1.本发明涉及中文语音合成技术领域,具体涉及一种儿化音合成方法、装置、电子设备及存储介质。
背景技术:
2.智能语音交互领域在近年来获得了长足瞩目的发展,逐渐成为国内外学术界、工业界的研究焦点,而其中实现机器“发声”的核心技术就是语音合成技术,其主要的功能是模仿人类的说话方式,通过文字产生相应的声音。通常在中文语音合成中,语音合成的基本单位是独立的每个字,或者是字对应的拼音等,可以直观地认为语音合成系统是将每个字单独映射成为对应的音频信号,但这其中也存在一些特殊情况,如普通话中的儿化音。儿化音是指一些字的末位韵母因卷舌动作而发生的音变现象,如“哪儿”通常会连读成一个卷舌的“哪”字音。
3.儿化音广泛存在于汉语的日常对话中,并且是十分多变的,并且没有固定的搭配形式,任意汉字后接“儿”字都有可能构成儿化音。这为语音合成系统的搭建带来了艰巨的挑战,因为在常用的语音数据集中很难涵盖所有儿化音出现的搭配情况,甚至在大多数数据集中儿化音只占很小的一部分,因而我们很难收集到足够多的儿化音对模型进行训练。
技术实现要素:
4.针对现有技术的不足,本发明提供了一种儿化音合成方法、装置、电子设备及存储介质,通过风格迁移模型构造足够多的儿化音数据,随后再用于语音合成模型进行儿化音数据的合成和语音转换,提高语音合成的系统鲁棒性。
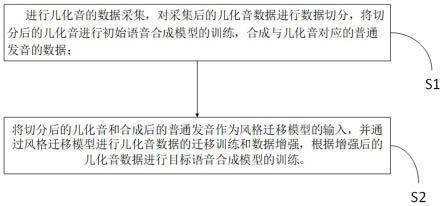
5.为了实现本发明的目的,本发明提供一种儿化音合成方法,包括如下步骤:s1:进行儿化音的数据采集,对采集后的儿化音数据进行数据切分,将切分后的儿化音进行初始语音合成模型的训练,用于合成与儿化音对应的普通发音的数据;s2:将切分后的儿化音和合成后的普通发音作为风格迁移模型的输入,并通过风格迁移模型进行儿化音数据的迁移训练和数据增强,根据增强后的儿化音数据进行目标语音合成模型的训练。
6.优选的,所述步骤s2中通过风格迁移模型进行儿化音数据的迁移训练的具体步骤为:将合成后的普通发音输送至cyclegan的第一对抗生成网络的第一生成器中,并进行儿化音的生成,将生成的儿化音作为第二对抗生成网络中的第二生成器的输入,并通过第二生成器进行普通发音的数据生成;其中,第一对抗生成网络还包括第一鉴别器,第二对抗生成网络还包括第二鉴别器,第一鉴别器用于鉴定第一生成器生成的数据是否为儿化音,第二鉴别器用于鉴定第二生成器转换的数据是否为普通发音。
7.优选的,所述步骤s2中通过风格迁移模型进行儿化音数据的数据增强的具体步骤
为:将经过风格迁移模型的第一生成器生成的儿化音数据输送至初始语音合成模型中进行训练,并通过语音合成模型进行普通发音数据的合成,将合成后的普通发音数据再次通过第一生成器进行儿化音数据的生成。
8.优选的,所述cyclegan的损失函数总和计算公式为:e=x y z其中,x代表第一鉴别器和第二鉴别器的使用损失,y代表第一生成器转换后的儿化音和增强后的儿化音的损失,z代表第二生成器转换后的普通发音和采集的儿化音的损失。
9.优选的,所述步骤s2中的目标语音合成模型用于将增强后的儿化音数据转换成相应的语音数据输出。
10.优选的,本发明还提供一种儿化音合成装置,包括:获取模块:采集儿化音的数据,并根据采集的儿化音进行数据切分;风格迁移模块:用于进行儿化音和普通发音之间的数据迁移和数据增强;合成模块:包括初始语音合成模块和目标语音合成模块;初始语音合成模块:用于用于合成与儿化音对应的普通发音的数据;目标语音合成模块:用于对增强后的儿化音进行训练并转换成语音数据输出。
11.优选的,所述风格迁移模块包括:第一生成模块:用于生成与普通发音相对应的儿化音;第二生成模块:将第一生成模块生成的儿化音进行普通发音的生成;第一鉴定模块:用于鉴定第一生成模块生成后的数据是否为儿化音;第二鉴定模块:用于鉴定第二生成模块转换后的数据是否为普通发音。
12.优选的,所述风格迁移模块还包括:数据增强模块:将经过风格迁移模块的第一生成模块生成的儿化音输送至初始语音合成模块中进行训练,并通过语音合成模块进行普通发音数据的合成,将合成后的普通发音数据再次通过第一生成模块进行儿化音数据的生成。
13.优选的,本发明还提供了一种电子设备,包括存储器和位于存储器上的至少一个计算机程序;还包括至少一个处理器,用于处理所述存储器中的至少一个计算机程序,所述处理器执行所述计算机程序时,实现上述实施例中的儿化音合成方法。
14.优选的,本发明还提供了一种计算机存储介质,所述计算机介质上存储有至少一个计算机程序,所述计算机程序在被执行时实现上述优选实施例中的儿化音合成方法。
