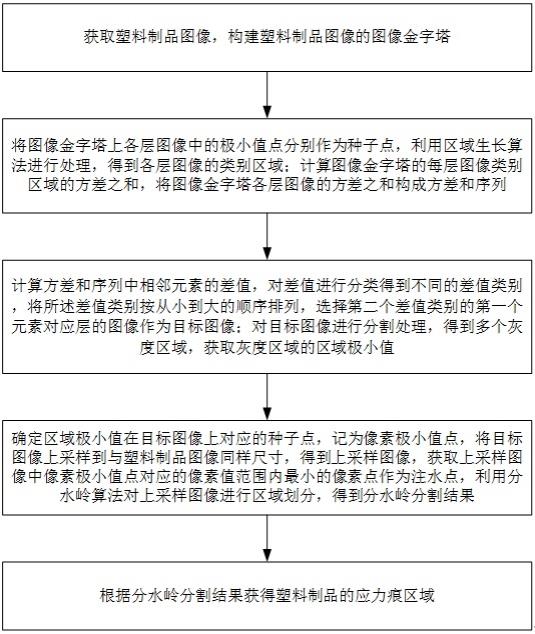
1.本发明涉及点云全景分割技术领域,特别涉及一种用于点云全景分割的系统及方法。
背景技术:
2.点云通常是指三维空间坐标系下的点集合,其例如可由激光雷达向目标发射激光获取,又例如可通过对建模仿真物体进行稀释点抽取获取。点云中所包含的点称为点云点,其可包括空间位置、强度、颜色和时间等信息。
3.点云全景分割技术目的在于将所有的像素点赋予类别的标签,并将不同的实例物体分割开来,多应用于自动驾驶、室内仿真、高精度地图制作以及增强现实等行业中。现有的点云全景分割任务通常同时采用了语义分割和实例分割两个分支共同解决点云全景分割任务。具体而言,这类方法首先利用点云特征提取技术从点云中提取特征,再将特征分别输入负责语义分割、实例分割的神经网络得到语义分割结果和实例分割结果,最后将这两个结果融合起来得到全景分割结果。其流程较为复杂,且需要设计合理的策略用以合并两个分支的分割结果,其可能存在较大的误差。此外,现有的实例分割技术中,通常需要手动生成的实例中心作为学习目标。这样的实例中心会随着激光雷达扫描角度的改变而改变,其稳定性较差,因此会造成训练的模糊性,影响最终性能。
技术实现要素:
4.针对现有技术中的部分或全部问题,本发明一方面提供一种用于点云全景分割的系统,包括可学习卷积核以及第一神经网络结构,其中所述可学习卷积核可通过所述第一神经网络结构动态地适应点云数据,并进行一对一地预测对象。
5.进一步地,所述第一神经网络结构包括加权平均层,所述可学习卷积核可通过所述加权平均层动态地适应所述点云特征,所述加权平均层包括多个多层感知器,所述多个多层感知器用于计算所述可学习卷积核与点云特征加权运算的权重值。
6.进一步地,所述第一神经网络结构还包括自注意力层以及前馈网络层,所述自注意力层以及前馈网络层用于构建所述可学习卷积核的全局关系,以使得所述可学习卷积核与预测对象一一对应。
7.进一步地,所述第一神经网络结构还包括至少一个规范化层,其设置于所述加权平均层,和/或所述自注意力层,和/或所述前馈网络层后,用于归一化上一层输出的数据。
8.进一步地,所述系统还包括特征提取模块,其用于从所述点云中提取点云特征。
9.进一步地,所述特征提取模块包括cylinder3d点云特征提取网络。
10.基于如前所述的系统,本发明另一方面提供一种用于点云全景分割的方法,包括:
11.从点云中提取点云特征;
12.将所述点云特征与可学习卷积核进行加权平均;以及
13.基于加权平均后的可学习卷积核进行对象预测。
14.进一步地,所述加权平均包括:
15.将所述点云特征分别输入第一多层感知器及第二多层感知器,以得到第一点云特征投影向量及第二点云特征投影向量;
16.将所述可学习卷积核分别输入第一多层感知器及第二多层感知器,以得到第一可学习卷积核投影特征向量及第二可学习卷积核投影特征向量;
17.计算所述第二点云特征投影向量与第二可学习卷积核投影特征向量的哈达玛积;
18.将所述哈达玛积分别输入第三多层感知器及第四多层感知器,以得到可学习卷积核权重以及点云特征权重;以及
19.基于所述点云特征权重以及可学习卷积核权重,对所述第一点云特征投影向量与第一可学习卷积核投影特征向量进行加权平均,得到加权平均后的可学习卷积核,完成对输入数据的动态适应。
20.进一步地,通过注意力机制实现对象预测。
21.进一步地,所述方法还包括:计算对象预测结果的置信度,若满足预设要求,则保留所述对象预测结果,并将保留的对象预测结果根据置信度由高到低合并成全景分割结果。
22.本发明提供的一种用于点云全景分割的系统及方法,在现有的神经网络结构(transformer)中增加了加权平均层,使得卷积核能够动态地适应点云数据,进而仅通过一个分支即可高效地完成点云全景分割。相较于现有的通过语义分割、实例分割两个分支共同进行全景分割的方法而言,一方面本发明提供的系统和方法流程简单,效率更高,另一方面,其不需要以实例中心作为学习目标,还能有效避免出现目标模糊的问题。
附图说明
23.为进一步阐明本发明的各实施例的以上和其它优点和特征,将参考附图来呈现本发明的各实施例的更具体的描述。可以理解,这些附图只描绘本发明的典型实施例,因此将不被认为是对其范围的限制。在附图中,为了清楚明了,相同或相应的部件将用相同或类似的标记表示。
