1.本发明涉及工业用电安全监测领域,具体涉及一种基于随机森林算法的化工厂区用电故障预测方法。
背景技术:
2.化工厂区供电系统发展过程中,如何对其常见问题进行有效预测,使供电系统能够保证化工厂进行稳定、可靠生产,是现阶段化工厂供电系统必须解决的一个重要问题。而电力变压器作为化工企业供电系统和线路传输的核心,其运行状况的变化直接反映了厂区供用电安全,电力变压器内部结构的温度决定着变压器负载能力及其内部绝缘系统的性能,进而影响着变压器的寿命。
3.从上个世纪开始,变压器就开始使用油作为绝缘和冷却的媒介,由于油具有防水防潮的效果,可以延缓机械的老化,这也是油浸式变压器的优点,现在油浸式变压器依旧占据庞大的份额,而油浸式变压器的油温也是油浸式变压器的研究热点。
4.目前变压器油温的温度预测相关研究很多。有通过对变压器传热过程构建热路模型,进行油温预测的;基于变压器修正热路模型,推导油浸式变压器顶层油温的温度;通过对变压器绕组发热机理和变压器油粘滞度分析,构造修正参数进行预测的;还有利用bp神经网络进行油浸式变压器油温的预测工作等等。因此对油浸式变压器油温的异常预测具有重要的有研究价值和理论意义。
5.基于大数据挖掘技术的油温异常预警是当前最具有发展潜力的一项技术,本发明将大数据及人工智能技术于与电力行业进行结合,提出一种基于随机森林方法(random forest,简称rf)预测变压器油温数据,进行化工厂区用电故障预测的方法。
技术实现要素:
6.本发明的目的在于提供一种基于随机森林算法的化工厂区用电故障预测方法,以解决上述的技术问题。
7.为了达到上述目的,本发明通过以下技术方案实现:
8.一种基于随机森林算法的化工厂区用电故障预测方法,该方法包含:
9.获取变压器在选定时间段内的运行数据的数据集;其中,所述运行数据包括所述变压器在多个维度的特征;
10.对所述数据集进行预处理,并将所述数据集划分为训练集和测试集;
11.在完成对所述数据集的划分之后,构建随机森林回归模型;
12.提取所述特征的重要性,并对所述特征的重要性进行分析排序;
13.对所述随机森林回归模型进行预测校验,并对所述随机森林回归模型的参数进行调整。
14.可选地,该方法还包括:
15.通过所述随机森林回归模型对所述变压器的油温进行预测。
16.可选地,该方法还包括:
17.展示基于所述测试集的预测值与实际值之间的差异,以验证预测效果。
18.可选地,所述对所述数据集进行预处理,包括:
19.处理所述数据集中的缺失数据;和/或
20.转换所述数据集中的非结构化数据。
21.可选地,所述选定时间段为两年。
22.可选地,所述在多个维度的特征包括记录日期、油温以及多个不同类型外部负载值。
23.可选地,该方法还包括:
24.通过打印或可视化方式将所述特征的重要性进行展示。
25.可选地,所述随机森林回归模型的参数包括随机森林中的分类器的个数、是否采用袋外误差来评估模型、决策树划分对特征的评价标准、建立决策树时选择的最大特征数目、决策树的最大深度、限制子树继续划分的条件、叶子节点的最小样本数目、叶子节点最小样本权重、最大叶子节点数、节点划分最小不纯度、设置程序的并行作业数量、随机数的设置、控制构建树过程中的详细程度中的至少一个。
26.可选地,该方法在所述构建随机森林回归模型之前还包括:
27.将分类器的个数设置为1000;
28.将随机数设置为42;
29.将其他参数设置为默认值。
30.可选地,该方法还包括:
31.引入randomizedsearchcv函数,以在参数空间中取得最优参数。
32.本发明与现有技术相比具有以下优点:
33.目前变压器故障诊断领域常用的浅表层机器学习方法,预测能力有限,预测和诊断正确率存在瓶颈,通过上述随机森林算法的应用,能够有效提高学习能力、并降低计算复杂度。
附图说明
34.为了更清楚地说明本发明专利实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明专利的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
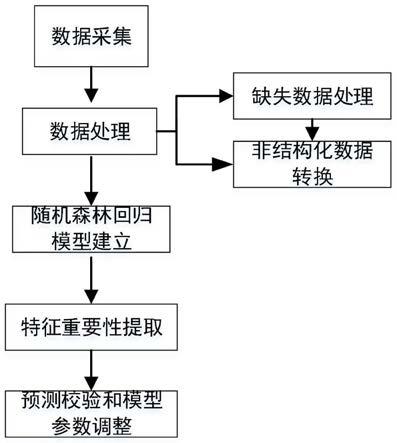
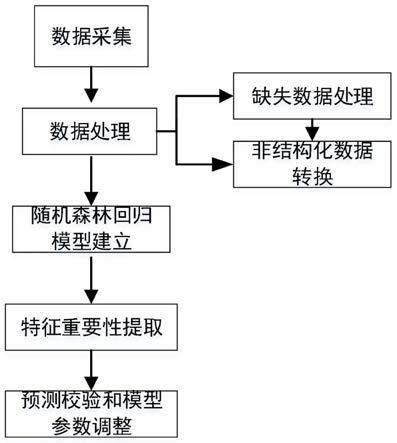
