时是独立的,会执行寄存器堆之间的数据拷贝指令,先将数据从其他寄存器堆拷贝到与当前执行单元关联的寄存器堆后,再让执行单元获取操作数。
8.为了提高处理器的性能,高性能处理器会使用各种技术手段让多个执行单元能够以时间并行的方式并行工作,其中之一就是保证多个执行单元能够并行的访问寄存器堆读取操作数和写回执行结果。为了让多个执行单元以时间并行的方式访问寄存器堆,并且在空间上缓解处理器的寄存器压力问题,通常逻辑上不同的寄存器堆在物理实现时是独立。以通用寄存器堆和向量寄存器堆举例而言,向量寄存器堆在实现上独立于通用寄存器堆,即通用寄存器堆在物理上是独立、完整且专属的寄存器阵列,向量寄存器堆在物理上也是独立、完整且专属的寄存器阵列。如图1所示,当逻辑上不同的寄存器堆的物理实现是独立的,且发生执行单元与寄存器堆之间的交叉访问时,在risc-v处理器的现有的技术方案中,会执行寄存器堆之间的数据拷贝指令,先将数据从其他寄存器堆拷贝到与当前执行单元关联的寄存器堆后,再让执行单元获取操作数。仍以通用寄存器堆和向量寄存器堆举例而言,在risc-v处理器的现有的技术方案中,当与通用寄存器关联的执行单元需要访问向量寄存器堆中的数据时,要先执行一条“vmv.x.s”指令将数据从向量寄存器堆拷贝到通用寄存器堆,执行单元才能进一步获取操作数。当与向量寄存器堆相关联的执行单元需要访问通用寄存器堆中的数据时,要先执行一条“vmv.s.x”指令将数据从通用寄存器堆拷贝到向量寄存器堆,执行单元才能进一步获取操作数。而由于1.深度学习领域算法的特征包括大模型尺寸、大数据量和大计算量;2.来自向量指令集的指令和来自自定义扩展指令集的指令在程序序列中存在大量的交叉;3.每执行一条数据拷贝指令都需要付出额外的性能代价和功耗代价,所以将该技术方案应用在向量执行单元和自定义扩展指令集执行单元对向量寄存器堆和瓦片寄存器堆的交叉访问上,risc-v处理器会付出极大且非必要的性能代价和功耗代价。
9.第二种:如果逻辑上不同的寄存器堆在物理实现时是共享的,当一个执行单元在访问寄存器堆时,为避免可能的数据冲突和有限数量寄存器堆读写端口的访问冲突,另一个执行单元必须等到寄存器堆的当前访问结束后才能开始自己的访问。
10.在主流处理器的技术方案中,也有逻辑上不同的寄存器堆的物理实现是共享的寄
存器阵列,多个关联到逻辑上不同寄存器堆的执行单元共享同一个寄存器阵列的设计方案。举例来说,如图2所示,armv8架构中与neon指令相关联的寄存器堆和与浮点指令相关联的寄存器堆在逻辑上是不同的,而在物理实现上是同一个寄存器阵列,这会导致1.寄存器压力问题加剧;2.可能的数据冲突和有限数量寄存器堆读写端口的访问冲突;3.执行单元无法充分利用时间并行性进而非必要空闲和非流水线执行,所以将该技术方案应用在向量执行单元和自定义扩展指令集执行单元对向量寄存器堆和瓦片寄存器堆的交叉访问上,risc-v处理器同样也会付出极大且非必要的性能代价。
11.综上,现有的risc-v处理器技术方案在向量执行单元和自定义扩展指令集执行单元对向量寄存器堆和瓦片寄存器堆交叉访问时性能和功耗代价太大,risc-v处理器需要一种性能更高、功耗更低的方法实现向量执行单元和自定义扩展指令集执行单元对向量寄存器堆和瓦片寄存器堆交叉访问。
12.相关现有技术可以参见专利文献:cn1378148a、cn1666480a、cn100481085c、cn101163129a、cn101763244a、cn102385504a、cn104216842a、cn111061729a、cn101847093a、cn114579188a、wo2019148781a1。
技术实现要素:
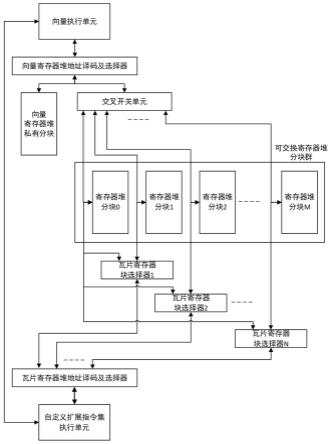