15.本发明的有益效果为:本发明提供的儿化音合成方法、装置、电子设备及存储介质,通过风格迁移模型构造足够多的儿化音数据,随后再用于语音合成模型进行儿化音数据的合成和语音转换,提高语音合成的系统鲁棒性。
附图说明
16.通过附图中所示的本发明优选实施例更具体说明,本发明上述及其它目的、特征和优势将变得更加清晰。在全部附图中相同的附图标记指示相同的部分,且并未刻意按实
际尺寸等比例缩放绘制附图,重点在于示出本的主旨。
17.图1为本发明实施例提供的儿化音合成方法的具体流程示意图;图2为本发明实施例提供的初始语音合成模型训练的流程示意图;图3为本发明实施例提供的儿化音数据生成阶段的流程示意图。
具体实施方式
18.下面结合附图和具体实施例对本发明技术方案作进一步的详细描述,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
19.请参考图1-3,本发明实施例提供一种儿化音合成方法,包括如下步骤:s1:进行儿化音的数据采集,对采集后的儿化音数据进行数据切分,将切分后的儿化音进行初始语音合成模型的训练,用于合成与儿化音对应的普通发音的数据;s2:将切分后的儿化音和合成后的普通发音作为风格迁移模型的输入,并通过风格迁移模型进行儿化音数据的迁移训练和数据增强,根据增强后的儿化音数据进行目标语音合成模型的训练。
20.请参考图1-3,所采集的儿化音的数据主要为常用中文语音数据集中的儿化音数据,也可为其他数据集中的儿化音数据,所采集的儿化音的数据为文本数据,然后对采集的儿化音进行切分备用,例如:采集的儿化音语句段为“你到哪儿去、我们在这儿”,切分步骤则是将“你到哪儿去、我们在这儿”中的“哪儿和这儿”从语句中切分并提取出来(此处的切分手段包括手工切分、利用语音对齐工具,也可采用其他切分手段),然后将切分好的儿化音数据(哪儿和这儿)输送至初始语音合成模型中,然后通过初始语音合成模型将切分好的儿化音数据进行相对应的普通发音的数据合成,如将儿化音数据(哪儿和这儿)合成为普通发音数据(哪和这),然后将儿化音数据和普通发音数据作为数据对,用来作为风格迁移模型的输入(原材料);然后对数据进行迁移模型的训练和数据增强,具体为:将普通发音迁移成儿化音,例如:将“哪”字的正常发音转换成为其在儿化音场景下的发音,即“哪儿”的音频,随后可生成任意文字的儿化音发音作为语音合成系统的训练数据,达到数据增强(扩充)的目的,然后将增强后的儿化音输送至目标语音合成模型中进行训练即可。
21.本发明的有益效果为:本发明提供的儿化音合成方法、装置、电子设备及存储介质,主要采用风格迁移模型先对儿化音数据进行增强,然后通过语音合成模型将对增强后的儿化音数据进行训练,一定程度上提高了语音合成模型的鲁棒性。
22.请参考图1-3,在优选实施例中,步骤s2中通过风格迁移模型进行儿化音数据的迁移训练的具体步骤为:将合成后的普通发音输送至cyclegan的第一对抗生成网络的第一生成器中,并进行儿化音的生成,将生成的儿化音作为第二对抗生成网络中的第二生成器的输入,并通过第二生成器进行普通发音的数据生成;其中,第一对抗生成网络还包括第一鉴别器,第二对抗生成网络还包括第二鉴别器,第一鉴别器用于鉴定第一生成器生成的数据是否为儿化音,第二鉴别器用于鉴定第二生成器转换的数据是否为普通发音。
23.cyclegan中包含两个对抗生成网络,对于第一对抗生成网络gan1,生成器g1需要将
普通读音a
ori
转化为儿化音发音a
erhua
,如将“哪”转化为“哪儿”,鉴别器d
erhua
需要鉴别生成器生成的是不是儿化音发音。对于第二生成对抗网络g2,它的生成器g2需要将的g1输出a
erhua
作为输入,然后将儿化音转化为普通读音,如将“哪儿”转换为“哪”,得到a-ori
,第二个鉴别器d
ori
用于鉴别a-ori
是不是普通读音。
24.本技术提供的儿化音合成方法,主要采用cyclegan的风格迁移方法,该风格迁移学习模型主要通过构建两个生成对抗网络(第一、第二生成对抗网络)和两个鉴别器(第一、第二鉴别器)来完成普通发音到儿化音发音的目标迁移学习任务,在训练过程中,固定判别器参数训练生成器(第一生成器和第一鉴别器、第二生成器和第二鉴别器),使得生成的儿化音发音在分布上更接近于目标儿化音发音,固定生成器的参数训练判别器使得判别器有更好的辨别能力从而保证生成器能产生更加真实的儿化音发音;训练过程中还有一个重要损失(cyclegan的损失函数)是,用来防止生成的儿化音发音内容本身发生改变。
