1.本发明涉及智能运维技术领域,具体的说是涉及一种面向运维工单的自动化处理方法。
背景技术:
2.在大规模系统智能运维场景中,系统节点繁多且节点之间的关系错综复杂,一旦某个节点出现故障,就会迅速传播并产生大量并发警告。根据技术人员提交或系统自动生成的工单,准确快速的发现系统故障节点,并针对故障提出相应的解决方案,可以有效帮助缩短处理故障时间,恢复系统正常工作。
3.zl2011100755972公开了一种基于移动终端的运维工单处理方法及装置,但专利对用户运维工单和系统运维工单不做区分统一处理,没有提供故障节点分析方法,专利直接将运维工单交给运维人员处理,没有提供解决方案匹配功能。
4.zl2020111786808公开了一种运维工单处理方法、装置、计算机设备和存储介质,此专利中的运维工单处理方法所根据所述运维工单的设备类型,确定运维工单的固定处理人员;将工单受理人与所述固定处理人员作为群组人员,创建所述运维工单的即时通信群组;通过即时通信群组,接收群组人员发送的工单处理信息。但该专利对用户运维工单和系统运维工单不做区分统一处理,是通过运维工单信息确定运维工单的处理人员。
5.综上所述,目前运维工单处理方法中,用户工单和系统工单采取统一方式提取特征,并未根据两种工单的特点进行区分。由于系统节点之间存在多重依赖关系,工单描述信息中的节点可能并非实际故障节点,故障根源难以确定。此外,存在不同的工单具有相同的解决方案,仅通过工单描述信息匹配无法准确匹配解决方案。
技术实现要素:
6.为了解决上述问题,本发明提出了一种面向运维工单的自动化处理方法,该方法采取不同的特征提取方式,为后续工单处理提供了更准确的信息,通过构建系统节点依赖关系图,基于节点依赖路径匹配待解决运维工单故障节点,避免匹配全部节点,提高故障节点发现速度,提高运维工单自动化处理的效率。
7.为了达到上述目的,本发明是通过以下技术方案实现的:
8.本发明是一种面向运维工单的自动化处理方法,包括如下步骤:
9.步骤1:采集历史运维工单数据,根据工单生成方式为用户提交或系统生成,分别构建用户工单数据集和系统工单数据集。
10.步骤2:对所述工单数据集,采用svm分类模型训练,获得运维工单svm分类器。
11.步骤3:统计所述数据集中历史运维工单的节点信息,基于专家知识构建运维工单节点依赖关系图。
12.步骤4:对所述节点依赖关系图的每个节点,分别选取属于该节点的用户工单和系统工单,采用图卷积网络gcn获得节点的用户工单特征向量表示和系统工单特征向量表示。
13.步骤5:对所述节点依赖关系图中每个节点下的不同的工单解决方案,每个解决方案选取属于该解决方案的历史用户工单描述和历史系统工单描述,获取该解决方案的用户序列特征向量表示和系统主题特征向量表示。
14.步骤6:获取待解决运维工单描述信息,采用所述svm分类器进行分类,确定运维工单所属类别。
15.步骤7:根据运维工单所属类别,选择模型输入运维工单描述信息,获得工单特征向量表示。
16.步骤8:计算待解决工单特征向量与所述依赖关系图节点特征向量的相似度,选取相似度最高的节点作为待解决工单的故障节点。
17.步骤9:根据选取故障节点,计算待解决工单特征向量和该节点下所有解决方案特征向量的相似度,选取相似度最高的解决方案作为待解决工单的解决方案。
18.进一步的,构造运维工单数据集,包括:
19.选择一段时间的历史工单数据,按照工单故障类别比例分别采集若干历史用户运维工单和历史系统运维工单,所采集工单属性包括工单编号、工单描述故障节点、工单实际故障节点、工单异常描述信息、工单对应解决方案;若采集的工单存在属性值缺失,重新采集对应类别工单替换该工单;对所采集工单数据集进行文本预处理,包括符号过滤、去停止词、词形还原。
20.进一步的,采用gcn模型获得节点的工单特征向量表示方式如下:
21.对所述节点依赖关系图的每个节点,选取k个属于该节点的用户工单描述进行拼接组成节点的用户特征信息nu,选取k个属于该节点的系统工单描述进行拼接组成节点的系统特征信息ns。
22.将系统节点的依赖关系用m*m维邻接矩阵a表示,其中m为节点数量,a[i][j]表示节点之间的依赖关系,依赖关系的权重为该依赖关系在历史工单描述故障节点和实际故障节点路径中的出现次数,a[i][i]=0表示节点间不存在依赖关系。