13.为了解决上述技术问题,本发明提供一种处理器寄存器堆之间的零拷贝数据传输装置及方法,其采用如下技术方案:一种处理器寄存器堆之间的零拷贝数据传输装置,包括:1)向量执行单元:执行risc-v指令集架构中向量扩展指令集部分的指令执行单元;2)自定义扩展指令集执行单元:执行以risc-v指令集架构为基础用于计算深度神经网络算子执行的指令集的执行单元;3)向量寄存器堆地址译码及选择器:根据指令要求选通32个向量寄存器中的至少一个向量寄存器,供向量执行单元读取操作数或写回执行结果;4)瓦片寄存器堆地址译码及选择器:根据指令要求选通n个瓦片寄存器中的至少一个瓦片寄存器,供自定义扩展指令集执行单元读取操作数或写回执行结果;5)寄存器堆分块:在物理上独立实现的寄存器阵列,数量总共是m 1个,根据处理器运行时状态选出总共m 1个中的m个寄存器堆分块构成逻辑上的瓦片寄存器堆,每个瓦片寄存器由vlen/128个寄存器堆分块构成;6)向量寄存器堆私有分块:向量寄存器堆中的向量寄存器数量是32个,将32个向量寄存器中的前16个向量寄存器v0~v15作为一个向量寄存器堆私有分块,向量寄存器堆私有分块的大小和寄存器堆分块的大小相同,且只能通过向量寄存器堆地址译码及选择器访问,物理上的向量寄存器堆私有分块和根据处理器运行时状态选出的1个寄存器堆分块构成逻辑上的向量寄存器堆;7)交叉开关单元:根据处理器运行时状态选出的1个寄存器堆分块构成逻辑上的向量寄存器堆的后16个向量寄存器v16~v31;8)瓦片寄存器块选择器:根据处理器运行时状态选择寄存器堆分块构成逻辑上的瓦片寄存器。
14.本发明一种处理器寄存器堆之间的零拷贝数据传输方法,包括步骤1:处理器将整个算法拆分成由向量指令和自定义扩展指令集指令构成的程序序列;步骤2:执行单元交叉访问寄存器堆获取操作数。
15.本发明具有以下有益技术效果:本发明提供了一种新的向量寄存器堆与其他包括瓦片寄存器堆在内的寄存器堆之间传输数据的颗粒度,能够兼容vlen的不同取值情况和不同的瓦片寄存器尺寸。
16.在保证执行单元拥有物理上独立的寄存器堆资源和保证原有的数据传输方案能正常工作的基础上,提供了一种新的零拷贝数据传输方式,无需进行数据的传输与拷贝,能够加快大块数据传输速度,降低大块数据的传输功耗,从而解决现有技术执行单元交叉访问寄存器堆来获取操作数时,需要通过向量执行单元和自定义扩展指令集执行单元之间的寄存器堆间数据拷贝通路拷贝每一个向量寄存器的数据而造成的性能和功耗代价。
17.本发明避免了数据在两个寄存器堆中逐一单向拷贝的过程,实现寄存器数据在两个功能模块间的零拷贝数据传输,降低了整体功耗,提高了整体性能。特别适用于像向量寄存器堆和瓦片寄存器堆这样数据量较大的寄存器堆的之间的数据传输;特别适用于深度学习领域算法的大数据量特征,进而在risc-v处理器上由不同执行单元串行执行时的大数据量传输特征;特别是在配合执行深度学习领域计算密度较低但数据量较大场景下的算子时,能显著的提高算法执行的整体性能和降低算法执行的整体功耗。
18.在零拷贝的前提下,实现了寄存器堆之间的双向数据传输,在优化向量指令和自定义扩展指令集指令的顺序以及平衡向量计算工作量和自定义扩展指令集指令计算工作量后,可以进一步提高硬件执行单元的利用率。
附图说明
19.以下结合附图对本发明作进一步说明:图1为现有技术独立寄存器堆之间数据传输方案示意图;图2为现有技术armv8浮点指令集寄存器堆和neon指令集寄存器堆示意图;图3为risc-v指令集架构规定的向量寄存器堆示意图;图4为本发明自定义扩展指令集规定的瓦片寄存器示意图;图5为本发明自定义扩展指令集规定的瓦片寄存器堆示意图;图6为本发明实施例vlen=128bit时寄存器堆之间的零拷贝数据传输装置示意图;图7为本发明实施例vlen=256bit时寄存器堆之间的零拷贝数据传输装置示意图;图8为本发明由物理上的向量寄存器堆私有分块和1个寄存器堆分块构成的逻辑上的向量寄存器堆示意图;图9为本发明由寄存器堆分块构成的逻辑上的瓦片寄存器示意图;图10为本发明实施例vlen=128bit时传输编号3的瓦片寄存器数据示意图;图11为本发明实施例vlen=256bit时传输编号3的瓦片寄存器数据示意图。
