1.本发明属于儿童白血病图像处理与分类技术领域,具体涉及一种基于分层注意力机制的儿童白血病多实例分类方法。
背景技术:
2.近十年来,深度学习以及卷积神经网络在计算机视觉领域的优势突出,已被广泛应用于医学图像分析。采用深度学习和计算机视觉技术能够帮助医生快速识别病变细胞,从而大幅提高儿童白血病诊断效率。但是,儿童白血病的病例数量限制,使得现有数据较少,预测模型不可避免的存在过拟合的可能性。同时,儿童白血病是一种高度异质性疾病,需要对其进行准确的分型,目前的预测模型有的只针对急性淋巴系和急性髓系白血病进行分类,或在某一系中进行子类型分类,不能真正满足临床诊断的需要。
3.在机器学习中,多实例学习是由监督型学习算法演变出的一种方法,定义“包”为多个实例的集合。模型不是接收一组单独标记的实例,而是接收一组带标签的包,每个包拥有多个实例,根据对实例预测结果,整体判断获取整体包的分类概率。这样的学习方式更符合医生根据一个病人的图像资料进行分析诊断的流程。目前,基于注意力机制的多实例学习方法则被广泛应用于医学图像领域,区分高诊断价值的子区域,从而达到更高的分类效果。例如在儿童白血病的骨髓细胞图像中,某细胞对分类有关键性的作用,则使模型更多地关注这个细胞,以期达到更好的分类效果。但是现有的基于注意力机制的方法是针对细胞对分类是否重要,而对于儿童白血病而言,不同的细胞对不同的分型的重要性是不同的,现有的方法未区分细胞对不同分型的分类贡献度。另外,对于儿童白血病的分型有层级特征,应先区分急性淋巴系白血病和急性髓系白血病,再分别在两大系中进一步划分更精细的分型,这样不会在两大系中造成混淆等消极影响。现有的基于注意力机制的方法只应用于粗分类或某一种大类的细分类。
技术实现要素:
4.为了克服上述现有技术存在的缺陷,本发明提出了一种基于分层注意力机制的儿童白血病多实例分类方法,通过构建一种分层的分类方法,并引入针对类别的注意力机制,使模型不仅能区分儿童白血病是急性淋巴系和急性髓系,而且可以从两大系的子分型对儿童白血病进行分型,从而满足儿童白血病分型多且细的特征;区分了各个细胞对不同分型的贡献度,且不同层级的分型间的注意力机制存在一定的制约,对细分型的注意力矩阵可聚合为针对粗分型的注意力矩阵,从而使细分型与粗分型间互有提升,且避免细胞在粗分型的类别间被分错,提高了分型的准确度。
5.为了实现上述目的,本发明采取的技术方案为:
6.一种基于分层注意力机制的儿童白血病多实例分类方法,具体包括以下步骤:
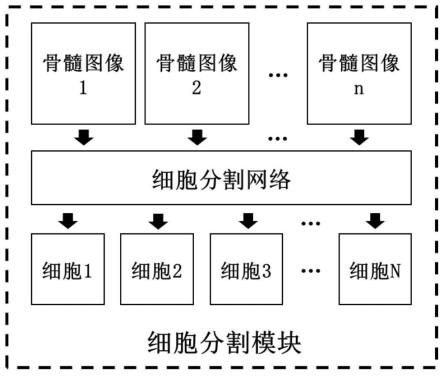
7.步骤一,进行细胞分割:
8.1)根据医生给出的儿童白血病分析诊断结果,将一个儿童白血病病人的多张骨髓
细胞图像中的有核细胞通过细胞分割模块提取出来,再进行n个细胞为一份的随机采样,得到一个多实例包,其中,n∈[50,200];
[0009]
2)对不同类型儿童白血病病人的骨髓细胞图像,根据步骤一第1)步依次形成多实例包样本;
[0010]
步骤二,进行儿童白血病分类:
[0011]
将步骤一中处理得到的多实例包输入儿童白血病分类模块,区分每个样本属于急性髓系白血病,还是急性淋巴系白血病,并进一步区分两大系中的不同子分型,分类到各个不同子分型后,进一步区分不易区分的子分型或子分型中的小类,即进行多个层级的分型;
[0012]
所述儿童白血病分类模块包括编码器、基于类别的注意力模块和分类器,编码器接受细胞分割模块的输出,得到细胞特征矩阵f
cell
∈rn×k,将细胞特征矩阵f
cell
∈rn×k输入基于类别的注意力模块获得注意力矩阵,再将细胞特征矩阵f
