1.本发明涉及文字检测领域,特别是涉及一种获取异常文字识别区域的方法、电子设备及存储介质。
背景技术:
2.图像文字检测和识别技术应用场景广泛,基于ocr的文本识别定义为将印刷体的字符从纸质文档中识别出来,进行分析处理,识别图像中文字信息,但在普通文档识别中,往往由于扫描仪分辨率低、纸张、油墨质量差等原因导致文本图像质量低下,同时文字行形状和方向可能会出现水平、垂直、倾斜、曲线等,对于弯曲文本的检测,常用的有pixellink等。
技术实现要素:
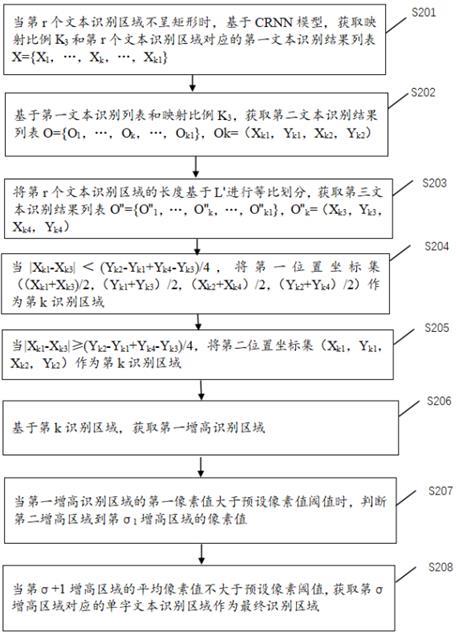
3.一种获取异常文字识别区域的方法,所述方法包括如下步骤:s201,当第r个文本识别区域不呈矩形时,基于crnn模型,获取映射比例k3和第r个文本识别区域对应的第一文本识别结果列表x={x1,
…
,xk,
…
,x
k1
},xk是指第k个字符对应的识别区域的中心在x轴的坐标,k的取值范围是1到k1,k1是指第r个文本识别区域中字符数量;s202,基于第一文本识别列表和映射比例k3,获取第二文本识别结果列表o={o1,
…
,ok,
…
,o
k1
},ok=(x
k1
,y
k1
,x
k2
,y
k2
),其中,x
k1
=k3*x
k-hr/2,y
k1
=y
ʹʹs,x
k2
=k3*xk hr/2,y
k2
=y
ʹʹs h
ʹʹs,其中,y
ʹʹs是指第r个文本识别区域左上角y轴的坐标,hr为第r个文本识别区域的高度;s203,将第r个文本识别区域的长度基于l
ʹ
进行等比划分,获取第三文本识别结果列表o
ʹʹ
={o
ʹʹ1,
…
,o
ʹʹk,
…
,o
ʹʹ
k1
},o
ʹʹk=(x
k3
,y
k3
,x
k4
,y
k4
),x
k3
是指第k个字符对应的第三识别区域的左上角在x轴的坐标,y
k3
是指第k个字符对应的第三识别区域的左上角在x轴的坐标,x
ʹ
k2
是指第k个字符对应的第三识别区域的右下角在x轴的坐标,y
k4
是指第k个字符对应的第三识别区域的右下角在y轴的坐标,其中,l
ʹ
=lr/k1;s204,当|x
k1-x
k3
|<(y
k2-y
k1
y
k4-y
k3
)/4,将第一位置坐标集((x
k1
x
k3
)/2,(y
k1
y
k3
)/2,(x
k2
x
k4
)/2,(y
k2
y
k4
)/2)作为第k识别区域;s205,当|x
k1-x
k3
|≥(y
k2-y
k1
y
k4-y
k3
)/4,将第二位置坐标集(x
k1
,y
k1
,x
k2
,y
k2
)作为第k识别区域;s206,基于第k识别区域,获取第一增高识别区域,所述第一增高区域是指以第k识别区域的上边缘为起始位置,向y轴反方向增加高度为ρ,长度为字符长度lr的矩形区域,ρ为第二预设增长因子;s207,当第一增高识别区域的第一像素值大于预设像素值阈值时,判断第二增高区域到第σ1增高区域的像素值,σ1是指预设高度阈值,所述第一像素值是指第一增高识别区域每个点的像素值的平均值;s208,当第σ 1增高区域的平均像素值不大于预设像素阈值,获取第σ增高区域对
应的单字文本识别区域作为最终识别区域,所述单字文本识别区域是指以第σ增高区域的上边缘为起始位置向y轴方向,高度为hr,宽度为第k个字符的第三位置的长度的矩形。