具体实施方式
20.本发明具体实施方式有以下参数设定和条件设定:如图3所示,risc-v指令集架构规定了向量寄存器堆的容量、结构和访问方式,规
定向量寄存器堆中的向量寄存器数量是32个,每个向量寄存器的宽度是vlen-bit,vlen的取值必须是2的幂次且小于2的16次方,常用的vlen取值为128、256和512等。
21.瓦片寄存器堆在不同的自定义扩展设计方案中的设计选择有所不同,一般而言瓦片寄存器堆中的寄存器都是能更好满足深度学习领域算法的特征额外增加的2维形状、大容量寄存器。如图4所示,本发明优先考虑深度学习领域常用的矩阵乘累加(扩位)的计算密度指标后,提供的适宜保存外积方式计算的矩阵乘累加结果的瓦片寄存器呈2维方形,即瓦片寄存器的宽度方向和高度方向包含相同数量的32-bit元素,元素数量为vlen/16个。如图5所示,瓦片寄存器堆中瓦片寄存器的数量为n,具体数值可根据处理器带宽、面积和寄存器压力问题等因素在实现时综合确定。
22.本发明处理器寄存器堆之间的零拷贝数据传输装置,包括:1)向量执行单元:执行risc-v指令集架构中向量扩展指令集部分的指令执行单元;向量执行单元执行算术和逻辑指令的操作数大多来自于向量寄存器堆,少量来自于通用寄存器堆,向量执行单元执行算术和逻辑指令的执行结果大多写入向量寄存器堆,少量写入通用寄存器堆;2)自定义扩展指令集执行单元:执行以risc-v指令集架构为基础用于计算深度神经网络算子执行的指令集的执行单元;自定义扩展指令集包括执行卷积、矩阵乘累加、池化、激活计算的自定义扩展指令,自定义扩展指令集执行单元执行算术和逻辑指令的操作数大多来自瓦片寄存器堆,少量来自于其他寄存器堆,如通用寄存器堆;自定义扩展指令集执行单元执行算术和逻辑指令的执行结果全都写入瓦片寄存器堆;3)向量寄存器堆地址译码及选择器:根据指令要求选通32个向量寄存器中的一个或多个向量寄存器,供向量执行单元读取操作数或写回执行结果;4)瓦片寄存器堆地址译码及选择器:根据指令要求选通n个瓦片寄存器中的一个或多个瓦片寄存器,供自定义扩展指令集执行单元读取操作数或写回执行结果;5)寄存器堆分块:寄存器堆分块是包含一定数量寄存器,在物理上独立实现的寄存器阵列;寄存器堆中除了包含寄存器阵列,还包含该寄存器阵列的地址译码及选择器,索引并选通当前寄存器堆中需要访问的寄存器的数字逻辑;还包含被瓦片寄存器堆地址译码及选择器和向量寄存器堆地址译码及选择器共享的寄存器读写端口,即包含仲裁逻辑供多个来源的读写请求时分复用的寄存器读写端口;寄存器堆分块的数量总共是m 1个,每个寄存器堆分块的容量是vlen*16bit,可以映射为向量寄存器堆中一半数量的向量寄存器;根据处理器运行时状态选出总共m 1个中的m个寄存器堆分块构成逻辑上的瓦片寄存器堆,每个的瓦片寄存器由vlen/128个寄存器堆分块构成;所有的寄存器堆分块统称可交换寄存器堆分块群;6)向量寄存器堆私有分块:risc-v指令集架构规定向量寄存器堆中的向量寄存器数量是32个,32个向量寄存器的编号依次为v0,v1,v2,
…
v31;本发明将32个向量寄存器中的前16个,编号依次为v0,v1,v2,
…
v15的向量寄存器作为一个向量寄存器堆私有分块;该向量寄存器堆私有分块的大小和寄存器堆分块的大小相同,但只能通过向量寄存器堆地址译码及选择器访问;如图8所示,物理上的向量寄存器堆私有分块和根据处理器运行时状态选出的1个寄存器堆分块组成了逻辑上的向量寄存器堆;7)交叉开关单元:根据处理器运行时状态选出的1个寄存器堆分块构成逻辑上的