cell
∈rn×k与不同层级的注意力矩阵相乘获得针对不同层级分类器的特征矩阵进行儿童白血病区分分型。
[0013]
所述步骤一第1)步形成一个多实例包,具体方法为:
[0014]
1.1)将一个儿童白血病病人的a张骨髓细胞图像进行步长为b像素,窗口大小为w像素的多中心裁剪,获取n1个覆盖全图的图块,并用x={x1,x2,...,x
n1
}表示图块集合,其中,a∈[15,50],b>0,w>0,n1>0且均为整数;
[0015]
1.2)将步骤一第1.1)步得到的每个图块随机采取形状、角度和颜色变化的图像增强方式,并进行中心裁剪,获取边长w1像素正方形图块,经过图像增强的图块集合表示为其中,w1∈[128,256];
[0016]
1.3)将步骤一第1.2)步得到的图块集合输入细胞分割模块,获取的输出图块,通过其中心坐标在原始图像中的位置,定位拼接得到原图像大小细胞分割结果,将分割结果中的所有细胞抽取出来,再随机进行采样获取n个细胞,单细胞图块集合表示为c={c1,c2,...,cn},其中,n∈[50,200];。
[0017]
所述步骤二的具体方法为:
[0018]
1)将步骤一第1.3)最终获得的单细胞图块集合c进行边界填充,将所有细胞图块填充为边长为w2像素的正方形,便于将所有细胞图块打包输入编码器,填充后的单细胞图块集合为其中,w2∈[128,256];
[0019]
2)对应病人的临床诊断报告,获取病人的白血病分型y
t
,即表示该病人为y
t
型;设病人分型共l1个细分型类数,并将病人标签转换为one-hot向量其中y
t
=1,其他分量为0;获取病人细胞比例s=(s1,s2),其中s2为癌细胞的比例,s1=1-s2,s1表示正常细胞的比例;
[0020]
3)将步骤二中第1)步获取的单细胞集合输入编码器,得到细胞特征矩阵f
cell
∈rn×k,其中,k表示单个细胞的特征维数,将f
cell
输入基于类别的注意力模块,即学习各个细胞对各个类别的分类贡献度的由全连接层构成的神经网络;在注意力模块中,首先将细胞特征矩阵分别通过全连接层和将特征维度降低至再分别进行tanh和sigmoid函数的归一化,将归一化后的结果相乘,再经过一个由维到l1维度的全连接层
获取注意力矩阵,即每个细胞对l1个类别的贡献度
[0021]
a1=w
×
(tanh(f
cell
×
u)
⊙
sigmoid(f
cell
×
v))
[0022]
其中
⊙
表示矩阵内对应点相乘;
[0023]
最终通过细胞特征矩阵与注意力矩阵的相乘得到最终通过细胞特征矩阵与注意力矩阵的相乘得到表示针对l1个类别的分类器的特征矩阵;
[0024]
设l2为相对细分型l1而言的第二层级粗分型的类别个数,则通过转换矩阵将针对l1个类别的注意力矩阵中对应类别的值聚合到l2个类别,即a2=a1×
t1,获得各个细胞对第二层级粗分型中各个类别的贡献度,通过注意力矩阵和细胞特征矩阵相乘,获得针对l2个类别的分类器的特征矩阵同理可知,达到第三层粗分型时,设l3类为第三层级粗分型的类别个数,则可将获得的第二层级粗分型的注意力矩阵通过转换矩阵通过转换矩阵聚合到第三层级粗分型的注意力矩阵a3=a2×
t2,通过注意力矩阵和细胞特征矩阵相乘,获得针对l3个类别的分类器的特征矩阵an=a
n-1
×
t
n-1
为针对n个层级分类的注意力矩阵表达,针对第n层级的分类器的特征矩阵通用表示为f
l
∈rk×
l
,表示该层级分型类别共l个,其中,n,l1,l2,l3,l,k>0,均为整数,且l1>l2>l3,即l
n-1
>ln;
[0025]