4.本发明至少具有以下有益效果:当存在异常文字时,例如文字的上下偏移时,使用文本识别区域进行检测会产生检测不全面的情况,现有技术中往往采用扩大文本识别区域的范围来保证检测到所有的文字,但同时扩大检测区域,对文字的上下倾斜的识别效果不好,因此本发明采用根据第二预设增长因子对文字进行逐个检测,提高了单个文字的检测精度。
附图说明
5.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
6.图1为本发明实施例提供的一种获取文本识别区域的数据处理系统的流程图。
7.图2为本发明实施例提供的一种获取异常文字识别区域的方法的流程图。
8.图3为本发明实施例提供的一种基于文本识别目标文本的方法的流程图。
具体实施方式
9.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
10.实施例1一种获取文本识别区域的数据处理系统,其特征在于,所述系统包括摄像装置、数据库,处理器和存储有计算机程序的存储器,所述数据库中存储有指定图像列表a={a1,
…
,ai,
…
,am},ai是指第i个指定图像,i的取值范围是1到m,m是指定图像的数量,当所述计算机程序被处理器被处理器执行时,实现如下步骤:s101,对目标图像进行仿射变换处理,获得目标图像对应的中间图像,目标图像是通过摄像装置获取到的目标文本对应的图像;其中,对目标图像进行仿射变换时,基于第一目标点列表c={c1,c2,c3},通过如下步骤获取目标点列表c:s1011,获取第一预设定点列表c
ʹ
={c
ʹ1,
…
,c
ʹj,
…
,c
ʹn},c
ʹj是指第j个第一预设定点,j的取值范围是1到n,n是指第一预设定点的数量,其中,第一类预设定点是指预先指定的点和目标图像的角点;s1013,获取c1所在的固定区域d
ζ1
,在d
ʹ
随机选择一个第一预设定点,标记为c2;其中,c1为随机选择的第一预设定点,d
ʹ
是指去除固定区域d
ζ1
的第二固定区域列表,d=(d1,
…
,d
ζ1
,
…
,d
ζ2
,
…
,d
ψ
),d
ζ
是指目标图像中被划分的第ζ个固定区域,ζ的取值范围是1到ψ,ψ是指固定区域的数量;s1015,获取c2所在固定区域d
ζ2
;
s1017,获取d
ʹʹ
对应的第二预设定点列表c
ʹʹ
={c
ʹʹ1,
…
,c
ʹʹ
j1
,
…
,c
ʹʹ
n1
},c
ʹʹ
j1
是指第j1个第二预设定点,j1的取值范围是指1到n1,n1是指第二预设定点的数量,第二预设点是指位于d
ʹʹ
的第一预设点;d
ʹʹ
是指去除固定区域d
ζ1
和d
ζ2
的第三固定区域列表;s1019,遍历c
ʹʹ
,获取c
ʹʹ
j1
与c1、c2构成第一平面区域列表α
ʹʹ
={α
ʹʹ1,
…
,α
ʹʹ
j1
,
…
,α
ʹʹ
n1
}并获取第一平面区域列表对应的第一平面区域面积列表s
ʹʹ
={s
ʹʹ1,
…
,s
ʹʹ
j1
,
…
,s
ʹʹ
n1
},其中,α
ʹʹ
j1
是指c
ʹʹ
j1
与c1、c2构成的平面区域,s
ʹʹ
j1
是指α
ʹʹ
j1
对应的面积;s1021,基于s
ʹʹ
获取第二平面面积区域列表s={s1,
…
,s
j2
,
…
,s
n1
}且将s1对应的平面区域作为目标平面区域,目标平面区域对应的第3个点标记为c3,其中,s
j2
是指第二平面区域列表第j2个平面区域,j2的取值范围是1到n1,其中,s
j2
≥s
j2 1
