一种硬件自动维护datacache数据一致性的方法
技术领域
1.本发明涉及cpu数据缓存领域,尤其涉及一种硬件自动维护datacache数据一致性的方法。
背景技术:
2.当前在嵌入式单片机或芯片中有很多处理单元或协处理器用来协助cpu搬运或者进行数据计算,可以释放cpu时间允许cpu处理更多事务,提高应用运行的性能。由于cpu访问内存或外存的效率较低,有些cpu中具有数据缓存功能,为cpu提供数据缓存的能力,可以提高数据访问的效率。cache的工作原理是:如果cpu需要读取从地址a开始长度是l个数据,cpu会访问cache。如果需要的数据正好在cache中,则视为命中,否则为未命中。在未命中的情况下,cache会主动从存储器地址a处主动中读取一整个cache行的数据,形成相同于存储器数据的一个备份,然后再提供给cpu。下次cpu访问a 1地址中的数据时,这个数据就已经存在于cache中,就直接命中。当cpu需要修改存储器中的数据时,其实是修改了cache中的数据。cache这种基于预测的数据缓存方法可以有效隐藏cpu直接访问其它存储设备花费的时间,从而提高cpu运算的效率。当通过软件的方法要求cache将更新的数据写回到存储器,或cahce基于自身的控制机会将数据写回到它们在存储器中的地址,对于程序来说数据才被真正的更新。但是这种基于备份的缓存机制和处理单元或协处理器的同时存在引入了一个新的问题,就是cache的数据一致性问题。理论上如果只有cpu读取和写数据,cache和存储器之间的数据会在cpu-datacache-存储器这个闭环中始终保持一致。但是由于处理单元、协处理器等一些cpu之外可以更新数据的单元的存在,数据会在cpu-dcache-存储器这个闭环外被修改。如果某些数据正好在datacache中存在备份,同时闭环外的单元正好又修改了存储器中的原始数据而datacache对此不知情且没有处理,没有维护cache和存储器数据之间的数据一致性,当cpu正好需要使用datacache中的这个过时的错的数据进行计算会直接命中,从而导致计算错误。
技术实现要素:
3.本发明的目的是:通过硬件自主执行datacahce中数据失效操作,维护datacache的数据一致性,本发明采用以下技术方案:
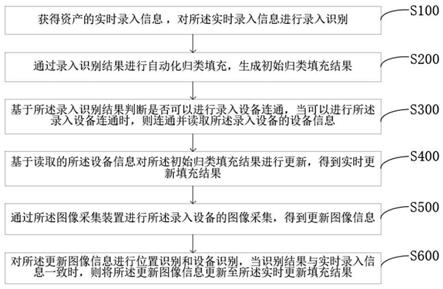
4.一种硬件自动维护datacache数据一致性的方法,包括以下步骤:
5.步骤s1:软件配置处理单元工作向存储器中写入目的地址a;
6.步骤s2:在处理单元向目的地址a写入地址时,通过硬件装置使datacache中目的地址a的存储区域失效;
7.步骤s3:如果cpu再次访问目的地址a时,未命中datacache中的目的地址a,cpu从存储器中读取数据。
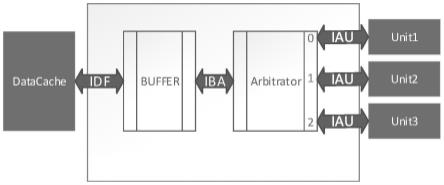
8.具体的,在步骤s2中,硬件包括缓冲器和仲裁器,datacache和缓冲器之间通过接口idf连接,缓冲器和仲裁器之间通过接口iba连接,仲裁器与多个处理单元之间分别通过
接口iau连接。
9.仲裁器的作用是从来自多个处理单元的多个请求中选出一个,将其通过iba接发送给缓冲器接收。仲裁器有多个id不同的端口,处理单元通过iau接口连接到不同的端口上。端口id越小,仲裁器处理这个端口的请求越优先。在同时有多个请求同时发生时,仲裁器按照这种固定优先级的原则,按照优先级从高到底依次发送给缓冲器接收。如果需要调整处理单元请求被处理的优先级,可以调整其通过iau连接到的仲裁器端口号更小的端口。
10.采用仲裁器的有益效果是允许处理并发请求。如果不采用仲裁器,要么是单设备的系统比如只有一个处理单元可以发送请求,要么要设计抢占式的总线系统。
11.缓冲器的作用是通过iba接口接收来自仲裁器的请求并缓存,缓存后的请求通过idf接口发送给datacache处理。缓冲器中的存储单元使用fifo实现,fifo深度为2,当fifo未满时,如果有有效请求,则同周期应该完成接收和缓存。当fifo中不空时,说明缓存中有被缓存的请求,将最先缓存的请求发送给datacache处理,等待datacache的done_ack置位,排出这个已经处理的请求。当fifo满了时,应该等待datacache处理。
12.具体的,多个iau接口发送请求至仲裁器,仲裁器的仲裁原则为固定优先级原则、循环优先级中一种。
