技术特征:
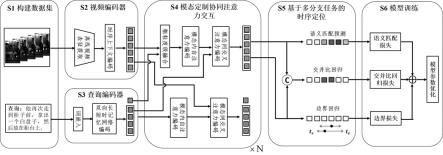
1.一种基于模态定制协同注意力交互的时序语言定位方法,其特征在于,包括以下步骤:步骤s1:获取成对的未剪辑视频-文本查询数据,构建时序语言定位任务的训练数据集和测试数据集,所述训练数据集中每样本由成对的未剪辑视频-文本查询以及目标视频片段相应的起始和结束时间标注组成,所述测试数据集仅由未提供目标视频片段时间标注的成对的未剪辑视频-文本查询样本组成;步骤s2:基于所述时序语言定位任务中的每对未剪辑视频-文本查询数据,对未修剪视频通过视频编码器提取视频表征v;步骤s3:基于所述时序语言定位任务中的每对未剪辑视频-文本查询数据,对文本查询数据通过查询编码器提取单词级查询表征w和句子级查询表征q
s
,所述单词级查询表征w和所述句子级查询表征q
s
组合得到多粒度查询表征q;步骤s4:将所述视频表征v和所述多粒度查询表征q共同输入模态定制协同注意力交互模块,获取视频-文本跨模态融合后已语义对齐视频表征;步骤s5:根据跨模态融合后的已语义对齐视频表征,采用包含稠密时序边界回归、语义匹配分数预测以及交并比回归的多分支任务,分别获得每一帧处的目标片段时序边界回归值、语义匹配分数和时序交并比回归值;步骤s6:对步骤s2-步骤s5所组成的基于模态定制协同注意力交互的时序语言定位模型,利用所述训练数据集进行训练,训练所采用的损失函数由边界损失、语义匹配损失和交并比回归损失三项组成,并使用优化器进行模型参数的更新,得到训练好的基于模态定制协同注意力交互的时序语言定位模型;步骤s7:利用所述测试数据集对训练好的基于模态定制协同注意力交互的时序语言定位模型进行测试,将所得到的具有最高置信度值的目标片段时序边界回归值作为所述测试数据集的时序语言定位结果。2.如权利要求1所述的一种基于模态定制协同注意力交互的时序语言定位方法,其特征在于,所述步骤s2具体包括以下子步骤:步骤s21:利用视频编码器中视觉预训练模型以离线方式对未剪辑视频-文本查询数据中的未剪辑视频提取视频帧表征并均匀地采样t帧;步骤s22:将t帧视频帧表征通过视频编码器中若干配备残差连接的一维卷积块,获取序列长度为t且特征维度为d的一组视频表征;步骤s23:将所述一组视频表征通过视频编码器中若干自注意力块,构建全局上下文时序依赖建模的视频表征v。3.如权利要求1所述的一种基于模态定制协同注意力交互的时序语言定位方法,其特征在于,所述步骤s3具体包括以下子步骤:步骤s31:利用查询编码器中预训练词嵌入模型对未剪辑视频-文本查询数据中的文本查询数据提取每个单词相应的词嵌入向量,获取词嵌入向量序列;步骤s32:通过查询编码器中多层的双向长短时记忆网络对所述词嵌入向量序列进行上下文编码,获得总单词数为l且特征维度为d的单词级查询表征w;步骤s33:将所述单词级查询表征中最后一个单词的前向隐状态向量和第一个单词的后向隐状态向量进行拼接,获得句子级查询表征q
s
;
步骤s34:所述单词级查询表征w和所述句子级查询表征q
s
组合得到多粒度查询表征q。4.如权利要求1所述的一种基于模态定制协同注意力交互的时序语言定位方法,其特征在于,所述步骤s4具体为:将所述视频表征v和所述多粒度查询表征q作为模态定制协同注意力交互模块的输入,依次经过所述模态定制协同注意力交互模块中的若干层模态定制的双流协同注意力交互层进行跨模态融合,得到对应层输出的视频表征和多粒度查询表征,最后一层模态定制的双流协同注意力交互层输出的视频表征作为已语义对齐视频表征。5.如权利要求4所述的一种基于模态定制协同注意力交互的时序语言定位方法,其特征在于,所述模态定制的双流协同注意力交互层包括视频流的多粒度协同注意力交互和查询流的标准协同注意力交互,具体实施过程为:视频流的多粒度协同注意力交互:将前一模态定制的双流协同注意力交互层输出的视频表征和多粒度查询表征作为输入,采用哈达玛乘积将所述视频表征和所述多粒度查询表征中的句子级查询表征进行粗粒度融合,得到背景帧表征抑制的视频表征,将所述背景帧表征抑制的视频表征采用一块多头自注意力块进行模态内时序上下文建模,得到视频表征;再次将所述视频表征作为查询,将所述多粒度查询表征中的单词级查询表征作为键和值,采用一块多头交叉注意力块进行模态间的跨模态对齐;最后采用两层的前馈网络得到第层模态定制的双流协同注意力交互层的视频表征输出;查询流的标准协同注意力交互:将前一模态定制的双流协同注意力交互层输出的视频表征和多粒度查询表征作为输入,将所述多粒度查询表征采用一块多头自注意力块进行模态内时序上下文建模,得到多粒度查询表征;将所述多粒度查询表征作为查询,将所述视频表征作为键和值,采用一块多头交叉注意力块进行模态间的跨模态对齐;最后采用两层的前馈网络得到第层模态定制的双流协同注意力交互层的多粒度查询表征输出。6.如权利要求1所述的一种基于模态定制协同注意力交互的时序语言定位方法,其特征在于,所述步骤s5具体包括以下子步骤:步骤s51:稠密时序边界回归任务:将所述已语义对齐视频表征作为稠密时序边界回归任务的输入,采用两层的一维卷积,经过第一层一维卷积后得到稠密时序边界回归的输出表征v