;基于s1011-s1021,通过选取目标图像的3个点进行仿射变换,通过在预先指定的点和角点中进行随机选择两个点并获取两个点所在固定区域,在剩余固定区域中选择剩余一个点组成平面区域,并获取平面区域面积最大组成的第三个点,作为目标点,因此避免了常用方法中使用三个角点,但角点有两个或两个以上确实的情况,扩大了仿射变换的使用情况;同时,可以使用目标图像上较特殊的点作为目标点,更加容易辨别和获取,例如预设位置区域的中心点、标识码的中心点。
11.s103,获取中间图像的文本识别区域列表b={b1,
…
,br,
…
,b
r1
},br=(xr,yr,hr,lr),br是指中间图像第r个文本识别区域,r的取值范围是1到r1,r1是指文本识别区域的数量,xr是指br左上角x轴的坐标,yr是指br左上角y轴的坐标,hr是指br的高度,lr是指br的长度。
12.具体地,在本发明中,以目标指定图像的左上角作为坐标轴原点,x轴正方向为水平向右,y轴正方向为垂直向下。
13.在本发明一个实施例中,通过如下办法获取br:s1031,基于指定图像列表a和目标图像,获取目标指定图像;s1032,获取目标指定图像对应的第一历史图像列表b
ʹ
={b
ʹ1,
…
,b
ʹs,
…
,b
ʹ
s1
},s的取值范围是s到s1,s1是指历史图像的数量,s1033,将第一历史图像进行归一化处理获得第二历史图像;s1034,获取第二历史图像第r个文本识别区域列表b
ʹʹ
={b
ʹʹ1,
…
,b
ʹʹs,
…
,b
ʹʹ
s1
},b
ʹʹs=(x
ʹʹs,y
ʹʹs,h
ʹʹs,l
ʹʹs),b
ʹʹs是指第二历史图像对应的第r个文本识别区域x
ʹʹs是指b
ʹʹs左上角x轴的坐标,y
ʹʹs是指b
ʹʹs左上角y轴的坐标,h
ʹʹs是指b
ʹʹs的高度,l
ʹʹs是指b
ʹʹs的长度;s1035,获取br:xr=x
ʹʹs,yr=y
ʹʹs,hr=max(h
ʹʹs),lr=max(l
ʹʹs)。
14.具体地,在s101之前还包括:s1,获取中间图像对应的目标位置,并基于目标位置进行识别,获取目标位置字符串;s2,遍历指定图像ai对应的目标位置的指定位置字符串,当指定位置字符串等于目标位置字符串,将指定位置字符串对应的指定图像ai作为目标图像对应的目标指定图像。
15.具体地,本领域技术人员知晓,可通过神经网络训练的方法获取目标位置字符串的位置。
16.基于s1-s2,根据预设位置区域识别目标位置字符串,当指定标题字符串等于目标
标题字符串时,可以理解为指定图像的标题和目标图像的标题相同,所以指定图像作为目标图像对应的目标指定图像。
17.本发明在s2后还包括:s3,第一目标点列表c={c1,c2,c3}经过仿射变换处理获得第二目标点列表θ={θ1,θ2,θ3},s4,获取ai={a
i1
,a
i2
,a
i3
},θ=ai,ai为指定图像对应的目标点列表。
18.具体地,当目标指定图像的数量sum》1时,执行如下步骤:s31,获取目标指定图像在第二预设位置区域对应的第二预设字符串列表e={e1,
…
,eg,
…
,ez},eg是指第g个目标指定图像对应的第二预设字符串,g的取值范围是1到z,z是指目标指定图像的数量;s33,获取目标图像在第二预设位置区域对应的第二目标字符串;s35,遍历e,使得第二中间预设字符串等于第二目标字符串,当第二中间预设字符串的数量k
ʹ
=1时,将第二中间预设字符串对应的目标指定图像作为最终目标指定图像。
19.在本发明一实施例中,第二中间预设字符串可以为“副本”等特殊字段。