向量寄存器堆的后16个向量寄存器,编号依次为v16,v17,v18,
…
v31;8)瓦片寄存器块选择器:根据处理器运行时状态选择寄存器堆分块构成逻辑上的瓦片寄存器。
23.不同vlen情况下,1个瓦片寄存器由vlen/128个寄存器堆分块构成,所以瓦片寄存器总数量n和寄存器堆分块总数量m 1之间的对应关系是m=(vlen/128)
×
n。本发明实现过程中,先确定向量寄存器宽度vlen,再确定瓦片寄存器数量n,最后由m和n之间的对应关系确定寄存器堆分块数量m。
24.为优化上述向量寄存器堆与瓦片寄存器堆之间的数据传输,其中图6为本发明实施例vlen=128bit时寄存器堆之间的零拷贝数据传输装置示意图,其中向量执行单元读写操作数和执行结果的逻辑上的向量寄存器堆,由1个向量寄存器堆私有分块和编号为0~m的m 1个寄存器堆分块中的任意1个寄存器堆分块构成,向量寄存器堆私有分块和寄存器堆分块的容量都是2048-bit。
25.当向量执行单元访问编号为v0~v15的向量寄存器(容量为128-bit)时,直接通过向量寄存器堆地址译码及选择器访问向量寄存器堆私有分块;当向量执行单元访问编号为v16~v31的向量寄存器时,需要通过向量寄存器堆地址译码及选择器访问交叉开关单元根据处理器运行时状态选出的1个寄存器堆分块。
26.编号为0~m的m 1个寄存器堆分块中剩余的m个寄存器堆分块构成自定义扩展指令集执行单元读写操作数和执行结果的逻辑上的瓦片寄存器堆,逻辑上的瓦片寄存器堆中的1个瓦片寄存器由1个寄存器堆分块构成,即编号n的数值与编号m的数值相等。
27.当自定义扩展指令集执行单元访问编号为1~n的瓦片寄存器(容量为2048-bit)时,需要通过瓦片寄存器堆地址译码及选择器访问瓦片寄存器块选择器1~n,每个瓦片寄存器块选择器根据处理器运行时状态选出的1个寄存器堆分块。
28.其中图7为本发明实施例vlen=256bit时寄存器堆之间的零拷贝数据传输装置示意图, 其中向量执行单元读写操作数和执行结果的逻辑上的向量寄存器堆,由1个向量寄存器堆私有分块和编号为0~m的m 1个寄存器堆分块中的任意1个寄存器堆分块构成,向量寄存器堆私有分块和寄存器堆分块的容量都是4096-bit。
29.当向量执行单元访问编号为v0~v15的向量寄存器(容量为256-bit)时,直接通过向量寄存器堆地址译码及选择器访问向量寄存器堆私有分块;当向量执行单元访问编号为v16~v31的向量寄存器时,需要通过向量寄存器堆地址译码及选择器访问交叉开关单元根据处理器运行时状态选出的1个寄存器堆分块。
30.编号为0~m的m 1个寄存器堆分块中剩余的m个寄存器堆分块构成自定义扩展指令集执行单元读写操作数和执行结果的逻辑上的瓦片寄存器堆,逻辑上的瓦片寄存器堆中的1个瓦片寄存器由2个寄存器堆分块构成,即编号n的数值与编号m的数值除以2相等。
31.当自定义扩展指令集执行单元访问编号为1~n的瓦片寄存器时,需要通过瓦片寄存器堆地址译码及选择器访问瓦片寄存器块选择器1~n,每个瓦片寄存器块选择器根据处理器运行时状态选出的1个寄存器堆分块。
32.本发明处理器寄存器堆之间的零拷贝数据传输方法,包括:处理器在执行深度学习领域算法前,会将整个复杂的算法拆分成大量简单算子的顺序执行过程,即由向量指令和自定义扩展指令集指令构成的程序序列。向量指令和自定