24.图1示出本发明一个实施例的一种用于点云全景分割的系统的结构示意图;
25.图2示出本发明一个实施例的第一神经网络结构的结构示意图;以及
26.图3示出本发明一个实施例的一种用于点云全景分割的方法的流程示意图。
具体实施方式
27.以下的描述中,参考各实施例对本发明进行描述。然而,本领域的技术人员将认识到可在没有一个或多个特定细节的情况下或者与其它替换和/或附加方法或组件一起实施各实施例。在其它情形中,未示出或未详细描述公知的结构或操作以免模糊本发明的发明点。类似地,为了解释的目的,阐述了特定数量和配置,以便提供对本发明的实施例的全面理解。然而,本发明并不限于这些特定细节。
28.在本说明书中,对“一个实施例”或“该实施例”的引用意味着结合该实施例描述的特定特征、结构或特性被包括在本发明的至少一个实施例中。在本说明书各处中出现的短语“在一个实施例中”并不一定全部指代同一实施例。
29.需要说明的是,本发明的实施例以特定顺序对方法步骤进行描述,然而这只是为了阐述该具体实施例,而不是限定各步骤的先后顺序。相反,在本发明的不同实施例中,可根据实际需求的调节来调整各步骤的先后顺序。
30.现有的点云全景分割技术中,通常需要融合语义分割结果和实例分割结果,进而才能得到最终的全景分割结果,这就使得必须要制定合理的融合策略,否则可能会导致较大的误差。此外,对于实例分割而言,还需要生成实例中心作为学习目标,极易出现目标模糊的问题。针对现有技术中的缺陷,本发明提供一种用于点云全景分割的系统及方法,采用可学习卷积核来实现点云全景分割任务,仅需采用一个分支即可完成全景分割,同时,由于不需要进行实例分割,还能有效地避免出现训练模糊性的问题。其中,所述可学习卷积核是一组随机初始化的可学习参数,每一个卷积核负责预测点云场景中的一个对象。所述可学习卷积核与普通卷积核在数据形式上一致,区别在于可学习卷积核能够动态地适应输入的数据,进而达到一对一预测对象的目的。在本发明的实施例中,动态地适应过程通过优化设计的神经网络结构(transformer)实现。
31.下面结合实施例附图,对本发明的方案做进一步描述。
32.图1示出本发明一个实施例的一种用于点云全景分割的系统的结构示意图。如图1所示,一种用于点云全景分割的系统,包括可学习卷积核101以及第一神经网络结构(transformer)102,其中所述可学习卷积核101可通过所述第一神经网络结构102动态地适应点云数据,并进行一对一地预测对象。
33.在本发明的一个实施例中,所述点云数据在输入所述第一神经网络结构102前,需要先进行预处理。所述预处理主要包括特征提取。因此,在本发明的一个实施例中,所述系统还包括特征提取模块103,其用于从所述点云数据中提取点云特征。在本发明的一个实施例中,采用cylinder3d点云特征提取网络来提取点云特征,其所提取得到的点云特征v的维度为n*d。应当理解的是,在本发明的其他实施例中,还可采用其他方法或结构来实现这一功能。
34.为了实现动态适应,在本发明的实施例中,所述可学习卷积核101的维度应当与所述点云特征相同,因此,所述可学习卷积核101可包括d个通道数,且每个通道中可学习卷积核的数目为n。所述可学习卷积核101在初始化后,通过所述第一神经网络结构(transformer)102实现与点云特征的信息交互,进而使得其能够动态地适应所述点云特征中的特定的对象,完成更精确的预测。基于此,所述第一神经网络结构(transformer)102至少应当实现两部分的功能:信息交互以及对象预测。图2示出本发明一个实施例的第一神经网络结构的结构示意图。如图2所示的实施例中,采用了transformer结构,即基于注意力机制来实现对象预测,同时,进一步地在所述transformer结构中增加了加权平均层用以实现信息交互。具体而言,如图2所示,所述第一神经网络结构102包括加权平均层201,所述加权平均层201用于计算权重,并对所述点云特征与所述可学习卷积核101进行加权平均运算,使得所述可学习卷积核101与点云特征实现信息交互,进而能够动态地适应输入的数据中的特定的对象。在本发明的一个实施例中,所述加权平均层201包括多个多层感知器,所述多个多层感知器用于计算所述可学习卷积核与点云特征加权运算时的权重值。
