基于cnn-lstm的波致海床瞬态液化对再悬浮贡献率的预测方法
技术领域
1.本发明涉及海洋沉积动力学领域,具体而言,特别涉及一种基于cnn-lstm的波致海床瞬态液化对再悬浮贡献率的预测方法。
背景技术:
2.在波浪循环荷载作用下,海床内孔隙水压力累积导致的海床渗流甚至液化,会使海床内部细颗粒发生向上输运到海水中,成为悬浮物质。已有研究成果表明,粉质土海床具有波致液化特性,瞬态液化和累积液化都会使海床内部细颗粒沉积物输运到上覆水体,其中,瞬态液化对沉积物再悬浮的贡献率不容忽视,达到了20%~60%。因此,准确预测不同海况下瞬态泵送对再悬浮的贡献率对近岸海床侵蚀量的计算和侵蚀灾害的有效评估具有重要意义。
3.近底床海水悬沙浓度(suspended sediment concentration, ssc)是研究海底侵蚀再悬浮的关键参数。对于悬沙浓度的预测,通常做法是在现场采集海水样品在室内进行分析,建立基于物理规律的数值计算模型或基于统计的数学模型。然而,为了使模型的计算精度更高,就需要考虑非常多的参数和复杂的过程,这是沉积物侵蚀再悬浮的一大难点。
4.因此,针对以上问题,需要建立一种找到一种具有物理意义的数据驱动方法,准确实现波致瞬态液化对再悬浮贡献率的预测,基于深度学习的人工智能方法是可行的方案。深度学习方法可以从大量数据集中提取特征信息,这些信息可以作为理解深层次物理规律的证据。人工神经网络(ann)已广泛应用于海岸泥沙动力学研究,在悬沙浓度(时间序列数据)的预测和沿岸泥沙输移速率计算等方面表现突出。
技术实现要素:
5.为了弥补现有技术的不足,本发明提供了一种基于cnn-lstm的波致海床瞬态液化对再悬浮贡献率的预测方法, 解决了以往技术中数据特征获取、传统预测方法精度不高等问题。
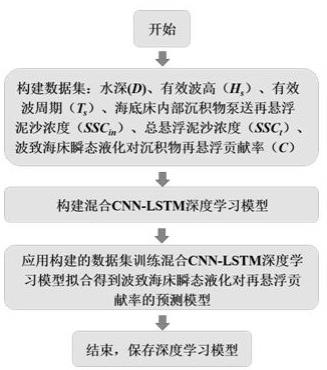
6.本发明是通过如下技术方案实现的:一种基于cnn-lstm的波致海床瞬态液化对再悬浮贡献率的预测方法,其特征在于,具体包括以下步骤:步骤1:在研究区进行海水悬沙浓度和水动力条件的原位长期观测,获取训练和测试模型的数据集,包括水深(d)、有效波高(hs)、有效波周期(ts)、海底床内部沉积物泵送再悬浮泥沙浓度(s
in
)、总悬浮泥沙浓度(s
t
);步骤2:按照公式(1)计算波致海床瞬态液化对沉积物再悬浮贡献率;
ꢀꢀ
(1)其中,为总悬浮泥沙浓度(s
t
)的均值;步骤3:得到自变量和目标变量的时间序列数据;
步骤4:根据式(2)对原始数据集进行归一化处理:
ꢀꢀ
(2);其中和分别为数据集的最大值和最小值,x为输入值,z为x的转换值。
7.步骤5:将数据集拆分为训练集和测试集,将训练集和测试集分别拆分为输入和输出变量。最后将输入变量(x)转变成conv1d需要的三维格式,即[samples, timesteps, features];步骤6:搭建深度学习预测方法的运行环境,安装python 3.6和集成开发环境pycharm软件,在pycharm上安装深度学习框架tensorflow和深度学习库keras;步骤7:建立cnn-lstm深度学习模型;依次设置conv1d层和maxpooling1d层三组,lstm层两层,在每层lstm后设置dropout防止过拟合,预测值在最后一层(第九层)输出;步骤8:设置超参数,包括学习率为0.0001,conv1d层和maxpooling1d层神经元单元数量均为64,filters=8,kernelsize=2,poolsize=2,两层lstm神经元数量均为100个,输出层设置一个神经元,也作为预测值的输出;dropout设置为0.5;步骤9:通过调用keras内置的model.fit函数来拟合混合cnn-lstm模型,设置迭代次数epoch=64,得到train和测试集test的损失函数值lossvalue1;步骤10:以迭代次数epoch为x轴,以损失函数值lossvalue1为y轴绘制平均绝对误差(mae)损失函数的趋势线;步骤11:调用keras内置的model.predict函数进行预测,输入数据为测试集的自变量矩阵,输出为模型的预测值c’;步骤12:将预测的数据集与测试数据集相结合,进行步骤4归一化处理的逆运算;步骤13:根据式(3)计算与变量本身相同的单位产生误差的均方根误差(rmse):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3);其中,t为计数参数,n为数据的个数,和分别为真实值和模型预测值;步骤14:若rmse过大,或者损失函数的趋势线手动调整cnn-lstm模型的超参数进行模型优化,直到得到相对较小的rmse值;步骤15:调用keras内置的model.save函数保存模型至计算机;步骤16:结束。
[0008]
作为优选方案,步骤3中的自变量包括水深(d)、有效波高(hs)、有效波周期(ts)、海底床内部沉积物泵送再悬浮泥沙浓度(s
in
)、总悬浮泥沙浓度(s
t
)。
[0009]
作为优选方案,步骤4中的数据集为训练集和测试集,x代指自变量和目标变量。
[0010]
作为优选方案,步骤5中将数据集拆分为训练集和测试集,将前75%的数据作为训练集,后25%的数据作为测试集。
[0011]
作为优选方案,步骤8中的所有激活函数都使用了整流线性单元(relus),优化算法optimizer为adam算法。
[0012]
本发明由于采用了以上技术方案,与现有技术相比使其具有以下有益效果:该方法使用原位观测的悬沙浓度和水动力条件数据,构建并拟合了基于cnn-lstm的混合深度学
习模型的波致海床瞬态液化对再悬浮贡献率模型,对侵蚀再悬浮沉积物的来源之一——波致瞬态液化导致的再悬浮量进行预测。该模型结合1d-cnn自动提取多变量之间特征,以及lstm自动提侵蚀再悬浮过程中的时间序列信息,最后通过捕捉各种再悬浮发生的变量相关性和时间序列相关性以得到更高的预测准确率。
