1.本发明涉及计算视觉领域,特别是涉及一种可见光红外图像融合目标检测实例分割方法。
背景技术:
2.视觉信息作为人类重要的获取信息渠道,人类获取的信息83%来自视觉信息。而视觉传感器作为辅助人类获取视觉信息的工具,在人类的生产生活中占据了重要的地位。然而面对复杂多变的自然环境,单一视觉传感器所得信息拥有极大的局限性,图像融合技术应运而生。
3.红外成像器件与可见光成像器件在成像器件领域受到了广泛的关注。可见光图像是依靠物体反射光成像,所产生图像适合人眼观测,具有较高的空间分辨率、相当多的细节和明暗对比,但是容易受到光照差、雾和其他恶劣天气等极端环境干扰。红外图像依靠物体物体热辐射成像,光照差、雾和其他恶劣天气的情况下,拥有良好的成像效果,但相比于可见光成像器件空间分辨率较低,细节也会有所降低。将红外图像与可见光图像进行融合,可以综合二者优势,产生出细节丰富,同时适合恶劣天气的图像。但全幅图像的融合会使得图像融合耗时长,比如对于城市交通情况,一般只需要关心,行人,车辆,自行摩托车等目标,对于背景的道路,广告牌,天空等目标融合会产生极大的亢余。
技术实现要素:
4.本发明的目的在于提供一种可见光红外图像融合目标检测实例分割方法,只针对关心的目标分割出相应实例。
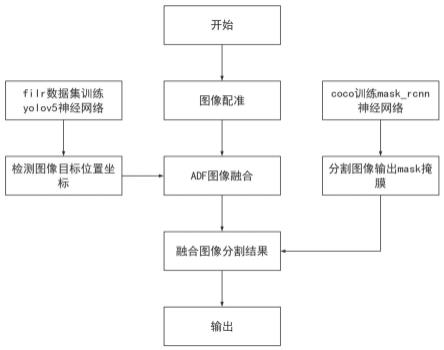
5.实现本发明目的的技术解决方案为:一种可见光红外图像融合目标检测实例分割方法,步骤如下:步骤1,将红外图像与可见光图像配准,对红外图像与可见光光图像中的相同目标进行标定,依据标定结果对红外图像进行平移、缩放,得到红外配准图像;步骤2,使用yolov5神经网络在红外配准图像中提取目标位置坐标;步骤3,使用mask_rcnn神经网络在红外配准图像中提取mask掩膜;步骤4,依据目标位置坐标确定融合范围,采用adf图像融合方法对可见光图像与红外配准图像进行融合;步骤5,对融合图像赋予伪彩色,并使用mask掩膜进行实例分割。
6.进一步的,步骤1,将红外图像与可见光图像配准,对红外图像与可见光光图像中的相同目标进行标定,依据标定结果对红外图像进行平移、缩放,得到红外配准图像,具体方法为:选取同时拍摄的可见光图像与红外图像各一张,于两张图像中分别选取12组标定点记录坐标为x
ir_i,yir_i
与x
vis_i,yvis_i
(i是∈[1,12]),其中下标为ir代表是红外图像的标记点,vis代表可见光图像标记点,i代表组数,对于每个标定点,要求现实空间位置相同,12组
标记点中4组来自近景目标,4组来自中景目标,4组来自远景目标;计算标定点的欧氏距离之和:通过操控红外图像平移缩放,使得标定点的欧氏距离之和最小,将平移缩放量记录下来,对所有红外图像进行相同变换,获得红外配准图像。
[0007]
进一步的,步骤2,使用yolov5神经网络在红外配准图像中获取目标位置坐标,具体方法为:(a)使用flir数据集对yolov5神经网络进行训练;使用flir数据集中的小型车辆、自行车辆、行人三种标签对yolov5神经网络进行训练,训练中采用mosaic数据增强,随机选取4张红外图像,通过随机缩放、随机裁剪、随机排布的方式组成一张全新图片,将原始flir数据集图像与mosaic数据增强后所得到的图像组成训练集输入yolov5神经网络中进行训练,获得训练权重;(b)使用yolov5神经网络进行目标检测;将配准红外图像采用最小黑边缩放,最小黑边缩放计算方法如下:其中m,n是原始的输入图像长宽系数,t为yolov5神经网络输入需要的图像边长,a
1,
a2是原始图像相对于yolov5神经网络需要图像输入的长宽缩放系数;将配准红外图像使用比例m
new
、n
new
进行缩放;其中a
min
是a
1,
a2中的较小值;在上下边填充长为c的黑框,填充边宽度计算公式为:,其中c为填充黑边大小;加载(a)中训练获得权重,将缩放填充后的红外配准图像输入yolov5神经网络之中,输出目标位置坐标(x1,x2,y1,y2,c),x1,y1为目标左上角点坐标,x2,y2为目标右下角点坐标,c为目标分类。
[0008]
进一步的,步骤3,使用mask_rcnn神经网络在红外图像中提取mask掩膜,包括:使用coco数据集进行mask_rcnn神经网络训练,获得训练权重;加载(a)中训练权重,将红外配准图像输入mask_rcnn神经网络中获得mask掩膜。
[0009]
进一步的,步骤4,依据目标位置坐标确定融合范围,采用adf图像融合方法对可见光图像与红外配准图像进行融合,具体方法为:步骤4.1,以x1,y1为左上角点坐标,x2,y2为右下角点坐标,构建目标位置坐标矩形框,对可见光图像与红外配准图像使用目标位置坐标矩形框选取待融合可见光图像与待融
