1.本发明涉及质谱分析,特别涉及基于直接电离质谱的爆炸物检测方法。
背景技术:
2.爆炸物常见检测方法包括免疫法、光谱法、化学传感器法以及质谱法等。 在众多检测方法中,质谱检测法因具有灵敏度高、分辨率高、定性定量准确等 优点得到广泛的发展与应用。对于复杂样品分析,一般采用色谱与质谱联用来 提高检测方法的抗干扰能力,然而,样品的制备及前处理过程使检测方法更繁 琐、耗时,大大降低了检测效率。随着安全形势的发展和公民环保意识的增强, 国土安全、环境保护等领域亟需现场快速准确检测爆炸物的有效方法。作为一 种在敞开式环境下实现原位、实时、快速离子化的新型质谱分析技术,敞开式 离子化技术的发展给无需或只需极少的样品前处理带来了可能。然而,敞开式 质谱检测系统通常因工作环境和基质差异大,质谱信号易受各种干扰,同时质 谱信号中噪声峰、同位素峰等的存在会降低目标物质鉴定的准确性,给质谱数 据的处理和分析带来了巨大的挑战。
[0003][0004]
传统的质谱数据分析方法(如:提取离子流计算信噪比、高斯混合模型方 法)仅仅利用峰强信息,忽略了峰形、峰位置、半峰宽等重要参数,且由于质 谱峰强呈现对数正态分布,检测结果中空白对照样本和爆炸物样本交叉面积大, 设定的阈值无法进行正确分类,从而导致质谱信号易产生假阳性或假阴性的后 果。
[0005]
机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理 论知识和复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学 习方式,并将现有内容进行知识结构划分来有效提高学习效率。
[0006]
质谱检测过程中空白样本较易获取,爆炸物样本数量较少,正负样本数据 不平衡,且检测结果中空白对照样本和爆炸物样本交叉面积大,采用机器学习 的常规数据集划分方法来处理无法发挥其优势,因此没有人将机器学习应用于 质谱数据分析领域。
技术实现要素:
[0007]
为解决上述现有技术方案中的不足,本发明提供了一种基于直接电离质谱 的爆炸物检测方法。
[0008]
本发明的目的是通过以下技术方案实现的:
[0009]
基于直接电离质谱的爆炸物检测方法,所述基于直接电离质谱的爆炸物检 测方法包括以下步骤:
[0010]
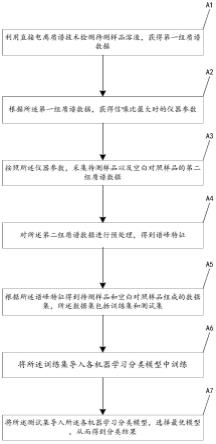
(a1)利用直接电离质谱技术检测待测样品溶液,获得第一组质谱数据;
[0011]
(a2)根据所述第一组质谱数据,获得信噪比最大时的仪器参数;
[0012]
(a3)按照所述仪器参数,采集待测样品以及空白对照样品的第二组质谱 数据;
[0013]
(a4)对所述第二组质谱数据进行预处理,得到谱峰特征;
[0014]
(a5)根据所述谱峰特征得到待测样品和空白对照样品组成的数据集,所 述数据集包括训练集和测试集;
[0015]
(a6)将所述训练集导入各机器学习分类模型中训练;
[0016]
(a7)将所述测试集导入所述各机器学习分类模型,选择最优模型,从而 得到分类结果。
[0017]
与现有技术相比,本发明具有的有益效果为:
[0018]
本发明解决了直接电离质谱和机器学习间组合的技术问题,从而将直接电 离质谱和机器学习组合在一起,达到了:
[0019]
1.采用boxcar滤波、基线扣除、插值平滑、高斯函数拟合组合的算法,得 到峰强、峰位置、半峰宽等重要参数,增加了机器学习算法的输入特征;
[0020]
2.利用机器学习算法,考虑了峰强、峰位置、半峰宽等重要峰形参数,解 决了直接电离质谱峰强呈现对数正态分布,空白对照样本和爆炸物样本交叉面 积大,常规检测算法依赖选取阈值的问题,以及单一峰强检测效果不佳的问题, 极大提高了检出限附近低浓度样品的检测准确率;