35.图1是本技术实施例中提供的一种基于随机森林算法的化工厂区用电故障预测方法的流程图;
36.图2是本技术实施例中测试集预测结果和实际值对比示意图。
具体实施方式
37.为了使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术作进一步地描述,所描述的实施例不应视为对本技术的限制,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
38.在以下的描述中,涉及到“一些实施例”、“一个或多个实施例”,其描述了所有可能实施例的子集,但是可以理解,“一些实施例”、“一个或多个实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互组合。
39.在以下的描述中,所涉及的术语“第一\第二\第三”仅仅用于分别类似的对象,不代表针对对象的特定排序,可以理解地,“第一\第二\第三”在允许的情况下可以互换特定的顺序或先后次序,以使这里描述的本技术实施例能够以除了在图示或描述的以外的顺序实施。
40.除非另有定义,本文所使用的所有的技术和科学术语与属于本技术的技术领域的技术人员通常理解的含义相同。本文中所使用的术语只是为了描述本技术实施例的目的,不是旨在限制本技术。
41.请参阅图1,本技术实施例提供了一种基于随机森林算法的化工厂区用电故障预测方法,该方法一般包含:
42.s101、获取变压器在选定时间段内的运行数据的数据集;其中,所述运行数据包括所述变压器在多个维度的特征;
43.该变压器指的是化工厂区的油浸式电力变压器,由于油具有防水防潮的作用,可以延缓其机械零部件的老化。油浸式电力变压器的油温决定着其负载能力及其内部绝缘系统的性能,进而影响其使用寿命。本技术实施例通过该基于随机森林算法的化工厂区用电故障预测方法预测该变压器的油温,进而预测化工厂区的用电是否发生故障。
44.选定时间段可以设置为两年,也可以根据具体的使用情景进行调整。
45.所述在多个维度的特征包括记录日期、油温以及多个不同类型外部负载值,多个不同类型外部负载值包括工作日、假日、季节、天气、温度等不同因素。
46.s102、对所述数据集进行预处理,并将所述数据集划分为训练集和测试集;
47.所述对所述数据集进行预处理,包括:处理所述数据集中的缺失数据;和/或转换所述数据集中的非结构化数据。
48.具体地,使用pandas的read_csv查看一下数据集,这里使用.describe来查看数据集的信息,如每一列的数据量、平均值、最小值、最大值等;也可以使用.head(5)查看数据集的前五行信息了解标签分布;使用.shape来查看数据集规模;使用.info()来查看数据集的缺失情况。
49.所述训练集用于对随机森林回归模型进行训练,所述测试集用于对随机森林回归模型进行测试。
50.s103、在完成对所述数据集的划分之后,构建随机森林回归模型;
51.在完成了数据集的划分之后就可以开始构建随机森林回归模型了,使用sklearn中的randomforestregressor建立随机森林回归模型。对于回归任务,评估的主要方法包括平均绝对误差、平均方差、r平方值。
52.s104、提取所述特征的重要性,并对所述特征的重要性进行分析排序;
53.为了尽可能多地选择有价值的特征,在sklearn中有用于计算特征重要性的函数(.feature_importance_),用来调用各项特征的重要性,对特征重要性进行分析排序,计算后的特征重要性可以通过打印或可视化方式展示出来。
54.s105、对所述随机森林回归模型进行预测校验,并对所述随机森林回归模型的参
数进行调整;
55.在测试集上进行模型预测值与实际值比较,通过matplotlib绘图进行准确度验证;展示基于所述测试集的预测值与实际值之间的差异,以验证预测效果。
56.引入randomizedsearchcv函数,不断地随机选择一组合适的参数来建模,并且求其交叉验证后的评估结果,以在参数空间中取得最优参数。
57.s106、通过所述随机森林回归模型对所述变压器的油温进行预测,进而确定化工厂区的用电情况。