4)将步骤二第3)步获取的特征矩阵f
l
∈rk×
l
输入l个二值分类器中,获取输出o
patient
∈r
l
×2,将细胞特征矩阵f
cell
∈rn×k输入关于细胞类别的二值分类器中获取是否为癌细胞的输出结果o
cell
∈rn×2;
[0026]
5)根据o
cell
计算细胞比例为其中为保留该比例中的梯度,从而调节网络参数,需要用到gumbel_softmax函数,将n
×
2维的矩阵在第1维中形成是否为癌细胞的概率表示,即关于每一个细胞i有即关于每一个细胞i有表示是正常细胞的概率,表示为癌症细胞的概率;按第0维求和除以总数n,即获得比例其中其中而o
patient
∈r
l
×2中,对于每一类j有该样本是否属于该类的概率pj∈[0,1],分类学习过程的损失函数表示为:
[0027][0028][0029]
相对于现有技术,本发明有益效果如下:
[0030]
1、本发明提出一套可以应用于儿童白血病分类的多实例学习框架,包括细胞分割模块,儿童白血病分类模块,使得框架可在弱监督即只有临床报告,不需要医生进行二次标注的情况下完成训练,达到可用精度。
[0031]
2、针对儿童白血病患者的多张骨髓细胞涂片和含有各类细胞比例的临床报告,设计了一种基于注意力机制的白血病分类模块,包括对患者进行分型和对其所包含的每一个细胞进行二分类,即分类为癌细胞或正常细胞。
[0032]
3、面向儿童白血病的分类特征,即不同类别的判别依赖于不同种类的细胞,提出
了基于类别的注意力机制,即针对不同类别学习不同的注意力矩阵。
[0033]
4、面向儿童白血病的诊断逻辑,即不同层次的树状诊断链条,提出了由细至粗的注意力矩阵转换方法,可以将不同层次的诊断逻辑融入到白血病分类模型中,进而提升分类的精度和临床可用性即尽量保证粗分类之间不混淆,提高了分型的准确度。
附图说明
[0034]
图1为步骤一细胞分割模块示意图。
[0035]
图2为步骤二儿童白血病分类模块示意图。
具体实施方式
[0036]
下面结合附图对本发明进一步详细描述。
[0037]
步骤一:进行细胞分割任务:参见图1
[0038]
1)根据医生给出的儿童白血病分析诊断结果,将一个儿童白血病病人的多张骨髓细胞图像中的有核细胞通过细胞分割模块提取出来,再进行n个细胞为一份的随机采样,形成一个多实例包,具体如下:
[0039]
1.1)将一个儿童白血病病人的a张骨髓细胞图像进行步长为b像素,窗口大小为w像素的多中心裁剪,获取n1个覆盖全图的图块,并用x={x1,x2,...,x
n1
}表示图块集合,其中,a∈[15,50],b>0,w>0,n1>0且均为整数;
[0040]
1.2)将步骤一第1.1)步得到的每个图块随机采取形状、角度和颜色变化的图像增强方式,并进行中心裁剪获取边长w1像素正方形图块,经过图像增强的图块集合表示为其中,w1∈[128,256];
[0041]
1.3)将步骤一第1.2)步得到的图块集合输入细胞分割模块,获取的输出图块,通过其中心坐标在原始图像中的位置,定位拼接得到原图像大小细胞分割结果,再将分割结果中的所有细胞抽取出来,设获取n个细胞,单细胞图块集合表示为c={c1,c2,...,cn},其中n∈[50,200];
[0042]
2)对不同类型儿童白血病病人的骨髓细胞图像,根据步骤一第1)步依次形成多实例包样本;
[0043]
参见图2:步骤二、进行儿童白血病分类任务
[0044]