[0021]
3.利用机器学习算法对爆炸物进行分类时,结合大数据调整自动对仪器参 数进行优化,进一步提高了检测准确率;
[0022]
4.设计了一种机器学习数据集正负样本按照一定比例划分的算法,解决了 正负样本数据不平衡的固有问题,使得检测结果不受数据不平衡的影响;
[0023]
5.在所有随机森林分类方法检测中,相对于质谱仪获取单个样品质谱数据 需3~6s,单个样本数据分析时间不超过0.1s,可满足地铁、高铁、机场、快 递物流等人员密集场所的安检、爆炸物现场残留检测等实际场景的检测需求;
[0024]
6.所用方法显著提高了直接电离质谱系统中检出限附近低浓度样品的检测 准确性,易于推广应用。
附图说明
[0025]
参照附图,本发明的公开内容将变得更易理解。本领域技术人员容易理解 的是:这些附图仅仅用于举例说明本发明的技术方案,而并非意在对本发明的 保护范围构成限制。图中:
[0026]
图1图1是本发明的基于直接电离质谱的爆炸物检测方法的流程示意图;
[0027]
图2是质谱峰强统计分布与拟合图;
[0028]
图3是基于提取离子流和高斯混合模型的tnt检测结果;
[0029]
图4是基于机器学习的分类方法流程。
具体实施方式
[0030]
图1-4和以下说明描述了本发明的可选实施方式以教导本领域技术人员如 何实施和再现本发明。为了解释本发明技术方案,已简化或省略了一些常规方 面。本领域技术人员应该理解源自这些实施方式的变型或替换将在本发明的范 围内。本领域技术人员应该理解下述特征能够以各种方式组合以形成本发明的 多个变型。由此,本发明并不局限于下述可选实施方式,而仅由权利要求和它 们的等同物限定。
[0031]
实施例1:
[0032]
图1示意性地给出了本发明实施例1的基于直接电离质谱的爆炸物检测方 法的流程图,如图1所示,所述基于直接电离质谱的爆炸物检测方法包括以下 步骤:
[0033]
(a1)利用直接电离质谱技术检测待测样品溶液,获得第一组质谱数据;
[0034]
(a2)根据所述第一组质谱数据,获得信噪比最大时的仪器参数;
[0035]
(a3)按照所述仪器参数,采集待测样品以及空白对照样品的第二组质谱 数据;
[0036]
(a4)对所述第二组质谱数据进行预处理,得到谱峰特征;
[0037]
(a5)根据所述谱峰特征得到待测样品和空白对照样品组成的数据集,所 述数据集包括训练集和测试集;
[0038]
(a6)将所述训练集导入各机器学习分类模型中训练;
[0039]
(a7)将所述测试集导入所述各机器学习分类模型,选择最优模型,从而 得到分类结果。
[0040]
为了提高预处理效果,进一步地,预处理的方式包括极限扣除、平滑滤波 和峰形校正中的至少一种。
[0041]
为了防止数据集不平衡带来的过拟合或欠拟合的问题,进一步地,所述数 据集中,60%-90%的正样本和60%-90%的负样本组成训练集,10%-40%的正样 本和10%-40%的负样本组成测试集,训练集和测试集之和为100%。
[0042]
为了提高检测的准确率,进一步地,所述最优模型的选择方式为:
[0043]
在步骤(a7)中,导入所述测试集后,获得与各机器学习分类模型分别对 应的a是真阳性率,b是假阳性率,c是假阴性率;
[0044]
获得各个f值中的最大值,与该最大值对应的机器学习分类模型是最优模 型。
[0045]
为了提高检测的准确率,进一步地,所述谱峰特征包括峰强、峰位置、半 峰宽和峰面积中至少一个。
[0046]
为了提高检测的准确率,进一步地,所述机器学习分类模型包括逻辑回归、 决策树、支持向量机、k近邻、朴素贝叶斯、随机森林或adaboost。