58.本技术实施例中,所述随机森林回归模型的参数包括随机森林中的分类器的个数、是否采用袋外误差来评估模型、决策树划分对特征的评价标准、建立决策树时选择的最大特征数目、决策树的最大深度、限制子树继续划分的条件、叶子节点的最小样本数目、叶子节点最小样本权重、最大叶子节点数、节点划分最小不纯度、设置程序的并行作业数量、随机数的设置、控制构建树过程中的详细程度中的至少一个。
59.本技术实施例中,选取包含两年运行数据的数据集,每个数据点每分钟记录一次(用m标记),它们分别来自中国同一个省的两个不同地区,分别名为ett
‑
small
‑
m1和ett
‑
small
‑
m2。每个数据集包含2年365天24小时60分钟=1,051,200数据点。此外,我们还提供一个小时级别粒度的数据集变体使用(用h*标记),即ett
‑
small
‑
h1和ett
‑
small
‑
h2。每个数据点均包含8维特征,包括数据点的记录日期、预测值“油温”以及6个不同类型的外部负载值。
60.本技术实施例中,在所述构建随机森林回归模型之前还包括:
61.将分类器的个数设置为1000;
62.将随机数设置为42;
63.将其他参数设置为默认值。
64.为了便于更好地理解理解随机森林回归模型的参数,下面将对主要参数进行具体介绍:
65.n_estimators:指定随机森林中的分类器的个数,默认为10。一般来说n_estimators太小容易欠拟合,太大计算量大,故需要参数调优选择一个适中的数值;
66.oob_score:是否采用袋外误差来评估模型,默认为false;
67.criterion:及cart树划分对特征的评价标准,默认我基尼指数,还可以选择信息增益;
68.max_features:建立决策树时选择的最大特征数目(从原始特征中选取多少特征进行建立决策树),默认为auto,意味着考虑sqrt(n_features)个特征;还可以为整数,即直接指定数目;浮点数,即指定百分比;sqrt与auto相同;log2即指定log2(n_features);如果是none,则为最大特征数n_features;
69.max_depth:决策树的最大深度,默认是不进行限制的,如果是模型样本量多,特征也多的情况,推荐限制修改这个,常用的可以取值为10
‑
100之间;
70.min_samples_split:限制子树继续划分的条件,如果某节点的样本数目小于此值,则不会再继续划分,默认为2,样本量非常大的时候,应该增大这个值;
71.min_samples_leaf:叶子节点的最小样本数目,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,默认为1,数据量大的时候可以增大这个值;
72.min_weight_fraction_leaf:叶子节点最小样本权重,这个值限制了叶子节点所有样本权重和最小值,如果小于最小值,则会和兄弟节点被剪枝。默认为0,就是不考虑权重。通常来说,若样本中存在较多的缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时就需要考虑这个值了。
73.max_leaf_nodes:最大叶子节点数,通过限制最大叶子节点数目来防止过拟合,默认为none,即不进行限制,如果特征分成很多可以加以限制;
74.min_impurity_split:节点划分最小不纯度,这个值限制了决策树的增长,如果某节点的不纯度小于这个阈值,则该节点不在生成子节点,即为叶子节点,一般不推荐改动,默认值为1e
‑
7;
75.min_impurity_decrease:若一个节点被分割,如果这个分割导致大于或等于该值。默认为0;
76.bootstrap:构建树时是否使用bootstrap采样,默认为true;
77.n_jobs:设置程序的并行作业数量,默认为1,如果为
‑
1,则作业数目为核心数;
78.random_state:随机数的设置;
79.verbose:控制构建树过程中的详细程度。
80.以上所述,仅为本技术的实施例而已,并非用于限定本技术的保护范围。凡在本技术的精神和范围之内做出的任何修改、等同替换和改进等,均包含在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。