[0023]
对于用户工单,通过word2vec将节点用户特征信息tu转为节点词向量表示hu,将所述节点向量表示hu和邻接矩阵a输入用户gcn模型,获得节点的用户工单特征向量表示h
u’。
[0024]
对于系统工单,通过计算词频-逆文档频率将工单系统特征信息ts转为向量化表示hs,将所述节点向量表示hs和邻接矩阵a输入系统gcn模型,获得节点的系统工单特征向量表示h
s’。
[0025]
gcn模型的更新公式如下:
[0026][0027]
其中,为a i,i为单位矩阵,为节点入度矩阵,h
(l)
为节点l层特征表示,w
(l)
为模型l层权重矩阵,α为非线性变换。
[0028]
进一步的,获取工单解决方案的特征向量表示方式如下:
[0029]
对所述不同的解决方案,每个解决方案选取x个与该解决方案相匹配的历史用户工单描述,并进行上述文本预处理,每个工单描述通过word2vec转换为词嵌入向量表示ru。
[0030]
将所述词嵌入向量表示ru依次输入lstm模型中获得x个含有序列信息的工单描述特征向量,将所述特征向量进行横向加和平均,获得该解决方案的用户序列特征向量r
u’。
[0031]
对所述不同的解决方案,每个解决方案选取x个与该解决方案相匹配的历史系统工单描述,并进行上述文本预处理,每个工单描述通过计算词频-逆文档频率转换为向量表示rs。
[0032]
将所述向量表示rs依次输入lda模型中获得x个含有主题分布的工单描述特征向量,将所述特征向量进行横向加和平均,获得该解决方案的系统主题特征向量r
s’。
[0033]
进一步的,获取待解决运维工单的特征向量方式如下:
[0034]
对所述待解决运维工单的描述信息进行上述文本预处理,输入所述svm分类器,获得待解决运维工单所属类别。
[0035]
若待解决运维工单为用户工单,将描述信息通过word2vec转化为词嵌入向量表示,输入lstm模型,获得待解决运维工单的序列特征向量表示tu。
[0036]
若待解决运维工单为系统工单,将描述信息通过计算词频-逆文档频率转化为向量表示,输入lda模型,获得待解决运维工单的主题特征向量表示ts。
[0037]
进一步的,匹配待解决运维工单故障节点的方式如下:
[0038]
根据待解决运维工单描述故障节点,选择所述节点依赖关系图对应节点和上游依赖节点。
[0039]
根据待解决运维工单的类别,计算待解决运维工单描述节点特征向量tu或ts与所选节点特征向量[h
u1’,h
u2’,
…
,h
ul’]或[h
s1’,h
s2’,
…
,h
sl’]的余弦相似度,选择相似度最高的节点作为待解决运维工单的故障节点,其中l为所选节点路径长度。
[0040]
进一步的,匹配待解决运维工单解决方案的方式如下:
[0041]
根据上述选择待解决运维工单故障节点,选择属于该节点的所有历史解决方案。
[0042]
根据待解决运维工单的类别,计算待解决运维工单描述节点特征向量tu或ts与所选解决方案特征向量[r
u1’,r
u2’,
…
,r
uv’]或[r
s1’,r
s2’,
…
,r
sv’]的余弦相似度,选择相似度最高的解决方案作为待解决运维工单的解决方案,其中v为该节点下解决方案的数量。
[0043]
本发明的有益效果是:
[0044]
本发明通过根据用户运维工单和系统运维工单的特点,采取不同的特征提取方式,通过lstm提取用户工单的序列特征表示,通过lda提取系统工单的主题特征表示,为后续工单处理提供了更准确的信息。
[0045]
本发明通过构建系统节点依赖关系图,基于节点依赖路径匹配待解决运维工单故障节点,避免匹配全部节点,提高故障节点发现速度,以及通过gcn模型提取节点特征向量,增强节点信息表示。
[0046]
本发明通过用多个历史工单描述特征融合表示解决方案,提高了运维工单和解决方案匹配的准确度,解决了不同运维工单存在相同解决方案的问题。
附图说明
[0047]
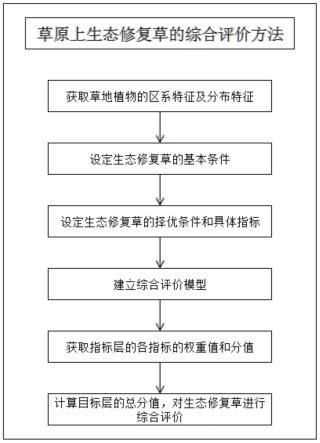
图1为本发明实施例运维工单自动化处理的流程示意图。
具体实施方式
[0048]