20.可以理解为:在目标指定图像的数量大于1时,具有相同标题的模板或者属于该标题下的同类型的模板有很多个,因此在目标指定图像有多个时,通过比较第二预设字符串来确定最终目标指定图像,因此模板的类型多样,使得匹配的目标图像更准确,同时,按照顺序进行指定位置字符串、第二中间字符串的比较,更加节省时间提高效率。
21.在本发明另一实施例中,s1035中还可通过如下步骤获取hr:hr=(1/s1)∑
s1s=1 h
ʹʹs。
22.在本发明又另一实施例中,s1035中还可通过如下步骤获取lr:lr=(1/s1)∑
s1s=1 l
ʹʹs。
23.基于s101-s103,对目标图像基于三点进行仿射变换,使得经过仿射变换后的图像与目标指定图像的方向完全相同,目标图像包括多个文本识别区域,通过获取s张文本图像中对应位置的文本识别区域的起始位置和截至位置的最小值和最大值,确定文本识别区域的长度,在本发明中,还可通过s张文本图像获取文本识别区域的起始位置和截至位置的平均值,作为文本识别区域的长度,通过本发明,更加准确地获取目标图像的文本识别区域的高度和长度。
24.实施例2在实施例1的基础上,本发明还包括一种基于异常文字进行识别的方法,所述方法包括如下步骤:s201,当第r个文本识别区域不呈矩形时,基于crnn模型,获取映射比例k3和第r个文本识别区域对应的第一文本识别结果列表x={x1,
…
,xk,
…
,x
k1
},xk是指第k个字符对应的识别区域的中心在x轴的坐标,k的取值范围是1到k1,k1是指第r个文本识别区域中字符数量;s202,基于第一文本识别列表和映射比例k3,获取第二文本识别结果列表o={o1,
…
,ok,
…
,o
k1
},ok=(x
k1
,y
k1
,x
k2
,y
k2
),其中,x
k1
=k3*x
k-hr/2,y
k1
=y
ʹʹs,x
k2
=k3*xk hr/2,y
k2
=y
ʹʹs h
ʹʹs,其中,y
ʹʹs是指第r个文本识别区域左上角y轴的坐标,hr为第r个文本识别区域的高度;
s203,将第r个文本识别区域的长度基于l
ʹ
进行等比划分,获取第三文本识别结果列表o
ʹʹ
={o
ʹʹ1,
…
,o
ʹʹk,
…
,o
ʹʹ
k1
},o
ʹʹk=(x
k3
,y
k3
,x
k4
,y
k4
),x
k3
是指第k个字符对应的第三识别区域的左上角在x轴的坐标,y
k3
是指第k个字符对应的第三识别区域的左上角在x轴的坐标,x
ʹ
k2
是指第k个字符对应的第三识别区域的右下角在x轴的坐标,y
k4
是指第k个字符对应的第三识别区域的右下角在y轴的坐标,其中,l
ʹ
=lr/k1;s204,当|x
k1-x
k3
|<(y
k2-y
k1
y
k4-y
k3
)/4,将第一位置坐标集((x
k1
x
k3
)/2,(y
k1
y
k3
)/2,(x
k2
x
k4
)/2,(y
k2
y
k4
)/2)作为第k识别区域;s205,当|x
k1-x
k3
|≥(y
k2-y
k1
y
k4-y
k3
)/4,将第二位置坐标集(x
k1
,y
k1
,x
k2
,y
k2