[0047]
实施例2:
[0048]
根据本发明实施例1的基于直接电离质谱的爆炸物检测方法在tnt检测中 的应用例。
[0049]
在本应用例中,基于直接电离质谱的爆炸物检测方法包括以下步骤:
[0050]
(a1)利用直接电离质谱技术检测待测样品溶液,获得第一组质谱数据;
[0051]
针对tnt一级质谱数据的采集,自动调整质谱仪参数,如喷雾电压、毛细 管电压、管透镜电压等,并记录一级特征离子m/z 226的谱峰强度,得到待测物 的多组质谱图数据;
[0052]
针对tnt二级质谱(ms/ms)数据的采集,自动调整质谱仪参数,如隔离 宽度、碰撞能量等,使得碎片子离子m/z 196和母离子m/z 226的谱峰强度呈现 不同的比例关系,得到待测物的多组质谱图数据;
[0053]
(a2)根据所述第一组质谱数据,获得信噪比最大时的仪器参数;
[0054]
结合大数据,记录信噪比最大时的仪器参数,即为最优仪器参数,此时, 碎片子离子m/z 196和母离子m/z 226的谱峰强度比约为3:1;
[0055]
(a3)按照所述仪器参数,采集待测样品以及空白对照样品的第二组质谱 数据;
[0056]
(a4)对所述第二组质谱数据进行预处理,进行本底扣除、平滑滤波、峰 形校正等处理,得到包括峰强、峰位置、半峰宽和峰面积的谱峰特征;
[0057]
(a5)根据所述谱峰特征得到待测样品和空白对照样品组成的数据集,将 数据集中正负样本分别按8:2划分为训练集和测试集;
[0058]
由于同一浓度爆炸物样本质谱峰强分布范围比较广,可达几个数量级,对 峰强取对数后服从高斯分布,也称对数正态分布,如图2所示;而传统质谱数 据分析方法(提取离子流计算信噪比和高斯混合模型方法)仅仅利用了峰强信 息,忽略了峰位置、半峰宽等重要峰特征参数,同时,由于质谱峰强呈现对数 正态分布,检测结果中空白对照样本和爆炸物样本交叉面积大,设定的阈值无 法进行正确分类,如图3所示,从而导致质谱信号易产生假阳性或假阴性;
[0059]
(a6)将所述训练集导入各机器学习分类模型中训练,所述机器学习分类 模型包括逻辑回归、决策树、支持向量机、k近邻、朴素贝叶斯、随机森林或 adaboost;
[0060]
(a7)将所述测试集导入所述各机器学习分类模型,之后,获得与各机器 学习分类模型分别对应的a是真阳性率,b是假阳性率,c是假阴 性率;
[0061]
获得各个f值中的最大值,与该最大值对应的机器学习分类模型是最优模 型;如下述表格所示,对于一级质谱数据高斯混合模型效果比较好,f为0.89; 而对于二级质谱数据,随机森林算法模型最好,f为0.93,且好于高斯混合模型 应用于一级质谱数据时的效果;
[0062][0063]
所述最优模型获得分类结果,也即检测结果。
[0064]
实施例3:
[0065]
根据本发明实施例1的基于直接电离质谱的爆炸物检测方法在tnt和硝酸 铵中的实验。
[0066]
1实验部分
[0067]
1.1主要仪器与试剂
[0068]
ltq质谱仪:美国thermo公司,配有xcalibur数据处理系统;dbdi-100 离子源:宁波华仪宁创智能科技有限公司;sqp分析天平:德国赛多利斯公司。
[0069]
梯恩梯(2,4,6-trinitrotoluene,tnt,纯度大于99%):上海百灵威化学技术有 限公司;硝酸铵(纯度大于99%):北京普天同创生物科技有限公司;乙酰水杨酸 (纯度大于
99%):上海阿拉丁生化科技股份有限公司;甲醇(色谱纯):宁波市江 东昌远仪器仪表有限公司。
[0070]
标准溶液的配置:tnt、硝酸铵和乙酰水杨酸分别用甲醇溶解,配置至所 需浓度。