容易理解,根据本发明的技术方案,在不变更本发明实质精神下,本领域的一般技术人员可以提出可相互替换的多种结构方式以及实现方式。因此,以下具体实施方式以及
附图仅是对本发明的技术方案的示例性说明,而不应当视为本发明的全部或者视为对本发明技术方案的限定或限制。
[0049]
如图1所示,本发明是一种面向运维工单的自动化处理方法,该地方法包括如下步骤:
[0050]
s101,采集历史运维工单数据,根据工单生成方式为用户提交或系统生成,分别构建用户工单数据集和系统工单数据集。
[0051]
本发明实施例中,所采集工单数据包括工单编号、工单描述故障节点、工单实际故障节点、工单异常描述信息、工单对应解决方案。其中工单异常描述信息记录异常发生的特征、时间等,工单解决方案记录运维人员针对该异常提出的维修方法,由于异常描述和解决方案为机器生成或人工填写,可能包含非英语单词、符号、单词缩写、单词拼写错误等,因此需对文本进行预处理,去除冗余信息。
[0052]
具体的,上述s101步骤如下:
[0053]
s1011,选择一段时间的历史工单数据,按照工单故障类别比例分别采集若干历史用户运维工单和历史系统运维工单,所采集工单属性包括工单编号、工单描述故障节点、工单实际故障节点、工单异常描述信息、工单对应解决方案;
[0054]
s1012,若采集的工单存在属性值缺失,重新采集对应类别工单替换该工单;
[0055]
s1013,对所采集工单数据集进行文本预处理,包括符号过滤、去停止词、词形还原。
[0056]
s102,对用户工单数据集和系统工单数据集,采用svm分类模型训练,获得运维工单svm分类器。
[0057]
s103,统计所述数据集中历史运维工单的节点信息,基于专家知识构建运维工单节点依赖关系图。
[0058]
s104,对所述节点依赖关系图的每个节点,分别选取属于该节点的用户工单和系统工单,采用图卷积网络gcn获得节点的用户工单特征向量表示和系统工单特征向量表示。
[0059]
由于用户工单和系统工单的生成方式不同,用户工单为人工填写,异常描述信息更接近自然语言,包含更多的序列信息,而系统工单为系统根据模板自动生成,异常描述信息更接近机器语言,包含更多的模板信息。因此采用两种不同的方式处理用户工单和系统工单,使用长短期记忆神经网络lstm提取用户工单描述信息的序列特征,使用主题模型lda提取系统工单描述信息的主题特征。
[0060]
由于同一节点下可能包含多种工单,直接使用工单描述信息表示节点特征不够准确,同时节点间存在不同程度的依赖关系,因此采用图卷积网络gcn通过节点间的依赖关系和节点的工单信息表示提取节点的特征向量表示。
[0061]
具体的,上述s104步骤如下:
[0062]
s1041,对所述节点依赖关系图的每个节点,选取k个属于该节点的用户工单描述进行拼接组成节点的用户特征信息nu,选取k个属于该节点的系统工单描述进行拼接组成节点的系统特征信息ns。
[0063]
s1042,将系统节点的依赖关系用m*m维邻接矩阵a表示,其中m为节点数量,a[i][j]表示节点之间的依赖关系,依赖关系的权重为该依赖关系在历史工单描述故障节点和实际故障节点路径中的出现次数,a[i][i]=0表示节点间不存在依赖关系。
[0064]
s1043,对于用户工单,通过word2vec将节点用户特征信息tu转为节点词向量表示hu,将所述节点向量表示hu和邻接矩阵a输入用户gcn模型,获得节点的用户工单特征向量表示h
u’。
[0065]
s1044,对于系统工单,通过计算词频-逆文档频率将工单系统特征信息ts转为向量化表示hs,将所述节点向量表示hs和邻接矩阵a输入系统gcn模型,获得节点的系统工单特征向量表示h
s’。
[0066]
gcn模型的更新公式如下:
[0067][0068]
其中,为a i,i为单位矩阵,为节点入度矩阵,h
(l)
为节点l层特征表示,w
(l)
为模型l层权重矩阵,α为非线性变换。
[0069]
s105,对所述节点依赖关系图中每个节点下的不同的工单解决方案,每个解决方案选取属于该解决方案的历史用户工单描述和历史系统工单描述,获取该解决方案的用户序列特征向量表示和系统主题特征向量表示。
[0070]