35.所述第一神经网络结构(transformer)102的其他结构与现有的transformer结构类似,例如包括自注意力层202以及前馈网络层203。所述自注意力层与前馈网络层相连接
组成的结构通常用作建立输入数据的全局关系模型。在本发明中,通过该结构进行可学习卷积核的全局关系建模,进而使得所述可学习卷积核与预测对象一一对应,避免多个可学习卷积核预测同一个对象的问题。所述自注意力层202以及前馈网络层203的实现原理和内部结构与现有技术基本一致,在此不再赘述。
36.此外,为了避免数据的极端分布,在本发明的一个实施例中,还进一步地在所述第一神经网络结构(transformer)102中设置了至少一个规范化层204。所述规范化层204例如可设置于所述加权平均层201,和/或所述自注意力层202,和/或所述前馈网络层203的输出端,用以归一化上一层输出的数据。所述规范化层204的实现原理和内部结构与现有技术基本一致,在此不再赘述。
37.基于如前所述的系统,图3示出本发明一个实施例的一种用于点云全景分割的方法的流程示意图。如图3所示,一种用于点云全景分割的方法,包括:
38.首先,在步骤301,提取特征。通过注入cylinder3d点云特征提取网络等,从输入的点云数据中提取点云特征v,所述点云特征v的维度为n*d;
39.接下来,在步骤302,可学习卷积核初始化。随机生成一组n*d维度的可学习参数,作为可学习卷积核的初始值;
40.接下来,在步骤303,动态适应特征。通过所述第一神经网络结构(transformer)102的加权平均层201,使得所述可学习卷积核动态适应所述点云特征。在本发明的一个实施例中,所述动态适应包括:
41.将所述点云特征v分别输入第一多层感知器及第二多层感知器,以得到第一点云特征投影向量zv及第二点云特征投影向量yv,所述zv及yv的维度均为n*d;
42.将所述可学习卷积核k分别输入第一多层感知器及第二多层感知器,以得到第一可学习卷积核投影特征向量zk及第二可学习卷积核投影特征向量yk,所述zk及yk的维度均为n*d;
43.计算所述第二点云特征投影向量yv与第二可学习卷积核yk投影特征向量的哈达玛积x;
44.将所述哈达玛积x分别输入第三多层感知器及第四多层感知器,以得到可学习卷积核权重gk以及点云特征权重gv;以及
45.基于所述点云特征权重gv以及可学习卷积核权重gk,对所述第一点云特征投影向量zv与第一可学习卷积核投影特征向量zk进行加权平均,得到加权平均后的可学习卷积核k
′
:
46.k
′
=gk⊙
zk gv⊙
zv;
47.至此,完成所述可学习卷积核对点云特征的动态适应;
48.接下来,在步骤304,对象预测。基于已动态适应所述点云特征的可学习卷积核、以及点云特征进行对象预测,实现全景分割。在本发明的一个实施例中,是通过注意力机制实现对象预测,即通过所述第一神经网络结构(transformer)102的自注意力层202以及前馈网络层203,基于加权平均后的可学习卷积核得到全景分割的结果;以及
49.最后,在步骤305,结果合并。将所有对象预测结果根据置信度合并成最终全景分割结果。在本发明的一个实施例中,通过计算对象预测结果的置信度,来判断是否需要保留所述对象预测结果:若所述置信度满足预设要求,则保留所述对象预测结果。最终将保留得
到的对象预测结果根据置信度由高到低合并成全景分割结果。
50.经过测试,本发明提供的一种用于点云全景分割的系统的结构及方法在目前开源的大型数据集上取得了比现有技术更好的效果。
51.尽管上文描述了本发明的各实施例,但是,应该理解,它们只是作为示例来呈现的,而不作为限制。对于相关领域的技术人员显而易见的是,可以对其做出各种组合、变型和改变而不背离本发明的精神和范围。因此,此处所公开的本发明的宽度和范围不应被上述所公开的示例性实施例所限制,而应当仅根据所附权利要求书及其等同替换来定义。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。