)作为第k识别区域;s206,基于第k识别区域,获取第一增高识别区域,所述第一增高区域是指以第k识别区域的上边缘为起始位置,向y轴反方向增加高度为ρ,长度为字符长度lr的矩形区域,ρ为第二预设增长因子;s207,当第一增高识别区域的第一像素值大于预设像素值阈值时,判断第二增高区域到第σ1增高区域的像素值,σ1是指预设高度阈值,所述第一像素值是指第一增高识别区域每个点的像素值的平均值;s208,当第σ 1增高区域的平均像素值不大于预设像素阈值,获取第σ增高区域对应的单字文本识别区域作为最终识别区域,所述单字文本识别区域是指以第σ增高区域的上边缘为起始位置向y轴方向,高度为hr,宽度为第k个字符的第三位置的长度的矩形。
25.基于s201-s208,当存在异常文字时,例如文字的上下偏移时,使用文本识别区域进行检测会产生检测不全面的情况,现有技术中往往采用扩大文本识别区域的范围来保证检测到所有的文字,但同时扩大检测区域,对文字的上下倾斜的识别效果不好,因此本发明采用根据第二预设增长因子对文字进行逐个检测,提高了单个文字的检测精度。
26.实施例3在实施例2的基础上,本发明还包括一种基于文本识别目标文本的方法,所述方法包括如下步骤:s301,对目标图像进行处理,获取文本识别区域对应的多边形标注信息;s302,基于多边形的标注信息,对多边形进行向内高度和长度的缩减,获取第一标签,其中,l=l
1-[l1*h1*r/(l1 h1)]*(1-k*l1/h1),h=h
1-[l1*h1*r/(l1 h1)]*(1-k*l1/h1),其中,h1为多边形标注的矩形的高度、l1为多边形标注的矩形的长度,r是经验系数,h是指缩减后多边形标注的矩形的高度,l是指缩减后多边形标注的矩形的长度,k是指预设缩减参数;s303,基于多边形的标注信息,对多边形进行向外高度和长度的的扩张,获取第二标签,l2=l1 [l1*h1*r/(l1 h1)]*(1-k*l1/h1),h2=h1 [l1*h1*r/(l1 h1)]*(1-k*l1/h1),h2是指扩张后多边形标注的矩形的高度,l2是指扩张后多边形标注的矩形的长度;s304,将第一标签、第二标签和目标图像输入图像处理模型,获取最终文本识别区域;s305,基于最终文本识别区域进行文字识别,获取目标字符串。
[0027]
在现有技术中,dbnet计算标签时,计算偏移量 d = a*r/l,其中d就是标注多边形
各边缩短的量,a是多边形的面积,r是经验系数1.5,l是多变形的边长,假设我们的文本目标都是矩形,那么该公式就可以简化为: d = w*h*r/(w h),将w看做常数对h求偏导,得到 = r*(w/(w h))**2,偏导数恒大于0,递增,令x=w/h 得到 r*(x/(x 1))**2,可以发现偏导数是递增的,也就是说随着长宽比例的增加,偏导数是增加的,也就是说,d会随着长宽比例的增加而增加,正因如此,会造成长宽比例较大的文本识别区域,其shrunk后的宽度会相对较小,这会促使模型,遇到长宽比列较大的文本区域时,就会学习出宽度相对较窄的区域,这就会促使模型输出一个较窄的区域,且该文本区域不能完全覆盖到文字的上下边界。
[0028]
基于s301-s305,获取待处理文本图像,对待处理文本图像进行预处理,获取中间文本图像,在进行预处理时,获取标注数据集,对标注数据集进行数据增强,遍历多边形标注,当有字符内容存在目标区域时,保留多边形标注并获取多边形标注对应的目标区域,对多边形标注的每条边向内缩减像素,其中在缩减过程中引入预设缩减参数,使得在缩减过程中,目标区域的长宽可以适当缩小,避免在缩减过程中,对于长宽比差异较大的矩形,文本区域不能完全覆盖到文字的上下边界,因此引入预设缩减参数,使得矩形的长宽自适应的缩小,最终获得目标文字。
[0029]