合红外图像,使用adf图像融合方法;步骤4.2,将可见光图像与红外配准图像进行各向异性滤波,得到可见光图像基础层b
vis
与红外配准图像基础层b
ir
,其中各向异性滤波对进行图像分解具体操作为:其中i
t 1
为输出图像,i
t
为输入图像,c是扩散速率,∨是梯度运算符,δ是拉普拉斯算符,t是设置迭代次数;步骤4.3,将待融合可见光图像减去可见光图像基础层获得可见光图像细节层,将待融合红外图像减去红外图像基础层获得红外图像细节层,其中红外图像细节层计算为:可见光图像细节层为:其中i
vis
与i
ir
分别为待融合可见光图像与红外配准图像;步骤4.4,将可见光图像细节层与红外配准图像细节层分别排列为x
vis
与x
ir
的列向量矩阵,找到x
vis
与x
ir
的协方差矩阵c
xx
,计算协方差矩阵c
xx
特征值集合w1、w2与特征向量集合:选取w1、w2中较大的特征值为w
max
,选取w
max
对应的特征向量v
max
,求得细节层不相关组件系数,kl1为可见光图像细节层不相关组件系数,kl2为红外图像细节层不相关组件系数:融合图像细节层:融合图像基础层:融合图像:。
[0010]
进一步的,步骤5,对融合图像赋予伪彩色,并使用mask掩膜进行实例分割,具体方法为:对融合后图像使用colormap_jet进行伪彩色处理,获取彩色融合图像,将可见光图像目标位置坐标矩形框内图像替换为彩色融合图像,获取全局彩色融合图像,使用mask掩膜取反与可见光图像叠加获得可见光背景图像,将mask掩膜与全局彩色融合图像叠加获
取全局彩色融合图像实例分割部分,再将全局彩色融合图像实例分割部分与可见光背景图像叠加获得最终结果。
[0011]
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时,基于所述的可见光红外图像融合目标检测实例分割方法,实现基于可见光图像与红外图像融合检测的目标实例分割。
[0012]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,基于所述的可见光红外图像融合目标检测实例分割方法,实现基于可见光图像与红外图像融合检测的目标实例分割。
[0013]
本发明与现有技术相比,其显著优点在于:(1)相比于一般的可见光与红外图像融合方法,能够智能的对于图像上关心的目标进行目标检测,并且对关心目标进行实例分割;(2)相比于一般的可见光与红外图像融合方法,采用了基于目标位置坐标的局部融合,既保证了关心目标的检测,又缩小了图像融合所消耗的时间;(3)对于mask_rcnn神经网络训练采用了mosaic数据增强方法,提高了网络对于小目标的检测性能。
附图说明
[0014]
图1为本发明结构实施流程示意图。
[0015]
图2为yolov5结构示意图。
[0016]
图3为yolov5具体模块示意图。
[0017]
图4为yolov5中slice的结构示意图。
[0018]
图5为mask_rcnn结构示意图。
[0019]
图6为resnet-fpn结构图。
[0020]
图7为prn网络结构。
[0021]
图8为adf图像融合流程图。
[0022]
图9为本发明检测效果图。
具体实施方式
[0023]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
[0024]
本发明一种可见光红外图像融合目标检测实例分割方法,整体流程图如图1所示,包括以下步骤:步骤1,对于红外图像与可见光图像进行配准处理,对红外图像与可见光光图像中的相同目标进行标定,依据标定结果对红外图像进行平移、缩放,得到红外配准图像;原始的可见光图像与红外图像存在视场不同的问题,直接融合会出现目标错位的现象,为了使融合图像目标位置严格对应,需要进行图像配准操作。选取同时拍摄的可见光图像与红外图像各一张,于两张图像中分别选取12组标定点记录坐标为x
ir_i,yir_i
与x
vis_i,yvis_i
(i是∈[1,12]),其中下标为ir代表是红外图像的标记点,vis代表可见光图像标记点,i代表组数,对于每个标定点,要求现实空间位置相同,12组标记点中4组来自近景目标,4组来自中景目标,4组来自远景目标。计算标定点的欧氏距离之和
通过操控红外图像平移缩放,使得标定点的欧氏距离之和最小,将平移缩放量记录下来,红外图像输入之后将按照这个平移缩放量进行变化,使得红外图像上的目标与可见光图像上相同目标做图像上像素坐标位置相同。