d
,且最后一层一维卷积用sigmoid函数激活,在视频每一帧处稠密回归当前帧到目标视频片段的起始和结束时间点的归一化距离,获得每一帧处的目标片段时序边界回归值;步骤s52:语义匹配分数预测任务:将所述已语义对齐视频表征作为语义匹配分数预测任务的输入,采用两层的一维卷积,经过第一层一维卷积后得到语义匹配分数预测的输出表征v
s
,且最后一层一维卷积不激活,获得每一帧处的语义匹配分数;步骤s53:时序交并比回归任务:将所述稠密时序边界回归任务的输出表征v
d
和所述语
义匹配分数预测任务的输出表征v
s
沿着通道维进行拼接,得到的拼接表征作为交并比回归任务的输入,采用三层的一维卷积且最后一层用sigmoid函数激活,获得每一帧处所回归目标片段与标注目标片段的时序交并比回归值。7.如权利要求1所述的一种基于模态定制协同注意力交互的时序语言定位方法,其特征在于,所述步骤s6具体包括以下子步骤:步骤s61:将所述训练数据集作为输入,通过步骤s2-步骤s5所组成的基于模态定制协同注意力交互的时序语言定位模型,得到每一帧的目标片段时序边界回归值、语义匹配分数和时序交并比回归值;步骤s62:计算边界损失:计算所述步骤s61中得到的每一帧所述目标片段时序边界回归值与相应目标片段时序边界标注值的平滑损失,作为每一帧的第一边界损失;计算步骤步骤s61中得到的每一帧所述目标片段时序边界回归值与相应目标片段时序边界标注值的时序交并比,并将所述时序交并比取负值,作为每一帧的第二边界损失;将每一帧的所述第一边界损失和所述第二边界损失求和作为每一帧边界损失,计算所述训练数据集中所标注目标视频片段内所有视频帧的边界损失平均值,作为模型训练的边界损失;步骤s63:计算语义匹配损失:将所述步骤s61中得到的每一帧所述语义匹配分数沿着时序维度依次进行softmax操作、取对数操作以及取负值操作,得到每一帧视频帧相应的语义匹配损失,计算所述训练数据集中所标注目标视频片段内所有视频帧的语义匹配损失平均值,作为模型训练的语义匹配损失;步骤s64:计算时序交并比回归损失:将所述步骤s61中得到的每一帧所述目标片段时序边界回归值与标注目标片段的时序交并比作为时序交并比目标值,计算每一帧所述时序交并比目标值与所述步骤s61中得到的每一帧所述时序交并比回归值的绝对差值,并计算所述绝对差值在所述训练数据集中所有视频帧的平均值,作为模型训练的时序交并比回归损失;步骤s65:将所述模型训练的边界损失、所述模型训练的语义匹配损失以及所述模型训练的时序交并比回归损失的加权和作为模型训练的总损失,并使用优化器进行模型参数的更新,经过预设次数迭代训练,得到训练好的基于模态定制协同注意力交互的时序语言定位模型。8.如权利要求1所述的一种基于模态定制协同注意力交互的时序语言定位方法,其特征在于,所述步骤s7具体包括以下子步骤:步骤s71:将所述测试数据集作为训练好的基于模态定制协同注意力交互的时序语言定位模型的输入,获得所述测试数据集每一帧处的目标片段时序边界回归值、语义匹配分数和时序交并比回归值,将得到的语义匹配分数经过sigmoid函数处理,得到归一化语义匹配分数;步骤s72:将所述归一化语义匹配分数与所述步骤s71中得到的所述时序交并比回归值在每一帧处相乘,所得的乘积作为每一帧处目标片段时序边界回归值的置信度值;步骤s73:选择具有最高置信度值的目标片段时序边界回归值作为所述测试数据集的时序语言定位结果。9.一种基于模态定制协同注意力交互的时序语言定位装置,其特征在于,包括存储器
和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现权利要求1-8中任一项所述的基于模态定制协同注意力交互的时序语言定位方法。10.一种计算机可读存储介质,其特征在于,其上存储有程序,该程序被处理器执行时,实现权利要求1-8中任一项所述的基于模态定制协同注意力交互的时序语言定位方法。
技术总结
本发明公开了基于模态定制协同注意力交互的时序语言定位方法及装置,包括以下步骤:步骤S1:构建数据集;步骤S2:提取视频表征;步骤S3:得到多粒度查询表征Q;步骤S4:获取已语义对齐视频表征;步骤S5:获得每一帧处的目标片段时序边界回归值、语义匹配分数和时序交并比回归值;步骤S6:得到训练好的基于模态定制协同注意力交互的时序语言定位模型;步骤S7:测试,得到时序语言定位结果。本发明将配备协同注意力的Transformer架构用于时序语言定位任务,并设计了一种模态定制的双流协同注意力交互层,用于并行的视频流的多粒度协同注意力交互和查询流的标准协同注意力交互,本发明方法实现简单,手段灵活,可显著提升时序语言定位任务性能。位任务性能。位任务性能。
技术研发人员:王聪 宋明黎
受保护的技术使用者:之江实验室
技术研发日:2022.09.21
技术公布日:2022/10/25
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。