13.具体的,处理单元包括dma、协处理器、加速器中的一种或多种。
14.具体的,缓存器用于接收来自仲裁器的请求并缓存,缓存后的请求发送给datacache处理,缓存器中设有存储单元,存储单元包括fifo存储单元,fifo存储单元的存储深度根据请求数量进行设定。缓冲器采用fifo存储单元的有益效果为:隐藏了datacache处理请求的时间,允许处理单元的请求被快速响应,提高了请求被响应的效率,同时通过fifo存储单元的先进先出的特性保证了先到的请求被优先处理。如果不采用fifo存储单元(其中fifo的存储深度大于等于1),处理单元发出的请求必须等待datacache处理完成,这样会使得处理单元的工作效率降低。
15.具体的,步骤s2中,通过硬件装置使datacache中目的地址a的存储区域失效,包括以下步骤:
16.步骤s21:n个处理单元同时请求datacache失效时,n个处理单元,包括处理单元1、处理单元2、处理单元3....处理单元n,通过iau接口同时发送请求至仲裁器,仲裁器响应n个处理单元的请求并同时传输至仲裁器,仲裁器按照仲裁优先级,依次响应并传输n个处理单元的请求至缓存器;
17.步骤s22:缓存器将请求通过idf接口发送给datacache,datacache开始处理请求,同时仲裁器将下一优先级处理单元的请求发给缓存器,缓存器判定缓存器中的存储单元是否已满:
18.若存储单元未满,则缓存器缓存下一优先级处理单元的请求并应答,同时将应答反馈至仲裁器,仲裁器再反馈至下一优先级处理单元,下一优先级处理单元的请求响应完成,并进入步骤s26;
19.若存储单元已满,则进入步骤s23;
20.步骤s23:当datacache完成上一优先级处理单元的请求后并反馈至缓存器,进入步骤s24;
21.步骤s24:缓存器排出上一优先级处理单元的请求后缓存应答下一优先级处理单
元的请求,并将下一优先级处理单元的请求的应答反馈至仲裁器,仲裁器再反馈至下一优先级处理单元,下一优先级处理单元的请求响应完成;
22.步骤s25:再次进入步骤s23,直至datacache完成所有处理单元的请求;
23.步骤s26:再次进入步骤s22,直至datacache完成所有处理单元的请求。
24.该方法的优点为:通过硬件自动化失效datacache中对应数据,避免潜在的重要环节的人为疏漏,可以降低程序对工程师经验的要求,提高程序鲁棒性,避免出现此类错误。
附图说明
25.图1是一种硬件自动维护datacache数据一致性的方法的流程图;
26.图2是通过iau接口信号,request和ack信号进行握手的时序图;
27.图3是通过iba接口信号,request和notfull_ack信号进行握手的时序图;
28.图4是通过idf接口信号,notempty_request和notfull_ack信号进行握手。
具体实施方式
29.根据图1至图4,该方法中工作流程为:
30.一种硬件自动维护datacache数据一致性的方法,包括以下步骤:
31.步骤s1:软件配置3个处理单元工作向存储器中写入目的地址a。其中处理单元分别为第一处理单元、第二处理单元以及第三处理单元;
32.步骤s2:在3个处理单元向目的地址a写入地址时,通过硬件装置使datacache中目的地址a的存储区域失效,其中包括以下步骤:
33.1系统复位,此时缓冲器里的fifo处于空的状态,随时可以缓冲请求。
34.2某一周期开始的第1个周期:
35.2.1第一处理单元和第二处理单元同时有需要请求datacache失效的情况发生时,通过iau接口发送给仲裁器。
36.2.2仲裁器同时接收到两个端口上的请求,优先响应端口0即来自第一处理单元的请求1,然后处理端口1即来自第二处理单元的请求2。仲裁器先将第一处理单元的请求发给缓冲器。
37.2.3此时缓冲器由于fifo为空直接缓冲请求并应答,同周期仲裁器将缓冲器的应答传回第一处理单元,第一处理单元的请求响应完成。
38.3第2个周期:
39.3.1缓冲器将缓冲的第一处理单元的请求1发给datacache。datacache开始处理请求1。
40.3.2仲裁器先将第二处理单元的请求发给缓冲器。
41.3.3缓冲器中的fifo的缓存深度为2,所以缓冲器中的fifo仍然处于未满的状态,可以直接缓冲。同周期仲裁器将缓冲器的应答传回第二处理单元,第二处理单元的请求响应完成。
42.4第3个周期:
43.4.1datacache还在处理请求1.