[0071]
1.2实验方法
[0072]
基于dbdi-ms的爆炸物样品检测平台,具体如下:离子源出口距质谱仪进 样口2.0cm,将配置好的样品溶液滴加在样品载台上,上表面距质谱仪进样口 下方0.5cm,以45
°
反射进样方式进行样品分析。本文dbdi采用单电极,当 电极上施加高压时,离子化气体电离形成稳定的等离子体,并通过绝缘介质管 喷射出来。实验采用ltq质谱仪,在full scan和ms/ms模式下进行,设置为 负离子检测模式,扫描范围m/z为60~580amu,喷雾电压为-4kv,离子化气体 为氦气,氦气流速为3l/min,离子源温度为200℃,离子传输线温度为275℃, 毛细管电压为-21v,管透镜电压为-57v。
[0073]
1.3数据分析
[0074]
1.3.1数据预处理
[0075]
采用numpy、scipy等对质谱数据进行处理。scikit-learn是python中广泛 应用的机器学习库,它包含了大量的ml算法及从数据预处理到模型训练、模 型测试等各个工具函数。研究中采用的数据预处理主要有boxcar滤波、插值平 滑和峰形校准。
[0076]
1.3.2分类方法
[0077]
(1)提取离子流
[0078]
eic指一定质荷比范围内的峰强之和。鉴于ltq-ms的分辨率,本研究在 目标峰对应的质荷比左右各0.5amu内,通过计算爆炸物和空白对照样本的eic 强度,计算各自的统计分布,并设定阈值进行分类。通常正态分布遵循如下高 斯函数:
[0079][0080]
式中,μ、σ分别表示eic强度的均值和标准差。
[0081]
(2)高斯混合模型
[0082]
gmm指多个高斯函数的线性组合,利用期望极大化(expectationmaximization,em)算法对参数进行估计。本研究分别提取爆炸物和空白对照样 本的峰强,以其均值和标准差作为初始值,通过em多次迭代得到收敛后的均 值和标准差作为样本中心,然后计算未知谱峰到样本中心的欧式距离并对其进 行分类。
[0083]
对多张质谱图中目标离子m/z 179对应的峰强进行统计分析,发现对于同一 浓度的乙酰水杨酸样品,其峰强分布范围比较广,可达五个数量级,且伽马函 数相比高斯函数具有更好的拟合效果,然而,拟合参数的选取对伽马函数的拟 合结果影响很大。若对峰强取对数后,相应几率与高斯函数高度吻合,通常这 种分布又称为对数正态分布。因此除特殊说明外,本研究都先对峰强取对数后, 再进行其它分析。
[0084]
(3)基于机器学习的分类方法
[0085]
本研究采用基于ml的分类方法对爆炸物进行分类。原始质谱数据经预处 理后,获得特征矢量(峰强、峰位置和半峰宽),并对其进行主成分分析(principalcomponent analysis,pca),计算各特征矢量占原始数据总信息量的比例。然后, 将数据集划分为训练集(80%)和测试集(20%)进行模型训练和模型测试。
[0086]
1.3.3性能评估
[0087]
爆炸物样本设为阳性,空白对照样本设为阴性。查准率(precision)、查全率(recall)分别反映假阳性(fp)、假阴性(fn)情况,本研究以precision和recall的调 和平均f作为综合性能指标,只有当两者均很高时,f才很大,即分类器效果好。 f与precision、recall之间的定量关系如下:
[0088][0089]
2结果与讨论
[0090]
本研究采用的数据集为检出限附近浓度为1ng/ml的乙酰水杨酸样本(115 个)、两种爆炸物样本(tnt、硝酸铵分别110个、90个)和空白对照样本(366 个)。
[0091]
2.1乙酰水杨酸检测结果分析
[0092]