将步骤一中处理得到的多实例包输入儿童白血病分类模块,儿童白血病分类模块即一个由编码器、注意力模块和分类器构成的卷积神经网络,其中注意力模块即由全连接层构成的神经网络,区分一个样本属于急性髓系白血病或急性淋巴系白血病,并进一步区分两大系中的不同子分型,分类到各个不同子分型后进一步区分不易区分的子分型或子分型中的小类,即进行多个层级的分型:
[0045]
1)将步骤一第1.3)最终获得的单细胞图块集合c进行边界填充,将所有细胞图块填充为边长为w2像素的正方形,便于将所有细胞图块打包输入编码器,填充后的单细胞图块集合为其中w2∈[128,256];
[0046]
2)从步骤一第1)步生成的样本所属的病人的临床诊断报告中获取病人的白血病分型y
t
,即表示该病人为y
t
型;设病人分型共l1个细分型类数,并将病人标签转换为one-hol
向量其中y
t
=1,其他分量为0;获取病人细胞比例s=(s1,s2),其中s2为癌细胞的比例,s1=1-s2,s1表示正常细胞的比例;
[0047]
3)将步骤二中第1)步获取的单细胞集合输入编码器,得到的细胞特征矩阵f
cell
∈rn×k,其中k表示单个细胞的特征维数,将f
cell
输入基于类别的注意力模块,即学习各个细胞对各个类别的分类贡献度的由全连接层构成的神经网络;在注意力模块中,首先将细胞特征矩阵分别通过全连接层和将特征维度降低至再分别进行tanh和sigmoid函数的归一化,将归一化后的结果相乘,再经过一个由维到l1维度的全连接层获取注意力矩阵,即每个细胞对l1个类别的贡献度
[0048]
a1=w
×
(tanh(f
cell
×
u)
⊙
sigmoid(f
cell
×
v))
[0049]
其中
⊙
表示矩阵内对应点相乘;
[0050]
最终通过细胞特征矩阵与注意力矩阵的相乘得到最终通过细胞特征矩阵与注意力矩阵的相乘得到表示针对l1个类别的分类器的特征矩阵;
[0051]
设l2为相对细分型l1而言的第二层级粗分型的类别个数,则通过转换矩阵将针对l1个类别的注意力矩阵中对应类别的值聚合到l2个类别,即a2=a1×
t1,获得各个细胞对第二层级粗分型中各个类别的贡献度,通过注意力矩阵和细胞特征矩阵相乘,获得针对l2个类别的分类器的特征矩阵同理可知,达到第三层粗分型时,设l3类为第三层级粗分型的类别个数,则可将获得的第二层级粗分型的注意力矩阵通过转换矩阵通过转换矩阵聚合到第三层级粗分型的注意力矩阵a3=a2×
t2,通过注意力矩阵和细胞特征矩阵相乘,获得针对l3个类别的分类器的特征矩阵an=a
n-1
×
t
n-1
为针对n个层级分类的注意力矩阵表达,针对第n层级的分类器的特征矩阵通用表示为f
l
∈rk×
l
,表示该层级分型类别共l个,其中,n,l1,l2,l3,l,k>0,均为整数,且l1>l2>l3,即l
n-1
>ln;
[0052]
4)将步骤二第3)步获取的特征矩阵f
l
∈rk×
l
输入l个二值分类器中,获取输出o
patient
∈r
l
×2,将细胞特征矩阵f
cell
∈rn×k输入关于细胞类别的二值分类器中获取是否为癌细胞的输出结果o
cell
∈rn×2;
[0053]
5)根据o
cell
计算细胞比例为其中为保留该比例中的梯度,从而调节网络参数,需要用到gumbel_softmax函数,将n
×
2维的矩阵在第1维中形成是否为癌细胞的概率表示,即关于每一个细胞i有即关于每一个细胞i有表示是正常细胞的概率,表示为癌症细胞的概率;按第0维求和除以总数n,即获得比例其中其中而o
patient
∈r
l
×2中,对于每一类j有该样本是否属于该类的概率pj∈[0,1],分类学习过程的损失函数表示为:
[0054][0055]
[0056]
本发明所述细胞分割模块为本领域现有技术。