[0025]
步骤2,训练yolov5神经网络,使用yolov5神经网络在红外配准图像中提取目标位置坐标;yolov5神经网络具体结构如图2与图3所示,包括:输入端,进行最小黑边填充;backbone部分,输入红外图像进行特征提取,得到特征图;neck部分,将输入的特征图进行上采样,得到三组不同尺度的特征图;预测部分,将三组尺度不同的特征图进行卷积运算,得到目标位置坐标,将三组尺度上的综合在输入图像上,即为最后目标位置坐标;输入图像进入yolov5神经网络前会进行最小黑边缩放成统一尺寸,本发明中t取值为608,输入的配准红外图像大小为640*512最小黑边缩放计算方法如下:其中m,n是原始的输入图像长宽系数,t为yolov5神经网络需要的图像边长,ai是缩放比选择最小的缩放系数对填充边数值进行计算,其中c为填充黑边大小。将配准红外图像使用比例m
new
、n
new
进行缩放,并在上下边填充长为c的黑框,图像高度上两端的黑边变少了,在推理时,计算量也会减少。
[0026]
backbone,由focus模块,与csp模块,spp模块排列构成,用于提取图形的特征图。是yolov5的主干网络。focus结构将一张图片分为四组不同的slice,通过contcat进行堆叠,如图4所示。经过第一个focus模块,获得304*304的特征图;经过cbl模块口获得152*152的特征图;经过csp1_1与cbl模块后获得76*76的特征图,经过csp1_3模块后一部分输入neck模块,一部分输入cbl模块获得38*38的特征图在经过csp1_3模块保存,输入cbl模块获得19*19的特征图,输入spp模块输入neck部分。
[0027]
neck,采用了fpn pan的结构,将图像下采样,提取不同尺度的目标特征,提供给预测层。fpn部分分别提取76*76,38*38,19*19从尺寸的特征层。两个特征层融合的具体做法是,较高层特征2倍上采样,较低层特征通过1
×
1卷积改变一下低层特征的通道数,然后简单地把将上采样和cbl卷积后的结果对应元素相加。pan结构中,将fpn中的特征金字塔最底层复制为新特征金字塔最底层,将特征金字塔底层上采样与fpn中的上一层进行叠加,在经过csp2_1卷积结构输出预测目标坐标位置与置信度。
[0028]
预测段,采用nms非极大值抑制进行目标筛选,nms非极大值抑制主要步骤是将所有矩形框按不同类别标签分组,组内按照置信度高低进行排序。将同标签的矩形框拿出,遍历剩余同标签矩形框,计算交并比,将剩余矩形框中大于设定的iou阈值的框删除。
[0029]
关于模型训练过程是本实施例的关键,下面对本发明中用到的目标检测用的 yolov5神经网络模型进行具体说明:本发明选用filr数据集训练yolov5神经网络,flir数据集是2018年7月发布的汽车交通道路可见光与红外图像数据集,一共选用14000张图像,选用其中人,自行车,汽车三种训练标签,采用mosaic数据增强,采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接,选取ciou_loss作为损失函数,ciou_loss损失函数公式如下:其中其中是两框交集面积,是两框并集面积。是两框最小外接矩形对角线长度,是两框图中心点欧氏距离。是衡量长宽比一致性的参数。具体计算公式为其中w
gt
,h
gt
分别代表预测框图的宽高,w
p
,h
p
分别代表实际框图的宽高。
[0030]
训练得到训练权重后,将匹配红外图像输入得到预测目标位置坐标,具体目标包括行人、自行车、汽车。
[0031]
步骤3,训练mask_rcnn神经网络,使用mask_rcnn神经网络在红外配准图像中提取mask掩膜。
[0032]
图5是mask_rcnn神经网络示意图,结构包括:resnet-fpn部分,提取出不同尺度的特征图,构建特征金字塔;rpn部分,提取特征图之中的需要部分;roi align部分,对特征图中提取部分进行池化;mask部分,输入特征图获取mask掩膜;resnet-fpn部分包括五个卷积层,从第二到第五层之间输出四张尺度不同的特征图,对于原始图像提取4,8,16,32倍缩放的特征图,如图6所示。
[0033]
rpn部分图片输入后,经过1*1的卷积层,一组经过reshape,softmax,reshape。其中softmax模块可以提取出提取特征图之中的需要部分,如图7所示;roi align将特征图的每个采样点内均分成四个方格,对每个单元格内的四个采样点进行maxpooling,就可以得到最终的roialign的结果。
[0034]