由于乙酰水杨酸母离子[m-h]-(m/z 179)易碎裂成m/z 137,故对其双目标离 子峰m/z 137、179进行质谱检测分析。
[0093]
2.1.1基于提取离子流和高斯混合模型方法的乙酰水杨酸检测结果
[0094]
数据分析表明,乙酰水杨酸在离子峰m/z 137和179处的峰强分布特点及一 级质谱检测结果均类似,且在离子峰m/z 137处的检测准确率更高,因此,本研 究重点介绍在离子峰m/z 137处的检测结果。对质量范围在136.5~137.5amu的 乙酰水杨酸采用eic和gmm的检测结果。乙酰水杨酸与空白对照样本eic强 度分布之间存在一定的交叉,可能导致设定单一的阈值检测效果不佳,从而出 现一定的假阳性率(fpr)、假阴性率(fnr)。fpr、fnr分别表示将阴性错分为 阳性的样本占所有阴性样本的比率、将阳性错分为阴性的样本量占所有阳性样 本的比率,分类结果比较依赖所设定的阈值。
[0095]
另外,采用gmm分类结果的准确性与所选取的阈值紧密相关。分析表明, 当设定阈值为4.2和f=0.58时,分别对应eic和gmm各自的最优检测结果, 此时,f分别为0.74和0.89。易知,gmm相比eic具有更高的检测准确性,然 而检测结果均过于依赖设定的阈值,在阈值附近的质谱信号很难被正确分类, 易造成假阳性、假阴性。
[0096]
2.1.2基于机器学习的乙酰水杨酸检测结果
[0097]
如引言所述eic和gmm仅仅利用了离子信号强度的信息,而忽略了峰位 置、半峰宽等重要信息。因此,本研究基于质谱信号的相关特征,结合ml对 不同样品进行分类,以提高检测的准确性。对乙酰水杨酸的pca分析结果表明, 峰强占82.4%,为最重要的特征,峰位置、半峰宽分别占13.8%、3.2%,下文将 这三个参数作为特征进行模型训练和测试。利用ml对乙酰水杨酸的检测结果 如下表所示。
[0098]
由于ml除了考虑峰强这个单一特征外,还引入了半峰宽和峰位置特征, 有效降低了空白样品中背景离子eic强度过高引起的fpr,故基于ml的检测 准确率整体都较高。综合考虑下表中各ml的训练时间、测试时间及检测准确 性等因素,重点介绍采用随机森林(random forest,rf)分类方法对乙酰水杨 酸数据的研究。rf是利用多棵树对样本进行训练、测试的一种集成算法。在进 行分类预测时,rf分别使用训练时得到的多组分类器进行预测,最终选择分类 器投票结果中最多的类别作为分类结果,具有防止过拟合、检测结果准确可靠、 适应性强等优势。分析结果表明,与eic和gmm相比,基于rf的检测准确率 具有最明显的提高,且单个样本数据分析时间均不超过0.1s,可达到快速检测 乙酰水杨酸的目
的。此外,为验证rf在爆炸物检测中的适用性,以同样的流程 对两种典型爆炸物tnt、硝酸铵进行研究。
[0099][0100]
**both training time and test time represent the average time required for a single sample data analysis(训 练时间、测试时间均表示平均单个样本数据分析所需的时间)
[0101]
2.2tnt检测结果分析
[0102]
2.2.1基于随机森林分类方法的tnt一级、二级质谱检测结果
[0103]
tnt的dbdi-ms一级负离子质谱(m/z 226)以及经碰撞诱导解离后的二级 质谱。在所有碎片离子中,[tnt-no-h]-(m/z 196)的丰度最高,可见tnt最易 丢失no基团。
[0104]