[0057]
本发明通过步骤一获取属于病人的多个骨髓细胞,并通过一定数量的采样打包形成样本,符合医生分析骨髓细胞诊断分型的流程;所以本方法所用的标签为病人的分型以及癌细胞的比例,是一个多示例学习的方法。
[0058]
通过步骤二将细胞编码成特征,并通过注意力模块计算不同细胞对各个类别的贡献度,分型形成层级特征,从细分型的注意力矩阵聚合至粗分型。步骤二中针对癌细胞比例的损失函数,通过对比例的限制,半监督地分类了各个细胞是否属于癌细胞,使得注意力机制可以更好地计算细胞对各个类别的贡献度。针对病人分型的损失函数,则保持了模型对儿童白血病分类的准确性。将细分类的注意力矩阵聚合到粗分类,使得两者之间形成制约,使得各个细胞在大类间不易混淆,使得分类更为精准。
[0059]
基于分层注意力机制的儿童白血病分类方法,模拟了真实的临床诊断流程,更符合儿童白血病分型多且细的特征。针对类别的注意力机制将每个细胞对不同类别的贡献度融入细胞特征中,更好发挥了注意力机制在多分类中的作用,让模型更好地注意到针对各个类别的细胞。分层级地进行分型,将细分型的注意力矩阵聚合到粗分型,使得细分型的特征不易在大类之间混淆,从而提高了分型的准确度。
[0060]
实施例:
[0061]
进行n=2个层级的分类。分别称这两个层级为粗粒度分型和细粒度分型。细粒度分型的类别个数l1=7,其中各个分型为m2,m3,m5,m7,l1&l2,l3,正常人(normal);粗粒度分型的类别个数l2=3,其中各个分型为急性髓系白血病(aml),急性淋巴系白血病(all),正常人(normal)。粗粒度与细粒度之间的转换关系为急性髓系白血病包含m2,m3,m5,m7;急性淋巴系白血病包含l1&l2,l3。
[0062]
参见图1,步骤一:进行细胞分割任务:
[0063]
1)根据医生给出的儿童白血病分析诊断结果,将一个儿童白血病病人的多张骨髓细胞图像中的有核细胞通过细胞分割模块提取出来,再进行50个细胞为一份的随机采样,形成一个多实例包,具体如下:
[0064]
1.1)将一个儿童白血病病人的15张尺寸为512像素
×
512像素骨髓细胞图像进行步长为128像素,窗口大小为256像素的多中心裁剪,获取16个覆盖全图的图块,并用x={x1,x2,...,x
16
}表示图块集合;
[0065]
1.2)将步骤一第1.1)步得到的每个图块随机采取形状、角度和颜色变化的图像增强方式,并进行中心裁剪获取边长256像素正方形图块,经过图像增强的图块集合表示为
[0066]
1.3)将步骤一第1.2)步得到的图块集合输入细胞分割模块,获取的输出图块,通过其中心坐标在原始图像中的位置,定位拼接得到原图像大小细胞分割结果,再将分割结果中的所有细胞抽取出来,设获取50个细胞,单细胞图块集合表示为c={c1,c2,...,c
50
};
[0067]
2)对不同类型儿童白血病病人的骨髓细胞图像,根据步骤一第1)步依次形成多实例包样本;
[0068]
参见图2,步骤二、进行儿童白血病分类任务:
[0069]
将步骤一中处理得到的多实例包输入儿童白血病分类模块,儿童白血病分类模块即一个由编码器、注意力模块和分类器构成的卷积神经网络,其中注意力模块即由全连接
层构成的神经网络,区分一个样本属于急性髓系白血病或急性淋巴系白血病,并进一步区分两大系中的不同子分型,分类到各个不同子分型后进一步区分不易区分的子分型或子分型中的小类,即进行多个层级的分型:
[0070]
1)将步骤一第1.3)最终获得的单细胞图块集合c进行边界填充,将所有细胞图块填充为边长为128像素的正方形,便于将所有细胞图块打包输入编码器,填充后的单细胞图块集合为