义扩展指令集指令在程序序列中的指令顺序并不固定,向量指令和自定义扩展指令集指令之间存在大量的交叉,为此执行单元需要交叉访问寄存器堆来获取操作数。如图8所示,为被(交叉)访问的逻辑上的向量寄存器堆和物理上的向量寄存器堆私有分块以及寄存器堆分块之间的映射关系。默认情况下,即处理器上电后且没有发生寄存器堆分块调换时,逻辑上的向量寄存器堆由向量寄存器堆私有分块和编号0的寄存器堆分块构成;如图9所示,为被(交叉)访问的逻辑上的瓦片寄存器和物理上的寄存器堆分块之间的映射关系,当vlen取值为128时,一个逻辑上的瓦片寄存器由1个寄存器堆分块构成;当vlen取值为256时,一个逻辑上的瓦片寄存器由2个寄存器堆分块构成;当vlen取值不固定(大于128)时,一个逻辑上的瓦片寄存器由vlen/128个寄存器堆分块构成。默认情况下,即处理器上电后且没有发生寄存器堆分块调换时,逻辑上的瓦片寄存器堆由编号1到编号m的寄存器堆分块构成。
33.当自定义扩展指令集执行单元完成计算并将执行结果存入瓦片寄存器堆之后,如果下一条指令调用向量执行单元对前述执行结果做进一步计算,传输方法包括以下步骤:1.处理器执行数据加载指令,将数据从存储器传输至瓦片寄存器堆。
34.2.处理器执行自定义扩展指令集指令,驱动自定义扩展指令集执行单元执行算术和逻辑指令,操作数从一个或多个瓦片寄存器堆中的寄存器获得,并将指令的执行结果写入瓦片寄存器堆。
35.3.处理器执行寄存器堆分块调换指令,配置交叉开关单元和瓦片寄存器块选择器,将保存上述执行结果的寄存器堆分块从瓦片寄存器堆调出,并调入向量寄存器堆。
36.根据本发明的一个实施方式,寄存器堆分块调换指令具有如下格式:switch imm12其中,其中imm12为第一操作数,指定了可交换寄存器堆分块群中需要调入向量寄存器堆的寄存器堆分块的编号。执行该指令的直接作用是改变了交叉开关单元和瓦片寄存器块选择器的选通方式,从而改变了向量寄存器堆和瓦片寄存器堆的构成方式。交换过程不能打断,否则回到前述默认构成方式。
37.由于瓦片寄存器尺寸较大,需要vlen/128次调换才能覆盖整个瓦片寄存器从瓦片寄存器堆到向量寄存器堆的调用。如果需要调用的瓦块寄存器编号是在1到n范围内的y,那么遍历整个瓦片寄存器需要依次交换的寄存器堆分块的编号是(y
–
1)*(vlen/128) 1到y*(vlen/128)。
38.举例而言,若vlen=128bit时,且瓦片寄存器的数量n取值为4,且需要传输的是编号3的瓦片寄存器内的数据,那么在这个步骤需要执行的switch指令有:switch3;imm12=3执行前,向量寄存器堆的构成方式如图10所示,由向量寄存器堆私有分块和编号为0的寄存器堆分块构成;瓦片寄存器堆的构成方式如图10所示,由编号为1、2、3和4的寄存器堆分块构成。
39.执行指令“switch3;imm12=3”后,向量寄存器堆的构成方式如图10所示,由向量寄存器堆私有分块和编号为3的寄存器堆分块构成;瓦片寄存器堆的构成方式如图10所示,由编号为1、2、0和4的寄存器堆分块构成。
40.举例而言,若vlen=256bit时,且瓦片寄存器的数量n取值为4,且需要传输的是编号3的瓦片寄存器内的数据,那么在这个步骤需要执行的switch指令有:
switch5;imm12=5switch6;imm12=6执行前,向量寄存器堆的构成方式如图11所示,由向量寄存器堆私有分块和编号为0的寄存器堆分块构成;瓦片寄存器堆的构成方式如图11所示,由编号为1、2、3、4、5、6、7和8的寄存器堆分块构成。
41.执行指令“switch5;imm12=5”后,向量寄存器堆的构成方式如图11所示,由向量寄存器堆私有分块和编号为5的寄存器堆分块构成;瓦片寄存器堆的构成方式如图11所示,由编号为1、2、3、4、0、6、7和8的寄存器堆分块构成。
42.执行指令“switch5;imm12=6”后,向量寄存器堆的构成方式如图11所示,由向量寄存器堆私有分块和编号为6的寄存器堆分块构成;瓦片寄存器堆的构成方式如图11所示,由编号为1、2、3、4、5、0、7和8的寄存器堆分块构成。