其中,在s305后还包括如下步骤:s3051,获取待处理文本图像对应的目标文本识别区域列表q={q1,
…
,qv,
…
,q
β
}和目标文本识别区域对应的对应的目标文字字符串,qv是指待处理文本图像对应的第v个目标文本识别区域,v的取值范围是1到β,β是指目标文本识别区域的个数;s3053,根据待处理文本图像对应的目标指定图像对应的第r个文本识别区域,遍历目标文本识别区域列表q,获取qv的中心点;s3055,当qv的中心点坐标属于第r个文本识别区域的区域范围时,获取第r个文本识别区域和目标文本识别区域qv的交并集iou;s3057,当iou大于预设交集阈值时,将qv对应的目标文本关联到第r个文本识别区域,形成键值对。
[0030]
基于s3051-s3057,根据判断目标文本识别区域的中心点在目标指定图像对应的第r个文本识别区域,当中心点在目标指定图像对应的文本识别区域的范围内时,获取第r个文本识别区域和目标文本识别区域的交并集,当交并集满足预设交集范围,生成对应的键值对,增加了判断标准,使得形成的键值对对应更加准确。
[0031]
在本发明一实施例中,本发明还包括如下步骤:s10,获取预先定义的特征列表u={u1,
…
,u
γ
,
…
,u
δ
},u
γ
是指第γ个特征,γ的取值范围是1到δ,δ是指预先定义的特征数量。
[0032]
在本发明一个实施例中,预先定义的特征列表包括标识码、印章标识、指纹标识、签名标识。
[0033]
优选地,δ≥3。
[0034]
s20,检测待处理文本图像是否包括预先定义的特征。
[0035]
s30,当待处理文本图像存在u
γ
时,将u
γ
对应的键值对标记为“1”。
[0036]
s40,当待处理文本图像不存在u
γ
时,将u
γ
对应的键值对标记为“0”。
[0037]
进一步地,键值对标识用于识别特征是否存在待处理文本图像的标识,其中,键值对标识为“1”或者“0”;可以理解为:本领域技术人员知晓,当特征存在待处理本本图像时,
键值对标识为“1”或者“0”;否则,当特征不存在待处理文本图像时,键值对标识为“0”或者“1”。
[0038]
优选地,当特征存在待处理本本图像时,键值对标识为“1”;否则,当特征不存在待处理文本图像时,键值对标识为“0”。
[0039]
基于s10-s40,使用通用目标检测判断待处理文本图像中是否包括标识码等特征,将待处理文本图像中的特征检测出来。
[0040]
本发明的实施例还提供了一种非瞬时性计算机可读存储介质,该存储介质可设置于电子设备之中以保存用于实现方法实施例中一种方法相关的至少一条指令或至少一段程序,该至少一条指令或该至少一段程序由该处理器加载并执行以实现上述实施例提供的方法。
[0041]
本发明的实施例还提供了一种电子设备,包括处理器和前述的非瞬时性计算机可读存储介质。
[0042]
本发明的实施例还提供一种计算机程序产品,其包括程序代码,当所述程序产品在电子设备上运行时,所述程序代码用于使该电子设备执行本说明书上述描述的根据本发明各种示例性实施方式的方法中的步骤。
[0043]
虽然已经通过示例对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员还应理解,可以对实施例进行多种修改而不脱离本发明的范围和精神。本发明开的范围由所附权利要求来限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。