[0071]
2)从步骤一第1)步生成的样本所属的病人的临床诊断报告中获取病人的白血病分型y
t
,即表示该病人为y
t
型;设病人分型共7个细分型类数,并将病人标签转换为one-hot向量y=(y1,y2,...,y7),其中y
t
=1,其他分量为0;获取病人细胞比例s=(s1,s2),其中s2为癌细胞的比例,s1=1-s2,s1表示正常细胞的比例;
[0072]
3)将步骤二中第1)步获取的单细胞集合输入编码器,得到的细胞特征矩阵f
cell
∈r
50
×
512
,其中512表示单个细胞的特征维数,将f
cell
输入基于类别的注意力模块,即学习各个细胞对各个类别的分类贡献度的由全连接层构成的神经网络;在注意力模块中,首先将细胞特征矩阵分别通过全连接层u∈r
512
×
256
和v∈r
512
×
256
将特征维度降低至256,再分别进行tanh和sigmoid函数的归一化,将归一化后的结果相乘,再经过一个由256维到7维的全连接层w∈r
256
×7,获取注意力矩阵,即每个细胞对7个类别的贡献度a1∈r
50
×7:
[0073]
a1=w
×
(tanh(f
cell
×
u)
⊙
sigmoid(f
cell
×
v))
[0074]
其中
⊙
表示矩阵内对应点相乘;
[0075]
最终通过细胞特征矩阵与注意力矩阵的相乘得到f7∈r
512
×7表示针对7个类别的分类器的特征矩阵;
[0076]
第二层级粗分型的类别个数为3,则通过转换矩阵t1∈r7×3,定义如下:
[0077][0078]
将针对7个类别的注意力矩阵中对应类别的值聚合到3个类别,即a2∈r
50
×3,a2=a1×
t1,获得各个细胞对第二层级粗分型中各个类别的贡献度,通过注意力矩阵和细胞特征矩阵相乘,获得针对3个类别的分类器的特征矩阵f3∈r
512
×3;
[0079]
4)将步骤二第3)步获取的特征矩阵f3∈r
512
×3输入3个二值分类器中,获取输出粗分型结果o
patient_3
∈r3×2,f7∈r
512
×7输入7个二值分类器中,获取输出细分型结果o
patient_7
∈
r7×2,将细胞特征矩阵f
cell
∈r
50
×
512
输入关于细胞类别的二值分类器中获取是否为癌细胞的输出结果o
cell
∈r
50
×2;
[0080]
5)用gumbel_softmax函数将o
cell
这个50
×
2维的矩阵在第1维中形成是否为癌细胞的概率表示,即关于每一个细胞i有胞的概率表示,即关于每一个细胞i有表示是正常细胞的概率,表示为癌症细胞的概率;按第0维求和除以总数50,即获得比例其中其中即求得了该病人的癌细胞比例而o
patient_7
∈r7×2和o
patient_3
∈r3×2中,对于每一类j有该样本是否属于该类的概率pj∈[0,1],取概率最高的那一类,即为本发明为该病人预测的细分型和粗分型。
[0081]
通过测试集的测试比对,基于分层注意力机制的分类方法对细粒度分型的正确率可以达到79%,对粗粒度分型的正确率可以达到97%。
[0082]
当细粒度分型与粗粒度分型之间不利用转换关系t1时,即分别用不同的注意力模块求得各自的注意力矩阵a1和a2,细粒度分型正确率仅71%,粗粒度分类的正确率仅94%。
[0083]
当粗分型与细分型分别用不同的模型进行预测时,即不基于分层的分类方法,细分型正确率仅73%,粗分类的正确率仅91%。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