参考2.1.2节中乙酰水杨酸各ml的研究结果,这里同样采用rf对tnt一 级、二级质谱进行检测。分析结果表明,tnt一级、二级质谱的f_score分别达 到0.76和0.93,且平均单个样本数据分析时间均不超过0.1s。相比一级质谱, ms/ms在fpr较低的情况下,仍然有很高的真阳性率,检测准确率提高比较显 著,这是因为m/z 196采用ms/ms获得,背景干扰被大幅度降低了,类似于利 用高分辨质谱可减少质荷比相同的背景离子对检测的影响。分析表明,与表1 中其它ml相比,rf为最佳选择,这与2.1.2节中乙酰水杨酸分析结果类似。
[0105]
2.2.2基于提取离子流和高斯混合模型方法的tnt一级、二级质谱检测结 果
[0106]
实验结果表明,对于tnt一级质谱,质量范围在225.5~226.5amu时,tnt 与空白对照样本的eic强度分布之间的交叉大。eic中fnr、fpr和阈值之间 的关系,通过设定单一的阈值检测效果不佳,fn、fp情况此消彼长,即出现少 量fn时,fp情况也严重,这与2.1.1节中乙酰水杨酸检测结果类似。当fnr、 fpr达到均衡状态时,也达到40%以上,这是由于溶剂或空气中背景离子m/z 226 的干扰,使空白样品中eic强度过高,从而出现fp。
[0107]
另外,采用gmm分类结果的准确性也与所选取的阈值紧密相关。分析表 明,当设定阈值为3.6和f=0.56时,分别对应eic和gmm各自的最优检测结 果,此时f分别为0.30、0.89,即gmm相比eic具有更高的检测准确性。可能 由于空气中塑化剂等的影响,tnt一级质谱杂质较多且噪声严重,从而使质谱 信号出现拖尾、重叠等不规则峰形,导致一级质谱的检测准确率偏低。
[0108]
tnt ms/ms的eic强度分布,与一级质谱相比,ms/ms中tnt与空白对 照样本的交叉明显减小,分类效果也有所提高。eic相比gmm的检测准确性略 高,如同上述tnt一级质谱结果,设定的阈值对检测结果影响均较大。因此, 与传统的eic和gmm方法相比,rf同样也能较好地对tnt进行分类。
[0109]
2.3硝酸铵检测结果分析
[0110]
除了tnt外,为进一步验证rf在爆炸物检测中的适用性,本研究还对另 一种爆炸
物硝酸铵进行研究。采用eic、gmm和ml对其双目标离子[no3]-(m/z 62)和[(hno3)no3]-(m/z 125)进行分类检测。结果表明,当eic中设定阈值为 5.1和gmm中f=0.56时,分别对应eic和gmm各自的最优检测结果,此时, f分别为0.84、0.88。利用rf检测时,f可达0.95,且单个样本数据分析时间 也不超过0.1s。因此,rf同样也能满足对硝酸铵的快速检测。
[0111]
3结论
[0112]
本研究基于dbdi-ms联用技术,利用爆炸物模拟物乙酰水杨酸进行质谱数 据预处理和分类算法研究,建立了一种适用于低浓度的典型爆炸物tnt和硝酸 铵的快速、准确检测方法。实验数据分析表明,无论是空白对照样品还是同一 浓度爆炸物样品,信号强度皆呈对数正态分布,横跨几个数量级,这导致传统 的eic和gmm对预设定的阈值较敏感。在典型爆炸物的分类检测中,rf检测 准确率均最高,可满足检测需求,且相比传统的eic和gmm,具有无需设定阈 值的优势;同时,在所有rf检测中,相对于质谱仪获取单个样品质谱数据需约 1~5s,单个样本数据分析时间皆不超过0.1s,因此可满足快速、实时检测需求。 此外,进一步研究发现,针对tnt检测,ms/ms相比一级质谱可大幅度降低背 景干扰,检测准确率显著提高。综上所述,直接电离质谱技术结合ml可满足 现场快速、实时、准确检测爆炸物的需求,具有较好的应用前景。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