[0013]
本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
附图说明
[0014]
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:图1是本发明总体流程图;图2为本发明构建混合cnn-lstm模型的逻辑结构图;图3为用于本发明一种基于cnn-lstm的波致海床瞬态液化对再悬浮贡献率的预测方法的训练和预测的时间序列数据示例图;图4为本发明步骤10得到的损失函数的趋势线图;图5为本发明步骤11得到的预测值与真实值对比图。
具体实施方式
[0015]
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。
[0016]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
[0017]
本发明的原理如下:将多变量时间序列矩阵数据按照一定的时间步长划分为3d张量格式,即[samples, timesteps, features]。1d-cnn可以从3d张量数据中提取特征,然后利用cnn的输出作为lstm的输入,发挥lstm的输入之间有一个很长的延迟和反馈,梯度既不会爆炸也不会消失的优点,进行时间序列的预测。
[0018]
下面结合图1至图5对本发明的实施例的波致海床瞬态液化对再悬浮贡献率的深度学习预测方法进行具体说明。
[0019]
如图1所示,本发明提出了骤1:在研究区进行海水悬沙浓度和水动力条件的原位长期观测,得到数据集包括水深(d)、有效波高(hs)、有效波周期(ts)、海底床内部沉积物泵送再悬浮泥沙浓度(sin)、总悬浮泥沙浓度(st)。
[0020]
步骤2:按照公式(1)计算波致海床瞬态液化对沉积物再悬浮贡献率。
[0021]
ꢀꢀ
(1)其中,为总悬浮泥沙浓度(s
t
)的均值;步骤3:得到自变量(d,hs,ts,s
in
,,s
t
)和目标变量(c)的时间序列数据(如附图3)。
[0022]
步骤4:根据式(2)对原始数据集进行归一化处理。
[0023]
(2)其中和分别为数据集(训练集和测试集)的最大值和最小值,x为输入值(这里代指自变量和目标变量),z为x的转换值。
[0024]
步骤5:将数据集拆分为训练集和测试集,这里将前75%的数据作为训练集,后25%的数据作为测试集。然后将训练集和测试集分别拆分为输入和输出变量。最后将输入变量(x)转变成conv1d需要的三维格式,即[samples, timesteps, features]。
[0025]
步骤6:搭建深度学习预测方法的运行环境。安装python 3.6和集成开发环境pycharm软件,在pycharm上安装深度学习框架tensorflow和深度学习库keras。
[0026]
步骤7:建立cnn-lstm深度学习模型。依次设置conv1d层和maxpooling1d层三组,lstm层两层,在每层lstm后设置dropout防止过拟合,预测值在最后一层(第九层)输出。
[0027]
步骤8:设置超参数,包括学习率为0.0001,conv1d层和maxpooling1d层神经元单元数量均为64,filters=8,kernelsize=2,poolsize=2,两层lstm神经元数量均为100个,输出层设置一个神经元,也作为预测值的输出。dropout设置为0.5。所有的激活函数都使用了整流线性单元(relus),优化算法optimizer为adam算法。
[0028]
步骤9:通过调用keras内置的model.fit函数来拟合混合cnn-lstm模型,设置迭代次数epoch=64,得到训练集train和测试集test的损失函数值lossvalue1。
[0029]
步骤10:以迭代次数epoch为x轴,以损失函数值lossvalue1为y轴绘制平均绝对误差(mae)损失函数的趋势线(附图4)。
[0030]
步骤11:调用keras内置的model.predict函数进行预测,输入数据为测试集的自变量矩阵,输出为模型的预测值c’。预测值c’与真实值c的对比结果如附图5。
[0031]
步骤12:根据式(3)计算与变量本身相同的单位产生误差的均方根误差(rmse)。
[0032]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)其中,n为数据的个数,和分别为真实值和模型预测值。
[0033]
步骤13:若rmse过大,或者损失函数的趋势线手动调整cnn-lstm模型的超参数进行模型优化,直到得到相对较小的rmse值。最后的rmse=1.5155。
[0034]
步骤14:保存模型至计算机。
[0035]
步骤15:结束。
[0036]
在本发明的描述中,术语“多个”则指两个或两个以上,除非另有明确的限定,术语“上”、“下”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制;术语“连接”、“安装”、“固定”等均应做广义理解,例如,“连接”可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
[0037]
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或特点包含于本发明的至少一个实
施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0038]
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。