mask部分使用fcn全卷积网络进行图像分割。
[0035]
本发明采用coco数据集进行mask_rcnn进行训练,coco数据集是一个大型的物体检测、分割和字符的数据集。包括330k本发明选取其中汽车,自行车,行人三种标签,并且剔除不相关图片进行训练,同时也采用mosaic数据增强的方法。
[0036]
训练取得相应权重后,对配准红外图像进行实例分割,获得mask掩膜。
[0037]
步骤4,依据目标位置坐标确定融合范围,对可见光图像与红外配准图像融合范围采用adf图像融合方法,并赋予伪彩色处理,对于伪彩色图像使用mask掩膜进行实例分割;将可见光图像与红外配准图像,以x
1,
y1为左上角点坐标,x
2,
y2为右下角点坐标构建目标位置坐标矩形框,使用目标位置坐标矩形框选取待融合可见光图像与待融合红外配准图像,使用adf图像融合方法。
[0038]
adf图像融合流程如图8所示,将可见光图像与红外配准图像进行各向异性滤波,得到可见光图像基础层b
vis
与红外配准图像基础层b
ir
:各向异性滤波对进行图像分解具体操作为:其中i
t 1
为输出图像,i
t
为输入图像,c是扩散速率,∨是梯度算符,δ是拉普拉斯算符,t是迭代次数,设置为10,输入原图像为i0,输入出为i1,在将i1输入,进行10次迭代获得i
10
,即为基础层图像,上述公式展开可得:∨是梯度算符,下标n,s,e,w代表对单方向求梯度,δ是拉普拉斯算符,t是迭代次数,cn,cs,cw,ce代表输入图像对南北西东方向的导通系数,i
ti,j
代表输入图像,i,j代表对单个像素位置坐标,i
t 1i,j
为输出图像迭代次数设置为10,λ取值区间为[0,1/4],对于公式中的∨
niti,j
,∨
siti,j
,∨
witi,j
,∨ei
ti,j
,部分展开公式如下:部分展开公式如下:其中i
i-1,j-i
i,j
表示对于图像上的每个像素,使用像素点下的像素减去该像素,边界位置取零值,其余公式同理,对于公式中的cn,cs,cw,ce部分具体计算公式如下:部分具体计算公式如下:其中∨
niti,j
,∨
siti,j
,∨
witi,j
,∨ei
ti,j
与上文中含义相同,函数需要满足单调递减以及两种计算选择,采用以下两种:上述操作可见光原图像为i0,输入出为i1,在将i1输入,进行10次迭代获得i
10
,即为可见光图像基础层b
vis
,红外配准图像使用同样得操作得到红外配准图像基础层b
ir
。
[0039]
将可见光图像减去可见光图像基础层获得可见光图像细节层,红外配准图像细节层计算为:
可见光图像细节层为:其中i
vis
与i
ir
分别为可见光图像与红外配准图像。
[0040]
将可见光图像细节层与红外图像细节层分别排列为x
vis
与x
ir
的列向量矩阵,找到x
vis
与x
ir
的协方差矩阵c
xx
,计算协方差矩阵c
xx
特征值集合w1、w2与特征向量集合计算不相关系数,选取较大的特征值w
max
,选取其对应的特征向量v
max
,求得细节层不相关组件系数融合图像细节层融合图像基础层融合图像为将融合图像部分使用colormap_jet策略进行伪彩色处理,获取彩色融合图像,将可见光图像目标位置坐标矩形框内图像替换为彩色融合图像,获取全局彩色融合图像,使用mask掩膜取反与可见光图像叠加获得可见光背景图像,将mask掩膜与全局彩色融合图像叠加获取全局彩色融合图像实例分割部分,再将全局彩色融合图像实例分割部分与可见光背景图像叠加获得最终结果。
[0041]
实验场景为面向城市交通道路场景,使用海康千兆网口工业面阵相机可见光探测器,xenicsgobi 640红外热像仪,双目摄像头于jetson-nano开发平台上60w功率实时运算结果。拍摄为3分23秒,包括4067张图片。
[0042]
图9是最终的检测样图,能精准的争对城市道路交通中的行人,车辆进行目标检测与分割,并对检测区域进行红外可见光的融合。
[0043]
表1是单张图片使用全融合与局部融合的时间消耗对比,与各个部分环节时间消耗,显然局部融合比起全局融合消耗时间有所下降。表2是不同分割方法的精准度对比,对于中大目标各神经网络分割效果相似,但对于远处小目标mask_rcnn网络拥有明显的优势。
[0044]
表1单张图片使用全融合与局部融合的时间消耗对比
表2不同分割方法的精准度对比以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0045]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。