25.请参考图2,在图2中,通过初始语音合成模型(系统)对切分后的儿化音数据进行相对应的普通发音的数据合成,然后将普通发音和对应的儿化音数据(作为输入)一并输送至风格迁移模型(风格转换模型)中进行风格迁移。
26.请参考图1-3,在优选实施例中,步骤s2中通过风格迁移模型进行儿化音数据的数据增强的具体步骤为:将经过风格迁移模型的第一生成器生成的儿化音数据输送至初始语音合成模型中进行训练,并通过语音合成模型进行普通发音数据的合成,将合成后的普通发音数据再次通过第一生成器进行儿化音数据的生成。
27.数据增强(扩充)主要是将经过风格迁移模型训练后的儿化音数据通过初始语音合成模型进行普通发音的生成,在将普通发音输送至第一生成器进行儿化音数据的生成,并将生成的儿化音数据存储在目标语音合成模型中,并将儿化音数据转换成语音数据输出。
28.请参考图3,在图3中,先通过初始语音合成模型(初始语音合成系统)对切分后的儿化音数据进行相应的普通发音的数据合成,然后通过风格转换模型(风格迁移模型)进行迁移,从而达到数据增强和扩充的效果。
29.请参考图1,在进一步的优选实施例中,cyclegan的损失函数总和计算公式为:e=x y z其中,x代表第一鉴别器和第二鉴别器的使用损失(指判断是目标儿化音发音的概率和是否是生成的儿化音概率的对数之和),y代表第一生成器转换后的儿化音和增强后的儿化音的损失(a
erhua
与目标儿化音音频的损失),z代表第二生成器转换后的普通发音和采集的儿化音的损失(a-ori
与原始的儿化音音频的损失)。
30.请参考图1-3,在进一步的优选实施例中,步骤s2中的目标语音合成模型用于将增强后的儿化音数据转换成相应的语音数据输出。
31.目标语音合成模型为基础的tts语音合成模型,是从文本到语音的合成模型,也就是说将增强后的儿化音文本数据转换成语音数据作为输出,而步骤s1中的初始语音合成模型指的是用于用于合成与儿化音对应的普通发音的数据。
32.在cyclegan(对抗生成网络)模型训练完毕后,则通过第一对抗生成网络和初始语音合成模型进行结合使用,将第一生成器生成的儿化音数据进行初始语音合成模型的训
练,合成相对应的普通发音的数据,在将普通发音的数据再次通过第一生成器进行相对应的儿化音数据的生成,从而达到数据增强(扩充)的结果。
33.请参考图2-3,在进一步的优选实施例中,本发明还提供了一种儿化音合成装置,包括:获取模块:采集儿化音的数据,并根据采集的儿化音进行数据切分;风格迁移模块:用于进行儿化音和普通发音之间的数据迁移和数据增强;合成模块:包括初始语音合成模块和目标语音合成模块;初始语音合成模块:用于用于合成与儿化音对应的普通发音的数据;目标语音合成模块:用于对增强后的儿化音进行训练并转换成语音数据输出。
34.请参考图2-3,在优选实施例中,风格迁移模块包括:风格迁移模块包括:第一生成模块:用于生成与普通发音相对应的儿化音;第二生成模块:将第一生成模块生成的儿化音进行普通发音的生成;第一鉴定模块:用于鉴定第一生成模块生成后的数据是否为儿化音;第二鉴定模块:用于鉴定第二生成模块转换后的数据是否为普通发音。
35.请参考图2-3,在优选实施例中,风格迁移模块还包括:数据增强模块:将经过风格迁移模块的第一生成模块生成的儿化音输送至初始语音合成模块中进行训练,并通过语音合成模块进行普通发音数据的合成,将合成后的普通发音数据再次通过第一生成模块进行儿化音数据的生成。
36.请参考图1-3,在优选实施例中,本发明还提供了一种电子设备,包括:存储器和位于存储器上的至少一个计算机程序;还包括至少一个处理器,用于处理存储器中的至少一个计算机程序,处理器执行计算机程序时,实现上述实施例中的儿化音合成方法。
37.电子设备可以是手机、电脑以及能够实现计算机程序的移动终端等。
38.请参考图1-3,在优选实施例中,本发明还提供了一种计算机存储介质,计算机介质上存储有至少一个计算机程序,计算机程序在被执行时实现上述实施例中的儿化音合成方法。计算机存储介质可以是u盘、闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等多种介质。
39.本发明的有益效果为:本发明提供了一种儿化音合成方法、装置、电子设备及存储介质,通过风格迁移模型构造足够多的儿化音数据,随后再用于语音合成模型进行儿化音数据的合成和语音转换,提高语音合成的系统鲁棒性。
40.以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。