43.4.处理器执行向量指令,驱动向量执行单元执行算术和逻辑指令,操作数从前述瓦片寄存器堆中的寄存器获得,并将指令的执行结果写入向量寄存器堆私有分块。若vlen=128,那么当向量执行单元处理完一个寄存器堆分块的数据后,即结束了对一个瓦片寄存器内全部数据的计算;若vlen》128,那么向量执行单元处理需要处理vlen/128份寄存器堆分块的数据后,才能完成一个瓦片寄存器内全部数据的计算;为此,若vlen》128,寄存器堆分块调换指令和数据处理需要交替进行vlen/128次,完成一个瓦片寄存器内全部数据的计算,且每次的执行结果保存在向量寄存器堆私有分块内。
44.5.完成一个瓦片寄存器内全部数据从瓦片寄存器堆到向量寄存器堆的传输,且向量执行单元以前述数据作为操作数完成计算后,处理器再次执行寄存器堆分块调换指令,还原寄存器堆分块在寄存器堆之间的分配关系。
45.举例而言,若vlen=128bit时,且瓦片寄存器的数量n取值为4,且已经传输的是编号3的瓦片寄存器内的数据,那么在这个步骤需要执行的switch指令有:switch0;imm12=0执行前,向量寄存器堆的构成方式如图10所示,由向量寄存器堆私有分块和编号为3的寄存器堆分块构成;瓦片寄存器堆的构成方式如图10所示,由编号为1、2、0和4的寄存器堆分块构成。
46.执行指令“switch3;imm12=0”后,向量寄存器堆的构成方式如图10所示,,由向量寄存器堆私有分块和编号为0的寄存器堆分块构成;瓦片寄存器堆的构成方式如图10所示,由编号为1、2、3和4的寄存器堆分块构成。
47.举例而言,若vlen=256bit时,且瓦片寄存器的数量n取值为4,且需要传输的是编号3的瓦片寄存器内的数据,那么在这个步骤需要执行的switch指令有:switch0;imm12=0执行前,向量寄存器堆的构成方式如图11所示,由向量寄存器堆私有分块和编号为6的寄存器堆分块构成;瓦片寄存器堆的构成方式如图11所示,由编号为1、2、3、4、5、0、7和8的寄存器堆分块构成。
48.执行指令“switch5;imm12=0”后,向量寄存器堆的构成方式如图11所示,由向量寄存器堆私有分块和编号为0的寄存器堆分块构成;瓦片寄存器堆的构成方式如图11所示,由编号为1、2、3、4、5、6、7和8的寄存器堆分块构成。
49.当向量执行单元完成计算并将执行结果存入向量寄存器堆之后,如果下一条指令调用自定义扩展指令集执行单元,传输方法包括以下步骤:1.处理器执行数据加载指令,将数据从存储器传输至向量寄存器堆。
50.2.处理器执行向量指令,驱动向量执行单元执行算术和逻辑指令,操作数从一个或多个向量寄存器堆中的寄存器获得,并将指令的执行结果写入向量寄存器堆。
51.3.处理器执行寄存器堆分块调换指令,配置交叉开关单元和瓦片寄存器块选择器,将保存上述执行结果的寄存器堆分块从向量寄存器堆调出,并调入瓦片寄存器堆。由于瓦片寄存器尺寸较大,只需要进行一次寄存器堆分块的调换。
52.4.处理器执行自定义扩展指令集指令,驱动自定义扩展指令集执行单元执行算术和逻辑指令,操作数从前述调入的寄存器堆分块中的寄存器获得,并将指令的执行结果写入其他瓦片寄存器。
53.5.完成一个寄存器堆分块内全部数据从向量寄存器堆到瓦片寄存器堆的传输,且自定义扩展指令集执行单元以前述数据作为操作数完成计算后,处理器再次执行寄存器堆分块调换指令,还原寄存器堆分块在寄存器堆之间的分配关系。
54.以上仅为本发明较佳实施例,但本发明的保护范围并不局限于此。任何以本发明为基础,对本发明相应技术特征以基本相同的手段,实现基本相同的功能,达到基本相同的效果,并且本领域普通技术人员在被诉侵权行为发生时无需经过创造性劳动就能联想到的特征进行替换,皆涵盖于本发明的保护范围之中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。