技术特征:
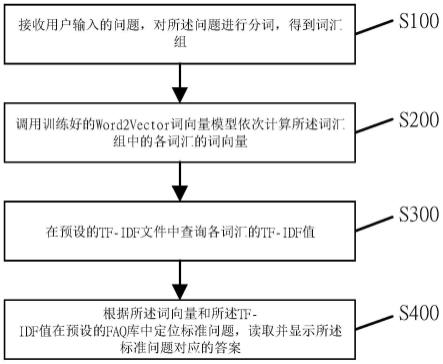
1.一种基于word2vector和tf-idf的智能客服系统文本匹配方法,其特征在于,所述方法包括:接收用户输入的问题,对所述问题进行分词,得到词汇组;调用训练好的word2vector词向量模型依次计算所述词汇组中的各词汇的词向量;在预设的tf-idf文件中查询各词汇的tf-idf值;根据所述词向量和所述tf-idf值在预设的faq库中定位标准问题,读取并显示所述标准问题对应的答案。2.根据权利要求1所述的基于word2vector和tf-idf的智能客服系统文本匹配方法,其特征在于,所述调用训练好的word2vector词向量模型依次计算所述词汇组中的各词汇的词向量的步骤包括:采用gensim库中的word2vector方法,选用skip-gram的方式训练word2vector词向量模型;采用对数似然逻辑回归作为损失函数;所述损失函数为:其中,i表示一个样本,m为总样本数,y表示真实输出值,x为真是输入值,hθ(x_i)为预测值。最终训练的模型文件大小约为1g。3.根据权利要求1所述的基于word2vector和tf-idf的智能客服系统文本匹配方法,其特征在于,所述tf-idf文件的生成步骤包括:读取预设的faq库中的问题,合并到同一文件;基于jieba算法对该文件进行分词,并统计每个词的词频;统计样本总数和每个词所在的样本数,根据预设的tf-idf公式计算每个词的tf-idf值,并一一存入txt文件中。4.根据权利要求1所述的基于word2vector和tf-idf的智能客服系统文本匹配方法,其特征在于,所述根据所述词向量和所述tf-idf值在预设的faq库中定位标准问题,读取并显示所述标准问题对应的答案的步骤包括:依次读取词汇组中各词汇的词向量和tf-idf值,将所述词向量与所述tf-idf值相乘,得到加权词向量;累加词汇组中所述词汇的加权词向量,得到问题的句向量;基于所述句向量与faq库中每个标准问题的句向量进行比对,计算相似度;根据相似度对faq库中每个标准问题进行降序排列,读取并显示首个标准问题及其答案。5.根据权利要求2所述的基于word2vector和tf-idf的智能客服系统文本匹配方法,其特征在于,所述调用训练好的word2vector词向量模型依次计算所述词汇组中的各词汇的词向量的步骤还包括:当词向量不存在时,根据预设的生成规则随机生成词向量。6.根据权利要求1所述的基于word2vector和tf-idf的智能客服系统文本匹配方法,其
特征在于,所述在预设的tf-idf文件中查询各词汇的tf-idf值的步骤包括:当某一词汇的tf-idf值不存在时,根据预设的数值对该词汇的tf-idf值进行赋值。
技术总结
本发明涉及智能问答服务技术领域,具体公开了一种基于Word2Vector和TF-IDF的智能客服系统文本匹配方法,所述方法包括接收用户输入的问题,对所述问题进行分词,得到词汇组;调用训练好的Word2Vector词向量模型依次计算所述词汇组中的各词汇的词向量;在预设的TF-IDF文件中查询各词汇的TF-IDF值;根据所述词向量和所述TF-IDF值在预设的FAQ库中定位标准问题,读取并显示所述标准问题对应的答案。本发明接收用户输入的问题,对问题进行分词、获取词向量、获取TF-IDF值、计算加权词向量、计算句向量、相似度计算与排序、返回标准答案;有效改善了编辑距离匹配算法和BM25等算法缺乏语义理解的不足。解的不足。解的不足。
技术研发人员:慈兴文 陈光
受保护的技术使用者:上海评驾科技有限公司
技术研发日:2022.07.20
技术公布日:2022/10/11
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。