44.4.2第三处理单元发送请求3,仲裁器将请求3转发给缓冲器,由于缓冲器的fifo处
于满的状态,无法缓存请求3,等待datacache处理。
45.5第4个周期:
46.5.1datacache完成请求1的处理,通过done_ack反馈缓冲器。
47.5.2缓冲器排出请求1,将请求2发送给datacache,缓冲请求3,通过notfull_ack反馈给仲裁器。
48.5.3同周期仲裁器反馈给处理单元,第三处理单元的请求响应完成。
49.6第5,6个周期,datacache处理请求第二处理单元.
50.7第7个周期
51.7.1datacache完成请求2的处理,通过done_ack反馈缓冲器。
52.7.2缓冲器排出请求2,将请求3发送给datacache.
53.8第8,9个周期,datacache处理请求第三处理单元
54.9第10个周期,datacache完成请求3的处理。
55.步骤s3:如果cpu再次访问目的地址a时,未命中datacache中的目的地址a,cpu从存储器中读取数据。
56.在步骤s2中,硬件包括缓冲器和仲裁器,datacache和缓冲器之间通过接口idf连接,缓冲器和仲裁器之间通过接口iba连接,仲裁器与处理单元之间通过接口iau连接。
57.其中,iau接口信号具体如下表1所示,通过request和ack信号进行握手,当request和ack信后都为高时说明一次请求发送和响应完成,时序图如图2所示。iba接口信号具体如表2所示,通过request和notfull_ack信号进行握手,当request和notfull_ack信后都为高时说明一次请求发送和响应完成,时序图如图3所示。idf接口信号具体如下表3所示,通过notempty_request和notfull_ack信号进行握手,当notempty_request和notfull_ack信后都为高时说明一次请求发送和响应完成,时序图如图4所示。
58.仲裁器的作用是从来自多个处理单元的多个请求中选出一个,将其通过iba发送给缓存器接收。仲裁器有多个id不同的端口,处理单元通过iau接口连接到不同的端口上。端口id越小,仲裁器处理这个端口的请求越优先。在同时有多个请求同时发生时,仲裁器按照这种固定优先级的原则,按照优先级从高到底依次发送给缓存器接收。如果需要调整处理单元请求被处理的优先级,可以调整其通过iau连接到的仲裁器端口号更小的端口。采用仲裁器的有益效果是允许处理并发请求。如果不采用仲裁器,要么是单设备的系统比如只有一个处理单元可以发送请求,要么要设计抢占式的总线系统。采用固定优先级的仲裁策略的有益效果是这种简单的仲裁策略设计简单,针对这种不复杂的并发请求效率较高。
59.缓存器的作用是通过iba接收来自仲裁器的请求并缓存,缓存后的请求通过idf发送给datacache处理。缓存器中的存储单元使用fifo实现,fio深度为2,当fifo未满时,如果有有效请求,则同周期应该完成接收和缓存。当fifo中不空时,说明缓存中有被缓存的请求,将最先缓存的请求发送给datacache处理,等待datacache的done_ack置位,排出这个已经处理的请求。当fifo满了时,应该等待datacache处理。
60.缓存器采用fifo的有益效果是隐藏了datacache处理请求的时间,允许处理单元的请求被快速响应,提高了请求被响应的效率,同时通过fifo的先进先出的特性保证了先到的请求被优先处理。如果不采用fifo(fifo深度》=1),处理单元发出的请求必须等待datacache处理完成,使得处理单元的工作效率降低。
61.综上所述,该方法的优点为:通过硬件自动化失效datacache中对应数据,避免潜在的重要环节的人为疏漏,可以降低程序对工程师经验的要求,提高程序鲁棒性,避免出现此类错误。
62.表1iau接口信号具体如下
[0063][0064]
表2、iba接口信号具体如下
[0065][0066]
表3、idf接口信号具体如下
[0067][0068][0069]
可以理解的是,以上关于本发明的具体描述,仅用于说明本发明而并非受限于本发明实施例所描述的技术方案。本领域的普通技术人员应当理解,仍然可以对本发明进行修改或等同替换,以达到相同的技术效果;只要满足使用需要,都在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。