由于系统环境和人工描述的差异,存在运维运维工单具有不同的异常描述信息,但对应的解决方案相同,传统直接匹配运维工单异常描述信息的方式准确度较低,因此本发明通过对属于不同解决方案的运维工单异常描述信息进行特征融合,提高解决方案的特征表示的准确性。
[0071]
具体的,上述s105步骤如下:
[0072]
s1051,对所述不同的解决方案,每个解决方案选取x个与该解决方案相匹配的历史用户工单描述,每个工单描述通过word2vec转换为词嵌入向量表示ru。
[0073]
s1052,将所述词嵌入向量表示ru依次输入lstm模型中获得x个含有序列信息的工单描述特征向量,将所述特征向量进行横向加和平均,获得该解决方案的用户序列特征向量r
u’。
[0074]
s1053,对所述不同的解决方案,每个解决方案选取x个与该解决方案相匹配的历史系统工单描述,每个工单描述通过计算词频-逆文档频率转换为向量表示rs。
[0075]
s1054,将所述向量表示rs依次输入lda模型中获得x个含有主题分布的工单描述特征向量,将所述特征向量进行横向加和平均,获得该解决方案的系统主题特征向量r
s’。
[0076]
s106,获取待解决运维工单描述信息,并进行上述文本预处理,采用所述svm分类器进行分类,确定运维工单所属类别。
[0077]
s107,根据运维工单所属类别,选择模型输入运维工单描述信息,获得工单特征向量表示。
[0078]
具体的,上述s107步骤如下:
[0079]
s1071,若待解决运维工单为用户工单,将描述信息通过word2vec转化为词嵌入向量表示,输入lstm模型,获得待解决运维工单的序列特征向量表示tu。
[0080]
s1072,若待解决运维工单为系统工单,将描述信息通过计算词频-逆文档频率转化为向量表示,输入lda模型,获得待解决运维工单的主题特征向量表示ts。
[0081]
s108,计算待解决工单特征向量与所述依赖关系图节点特征向量的相似度,选取相似度最高的节点作为待解决工单的故障节点。
[0082]
具体的,上述s108步骤如下:
[0083]
s1081,根据待解决运维工单描述故障节点,选择所述节点依赖关系图对应节点和上游依赖节点。
[0084]
s1082,根据待解决运维工单的类别,计算待解决运维工单描述节点特征向量tu或ts与所选节点特征向量[h
u1’,h
u2’,
…
,h
ul’]或[h
s1’,h
s2’,
…
,h
sl’]的余弦相似度,选择相似度最高的节点作为待解决运维工单的故障节点,其中l为所选节点路径长度。
[0085]
s109,根据选取故障节点,计算待解决工单特征向量和该节点下所有解决方案特征向量的相似度,选取相似度最高的解决方案作为待解决工单的解决方案。
[0086]
具体的,上述s109步骤如下:
[0087]
s1091,根据上述选择待解决运维工单故障节点,选择属于该节点的所有历史解决方案。
[0088]
s1092,根据待解决运维工单的类别,计算待解决运维工单描述节点特征向量tu或ts与所选解决方案特征向量[r
u1’,r
u2’,
…
,r
uv’]或[r
s1’,r
s2’,
…
,r
sv’]的余弦相似度,选择相似度最高的解决方案作为待解决运维工单的解决方案,其中v为该节点下解决方案的数量。
[0089]
综上所述,本发明通过lstm提取用户工单的序列特征表示,通过lda提取系统工单的主题特征表示,为后续工单处理提供了更准确的信息,本发明通过构建系统节点依赖关系图,基于节点依赖路径匹配待解决运维工单故障节点,避免匹配全部节点,提高故障节点发现速度,以及通过gcn模型提取节点特征向量,增强节点信息表示;本发明通过用多个历史工单描述特征融合表示解决方案,提高了运维工单和解决方案匹配的准确度,解决了不同运维工单存在相同解决方案的问题。
[0090]
以上所述仅为本发明的实施方式而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理的内所作的任何修改、等同替换、改进等,均应包括在本发明的权利要求范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。